 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Embedded Clustering with Distribution Consistency Preservation for Attributed Networks
May 28, 2022
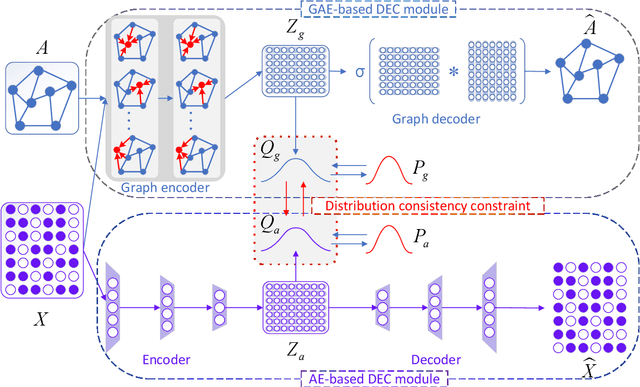
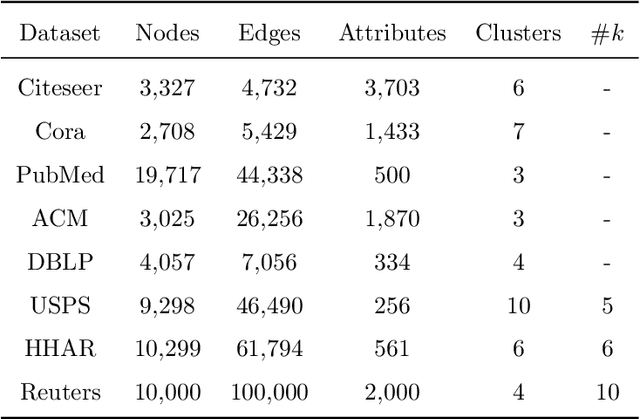

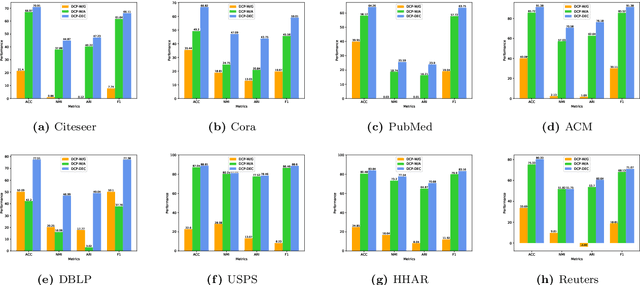
Many complex systems in the real world can be characterized by attributed networks. To mine the potential information in these networks, deep embedded clustering, which obtains node representations and clusters simultaneously, has been paid much attention in recent years. Under the assumption of consistency for data in different views, the cluster structure of network topology and that of node attributes should be consistent for an attributed network. However, many existing methods ignore this property, even though they separately encode node representations from network topology and node attributes meanwhile clustering nodes on representation vectors learnt from one of the views. Therefore, in this study, we propose an end-to-end deep embedded clustering model for attributed networks. It utilizes graph autoencoder and node attribute autoencoder to respectively learn node representations and cluster assignments. In addition, a distribution consistency constraint is introduced to maintain the latent consistency of cluster distributions of two views. Extensive experiments on several datasets demonstrate that the proposed model achieves significantly better or competitive performance compared with the state-of-the-art methods. The source code can be found at https://github.com/Zhengymm/DCP.
Predicting non-native speech perception using the Perceptual Assimilation Model and state-of-the-art acoustic models
May 31, 2022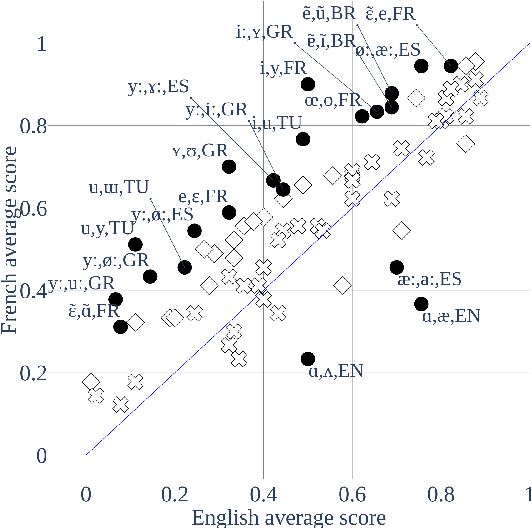
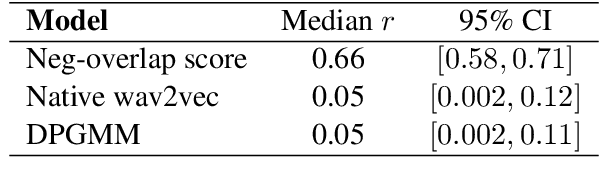
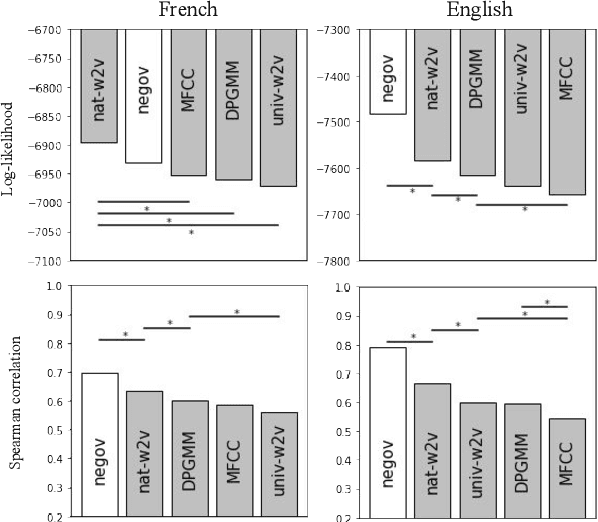

Our native language influences the way we perceive speech sounds, affecting our ability to discriminate non-native sounds. We compare two ideas about the influence of the native language on speech perception: the Perceptual Assimilation Model, which appeals to a mental classification of sounds into native phoneme categories, versus the idea that rich, fine-grained phonetic representations tuned to the statistics of the native language, are sufficient. We operationalize this idea using representations from two state-of-the-art speech models, a Dirichlet process Gaussian mixture model and the more recent wav2vec 2.0 model. We present a new, open dataset of French- and English-speaking participants' speech perception behaviour for 61 vowel sounds from six languages. We show that phoneme assimilation is a better predictor than fine-grained phonetic modelling, both for the discrimination behaviour as a whole, and for predicting differences in discriminability associated with differences in native language background. We also show that wav2vec 2.0, while not good at capturing the effects of native language on speech perception, is complementary to information about native phoneme assimilation, and provides a good model of low-level phonetic representations, supporting the idea that both categorical and fine-grained perception are used during speech perception.
Feature Learning in $L_{2}$-regularized DNNs: Attraction/Repulsion and Sparsity
May 31, 2022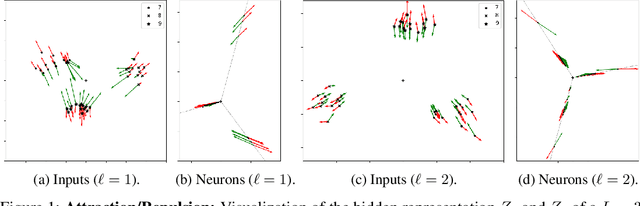
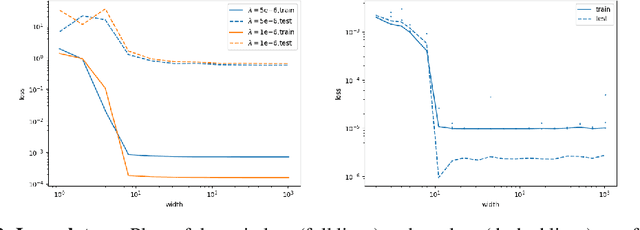
We study the loss surface of DNNs with $L_{2}$ regularization. We show that the loss in terms of the parameters can be reformulated into a loss in terms of the layerwise activations $Z_{\ell}$ of the training set. This reformulation reveals the dynamics behind feature learning: each hidden representations $Z_{\ell}$ are optimal w.r.t. to an attraction/repulsion problem and interpolate between the input and output representations, keeping as little information from the input as necessary to construct the activation of the next layer. For positively homogeneous non-linearities, the loss can be further reformulated in terms of the covariances of the hidden representations, which takes the form of a partially convex optimization over a convex cone. This second reformulation allows us to prove a sparsity result for homogeneous DNNs: any local minimum of the $L_{2}$-regularized loss can be achieved with at most $N(N+1)$ neurons in each hidden layer (where $N$ is the size of the training set). We show that this bound is tight by giving an example of a local minimum which requires $N^{2}/4$ hidden neurons. But we also observe numerically that in more traditional settings much less than $N^{2}$ neurons are required to reach the minima.
A Spiking Neural Network based on Neural Manifold for Augmenting Intracortical Brain-Computer Interface Data
Mar 26, 2022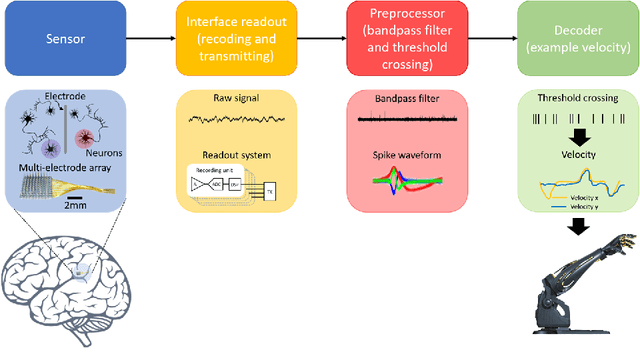
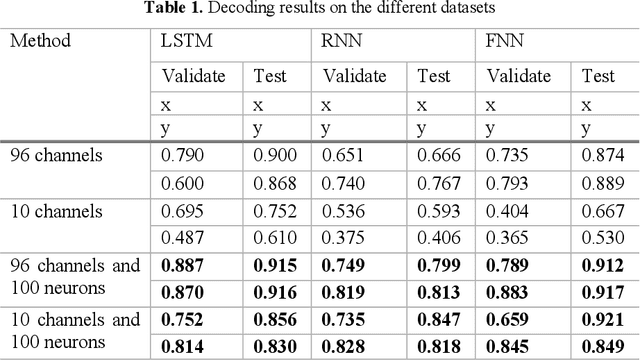
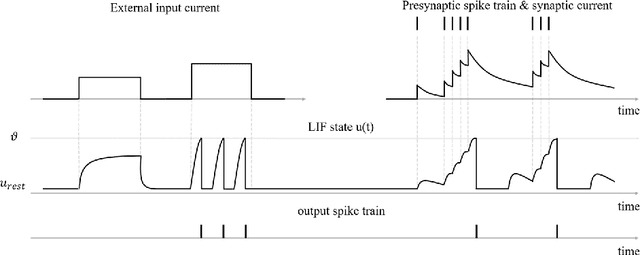
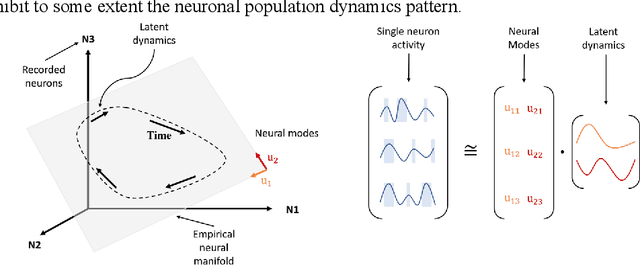
Brain-computer interfaces (BCIs), transform neural signals in the brain into in-structions to control external devices. However, obtaining sufficient training data is difficult as well as limited. With the advent of advanced machine learning methods, the capability of brain-computer interfaces has been enhanced like never before, however, these methods require a large amount of data for training and thus require data augmentation of the limited data available. Here, we use spiking neural networks (SNN) as data generators. It is touted as the next-generation neu-ral network and is considered as one of the algorithms oriented to general artifi-cial intelligence because it borrows the neural information processing from bio-logical neurons. We use the SNN to generate neural spike information that is bio-interpretable and conforms to the intrinsic patterns in the original neural data. Ex-periments show that the model can directly synthesize new spike trains, which in turn improves the generalization ability of the BCI decoder. Both the input and output of the spiking neural model are spike information, which is a brain-inspired intelligence approach that can be better integrated with BCI in the future.
Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots
Mar 15, 2022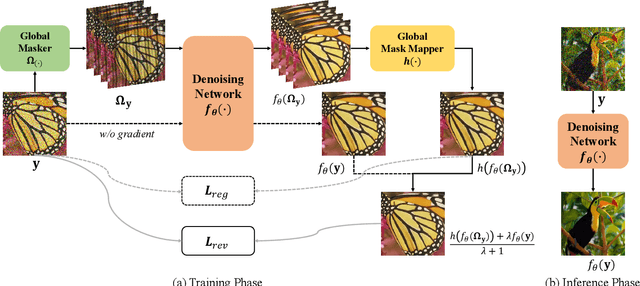
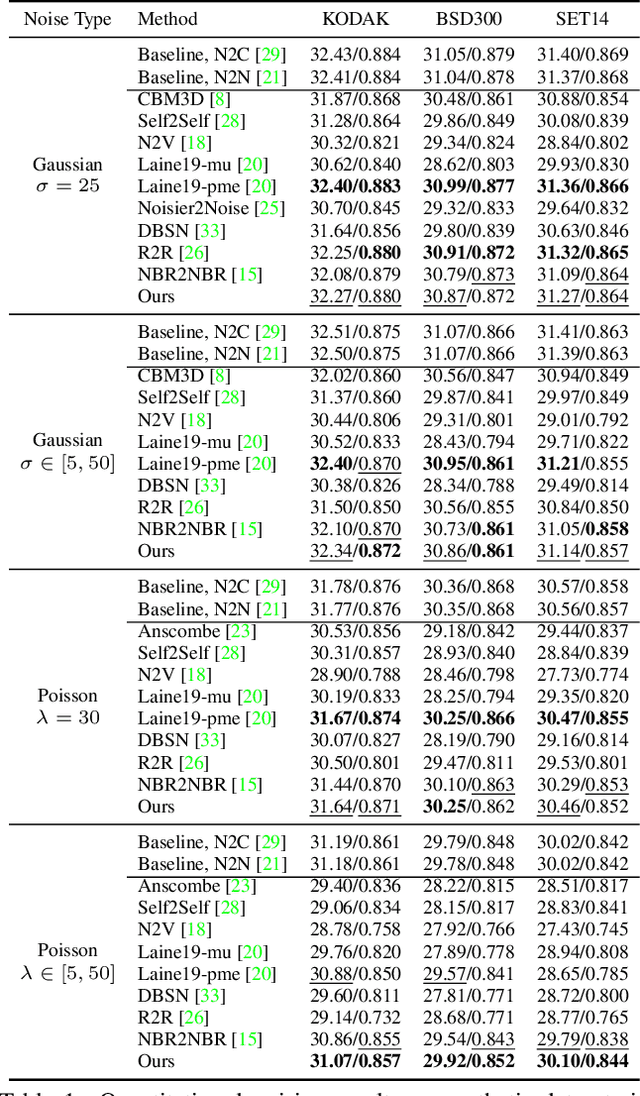
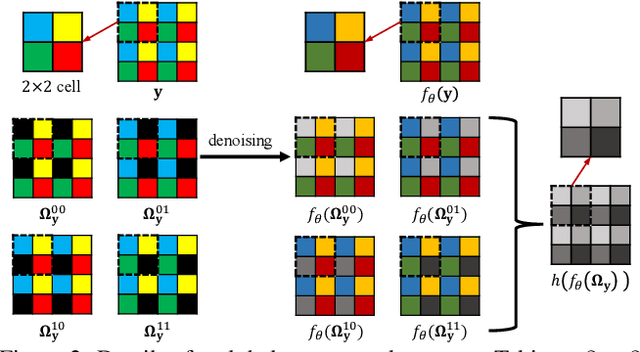
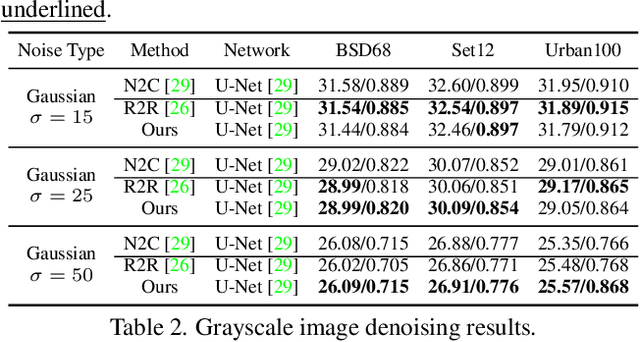
Real noisy-clean pairs on a large scale are costly and difficult to obtain. Meanwhile, supervised denoisers trained on synthetic data perform poorly in practice. Self-supervised denoisers, which learn only from single noisy images, solve the data collection problem. However, self-supervised denoising methods, especially blindspot-driven ones, suffer sizable information loss during input or network design. The absence of valuable information dramatically reduces the upper bound of denoising performance. In this paper, we propose a simple yet efficient approach called Blind2Unblind to overcome the information loss in blindspot-driven denoising methods. First, we introduce a global-aware mask mapper that enables global perception and accelerates training. The mask mapper samples all pixels at blind spots on denoised volumes and maps them to the same channel, allowing the loss function to optimize all blind spots at once. Second, we propose a re-visible loss to train the denoising network and make blind spots visible. The denoiser can learn directly from raw noise images without losing information or being trapped in identity mapping. We also theoretically analyze the convergence of the re-visible loss. Extensive experiments on synthetic and real-world datasets demonstrate the superior performance of our approach compared to previous work. Code is available at https://github.com/demonsjin/Blind2Unblind.
Learning Sequential Latent Variable Models from Multimodal Time Series Data
Apr 21, 2022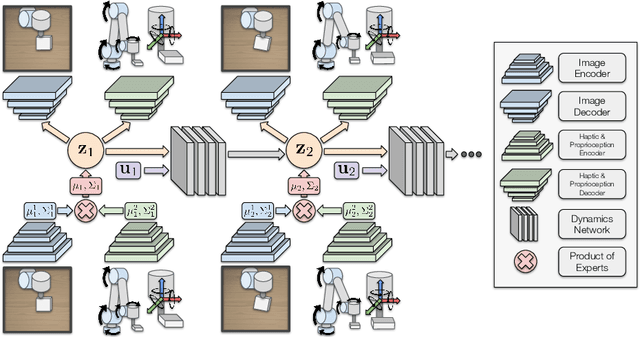

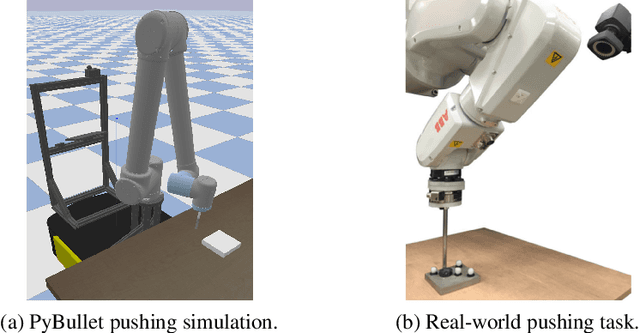

Sequential modelling of high-dimensional data is an important problem that appears in many domains including model-based reinforcement learning and dynamics identification for control. Latent variable models applied to sequential data (i.e., latent dynamics models) have been shown to be a particularly effective probabilistic approach to solve this problem, especially when dealing with images. However, in many application areas (e.g., robotics), information from multiple sensing modalities is available -- existing latent dynamics methods have not yet been extended to effectively make use of such multimodal sequential data. Multimodal sensor streams can be correlated in a useful manner and often contain complementary information across modalities. In this work, we present a self-supervised generative modelling framework to jointly learn a probabilistic latent state representation of multimodal data and the respective dynamics. Using synthetic and real-world datasets from a multimodal robotic planar pushing task, we demonstrate that our approach leads to significant improvements in prediction and representation quality. Furthermore, we compare to the common learning baseline of concatenating each modality in the latent space and show that our principled probabilistic formulation performs better. Finally, despite being fully self-supervised, we demonstrate that our method is nearly as effective as an existing supervised approach that relies on ground truth labels.
Multi-Agent Distributed Reinforcement Learning for Making Decentralized Offloading Decisions
Apr 05, 2022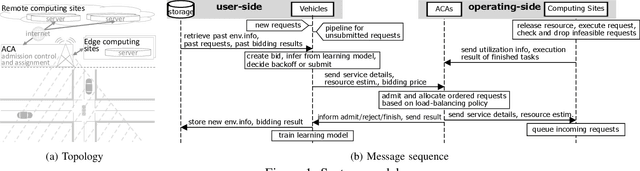
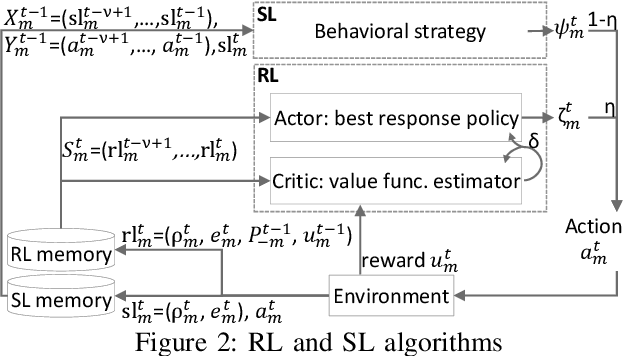
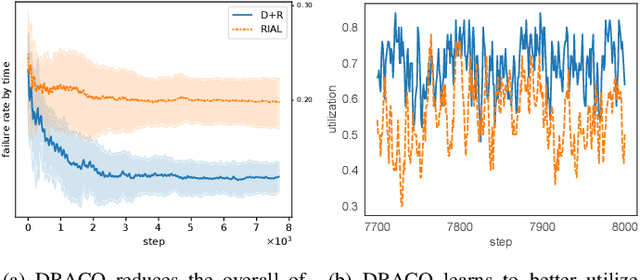

We formulate computation offloading as a decentralized decision-making problem with autonomous agents. We design an interaction mechanism that incentivizes agents to align private and system goals by balancing between competition and cooperation. The mechanism provably has Nash equilibria with optimal resource allocation in the static case. For a dynamic environment, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, and a reward signal that reduces information need to a great extent. Empirical results confirm that through learning, agents significantly improve both system and individual performance, e.g., 40% offloading failure rate reduction, 32% communication overhead reduction, up to 38% computation resource savings in low contention, 18% utilization increase with reduced load variation in high contention, and improvement in fairness. Results also confirm the algorithm's good convergence and generalization property in significantly different environments.
AFNet-M: Adaptive Fusion Network with Masks for 2D+3D Facial Expression Recognition
May 24, 2022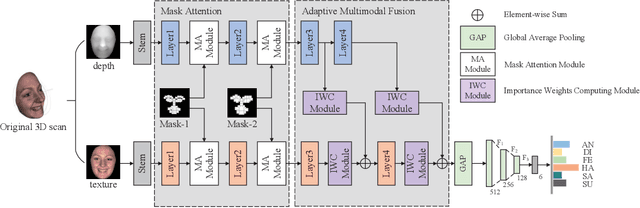
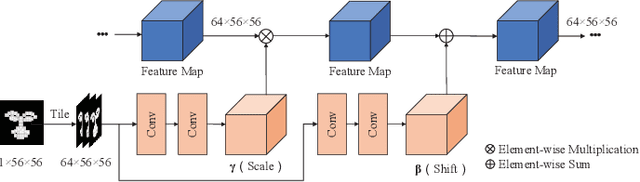
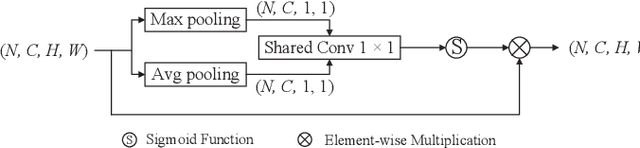
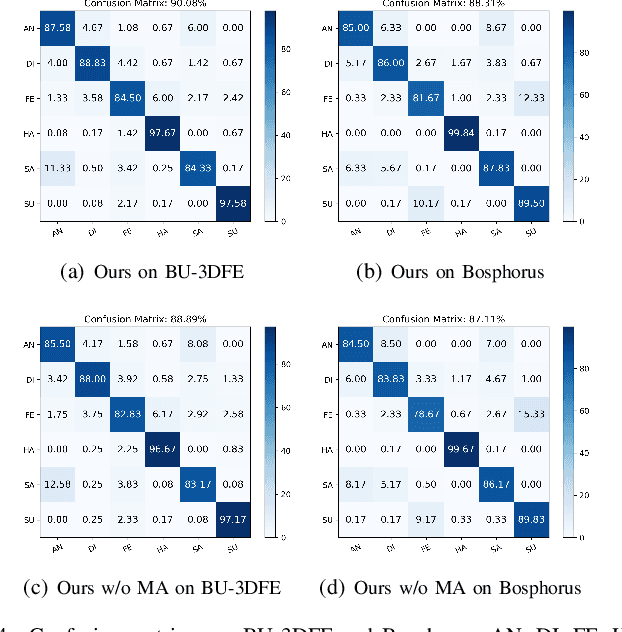
2D+3D facial expression recognition (FER) can effectively cope with illumination changes and pose variations by simultaneously merging 2D texture and more robust 3D depth information. Most deep learning-based approaches employ the simple fusion strategy that concatenates the multimodal features directly after fully-connected layers, without considering the different degrees of significance for each modality. Meanwhile, how to focus on both 2D and 3D local features in salient regions is still a great challenge. In this letter, we propose the adaptive fusion network with masks (AFNet-M) for 2D+3D FER. To enhance 2D and 3D local features, we take the masks annotating salient regions of the face as prior knowledge and design the mask attention module (MA) which can automatically learn two modulation vectors to adjust the feature maps. Moreover, we introduce a novel fusion strategy that can perform adaptive fusion at convolutional layers through the designed importance weights computing module (IWC). Experimental results demonstrate that our AFNet-M achieves the state-of-the-art performance on BU-3DFE and Bosphorus datasets and requires fewer parameters in comparison with other models.
Learning by non-interfering feedback chemical signaling in physical networks
Mar 22, 2022
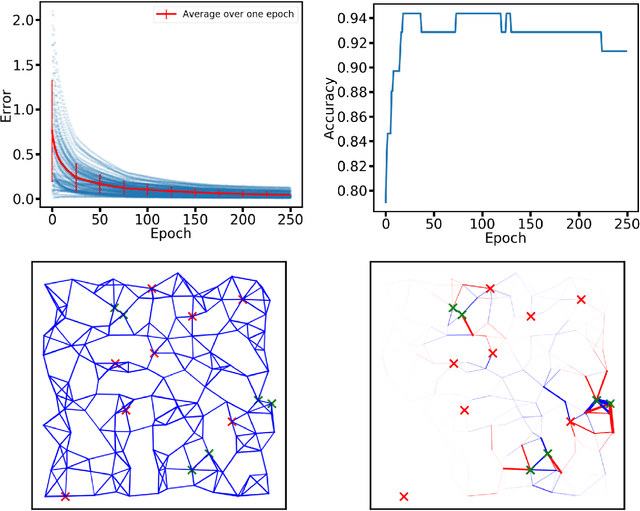
Both non-neural and neural biological systems can learn. So rather than focusing on purely brain-like learning, efforts are underway to study learning in physical systems. Such efforts include equilibrium propagation (EP) and coupled learning (CL), which require storage of two different states-the free state and the perturbed state-during the learning process to retain information about gradients. Inspired by slime mold, we propose a new learning algorithm rooted in chemical signaling that does not require storage of two different states. Rather, the output error information is encoded in a chemical signal that diffuses into the network in a similar way as the activation/feedforward signal. The steady state feedback chemical concentration, along with the activation signal, stores the required gradient information locally. We apply our algorithm using a physical, linear flow network and test it using the Iris data set with 93% accuracy. We also prove that our algorithm performs gradient descent. Finally, in addition to comparing our algorithm directly with EP and CL, we address the biological plausibility of the algorithm.
Optimising Equal Opportunity Fairness in Model Training
May 05, 2022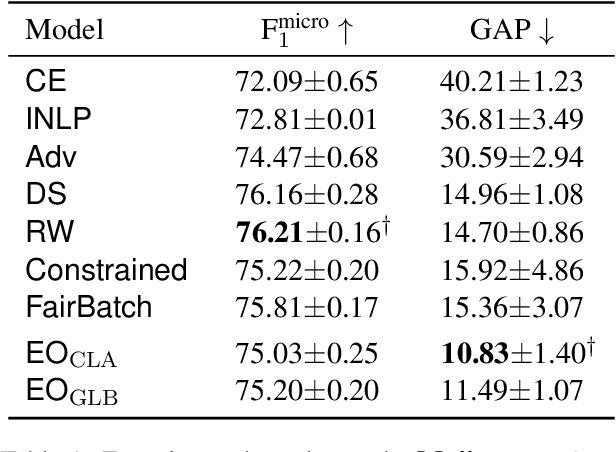
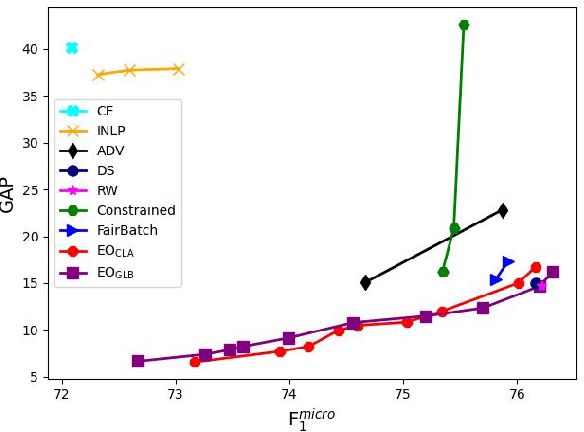
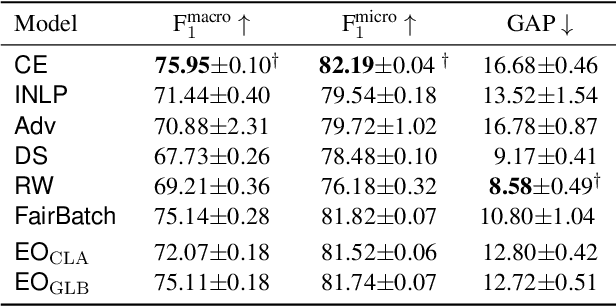
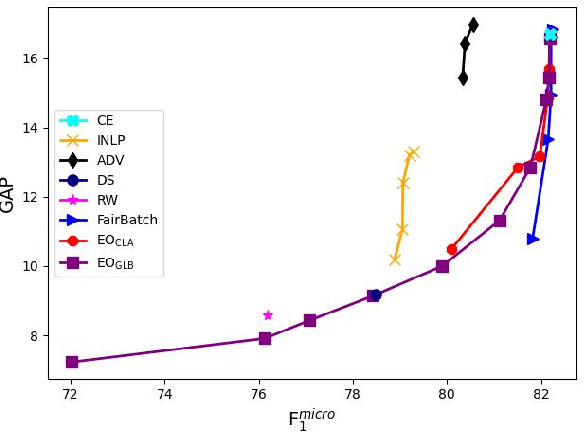
Real-world datasets often encode stereotypes and societal biases. Such biases can be implicitly captured by trained models, leading to biased predictions and exacerbating existing societal preconceptions. Existing debiasing methods, such as adversarial training and removing protected information from representations, have been shown to reduce bias. However, a disconnect between fairness criteria and training objectives makes it difficult to reason theoretically about the effectiveness of different techniques. In this work, we propose two novel training objectives which directly optimise for the widely-used criterion of {\it equal opportunity}, and show that they are effective in reducing bias while maintaining high performance over two classification tasks.