 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Calibrated Bagging Deep Learning for Image Semantic Segmentation: A Case Study on COVID-19 Chest X-ray Image
May 27, 2022
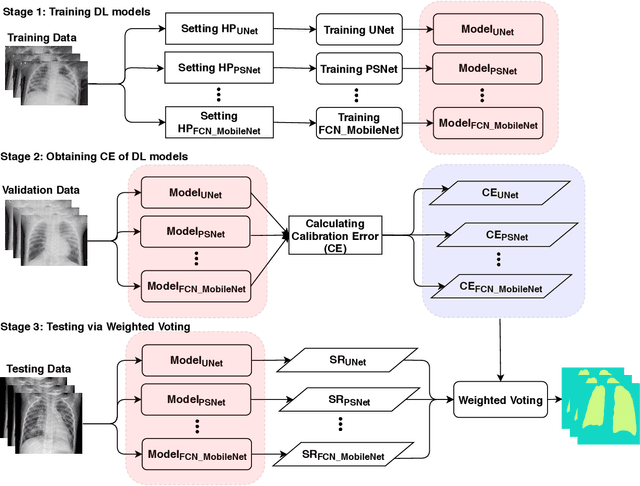
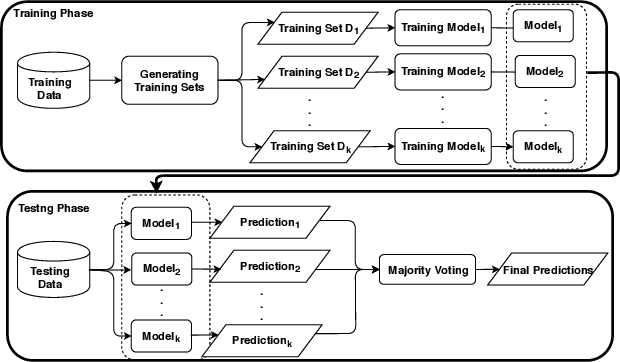
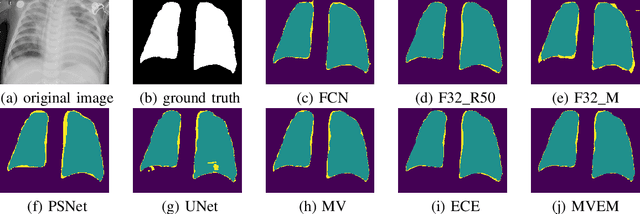
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) causes coronavirus disease 2019 (COVID-19). Imaging tests such as chest X-ray (CXR) and computed tomography (CT) can provide useful information to clinical staff for facilitating a diagnosis of COVID-19 in a more efficient and comprehensive manner. As a breakthrough of artificial intelligence (AI), deep learning has been applied to perform COVID-19 infection region segmentation and disease classification by analyzing CXR and CT data. However, prediction uncertainty of deep learning models for these tasks, which is very important to safety-critical applications like medical image processing, has not been comprehensively investigated. In this work, we propose a novel ensemble deep learning model through integrating bagging deep learning and model calibration to not only enhance segmentation performance, but also reduce prediction uncertainty. The proposed method has been validated on a large dataset that is associated with CXR image segmentation. Experimental results demonstrate that the proposed method can improve the segmentation performance, as well as decrease prediction uncertainties.
Deep Leakage from Model in Federated Learning
Jun 10, 2022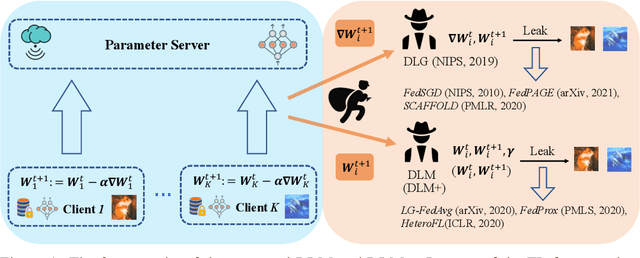
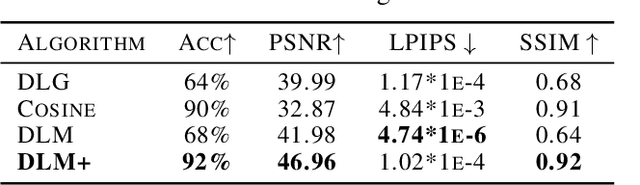

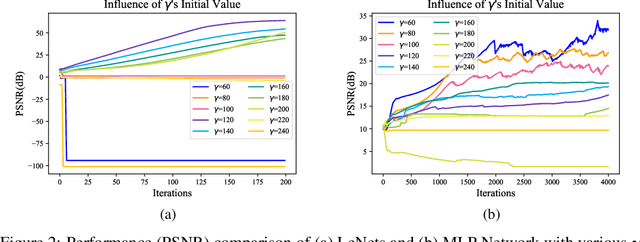
Distributed machine learning has been widely used in recent years to tackle the large and complex dataset problem. Therewith, the security of distributed learning has also drawn increasing attentions from both academia and industry. In this context, federated learning (FL) was developed as a "secure" distributed learning by maintaining private training data locally and only public model gradients are communicated between. However, to date, a variety of gradient leakage attacks have been proposed for this procedure and prove that it is insecure. For instance, a common drawback of these attacks is shared: they require too much auxiliary information such as model weights, optimizers, and some hyperparameters (e.g., learning rate), which are difficult to obtain in real situations. Moreover, many existing algorithms avoid transmitting model gradients in FL and turn to sending model weights, such as FedAvg, but few people consider its security breach. In this paper, we present two novel frameworks to demonstrate that transmitting model weights is also likely to leak private local data of clients, i.e., (DLM and DLM+), under the FL scenario. In addition, a number of experiments are performed to illustrate the effect and generality of our attack frameworks. At the end of this paper, we also introduce two defenses to the proposed attacks and evaluate their protection effects. Comprehensively, the proposed attack and defense schemes can be applied to the general distributed learning scenario as well, just with some appropriate customization.
GAP: A Graph-aware Language Model Framework for Knowledge Graph-to-Text Generation
Apr 13, 2022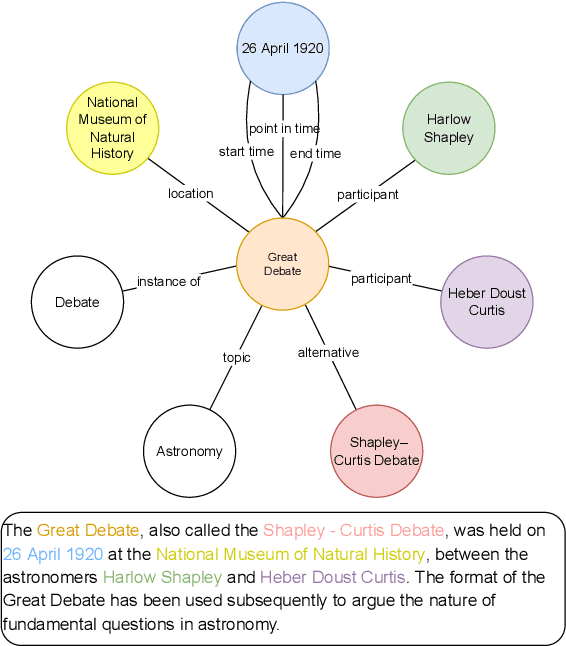

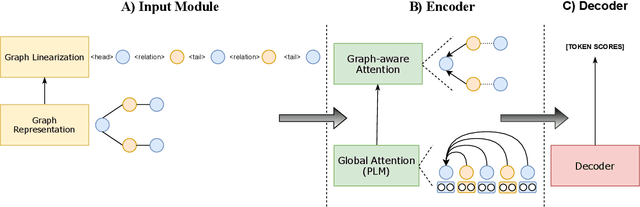
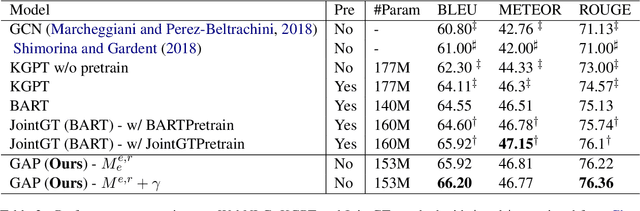
Recent improvements in KG-to-text generation are due to additional auxiliary pre-trained tasks designed to give the fine-tune task a boost in performance. These tasks require extensive computational resources while only suggesting marginal improvements. Here, we demonstrate that by fusing graph-aware elements into existing pre-trained language models, we are able to outperform state-of-the-art models and close the gap imposed by additional pre-train tasks. We do so by proposing a mask structure to capture neighborhood information and a novel type encoder that adds a bias to the graph-attention weights depending on the connection type. Experiments on two KG-to-text benchmark datasets show these models to be superior in quality while involving fewer parameters and no additional pre-trained tasks. By formulating the problem as a framework, we can interchange the various proposed components and begin interpreting KG-to-text generative models based on the topological and type information found in a graph.
Fine-Grained Counting with Crowd-Sourced Supervision
May 23, 2022
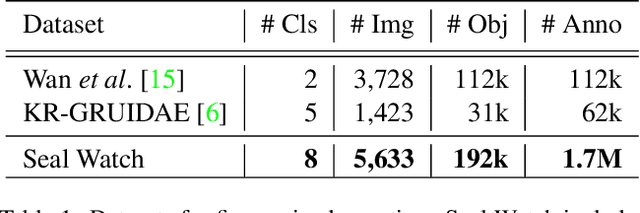

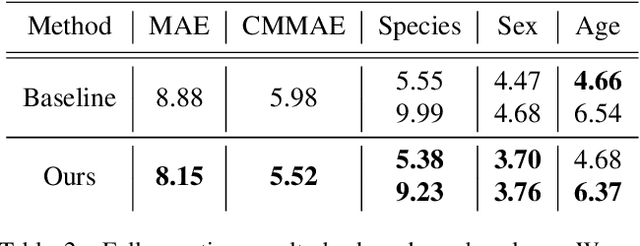
Crowd-sourcing is an increasingly popular tool for image analysis in animal ecology. Computer vision methods that can utilize crowd-sourced annotations can help scale up analysis further. In this work we study the potential to do so on the challenging task of fine-grained counting. As opposed to the standard crowd counting task, fine-grained counting also involves classifying attributes of individuals in dense crowds. We introduce a new dataset from animal ecology to enable this study that contains 1.7M crowd-sourced annotations of 8 fine-grained classes. It is the largest available dataset for fine-grained counting and the first to enable the study of the task with crowd-sourced annotations. We introduce methods for generating aggregate "ground truths" from the collected annotations, as well as a counting method that can utilize the aggregate information. Our method improves results by 8% over a comparable baseline, indicating the potential for algorithms to learn fine-grained counting using crowd-sourced supervision.
Transformers for Multi-Object Tracking on Point Clouds
May 31, 2022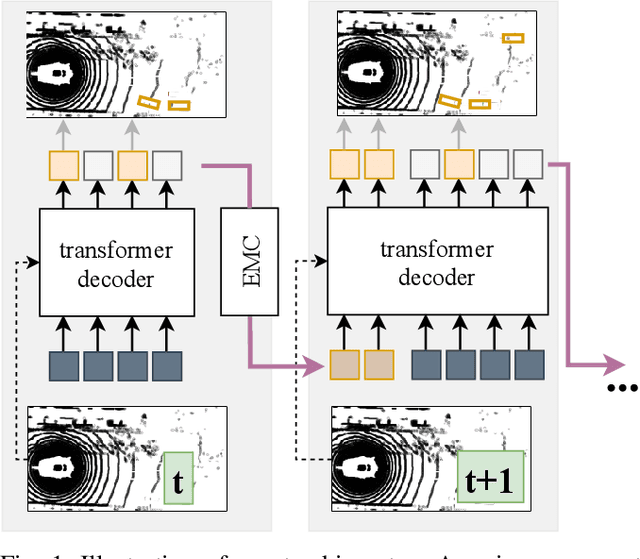
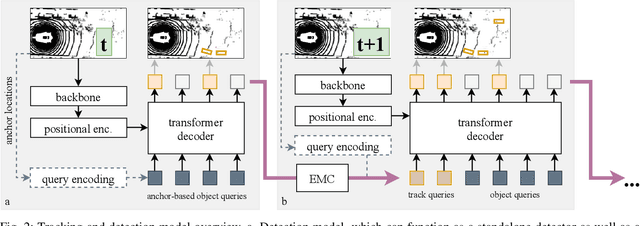
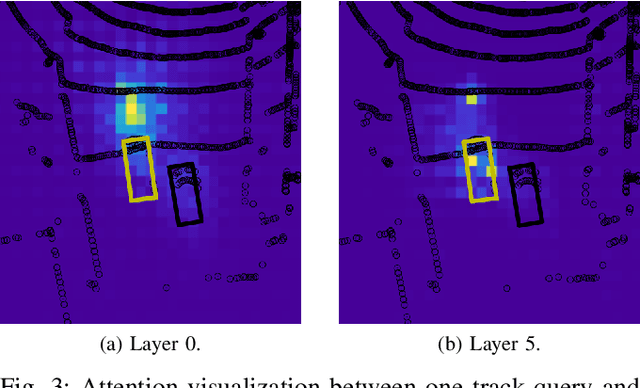
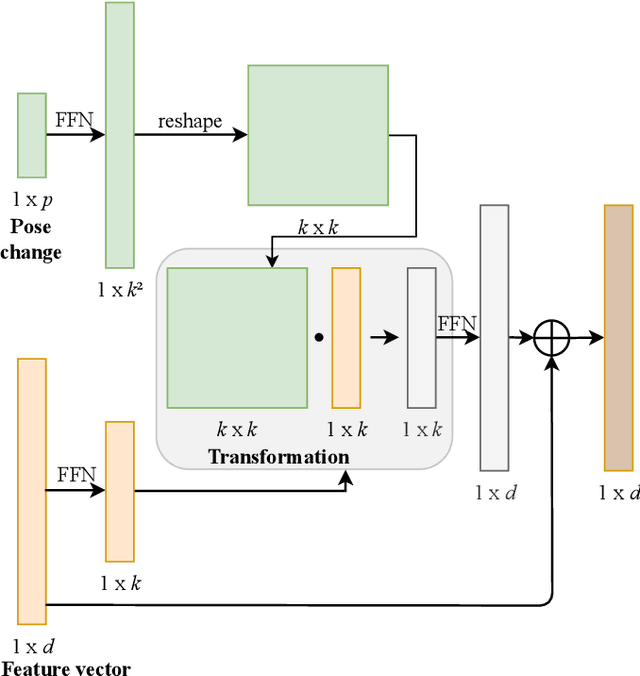
We present TransMOT, a novel transformer-based end-to-end trainable online tracker and detector for point cloud data. The model utilizes a cross- and a self-attention mechanism and is applicable to lidar data in an automotive context, as well as other data types, such as radar. Both track management and the detection of new tracks are performed by the same transformer decoder module and the tracker state is encoded in feature space. With this approach, we make use of the rich latent space of the detector for tracking rather than relying on low-dimensional bounding boxes. Still, we are able to retain some of the desirable properties of traditional Kalman-filter based approaches, such as an ability to handle sensor input at arbitrary timesteps or to compensate frame skips. This is possible due to a novel module that transforms the track information from one frame to the next on feature-level and thereby fulfills a similar task as the prediction step of a Kalman filter. Results are presented on the challenging real-world dataset nuScenes, where the proposed model outperforms its Kalman filter-based tracking baseline.
Contrastive Supervised Distillation for Continual Representation Learning
May 11, 2022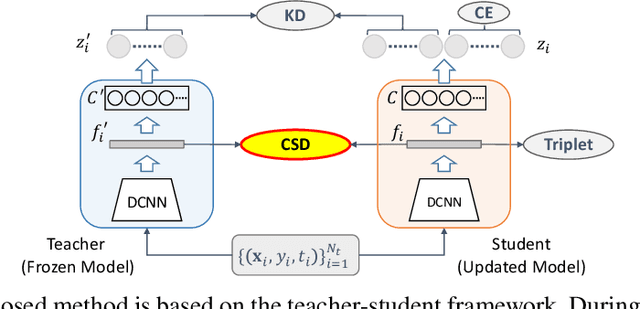
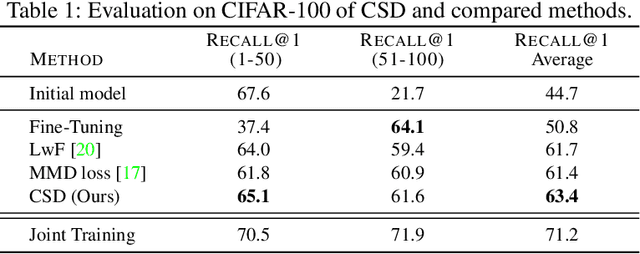
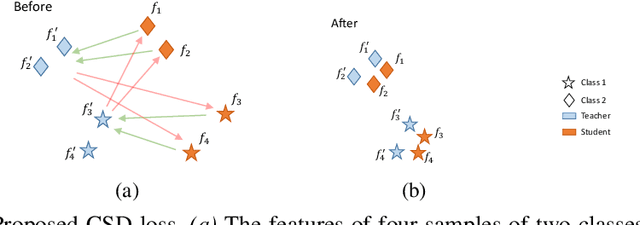
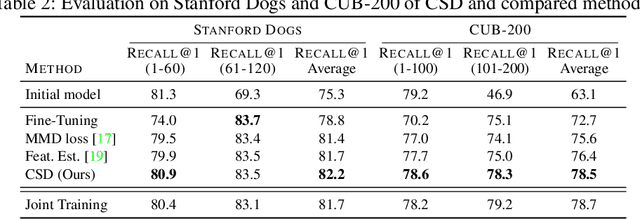
In this paper, we propose a novel training procedure for the continual representation learning problem in which a neural network model is sequentially learned to alleviate catastrophic forgetting in visual search tasks. Our method, called Contrastive Supervised Distillation (CSD), reduces feature forgetting while learning discriminative features. This is achieved by leveraging labels information in a distillation setting in which the student model is contrastively learned from the teacher model. Extensive experiments show that CSD performs favorably in mitigating catastrophic forgetting by outperforming current state-of-the-art methods. Our results also provide further evidence that feature forgetting evaluated in visual retrieval tasks is not as catastrophic as in classification tasks. Code at: https://github.com/NiccoBiondi/ContrastiveSupervisedDistillation.
* Paper published as Oral at ICIAP21
CATNet: Cross-event Attention-based Time-aware Network for Medical Event Prediction
Apr 29, 2022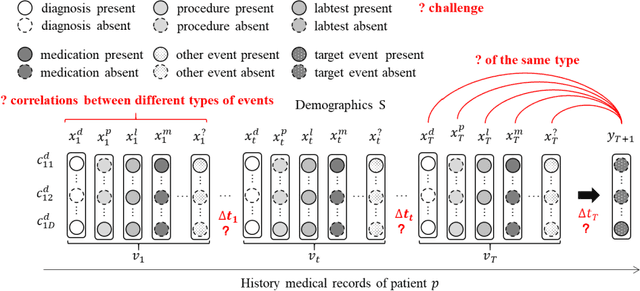

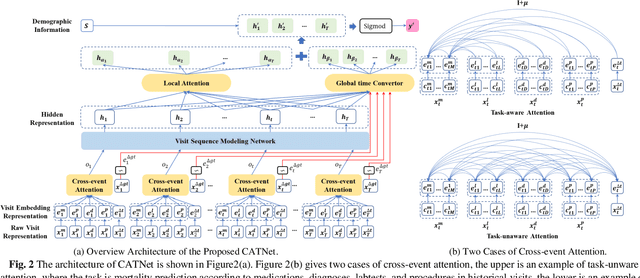
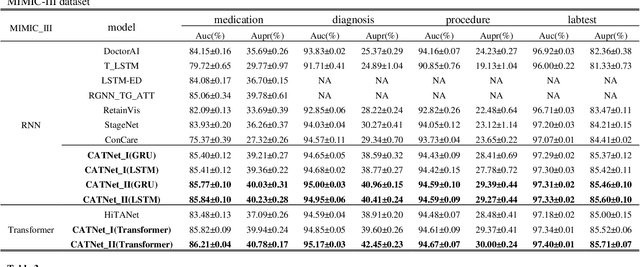
Medical event prediction (MEP) is a fundamental task in the medical domain, which needs to predict medical events, including medications, diagnosis codes, laboratory tests, procedures, outcomes, and so on, according to historical medical records. The task is challenging as medical data is a type of complex time series data with heterogeneous and temporal irregular characteristics. Many machine learning methods that consider the two characteristics have been proposed for medical event prediction. However, most of them consider the two characteristics separately and ignore the correlations among different types of medical events, especially relations between historical medical events and target medical events. In this paper, we propose a novel neural network based on attention mechanism, called cross-event attention-based time-aware network (CATNet), for medical event prediction. It is a time-aware, event-aware and task-adaptive method with the following advantages: 1) modeling heterogeneous information and temporal information in a unified way and considering temporal irregular characteristics locally and globally respectively, 2) taking full advantage of correlations among different types of events via cross-event attention. Experiments on two public datasets (MIMIC-III and eICU) show CATNet can be adaptive with different MEP tasks and outperforms other state-of-the-art methods on various MEP tasks. The source code of CATNet will be released after this manuscript is accepted.
Automated Imbalanced Classification via Layered Learning
May 05, 2022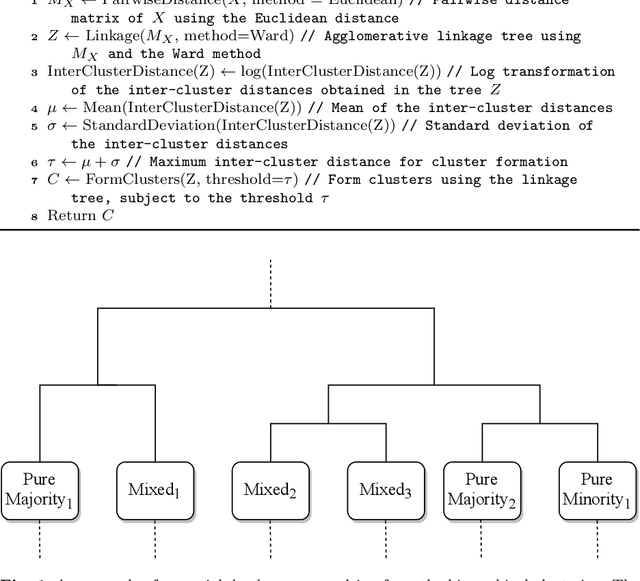
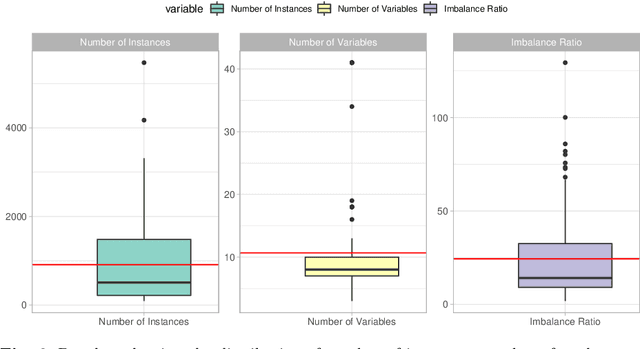
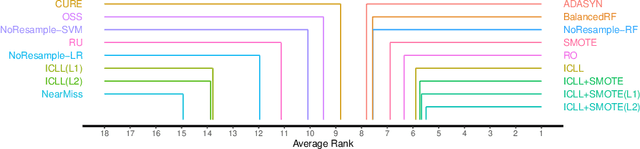
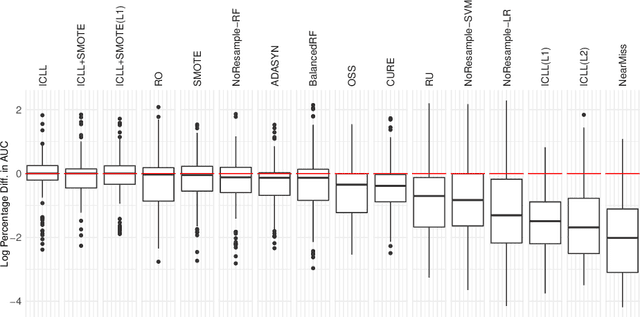
In this paper we address imbalanced binary classification (IBC) tasks. Applying resampling strategies to balance the class distribution of training instances is a common approach to tackle these problems. Many state-of-the-art methods find instances of interest close to the decision boundary to drive the resampling process. However, under-sampling the majority class may potentially lead to important information loss. Over-sampling also may increase the chance of overfitting by propagating the information contained in instances from the minority class. The main contribution of our work is a new method called ICLL for tackling IBC tasks which is not based on resampling training observations. Instead, ICLL follows a layered learning paradigm to model the data in two stages. In the first layer, ICLL learns to distinguish cases close to the decision boundary from cases which are clearly from the majority class, where this dichotomy is defined using a hierarchical clustering analysis. In the subsequent layer, we use instances close to the decision boundary and instances from the minority class to solve the original predictive task. A second contribution of our work is the automatic definition of the layers which comprise the layered learning strategy using a hierarchical clustering model. This is a relevant discovery as this process is usually performed manually according to domain knowledge. We carried out extensive experiments using 100 benchmark data sets. The results show that the proposed method leads to a better performance relatively to several state-of-the-art methods for IBC.
Dual Convexified Convolutional Neural Networks
May 27, 2022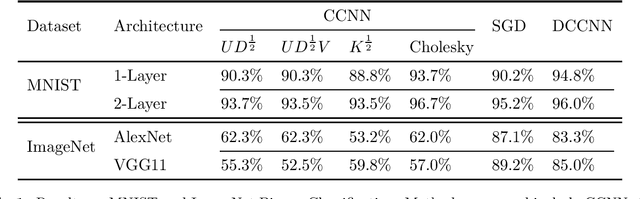
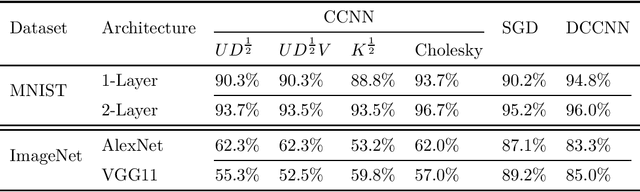
We propose the framework of dual convexified convolutional neural networks (DCCNNs). In this framework, we first introduce a primal learning problem motivated from convexified convolutional neural networks (CCNNs), and then construct the dual convex training program through careful analysis of the Karush-Kuhn-Tucker (KKT) conditions and Fenchel conjugates. Our approach reduces the memory overhead of constructing a large kernel matrix and eliminates the ambiguity of factorizing the matrix. Due to the low-rank structure in CCNNs and the related subdifferential of nuclear norms, there is no closed-form expression to recover the primal solution from the dual solution. To overcome this, we propose a highly novel weight recovery algorithm, which takes the dual solution and the kernel information as the input, and recovers the linear and convolutional weights of a CCNN. Furthermore, our recovery algorithm exploits the low-rank structure and imposes a small number of filters indirectly, which reduces the parameter size. As a result, DCCNNs inherit all the statistical benefits of CCNNs, while enjoying a more formal and efficient workflow.
Benign Overparameterization in Membership Inference with Early Stopping
May 27, 2022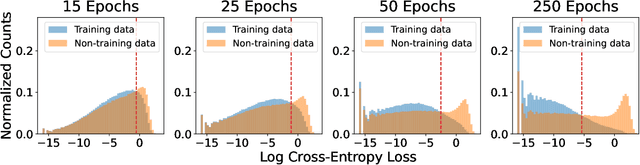
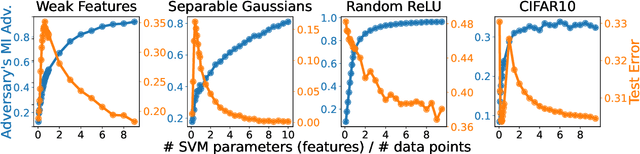
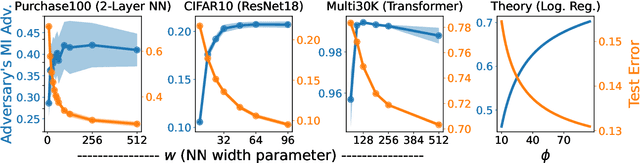
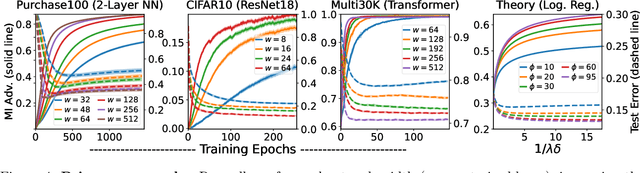
Does a neural network's privacy have to be at odds with its accuracy? In this work, we study the effects the number of training epochs and parameters have on a neural network's vulnerability to membership inference (MI) attacks, which aim to extract potentially private information about the training data. We first demonstrate how the number of training epochs and parameters individually induce a privacy-utility trade-off: more of either improves generalization performance at the expense of lower privacy. However, remarkably, we also show that jointly tuning both can eliminate this privacy-utility trade-off. Specifically, with careful tuning of the number of training epochs, more overparameterization can increase model privacy for fixed generalization error. To better understand these phenomena theoretically, we develop a powerful new leave-one-out analysis tool to study the asymptotic behavior of linear classifiers and apply it to characterize the sample-specific loss threshold MI attack in high-dimensional logistic regression. For practitioners, we introduce a low-overhead procedure to estimate MI risk and tune the number of training epochs to guard against MI attacks.