 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-Driven Upper Bounds on Channel Capacity
May 13, 2022
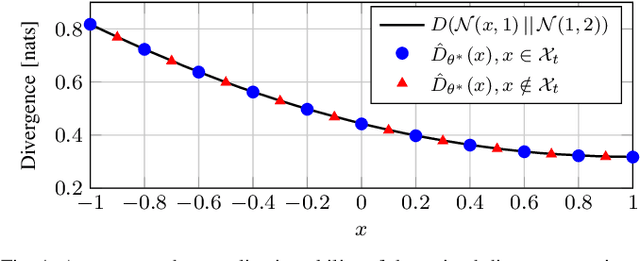
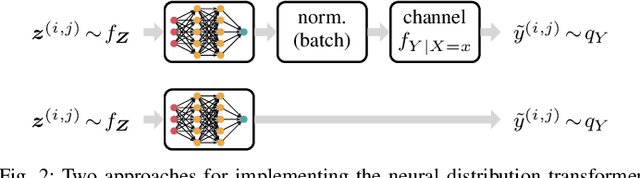
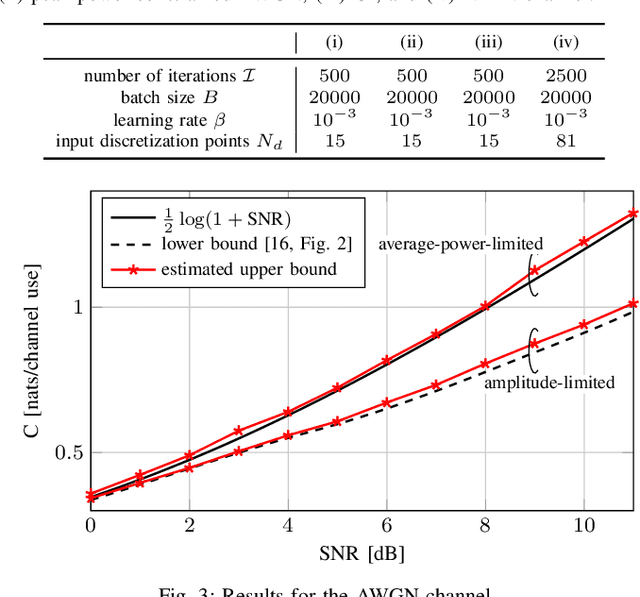
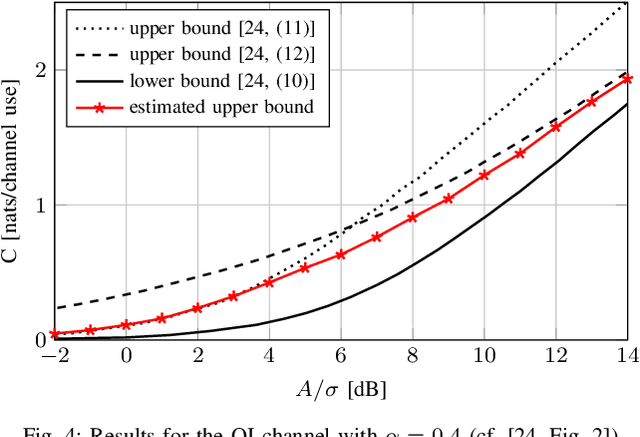
We consider the problem of estimating an upper bound on the capacity of a memoryless channel with unknown channel law and continuous output alphabet. A novel data-driven algorithm is proposed that exploits the dual representation of capacity where the maximization over the input distribution is replaced with a minimization over a reference distribution on the channel output. To efficiently compute the required divergence maximization between the conditional channel and the reference distribution, we use a modified mutual information neural estimator that takes the channel input as an additional parameter. We evaluate our approach on different memoryless channels and show that the estimated upper bounds closely converge either to the channel capacity or to best-known lower bounds.
Semantic Similarity Computing for Scientific Academic Conferences fused with domain features
Mar 21, 2022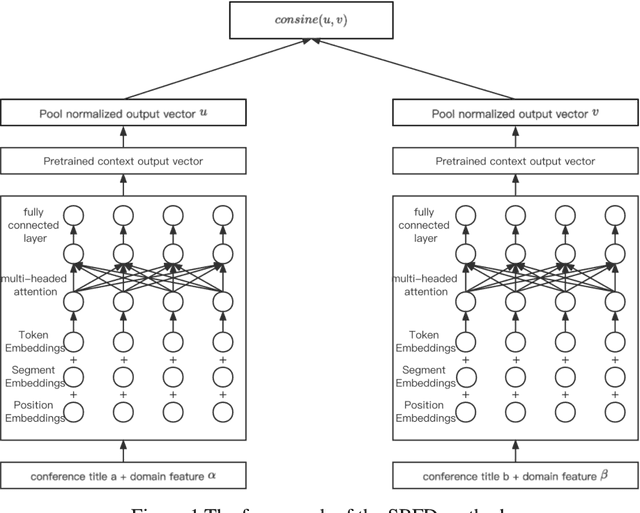
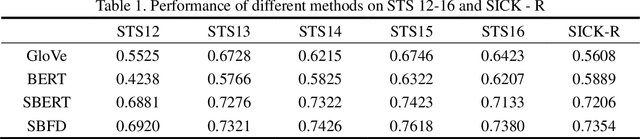
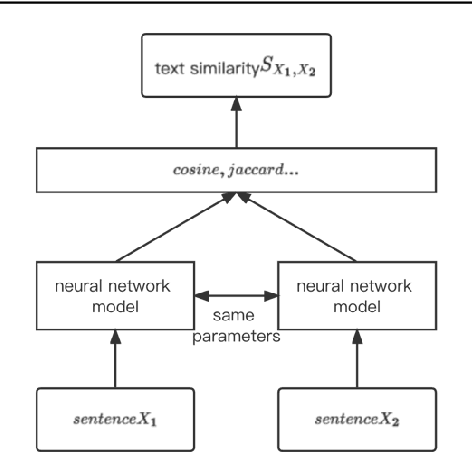
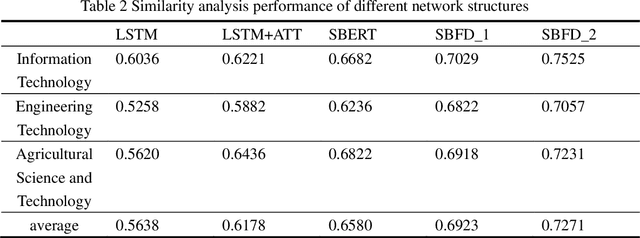
Aiming at the problem that the current general-purpose semantic text similarity calculation methods are difficult to use the semantic information of scientific academic conference data, a semantic similarity calculation algorithm for scientific academic conferences by fusion with domain features is proposed. First, the domain feature information of the conference is obtained through entity recognition and keyword extraction, and it is input into the BERT network as a feature and the conference information. The structure of the Siamese network is used to solve the anisotropy problem of BERT. The output of the network is pooled and normalized, and finally the cosine similarity is used to calculate the similarity between the two sessions. Experimental results show that the SBFD algorithm has achieved good results on different data sets, and the Spearman correlation coefficient has a certain improvement compared with the comparison algorithm.
Improved and Efficient Text Adversarial Attacks using Target Information
Apr 27, 2021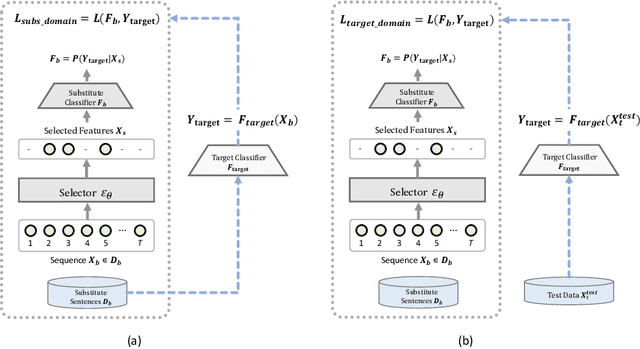
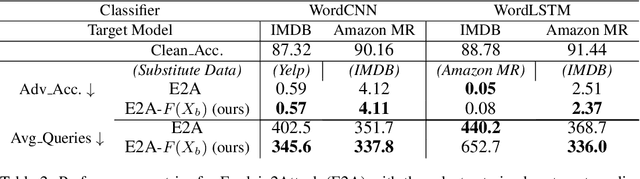
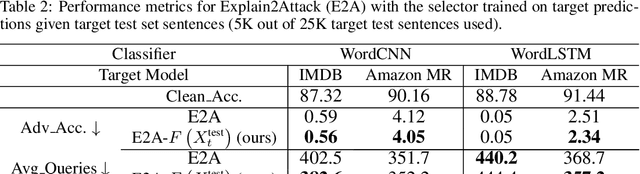
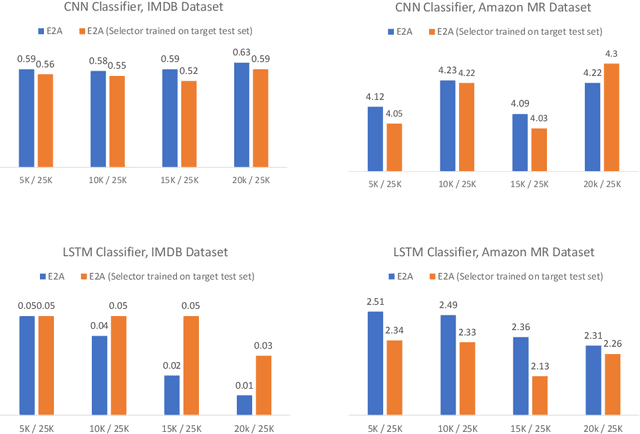
There has been recently a growing interest in studying adversarial examples on natural language models in the black-box setting. These methods attack natural language classifiers by perturbing certain important words until the classifier label is changed. In order to find these important words, these methods rank all words by importance by querying the target model word by word for each input sentence, resulting in high query inefficiency. A new interesting approach was introduced that addresses this problem through interpretable learning to learn the word ranking instead of previous expensive search. The main advantage of using this approach is that it achieves comparable attack rates to the state-of-the-art methods, yet faster and with fewer queries, where fewer queries are desirable to avoid suspicion towards the attacking agent. Nonetheless, this approach sacrificed the useful information that could be leveraged from the target classifier for that sake of query efficiency. In this paper we study the effect of leveraging the target model outputs and data on both attack rates and average number of queries, and we show that both can be improved, with a limited overhead of additional queries.
RoSGAS: Adaptive Social Bot Detection with Reinforced Self-Supervised GNN Architecture Search
Jun 14, 2022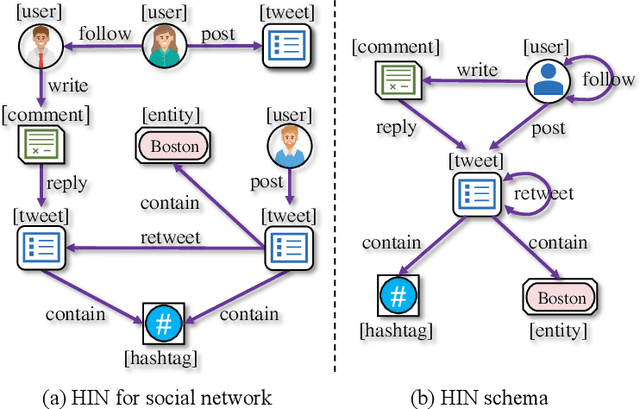
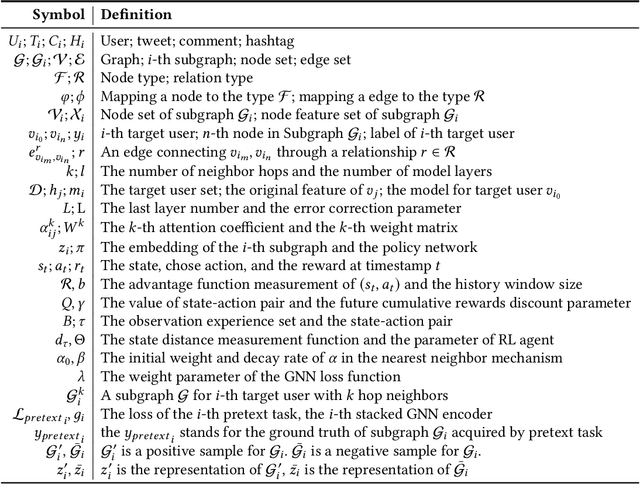
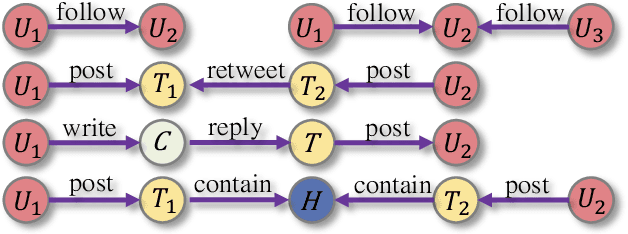
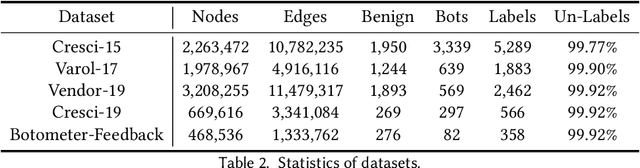
Social bots are referred to as the automated accounts on social networks that make attempts to behave like human. While Graph Neural Networks (GNNs) has been massively applied to the field of social bot detection, a huge amount of domain expertise and prior knowledge is heavily engaged in the state-of-the art approaches to design a dedicated neural network architecture for a specific classification task. Involving oversized nodes and network layers in the model design, however, usually causes the over-smoothing problem and the lack of embedding discrimination. In this paper, we propose RoSGAS, a novel Reinforced and Self-supervised GNN Architecture Search framework to adaptively pinpoint the most suitable multi-hop neighborhood and the number of layers in the GNN architecture. More specifically, we consider the social bot detection problem as a user-centric subgraph embedding and classification task. We exploit heterogeneous information network to present the user connectivity by leveraging account metadata, relationships, behavioral features and content features. RoSGAS uses a multi-agent deep reinforcement learning (RL) mechanism for navigating the search of optimal neighborhood and network layers to learn individually the subgraph embedding for each target user. A nearest neighbor mechanism is developed for accelerating the RL training process, and RoSGAS can learn more discriminative subgraph embedding with the aid of self-supervised learning. Experiments on 5 Twitter datasets show that RoSGAS outperforms the state-of-the-art approaches in terms of accuracy, training efficiency and stability, and has better generalization when handling unseen samples.
Deep Convolutional Sparse Coding Network for Pansharpening with Guidance of Side Information
Mar 10, 2021
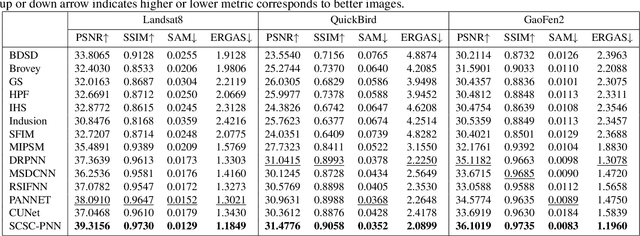
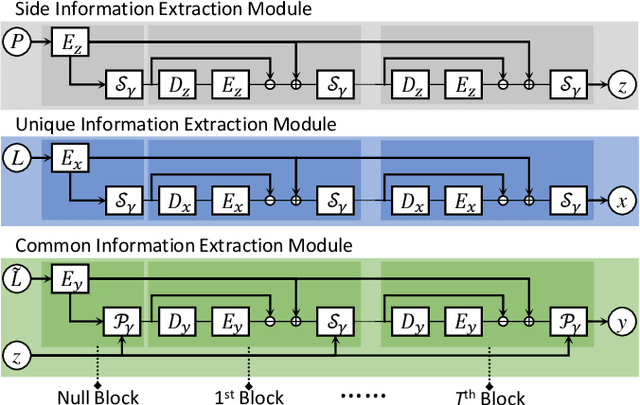
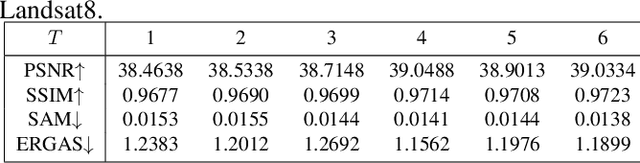
Pansharpening is a fundamental issue in remote sensing field. This paper proposes a side information partially guided convolutional sparse coding (SCSC) model for pansharpening. The key idea is to split the low resolution multispectral image into a panchromatic image related feature map and a panchromatic image irrelated feature map, where the former one is regularized by the side information from panchromatic images. With the principle of algorithm unrolling techniques, the proposed model is generalized as a deep neural network, called as SCSC pansharpening neural network (SCSC-PNN). Compared with 13 classic and state-of-the-art methods on three satellites, the numerical experiments show that SCSC-PNN is superior to others. The codes are available at https://github.com/xsxjtu/SCSC-PNN.
Deep Reinforcement Learning Based on Location-Aware Imitation Environment for RIS-Aided mmWave MIMO Systems
May 18, 2022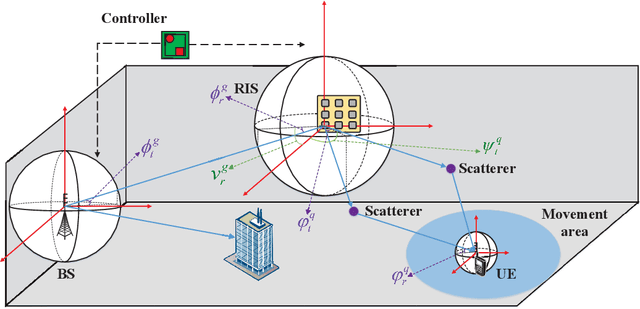
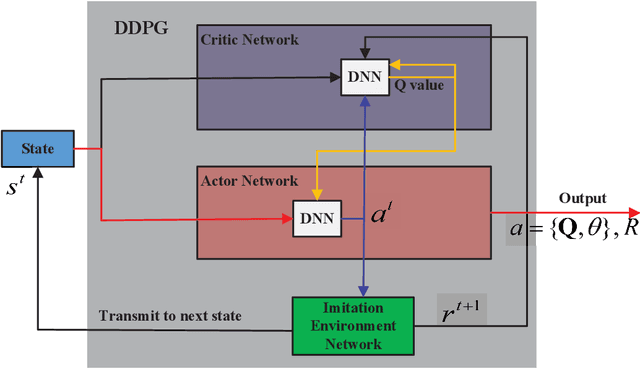
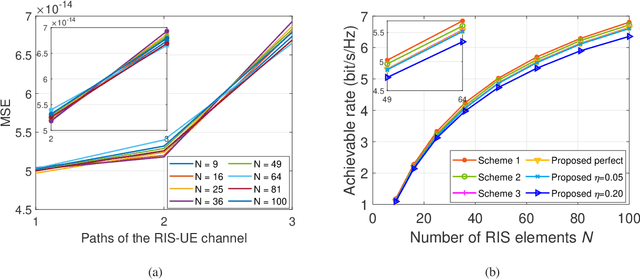
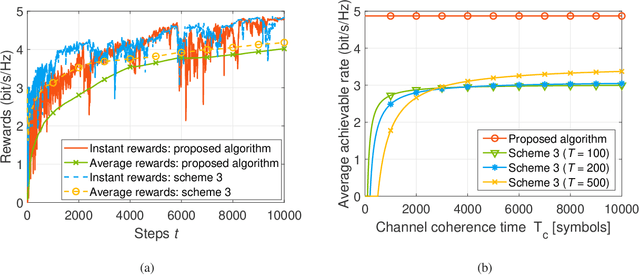
Reconfigurable intelligent surface (RIS) has recently gained popularity as a promising solution for improving the signal transmission quality of wireless communications with less hardware cost and energy consumption. This letter offers a novel deep reinforcement learning (DRL) algorithm based on a location-aware imitation environment for the joint beamforming design in an RIS-aided mmWave multiple-input multiple-output system. Specifically, we design a neural network to imitate the transmission environment based on the geometric relationship between the user's location and the mmWave channel. Following this, a novel DRL-based method is developed that interacts with the imitation environment using the easily available location information. Finally, simulation results demonstrate that the proposed DRL-based algorithm provides more robust performance without excessive interaction overhead compared to the existing DRL-based approaches.
Propose-and-Refine: A Two-Stage Set Prediction Network for Nested Named Entity Recognition
Apr 27, 2022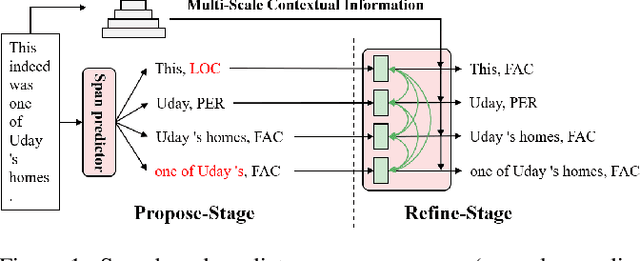
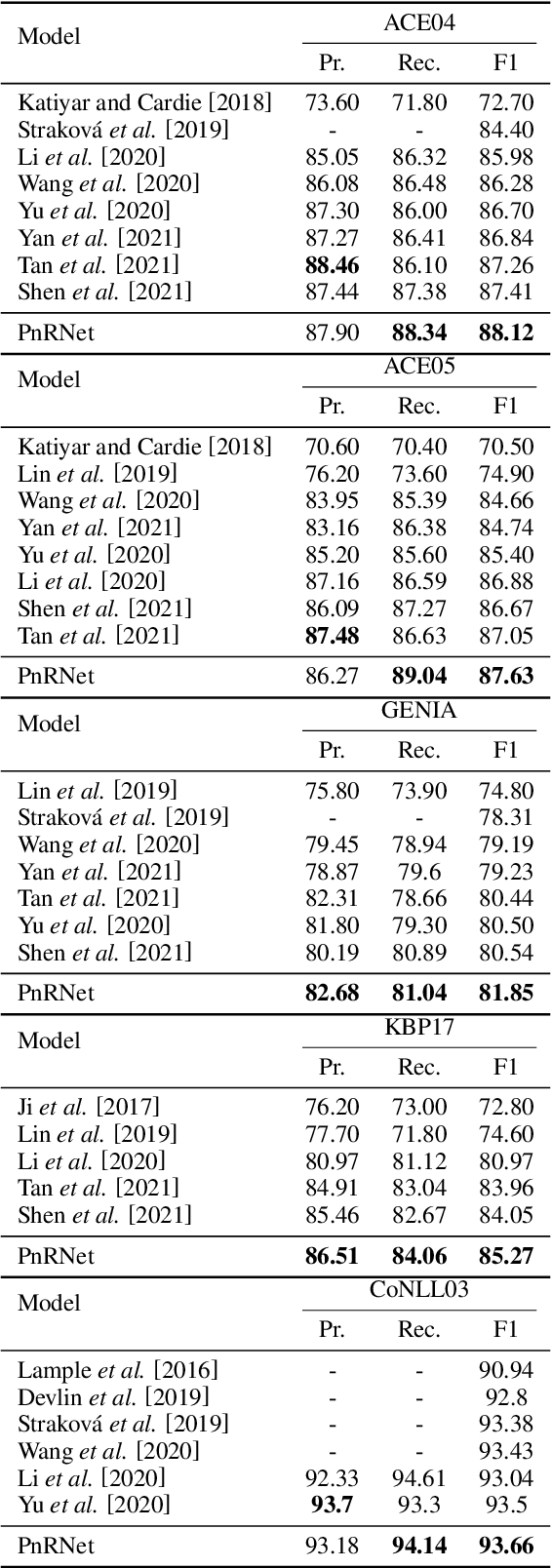
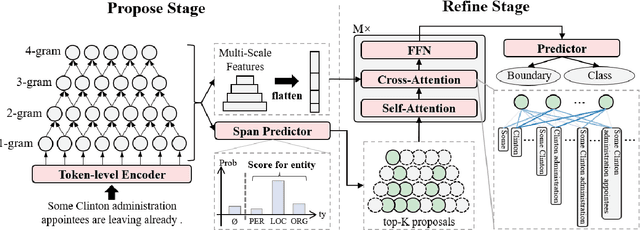

Nested named entity recognition (nested NER) is a fundamental task in natural language processing. Various span-based methods have been proposed to detect nested entities with span representations. However, span-based methods do not consider the relationship between a span and other entities or phrases, which is helpful in the NER task. Besides, span-based methods have trouble predicting long entities due to limited span enumeration length. To mitigate these issues, we present the Propose-and-Refine Network (PnRNet), a two-stage set prediction network for nested NER. In the propose stage, we use a span-based predictor to generate some coarse entity predictions as entity proposals. In the refine stage, proposals interact with each other, and richer contextual information is incorporated into the proposal representations. The refined proposal representations are used to re-predict entity boundaries and classes. In this way, errors in coarse proposals can be eliminated, and the boundary prediction is no longer constrained by the span enumeration length limitation. Additionally, we build multi-scale sentence representations, which better model the hierarchical structure of sentences and provide richer contextual information than token-level representations. Experiments show that PnRNet achieves state-of-the-art performance on four nested NER datasets and one flat NER dataset.
Speaker Diarization with Lexical Information
Apr 13, 2020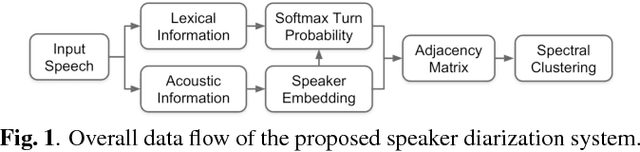
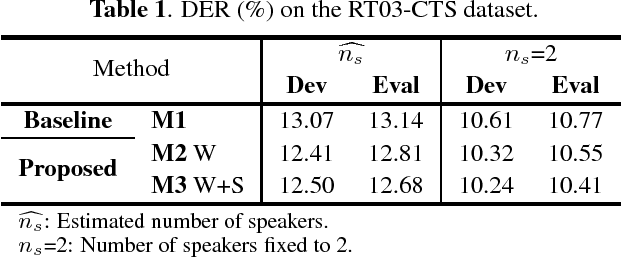
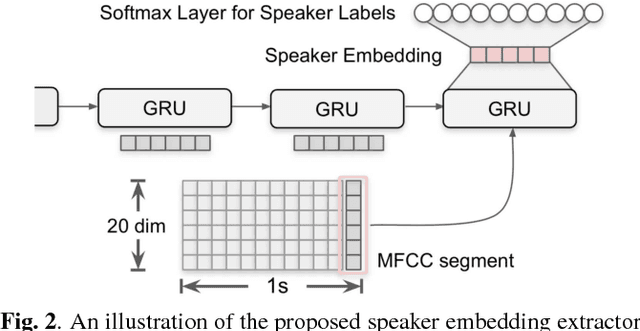
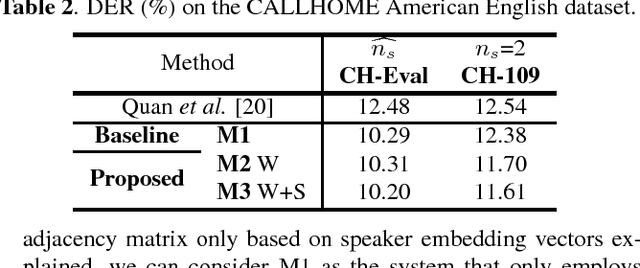
This work presents a novel approach for speaker diarization to leverage lexical information provided by automatic speech recognition. We propose a speaker diarization system that can incorporate word-level speaker turn probabilities with speaker embeddings into a speaker clustering process to improve the overall diarization accuracy. To integrate lexical and acoustic information in a comprehensive way during clustering, we introduce an adjacency matrix integration for spectral clustering. Since words and word boundary information for word-level speaker turn probability estimation are provided by a speech recognition system, our proposed method works without any human intervention for manual transcriptions. We show that the proposed method improves diarization performance on various evaluation datasets compared to the baseline diarization system using acoustic information only in speaker embeddings.
Reinforcement Learning-driven Information Seeking: A Quantum Probabilistic Approach
Aug 05, 2020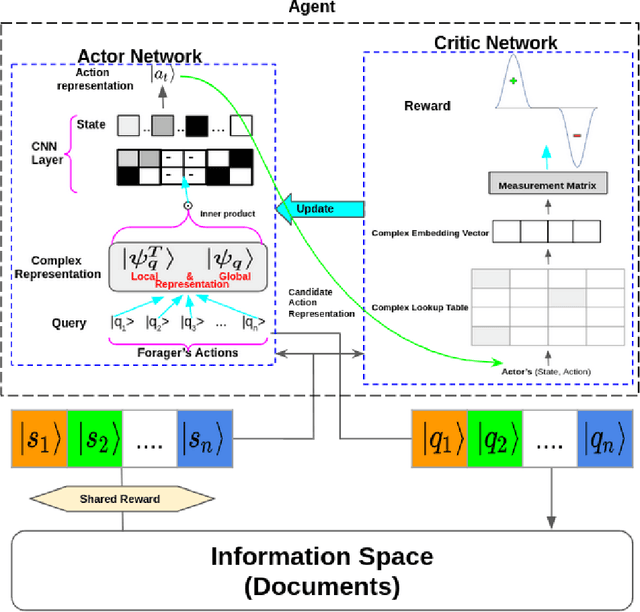
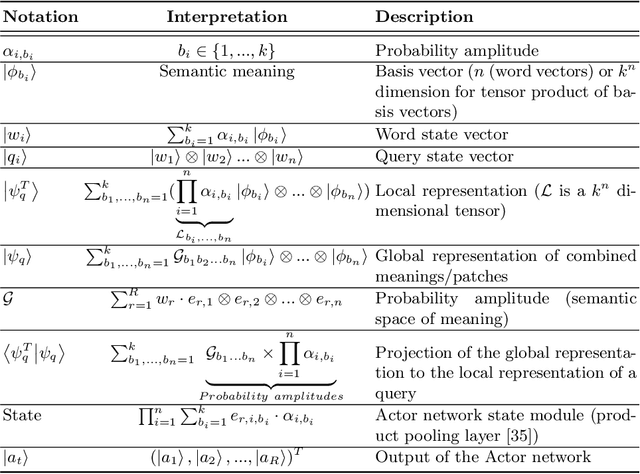
Understanding an information forager's actions during interaction is very important for the study of interactive information retrieval. Although information spread in uncertain information space is substantially complex due to the high entanglement of users interacting with information objects~(text, image, etc.). However, an information forager, in general, accompanies a piece of information (information diet) while searching (or foraging) alternative contents, typically subject to decisive uncertainty. Such types of uncertainty are analogous to measurements in quantum mechanics which follow the uncertainty principle. In this paper, we discuss information seeking as a reinforcement learning task. We then present a reinforcement learning-based framework to model forager exploration that treats the information forager as an agent to guide their behaviour. Also, our framework incorporates the inherent uncertainty of the foragers' action using the mathematical formalism of quantum mechanics.
When Is Partially Observable Reinforcement Learning Not Scary?
Apr 19, 2022Applications of Reinforcement Learning (RL), in which agents learn to make a sequence of decisions despite lacking complete information about the latent states of the controlled system, that is, they act under partial observability of the states, are ubiquitous. Partially observable RL can be notoriously difficult -- well-known information-theoretic results show that learning partially observable Markov decision processes (POMDPs) requires an exponential number of samples in the worst case. Yet, this does not rule out the existence of large subclasses of POMDPs over which learning is tractable. In this paper we identify such a subclass, which we call weakly revealing POMDPs. This family rules out the pathological instances of POMDPs where observations are uninformative to a degree that makes learning hard. We prove that for weakly revealing POMDPs, a simple algorithm combining optimism and Maximum Likelihood Estimation (MLE) is sufficient to guarantee polynomial sample complexity. To the best of our knowledge, this is the first provably sample-efficient result for learning from interactions in overcomplete POMDPs, where the number of latent states can be larger than the number of observations.