 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DouZero+: Improving DouDizhu AI by Opponent Modeling and Coach-guided Learning
Apr 06, 2022




Recent years have witnessed the great breakthrough of deep reinforcement learning (DRL) in various perfect and imperfect information games. Among these games, DouDizhu, a popular card game in China, is very challenging due to the imperfect information, large state space, elements of collaboration and a massive number of possible moves from turn to turn. Recently, a DouDizhu AI system called DouZero has been proposed. Trained using traditional Monte Carlo method with deep neural networks and self-play procedure without the abstraction of human prior knowledge, DouZero has outperformed all the existing DouDizhu AI programs. In this work, we propose to enhance DouZero by introducing opponent modeling into DouZero. Besides, we propose a novel coach network to further boost the performance of DouZero and accelerate its training process. With the integration of the above two techniques into DouZero, our DouDizhu AI system achieves better performance and ranks top in the Botzone leaderboard among more than 400 AI agents, including DouZero.
Autoregressive Linguistic Steganography Based on BERT and Consistency Coding
Mar 26, 2022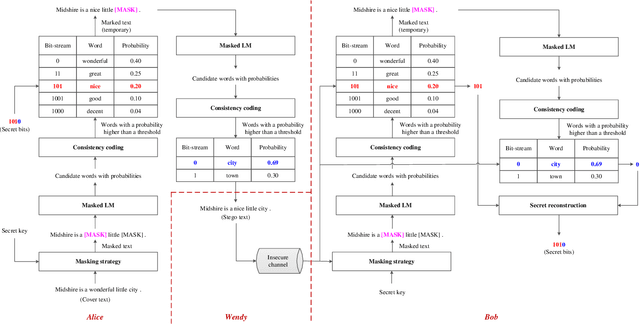



Linguistic steganography (LS) conceals the presence of communication by embedding secret information into a text. How to generate a high-quality text carrying secret information is a key problem. With the widespread application of deep learning in natural language processing, recent algorithms use a language model (LM) to generate the steganographic text, which provides a higher payload compared with many previous arts. However, the security still needs to be enhanced. To tackle with this problem, we propose a novel autoregressive LS algorithm based on BERT and consistency coding, which achieves a better trade-off between embedding payload and system security. In the proposed work, based on the introduction of the masked LM, given a text, we use consistency coding to make up for the shortcomings of block coding used in the previous work so that we can encode arbitrary-size candidate token set and take advantages of the probability distribution for information hiding. The masked positions to be embedded are filled with tokens determined by an autoregressive manner to enhance the connection between contexts and therefore maintain the quality of the text. Experimental results have shown that, compared with related works, the proposed work improves the fluency of the steganographic text while guaranteeing security, and also increases the embedding payload to a certain extent.
On Releasing Annotator-Level Labels and Information in Datasets
Oct 12, 2021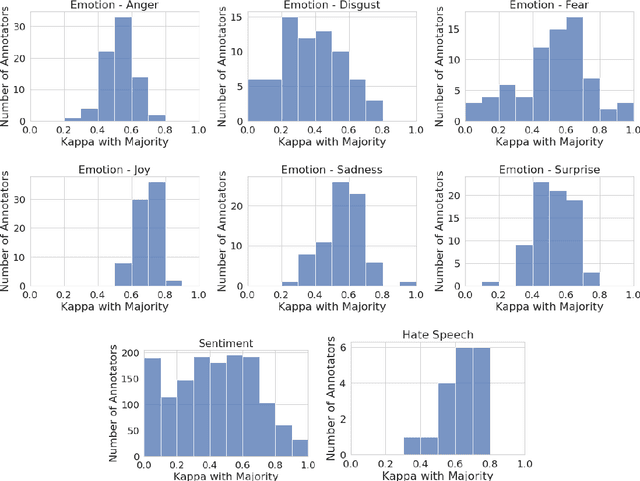
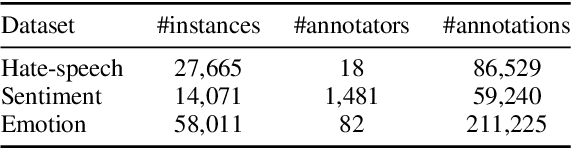

A common practice in building NLP datasets, especially using crowd-sourced annotations, involves obtaining multiple annotator judgements on the same data instances, which are then flattened to produce a single "ground truth" label or score, through majority voting, averaging, or adjudication. While these approaches may be appropriate in certain annotation tasks, such aggregations overlook the socially constructed nature of human perceptions that annotations for relatively more subjective tasks are meant to capture. In particular, systematic disagreements between annotators owing to their socio-cultural backgrounds and/or lived experiences are often obfuscated through such aggregations. In this paper, we empirically demonstrate that label aggregation may introduce representational biases of individual and group perspectives. Based on this finding, we propose a set of recommendations for increased utility and transparency of datasets for downstream use cases.
GAN-based Medical Image Small Region Forgery Detection via a Two-Stage Cascade Framework
May 30, 2022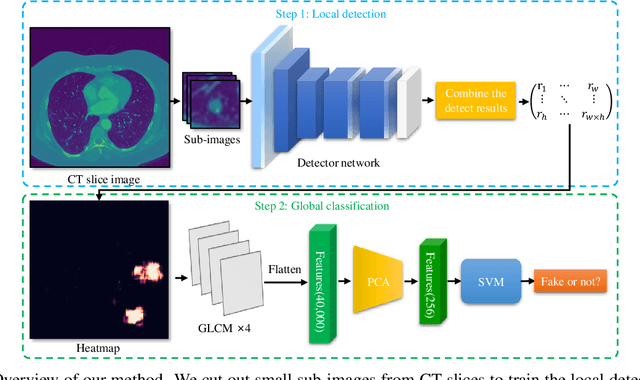
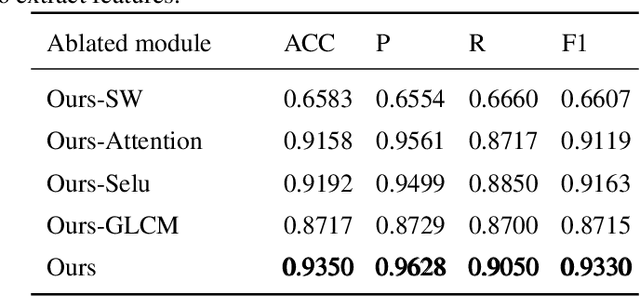
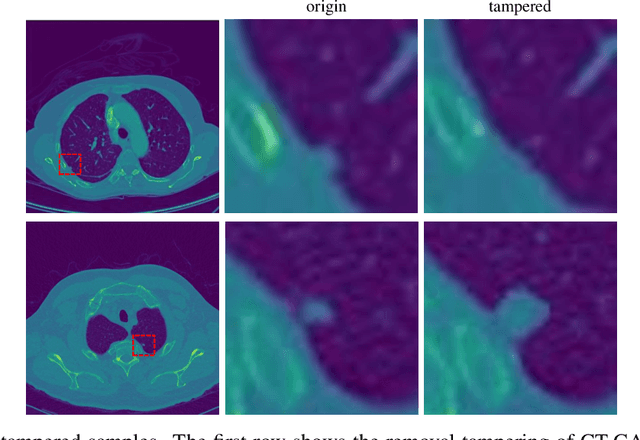
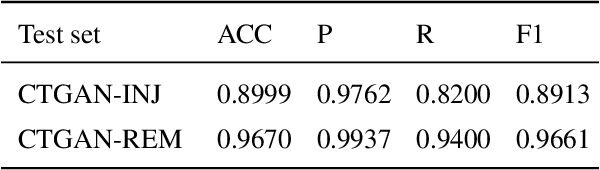
Using generative adversarial network (GAN)\cite{RN90} for data enhancement of medical images is significantly helpful for many computer-aided diagnosis (CAD) tasks. A new attack called CT-GAN has emerged. It can inject or remove lung cancer lesions to CT scans. Because the tampering region may even account for less than 1\% of the original image, even state-of-the-art methods are challenging to detect the traces of such tampering. This paper proposes a cascade framework to detect GAN-based medical image small region forgery like CT-GAN. In the local detection stage, we train the detector network with small sub-images so that interference information in authentic regions will not affect the detector. We use depthwise separable convolution and residual to prevent the detector from over-fitting and enhance the ability to find forged regions through the attention mechanism. The detection results of all sub-images in the same image will be combined into a heatmap. In the global classification stage, using gray level co-occurrence matrix (GLCM) can better extract features of the heatmap. Because the shape and size of the tampered area are uncertain, we train PCA and SVM methods for classification. Our method can classify whether a CT image has been tampered and locate the tampered position. Sufficient experiments show that our method can achieve excellent performance.
Information-Theoretic Generalization Bounds for Stochastic Gradient Descent
Feb 01, 2021We study the generalization properties of the popular stochastic gradient descent method for optimizing general non-convex loss functions. Our main contribution is providing upper bounds on the generalization error that depend on local statistics of the stochastic gradients evaluated along the path of iterates calculated by SGD. The key factors our bounds depend on are the variance of the gradients (with respect to the data distribution) and the local smoothness of the objective function along the SGD path, and the sensitivity of the loss function to perturbations to the final output. Our key technical tool is combining the information-theoretic generalization bounds previously used for analyzing randomized variants of SGD with a perturbation analysis of the iterates.
Predicting Vehicles Trajectories in Urban Scenarios with Transformer Networks and Augmented Information
Jun 01, 2021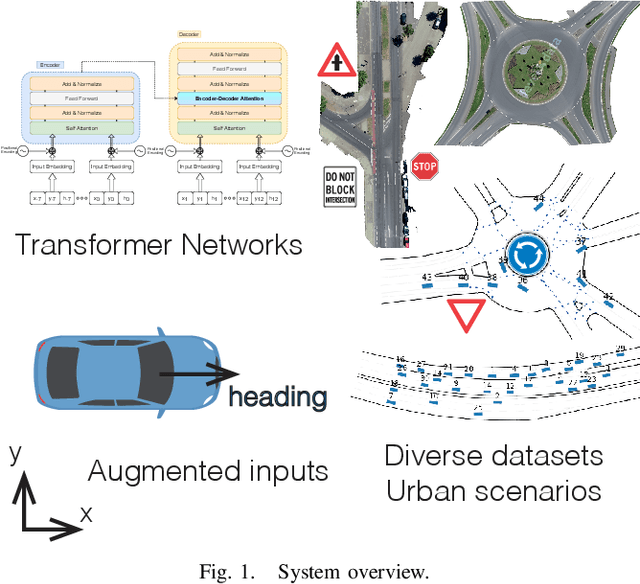
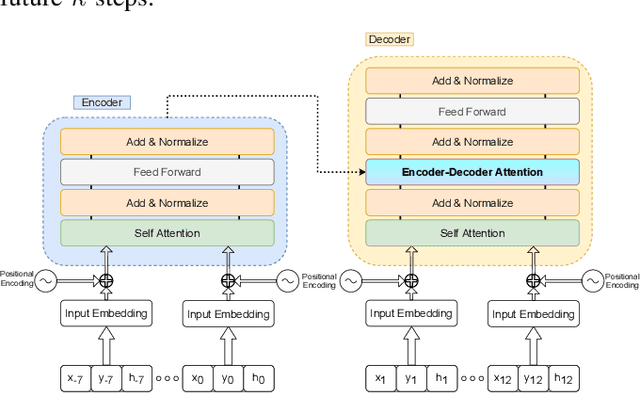
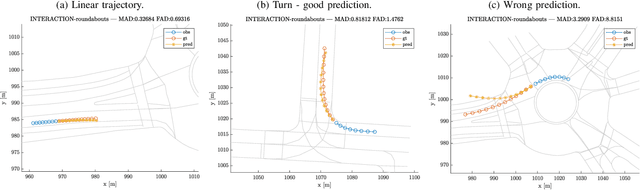
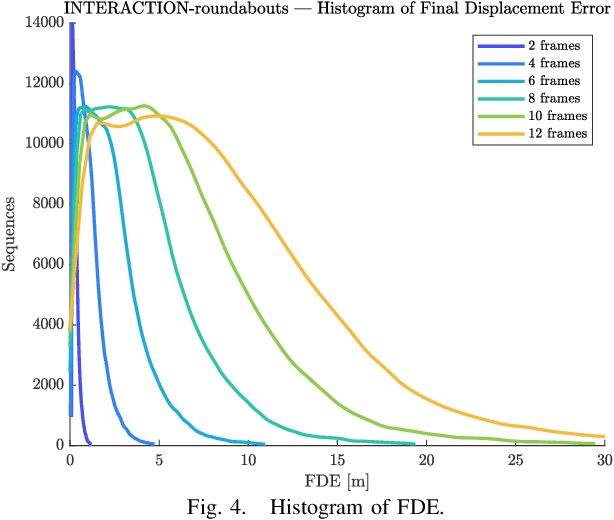
Understanding the behavior of road users is of vital importance for the development of trajectory prediction systems. In this context, the latest advances have focused on recurrent structures, establishing the social interaction between the agents involved in the scene. More recently, simpler structures have also been introduced for predicting pedestrian trajectories, based on Transformer Networks, and using positional information. They allow the individual modelling of each agent's trajectory separately without any complex interaction terms. Our model exploits these simple structures by adding augmented data (position and heading), and adapting their use to the problem of vehicle trajectory prediction in urban scenarios in prediction horizons up to 5 seconds. In addition, a cross-performance analysis is performed between different types of scenarios, including highways, intersections and roundabouts, using recent datasets (inD, rounD, highD and INTERACTION). Our model achieves state-of-the-art results and proves to be flexible and adaptable to different types of urban contexts.
Textural-Structural Joint Learning for No-Reference Super-Resolution Image Quality Assessment
May 27, 2022
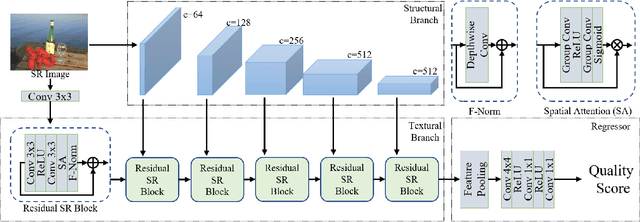
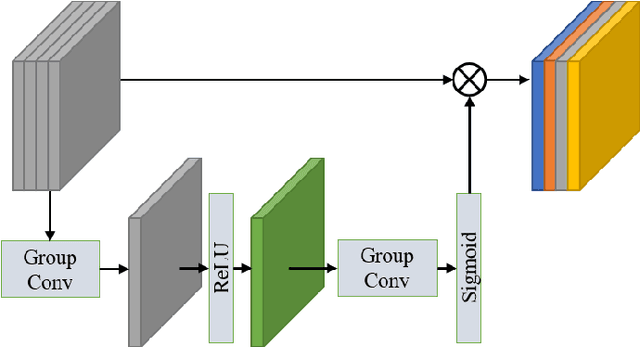

Image super-resolution (SR) has been widely investigated in recent years. However, it is challenging to fairly estimate the performances of various SR methods, as the lack of reliable and accurate criteria for perceptual quality. Existing SR image quality assessment (IQA) metrics usually concentrate on the specific kind of degradation without distinguishing the visual sensitive areas, which have no adaptive ability to describe the diverse SR degeneration situations. In this paper, we focus on the textural and structural degradation of image SR which acts as a critical role for visual perception, and design a dual stream network to jointly explore the textural and structural information for quality prediction, dubbed TSNet. By mimicking the human vision system (HVS) that pays more attention to the significant areas of the image, we develop the spatial attention mechanism to make the visual-sensitive areas more distinguishable, which improves the prediction accuracy. Feature normalization (F-Norm) is also developed to investigate the inherent spatial correlation of SR features and boost the network representation capacity. Experimental results show the proposed TSNet predicts the visual quality more accurate than the state-of-the-art IQA methods, and demonstrates better consistency with the human's perspective. The source code will be made available at http://github.com/yuqing-liu-dut/NRIQA_SR.
Recurrent Encoder-Decoder Networks for Vessel Trajectory Prediction with Uncertainty Estimation
May 11, 2022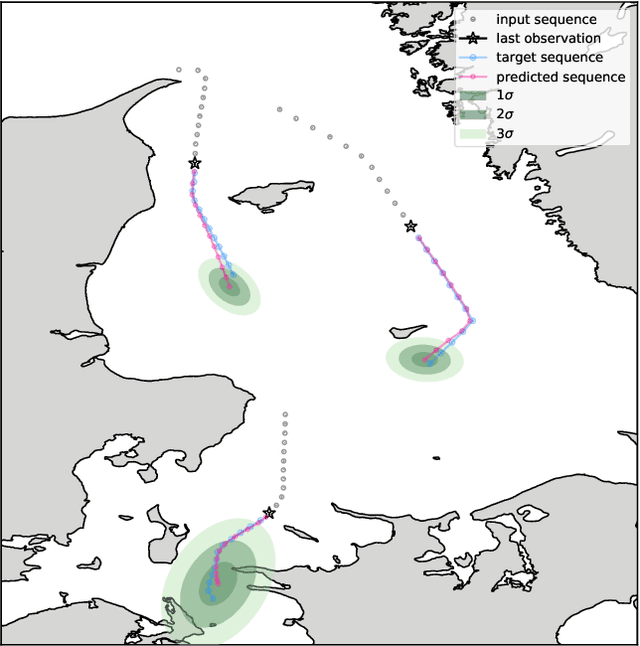
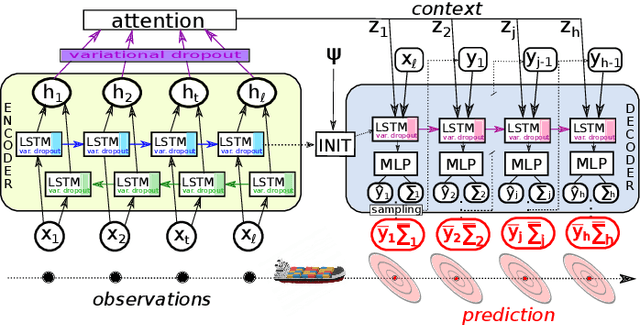
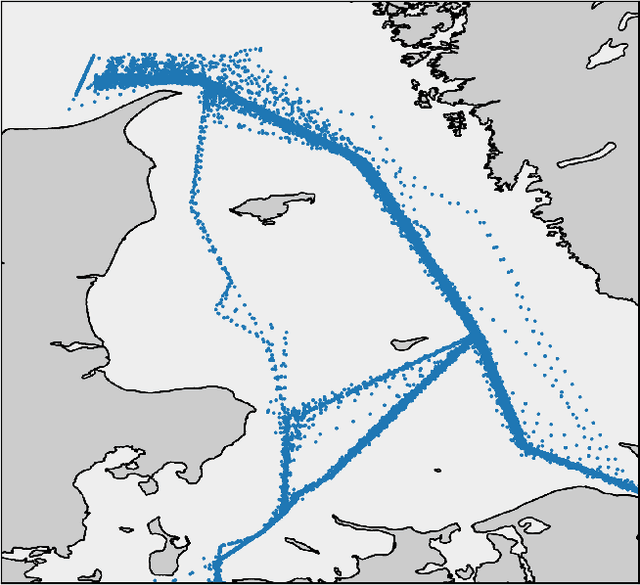
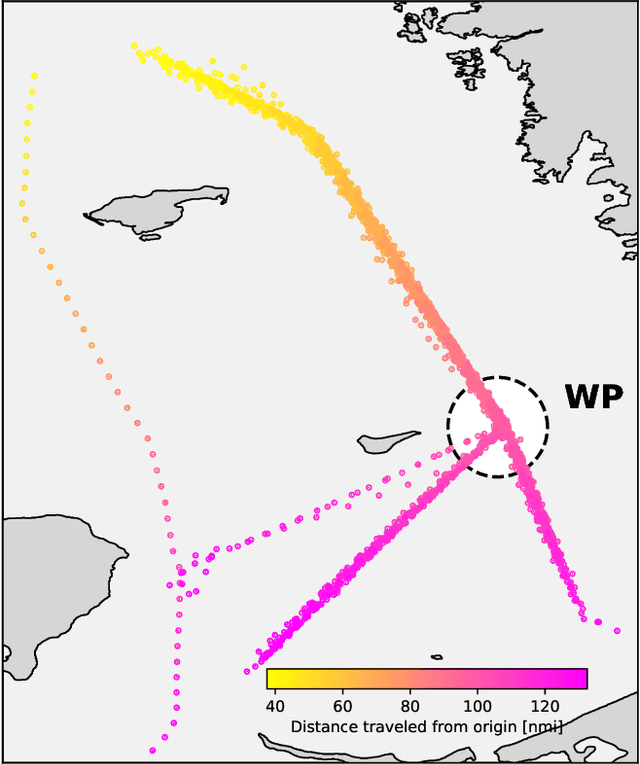
Recent deep learning methods for vessel trajectory prediction are able to learn complex maritime patterns from historical Automatic Identification System (AIS) data and accurately predict sequences of future vessel positions with a prediction horizon of several hours. However, in maritime surveillance applications, reliably quantifying the prediction uncertainty can be as important as obtaining high accuracy. This paper extends deep learning frameworks for trajectory prediction tasks by exploring how recurrent encoder-decoder neural networks can be tasked not only to predict but also to yield a corresponding prediction uncertainty via Bayesian modeling of epistemic and aleatoric uncertainties. We compare the prediction performance of two different models based on labeled or unlabeled input data to highlight how uncertainty quantification and accuracy can be improved by using, if available, additional information on the intention of the ship (e.g., its planned destination).
CGMN: A Contrastive Graph Matching Network for Self-Supervised Graph Similarity Learning
May 30, 2022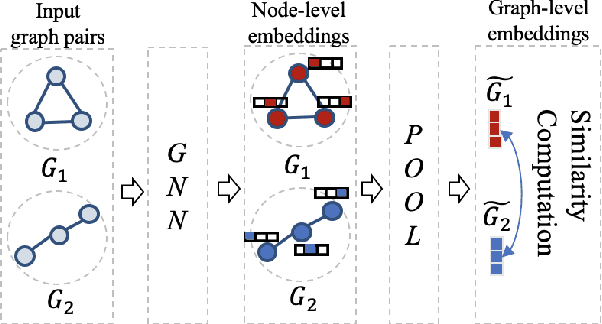
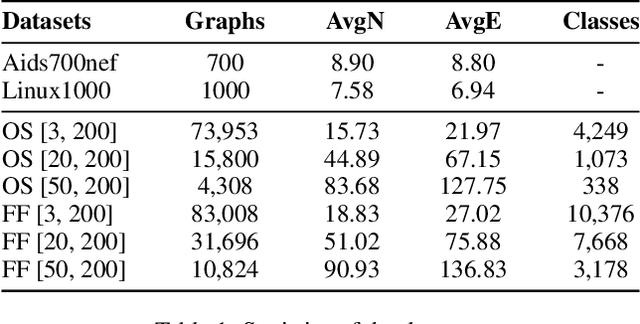
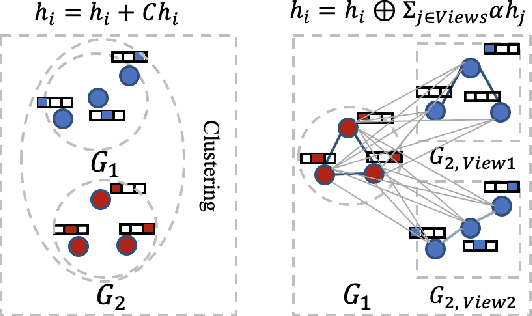
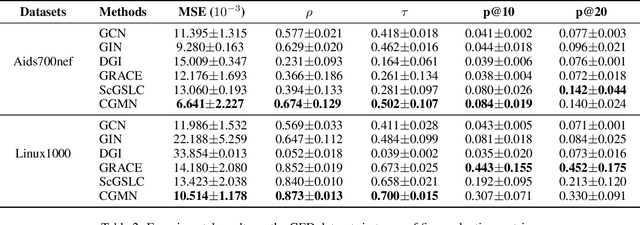
Graph similarity learning refers to calculating the similarity score between two graphs, which is required in many realistic applications, such as visual tracking, graph classification, and collaborative filtering. As most of the existing graph neural networks yield effective graph representations of a single graph, little effort has been made for jointly learning two graph representations and calculating their similarity score. In addition, existing unsupervised graph similarity learning methods are mainly clustering-based, which ignores the valuable information embodied in graph pairs. To this end, we propose a contrastive graph matching network (CGMN) for self-supervised graph similarity learning in order to calculate the similarity between any two input graph objects. Specifically, we generate two augmented views for each graph in a pair respectively. Then, we employ two strategies, namely cross-view interaction and cross-graph interaction, for effective node representation learning. The former is resorted to strengthen the consistency of node representations in two views. The latter is utilized to identify node differences between different graphs. Finally, we transform node representations into graph-level representations via pooling operations for graph similarity computation. We have evaluated CGMN on eight real-world datasets, and the experiment results show that the proposed new approach is superior to the state-of-the-art methods in graph similarity learning downstream tasks.
Improving Monaural Speech Enhancement with Multi-head Self and Cross Attention
May 20, 2022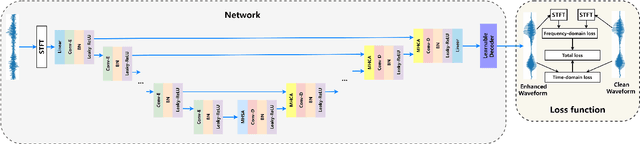
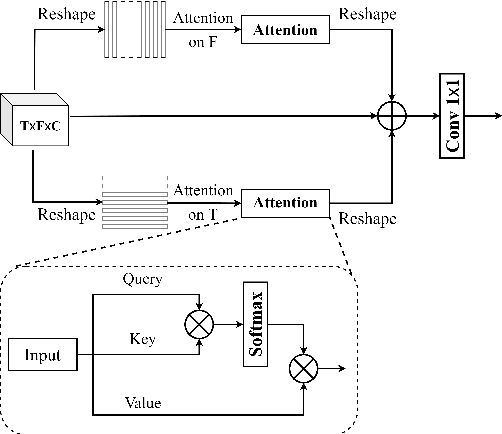
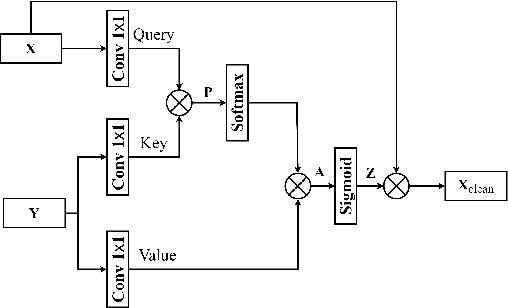
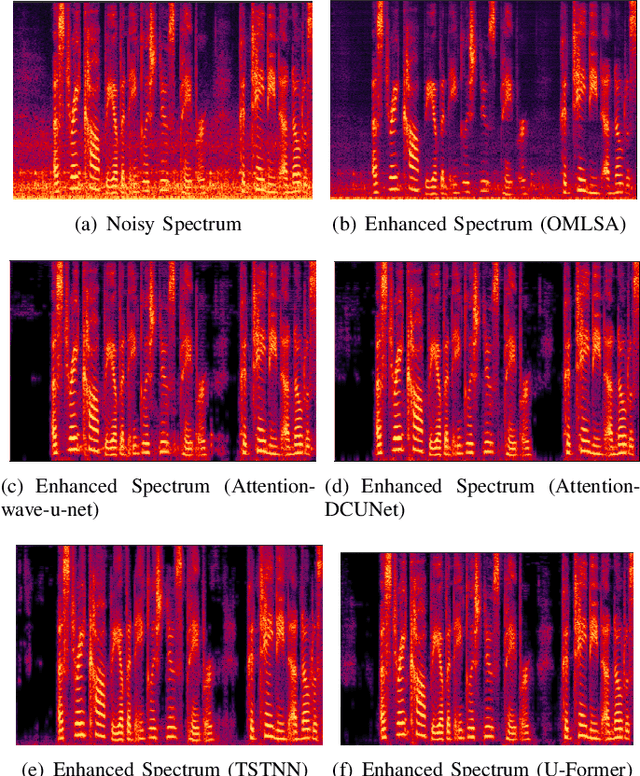
For supervised speech enhancement, contextual information is important for accurate spectral mapping. However, commonly used deep neural networks (DNNs) are limited in capturing temporal contexts. To leverage long-term contexts for tracking a target speaker, this paper treats the speech enhancement as sequence-to-sequence mapping, and propose a novel monaural speech enhancement U-net structure based on Transformer, dubbed U-Former. The key idea is to model long-term correlations and dependencies, which are crucial for accurate noisy speech modeling, through the multi-head attention mechanisms. For this purpose, U-Former incorporates multi-head attention mechanisms at two levels: 1) a multi-head self-attention module which calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps for leveraging global interactions between encoder features, while 2) multi-head cross-attention module which are inserted in the skip connections allows a fine recovery in the decoder by filtering out uncorrelated features. Experimental results illustrate that the U-Former obtains consistently better performance than recent models of PESQ, STOI, and SSNR scores.