 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Adversarial Learning for Cross-domain Fair Classification
Jun 08, 2022
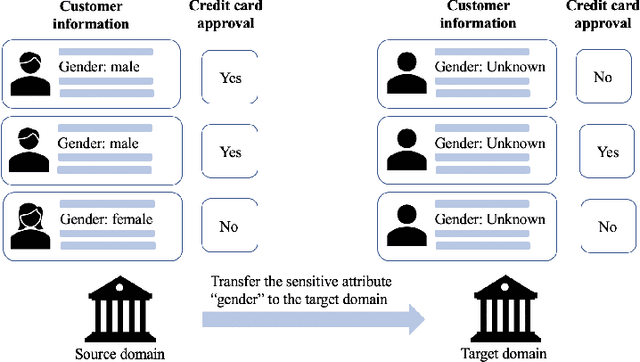
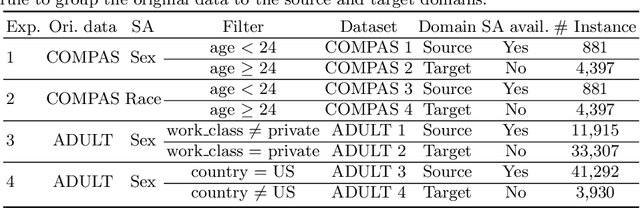
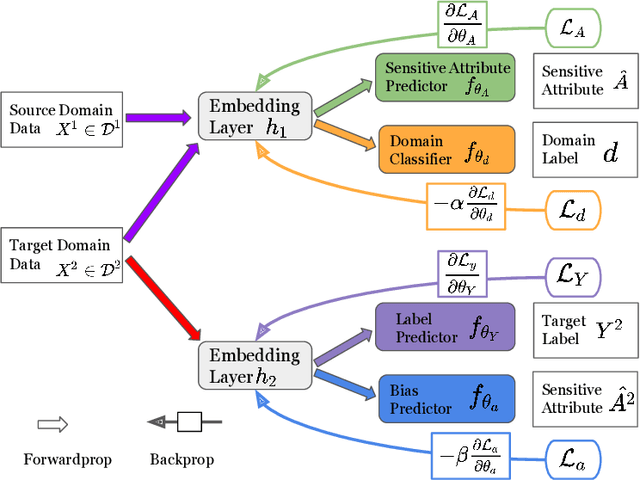
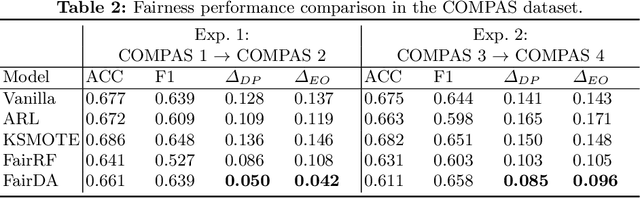
Modern machine learning (ML) models are becoming increasingly popular and are widely used in decision-making systems. However, studies have shown critical issues of ML discrimination and unfairness, which hinder their adoption on high-stake applications. Recent research on fair classifiers has drawn significant attention to develop effective algorithms to achieve fairness and good classification performance. Despite the great success of these fairness-aware machine learning models, most of the existing models require sensitive attributes to preprocess the data, regularize the model learning or postprocess the prediction to have fair predictions. However, sensitive attributes are often incomplete or even unavailable due to privacy, legal or regulation restrictions. Though we lack the sensitive attribute for training a fair model in the target domain, there might exist a similar domain that has sensitive attributes. Thus, it is important to exploit auxiliary information from the similar domain to help improve fair classification in the target domain. Therefore, in this paper, we study a novel problem of exploring domain adaptation for fair classification. We propose a new framework that can simultaneously estimate the sensitive attributes while learning a fair classifier in the target domain. Extensive experiments on real-world datasets illustrate the effectiveness of the proposed model for fair classification, even when no sensitive attributes are available in the target domain.
A Generalized Supervised Contrastive Learning Framework
Jun 01, 2022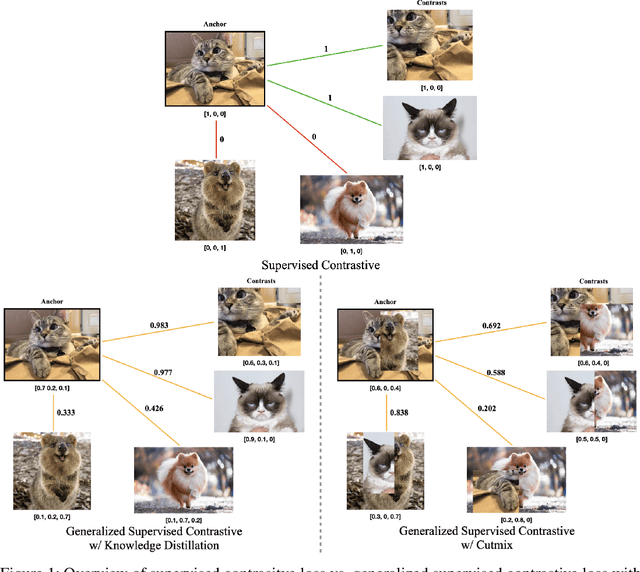

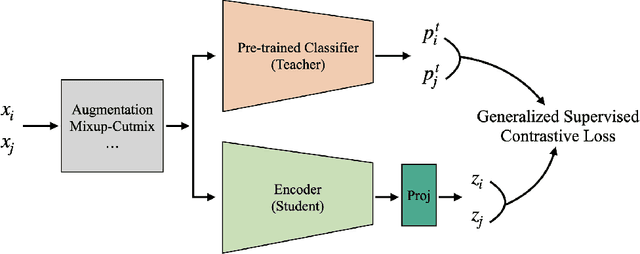

Based on recent remarkable achievements of contrastive learning in self-supervised representation learning, supervised contrastive learning (SupCon) has successfully extended the batch contrastive approaches to the supervised context and outperformed cross-entropy on various datasets on ResNet. In this work, we present GenSCL: a generalized supervised contrastive learning framework that seamlessly adapts modern image-based regularizations (such as Mixup-Cutmix) and knowledge distillation (KD) to SupCon by our generalized supervised contrastive loss. Generalized supervised contrastive loss is a further extension of supervised contrastive loss measuring cross-entropy between the similarity of labels and that of latent features. Then a model can learn to what extent contrastives should be pulled closer to an anchor in the latent space. By explicitly and fully leveraging label information, GenSCL breaks the boundary between conventional positives and negatives, and any kind of pre-trained teacher classifier can be utilized. ResNet-50 trained in GenSCL with Mixup-Cutmix and KD achieves state-of-the-art accuracies of 97.6% and 84.7% on CIFAR10 and CIFAR100 without external data, which significantly improves the results reported in the original SupCon (1.6% and 8.2%, respectively). Pytorch implementation is available at https://t.ly/yuUO.
DeepFormableTag: End-to-end Generation and Recognition of Deformable Fiducial Markers
Jun 16, 2022
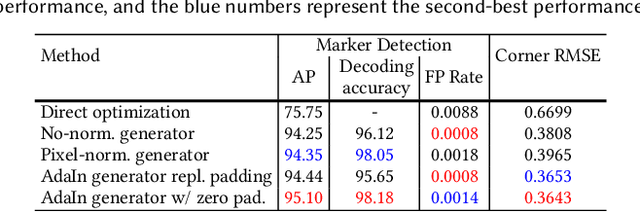
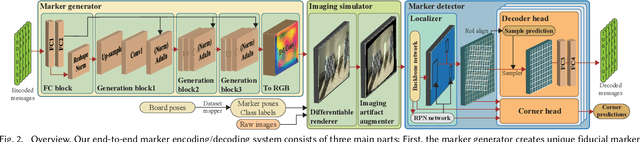

Fiducial markers have been broadly used to identify objects or embed messages that can be detected by a camera. Primarily, existing detection methods assume that markers are printed on ideally planar surfaces. Markers often fail to be recognized due to various imaging artifacts of optical/perspective distortion and motion blur. To overcome these limitations, we propose a novel deformable fiducial marker system that consists of three main parts: First, a fiducial marker generator creates a set of free-form color patterns to encode significantly large-scale information in unique visual codes. Second, a differentiable image simulator creates a training dataset of photorealistic scene images with the deformed markers, being rendered during optimization in a differentiable manner. The rendered images include realistic shading with specular reflection, optical distortion, defocus and motion blur, color alteration, imaging noise, and shape deformation of markers. Lastly, a trained marker detector seeks the regions of interest and recognizes multiple marker patterns simultaneously via inverse deformation transformation. The deformable marker creator and detector networks are jointly optimized via the differentiable photorealistic renderer in an end-to-end manner, allowing us to robustly recognize a wide range of deformable markers with high accuracy. Our deformable marker system is capable of decoding 36-bit messages successfully at ~29 fps with severe shape deformation. Results validate that our system significantly outperforms the traditional and data-driven marker methods. Our learning-based marker system opens up new interesting applications of fiducial markers, including cost-effective motion capture of the human body, active 3D scanning using our fiducial markers' array as structured light patterns, and robust augmented reality rendering of virtual objects on dynamic surfaces.
Context Attention Network for Skeleton Extraction
May 24, 2022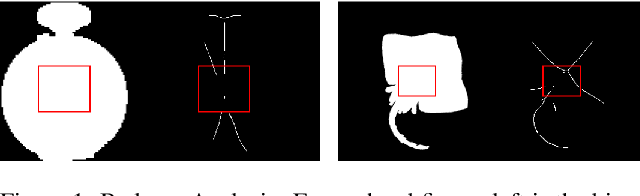

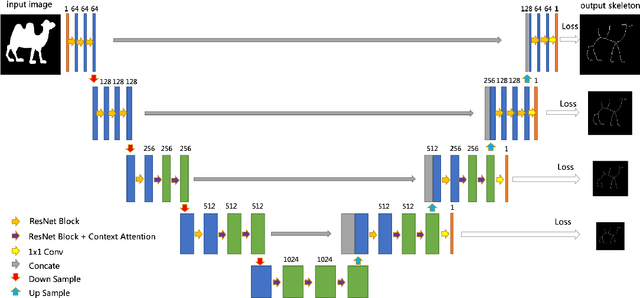

Skeleton extraction is a task focused on providing a simple representation of an object by extracting the skeleton from the given binary or RGB image. In recent years many attractive works in skeleton extraction have been made. But as far as we know, there is little research on how to utilize the context information in the binary shape of objects. In this paper, we propose an attention-based model called Context Attention Network (CANet), which integrates the context extraction module in a UNet architecture and can effectively improve the ability of network to extract the skeleton pixels. Meanwhile, we also use some novel techniques including distance transform, weight focal loss to achieve good results on the given dataset. Finally, without model ensemble and with only 80% of the training images, our method achieves 0.822 F1 score during the development phase and 0.8507 F1 score during the final phase of the Pixel SkelNetOn Competition, ranking 1st place on the leaderboard.
On the Arithmetic and Geometric Fusion of Beliefs for Distributed Inference
Apr 28, 2022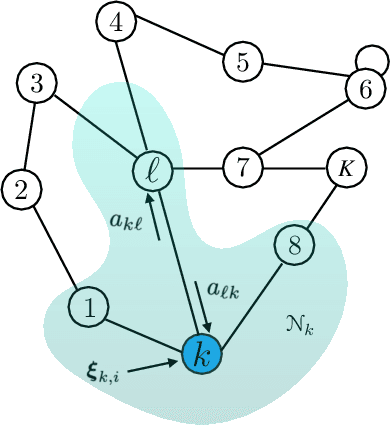
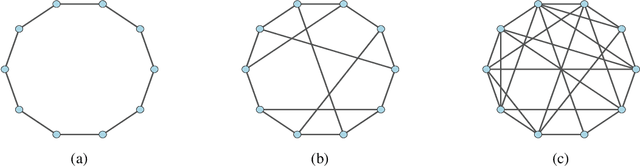
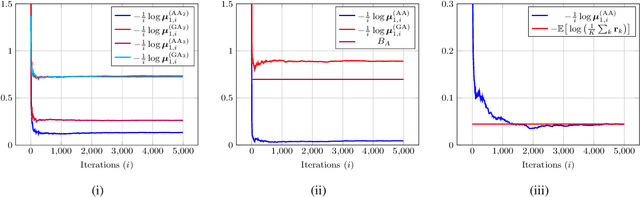
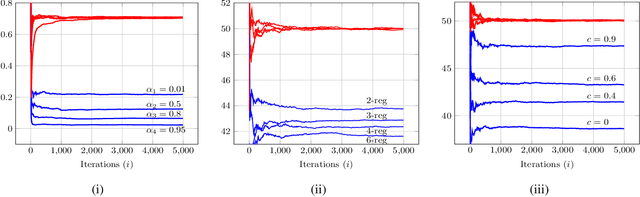
We study the asymptotic learning rates under linear and log-linear combination rules of belief vectors in a distributed hypothesis testing problem. We show that under both combination strategies, agents are able to learn the truth exponentially fast, with a faster rate under log-linear fusion. We examine the gap between the rates in terms of network connectivity and information diversity. We also provide closed-form expressions for special cases involving federated architectures and exchangeable networks.
HCFRec: Hash Collaborative Filtering via Normalized Flow with Structural Consensus for Efficient Recommendation
May 24, 2022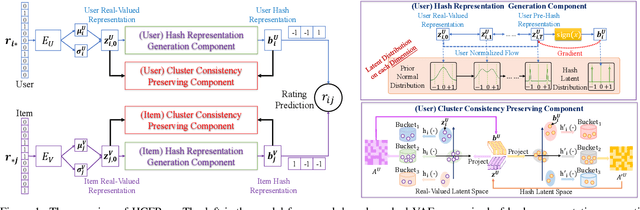
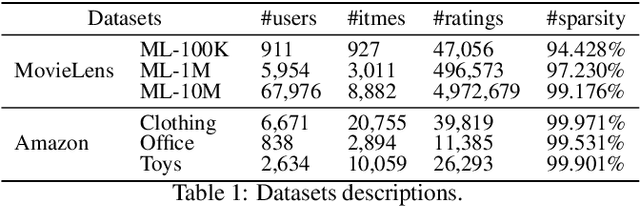
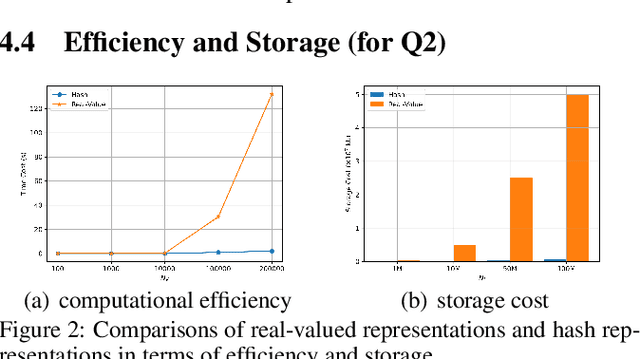
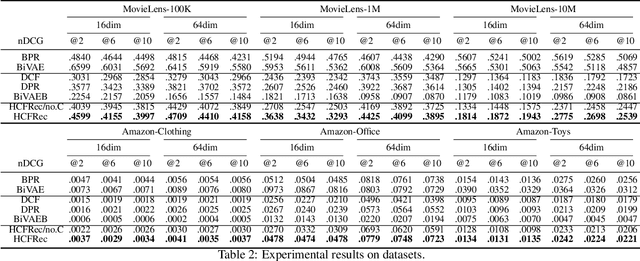
The ever-increasing data scale of user-item interactions makes it challenging for an effective and efficient recommender system. Recently, hash-based collaborative filtering (Hash-CF) approaches employ efficient Hamming distance of learned binary representations of users and items to accelerate recommendations. However, Hash-CF often faces two challenging problems, i.e., optimization on discrete representations and preserving semantic information in learned representations. To address the above two challenges, we propose HCFRec, a novel Hash-CF approach for effective and efficient recommendations. Specifically, HCFRec not only innovatively introduces normalized flow to learn the optimal hash code by efficiently fit a proposed approximate mixture multivariate normal distribution, a continuous but approximately discrete distribution, but also deploys a cluster consistency preserving mechanism to preserve the semantic structure in representations for more accurate recommendations. Extensive experiments conducted on six real-world datasets demonstrate the superiority of our HCFRec compared to the state-of-art methods in terms of effectiveness and efficiency.
ME-CapsNet: A Multi-Enhanced Capsule Networks with Routing Mechanism
Mar 31, 2022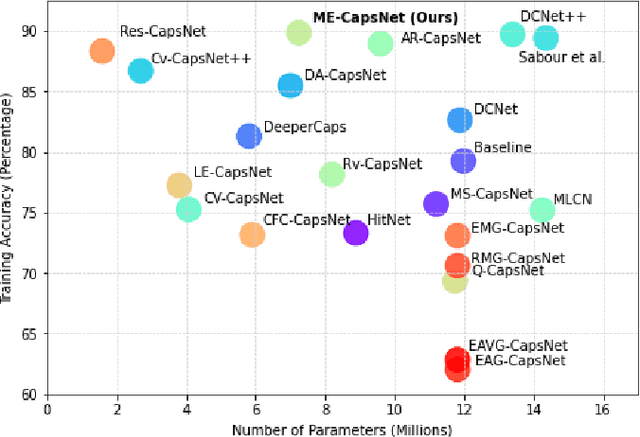

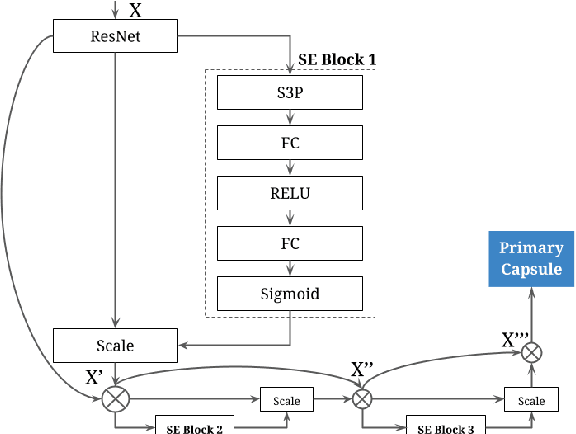
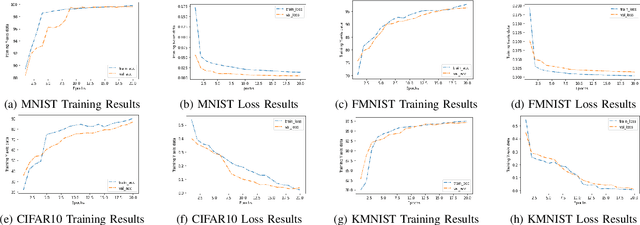
Convolutional Neural Networks need the construction of informative features, which are determined by channel-wise and spatial-wise information at the network's layers. In this research, we focus on bringing in a novel solution that uses sophisticated optimization for enhancing both the spatial and channel components inside each layer's receptive field. Capsule Networks were used to understand the spatial association between features in the feature map. Standalone capsule networks have shown good results on comparatively simple datasets than on complex datasets as a result of the inordinate amount of feature information. Thus, to tackle this issue, we have proposed ME-CapsNet by introducing deeper convolutional layers to extract important features before passing through modules of capsule layers strategically to improve the performance of the network significantly. The deeper convolutional layer includes blocks of Squeeze-Excitation networks which use a stochastic sampling approach for progressively reducing the spatial size thereby dynamically recalibrating the channels by reconstructing their interdependencies without much loss of important feature information. Extensive experimentation was done using commonly used datasets demonstrating the efficiency of the proposed ME-CapsNet, which clearly outperforms various research works by achieving higher accuracy with minimal model complexity in complex datasets.
S$^2$-FPN: Scale-ware Strip Attention Guided Feature Pyramid Network for Real-time Semantic Segmentation
Jun 16, 2022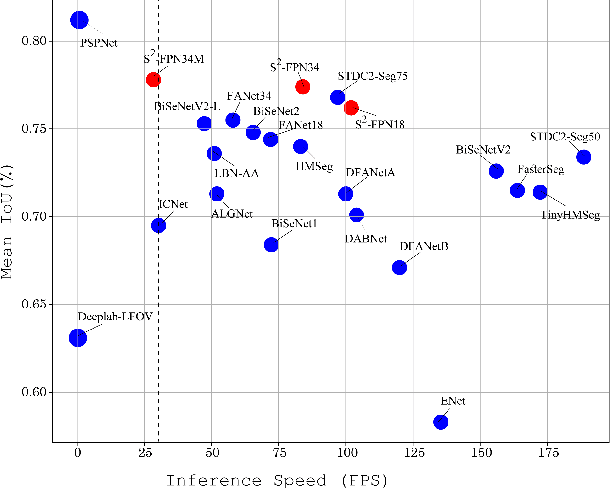
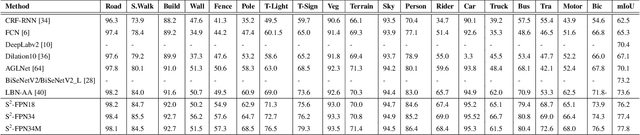
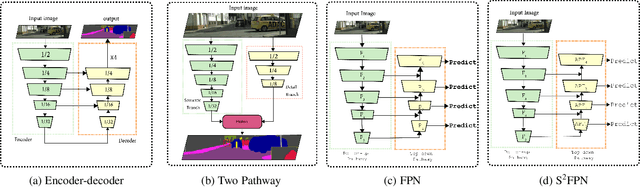
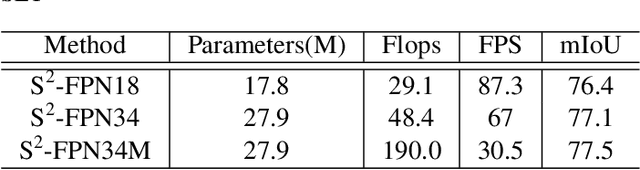
Modern high-performance semantic segmentation methods employ a heavy backbone and dilated convolution to extract the relevant feature. Although extracting features with both contextual and semantic information is critical for the segmentation tasks, it brings a memory footprint and high computation cost for real-time applications. This paper presents a new model to achieve a trade-off between accuracy/speed for real-time road scene semantic segmentation. Specifically, we proposed a lightweight model named Scale-aware Strip Attention Guided Feature Pyramid Network (S$^2$-FPN). Our network consists of three main modules: Attention Pyramid Fusion (APF) module, Scale-aware Strip Attention Module (SSAM), and Global Feature Upsample (GFU) module. APF adopts an attention mechanisms to learn discriminative multi-scale features and help close the semantic gap between different levels. APF uses the scale-aware attention to encode global context with vertical stripping operation and models the long-range dependencies, which helps relate pixels with similar semantic label. In addition, APF employs channel-wise reweighting block (CRB) to emphasize the channel features. Finally, the decoder of S$^2$-FPN then adopts GFU, which is used to fuse features from APF and the encoder. Extensive experiments have been conducted on two challenging semantic segmentation benchmarks, which demonstrate that our approach achieves better accuracy/speed trade-off with different model settings. The proposed models have achieved a results of 76.2\%mIoU/87.3FPS, 77.4\%mIoU/67FPS, and 77.8\%mIoU/30.5FPS on Cityscapes dataset, and 69.6\%mIoU,71.0\% mIoU, and 74.2\% mIoU on Camvid dataset. The code for this work will be made available at \url{https://github.com/mohamedac29/S2-FPN
Evaluating the Fairness Impact of Differentially Private Synthetic Data
May 09, 2022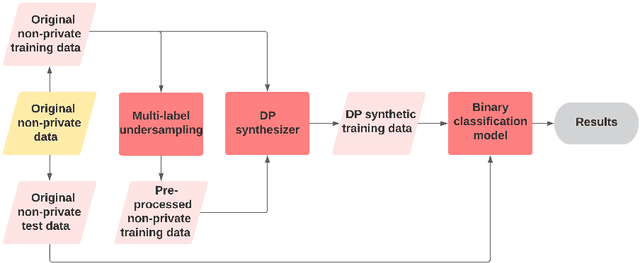
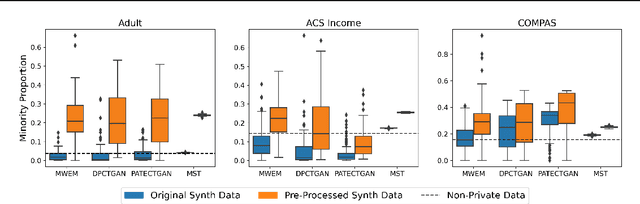
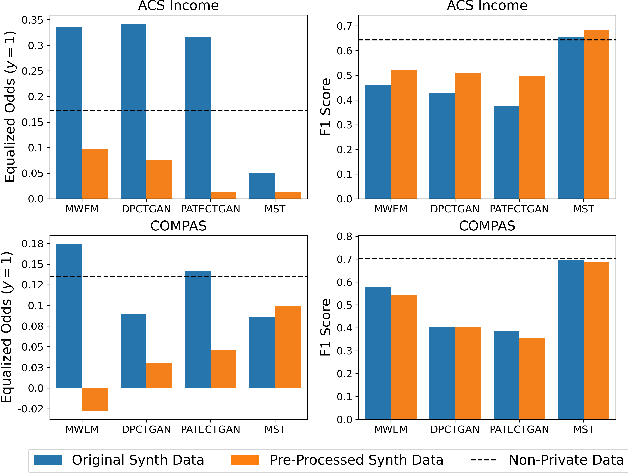
Differentially private (DP) synthetic data is a promising approach to maximizing the utility of data containing sensitive information. Due to the suppression of underrepresented classes that is often required to achieve privacy, however, it may be in conflict with fairness. We evaluate four DP synthesizers and present empirical results indicating that three of these models frequently degrade fairness outcomes on downstream binary classification tasks. We draw a connection between fairness and the proportion of minority groups present in the generated synthetic data, and find that training synthesizers on data that are pre-processed via a multi-label undersampling method can promote more fair outcomes without degrading accuracy.
Multi-modal Emotion Estimation for in-the-wild Videos
Mar 31, 2022



In this paper, we briefly introduce our submission to the Valence-Arousal Estimation Challenge of the 3rd Affective Behavior Analysis in-the-wild (ABAW) competition. Our method utilizes the multi-modal information, i.e., the visual and audio information, and employs a temporal encoder to model the temporal context in the videos. Besides, a smooth processor is applied to get more reasonable predictions, and a model ensemble strategy is used to improve the performance of our proposed method. The experiment results show that our method achieves 65.55% ccc for valence and 70.88% ccc for arousal on the validation set of the Aff-Wild2 dataset, which prove the effectiveness of our proposed method.