 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Memory-enriched computation and learning in spiking neural networks through Hebbian plasticity
May 23, 2022
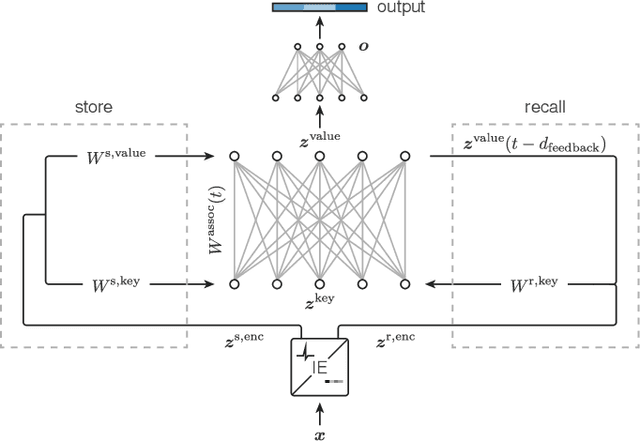
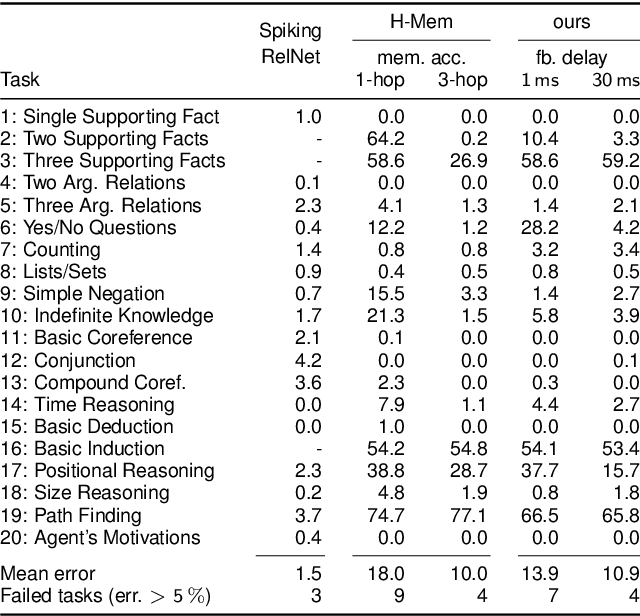
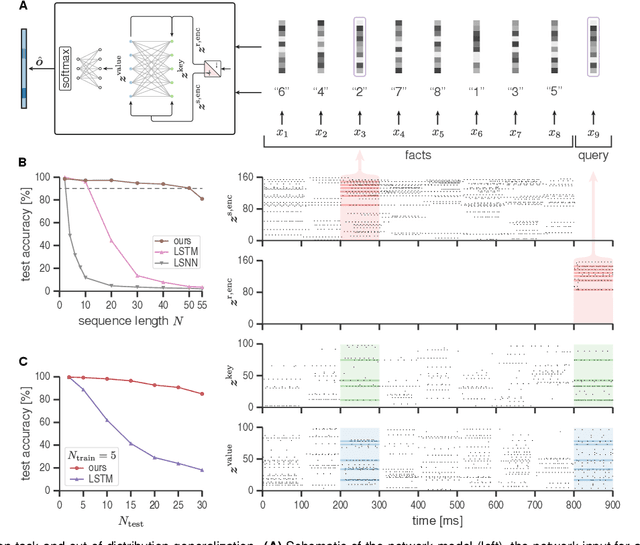

Memory is a key component of biological neural systems that enables the retention of information over a huge range of temporal scales, ranging from hundreds of milliseconds up to years. While Hebbian plasticity is believed to play a pivotal role in biological memory, it has so far been analyzed mostly in the context of pattern completion and unsupervised learning. Here, we propose that Hebbian plasticity is fundamental for computations in biological neural systems. We introduce a novel spiking neural network architecture that is enriched by Hebbian synaptic plasticity. We show that Hebbian enrichment renders spiking neural networks surprisingly versatile in terms of their computational as well as learning capabilities. It improves their abilities for out-of-distribution generalization, one-shot learning, cross-modal generative association, language processing, and reward-based learning. As spiking neural networks are the basis for energy-efficient neuromorphic hardware, this also suggests that powerful cognitive neuromorphic systems can be build based on this principle.
Beyond Faithfulness: A Framework to Characterize and Compare Saliency Methods
Jun 07, 2022
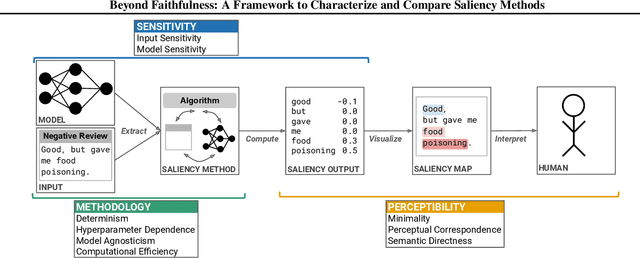
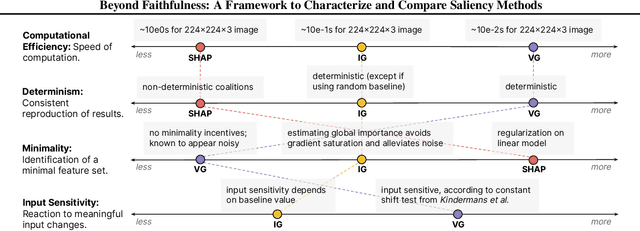

Saliency methods calculate how important each input feature is to a machine learning model's prediction, and are commonly used to understand model reasoning. "Faithfulness", or how fully and accurately the saliency output reflects the underlying model, is an oft-cited desideratum for these methods. However, explanation methods must necessarily sacrifice certain information in service of user-oriented goals such as simplicity. To that end, and akin to performance metrics, we frame saliency methods as abstractions: individual tools that provide insight into specific aspects of model behavior and entail tradeoffs. Using this framing, we describe a framework of nine dimensions to characterize and compare the properties of saliency methods. We group these dimensions into three categories that map to different phases of the interpretation process: methodology, or how the saliency is calculated; sensitivity, or relationships between the saliency result and the underlying model or input; and, perceptibility, or how a user interprets the result. As we show, these dimensions give us a granular vocabulary for describing and comparing saliency methods -- for instance, allowing us to develop "saliency cards" as a form of documentation, or helping downstream users understand tradeoffs and choose a method for a particular use case. Moreover, by situating existing saliency methods within this framework, we identify opportunities for future work, including filling gaps in the landscape and developing new evaluation metrics.
An Adversarial Imitation Click Model for Information Retrieval
Apr 19, 2021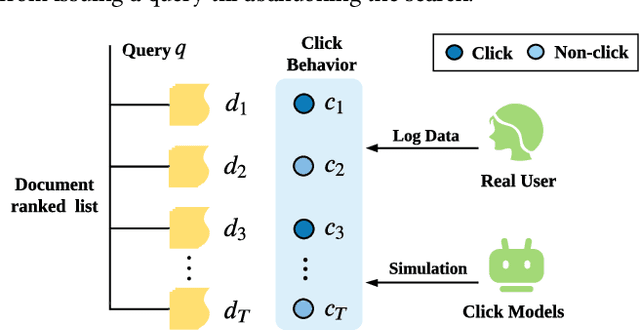
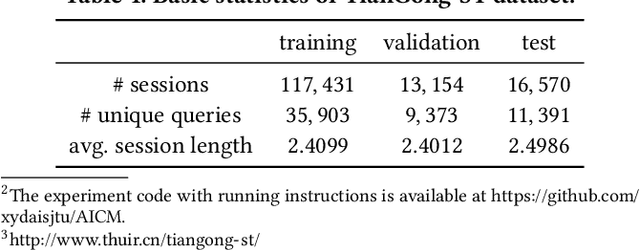
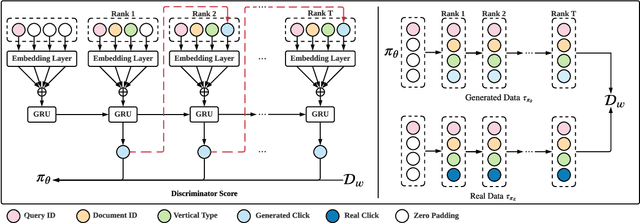
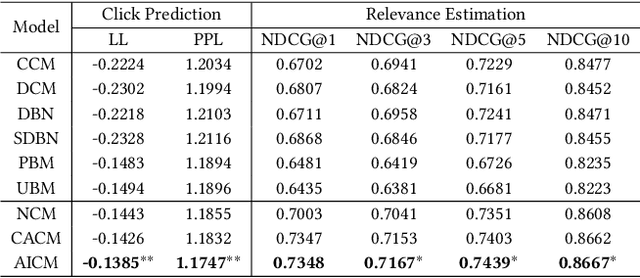
Modern information retrieval systems, including web search, ads placement, and recommender systems, typically rely on learning from user feedback. Click models, which study how users interact with a ranked list of items, provide a useful understanding of user feedback for learning ranking models. Constructing "right" dependencies is the key of any successful click model. However, probabilistic graphical models (PGMs) have to rely on manually assigned dependencies, and oversimplify user behaviors. Existing neural network based methods promote PGMs by enhancing the expressive ability and allowing flexible dependencies, but still suffer from exposure bias and inferior estimation. In this paper, we propose a novel framework, Adversarial Imitation Click Model (AICM), based on imitation learning. Firstly, we explicitly learn the reward function that recovers users' intrinsic utility and underlying intentions. Secondly, we model user interactions with a ranked list as a dynamic system instead of one-step click prediction, alleviating the exposure bias problem. Finally, we minimize the JS divergence through adversarial training and learn a stable distribution of click sequences, which makes AICM generalize well across different distributions of ranked lists. A theoretical analysis has indicated that AICM reduces the exposure bias from $O(T^2)$ to $O(T)$. Our studies on a public web search dataset show that AICM not only outperforms state-of-the-art models in traditional click metrics but also achieves superior performance in addressing the exposure bias and recovering the underlying patterns of click sequences.
Scalable Multi-view Clustering with Graph Filtering
May 18, 2022With the explosive growth of multi-source data, multi-view clustering has attracted great attention in recent years. Most existing multi-view methods operate in raw feature space and heavily depend on the quality of original feature representation. Moreover, they are often designed for feature data and ignore the rich topology structure information. Accordingly, in this paper, we propose a generic framework to cluster both attribute and graph data with heterogeneous features. It is capable of exploring the interplay between feature and structure. Specifically, we first adopt graph filtering technique to eliminate high-frequency noise to achieve a clustering-friendly smooth representation. To handle the scalability challenge, we develop a novel sampling strategy to improve the quality of anchors. Extensive experiments on attribute and graph benchmarks demonstrate the superiority of our approach with respect to state-of-the-art approaches.
Predicting Electricity Infrastructure Induced Wildfire Risk in California
Jun 06, 2022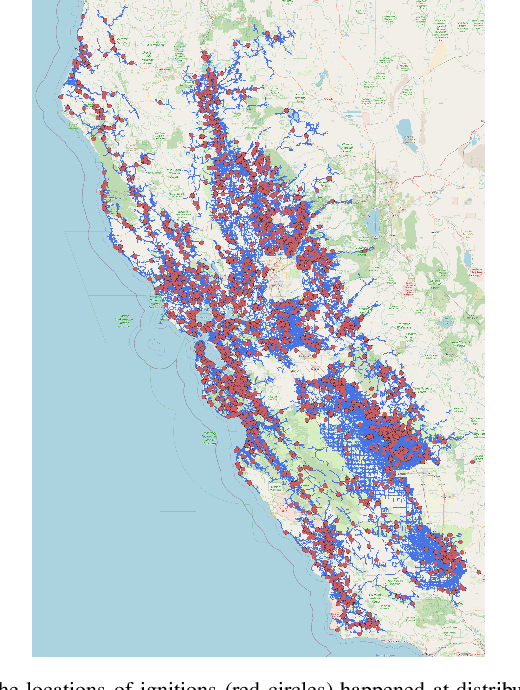
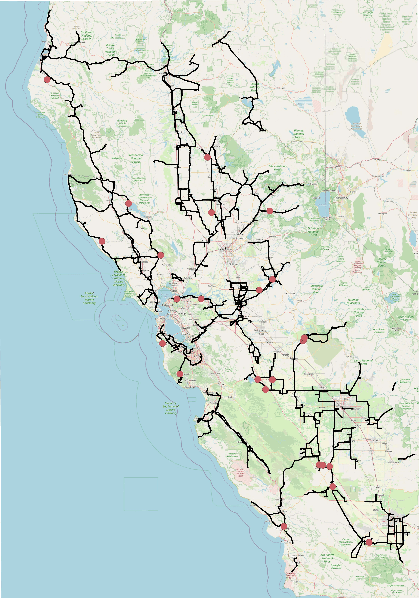
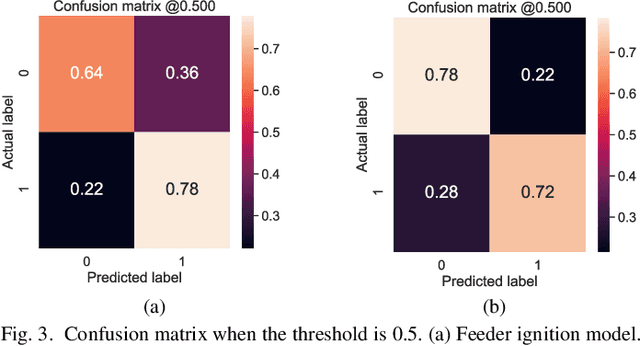
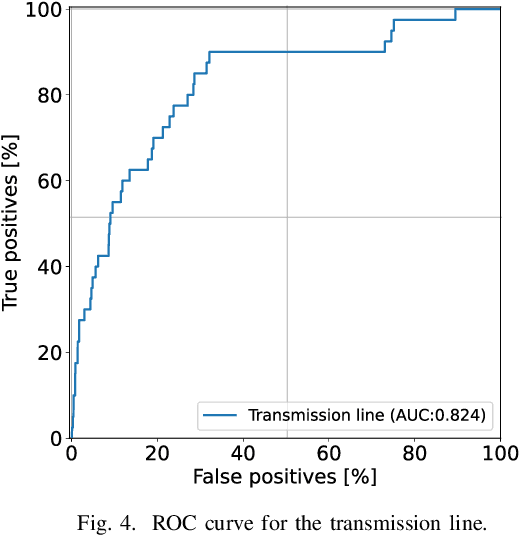
This paper examines the use of risk models to predict the timing and location of wildfires caused by electricity infrastructure. Our data include historical ignition and wire-down points triggered by grid infrastructure collected between 2015 to 2019 in Pacific Gas & Electricity territory along with various weather, vegetation, and very high resolution data on grid infrastructure including location, age, materials. With these data we explore a range of machine learning methods and strategies to manage training data imbalance. The best area under the receiver operating characteristic we obtain is 0.776 for distribution feeder ignitions and 0.824 for transmission line wire-down events, both using the histogram-based gradient boosting tree algorithm (HGB) with under-sampling. We then use these models to identify which information provides the most predictive value. After line length, we find that weather and vegetation features dominate the list of top important features for ignition or wire-down risk. Distribution ignition models show more dependence on slow-varying vegetation variables such as burn index, energy release content, and tree height, whereas transmission wire-down models rely more on primary weather variables such as wind speed and precipitation. These results point to the importance of improved vegetation modeling for feeder ignition risk models, and improved weather forecasting for transmission wire-down models. We observe that infrastructure features make small but meaningful improvements to risk model predictive power.
Meta Transfer Learning for Early Success Prediction in MOOCs
Apr 25, 2022
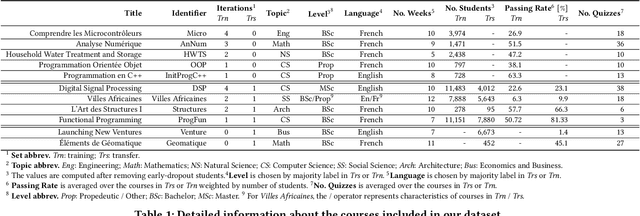
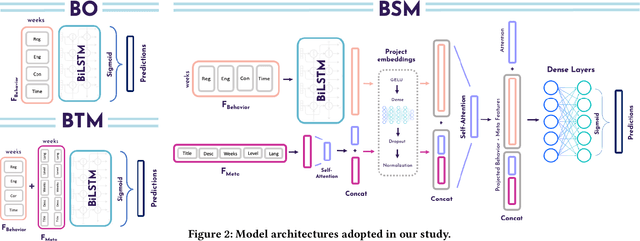
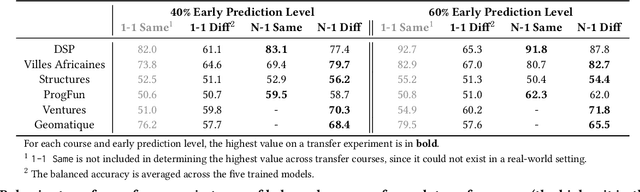
Despite the increasing popularity of massive open online courses (MOOCs), many suffer from high dropout and low success rates. Early prediction of student success for targeted intervention is therefore essential to ensure no student is left behind in a course. There exists a large body of research in success prediction for MOOCs, focusing mainly on training models from scratch for individual courses. This setting is impractical in early success prediction as the performance of a student is only known at the end of the course. In this paper, we aim to create early success prediction models that can be transferred between MOOCs from different domains and topics. To do so, we present three novel strategies for transfer: 1) pre-training a model on a large set of diverse courses, 2) leveraging the pre-trained model by including meta information about courses, and 3) fine-tuning the model on previous course iterations. Our experiments on 26 MOOCs with over 145,000 combined enrollments and millions of interactions show that models combining interaction data and course information have comparable or better performance than models which have access to previous iterations of the course. With these models, we aim to effectively enable educators to warm-start their predictions for new and ongoing courses.
User-Centric Conversational Recommendation with Multi-Aspect User Modeling
Apr 25, 2022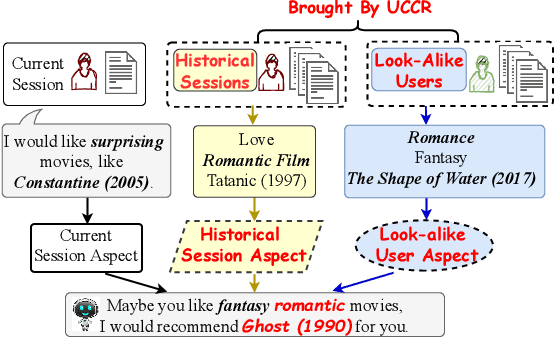
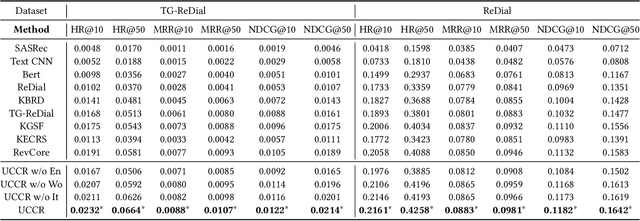
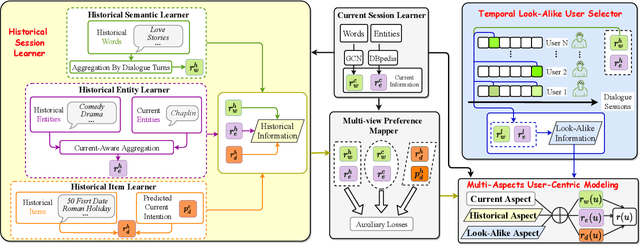
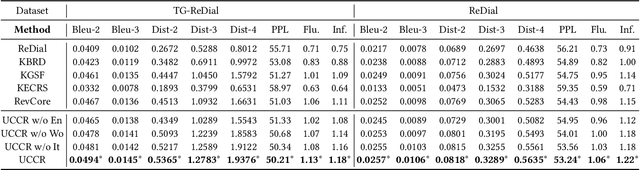
Conversational recommender systems (CRS) aim to provide highquality recommendations in conversations. However, most conventional CRS models mainly focus on the dialogue understanding of the current session, ignoring other rich multi-aspect information of the central subjects (i.e., users) in recommendation. In this work, we highlight that the user's historical dialogue sessions and look-alike users are essential sources of user preferences besides the current dialogue session in CRS. To systematically model the multi-aspect information, we propose a User-Centric Conversational Recommendation (UCCR) model, which returns to the essence of user preference learning in CRS tasks. Specifically, we propose a historical session learner to capture users' multi-view preferences from knowledge, semantic, and consuming views as supplements to the current preference signals. A multi-view preference mapper is conducted to learn the intrinsic correlations among different views in current and historical sessions via self-supervised objectives. We also design a temporal look-alike user selector to understand users via their similar users. The learned multi-aspect multi-view user preferences are then used for the recommendation and dialogue generation. In experiments, we conduct comprehensive evaluations on both Chinese and English CRS datasets. The significant improvements over competitive models in both recommendation and dialogue generation verify the superiority of UCCR.
Transformer-Empowered Content-Aware Collaborative Filtering
Apr 02, 2022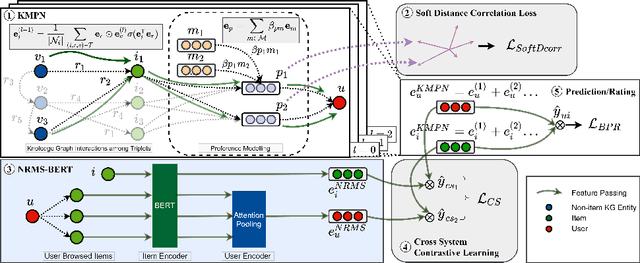
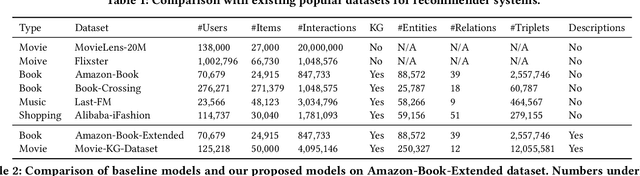
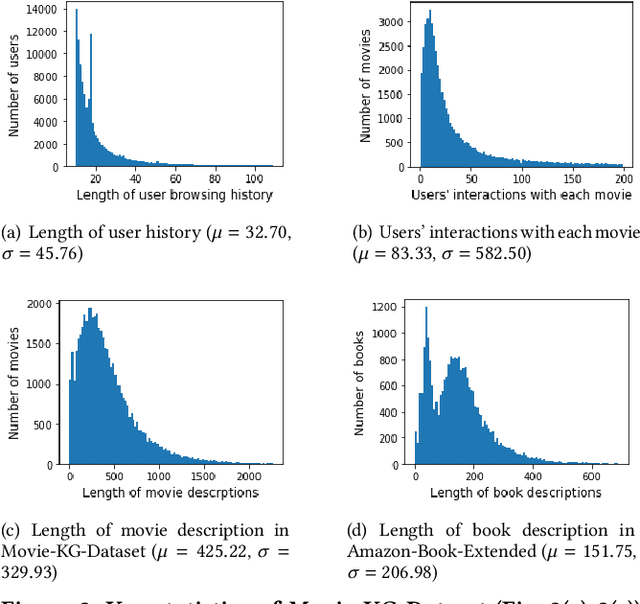
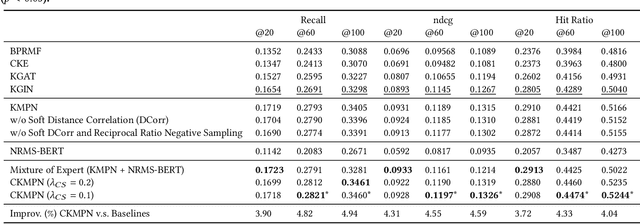
Knowledge graph (KG) based Collaborative Filtering is an effective approach to personalizing recommendation systems for relatively static domains such as movies and books, by leveraging structured information from KG to enrich both item and user representations. Motivated by the use of Transformers for understanding rich text in content-based filtering recommender systems, we propose Content-aware KG-enhanced Meta-preference Networks as a way to enhance collaborative filtering recommendation based on both structured information from KG as well as unstructured content features based on Transformer-empowered content-based filtering. To achieve this, we employ a novel training scheme, Cross-System Contrastive Learning, to address the inconsistency of the two very different systems and propose a powerful collaborative filtering model and a variant of the well-known NRMS system within this modeling framework. We also contribute to public domain resources through the creation of a large-scale movie-knowledge-graph dataset and an extension of the already public Amazon-Book dataset through incorporation of text descriptions crawled from external sources. We present experimental results showing that enhancing collaborative filtering with Transformer-based features derived from content-based filtering outperforms strong baseline systems, improving the ability of knowledge-graph-based collaborative filtering systems to exploit item content information.
A Word is Worth A Thousand Dollars: Adversarial Attack on Tweets Fools Stock Prediction
May 11, 2022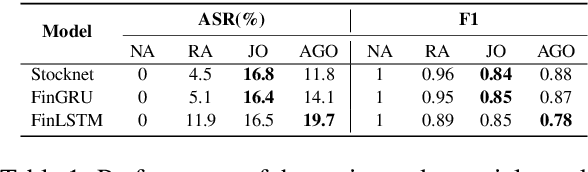
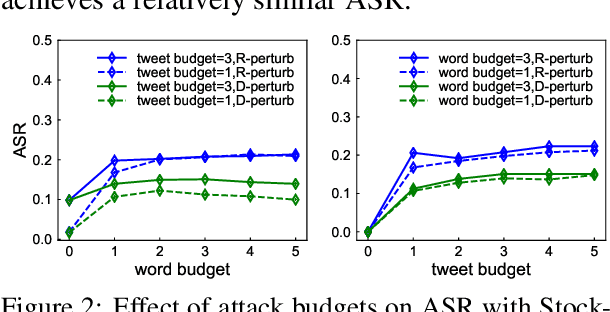
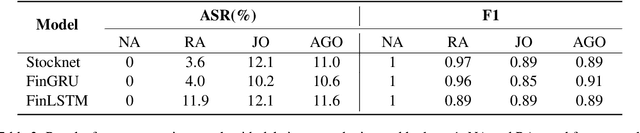
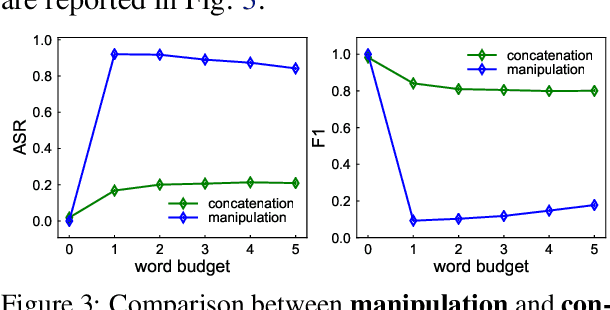
More and more investors and machine learning models rely on social media (e.g., Twitter and Reddit) to gather real-time information and sentiment to predict stock price movements. Although text-based models are known to be vulnerable to adversarial attacks, whether stock prediction models have similar vulnerability is underexplored. In this paper, we experiment with a variety of adversarial attack configurations to fool three stock prediction victim models. We address the task of adversarial generation by solving combinatorial optimization problems with semantics and budget constraints. Our results show that the proposed attack method can achieve consistent success rates and cause significant monetary loss in trading simulation by simply concatenating a perturbed but semantically similar tweet.
Explainable expected goal models for performance analysis in football analytics
Jun 14, 2022
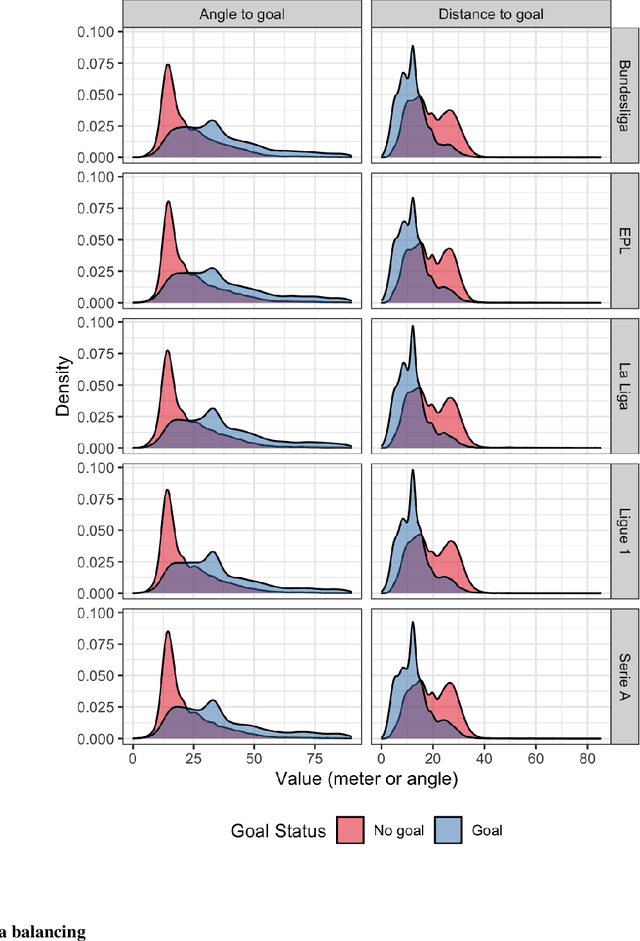
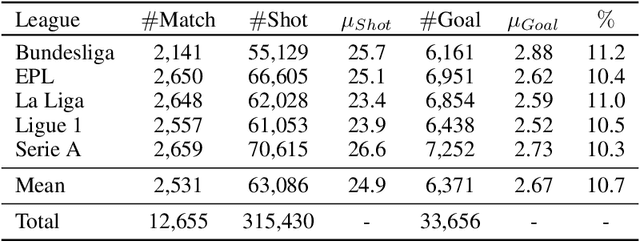
The expected goal provides a more representative measure of the team and player performance which also suit the low-scoring nature of football instead of score in modern football. The score of a match involves randomness and often may not represent the performance of the teams and players, therefore it has been popular to use the alternative statistics in recent years such as shots on target, ball possessions, and drills. To measure the probability of a shot being a goal by the expected goal, several features are used to train an expected goal model which is based on the event and tracking football data. The selection of these features, the size and date of the data, and the model which are used as the parameters that may affect the performance of the model. Using black-box machine learning models for increasing the predictive performance of the model decreases its interpretability that causes the loss of information that can be gathered from the model. This paper proposes an accurate expected goal model trained consisting of 315,430 shots from seven seasons between 2014-15 and 2020-21 of the top-five European football leagues. Moreover, this model is explained by using explainable artificial intelligence tool to obtain an explainable expected goal model for evaluating a team or player performance. To best of our knowledge, this is the first paper that demonstrates a practical application of an explainable artificial intelligence tool aggregated profiles to explain a group of observations on an accurate expected goal model for monitoring the team and player performance. Moreover, these methods can be generalized to other sports branches.