 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spectral Roll-off Points: Estimating Useful Information Under the Basis of Low-frequency Data Representations
Jan 31, 2021

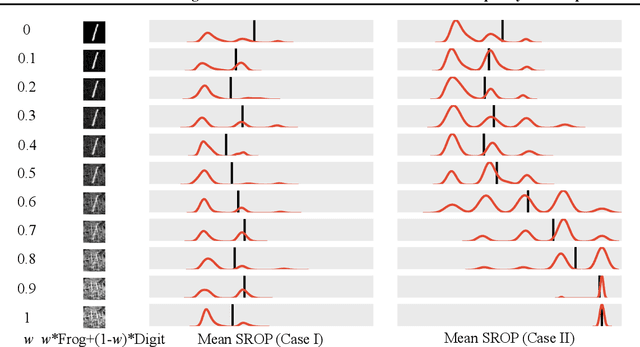
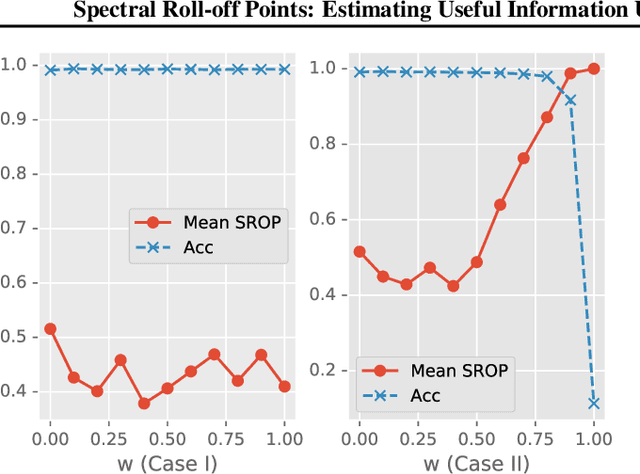
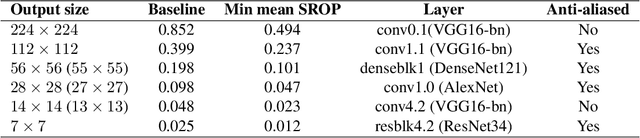
Useful information is the basis for model decisions. Estimating useful information in feature maps promotes the understanding of the mechanisms of neural networks. Low frequency is a prerequisite for useful information in data representations, because downscaling operations reduce the communication bandwidth. This study proposes the use of spectral roll-off points (SROPs) to integrate the low-frequency condition when estimating useful information. The computation of an SROP is extended from a 1-D signal to a 2-D image by the required rotation invariance in image classification tasks. SROP statistics across feature maps are implemented for layer-wise useful information estimation. Sanity checks demonstrate that the variation of layer-wise SROP distributions among model input can be used to recognize useful components that support model decisions. Moreover, the variations of SROPs and accuracy, the ground truth of useful information of models, are synchronous when adopting sufficient training in various model structures. Therefore, SROP is an accurate and convenient estimation of useful information. It promotes the explainability of artificial intelligence with respect to frequency-domain knowledge.
A Holistic Framework for Analyzing the COVID-19 Vaccine Debate
May 03, 2022


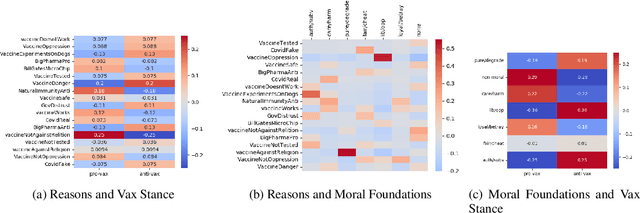
The Covid-19 pandemic has led to infodemic of low quality information leading to poor health decisions. Combating the outcomes of this infodemic is not only a question of identifying false claims, but also reasoning about the decisions individuals make. In this work we propose a holistic analysis framework connecting stance and reason analysis, and fine-grained entity level moral sentiment analysis. We study how to model the dependencies between the different level of analysis and incorporate human insights into the learning process. Experiments show that our framework provides reliable predictions even in the low-supervision settings.
Context Matters for Image Descriptions for Accessibility: Challenges for Referenceless Evaluation Metrics
May 21, 2022
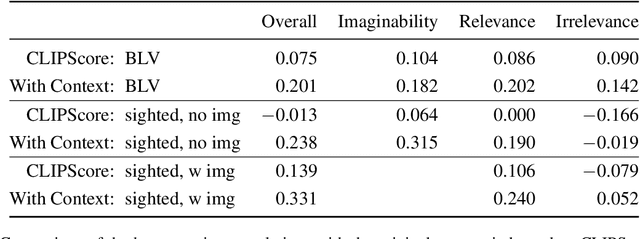
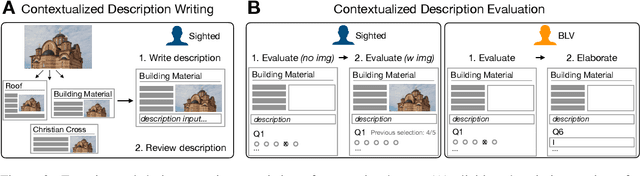
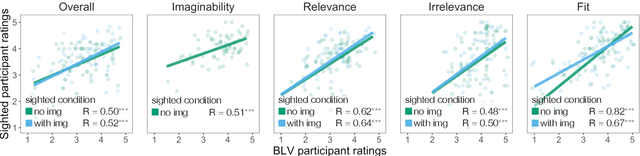
Few images on the Web receive alt-text descriptions that would make them accessible to blind and low vision (BLV) users. Image-based NLG systems have progressed to the point where they can begin to address this persistent societal problem, but these systems will not be fully successful unless we evaluate them on metrics that guide their development correctly. Here, we argue against current referenceless metrics -- those that don't rely on human-generated ground-truth descriptions -- on the grounds that they do not align with the needs of BLV users. The fundamental shortcoming of these metrics is that they cannot take context into account, whereas contextual information is highly valued by BLV users. To substantiate these claims, we present a study with BLV participants who rated descriptions along a variety of dimensions. An in-depth analysis reveals that the lack of context-awareness makes current referenceless metrics inadequate for advancing image accessibility, requiring a rethinking of referenceless evaluation metrics for image-based NLG systems.
Unified Speech-Text Pre-training for Speech Translation and Recognition
Apr 11, 2022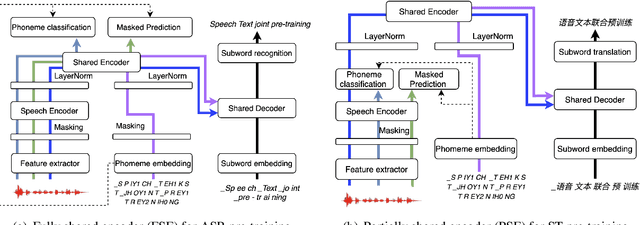

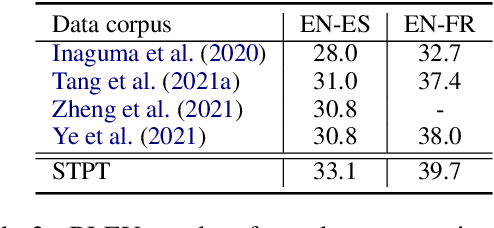
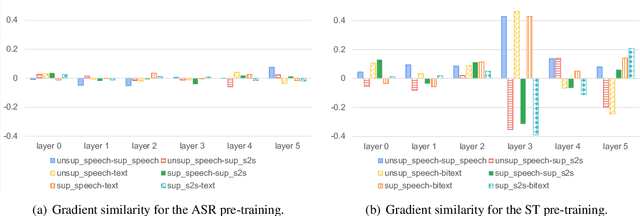
We describe a method to jointly pre-train speech and text in an encoder-decoder modeling framework for speech translation and recognition. The proposed method incorporates four self-supervised and supervised subtasks for cross modality learning. A self-supervised speech subtask leverages unlabelled speech data, and a (self-)supervised text to text subtask makes use of abundant text training data. Two auxiliary supervised speech tasks are included to unify speech and text modeling space. Our contribution lies in integrating linguistic information from the text corpus into the speech pre-training. Detailed analysis reveals learning interference among subtasks. Two pre-training configurations for speech translation and recognition, respectively, are presented to alleviate subtask interference. Our experiments show the proposed method can effectively fuse speech and text information into one model. It achieves between 1.7 and 2.3 BLEU improvement above the state of the art on the MuST-C speech translation dataset and comparable WERs to wav2vec 2.0 on the Librispeech speech recognition task.
Insights on Modelling Physiological, Appraisal, and Affective Indicators of Stress using Audio Features
May 09, 2022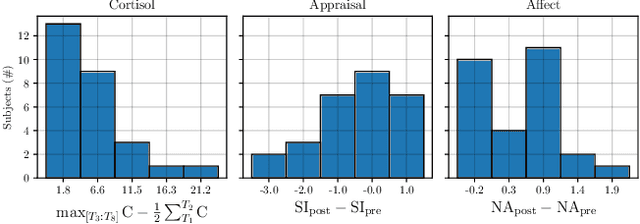
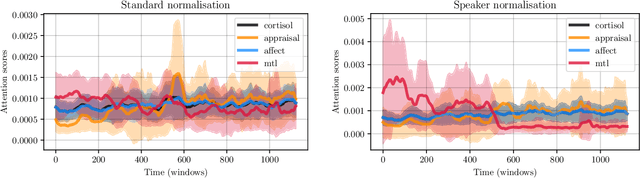
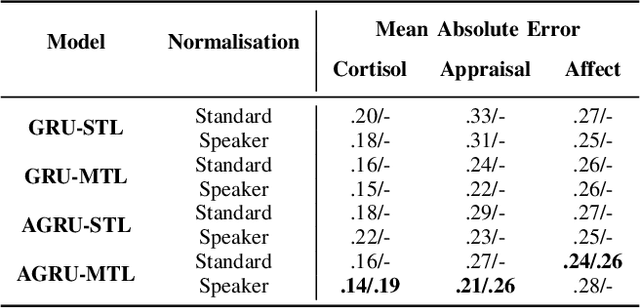
Stress is a major threat to well-being that manifests in a variety of physiological and mental symptoms. Utilising speech samples collected while the subject is undergoing an induced stress episode has recently shown promising results for the automatic characterisation of individual stress responses. In this work, we introduce new findings that shed light onto whether speech signals are suited to model physiological biomarkers, as obtained via cortisol measurements, or self-assessed appraisal and affect measurements. Our results show that different indicators impact acoustic features in a diverse way, but that their complimentary information can nevertheless be effectively harnessed by a multi-tasking architecture to improve prediction performance for all of them.
Diminishing Empirical Risk Minimization for Unsupervised Anomaly Detection
May 29, 2022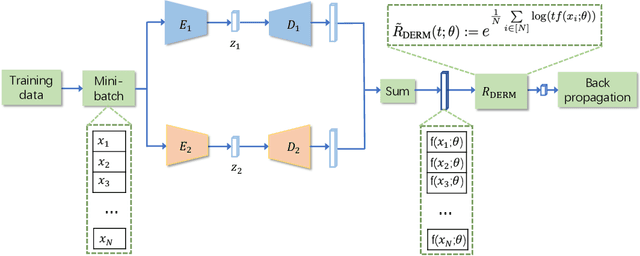
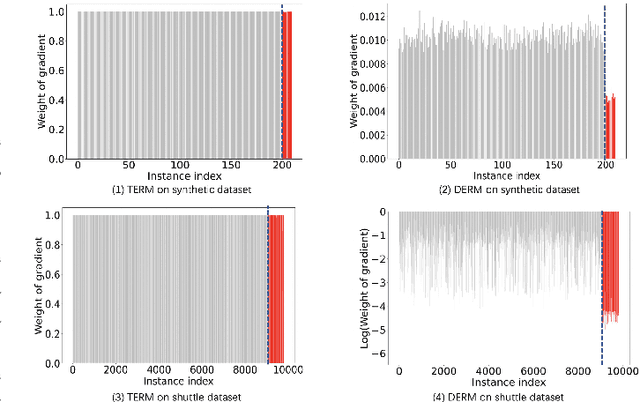
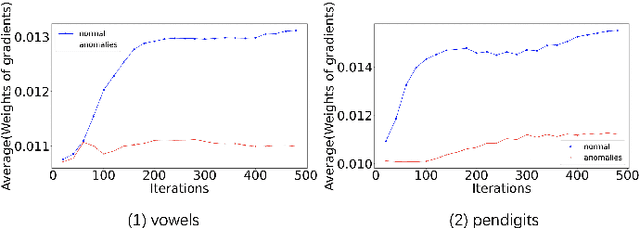
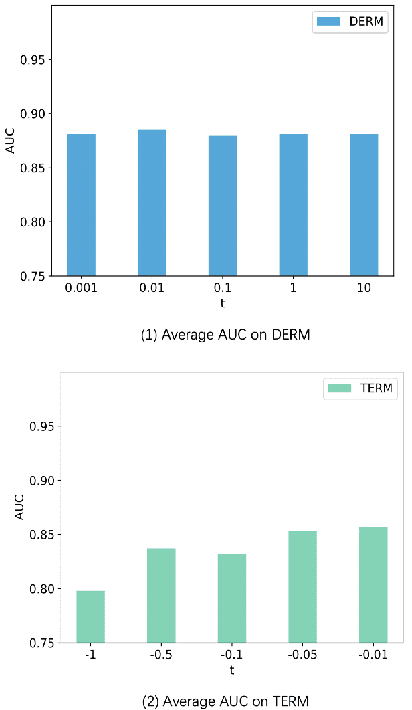
Unsupervised anomaly detection (AD) is a challenging task in realistic applications. Recently, there is an increasing trend to detect anomalies with deep neural networks (DNN). However, most popular deep AD detectors cannot protect the network from learning contaminated information brought by anomalous data, resulting in unsatisfactory detection performance and overfitting issues. In this work, we identify one reason that hinders most existing DNN-based anomaly detection methods from performing is the wide adoption of the Empirical Risk Minimization (ERM). ERM assumes that the performance of an algorithm on an unknown distribution can be approximated by averaging losses on the known training set. This averaging scheme thus ignores the distinctions between normal and anomalous instances. To break through the limitations of ERM, we propose a novel Diminishing Empirical Risk Minimization (DERM) framework. Specifically, DERM adaptively adjusts the impact of individual losses through a well-devised aggregation strategy. Theoretically, our proposed DERM can directly modify the gradient contribution of each individual loss in the optimization process to suppress the influence of outliers, leading to a robust anomaly detector. Empirically, DERM outperformed the state-of-the-art on the unsupervised AD benchmark consisting of 18 datasets.
A Unified Model for Multi-class Anomaly Detection
Jun 08, 2022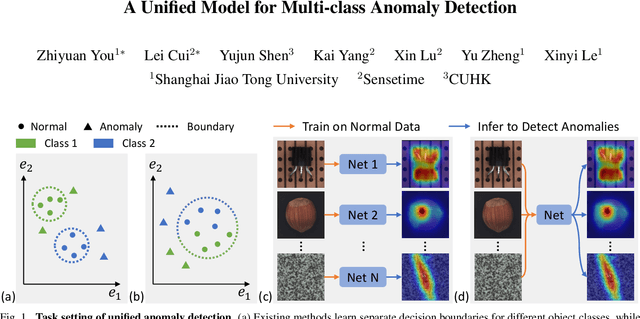
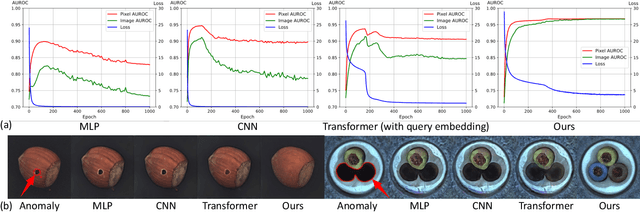
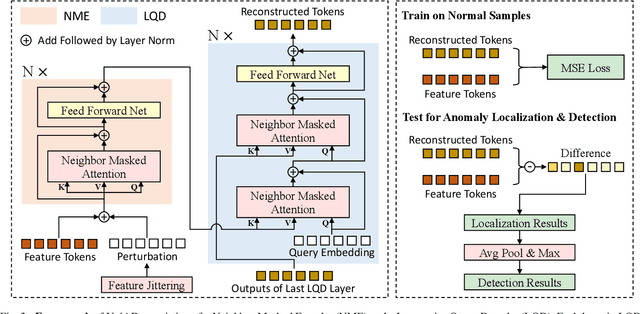
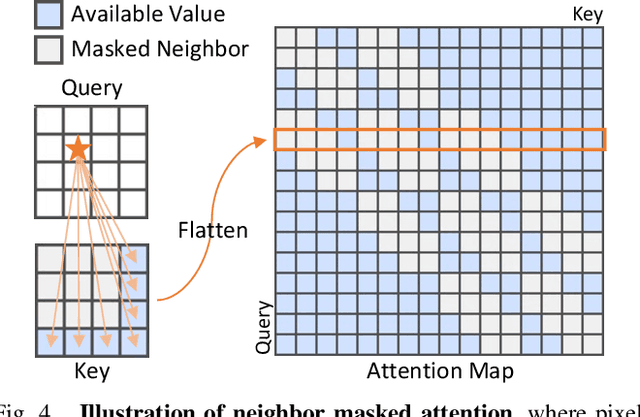
Despite the rapid advance of unsupervised anomaly detection, existing methods require to train separate models for different objects. In this work, we present UniAD that accomplishes anomaly detection for multiple classes with a unified framework. Under such a challenging setting, popular reconstruction networks may fall into an "identical shortcut", where both normal and anomalous samples can be well recovered, and hence fail to spot outliers. To tackle this obstacle, we make three improvements. First, we revisit the formulations of fully-connected layer, convolutional layer, as well as attention layer, and confirm the important role of query embedding (i.e., within attention layer) in preventing the network from learning the shortcut. We therefore come up with a layer-wise query decoder to help model the multi-class distribution. Second, we employ a neighbor masked attention module to further avoid the information leak from the input feature to the reconstructed output feature. Third, we propose a feature jittering strategy that urges the model to recover the correct message even with noisy inputs. We evaluate our algorithm on MVTec-AD and CIFAR-10 datasets, where we surpass the state-of-the-art alternatives by a sufficiently large margin. For example, when learning a unified model for 15 categories in MVTec-AD, we surpass the second competitor on the tasks of both anomaly detection (from 88.1% to 96.5%) and anomaly localization (from 89.5% to 96.8%). Code will be made publicly available.
SCGC : Self-Supervised Contrastive Graph Clustering
Apr 27, 2022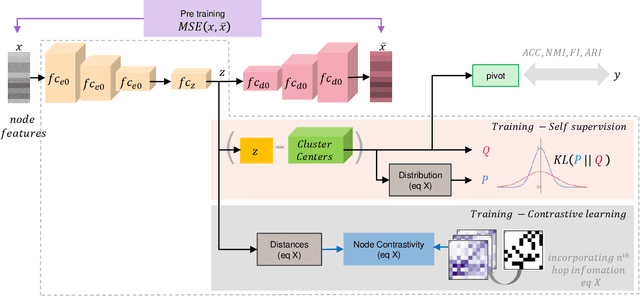
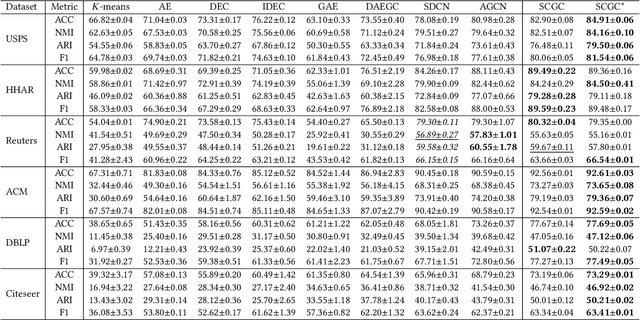
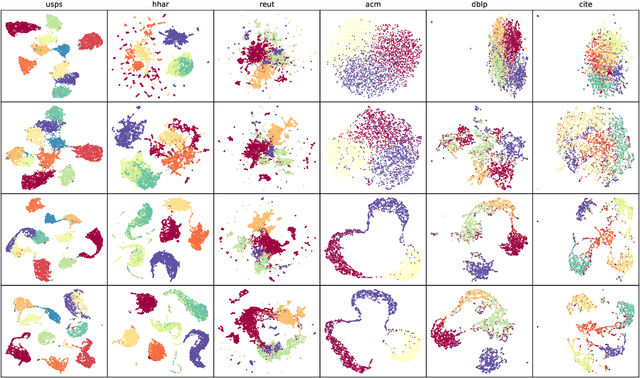
Graph clustering discovers groups or communities within networks. Deep learning methods such as autoencoders (AE) extract effective clustering and downstream representations but cannot incorporate rich structural information. While Graph Neural Networks (GNN) have shown great success in encoding graph structure, typical GNNs based on convolution or attention variants suffer from over-smoothing, noise, heterophily, are computationally expensive and typically require the complete graph being present. Instead, we propose Self-Supervised Contrastive Graph Clustering (SCGC), which imposes graph-structure via contrastive loss signals to learn discriminative node representations and iteratively refined soft cluster labels. We also propose SCGC*, with a more effective, novel, Influence Augmented Contrastive (IAC) loss to fuse richer structural information, and half the original model parameters. SCGC(*) is faster with simple linear units, completely eliminate convolutions and attention of traditional GNNs, yet efficiently incorporates structure. It is impervious to layer depth and robust to over-smoothing, incorrect edges and heterophily. It is scalable by batching, a limitation in many prior GNN models, and trivially parallelizable. We obtain significant improvements over state-of-the-art on a wide range of benchmark graph datasets, including images, sensor data, text, and citation networks efficiently. Specifically, 20% on ARI and 18% on NMI for DBLP; overall 55% reduction in training time and overall, 81% reduction on inference time. Our code is available at : https://github.com/gayanku/SCGC
DProQ: A Gated-Graph Transformer for Protein Complex Structure Assessment
May 21, 2022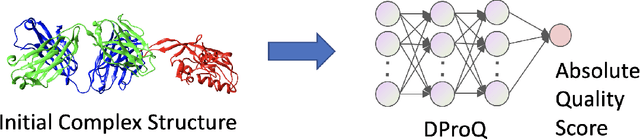
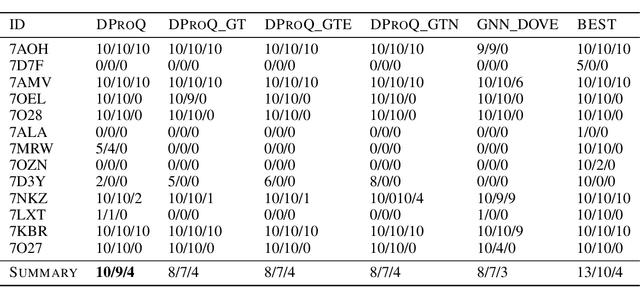
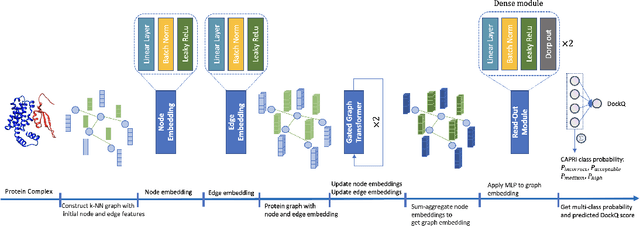
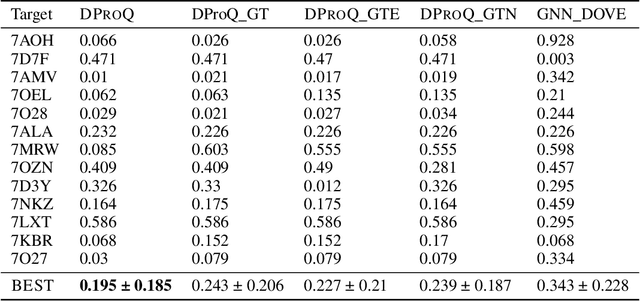
Proteins interact to form complexes to carry out essential biological functions. Computational methods have been developed to predict the structures of protein complexes. However, an important challenge in protein complex structure prediction is to estimate the quality of predicted protein complex structures without any knowledge of the corresponding native structures. Such estimations can then be used to select high-quality predicted complex structures to facilitate biomedical research such as protein function analysis and drug discovery. We challenge this significant task with DProQ, which introduces a gated neighborhood-modulating Graph Transformer (GGT) designed to predict the quality of 3D protein complex structures. Notably, we incorporate node and edge gates within a novel Graph Transformer framework to control information flow during graph message passing. We train and evaluate DProQ on four newly-developed datasets that we make publicly available in this work. Our rigorous experiments demonstrate that DProQ achieves state-of-the-art performance in ranking protein complex structures.
Predicting Vehicles Trajectories in Urban Scenarios with Transformer Networks and Augmented Information
Jun 07, 2021
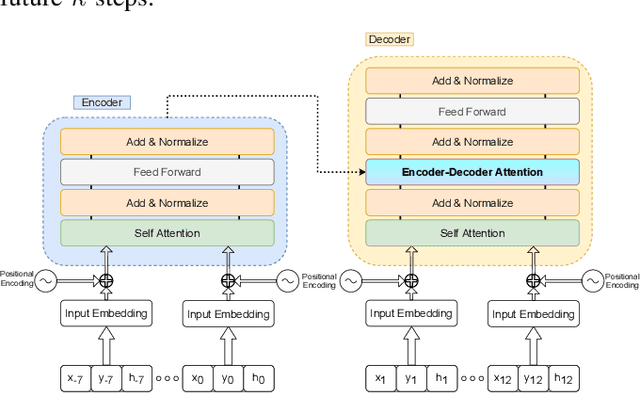
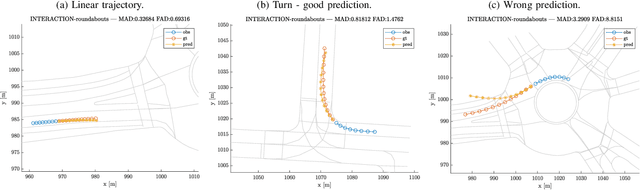
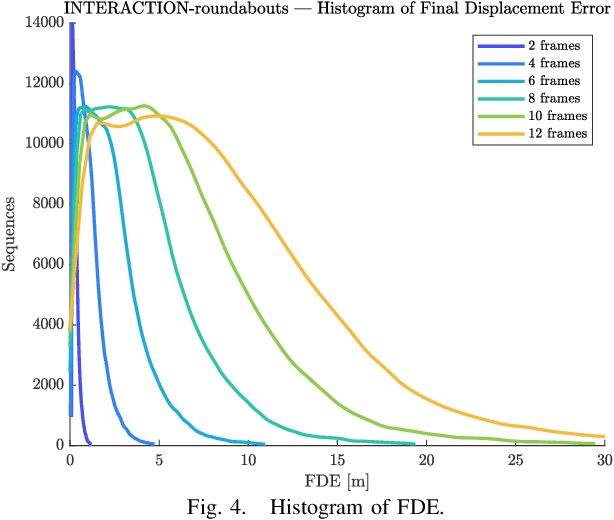
Understanding the behavior of road users is of vital importance for the development of trajectory prediction systems. In this context, the latest advances have focused on recurrent structures, establishing the social interaction between the agents involved in the scene. More recently, simpler structures have also been introduced for predicting pedestrian trajectories, based on Transformer Networks, and using positional information. They allow the individual modelling of each agent's trajectory separately without any complex interaction terms. Our model exploits these simple structures by adding augmented data (position and heading), and adapting their use to the problem of vehicle trajectory prediction in urban scenarios in prediction horizons up to 5 seconds. In addition, a cross-performance analysis is performed between different types of scenarios, including highways, intersections and roundabouts, using recent datasets (inD, rounD, highD and INTERACTION). Our model achieves state-of-the-art results and proves to be flexible and adaptable to different types of urban contexts.