 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recurrence-in-Recurrence Networks for Video Deblurring
Mar 12, 2022

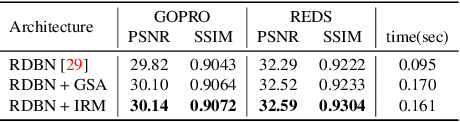
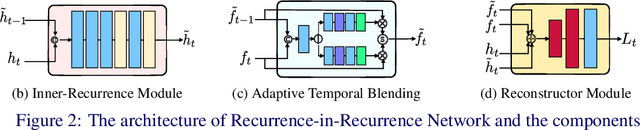
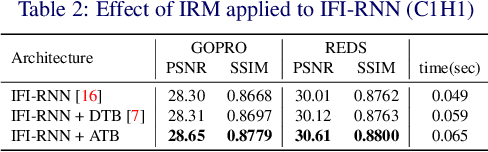
State-of-the-art video deblurring methods often adopt recurrent neural networks to model the temporal dependency between the frames. While the hidden states play key role in delivering information to the next frame, abrupt motion blur tend to weaken the relevance in the neighbor frames. In this paper, we propose recurrence-in-recurrence network architecture to cope with the limitations of short-ranged memory. We employ additional recurrent units inside the RNN cell. First, we employ inner-recurrence module (IRM) to manage the long-ranged dependency in a sequence. IRM learns to keep track of the cell memory and provides complementary information to find the deblurred frames. Second, we adopt an attention-based temporal blending strategy to extract the necessary part of the information in the local neighborhood. The adpative temporal blending (ATB) can either attenuate or amplify the features by the spatial attention. Our extensive experimental results and analysis validate the effectiveness of IRM and ATB on various RNN architectures.
* accepted paper in BMVC 2021
Information-Theoretic Segmentation by Inpainting Error Maximization
Dec 14, 2020
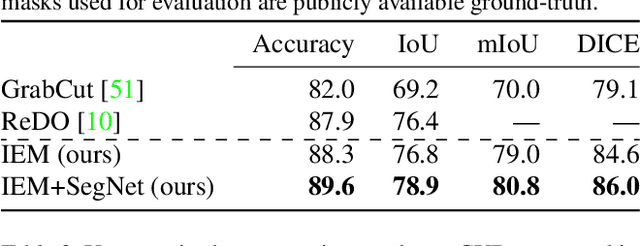
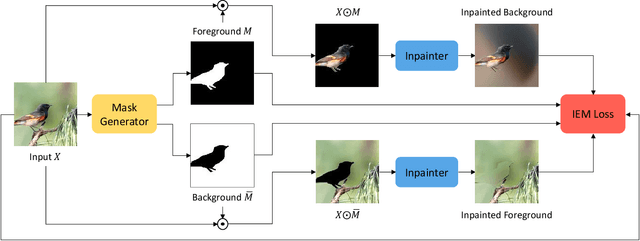
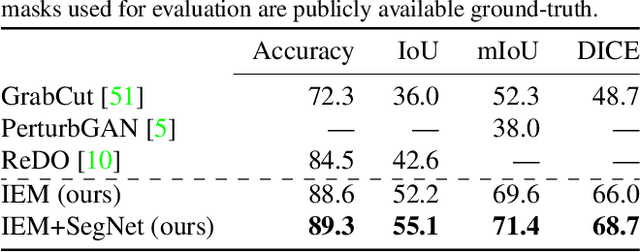
We study image segmentation from an information-theoretic perspective, proposing a novel adversarial method that performs unsupervised segmentation by partitioning images into maximally independent sets. More specifically, we group image pixels into foreground and background, with the goal of minimizing predictability of one set from the other. An easily computed loss drives a greedy search process to maximize inpainting error over these partitions. Our method does not involve training deep networks, is computationally cheap, class-agnostic, and even applicable in isolation to a single unlabeled image. Experiments demonstrate that it achieves a new state-of-the-art in unsupervised segmentation quality, while being substantially faster and more general than competing approaches.
Democracy Does Matter: Comprehensive Feature Mining for Co-Salient Object Detection
Mar 11, 2022
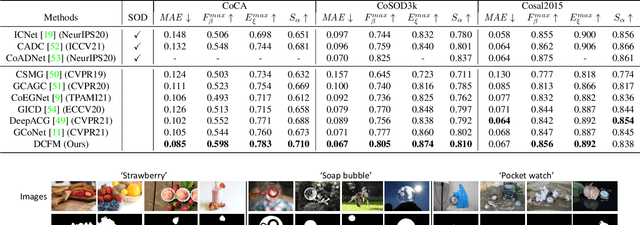
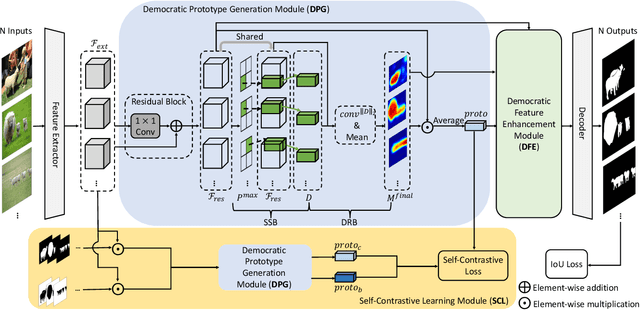
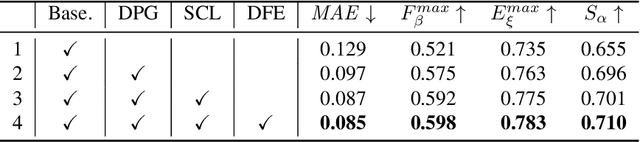
Co-salient object detection, with the target of detecting co-existed salient objects among a group of images, is gaining popularity. Recent works use the attention mechanism or extra information to aggregate common co-salient features, leading to incomplete even incorrect responses for target objects. In this paper, we aim to mine comprehensive co-salient features with democracy and reduce background interference without introducing any extra information. To achieve this, we design a democratic prototype generation module to generate democratic response maps, covering sufficient co-salient regions and thereby involving more shared attributes of co-salient objects. Then a comprehensive prototype based on the response maps can be generated as a guide for final prediction. To suppress the noisy background information in the prototype, we propose a self-contrastive learning module, where both positive and negative pairs are formed without relying on additional classification information. Besides, we also design a democratic feature enhancement module to further strengthen the co-salient features by readjusting attention values. Extensive experiments show that our model obtains better performance than previous state-of-the-art methods, especially on challenging real-world cases (e.g., for CoCA, we obtain a gain of 2.0% for MAE, 5.4% for maximum F-measure, 2.3% for maximum E-measure, and 3.7% for S-measure) under the same settings. Code will be released soon.
Multi-Sample $ζ$-mixup: Richer, More Realistic Synthetic Samples from a $p$-Series Interpolant
Apr 07, 2022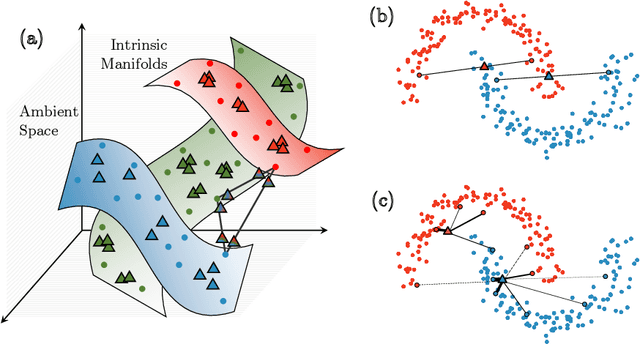
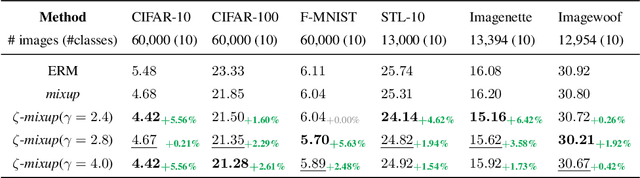
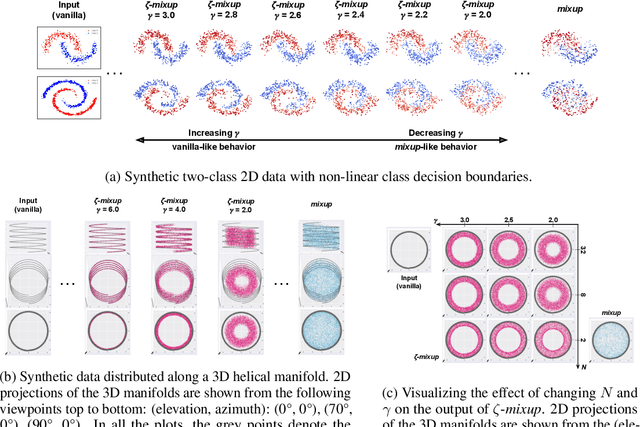
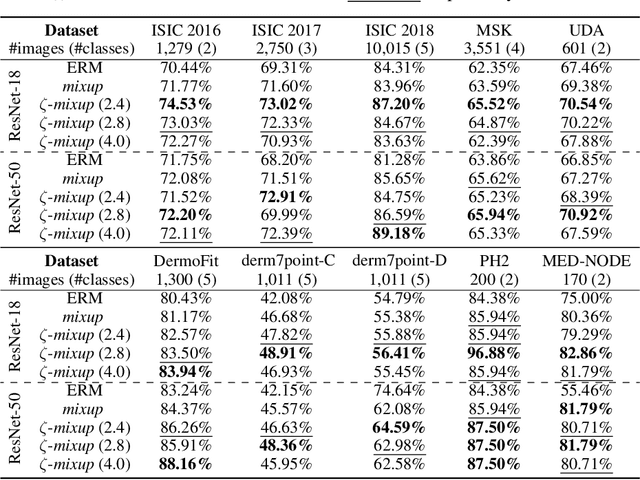
Modern deep learning training procedures rely on model regularization techniques such as data augmentation methods, which generate training samples that increase the diversity of data and richness of label information. A popular recent method, mixup, uses convex combinations of pairs of original samples to generate new samples. However, as we show in our experiments, mixup can produce undesirable synthetic samples, where the data is sampled off the manifold and can contain incorrect labels. We propose $\zeta$-mixup, a generalization of mixup with provably and demonstrably desirable properties that allows convex combinations of $N \geq 2$ samples, leading to more realistic and diverse outputs that incorporate information from $N$ original samples by using a $p$-series interpolant. We show that, compared to mixup, $\zeta$-mixup better preserves the intrinsic dimensionality of the original datasets, which is a desirable property for training generalizable models. Furthermore, we show that our implementation of $\zeta$-mixup is faster than mixup, and extensive evaluation on controlled synthetic and 24 real-world natural and medical image classification datasets shows that $\zeta$-mixup outperforms mixup and traditional data augmentation techniques.
Category-Aware Transformer Network for Better Human-Object Interaction Detection
Apr 11, 2022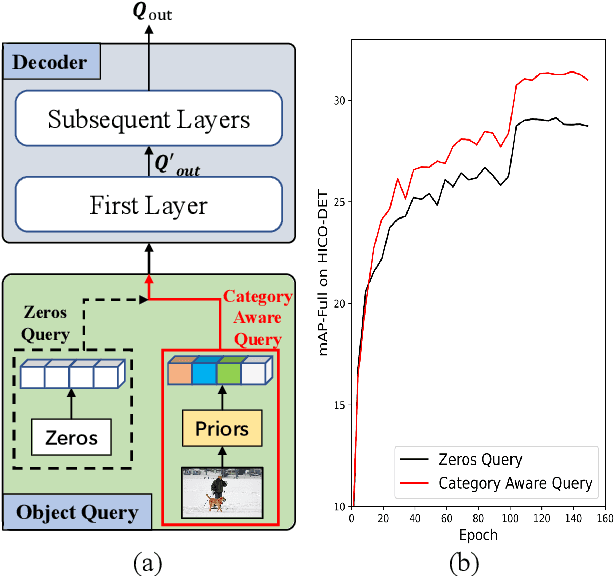
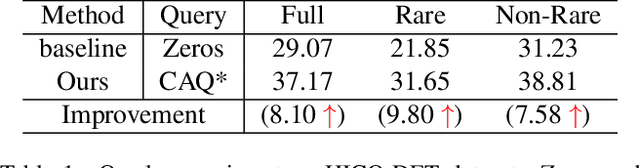
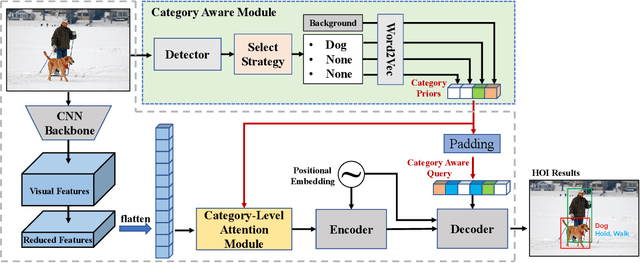
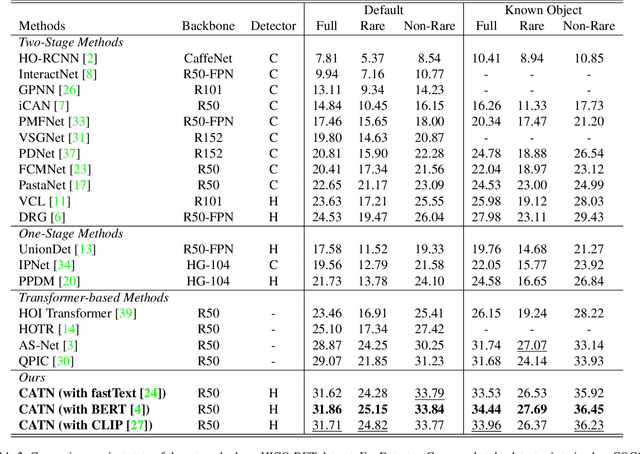
Human-Object Interactions (HOI) detection, which aims to localize a human and a relevant object while recognizing their interaction, is crucial for understanding a still image. Recently, transformer-based models have significantly advanced the progress of HOI detection. However, the capability of these models has not been fully explored since the Object Query of the model is always simply initialized as just zeros, which would affect the performance. In this paper, we try to study the issue of promoting transformer-based HOI detectors by initializing the Object Query with category-aware semantic information. To this end, we innovatively propose the Category-Aware Transformer Network (CATN). Specifically, the Object Query would be initialized via category priors represented by an external object detection model to yield better performance. Moreover, such category priors can be further used for enhancing the representation ability of features via the attention mechanism. We have firstly verified our idea via the Oracle experiment by initializing the Object Query with the groundtruth category information. And then extensive experiments have been conducted to show that a HOI detection model equipped with our idea outperforms the baseline by a large margin to achieve a new state-of-the-art result.
On statistic alignment for domain adaptation in structural health monitoring
May 24, 2022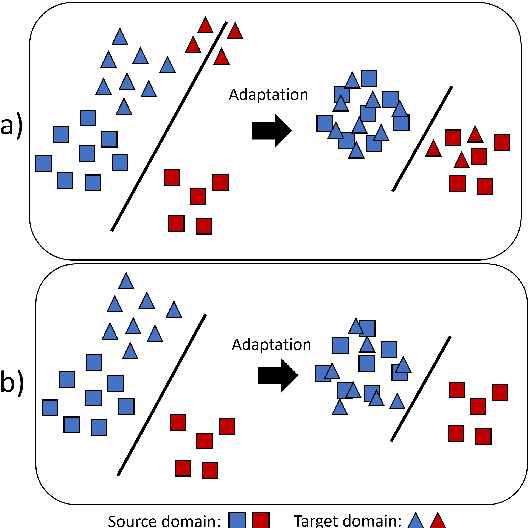
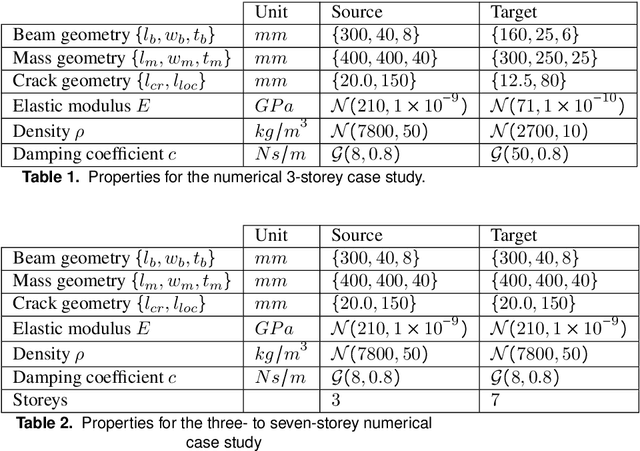
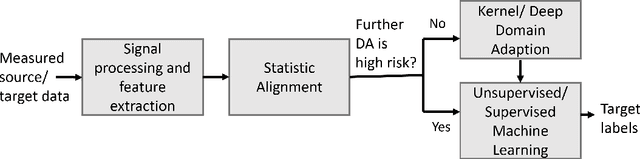
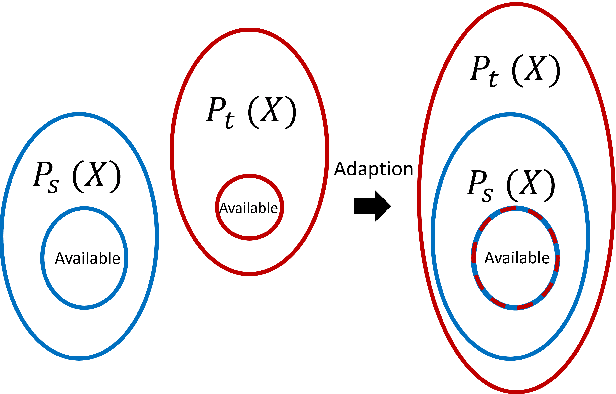
The practical application of structural health monitoring (SHM) is often limited by the availability of labelled data. Transfer learning - specifically in the form of domain adaptation (DA) - gives rise to the possibility of leveraging information from a population of physical or numerical structures, by inferring a mapping that aligns the feature spaces. Typical DA methods rely on nonparametric distance metrics, which require sufficient data to perform density estimation. In addition, these methods can be prone to performance degradation under class imbalance. To address these issues, statistic alignment (SA) is discussed, with a demonstration of how these methods can be made robust to class imbalance, including a special case of class imbalance called a partial DA scenario. SA is demonstrated to facilitate damage localisation with no target labels in a numerical case study, outperforming other state-of-the-art DA methods. It is then shown to be capable of aligning the feature spaces of a real heterogeneous population, the Z24 and KW51 bridges, with only 220 samples used from the KW51 bridge. Finally, in scenarios where more complex mappings are required for knowledge transfer, SA is shown to be a vital pre-processing tool, increasing the performance of established DA methods.
Effect of Gender, Pose and Camera Distance on Human Body Dimensions Estimation
May 24, 2022
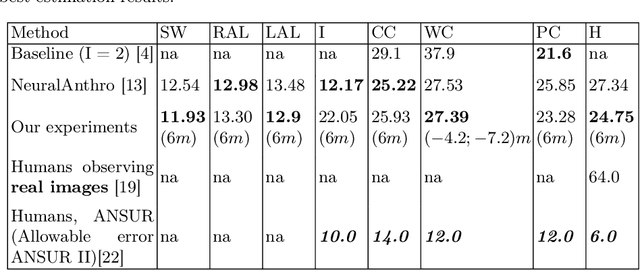
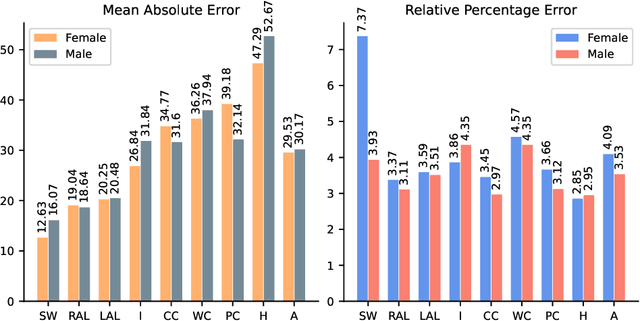
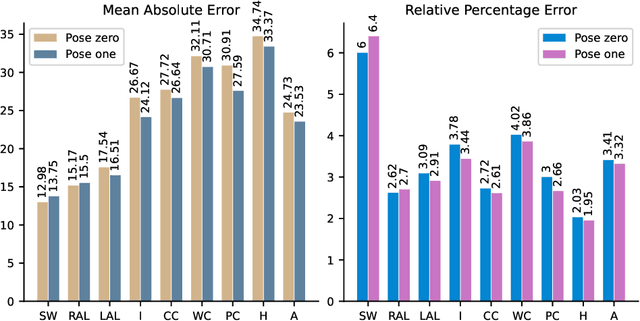
Human Body Dimensions Estimation (HBDE) is a task that an intelligent agent can perform to attempt to determine human body information from images (2D) or point clouds or meshes (3D). More specifically, if we define the HBDE problem as inferring human body measurements from images, then HBDE is a difficult, inverse, multi-task regression problem that can be tackled with machine learning techniques, particularly convolutional neural networks (CNN). Despite the community's tremendous effort to advance human shape analysis, there is a lack of systematic experiments to assess CNNs estimation of human body dimensions from images. Our contribution lies in assessing a CNN estimation performance in a series of controlled experiments. To that end, we augment our recently published neural anthropometer dataset by rendering images with different camera distance. We evaluate the network inference absolute and relative mean error between the estimated and actual HBDs. We train and evaluate the CNN in four scenarios: (1) training with subjects of a specific gender, (2) in a specific pose, (3) sparse camera distance and (4) dense camera distance. Not only our experiments demonstrate that the network can perform the task successfully, but also reveal a number of relevant facts that contribute to better understand the task of HBDE.
Transformer Language Models with LSTM-based Cross-utterance Information Representation
Feb 12, 2021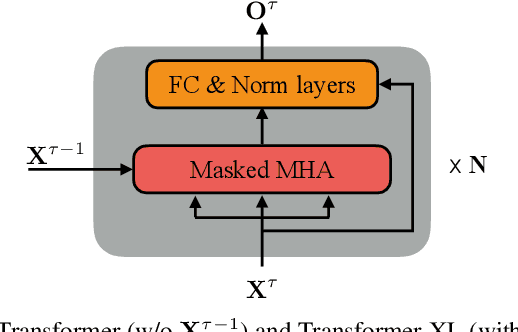
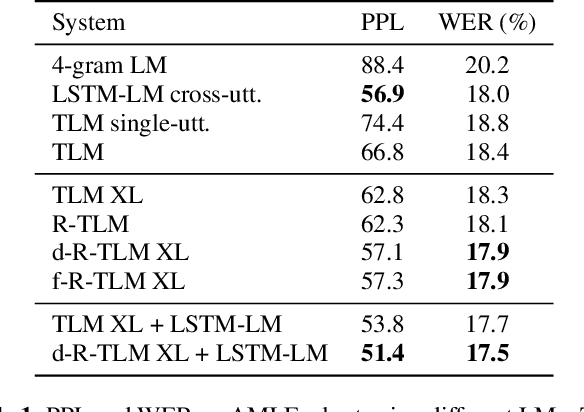
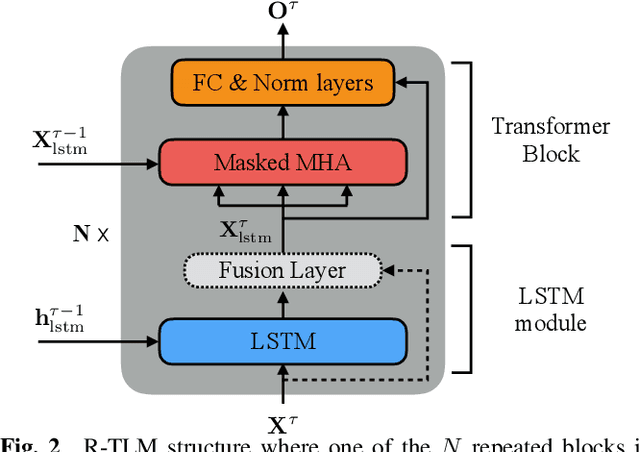
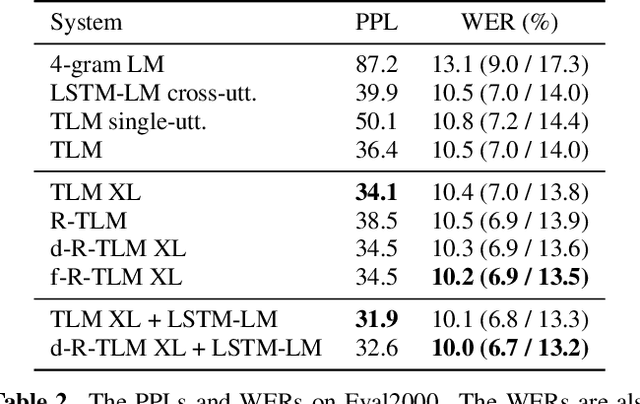
The effective incorporation of cross-utterance information has the potential to improve language models (LMs) for automatic speech recognition (ASR). To extract more powerful and robust cross-utterance representations for the Transformer LM (TLM), this paper proposes the R-TLM which uses hidden states in a long short-term memory (LSTM) LM. To encode the cross-utterance information, the R-TLM incorporates an LSTM module together with a segment-wise recurrence in some of the Transformer blocks. In addition to the LSTM module output, a shortcut connection using a fusion layer that bypasses the LSTM module is also investigated. The proposed system was evaluated on the AMI meeting corpus, the Eval2000 and the RT03 telephone conversation evaluation sets. The best R-TLM achieved 0.9%, 0.6%, and 0.8% absolute WER reductions over the single-utterance TLM baseline, and 0.5%, 0.3%, 0.2% absolute WER reductions over a strong cross-utterance TLM baseline on the AMI evaluation set, Eval2000 and RT03 respectively. Improvements on Eval2000 and RT03 were further supported by significance tests. R-TLMs were found to have better LM scores on words where recognition errors are more likely to occur. The R-TLM WER can be further reduced by interpolation with an LSTM-LM.
A Linear Comb Filter for Event Flicker Removal
May 17, 2022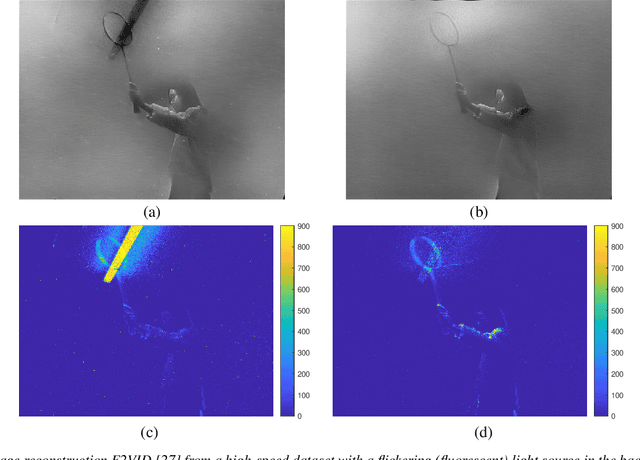
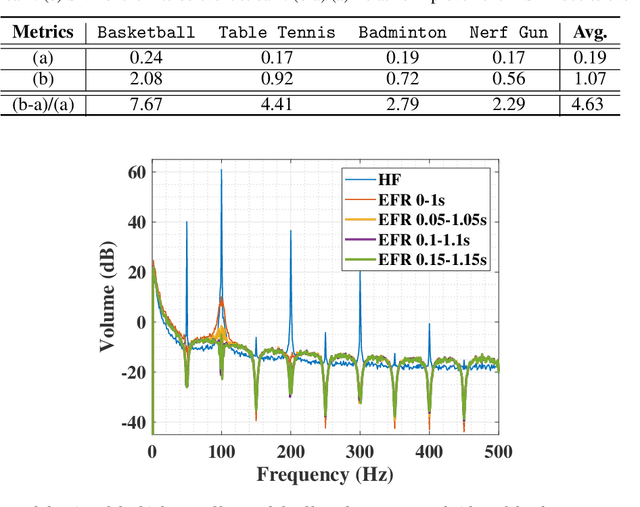
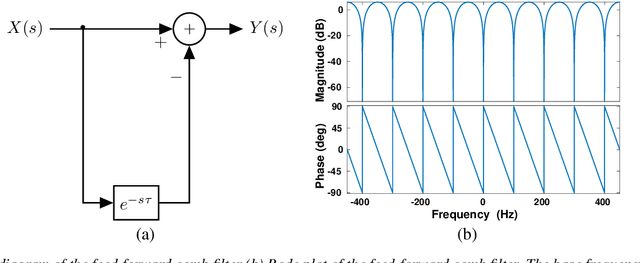
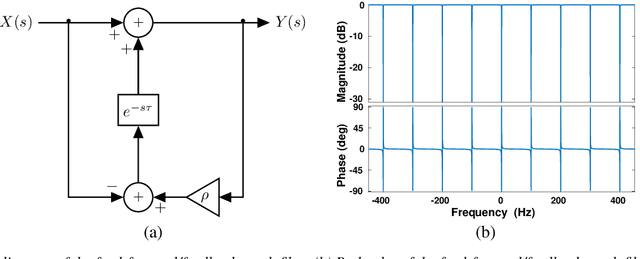
Event cameras are bio-inspired sensors that capture per-pixel asynchronous intensity change rather than the synchronous absolute intensity frames captured by a classical camera sensor. Such cameras are ideal for robotics applications since they have high temporal resolution, high dynamic range and low latency. However, due to their high temporal resolution, event cameras are particularly sensitive to flicker such as from fluorescent or LED lights. During every cycle from bright to dark, pixels that image a flickering light source generate many events that provide little or no useful information for a robot, swamping the useful data in the scene. In this paper, we propose a novel linear filter to preprocess event data to remove unwanted flicker events from an event stream. The proposed algorithm achieves over 4.6 times relative improvement in the signal-to-noise ratio when compared to the raw event stream due to the effective removal of flicker from fluorescent lighting. Thus, it is ideally suited to robotics applications that operate in indoor settings or scenes illuminated by flickering light sources.
Residual Q-Networks for Value Function Factorizing in Multi-Agent Reinforcement Learning
May 30, 2022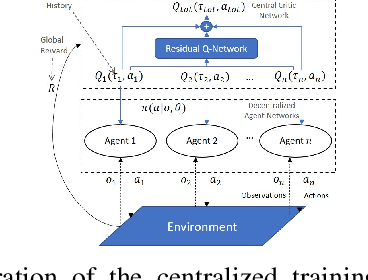
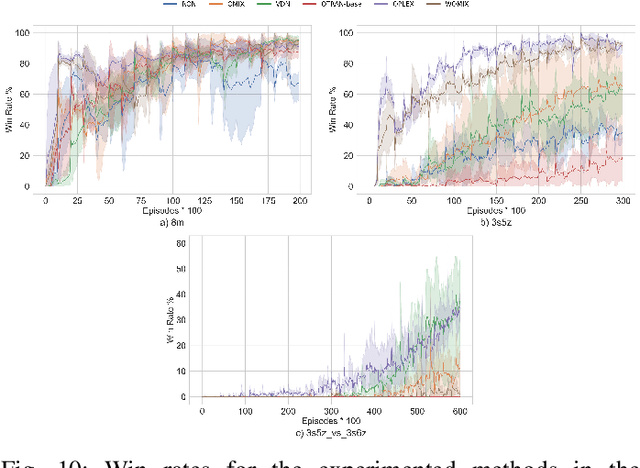
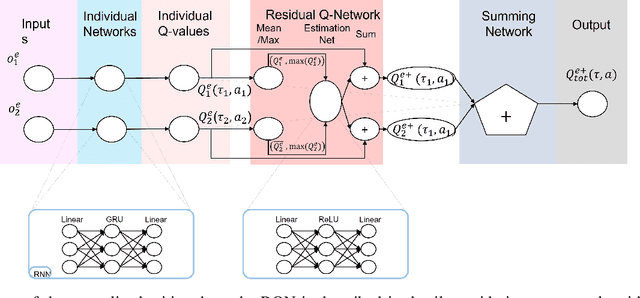
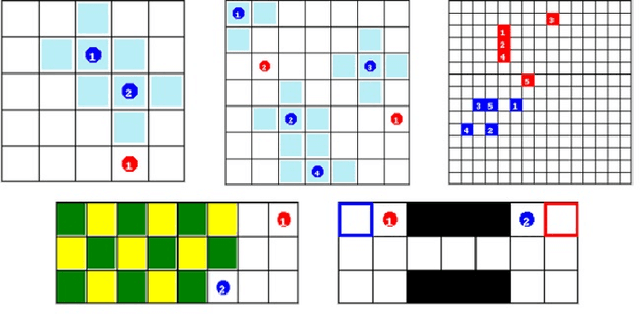
Multi-Agent Reinforcement Learning (MARL) is useful in many problems that require the cooperation and coordination of multiple agents. Learning optimal policies using reinforcement learning in a multi-agent setting can be very difficult as the number of agents increases. Recent solutions such as Value Decomposition Networks (VDN), QMIX, QTRAN and QPLEX adhere to the centralized training and decentralized execution scheme and perform factorization of the joint action-value functions. However, these methods still suffer from increased environmental complexity, and at times fail to converge in a stable manner. We propose a novel concept of Residual Q-Networks (RQNs) for MARL, which learns to transform the individual Q-value trajectories in a way that preserves the Individual-Global-Max criteria (IGM), but is more robust in factorizing action-value functions. The RQN acts as an auxiliary network that accelerates convergence and will become obsolete as the agents reach the training objectives. The performance of the proposed method is compared against several state-of-the-art techniques such as QPLEX, QMIX, QTRAN and VDN, in a range of multi-agent cooperative tasks. The results illustrate that the proposed method, in general, converges faster, with increased stability and shows robust performance in a wider family of environments. The improvements in results are more prominent in environments with severe punishments for non-cooperative behaviours and especially in the absence of complete state information during training time.