 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Few-Shot Learning Algorithm for Rare Sound Event Detection
May 24, 2022
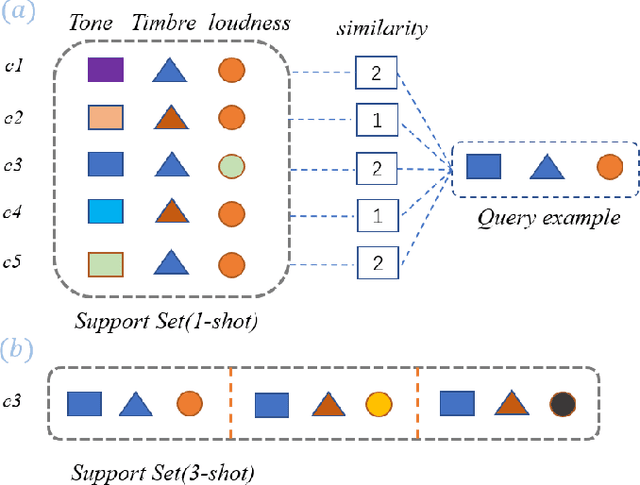
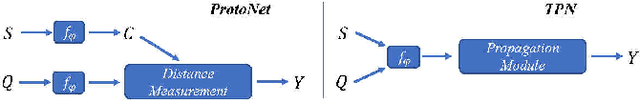
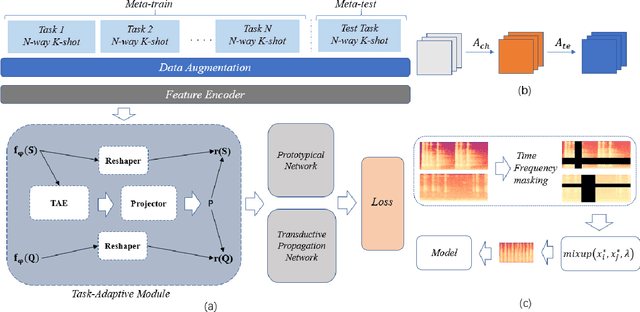
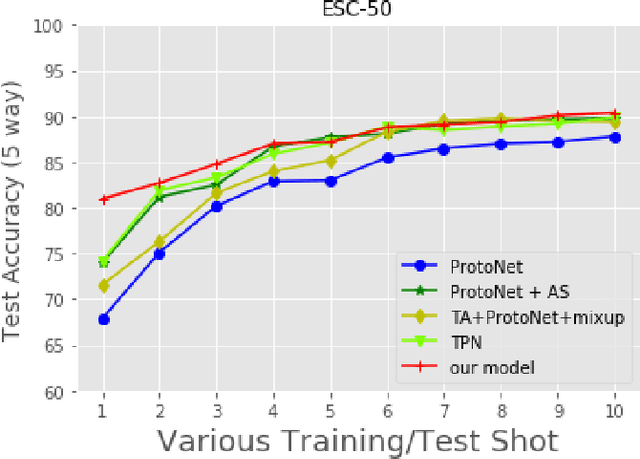
Sound event detection is to infer the event by understanding the surrounding environmental sounds. Due to the scarcity of rare sound events, it becomes challenging for the well-trained detectors which have learned too much prior knowledge. Meanwhile, few-shot learning methods promise a good generalization ability when facing a new limited-data task. Recent approaches have achieved promising results in this field. However, these approaches treat each support example independently, ignoring the information of other examples from the whole task. Because of this, most of previous methods are constrained to generate a same feature embedding for all test-time tasks, which is not adaptive to each inputted data. In this work, we propose a novel task-adaptive module which is easy to plant into any metric-based few-shot learning frameworks. The module could identify the task-relevant feature dimension. Incorporating our module improves the performance considerably on two datasets over baseline methods, especially for the transductive propagation network. Such as +6.8% for 5-way 1-shot accuracy on ESC-50, and +5.9% on noiseESC-50. We investigate our approach in the domain-mismatch setting and also achieve better results than previous methods.
From Easy to Hard: Two-stage Selector and Reader for Multi-hop Question Answering
May 24, 2022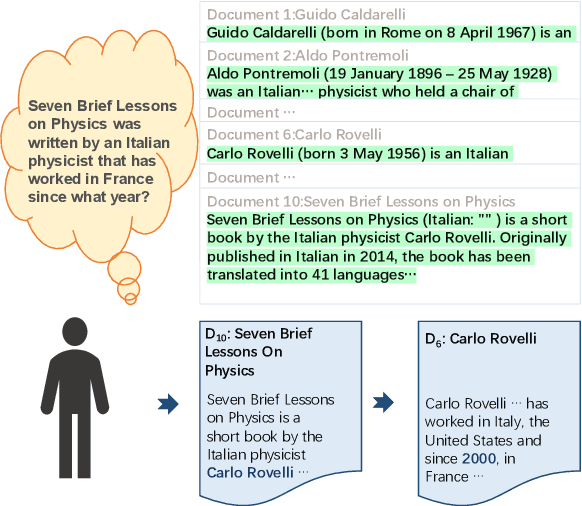
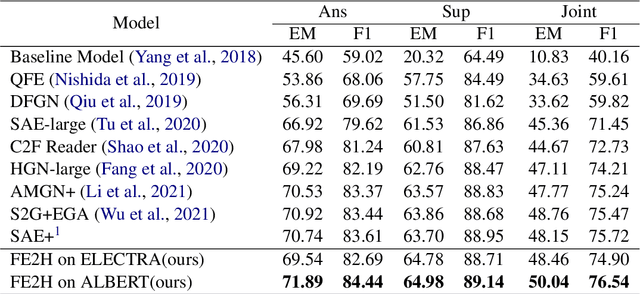
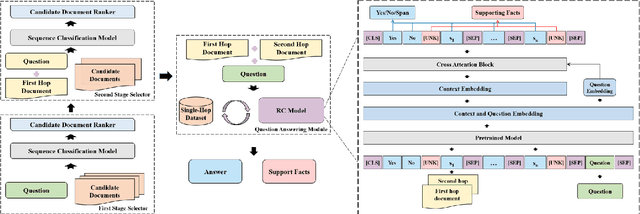
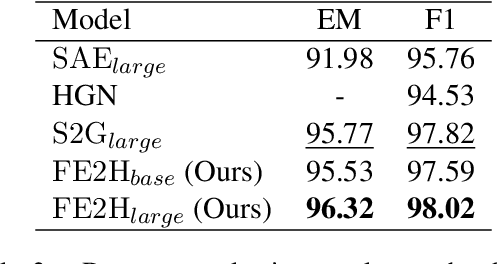
Multi-hop question answering (QA) is a challenging task requiring QA systems to perform complex reasoning over multiple documents and provide supporting facts together with the exact answer. Existing works tend to utilize graph-based reasoning and question decomposition to obtain the reasoning chain, which inevitably introduces additional complexity and cumulative error to the system. To address the above issue, we propose a simple yet effective novel framework, From Easy to Hard (FE2H), to remove distracting information and obtain better contextual representations for the multi-hop QA task. Inspired by the iterative document selection process and the progressive learning custom of humans, FE2H divides both the document selector and reader into two stages following an easy-to-hard manner. Specifically, we first select the document most relevant to the question and then utilize the question together with this document to select other pertinent documents. As for the QA phase, our reader is first trained on a single-hop QA dataset and then transferred into the multi-hop QA task. We comprehensively evaluate our model on the popular multi-hop QA benchmark HotpotQA. Experimental results demonstrate that our method ourperforms all other methods in the leaderboard of HotpotQA (distractor setting).
An Enactivist-Inspired Mathematical Model of Cognition
Jun 10, 2022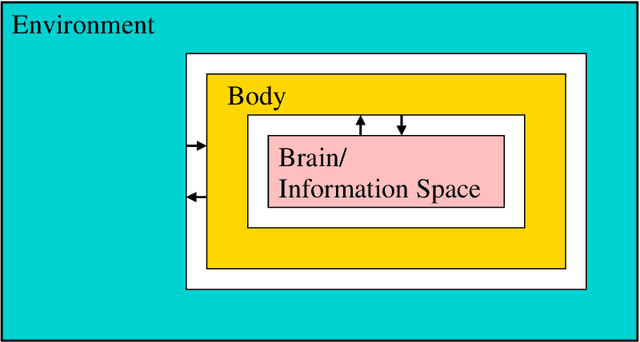
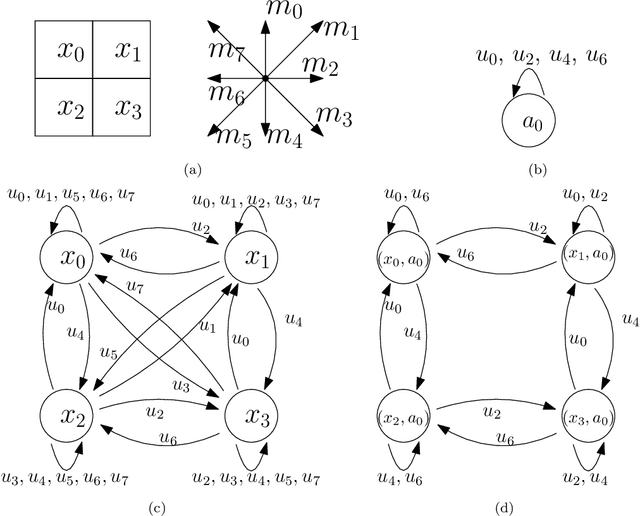
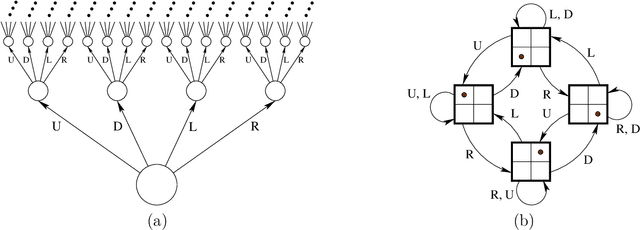
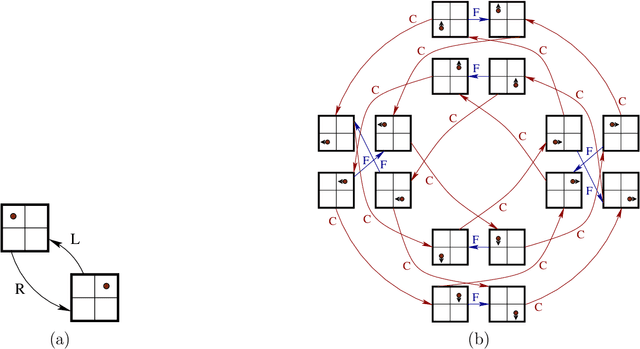
We formulate five basic tenets of enactivist cognitive science that we have carefully identified in the relevant literature as the main underlying principles of that philosophy. We then develop a mathematical framework to talk about cognitive systems (both artificial and natural) which complies with these enactivist tenets. In particular we pay attention that our mathematical modeling does not attribute contentful symbolic representations to the agents, and that the agent's brain, body and environment are modeled in a way that makes them an inseparable part of a greater totality. The purpose is to create a mathematical foundation for cognition which is in line with enactivism. We see two main benefits of doing so: (1) It enables enactivist ideas to be more accessible for computer scientists, AI researchers, roboticists, cognitive scientists, and psychologists, and (2) it gives the philosophers a mathematical tool which can be used to clarify their notions and help with their debates. Our main notion is that of a sensorimotor system which is a special case of a well studied notion of a transition system. We also consider related notions such as labeled transition systems and deterministic automata. We analyze a notion called sufficiency and show that it is a very good candidate for a foundational notion in the "mathematics of cognition from an enactivist perspective". We demonstrate its importance by proving a uniqueness theorem about the minimal sufficient refinements (which correspond in some sense to an optimal attunement of an organism to its environment) and by showing that sufficiency corresponds to known notions such as sufficient history information spaces. We then develop other related notions such as degree of insufficiency, universal covers, hierarchies, strategic sufficiency. In the end, we tie it all back to the enactivist tenets.
Model-Based Deep Learning of Joint Probabilistic and Geometric Shaping for Optical Communication
Apr 05, 2022
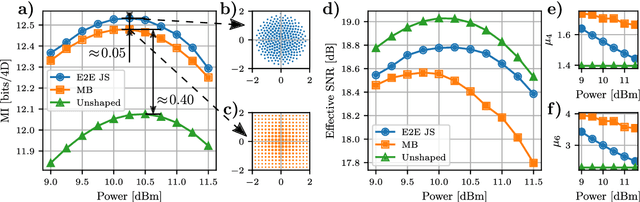
Autoencoder-based deep learning is applied to jointly optimize geometric and probabilistic constellation shaping for optical coherent communication. The optimized constellation shaping outperforms the 256 QAM Maxwell-Boltzmann probabilistic distribution with extra 0.05 bits/4D-symbol mutual information for 64 GBd transmission over 170 km SMF link.
Algorithmic Foundation of Deep X-Risk Optimization
Jun 02, 2022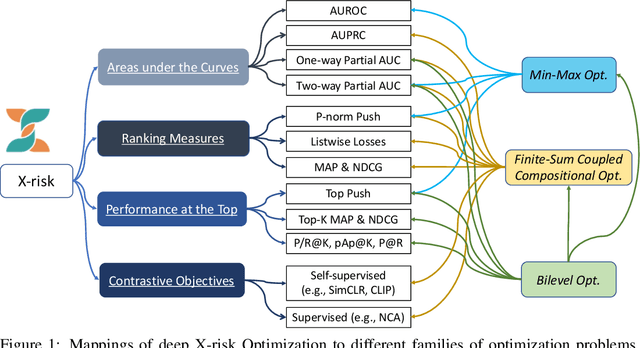

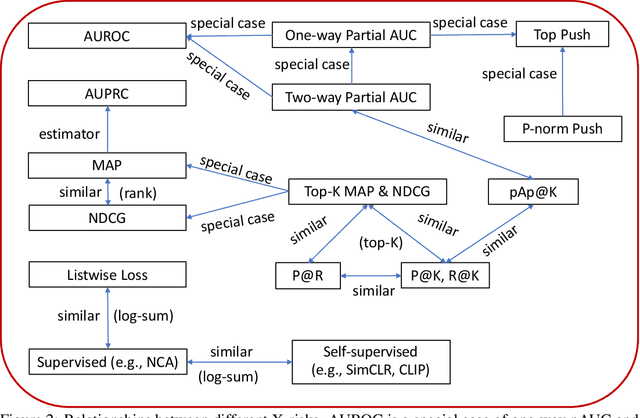
X-risk is a term introduced to represent a family of compositional measures or objectives, in which each data point is compared with a set of data points explicitly or implicitly for defining a risk function. It includes many widely used measures or objectives, e.g., AUROC, AUPRC, partial AUROC, NDCG, MAP, top-$K$ NDCG, top-$K$ MAP, listwise losses, p-norm push, top push, precision/recall at top $K$ positions, precision at a certain recall level, contrastive objectives, etc. While these measures/objectives and their optimization algorithms have been studied in the literature of machine learning, computer vision, information retrieval, and etc, optimizing these measures/objectives has encountered some unique challenges for deep learning. In this technical report, we survey our recent rigorous efforts for deep X-risk optimization (DXO) by focusing on its algorithmic foundation. We introduce a class of techniques for optimizing X-risk for deep learning. We formulate DXO into three special families of non-convex optimization problems belonging to non-convex min-max optimization, non-convex compositional optimization, and non-convex bilevel optimization, respectively. For each family of problems, we present some strong baseline algorithms and their complexities, which will motivate further research for improving the existing results. Discussions about the presented results and future studies are given at the end. Efficient algorithms for optimizing a variety of X-risks are implemented in the LibAUC library at www.libauc.org.
A Property Induction Framework for Neural Language Models
May 13, 2022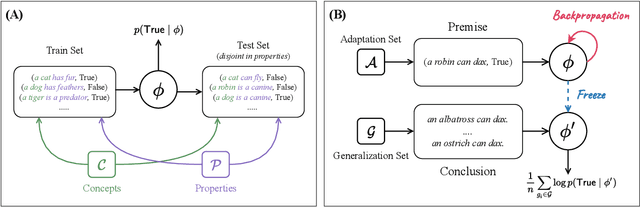
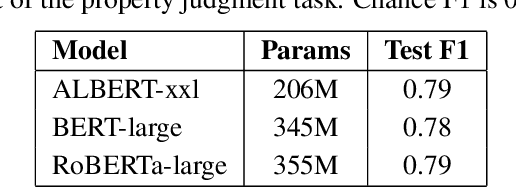
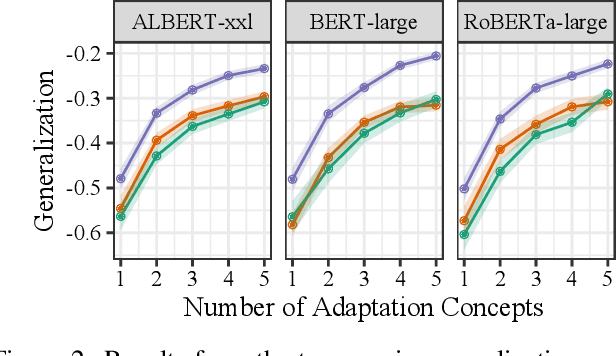
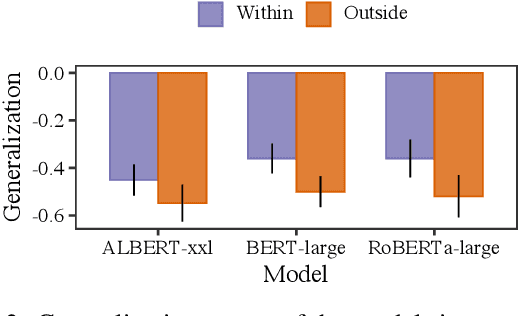
To what extent can experience from language contribute to our conceptual knowledge? Computational explorations of this question have shed light on the ability of powerful neural language models (LMs) -- informed solely through text input -- to encode and elicit information about concepts and properties. To extend this line of research, we present a framework that uses neural-network language models (LMs) to perform property induction -- a task in which humans generalize novel property knowledge (has sesamoid bones) from one or more concepts (robins) to others (sparrows, canaries). Patterns of property induction observed in humans have shed considerable light on the nature and organization of human conceptual knowledge. Inspired by this insight, we use our framework to explore the property inductions of LMs, and find that they show an inductive preference to generalize novel properties on the basis of category membership, suggesting the presence of a taxonomic bias in their representations.
DropMessage: Unifying Random Dropping for Graph Neural Networks
Apr 21, 2022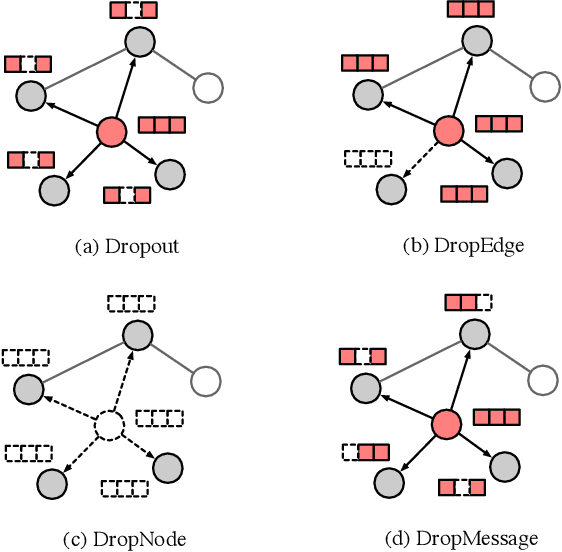

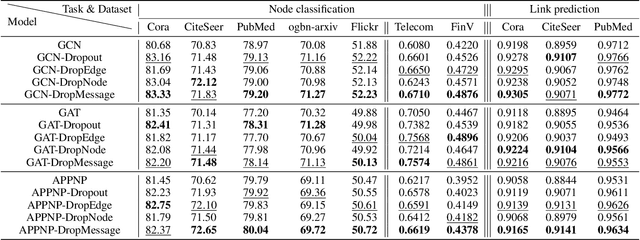
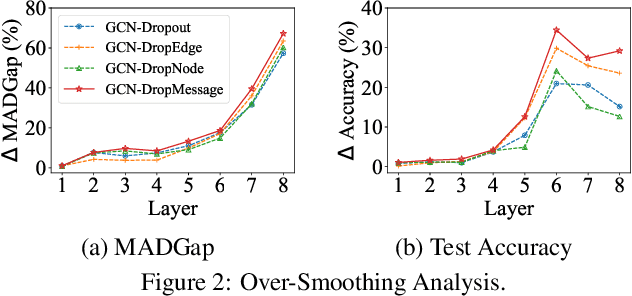
Graph Neural Networks (GNNs) are powerful tools for graph representation learning. Despite their rapid development, GNNs also faces some challenges, such as over-fitting, over-smoothing, and non-robustness. Previous works indicate that these problems can be alleviated by random dropping methods, which integrate noises into models by randomly masking parts of the input. However, some open-ended problems of random dropping on GNNs remain to solve. First, it is challenging to find a universal method that are suitable for all cases considering the divergence of different datasets and models. Second, random noises introduced to GNNs cause the incomplete coverage of parameters and unstable training process. In this paper, we propose a novel random dropping method called DropMessage, which performs dropping operations directly on the message matrix and can be applied to any message-passing GNNs. Furthermore, we elaborate the superiority of DropMessage: it stabilizes the training process by reducing sample variance; it keeps information diversity from the perspective of information theory, which makes it a theoretical upper bound of other methods. Also, we unify existing random dropping methods into our framework and analyze their effects on GNNs. To evaluate our proposed method, we conduct experiments that aims for multiple tasks on five public datasets and two industrial datasets with various backbone models. The experimental results show that DropMessage has both advantages of effectiveness and generalization.
GAN-based Medical Image Small Region Forgery Detection via a Two-Stage Cascade Framework
May 30, 2022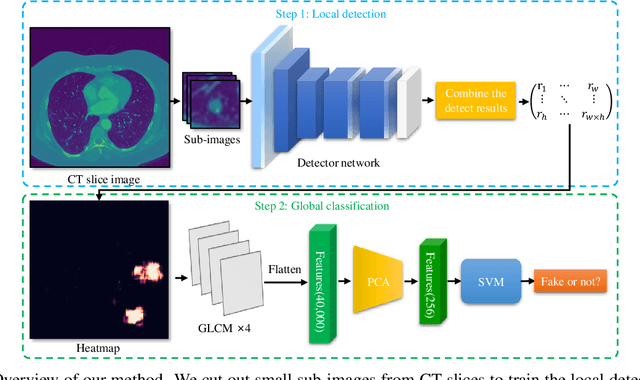
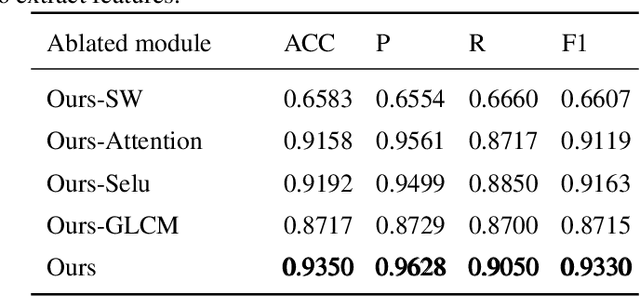
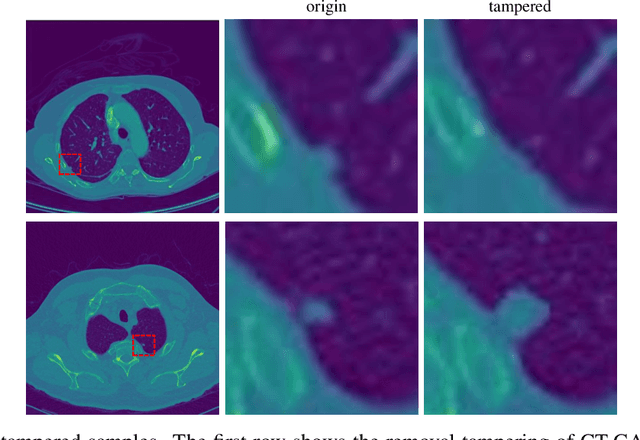
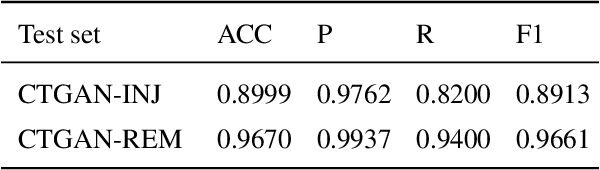
Using generative adversarial network (GAN)\cite{RN90} for data enhancement of medical images is significantly helpful for many computer-aided diagnosis (CAD) tasks. A new attack called CT-GAN has emerged. It can inject or remove lung cancer lesions to CT scans. Because the tampering region may even account for less than 1\% of the original image, even state-of-the-art methods are challenging to detect the traces of such tampering. This paper proposes a cascade framework to detect GAN-based medical image small region forgery like CT-GAN. In the local detection stage, we train the detector network with small sub-images so that interference information in authentic regions will not affect the detector. We use depthwise separable convolution and residual to prevent the detector from over-fitting and enhance the ability to find forged regions through the attention mechanism. The detection results of all sub-images in the same image will be combined into a heatmap. In the global classification stage, using gray level co-occurrence matrix (GLCM) can better extract features of the heatmap. Because the shape and size of the tampered area are uncertain, we train PCA and SVM methods for classification. Our method can classify whether a CT image has been tampered and locate the tampered position. Sufficient experiments show that our method can achieve excellent performance.
Multimodal Clustering with Role Induced Constraints for Speaker Diarization
Apr 01, 2022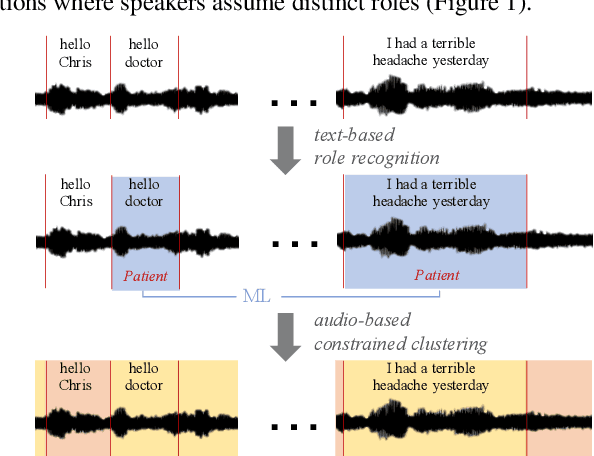
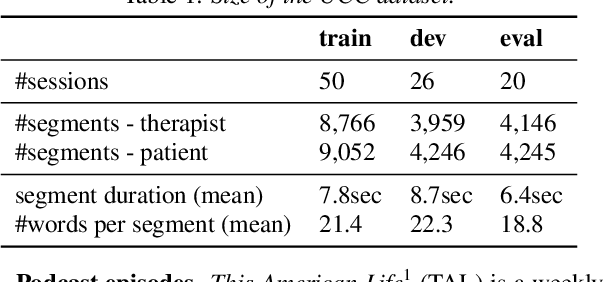
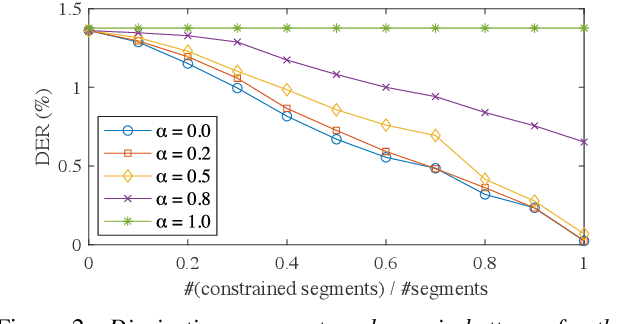
Speaker clustering is an essential step in conventional speaker diarization systems and is typically addressed as an audio-only speech processing task. The language used by the participants in a conversation, however, carries additional information that can help improve the clustering performance. This is especially true in conversational interactions, such as business meetings, interviews, and lectures, where specific roles assumed by interlocutors (manager, client, teacher, etc.) are often associated with distinguishable linguistic patterns. In this paper we propose to employ a supervised text-based model to extract speaker roles and then use this information to guide an audio-based spectral clustering step by imposing must-link and cannot-link constraints between segments. The proposed method is applied on two different domains, namely on medical interactions and on podcast episodes, and is shown to yield improved results when compared to the audio-only approach.
Context-aware Visual Tracking with Joint Meta-updating
Apr 04, 2022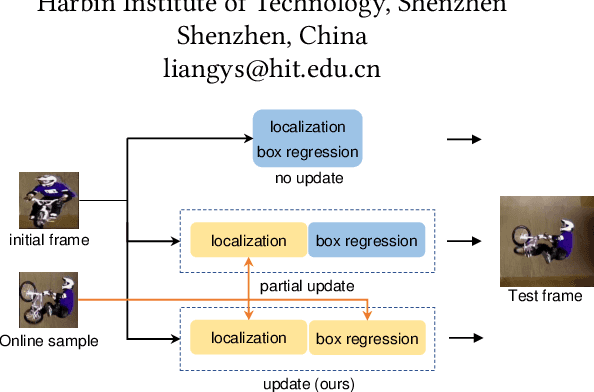
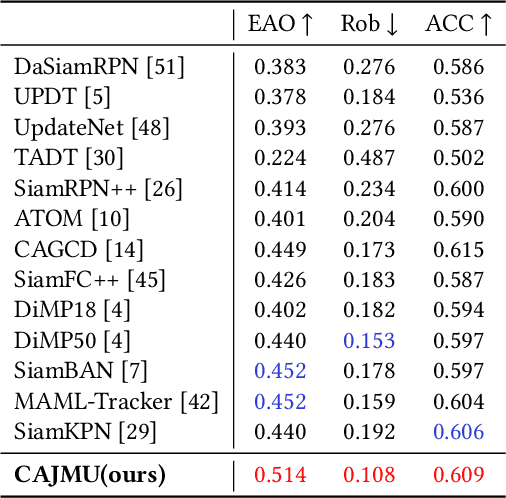
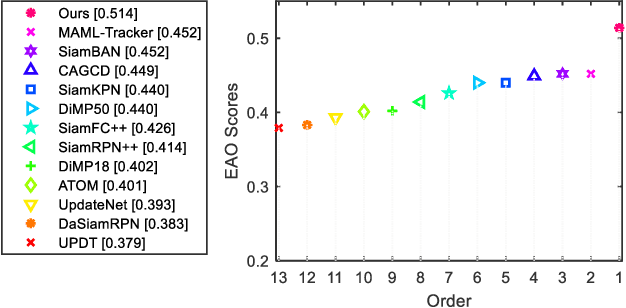

Visual object tracking acts as a pivotal component in various emerging video applications. Despite the numerous developments in visual tracking, existing deep trackers are still likely to fail when tracking against objects with dramatic variation. These deep trackers usually do not perform online update or update single sub-branch of the tracking model, for which they cannot adapt to the appearance variation of objects. Efficient updating methods are therefore crucial for tracking while previous meta-updater optimizes trackers directly over parameter space, which is prone to over-fit even collapse on longer sequences. To address these issues, we propose a context-aware tracking model to optimize the tracker over the representation space, which jointly meta-update both branches by exploiting information along the whole sequence, such that it can avoid the over-fitting problem. First, we note that the embedded features of the localization branch and the box-estimation branch, focusing on the local and global information of the target, are effective complements to each other. Based on this insight, we devise a context-aggregation module to fuse information in historical frames, followed by a context-aware module to learn affinity vectors for both branches of the tracker. Besides, we develop a dedicated meta-learning scheme, on account of fast and stable updating with limited training samples. The proposed tracking method achieves an EAO score of 0.514 on VOT2018 with the speed of 40FPS, demonstrating its capability of improving the accuracy and robustness of the underlying tracker with little speed drop.