 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Meeting Transcription System for an Ad-Hoc Acoustic Sensor Network
May 02, 2022
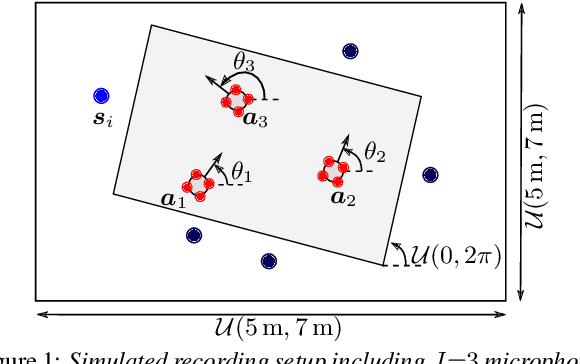
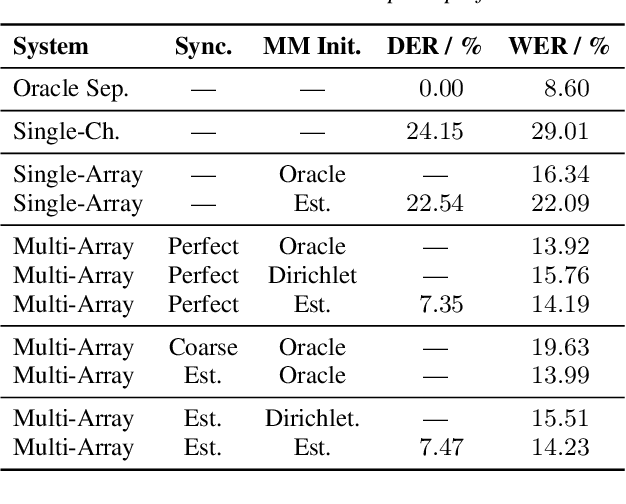
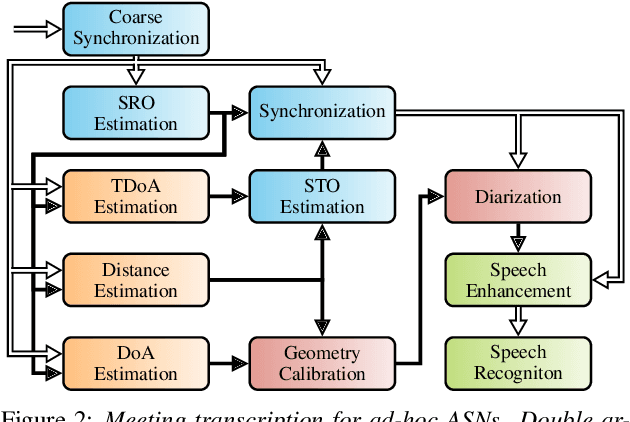
We propose a system that transcribes the conversation of a typical meeting scenario that is captured by a set of initially unsynchronized microphone arrays at unknown positions. It consists of subsystems for signal synchronization, including both sampling rate and sampling time offset estimation, diarization based on speaker and microphone array position estimation, multi-channel speech enhancement, and automatic speech recognition. With the estimated diarization information, a spatial mixture model is initialized that is used to estimate beamformer coefficients for source separation. Simulations show that the speech recognition accuracy can be improved by synchronizing and combining multiple distributed microphone arrays compared to a single compact microphone array. Furthermore, the proposed informed initialization of the spatial mixture model delivers a clear performance advantage over random initialization.
2D versus 3D Convolutional Spiking Neural Networks Trained with Unsupervised STDP for Human Action Recognition
May 26, 2022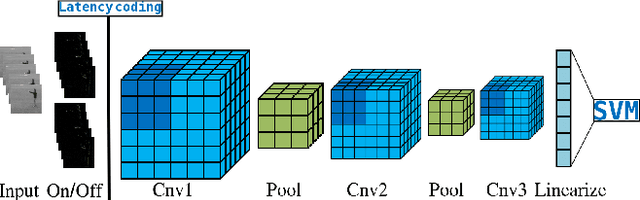
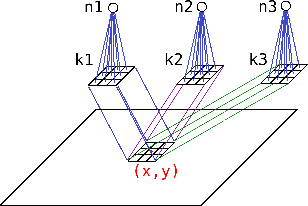
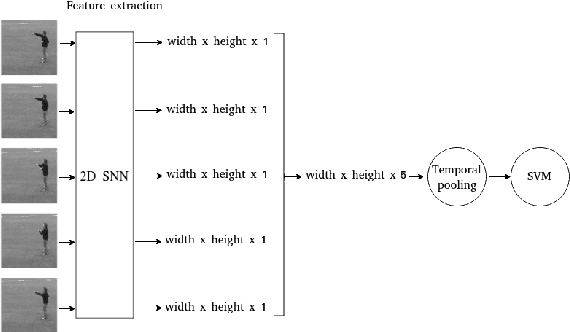
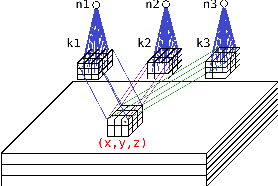
Current advances in technology have highlighted the importance of video analysis in the domain of computer vision. However, video analysis has considerably high computational costs with traditional artificial neural networks (ANNs). Spiking neural networks (SNNs) are third generation biologically plausible models that process the information in the form of spikes. Unsupervised learning with SNNs using the spike timing dependent plasticity (STDP) rule has the potential to overcome some bottlenecks of regular artificial neural networks, but STDP-based SNNs are still immature and their performance is far behind that of ANNs. In this work, we study the performance of SNNs when challenged with the task of human action recognition, because this task has many real-time applications in computer vision, such as video surveillance. In this paper we introduce a multi-layered 3D convolutional SNN model trained with unsupervised STDP. We compare the performance of this model to those of a 2D STDP-based SNN when challenged with the KTH and Weizmann datasets. We also compare single-layer and multi-layer versions of these models in order to get an accurate assessment of their performance. We show that STDP-based convolutional SNNs can learn motion patterns using 3D kernels, thus enabling motion-based recognition from videos. Finally, we give evidence that 3D convolution is superior to 2D convolution with STDP-based SNNs, especially when dealing with long video sequences.
Follow-the-Perturbed-Leader for Adversarial Markov Decision Processes with Bandit Feedback
May 26, 2022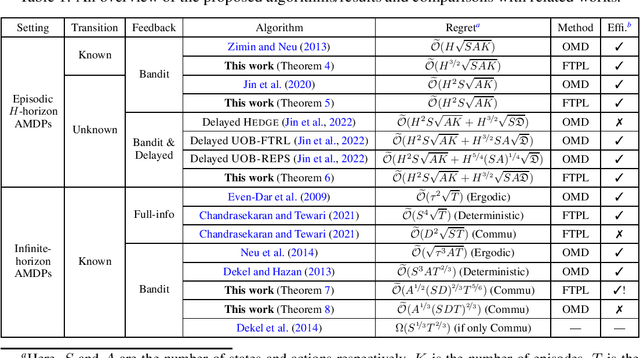
We consider regret minimization for Adversarial Markov Decision Processes (AMDPs), where the loss functions are changing over time and adversarially chosen, and the learner only observes the losses for the visited state-action pairs (i.e., bandit feedback). While there has been a surge of studies on this problem using Online-Mirror-Descent (OMD) methods, very little is known about the Follow-the-Perturbed-Leader (FTPL) methods, which are usually computationally more efficient and also easier to implement since it only requires solving an offline planning problem. Motivated by this, we take a closer look at FTPL for learning AMDPs, starting from the standard episodic finite-horizon setting. We find some unique and intriguing difficulties in the analysis and propose a workaround to eventually show that FTPL is also able to achieve near-optimal regret bounds in this case. More importantly, we then find two significant applications: First, the analysis of FTPL turns out to be readily generalizable to delayed bandit feedback with order-optimal regret, while OMD methods exhibit extra difficulties (Jin et al., 2022). Second, using FTPL, we also develop the first no-regret algorithm for learning communicating AMDPs in the infinite-horizon setting with bandit feedback and stochastic transitions. Our algorithm is efficient assuming access to an offline planning oracle, while even for the easier full-information setting, the only existing algorithm (Chandrasekaran and Tewari, 2021) is computationally inefficient.
ROMA: Cross-Domain Region Similarity Matching for Unpaired Nighttime Infrared to Daytime Visible Video Translation
Apr 26, 2022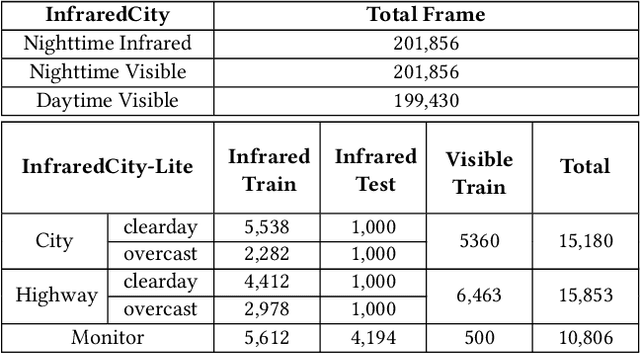
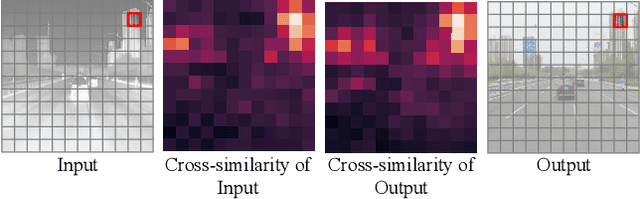
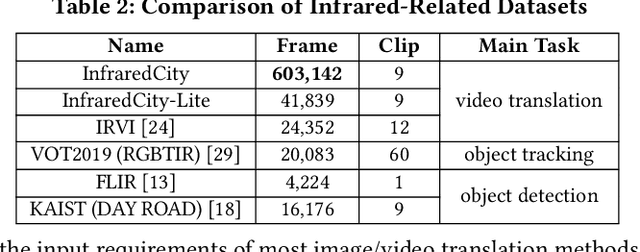
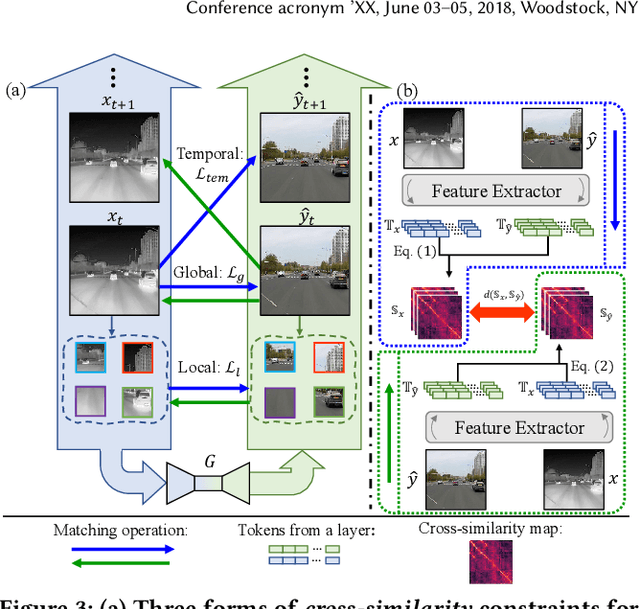
Infrared cameras are often utilized to enhance the night vision since the visible light cameras exhibit inferior efficacy without sufficient illumination. However, infrared data possesses inadequate color contrast and representation ability attributed to its intrinsic heat-related imaging principle. This makes it arduous to capture and analyze information for human beings, meanwhile hindering its application. Although, the domain gaps between unpaired nighttime infrared and daytime visible videos are even huger than paired ones that captured at the same time, establishing an effective translation mapping will greatly contribute to various fields. In this case, the structural knowledge within nighttime infrared videos and semantic information contained in the translated daytime visible pairs could be utilized simultaneously. To this end, we propose a tailored framework ROMA that couples with our introduced cRoss-domain regiOn siMilarity mAtching technique for bridging the huge gaps. To be specific, ROMA could efficiently translate the unpaired nighttime infrared videos into fine-grained daytime visible ones, meanwhile maintain the spatiotemporal consistency via matching the cross-domain region similarity. Furthermore, we design a multiscale region-wise discriminator to distinguish the details from synthesized visible results and real references. Extensive experiments and evaluations for specific applications indicate ROMA outperforms the state-of-the-art methods. Moreover, we provide a new and challenging dataset encouraging further research for unpaired nighttime infrared and daytime visible video translation, named InfraredCity. In particular, it consists of 9 long video clips including City, Highway and Monitor scenarios. All clips could be split into 603,142 frames in total, which are 20 times larger than the recently released daytime infrared-to-visible dataset IRVI.
Zero Shot Crosslingual Eye-Tracking Data Prediction using Multilingual Transformer Models
Mar 30, 2022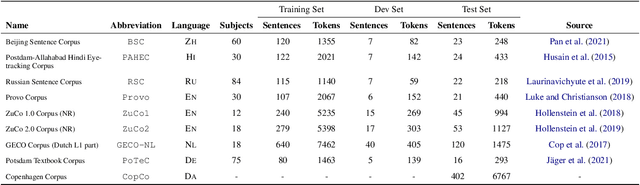
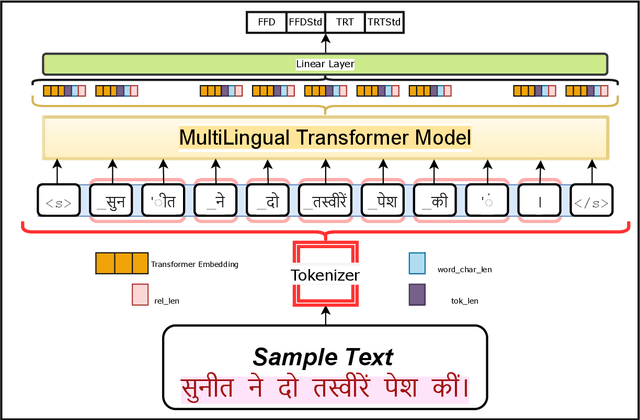
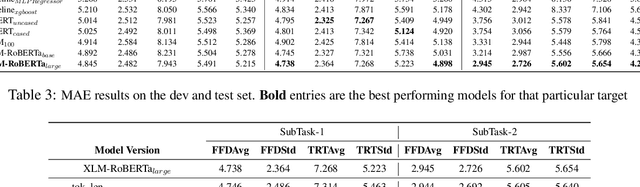
Eye tracking data during reading is a useful source of information to understand the cognitive processes that take place during language comprehension processes. Different languages account for different brain triggers , however there seems to be some uniform indicators. In this paper, we describe our submission to the CMCL 2022 shared task on predicting human reading patterns for multi-lingual dataset. Our model uses text representations from transformers and some hand engineered features with a regression layer on top to predict statistical measures of mean and standard deviation for 2 main eye-tracking features. We train an end to end model to extract meaningful information from different languages and test our model on two seperate datasets. We compare different transformer models and show ablation studies affecting model performance. Our final submission ranked 4th place for SubTask-1 and 1st place for SubTask-2 for the shared task.
GraphAD: A Graph Neural Network for Entity-Wise Multivariate Time-Series Anomaly Detection
May 23, 2022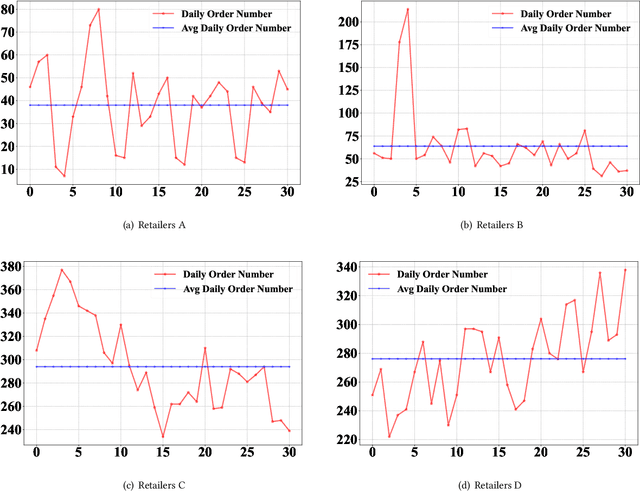
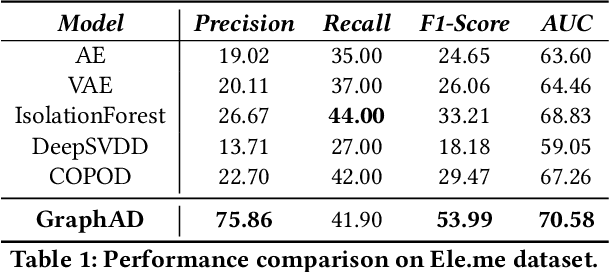
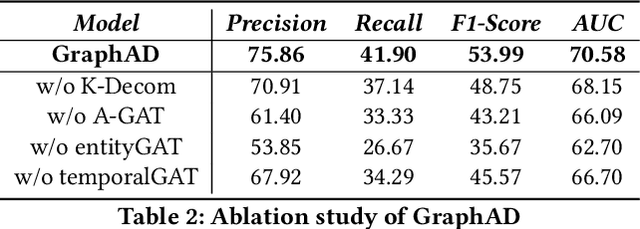
In recent years, the emergence and development of third-party platforms have greatly facilitated the growth of the Online to Offline (O2O) business. However, the large amount of transaction data raises new challenges for retailers, especially anomaly detection in operating conditions. Thus, platforms begin to develop intelligent business assistants with embedded anomaly detection methods to reduce the management burden on retailers. Traditional time-series anomaly detection methods capture underlying patterns from the perspectives of time and attributes, ignoring the difference between retailers in this scenario. Besides, similar transaction patterns extracted by the platforms can also provide guidance to individual retailers and enrich their available information without privacy issues. In this paper, we pose an entity-wise multivariate time-series anomaly detection problem that considers the time-series of each unique entity. To address this challenge, we propose GraphAD, a novel multivariate time-series anomaly detection model based on the graph neural network. GraphAD decomposes the Key Performance Indicator (KPI) into stable and volatility components and extracts their patterns in terms of attributes, entities and temporal perspectives via graph neural networks. We also construct a real-world entity-wise multivariate time-series dataset from the business data of Ele.me. The experimental results on this dataset show that GraphAD significantly outperforms existing anomaly detection methods.
MSTRIQ: No Reference Image Quality Assessment Based on Swin Transformer with Multi-Stage Fusion
May 23, 2022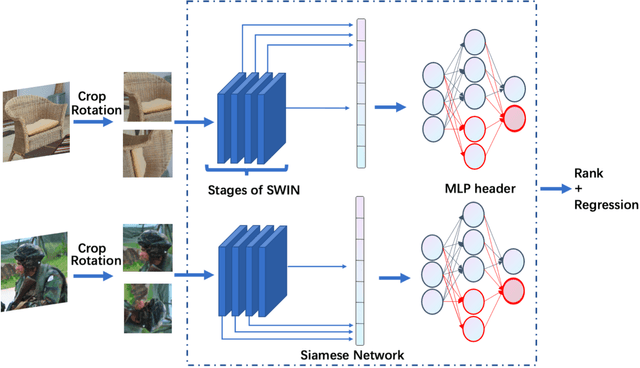
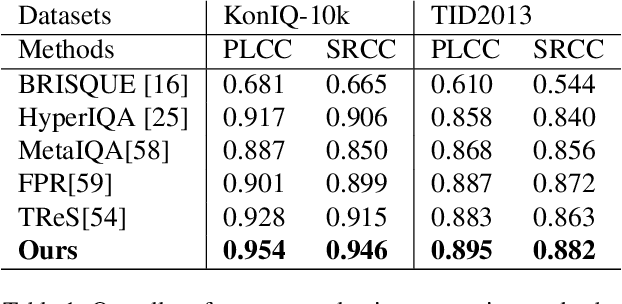
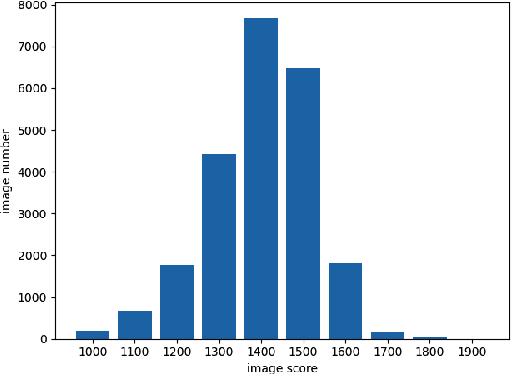
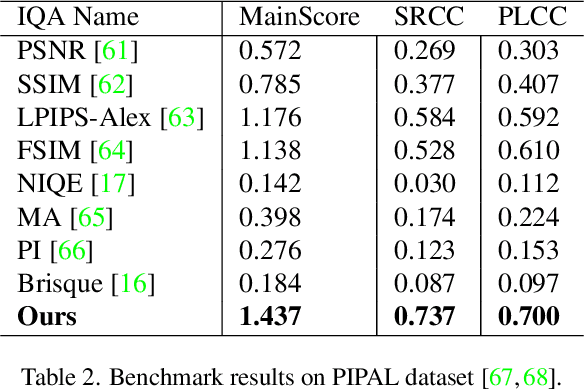
Measuring the perceptual quality of images automatically is an essential task in the area of computer vision, as degradations on image quality can exist in many processes from image acquisition, transmission to enhancing. Many Image Quality Assessment(IQA) algorithms have been designed to tackle this problem. However, it still remains un settled due to the various types of image distortions and the lack of large-scale human-rated datasets. In this paper, we propose a novel algorithm based on the Swin Transformer [31] with fused features from multiple stages, which aggregates information from both local and global features to better predict the quality. To address the issues of small-scale datasets, relative rankings of images have been taken into account together with regression loss to simultaneously optimize the model. Furthermore, effective data augmentation strategies are also used to improve the performance. In comparisons with previous works, experiments are carried out on two standard IQA datasets and a challenge dataset. The results demonstrate the effectiveness of our work. The proposed method outperforms other methods on standard datasets and ranks 2nd in the no-reference track of NTIRE 2022 Perceptual Image Quality Assessment Challenge [53]. It verifies that our method is promising in solving diverse IQA problems and thus can be used to real-word applications.
Social Interpretable Tree for Pedestrian Trajectory Prediction
May 26, 2022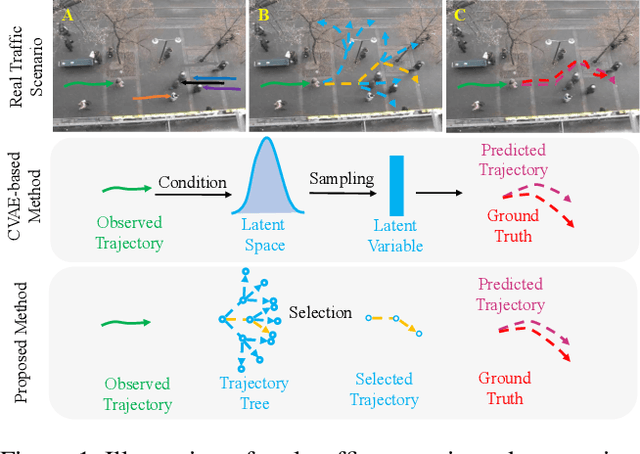
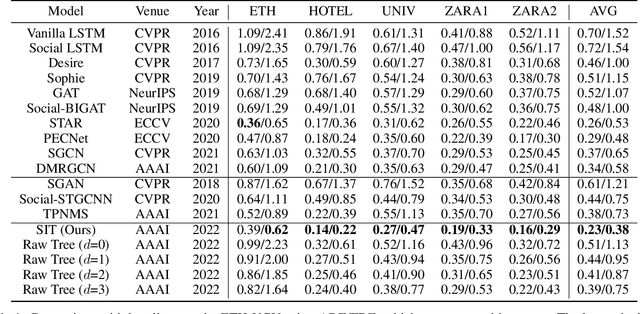
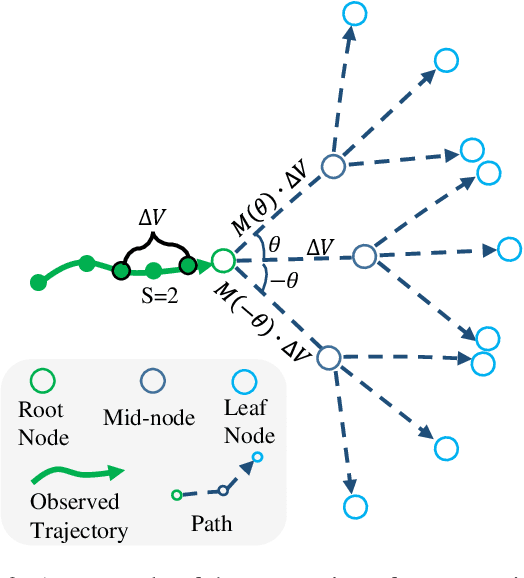
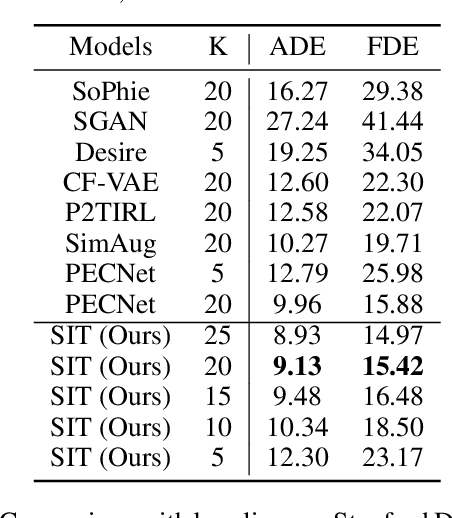
Understanding the multiple socially-acceptable future behaviors is an essential task for many vision applications. In this paper, we propose a tree-based method, termed as Social Interpretable Tree (SIT), to address this multi-modal prediction task, where a hand-crafted tree is built depending on the prior information of observed trajectory to model multiple future trajectories. Specifically, a path in the tree from the root to leaf represents an individual possible future trajectory. SIT employs a coarse-to-fine optimization strategy, in which the tree is first built by high-order velocity to balance the complexity and coverage of the tree and then optimized greedily to encourage multimodality. Finally, a teacher-forcing refining operation is used to predict the final fine trajectory. Compared with prior methods which leverage implicit latent variables to represent possible future trajectories, the path in the tree can explicitly explain the rough moving behaviors (e.g., go straight and then turn right), and thus provides better interpretability. Despite the hand-crafted tree, the experimental results on ETH-UCY and Stanford Drone datasets demonstrate that our method is capable of matching or exceeding the performance of state-of-the-art methods. Interestingly, the experiments show that the raw built tree without training outperforms many prior deep neural network based approaches. Meanwhile, our method presents sufficient flexibility in long-term prediction and different best-of-$K$ predictions.
End-to-End Zero-Shot Voice Style Transfer with Location-Variable Convolutions
May 19, 2022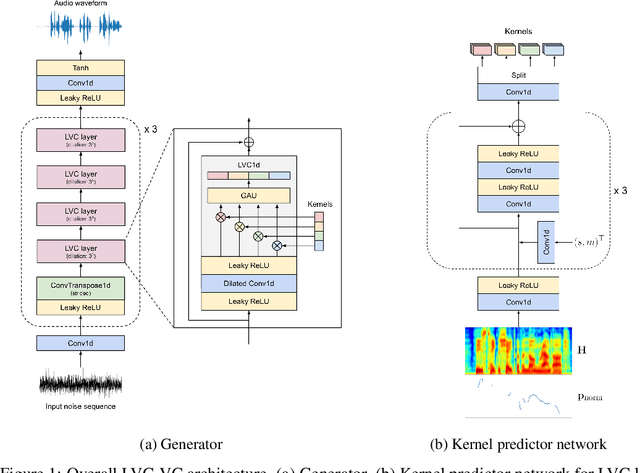
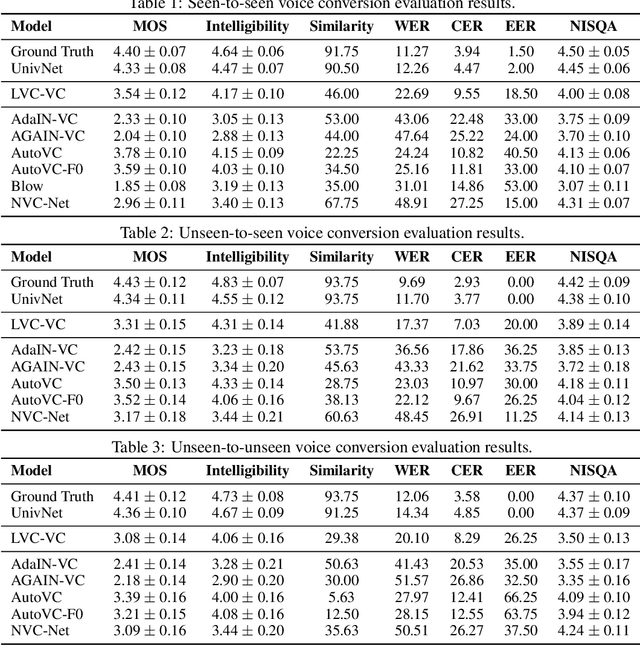

Zero-shot voice conversion is becoming an increasingly popular research direction, as it promises the ability to transform speech to match the voice style of any speaker. However, little work has been done on end-to-end methods for this task, which are appealing because they remove the need for a separate vocoder to generate audio from intermediate features. In this work, we propose Location-Variable Convolution-based Voice Conversion (LVC-VC), a model for performing end-to-end zero-shot voice conversion that is based on a neural vocoder. LVC-VC utilizes carefully designed input features that have disentangled content and speaker style information, and the vocoder-like architecture learns to combine them to simultaneously perform voice conversion while synthesizing audio. To the best of our knowledge, LVC-VC is one of the first models to be proposed that can perform zero-shot voice conversion in an end-to-end manner, and it is the first to do so using a vocoder-like neural framework. Experiments show that our model achieves competitive or better voice style transfer performance compared to several baselines while maintaining the intelligibility of transformed speech much better.
A 3-stage Spectral-spatial Method for Hyperspectral Image Classification
Apr 20, 2022
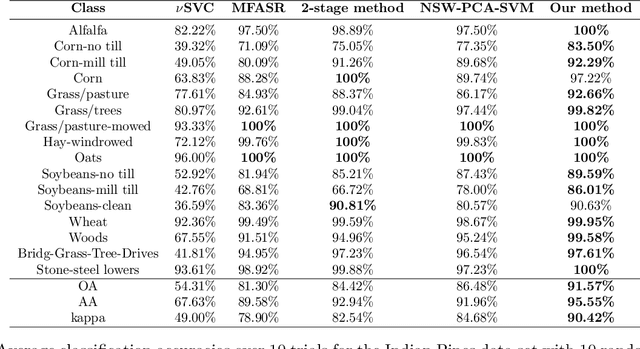
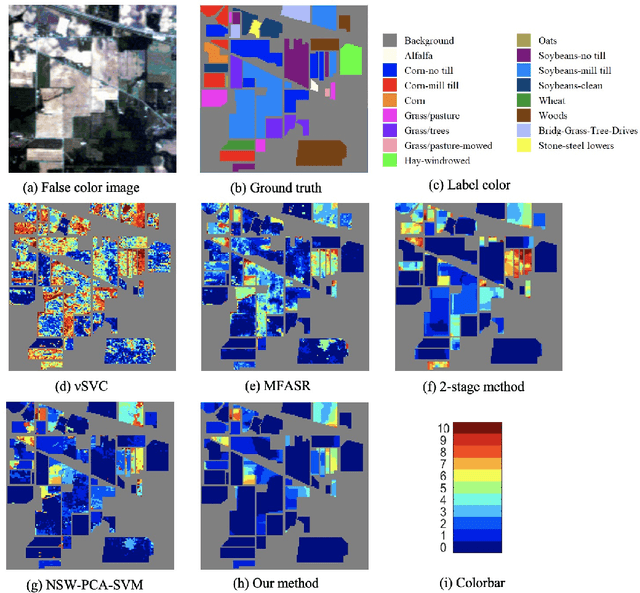
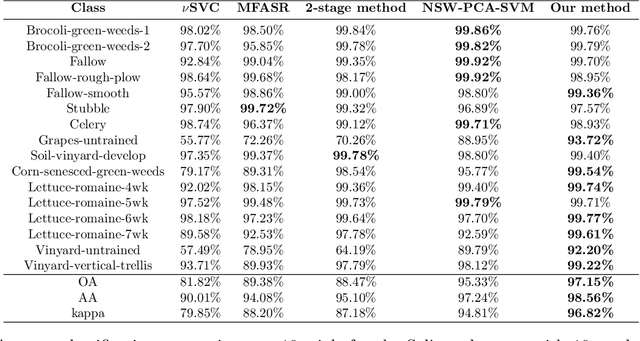
Hyperspectral images often have hundreds of spectral bands of different wavelengths captured by aircraft or satellites that record land coverage. Identifying detailed classes of pixels becomes feasible due to the enhancement in spectral and spatial resolution of hyperspectral images. In this work, we propose a novel framework that utilizes both spatial and spectral information for classifying pixels in hyperspectral images. The method consists of three stages. In the first stage, the pre-processing stage, Nested Sliding Window algorithm is used to reconstruct the original data by {enhancing the consistency of neighboring pixels} and then Principal Component Analysis is used to reduce the dimension of data. In the second stage, Support Vector Machines are trained to estimate the pixel-wise probability map of each class using the spectral information from the images. Finally, a smoothed total variation model is applied to smooth the class probability vectors by {ensuring spatial connectivity} in the images. We demonstrate the superiority of our method against three state-of-the-art algorithms on six benchmark hyperspectral data sets with 10 to 50 training labels for each class. The results show that our method gives the overall best performance in accuracy. Especially, our gain in accuracy increases when the number of labeled pixels decreases and therefore our method is more advantageous to be applied to problems with small training set. Hence it is of great practical significance since expert annotations are often expensive and difficult to collect.