 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TC-Net: Triple Context Network for Automated Stroke Lesion Segmentation
Feb 28, 2022
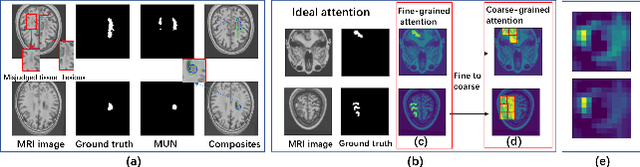
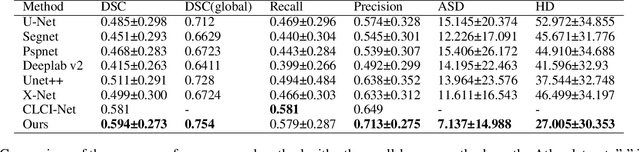
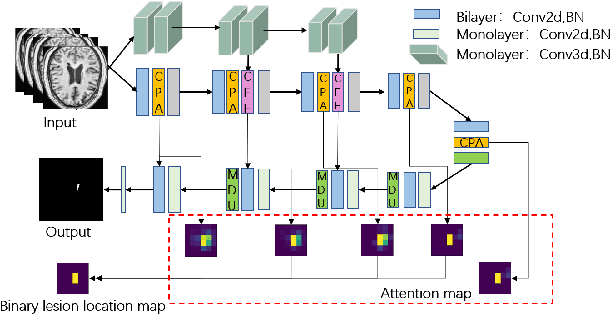

Accurate lesion segmentation plays a key role in the clinical mapping of stroke. Convolutional neural network (CNN) approaches based on U-shaped structures have achieved remarkable performance in this task. However, the single-stage encoder-decoder unresolvable the inter-class similarity due to the inadequate utilization of contextual information, such as lesion-tissue similarity. In addition, most approaches use fine-grained spatial attention to capture spatial context information, yet fail to generate accurate attention maps in encoding stage and lack effective regularization. In this work, we propose a new network, Triple Context Network (TC-Net), with the capture of spatial contextual information as the core. We firstly design a coarse-grained patch attention module to generate patch-level attention maps in the encoding stage to distinguish targets from patches and learn target-specific detail features. Then, to enrich the representation of boundary information of these features, a cross-feature fusion module with global contextual information is explored to guide the selective aggregation of 2D and 3D feature maps, which compensates for the lack of boundary learning capability of 2D convolution. Finally, we use multi-scale deconvolution instead of linear interpolation to enhance the recovery of target space and boundary information in the decoding stage. Our network is evaluated on the open dataset ATLAS, achieving the highest DSC score of 0.594, Hausdorff distance of 27.005 mm, and average symmetry surface distance of 7.137 mm, where our proposed method outperforms other state-of-the-art methods.
End-to-end Optimization of Machine Learning Prediction Queries
May 31, 2022
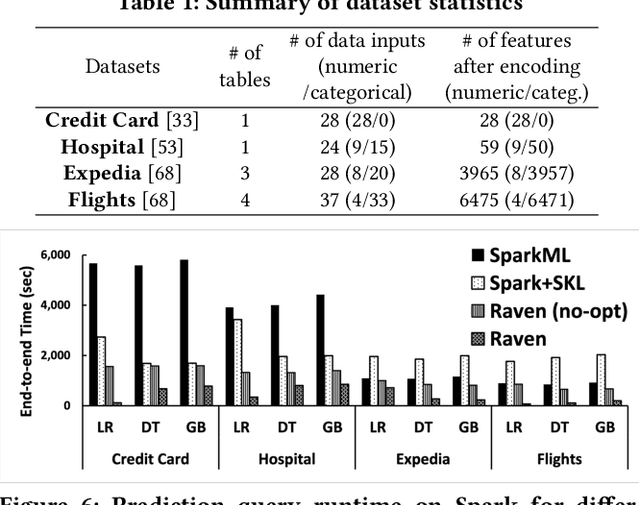
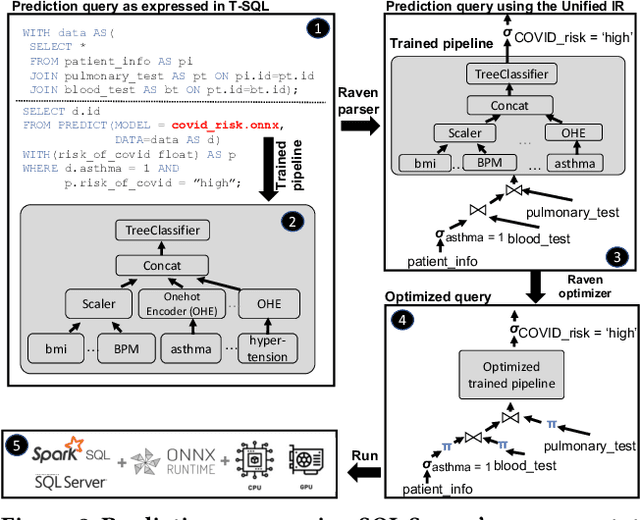
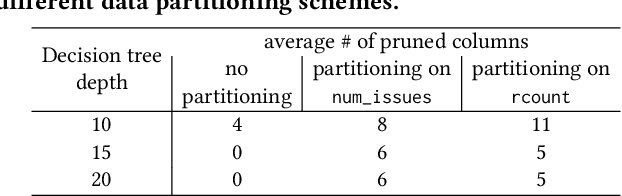
Prediction queries are widely used across industries to perform advanced analytics and draw insights from data. They include a data processing part (e.g., for joining, filtering, cleaning, featurizing the datasets) and a machine learning (ML) part invoking one or more trained models to perform predictions. These parts have so far been optimized in isolation, leaving significant opportunities for optimization unexplored. We present Raven, a production-ready system for optimizing prediction queries. Raven follows the enterprise architectural trend of collocating data and ML runtimes. It relies on a unified intermediate representation that captures both data and ML operators in a single graph structure to unlock two families of optimizations. First, it employs logical optimizations that pass information between the data part (and the properties of the underlying data) and the ML part to optimize each other. Second, it introduces logical-to-physical transformations that allow operators to be executed on different runtimes (relational, ML, and DNN) and hardware (CPU, GPU). Novel data-driven optimizations determine the runtime to be used for each part of the query to achieve optimal performance. Our evaluation shows that Raven improves performance of prediction queries on Apache Spark and SQL Server by up to 13.1x and 330x, respectively. For complex models where GPU acceleration is beneficial, Raven provides up to 8x speedup compared to state-of-the-art systems.
Observation Site Selection for Physical Model Parameter Estimation toward Process-Driven Seismic Wavefield Reconstruction
Jun 09, 2022
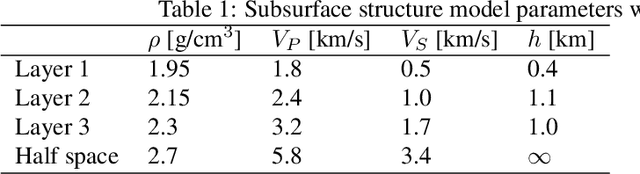
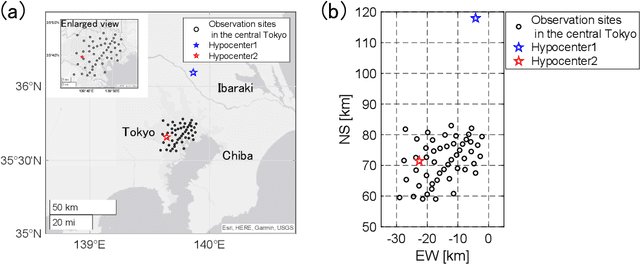
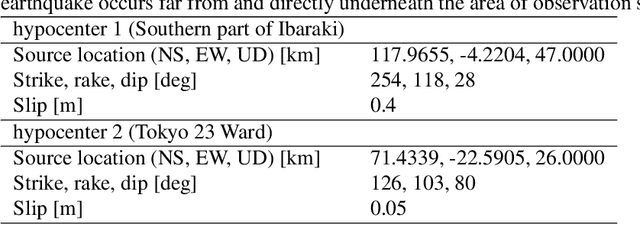
The seismic data not only acquired by seismometers but also acquired by vibrometers installed in buildings and infrastructure and accelerometers installed in smartphones will be certainly utilized for seismic research in the near future. Since it is impractical to utilize all the seismic big data in terms of the computational cost, methods which can select observation sites depending on the purpose are indispensable. We propose an observation site selection method for the accurate reconstruction of the seismic wavefield by process-driven approaches. The proposed method selects observation sites suitable for accurately estimating physical model parameters such as subsurface structures and source information to be input into a numerical simulation of the seismic wavefield. The seismic wavefield is reconstructed by the numerical simulation using the parameters estimated based on the observed signals at only observation sites selected by the proposed method. The observation site selection in the proposed method is based on the sensitivity of each observation site candidate to the physical model parameters; the matrix corresponding to the sensitivity is constructed by approximately calculating the derivatives based on the simulations, and then, observation sites are selected by evaluating the quantity of the sensitivity matrix based on the D-optimality criterion proposed in the optimal design of experiments. In the present study, physical knowledge on the sensitivity to the parameters such as seismic velocity, layer thickness, and hypocenter location was obtained by investigating the characteristics of the sensitivity matrix. Furthermore, the effectiveness of the proposed method was shown by verifying the accuracy of seismic wavefield reconstruction using the observation sites selected by the proposed method.
Policy Optimization for Markov Games: Unified Framework and Faster Convergence
Jun 06, 2022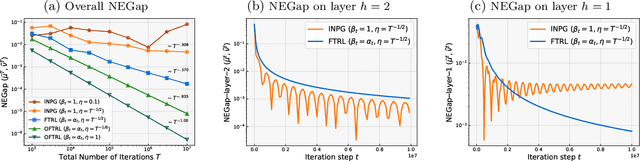
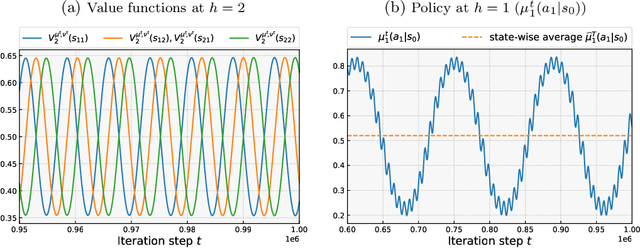
This paper studies policy optimization algorithms for multi-agent reinforcement learning. We begin by proposing an algorithm framework for two-player zero-sum Markov Games in the full-information setting, where each iteration consists of a policy update step at each state using a certain matrix game algorithm, and a value update step with a certain learning rate. This framework unifies many existing and new policy optimization algorithms. We show that the state-wise average policy of this algorithm converges to an approximate Nash equilibrium (NE) of the game, as long as the matrix game algorithms achieve low weighted regret at each state, with respect to weights determined by the speed of the value updates. Next, we show that this framework instantiated with the Optimistic Follow-The-Regularized-Leader (OFTRL) algorithm at each state (and smooth value updates) can find an $\mathcal{\widetilde{O}}(T^{-5/6})$ approximate NE in $T$ iterations, which improves over the current best $\mathcal{\widetilde{O}}(T^{-1/2})$ rate of symmetric policy optimization type algorithms. We also extend this algorithm to multi-player general-sum Markov Games and show an $\mathcal{\widetilde{O}}(T^{-3/4})$ convergence rate to Coarse Correlated Equilibria (CCE). Finally, we provide a numerical example to verify our theory and investigate the importance of smooth value updates, and find that using "eager" value updates instead (equivalent to the independent natural policy gradient algorithm) may significantly slow down the convergence, even on a simple game with $H=2$ layers.
Gender and Racial Stereotype Detection in Legal Opinion Word Embeddings
Apr 12, 2022
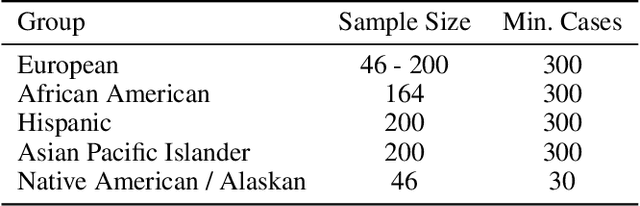
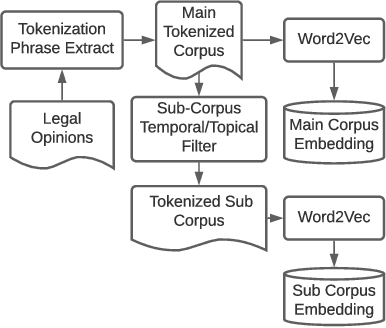

Studies have shown that some Natural Language Processing (NLP) systems encode and replicate harmful biases with potential adverse ethical effects in our society. In this article, we propose an approach for identifying gender and racial stereotypes in word embeddings trained on judicial opinions from U.S. case law. Embeddings containing stereotype information may cause harm when used by downstream systems for classification, information extraction, question answering, or other machine learning systems used to build legal research tools. We first explain how previously proposed methods for identifying these biases are not well suited for use with word embeddings trained on legal opinion text. We then propose a domain adapted method for identifying gender and racial biases in the legal domain. Our analyses using these methods suggest that racial and gender biases are encoded into word embeddings trained on legal opinions. These biases are not mitigated by exclusion of historical data, and appear across multiple large topical areas of the law. Implications for downstream systems that use legal opinion word embeddings and suggestions for potential mitigation strategies based on our observations are also discussed.
End-to-End Multimodal Fact-Checking and Explanation Generation: A Challenging Dataset and Models
May 25, 2022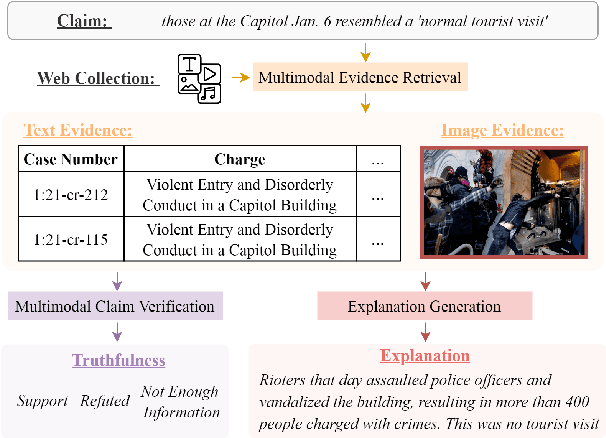
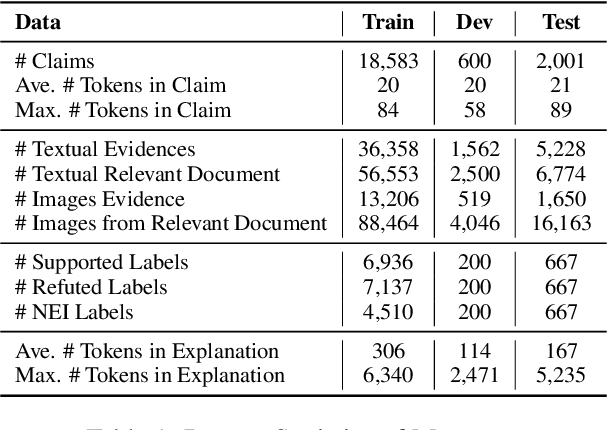
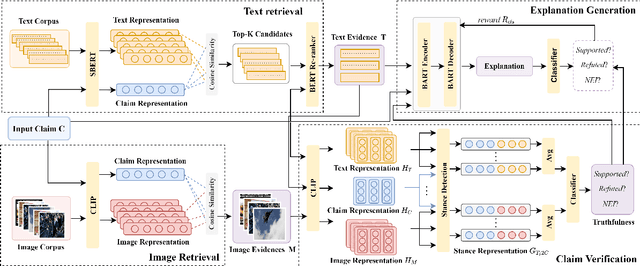
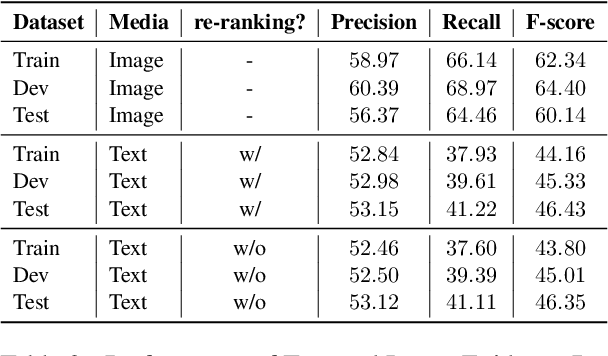
We propose the end-to-end multimodal fact-checking and explanation generation, where the input is a claim and a large collection of web sources, including articles, images, videos, and tweets, and the goal is to assess the truthfulness of the claim by retrieving relevant evidence and predicting a truthfulness label (i.e., support, refute and not enough information), and generate a rationalization statement to explain the reasoning and ruling process. To support this research, we construct Mocheg, a large-scale dataset that consists of 21,184 claims where each claim is assigned with a truthfulness label and ruling statement, with 58,523 evidence in the form of text and images. To establish baseline performances on Mocheg, we experiment with several state-of-the-art neural architectures on the three pipelined subtasks: multimodal evidence retrieval, claim verification, and explanation generation, and demonstrate the current state-of-the-art performance of end-to-end multimodal fact-checking is still far from satisfying. To the best of our knowledge, we are the first to build the benchmark dataset and solutions for end-to-end multimodal fact-checking and justification.
Conditional Mutual Information Bound for Meta Generalization Gap
Oct 21, 2020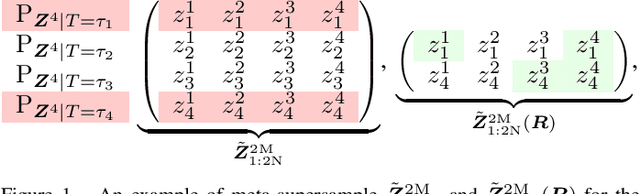
Meta-learning infers an inductive bias---typically in the form of the hyperparameters of a base-learning algorithm---by observing data from a finite number of related tasks. This paper presents an information-theoretic upper bound on the average meta-generalization gap that builds on the conditional mutual information (CMI) framework of Steinke and Zakynthinou (2020), which was originally developed for conventional learning. In the context of meta-learning, the CMI framework involves a training \textit{meta-supersample} obtained by first sampling $2N$ independent tasks from the task environment, and then drawing $2M$ independent training samples for each sampled task. The meta-training data fed to the meta-learner is then obtained by randomly selecting $N$ tasks from the available $2N$ tasks and $M$ training samples per task from the available $2M$ training samples per task. The resulting bound is explicit in two CMI terms, which measure the information that the meta-learner output and the base-learner output respectively provide about which training data are selected given the entire meta-supersample.
Neural Processes with Stochastic Attention: Paying more attention to the context dataset
Apr 11, 2022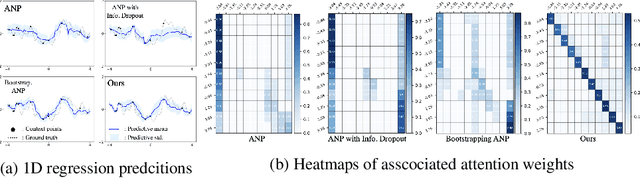
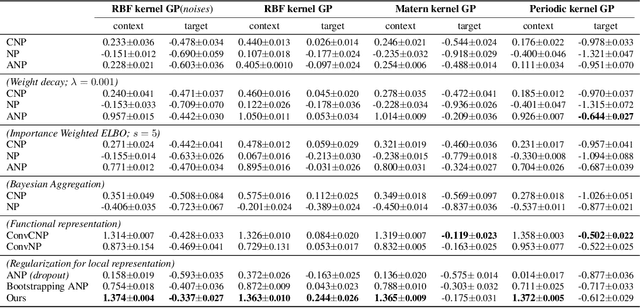
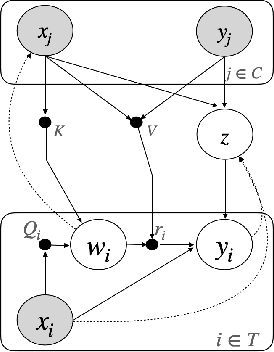
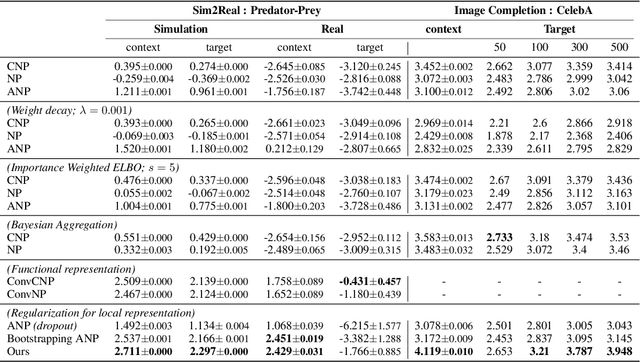
Neural processes (NPs) aim to stochastically complete unseen data points based on a given context dataset. NPs essentially leverage a given dataset as a context representation to derive a suitable identifier for a novel task. To improve the prediction accuracy, many variants of NPs have investigated context embedding approaches that generally design novel network architectures and aggregation functions satisfying permutation invariant. In this work, we propose a stochastic attention mechanism for NPs to capture appropriate context information. From the perspective of information theory, we demonstrate that the proposed method encourages context embedding to be differentiated from a target dataset, allowing NPs to consider features in a target dataset and context embedding independently. We observe that the proposed method can appropriately capture context embedding even under noisy data sets and restricted task distributions, where typical NPs suffer from a lack of context embeddings. We empirically show that our approach substantially outperforms conventional NPs in various domains through 1D regression, predator-prey model, and image completion. Moreover, the proposed method is also validated by MovieLens-10k dataset, a real-world problem.
Improving CTC-based ASR Models with Gated Interlayer Collaboration
May 25, 2022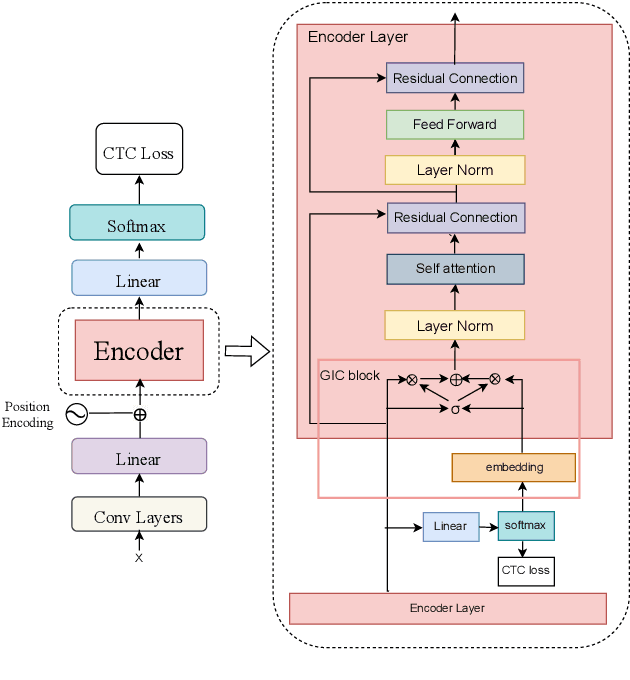
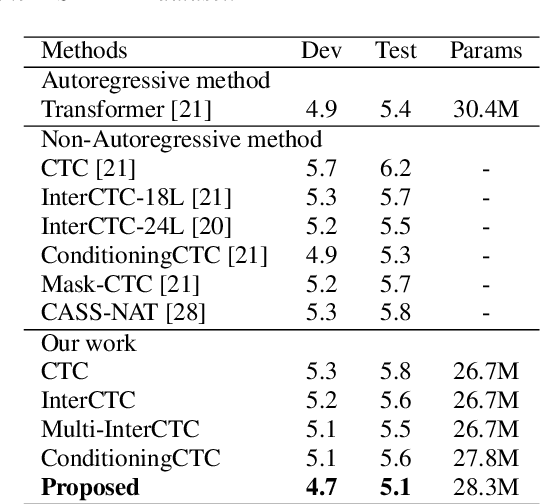
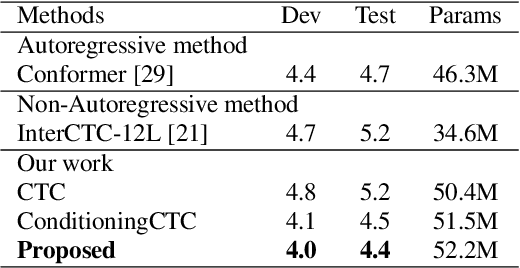
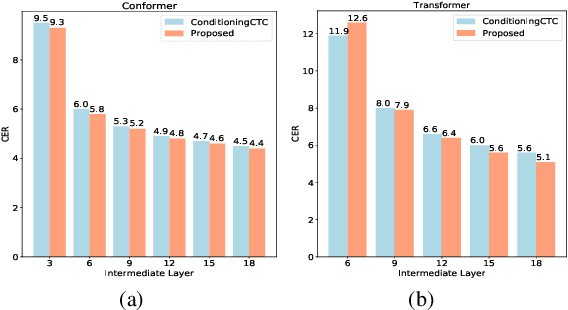
For Automatic Speech Recognition (ASR), the CTC-based methods have become a dominant paradigm due to its simple architecture and efficient non-autoregressive inference manner. However, these methods without external language models usually lack the capacity of modeling the conditional dependencies and the textual interaction. In this work, we present a Gated Interlayer Collaboration (GIC) mechanism which introduces the contextual information into the models and relaxes the conditional independence assumption of the CTC-based models. Specifically, we train the model with intermediate CTC losses calculated by the interlayer outputs of the model, in which the probability distributions of the intermediate layers naturally serve as soft label sequences. The GIC block consists of an embedding layer to obtain the textual embedding of the soft label at each position, and a gate unit to fuse the textual embedding and the acoustic features. Experiments on AISHELL-1 and AIDATATANG benchmarks show that the proposed method outperforms the recently published CTC-based ASR models. Specifically, our method achieves CER of 4.0%/4.4% on AISHELL-1 dev/test sets and CER of 3.8%/4.4% on AIDATATANG dev/test sets using CTC greedy search decoding without external language models.
Video Sentiment Analysis with Bimodal Information-augmented Multi-Head Attention
Mar 03, 2021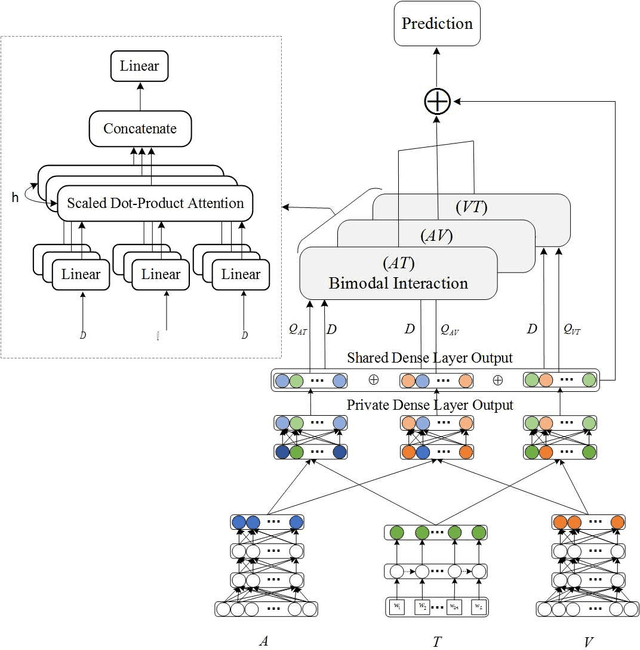
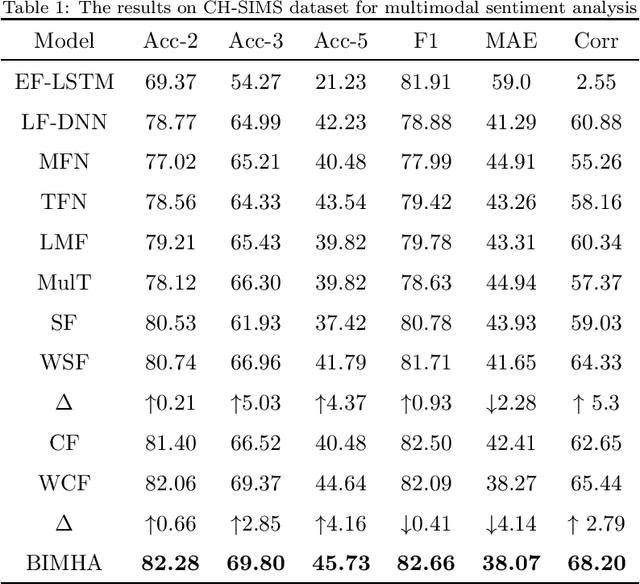
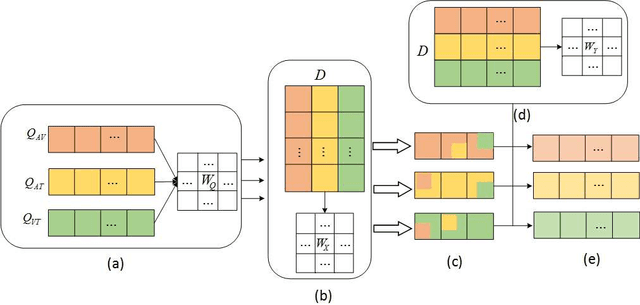
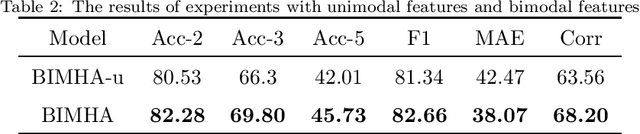
Sentiment analysis is the basis of intelligent human-computer interaction. As one of the frontier research directions of artificial intelligence, it can help computers better identify human intentions and emotional states so that provide more personalized services. However, as human present sentiments by spoken words, gestures, facial expressions and others which involve variable forms of data including text, audio, video, etc., it poses many challenges to this study. Due to the limitations of unimodal sentiment analysis, recent research has focused on the sentiment analysis of videos containing time series data of multiple modalities. When analyzing videos with multimodal data, the key problem is how to fuse these heterogeneous data. In consideration that the contribution of each modality is different, current fusion methods tend to extract the important information of single modality prior to fusion, which ignores the consistency and complementarity of bimodal interaction and has influences on the final decision. To solve this problem, a video sentiment analysis method using multi-head attention with bimodal information augmented is proposed. Based on bimodal interaction, more important bimodal features are assigned larger weights. In this way, different feature representations are adaptively assigned corresponding attention for effective multimodal fusion. Extensive experiments were conducted on both Chinese and English public datasets. The results show that our approach outperforms the existing methods and can give an insight into the contributions of bimodal interaction among three modalities.