 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Pre-training for AMR Parsing and Generation
Mar 31, 2022
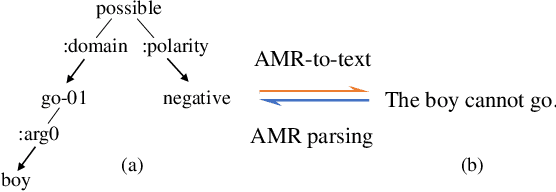

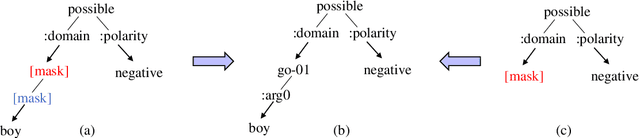

Abstract meaning representation (AMR) highlights the core semantic information of text in a graph structure. Recently, pre-trained language models (PLMs) have advanced tasks of AMR parsing and AMR-to-text generation, respectively. However, PLMs are typically pre-trained on textual data, thus are sub-optimal for modeling structural knowledge. To this end, we investigate graph self-supervised training to improve the structure awareness of PLMs over AMR graphs. In particular, we introduce two graph auto-encoding strategies for graph-to-graph pre-training and four tasks to integrate text and graph information during pre-training. We further design a unified framework to bridge the gap between pre-training and fine-tuning tasks. Experiments on both AMR parsing and AMR-to-text generation show the superiority of our model. To our knowledge, we are the first to consider pre-training on semantic graphs.
Online greedy identification of linear dynamical systems
Apr 13, 2022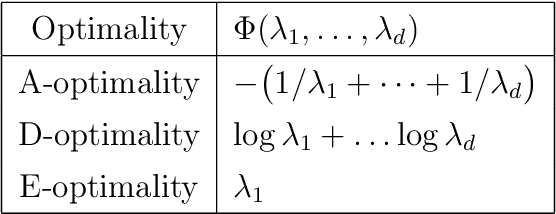
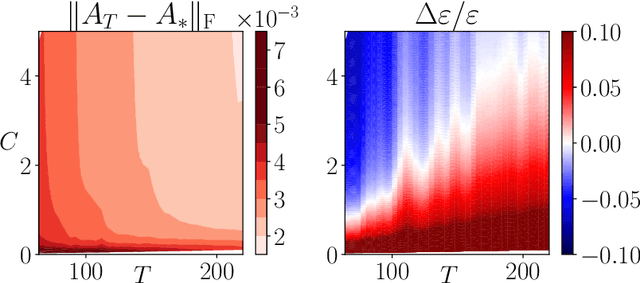
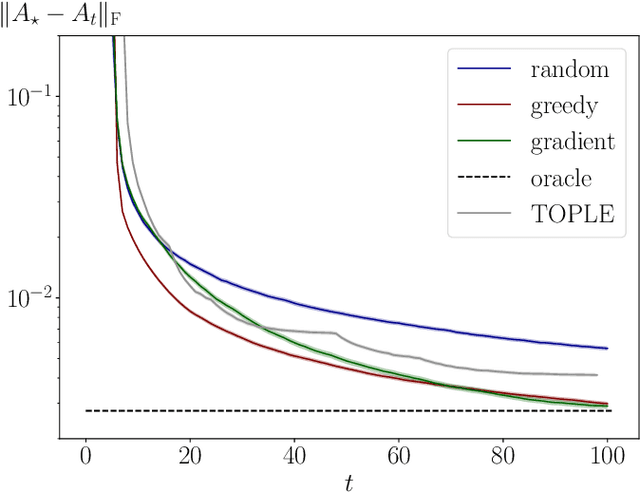
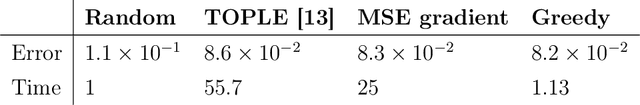
This work addresses the problem of exploration in an unknown environment. For linear dynamical systems, we use an experimental design framework and introduce an online greedy policy where the control maximizes the information of the next step. In a setting with a limited number of experimental trials, our algorithm has low complexity and shows experimentally competitive performances compared to more elaborate gradient-based methods.
Medical Information Retrieval and Interpretation: A Question-Answer based Interaction Model
Jan 24, 2021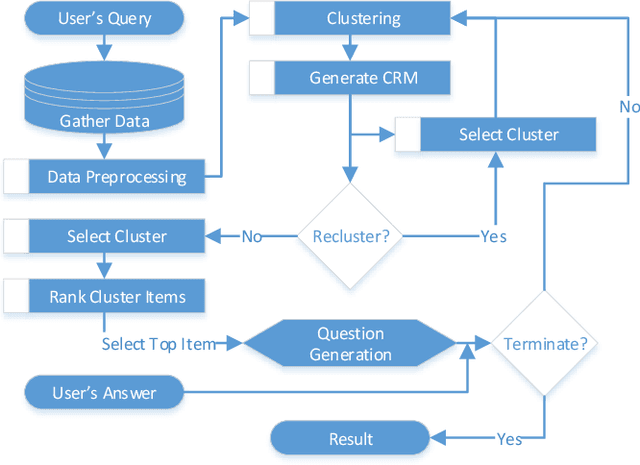
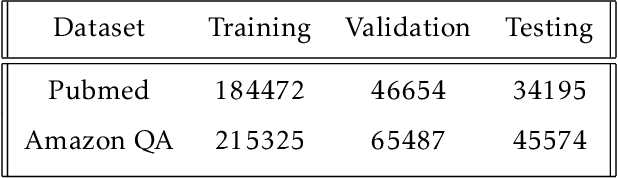
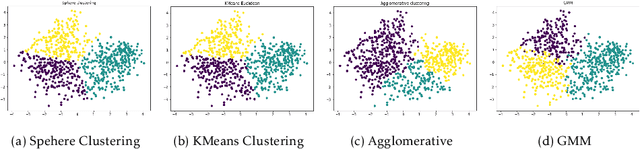
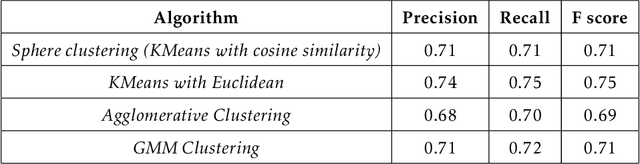
The Internet has become a very powerful platform where diverse medical information are expressed daily. Recently, a huge growth is seen in searches like symptoms, diseases, medicines, and many other health related queries around the globe. The search engines typically populate the result by using the single query provided by the user and hence reaching to the final result may require a lot of manual filtering from the user's end. Current search engines and recommendation systems still lack real time interactions that may provide more precise result generation. This paper proposes an intelligent and interactive system tied up with the vast medical big data repository on the web and illustrates its potential in finding medical information.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
May 26, 2022
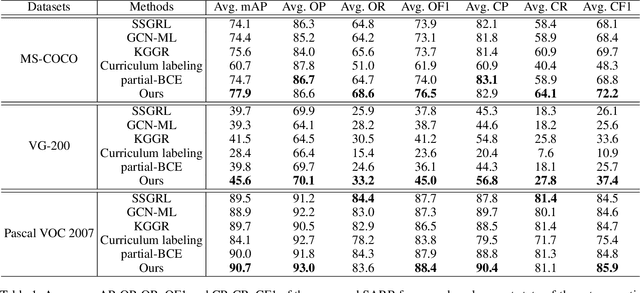
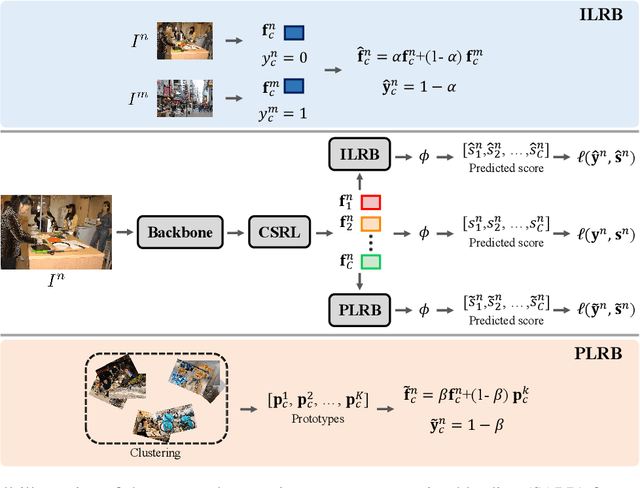
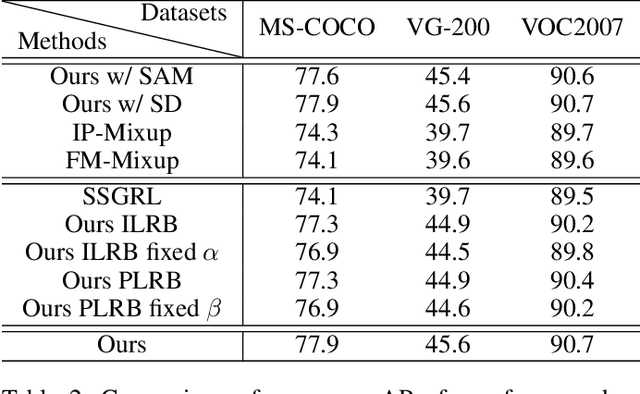
Despite achieving impressive progress, current multi-label image recognition (MLR) algorithms heavily depend on large-scale datasets with complete labels, making collecting large-scale datasets extremely time-consuming and labor-intensive. Training the multi-label image recognition models with partial labels (MLR-PL) is an alternative way to address this issue, in which merely some labels are known while others are unknown for each image (see Figure 1). However, current MLP-PL algorithms mainly rely on the pre-trained image classification or similarity models to generate pseudo labels for the unknown labels. Thus, they depend on a certain amount of data annotations and inevitably suffer from obvious performance drops, especially when the known label proportion is low. To address this dilemma, we propose a unified semantic-aware representation blending (SARB) that consists of two crucial modules to blend multi-granularity category-specific semantic representation across different images to transfer information of known labels to complement unknown labels. Extensive experiments on the MS-COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed SARB consistently outperforms current state-of-the-art algorithms on all known label proportion settings. Concretely, it obtain the average mAP improvement of 1.9%, 4.5%, 1.0% on the three benchmark datasets compared with the second-best algorithm.
Heterogeneous Separation Consistency Training for Adaptation of Unsupervised Speech Separation
Apr 23, 2022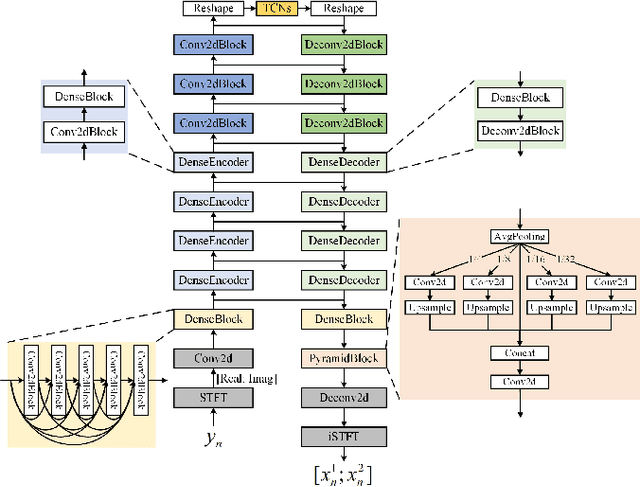
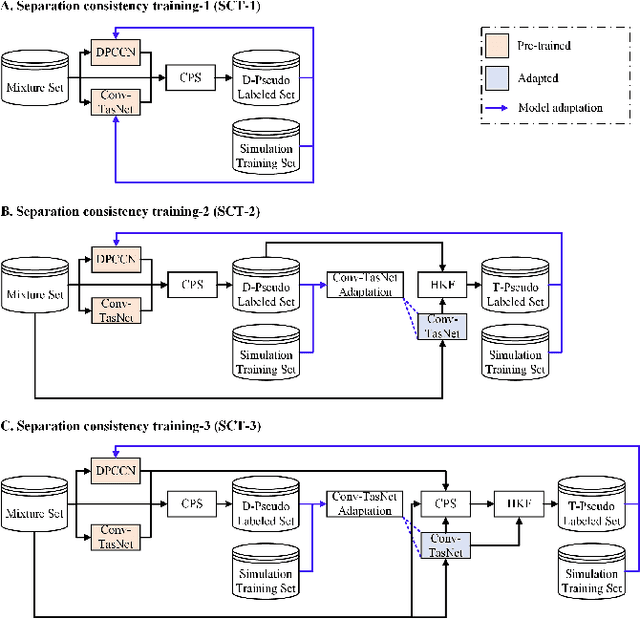
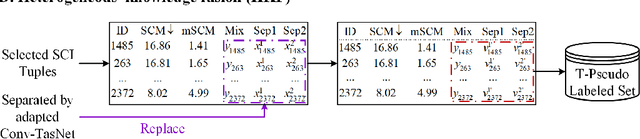
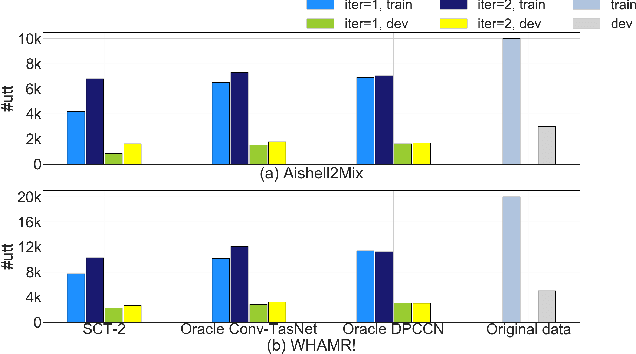
Recently, supervised speech separation has made great progress. However, limited by the nature of supervised training, most existing separation methods require ground-truth sources and are trained on synthetic datasets. This ground-truth reliance is problematic, because the ground-truth signals are usually unavailable in real conditions. Moreover, in many industry scenarios, the real acoustic characteristics deviate far from the ones in simulated datasets. Therefore, the performance usually degrades significantly when applying the supervised speech separation models to real applications. To address these problems, in this study, we propose a novel separation consistency training, termed SCT, to exploit the real-world unlabeled mixtures for improving cross-domain unsupervised speech separation in an iterative manner, by leveraging upon the complementary information obtained from heterogeneous (structurally distinct but behaviorally complementary) models. SCT follows a framework using two heterogeneous neural networks (HNNs) to produce high confidence pseudo labels of unlabeled real speech mixtures. These labels are then updated, and used to refine the HNNs to produce more reliable consistent separation results for real mixture pseudo-labeling. To maximally utilize the large complementary information between different separation networks, a cross-knowledge adaptation is further proposed. Together with simulated dataset, those real mixtures with high confidence pseudo labels are then used to update the HNN separation models iteratively. In addition, we find that combing the heterogeneous separation outputs by a simple linear fusion can further slightly improve the final system performance.
Masked Autoencoders As Spatiotemporal Learners
May 18, 2022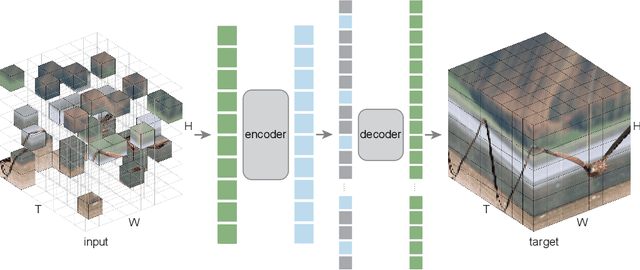



This paper studies a conceptually simple extension of Masked Autoencoders (MAE) to spatiotemporal representation learning from videos. We randomly mask out spacetime patches in videos and learn an autoencoder to reconstruct them in pixels. Interestingly, we show that our MAE method can learn strong representations with almost no inductive bias on spacetime (only except for patch and positional embeddings), and spacetime-agnostic random masking performs the best. We observe that the optimal masking ratio is as high as 90% (vs. 75% on images), supporting the hypothesis that this ratio is related to information redundancy of the data. A high masking ratio leads to a large speedup, e.g., > 4x in wall-clock time or even more. We report competitive results on several challenging video datasets using vanilla Vision Transformers. We observe that MAE can outperform supervised pre-training by large margins. We further report encouraging results of training on real-world, uncurated Instagram data. Our study suggests that the general framework of masked autoencoding (BERT, MAE, etc.) can be a unified methodology for representation learning with minimal domain knowledge.
Real-time Human-Robot Collaborative Manipulations of Cylindrical and Cubic Objects via Geometric Primitives and Depth Information
Jun 28, 2021
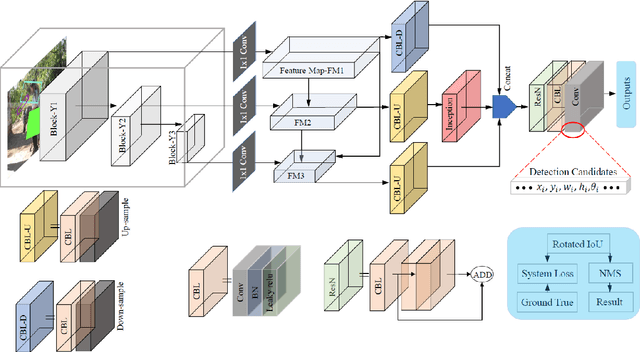
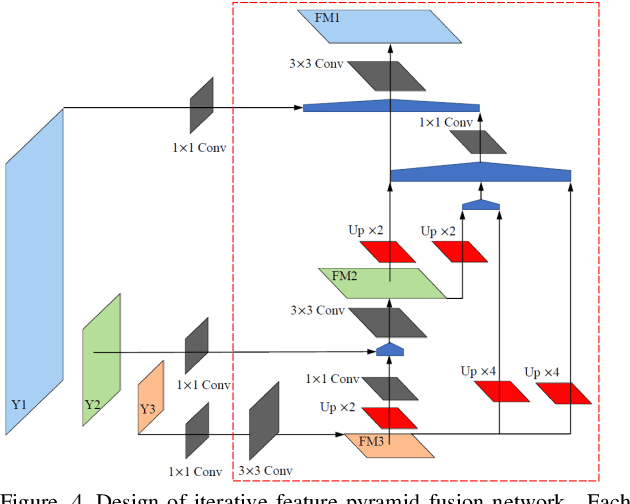
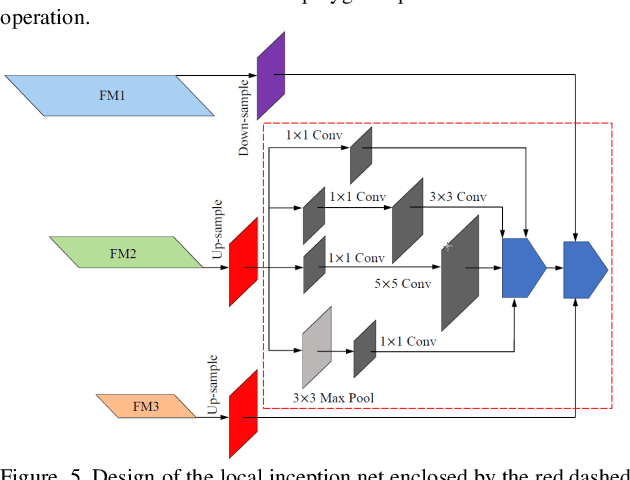
Many objects commonly found in household and industrial environments are represented by cylindrical and cubic shapes. Thus, it is available for robots to manipulate them through the real-time detection of elliptic and rectangle shape primitives formed by the circular and rectangle tops of these objects. We devise a robust grasping system that enables a robot to manipulate cylindrical and cubic objects in collaboration scenarios by the proposed perception strategy including the detection of elliptic and rectangle shape primitives and depth information. The proposed method of detecting ellipses and rectangles incorporates a one-stage detection backbone and then, accommodates the proposed adaptive multi-branch multi-scale net with a designed iterative feature pyramid network, local inception net, and multi-receptive-filed feature fusion net to generate object detection recommendations. In terms of manipulating objects with different shapes, we propose the grasp synthetic to align the grasp pose of the gripper with an object's pose based on the proposed detector and registered depth information. The proposed robotic perception algorithm has been integrated on a robot to demonstrate the ability to carry out human-robot collaborative manipulations of cylindrical and cubic objects in real-time. We show that the robotic manipulator, empowered by the proposed detector, performs well in practical manipulation scenarios.(An experiment video is available in YouTube, https://www.youtube.com/watch?v=Amcs8lwvNK8.)
A Computational Acquisition Model for Multimodal Word Categorization
May 12, 2022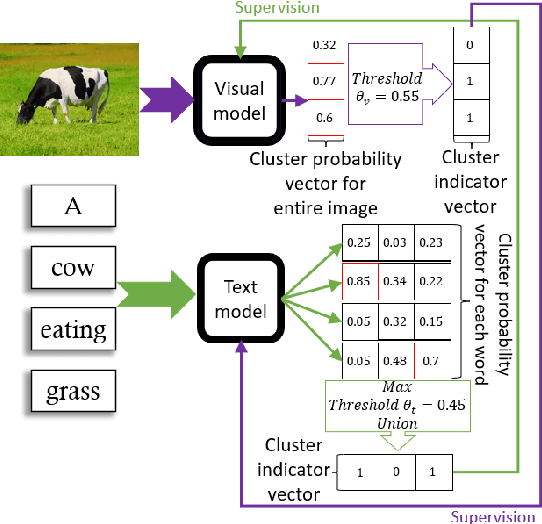

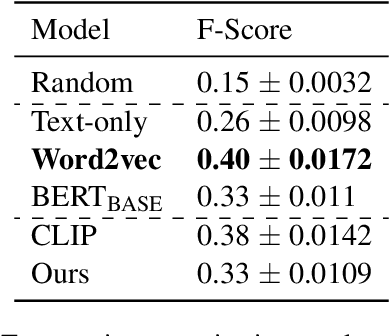
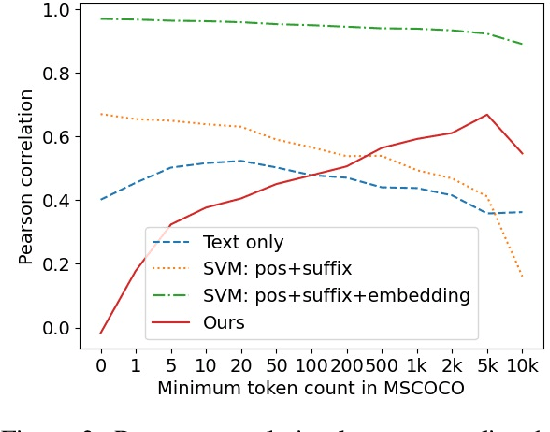
Recent advances in self-supervised modeling of text and images open new opportunities for computational models of child language acquisition, which is believed to rely heavily on cross-modal signals. However, prior studies have been limited by their reliance on vision models trained on large image datasets annotated with a pre-defined set of depicted object categories. This is (a) not faithful to the information children receive and (b) prohibits the evaluation of such models with respect to category learning tasks, due to the pre-imposed category structure. We address this gap, and present a cognitively-inspired, multimodal acquisition model, trained from image-caption pairs on naturalistic data using cross-modal self-supervision. We show that the model learns word categories and object recognition abilities, and presents trends reminiscent of those reported in the developmental literature. We make our code and trained models public for future reference and use.
Map-based Visual-Inertial Localization: Consistency and Complexity
Apr 26, 2022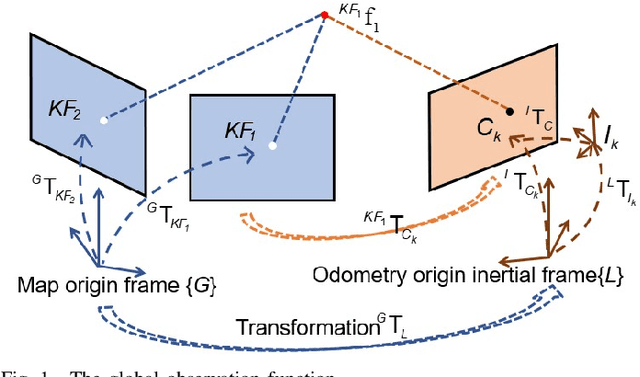
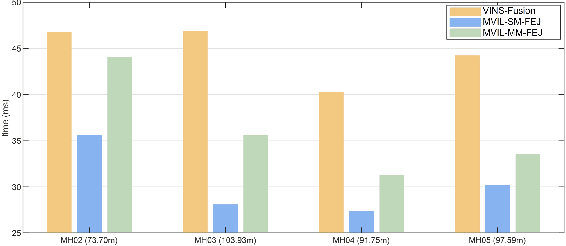
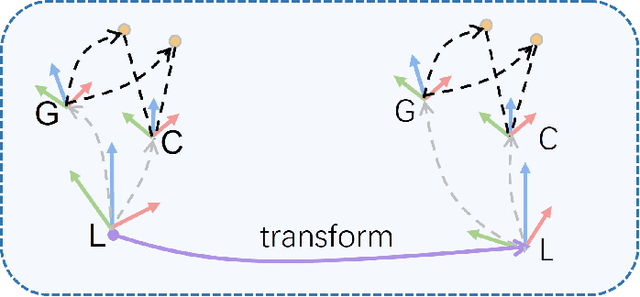
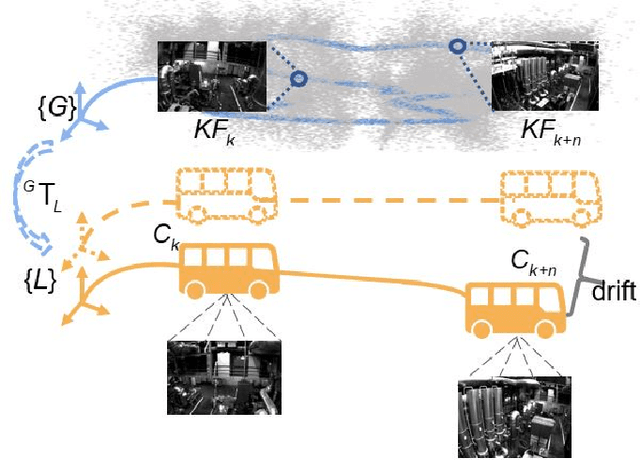
Drift-free localization is essential for autonomous vehicles. In this paper, we address the problem by proposing a filter-based framework, which integrates the visual-inertial odometry and the measurements of the features in the pre-built map. In this framework, the transformation between the odometry frame and the map frame is augmented into the state and estimated on the fly. Besides, we maintain only the keyframe poses in the map and employ Schmidt extended Kalman filter to update the state partially, so that the uncertainty of the map information can be consistently considered with low computational cost. Moreover, we theoretically demonstrate that the ever-changing linearization points of the estimated state can introduce spurious information to the augmented system and make the original four-dimensional unobservable subspace vanish, leading to inconsistent estimation in practice. To relieve this problem, we employ first-estimate Jacobian (FEJ) to maintain the correct observability properties of the augmented system. Furthermore, we introduce an observability-constrained updating method to compensate for the significant accumulated error after the long-term absence (can be 3 minutes and 1 km) of map-based measurements. Through simulations, the consistent estimation of our proposed algorithm is validated. Through real-world experiments, we demonstrate that our proposed algorithm runs successfully on four kinds of datasets with the lower computational cost (20% time-saving) and the better estimation accuracy (45% trajectory error reduction) compared with the baseline algorithm VINS-Fusion, whereas VINS-Fusion fails to give bounded localization performance on three of four datasets because of its inconsistent estimation.
Contextual Attention Network: Transformer Meets U-Net
Mar 31, 2022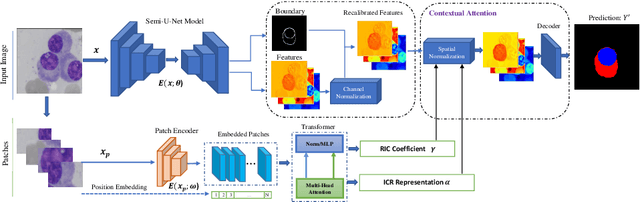
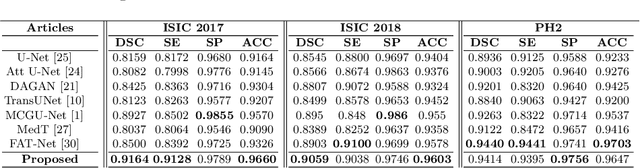


Currently, convolutional neural networks (CNN) (e.g., U-Net) have become the de facto standard and attained immense success in medical image segmentation. However, as a downside, CNN based methods are a double-edged sword as they fail to build long-range dependencies and global context connections due to the limited receptive field that stems from the intrinsic characteristics of the convolution operation. Hence, recent articles have exploited Transformer variants for medical image segmentation tasks which open up great opportunities due to their innate capability of capturing long-range correlations through the attention mechanism. Although being feasibly designed, most of the cohort studies incur prohibitive performance in capturing local information, thereby resulting in less lucidness of boundary areas. In this paper, we propose a contextual attention network to tackle the aforementioned limitations. The proposed method uses the strength of the Transformer module to model the long-range contextual dependency. Simultaneously, it utilizes the CNN encoder to capture local semantic information. In addition, an object-level representation is included to model the regional interaction map. The extracted hierarchical features are then fed to the contextual attention module to adaptively recalibrate the representation space using the local information. Then, they emphasize the informative regions while taking into account the long-range contextual dependency derived by the Transformer module. We validate our method on several large-scale public medical image segmentation datasets and achieve state-of-the-art performance. We have provided the implementation code in https://github.com/rezazad68/TMUnet.