 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DynamicRetriever: A Pre-training Model-based IR System with Neither Sparse nor Dense Index
Mar 01, 2022
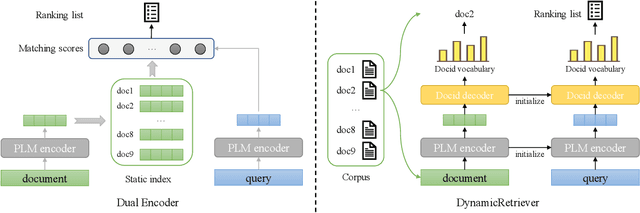
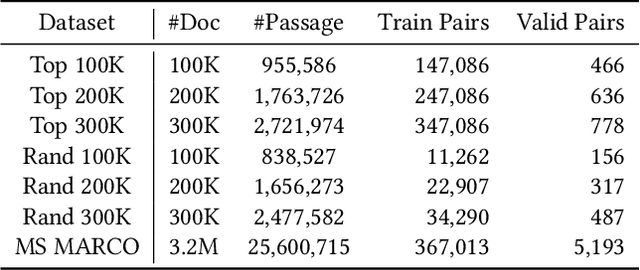
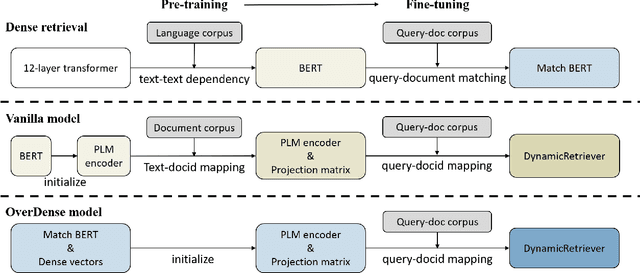
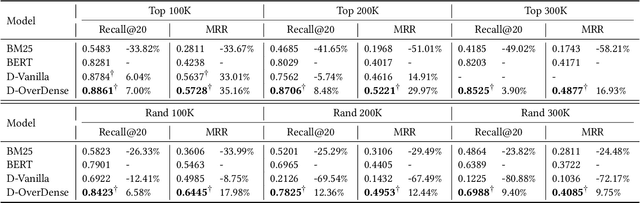
Web search provides a promising way for people to obtain information and has been extensively studied. With the surgence of deep learning and large-scale pre-training techniques, various neural information retrieval models are proposed and they have demonstrated the power for improving search (especially, the ranking) quality. All these existing search methods follow a common paradigm, i.e. index-retrieve-rerank, where they first build an index of all documents based on document terms (i.e., sparse inverted index) or representation vectors (i.e., dense vector index), then retrieve and rerank retrieved documents based on similarity between the query and documents via ranking models. In this paper, we explore a new paradigm of information retrieval with neither sparse nor dense index but only a model. Specifically, we propose a pre-training model-based IR system called DynamicRetriever. As for this system, the training stage embeds the token-level and document-level information (especially, document identifiers) of the corpus into the model parameters, then the inference stage directly generates document identifiers for a given query. Compared with existing search methods, the model-based IR system has two advantages: i) it parameterizes the traditional static index with a pre-training model, which converts the document semantic mapping into a dynamic and updatable process; ii) with separate document identifiers, it captures both the term-level and document-level information for each document. Extensive experiments conducted on the public search benchmark MS MARCO verify the effectiveness and potential of our proposed new paradigm for information retrieval.
Graph Neural Networks for Multiparallel Word Alignment
Mar 16, 2022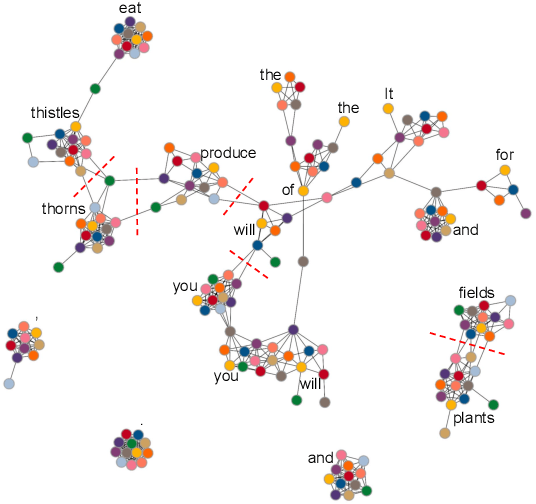
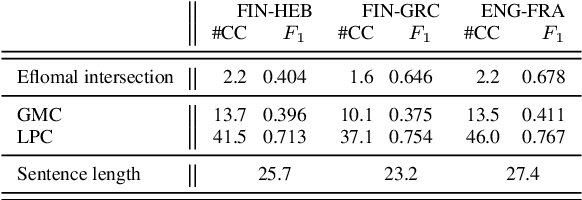
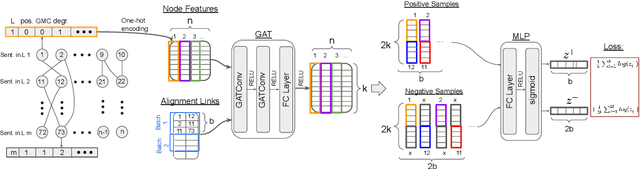
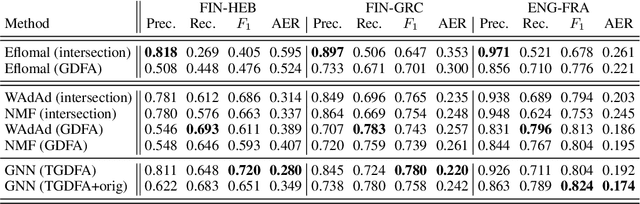
After a period of decrease, interest in word alignments is increasing again for their usefulness in domains such as typological research, cross-lingual annotation projection, and machine translation. Generally, alignment algorithms only use bitext and do not make use of the fact that many parallel corpora are multiparallel. Here, we compute high-quality word alignments between multiple language pairs by considering all language pairs together. First, we create a multiparallel word alignment graph, joining all bilingual word alignment pairs in one graph. Next, we use graph neural networks (GNNs) to exploit the graph structure. Our GNN approach (i) utilizes information about the meaning, position, and language of the input words, (ii) incorporates information from multiple parallel sentences, (iii) adds and removes edges from the initial alignments, and (iv) yields a prediction model that can generalize beyond the training sentences. We show that community detection provides valuable information for multiparallel word alignment. Our method outperforms previous work on three word-alignment datasets and on a downstream task.
Meta-Learning Based Knowledge Extrapolation for Knowledge Graphs in the Federated Setting
May 10, 2022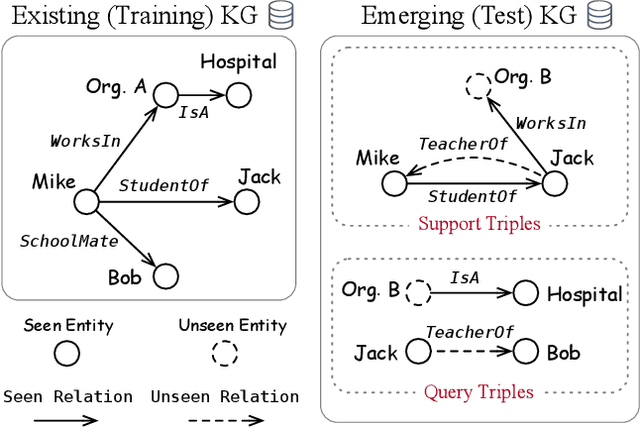
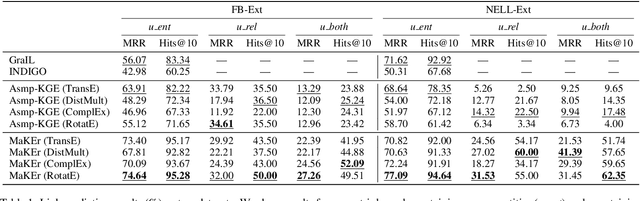
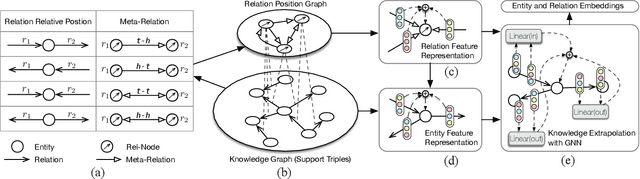

We study the knowledge extrapolation problem to embed new components (i.e., entities and relations) that come with emerging knowledge graphs (KGs) in the federated setting. In this problem, a model trained on an existing KG needs to embed an emerging KG with unseen entities and relations. To solve this problem, we introduce the meta-learning setting, where a set of tasks are sampled on the existing KG to mimic the link prediction task on the emerging KG. Based on sampled tasks, we meta-train a graph neural network framework that can construct features for unseen components based on structural information and output embeddings for them. Experimental results show that our proposed method can effectively embed unseen components and outperforms models that consider inductive settings for KGs and baselines that directly use conventional KG embedding methods.
A Framework for CSI-Based Indoor Localization with 1D Convolutional Neural Networks
May 17, 2022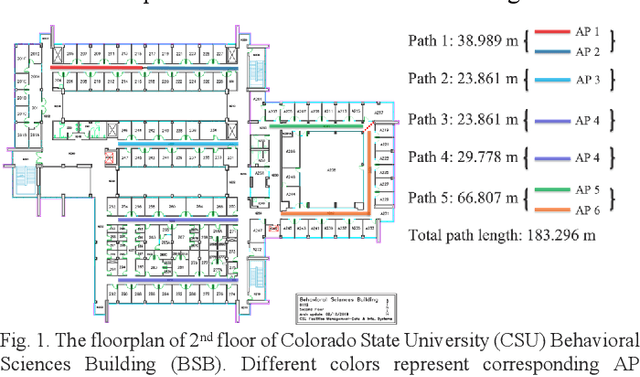
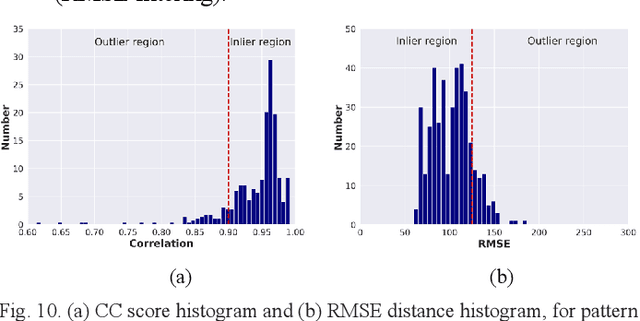
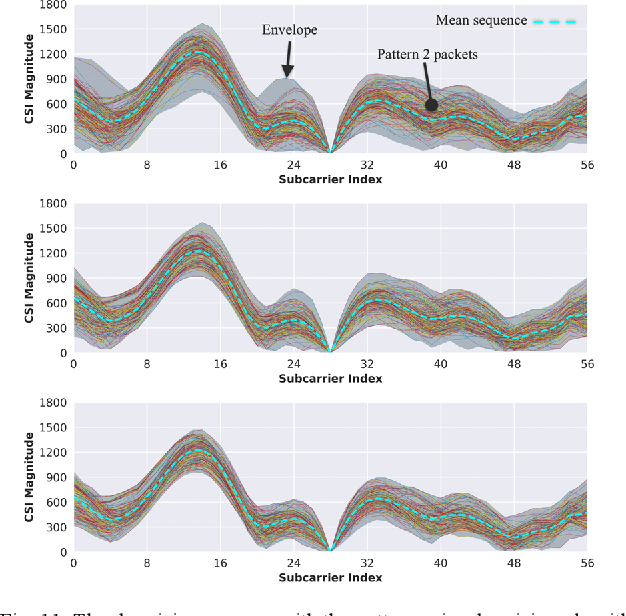
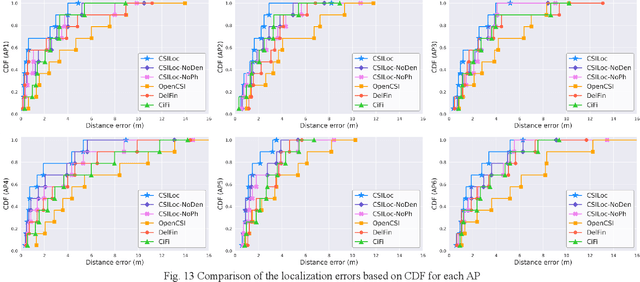
Modern indoor localization techniques are essential to overcome the weak GPS coverage in indoor environments. Recently, considerable progress has been made in Channel State Information (CSI) based indoor localization with signal fingerprints. However, CSI signal patterns can be complicated in the large and highly dynamic indoor spaces with complex interiors, thus a solution for solving this issue is urgently needed to expand the applications of CSI to a broader indoor space. In this paper, we propose an end-to-end solution including data collection, pattern clustering, denoising, calibration and a lightweight one-dimensional convolutional neural network (1D CNN) model with CSI fingerprinting to tackle this problem. We have also created and plan to open source a CSI dataset with a large amount of data collected across complex indoor environments at Colorado State University. Experiments indicate that our approach achieves up to 68.5% improved performance (mean distance error) with minimal number of parameters, compared to the best-known deep machine learning and CSI-based indoor localization works.
Ontological Learning from Weak Labels
Mar 04, 2022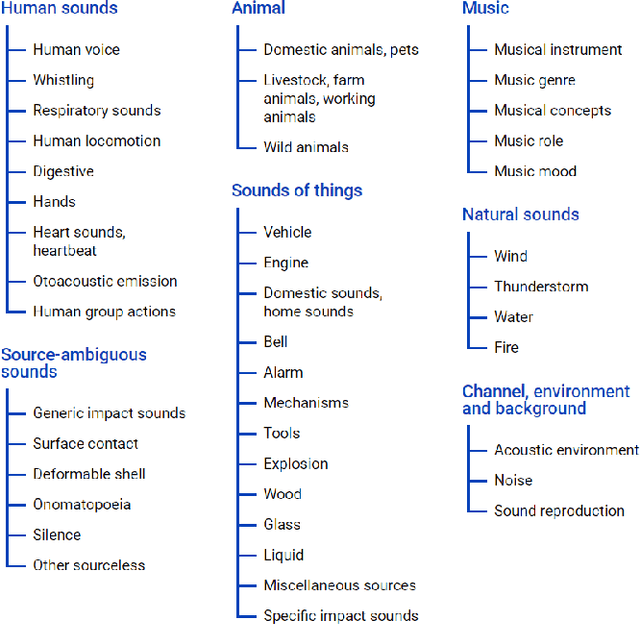


Ontologies encompass a formal representation of knowledge through the definition of concepts or properties of a domain, and the relationships between those concepts. In this work, we seek to investigate whether using this ontological information will improve learning from weakly labeled data, which are easier to collect since it requires only the presence or absence of an event to be known. We use the AudioSet ontology and dataset, which contains audio clips weakly labeled with the ontology concepts and the ontology providing the "Is A" relations between the concepts. We first re-implemented the model proposed by soundevent_ontology with modification to fit the multi-label scenario and then expand on that idea by using a Graph Convolutional Network (GCN) to model the ontology information to learn the concepts. We find that the baseline Siamese does not perform better by incorporating ontology information in the weak and multi-label scenario, but that the GCN does capture the ontology knowledge better for weak, multi-labeled data. In our experiments, we also investigate how different modules can tolerate noises introduced from weak labels and better incorporate ontology information. Our best Siamese-GCN model achieves mAP=0.45 and AUC=0.87 for lower-level concepts and mAP=0.72 and AUC=0.86 for higher-level concepts, which is an improvement over the baseline Siamese but about the same as our models that do not use ontology information.
Video Sentiment Analysis with Bimodal Information-augmented Multi-Head Attention
Mar 03, 2021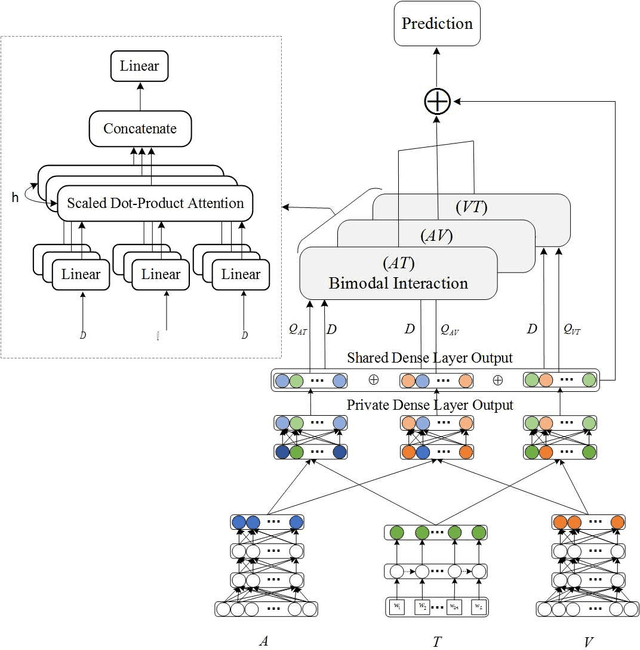
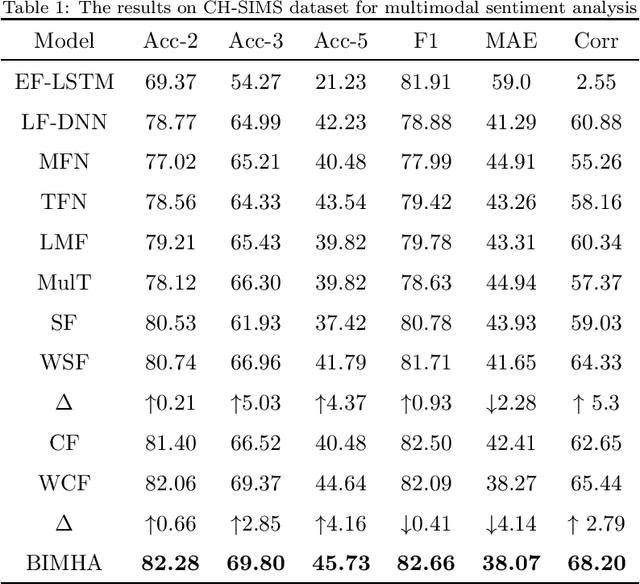
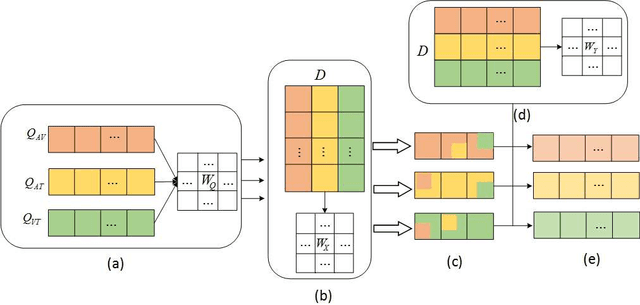
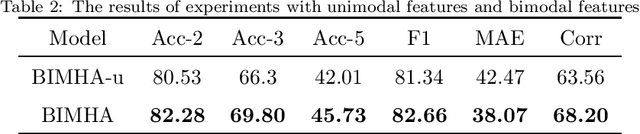
Sentiment analysis is the basis of intelligent human-computer interaction. As one of the frontier research directions of artificial intelligence, it can help computers better identify human intentions and emotional states so that provide more personalized services. However, as human present sentiments by spoken words, gestures, facial expressions and others which involve variable forms of data including text, audio, video, etc., it poses many challenges to this study. Due to the limitations of unimodal sentiment analysis, recent research has focused on the sentiment analysis of videos containing time series data of multiple modalities. When analyzing videos with multimodal data, the key problem is how to fuse these heterogeneous data. In consideration that the contribution of each modality is different, current fusion methods tend to extract the important information of single modality prior to fusion, which ignores the consistency and complementarity of bimodal interaction and has influences on the final decision. To solve this problem, a video sentiment analysis method using multi-head attention with bimodal information augmented is proposed. Based on bimodal interaction, more important bimodal features are assigned larger weights. In this way, different feature representations are adaptively assigned corresponding attention for effective multimodal fusion. Extensive experiments were conducted on both Chinese and English public datasets. The results show that our approach outperforms the existing methods and can give an insight into the contributions of bimodal interaction among three modalities.
Reinforced Pedestrian Attribute Recognition with Group Optimization Reward
May 21, 2022

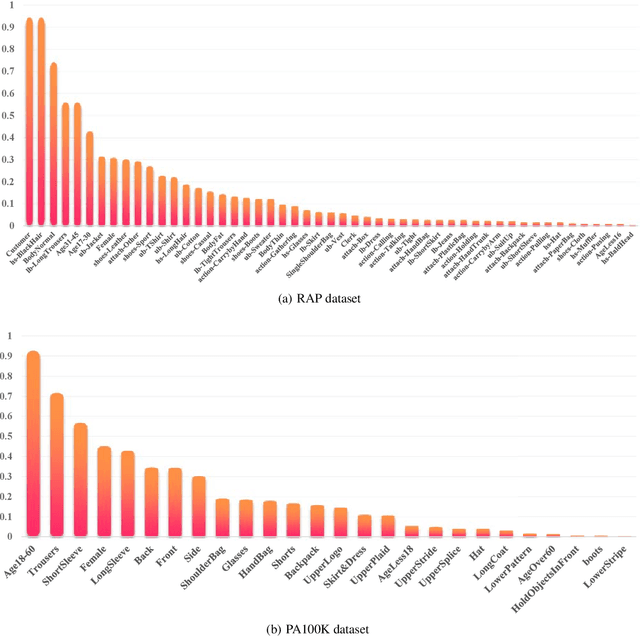

Pedestrian Attribute Recognition (PAR) is a challenging task in intelligent video surveillance. Two key challenges in PAR include complex alignment relations between images and attributes, and imbalanced data distribution. Existing approaches usually formulate PAR as a recognition task. Different from them, this paper addresses it as a decision-making task via a reinforcement learning framework. Specifically, PAR is formulated as a Markov decision process (MDP) by designing ingenious states, action space, reward function and state transition. To alleviate the inter-attribute imbalance problem, we apply an Attribute Grouping Strategy (AGS) by dividing all attributes into subgroups according to their region and category information. Then we employ an agent to recognize each group of attributes, which is trained with Deep Q-learning algorithm. We also propose a Group Optimization Reward (GOR) function to alleviate the intra-attribute imbalance problem. Experimental results on the three benchmark datasets of PETA, RAP and PA100K illustrate the effectiveness and competitiveness of the proposed approach and demonstrate that the application of reinforcement learning to PAR is a valuable research direction.
Exploring Body Texture from mmW Images for Person Recognition
Mar 27, 2022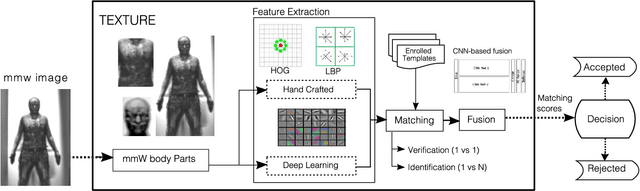

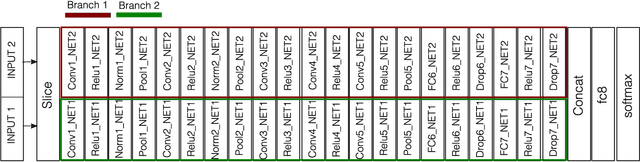

Imaging using millimeter waves (mmWs) has many advantages including the ability to penetrate obscurants such as clothes and polymers. After having explored shape information retrieved from mmW images for person recognition, in this work we aim to gain some insight about the potential of using mmW texture information for the same task, considering not only the mmW face, but also mmW torso and mmW wholebody. We report experimental results using the mmW TNO database consisting of 50 individuals based on both hand-crafted and learned features from Alexnet and VGG-face pretrained Convolutional Neural Networks (CNN) models. First, we analyze the individual performance of three mmW body parts, concluding that: i) mmW torso region is more discriminative than mmW face and the whole body, ii) CNN features produce better results compared to hand-crafted features on mmW faces and the entire body, and iii) hand-crafted features slightly outperform CNN features on mmW torso. In the second part of this work, we analyze different multi-algorithmic and multi-modal techniques, including a novel CNN-based fusion technique, improving verification results to 2% EER and identification rank-1 results up to 99%. Comparative analyses with mmW body shape information and face recognition in the visible and NIR spectral bands are also reported.
Transcormer: Transformer for Sentence Scoring with Sliding Language Modeling
May 28, 2022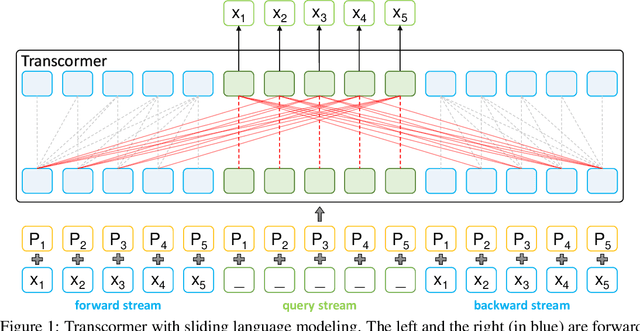

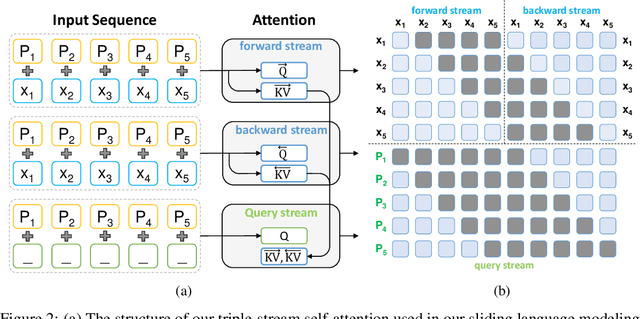
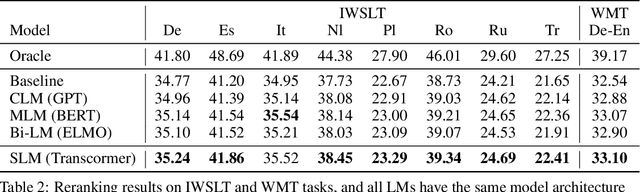
Sentence scoring aims at measuring the likelihood score of a sentence and is widely used in many natural language processing scenarios, like reranking, which is to select the best sentence from multiple candidates. Previous works on sentence scoring mainly adopted either causal language modeling (CLM) like GPT or masked language modeling (MLM) like BERT, which have some limitations: 1) CLM only utilizes unidirectional information for the probability estimation of a sentence without considering bidirectional context, which affects the scoring quality; 2) MLM can only estimate the probability of partial tokens at a time and thus requires multiple forward passes to estimate the probability of the whole sentence, which incurs large computation and time cost. In this paper, we propose \textit{Transcormer} -- a Transformer model with a novel \textit{sliding language modeling} (SLM) for sentence scoring. Specifically, our SLM adopts a triple-stream self-attention mechanism to estimate the probability of all tokens in a sentence with bidirectional context and only requires a single forward pass. SLM can avoid the limitations of CLM (only unidirectional context) and MLM (multiple forward passes) and inherit their advantages, and thus achieve high effectiveness and efficiency in scoring. Experimental results on multiple tasks demonstrate that our method achieves better performance than other language modelings.
Medical Scientific Table-to-Text Generation with Human-in-the-Loop under the Data Sparsity Constraint
May 24, 2022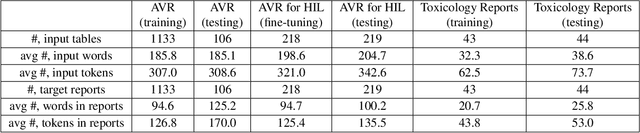
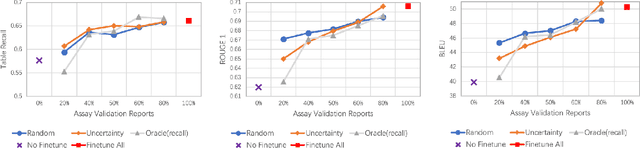
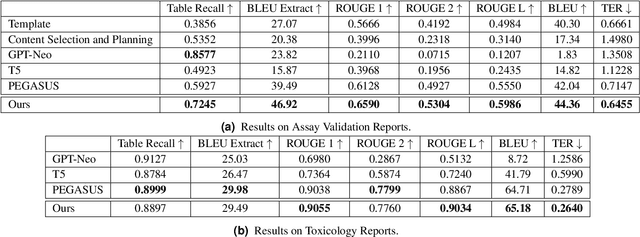
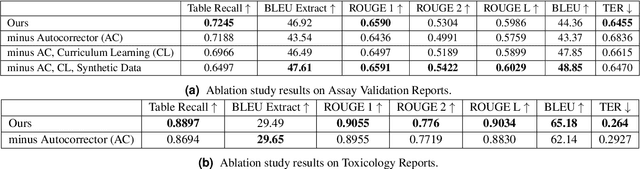
Structured (tabular) data in the preclinical and clinical domains contains valuable information about individuals and an efficient table-to-text summarization system can drastically reduce manual efforts to condense this data into reports. However, in practice, the problem is heavily impeded by the data paucity, data sparsity and inability of the state-of-the-art natural language generation models (including T5, PEGASUS and GPT-Neo) to produce accurate and reliable outputs. In this paper, we propose a novel table-to-text approach and tackle these problems with a novel two-step architecture which is enhanced by auto-correction, copy mechanism and synthetic data augmentation. The study shows that the proposed approach selects salient biomedical entities and values from structured data with improved precision (up to 0.13 absolute increase) of copying the tabular values to generate coherent and accurate text for assay validation reports and toxicology reports. Moreover, we also demonstrate a light-weight adaptation of the proposed system to new datasets by fine-tuning with as little as 40\% training examples. The outputs of our model are validated by human experts in the Human-in-the-Loop scenario.