 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalizing Brain Decoding Across Subjects with Deep Learning
May 27, 2022
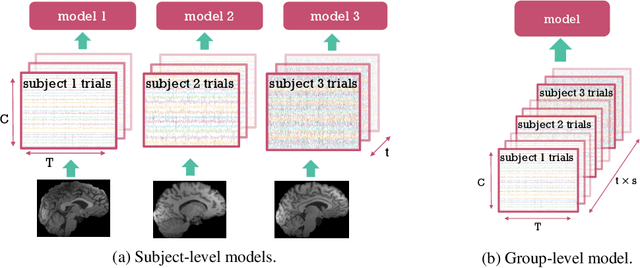
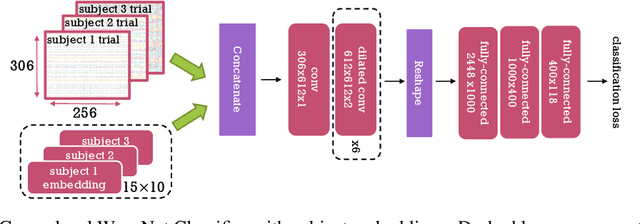
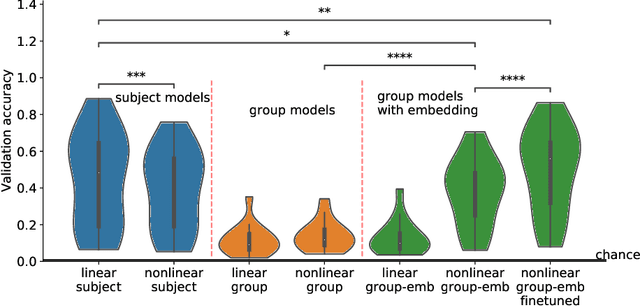
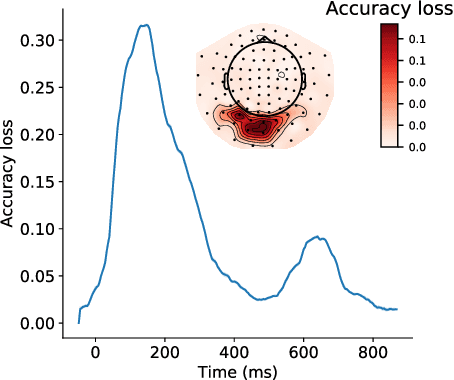
Decoding experimental variables from brain imaging data is gaining popularity, with applications in brain-computer interfaces and the study of neural representations. Decoding is typically subject-specific and does not generalise well over subjects. Here, we investigate ways to achieve cross-subject decoding. We used magnetoencephalography (MEG) data where 15 subjects viewed 118 different images, with 30 examples per image. Training on the entire 1s window following the presentation of each image, we experimented with an adaptation of the WaveNet architecture for classification. We also investigated the use of subject embedding to aid learning of subject variability in the group model. We show that deep learning and subject embedding are crucial to closing the performance gap between subject and group-level models. Importantly group models outperform subject models when tested on an unseen subject with little available data. The potential of such group modelling is even higher with bigger datasets. Furthermore, we demonstrate the use of permutation feature importance to gain insight into the spatio-temporal and spectral information encoded in the models, enabling better physiological interpretation. All experimental code is available at https://github.com/ricsinaruto/MEG-group-decode.
Deep Unsupervised Image Anomaly Detection: An Information Theoretic Framework
Dec 09, 2020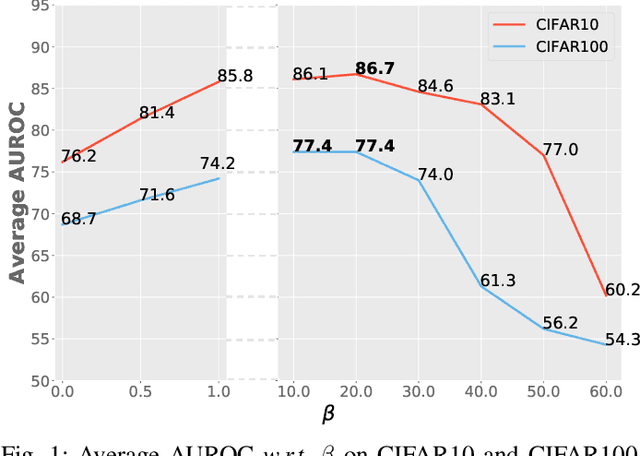
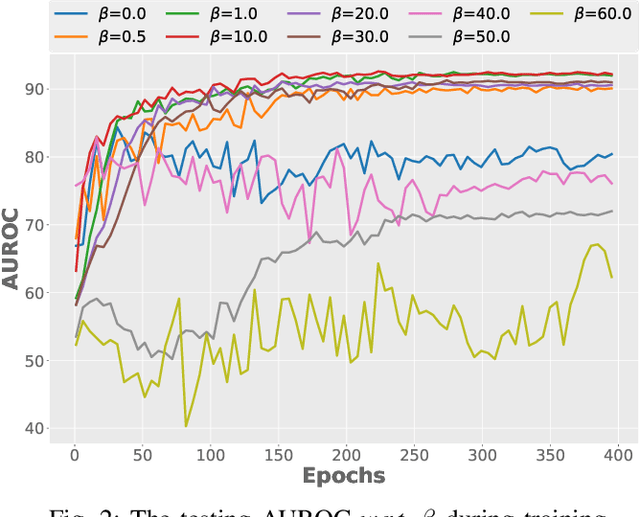
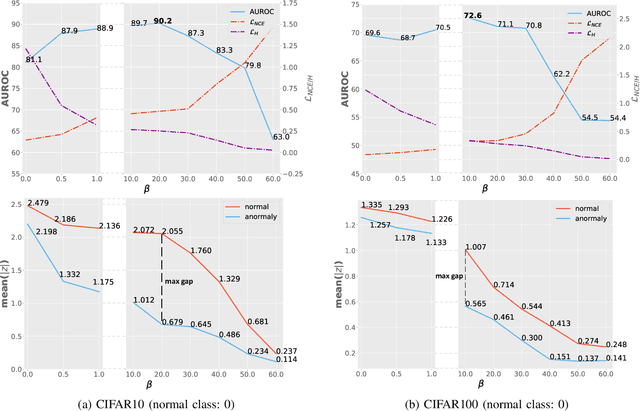
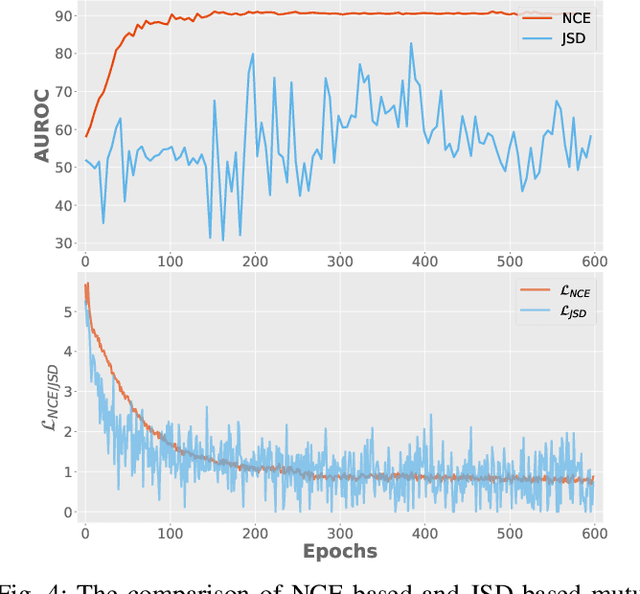
Surrogate task based methods have recently shown great promise for unsupervised image anomaly detection. However, there is no guarantee that the surrogate tasks share the consistent optimization direction with anomaly detection. In this paper, we return to a direct objective function for anomaly detection with information theory, which maximizes the distance between normal and anomalous data in terms of the joint distribution of images and their representation. Unfortunately, this objective function is not directly optimizable under the unsupervised setting where no anomalous data is provided during training. Through mathematical analysis of the above objective function, we manage to decompose it into four components. In order to optimize in an unsupervised fashion, we show that, under the assumption that distribution of the normal and anomalous data are separable in the latent space, its lower bound can be considered as a function which weights the trade-off between mutual information and entropy. This objective function is able to explain why the surrogate task based methods are effective for anomaly detection and further point out the potential direction of improvement. Based on this object function we introduce a novel information theoretic framework for unsupervised image anomaly detection. Extensive experiments have demonstrated that the proposed framework significantly outperforms several state-of-the-arts on multiple benchmark data sets.
A Computational Inflection for Scientific Discovery
May 04, 2022
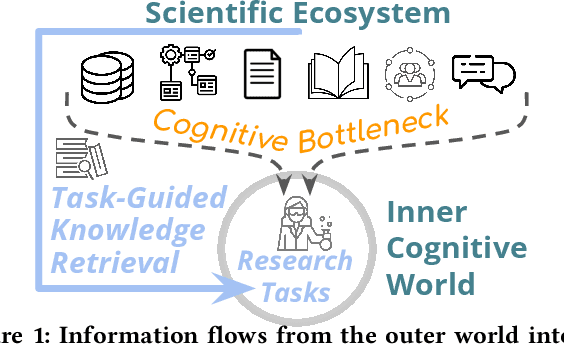
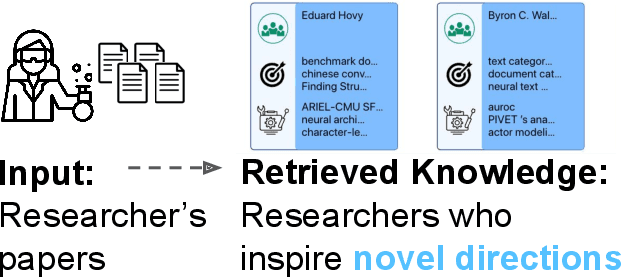
We stand at the foot of a significant inflection in the trajectory of scientific discovery. As society continues on its fast-paced digital transformation, so does humankind's collective scientific knowledge and discourse. We now read and write papers in digitized form, and a great deal of the formal and informal processes of science are captured digitally -- including papers, preprints and books, code and datasets, conference presentations, and interactions in social networks and communication platforms. The transition has led to the growth of a tremendous amount of information, opening exciting opportunities for computational models and systems that analyze and harness it. In parallel, exponential growth in data processing power has fueled remarkable advances in AI, including self-supervised neural models capable of learning powerful representations from large-scale unstructured text without costly human supervision. The confluence of societal and computational trends suggests that computer science is poised to ignite a revolution in the scientific process itself. However, the explosion of scientific data, results and publications stands in stark contrast to the constancy of human cognitive capacity. While scientific knowledge is expanding with rapidity, our minds have remained static, with severe limitations on the capacity for finding, assimilating and manipulating information. We propose a research agenda of task-guided knowledge retrieval, in which systems counter humans' bounded capacity by ingesting corpora of scientific knowledge and retrieving inspirations, explanations, solutions and evidence synthesized to directly augment human performance on salient tasks in scientific endeavors. We present initial progress on methods and prototypes, and lay out important opportunities and challenges ahead with computational approaches that have the potential to revolutionize science.
Self-Supervised Graph Neural Network for Multi-Source Domain Adaptation
Apr 08, 2022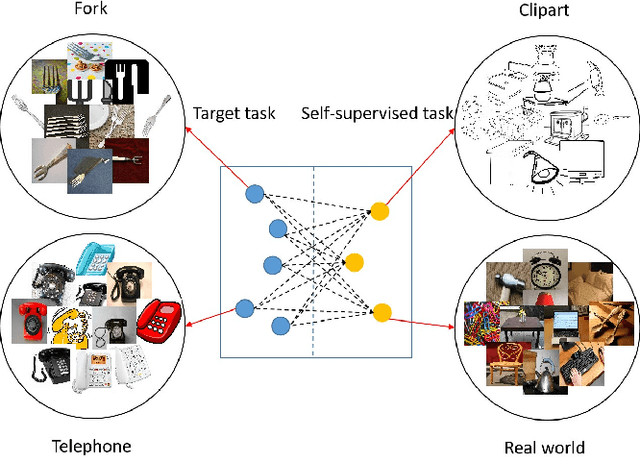
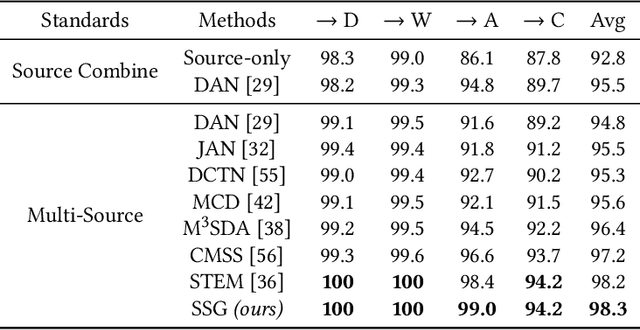
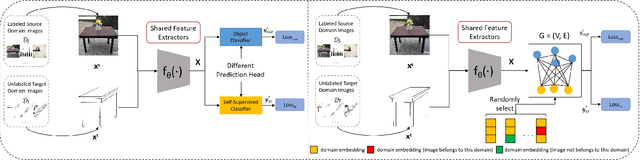
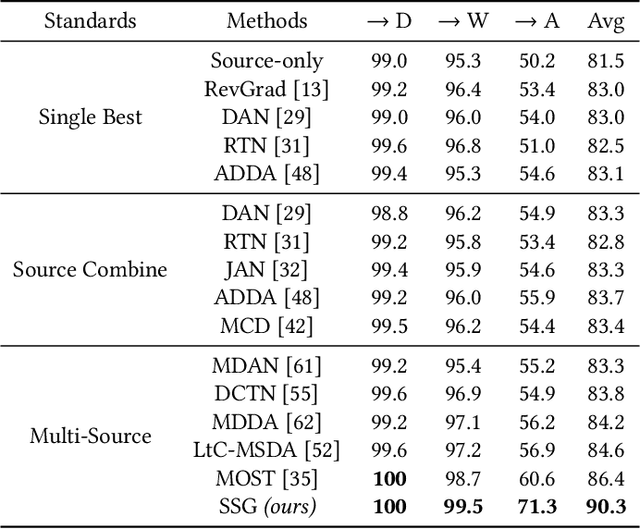
Domain adaptation (DA) tries to tackle the scenarios when the test data does not fully follow the same distribution of the training data, and multi-source domain adaptation (MSDA) is very attractive for real world applications. By learning from large-scale unlabeled samples, self-supervised learning has now become a new trend in deep learning. It is worth noting that both self-supervised learning and multi-source domain adaptation share a similar goal: they both aim to leverage unlabeled data to learn more expressive representations. Unfortunately, traditional multi-task self-supervised learning faces two challenges: (1) the pretext task may not strongly relate to the downstream task, thus it could be difficult to learn useful knowledge being shared from the pretext task to the target task; (2) when the same feature extractor is shared between the pretext task and the downstream one and only different prediction heads are used, it is ineffective to enable inter-task information exchange and knowledge sharing. To address these issues, we propose a novel \textbf{S}elf-\textbf{S}upervised \textbf{G}raph Neural Network (SSG), where a graph neural network is used as the bridge to enable more effective inter-task information exchange and knowledge sharing. More expressive representation is learned by adopting a mask token strategy to mask some domain information. Our extensive experiments have demonstrated that our proposed SSG method has achieved state-of-the-art results over four multi-source domain adaptation datasets, which have shown the effectiveness of our proposed SSG method from different aspects.
Distributed Multi-Agent Deep Reinforcement Learning for Robust Coordination against Noise
May 19, 2022
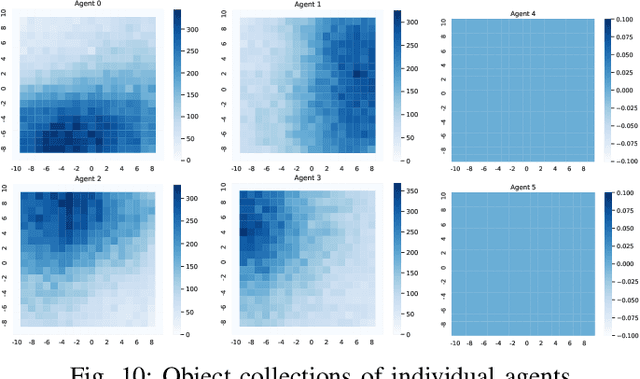
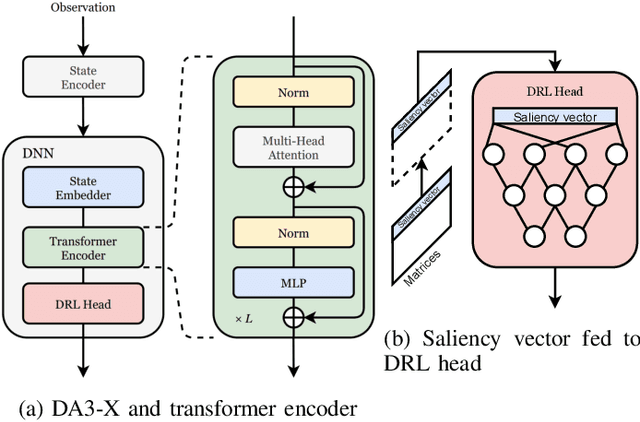
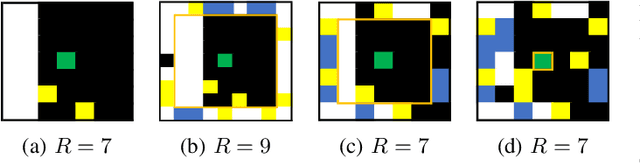
In multi-agent systems, noise reduction techniques are important for improving the overall system reliability as agents are required to rely on limited environmental information to develop cooperative and coordinated behaviors with the surrounding agents. However, previous studies have often applied centralized noise reduction methods to build robust and versatile coordination in noisy multi-agent environments, while distributed and decentralized autonomous agents are more plausible for real-world application. In this paper, we introduce a \emph{distributed attentional actor architecture model for a multi-agent system} (DA3-X), using which we demonstrate that agents with DA3-X can selectively learn the noisy environment and behave cooperatively. We experimentally evaluate the effectiveness of DA3-X by comparing learning methods with and without DA3-X and show that agents with DA3-X can achieve better performance than baseline agents. Furthermore, we visualize heatmaps of \emph{attentional weights} from the DA3-X to analyze how the decision-making process and coordinated behavior are influenced by noise.
ActiveMLP: An MLP-like Architecture with Active Token Mixer
Mar 11, 2022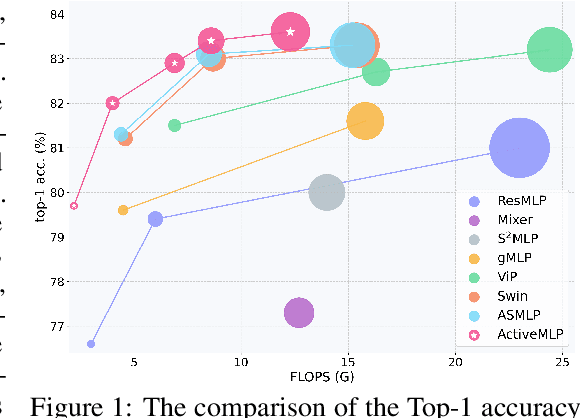

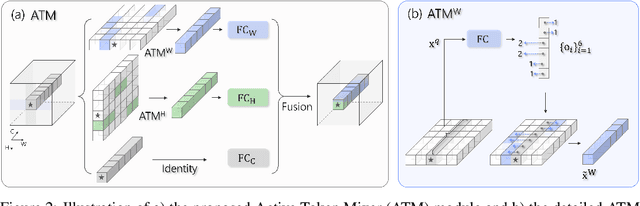
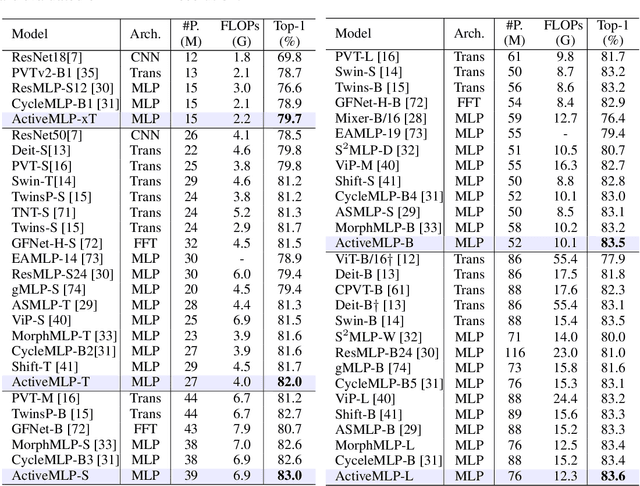
This paper presents ActiveMLP, a general MLP-like backbone for computer vision. The three existing dominant network families, i.e., CNNs, Transformers and MLPs, differ from each other mainly in the ways to fuse contextual information into a given token, leaving the design of more effective token-mixing mechanisms at the core of backbone architecture development. In ActiveMLP, we propose an innovative token-mixer, dubbed Active Token Mixer (ATM), to actively incorporate contextual information from other tokens in the global scope into the given one. This fundamental operator actively predicts where to capture useful contexts and learns how to fuse the captured contexts with the original information of the given token at channel levels. In this way, the spatial range of token-mixing is expanded and the way of token-mixing is reformed. With this design, ActiveMLP is endowed with the merits of global receptive fields and more flexible content-adaptive information fusion. Extensive experiments demonstrate that ActiveMLP is generally applicable and comprehensively surpasses different families of SOTA vision backbones by a clear margin on a broad range of vision tasks, including visual recognition and dense prediction tasks. The code and models will be available at https://github.com/microsoft/ActiveMLP.
Who Is Missing? Characterizing the Participation of Different Demographic Groups in a Korean Nationwide Daily Conversation Corpus
Apr 20, 2022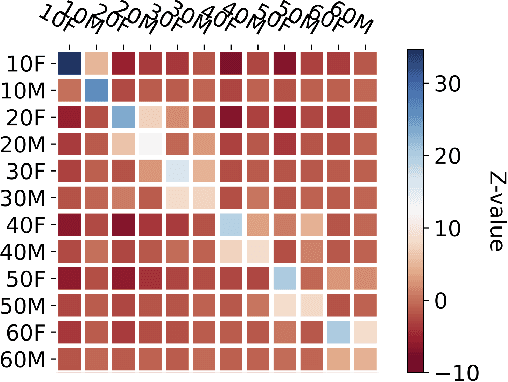
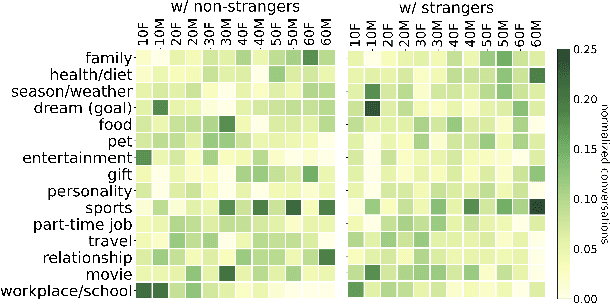
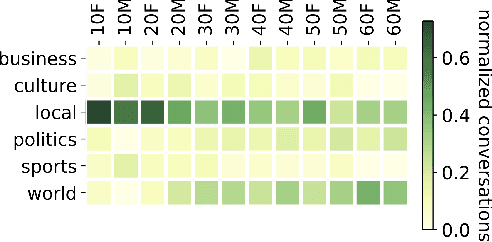
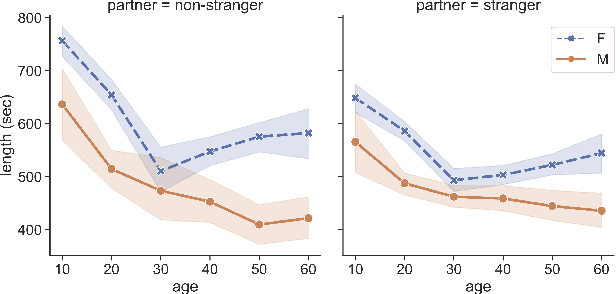
A conversation corpus is essential to build interactive AI applications. However, the demographic information of the participants in such corpora is largely underexplored mainly due to the lack of individual data in many corpora. In this work, we analyze a Korean nationwide daily conversation corpus constructed by the National Institute of Korean Language (NIKL) to characterize the participation of different demographic (age and sex) groups in the corpus.
Improving Sequential Query Recommendation with Immediate User Feedback
May 12, 2022
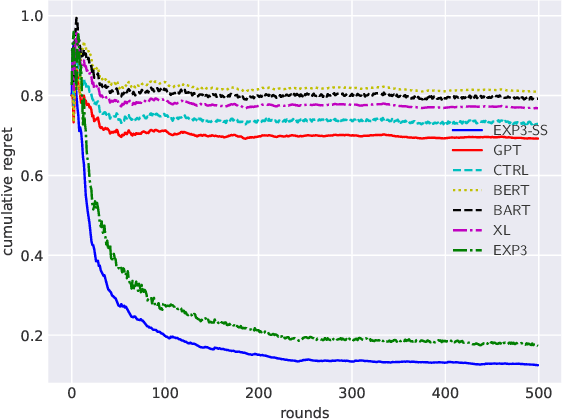
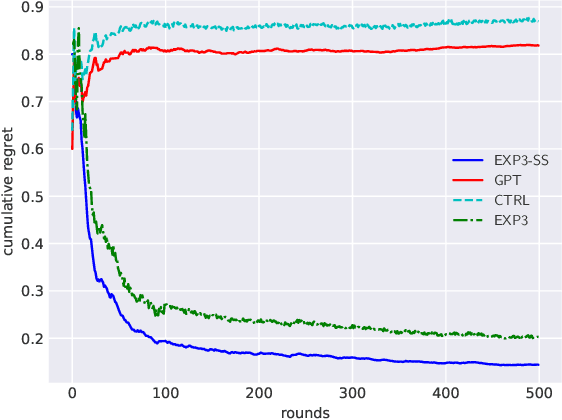
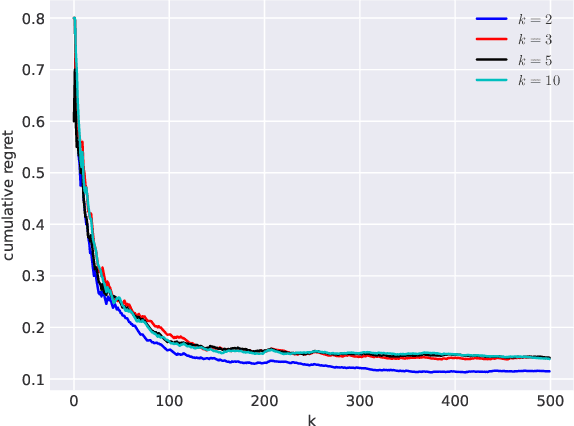
We propose an algorithm for next query recommendation in interactive data exploration settings, like knowledge discovery for information gathering. The state-of-the-art query recommendation algorithms are based on sequence-to-sequence learning approaches that exploit historical interaction data. We propose to augment the transformer-based causal language models for query recommendations to adapt to the immediate user feedback using multi-armed bandit (MAB) framework. We conduct a large-scale experimental study using log files from a popular online literature discovery service and demonstrate that our algorithm improves the cumulative regret substantially, with respect to the state-of-the-art transformer-based query recommendation models, which do not make use of the immediate user feedback. Our data model and source code are available at ~\url{https://anonymous.4open.science/r/exp3_ss-9985/}.
A framework for robotic arm pose estimation and movement prediction based on deep and extreme learning models
May 27, 2022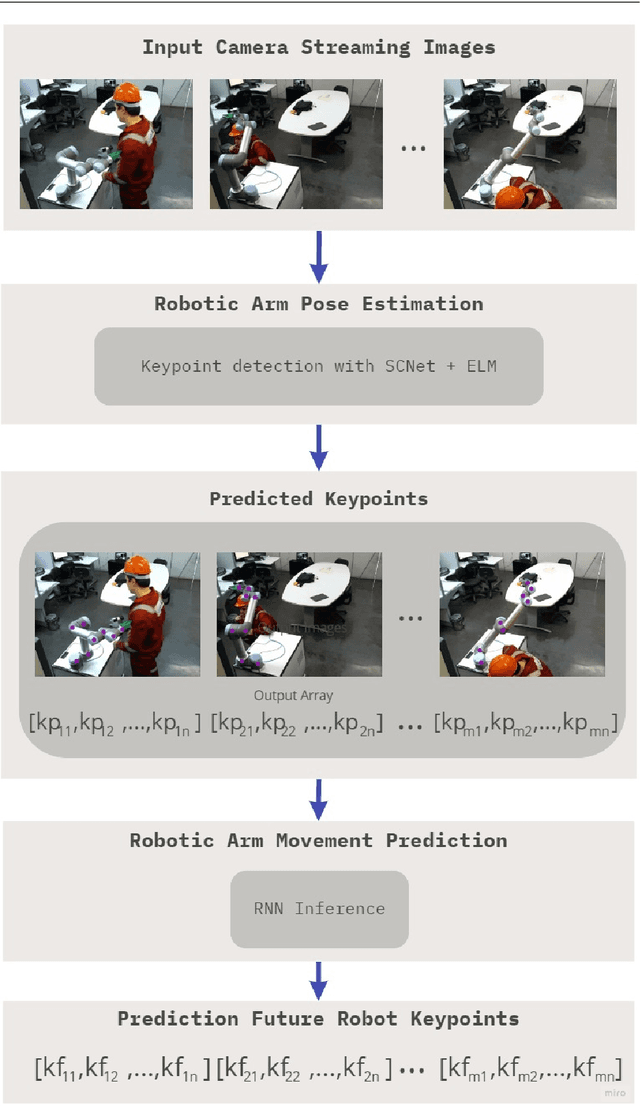
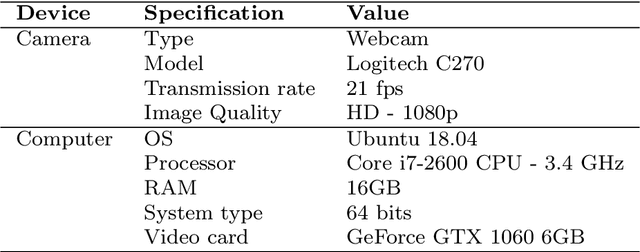
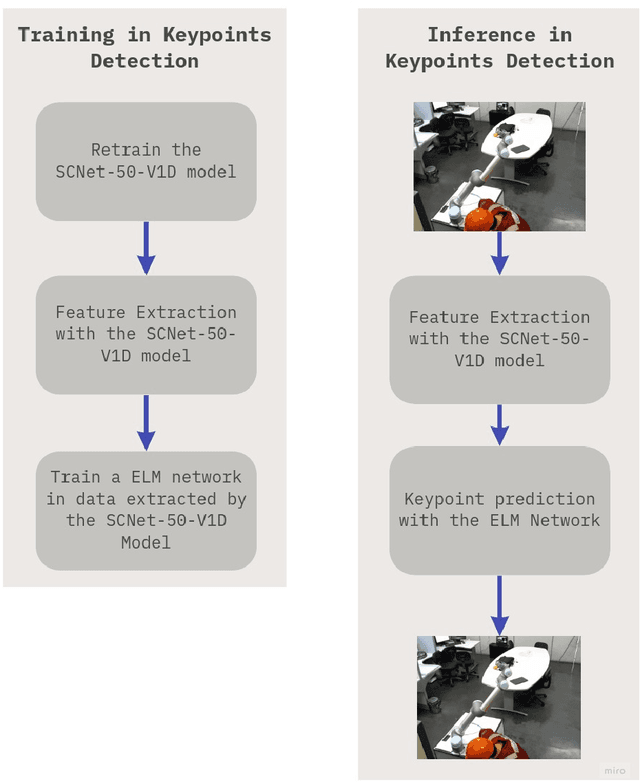

Human-robot collaboration has gained a notable prominence in Industry 4.0, as the use of collaborative robots increases efficiency and productivity in the automation process. However, it is necessary to consider the use of mechanisms that increase security in these environments, as the literature reports that risk situations may exist in the context of human-robot collaboration. One of the strategies that can be adopted is the visual recognition of the collaboration environment using machine learning techniques, which can automatically identify what is happening in the scene and what may happen in the future. In this work, we are proposing a new framework that is capable of detecting robotic arm keypoints commonly used in Industry 4.0. In addition to detecting, the proposed framework is able to predict the future movement of these robotic arms, thus providing relevant information that can be considered in the recognition of the human-robot collaboration scenario. The proposed framework is based on deep and extreme learning machine techniques. Results show that the proposed framework is capable of detecting and predicting with low error, contributing to the mitigation of risks in human-robot collaboration.
Pixel-by-pixel Mean Opinion Score (pMOS) for No-Reference Image Quality Assessment
Jun 14, 2022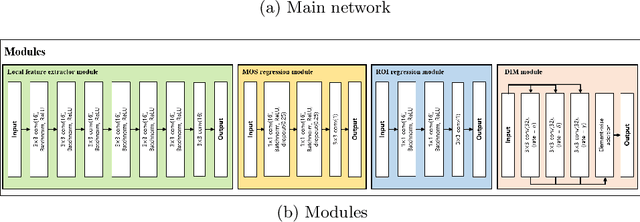
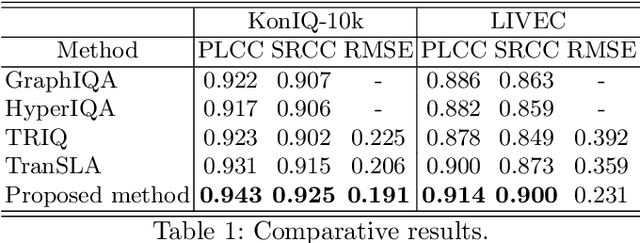
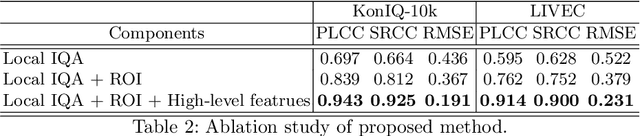
Deep-learning based techniques have contributed to the remarkable progress in the field of automatic image quality assessment (IQA). Existing IQA methods are designed to measure the quality of an image in terms of Mean Opinion Score (MOS) at the image-level (i.e. the whole image) or at the patch-level (dividing the image into multiple units and measuring quality of each patch). Some applications may require assessing the quality at the pixel-level (i.e. MOS value for each pixel), however, this is not possible in case of existing techniques as the spatial information is lost owing to their network structures. This paper proposes an IQA algorithm that can measure the MOS at the pixel-level, in addition to the image-level MOS. The proposed algorithm consists of three core parts, namely: i) Local IQA; ii) Region of Interest (ROI) prediction; iii) High-level feature embedding. The Local IQA part outputs the MOS at the pixel-level, or pixel-by-pixel MOS - we term it 'pMOS'. The ROI prediction part outputs weights that characterize the relative importance of region when calculating the image-level IQA. The high-level feature embedding part extracts high-level image features which are then embedded into the Local IQA part. In other words, the proposed algorithm yields three outputs: the pMOS which represents MOS for each pixel, the weights from the ROI indicating the relative importance of region, and finally the image-level MOS that is obtained by the weighted sum of pMOS and ROI values. The image-level MOS thus obtained by utilizing pMOS and ROI weights shows superior performance compared to the existing popular IQA techniques. In addition, visualization results indicate that predicted pMOS and ROI outputs are reasonably aligned with the general principles of the human visual system (HVS).