 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
User-Centric Conversational Recommendation with Multi-Aspect User Modeling
Apr 20, 2022
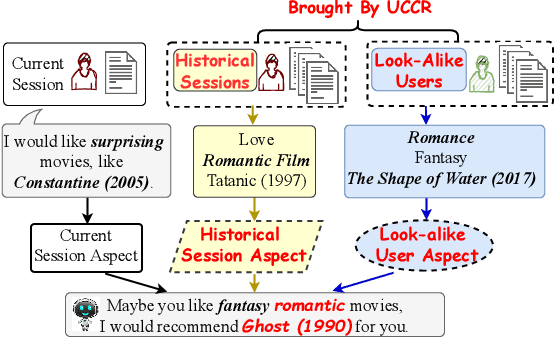
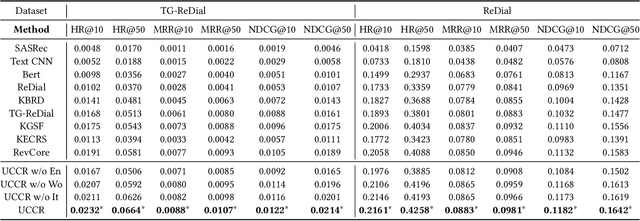
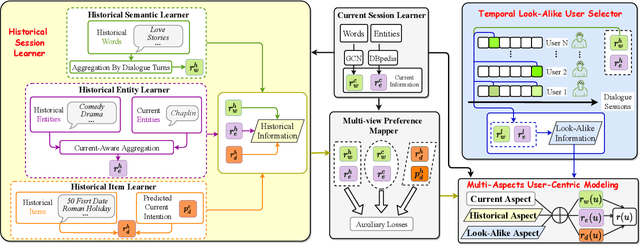
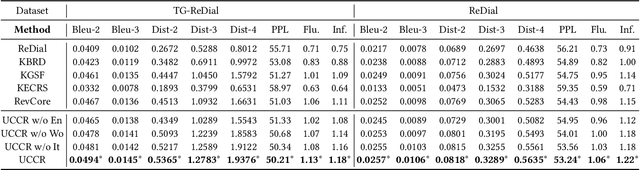
Conversational recommender systems (CRS) aim to provide highquality recommendations in conversations. However, most conventional CRS models mainly focus on the dialogue understanding of the current session, ignoring other rich multi-aspect information of the central subjects (i.e., users) in recommendation. In this work, we highlight that the user's historical dialogue sessions and look-alike users are essential sources of user preferences besides the current dialogue session in CRS. To systematically model the multi-aspect information, we propose a User-Centric Conversational Recommendation (UCCR) model, which returns to the essence of user preference learning in CRS tasks. Specifically, we propose a historical session learner to capture users' multi-view preferences from knowledge, semantic, and consuming views as supplements to the current preference signals. A multi-view preference mapper is conducted to learn the intrinsic correlations among different views in current and historical sessions via self-supervised objectives. We also design a temporal look-alike user selector to understand users via their similar users. The learned multi-aspect multi-view user preferences are then used for the recommendation and dialogue generation. In experiments, we conduct comprehensive evaluations on both Chinese and English CRS datasets. The significant improvements over competitive models in both recommendation and dialogue generation verify the superiority of UCCR.
Conditional Mutual Information Bound for Meta Generalization Gap
Oct 21, 2020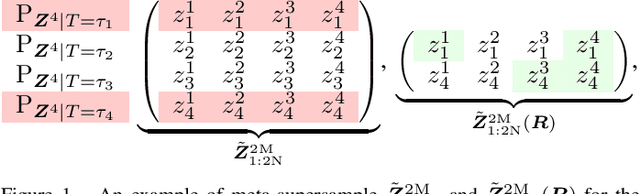
Meta-learning infers an inductive bias---typically in the form of the hyperparameters of a base-learning algorithm---by observing data from a finite number of related tasks. This paper presents an information-theoretic upper bound on the average meta-generalization gap that builds on the conditional mutual information (CMI) framework of Steinke and Zakynthinou (2020), which was originally developed for conventional learning. In the context of meta-learning, the CMI framework involves a training \textit{meta-supersample} obtained by first sampling $2N$ independent tasks from the task environment, and then drawing $2M$ independent training samples for each sampled task. The meta-training data fed to the meta-learner is then obtained by randomly selecting $N$ tasks from the available $2N$ tasks and $M$ training samples per task from the available $2M$ training samples per task. The resulting bound is explicit in two CMI terms, which measure the information that the meta-learner output and the base-learner output respectively provide about which training data are selected given the entire meta-supersample.
Do Deep Learning Models and News Headlines Outperform Conventional Prediction Techniques on Forex Data?
May 22, 2022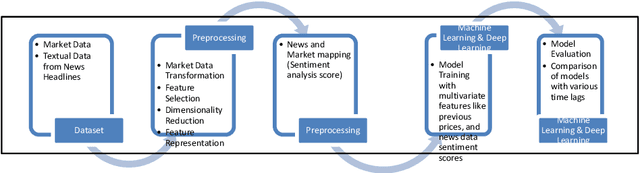

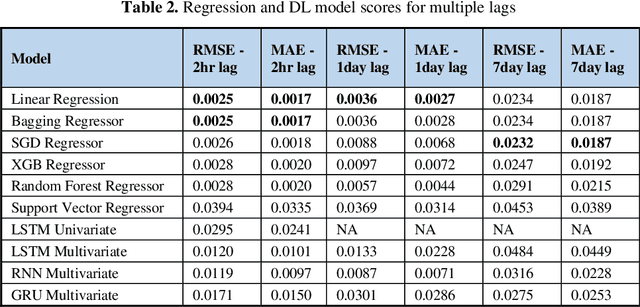
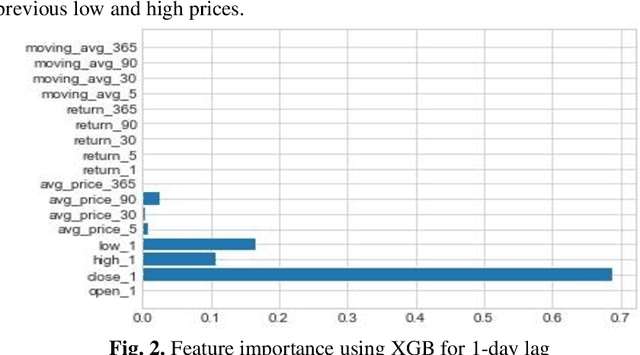
Foreign Exchange (FOREX) is a decentralised global market for exchanging currencies. The Forex market is enormous, and it operates 24 hours a day. Along with country-specific factors, Forex trading is influenced by cross-country ties and a variety of global events. Recent pandemic scenarios such as COVID19 and local elections can also have a significant impact on market pricing. We tested and compared various predictions with external elements such as news items in this work. Additionally, we compared classical machine learning methods to deep learning algorithms. We also added sentiment features from news headlines using NLP-based word embeddings and compared the performance. Our results indicate that simple regression model like linear, SGD, and Bagged performed better than deep learning models such as LSTM and RNN for single-step forecasting like the next two hours, the next day, and seven days. Surprisingly, news articles failed to improve the predictions indicating domain-based and relevant information only adds value. Among the text vectorization techniques, Word2Vec and SentenceBERT perform better.
Multi-Tree Guided Efficient Robot Motion Planning
May 18, 2022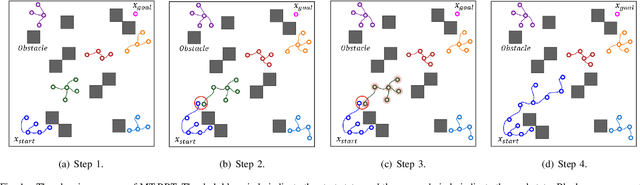
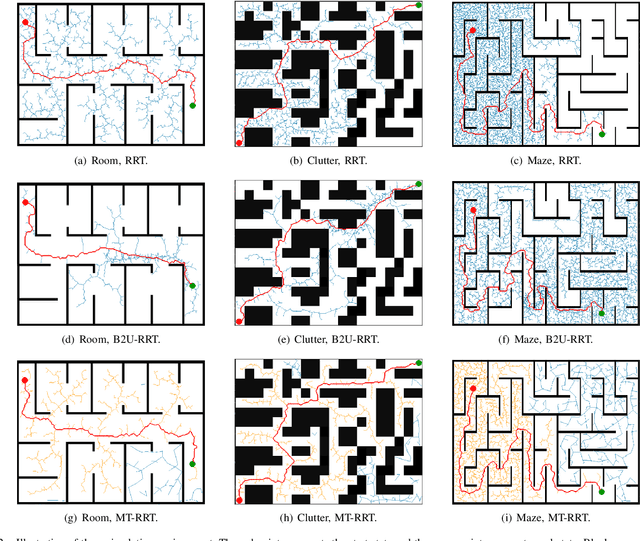
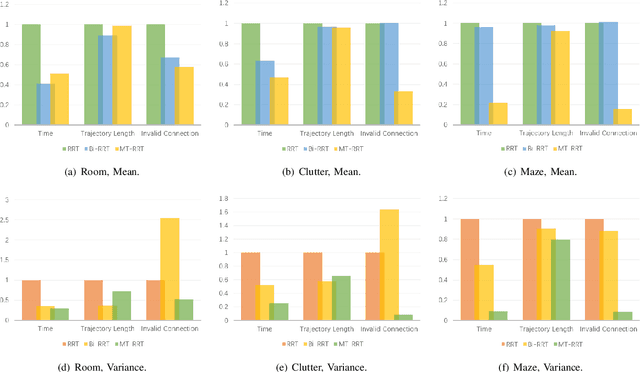
Motion Planning is necessary for robots to complete different tasks. Rapidly-exploring Random Tree (RRT) and its variants have been widely used in robot motion planning due to their fast search in state space. However, they perform not well in many complex environments since the motion planning needs to simultaneously consider the geometry constraints and differential constraints. In this article, we propose a novel robot motion planning algorithm that utilizes multi-tree to guide the exploration and exploitation. The proposed algorithm maintains more than two trees to search the state space at first. Each tree will explore the local environment. The tree starts from the root will gradually collect information from other trees and grow towards the goal state. This simultaneous exploration and exploitation method can quickly find a feasible trajectory. We compare the proposed algorithm with other popular motion planning algorithms. The experiment results demonstrate that our algorithm achieves the best performance on different evaluation metrics.
Masking Adversarial Damage: Finding Adversarial Saliency for Robust and Sparse Network
Apr 06, 2022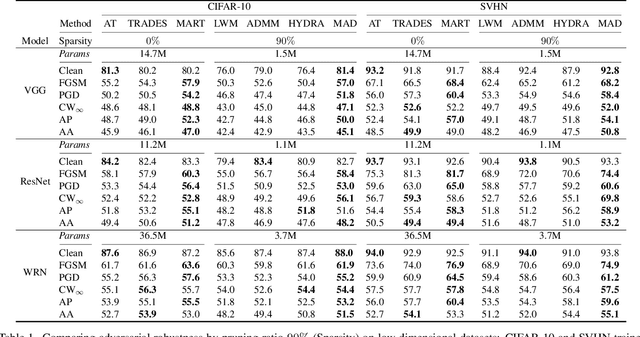
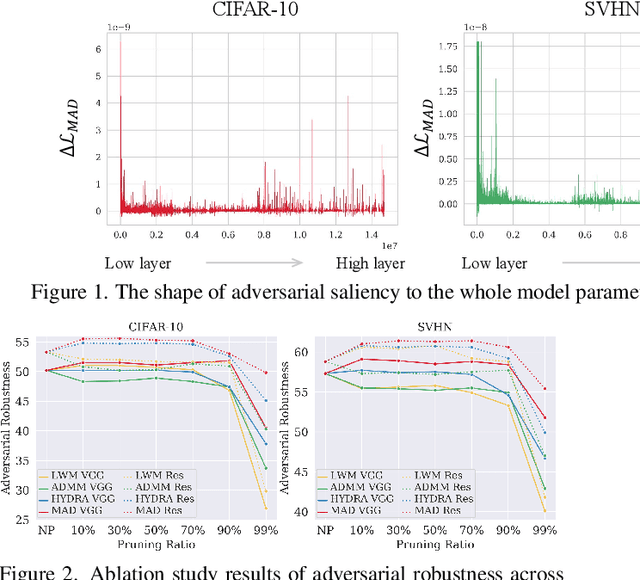
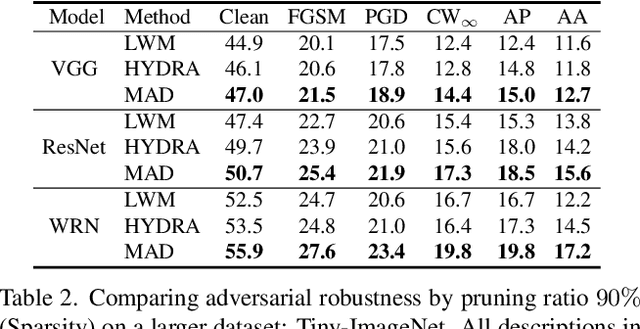
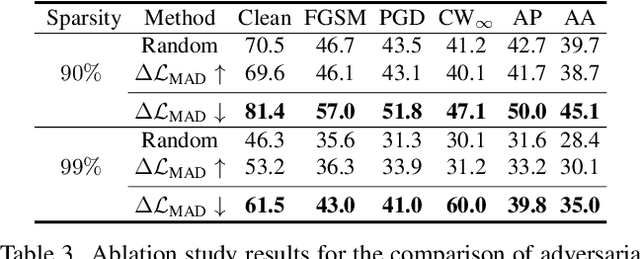
Adversarial examples provoke weak reliability and potential security issues in deep neural networks. Although adversarial training has been widely studied to improve adversarial robustness, it works in an over-parameterized regime and requires high computations and large memory budgets. To bridge adversarial robustness and model compression, we propose a novel adversarial pruning method, Masking Adversarial Damage (MAD) that employs second-order information of adversarial loss. By using it, we can accurately estimate adversarial saliency for model parameters and determine which parameters can be pruned without weakening adversarial robustness. Furthermore, we reveal that model parameters of initial layer are highly sensitive to the adversarial examples and show that compressed feature representation retains semantic information for the target objects. Through extensive experiments on three public datasets, we demonstrate that MAD effectively prunes adversarially trained networks without loosing adversarial robustness and shows better performance than previous adversarial pruning methods.
Cross-modal Clinical Graph Transformer for Ophthalmic Report Generation
Jun 04, 2022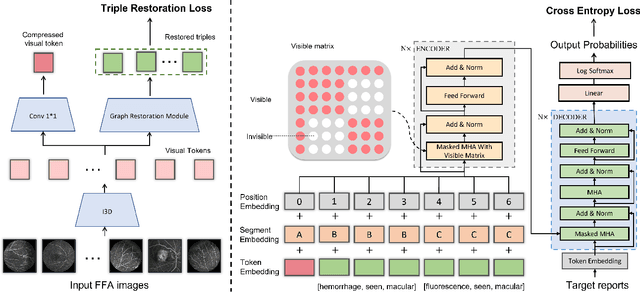

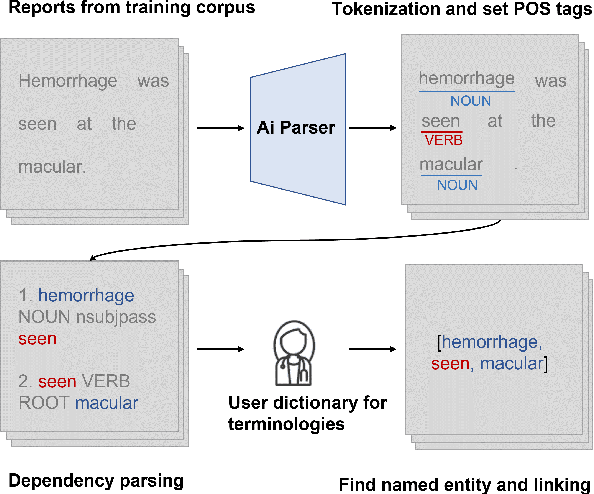
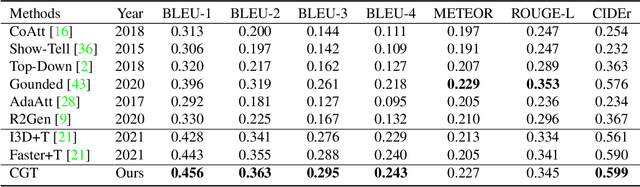
Automatic generation of ophthalmic reports using data-driven neural networks has great potential in clinical practice. When writing a report, ophthalmologists make inferences with prior clinical knowledge. This knowledge has been neglected in prior medical report generation methods. To endow models with the capability of incorporating expert knowledge, we propose a Cross-modal clinical Graph Transformer (CGT) for ophthalmic report generation (ORG), in which clinical relation triples are injected into the visual features as prior knowledge to drive the decoding procedure. However, two major common Knowledge Noise (KN) issues may affect models' effectiveness. 1) Existing general biomedical knowledge bases such as the UMLS may not align meaningfully to the specific context and language of the report, limiting their utility for knowledge injection. 2) Incorporating too much knowledge may divert the visual features from their correct meaning. To overcome these limitations, we design an automatic information extraction scheme based on natural language processing to obtain clinical entities and relations directly from in-domain training reports. Given a set of ophthalmic images, our CGT first restores a sub-graph from the clinical graph and injects the restored triples into visual features. Then visible matrix is employed during the encoding procedure to limit the impact of knowledge. Finally, reports are predicted by the encoded cross-modal features via a Transformer decoder. Extensive experiments on the large-scale FFA-IR benchmark demonstrate that the proposed CGT is able to outperform previous benchmark methods and achieve state-of-the-art performances.
Age Minimization in Outdoor and Indoor Communications with Relay-aided Dual RIS
May 06, 2022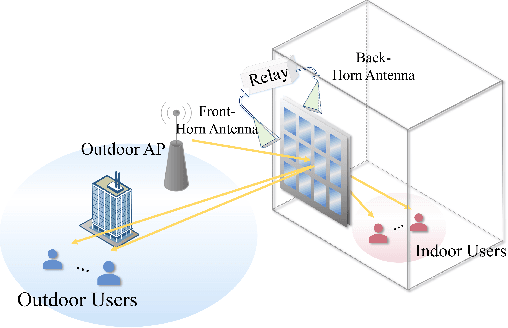

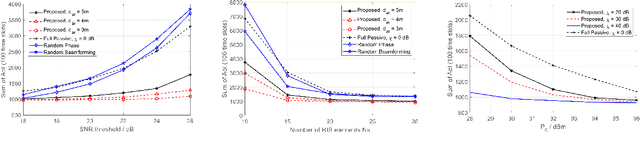
In this paper, we investigate an outdoor and indoor wireless communication network with the assistance of a novel relay-aided double-sided reconfigurable intelligent surface (RIS). A scheduling problem is considered at the outdoor access point (AP) to minimize the sum of age of information (AoI). To serve the indoor users and further enhance the wireless link quality, a novel double-sided RIS with relay is utilized. Since the formulated problem is non-convex with highly-coupled variables, a successive convex approximation (SCA) based alternating optimization (AO) algorithm is proposed to solve it in an iterative manner. Finally, simulation results show the effectiveness and significant performance improvement in terms of AoI of the proposed algorithm compared with other benchmarks.
Disentangling Spatial-Temporal Functional Brain Networks via Twin-Transformers
Apr 20, 2022

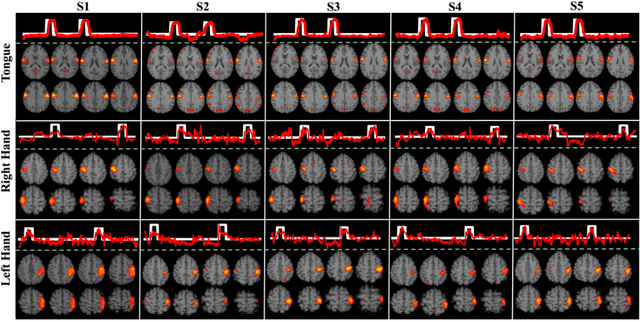
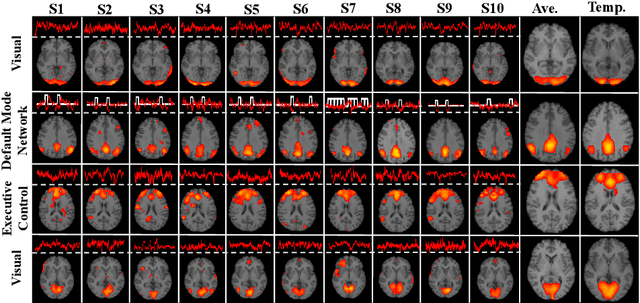
How to identify and characterize functional brain networks (BN) is fundamental to gain system-level insights into the mechanisms of brain organizational architecture. Current functional magnetic resonance (fMRI) analysis highly relies on prior knowledge of specific patterns in either spatial (e.g., resting-state network) or temporal (e.g., task stimulus) domain. In addition, most approaches aim to find group-wise common functional networks, individual-specific functional networks have been rarely studied. In this work, we propose a novel Twin-Transformers framework to simultaneously infer common and individual functional networks in both spatial and temporal space, in a self-supervised manner. The first transformer takes space-divided information as input and generates spatial features, while the second transformer takes time-related information as input and outputs temporal features. The spatial and temporal features are further separated into common and individual ones via interactions (weights sharing) and constraints between the two transformers. We applied our TwinTransformers to Human Connectome Project (HCP) motor task-fMRI dataset and identified multiple common brain networks, including both task-related and resting-state networks (e.g., default mode network). Interestingly, we also successfully recovered a set of individual-specific networks that are not related to task stimulus and only exist at the individual level.
Deep Unsupervised Image Anomaly Detection: An Information Theoretic Framework
Dec 09, 2020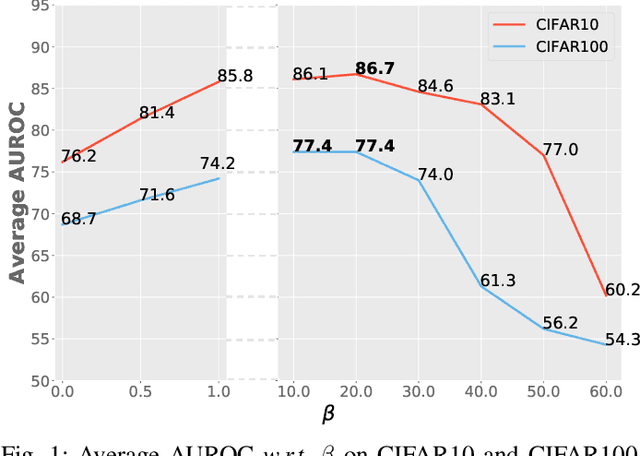
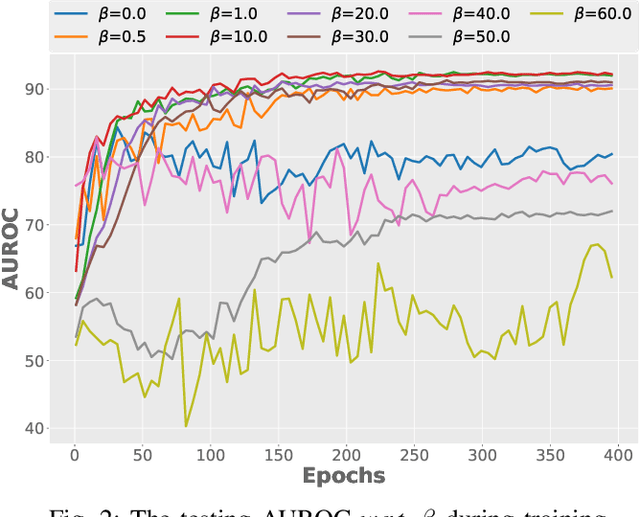
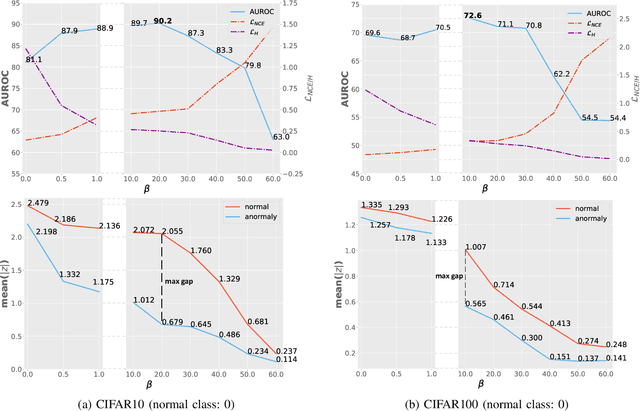
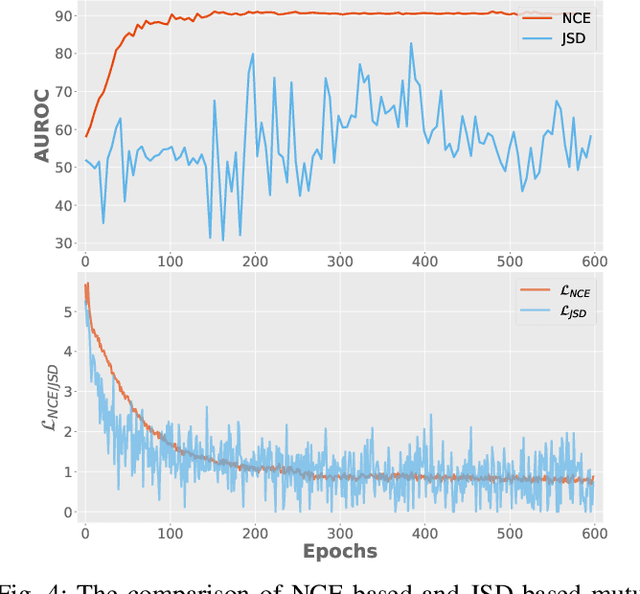
Surrogate task based methods have recently shown great promise for unsupervised image anomaly detection. However, there is no guarantee that the surrogate tasks share the consistent optimization direction with anomaly detection. In this paper, we return to a direct objective function for anomaly detection with information theory, which maximizes the distance between normal and anomalous data in terms of the joint distribution of images and their representation. Unfortunately, this objective function is not directly optimizable under the unsupervised setting where no anomalous data is provided during training. Through mathematical analysis of the above objective function, we manage to decompose it into four components. In order to optimize in an unsupervised fashion, we show that, under the assumption that distribution of the normal and anomalous data are separable in the latent space, its lower bound can be considered as a function which weights the trade-off between mutual information and entropy. This objective function is able to explain why the surrogate task based methods are effective for anomaly detection and further point out the potential direction of improvement. Based on this object function we introduce a novel information theoretic framework for unsupervised image anomaly detection. Extensive experiments have demonstrated that the proposed framework significantly outperforms several state-of-the-arts on multiple benchmark data sets.
Distributed learning optimisation of Cox models can leak patient data: Risks and solutions
Apr 12, 2022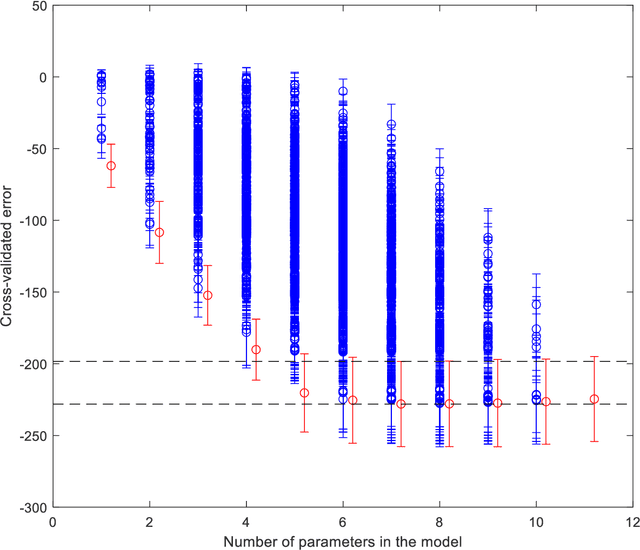
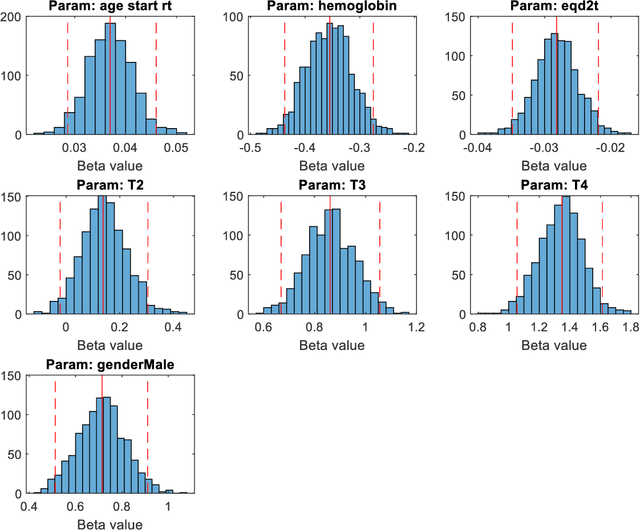
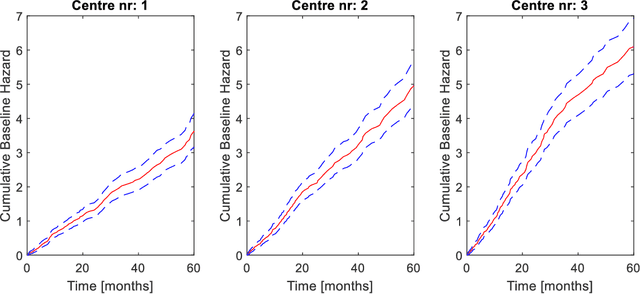
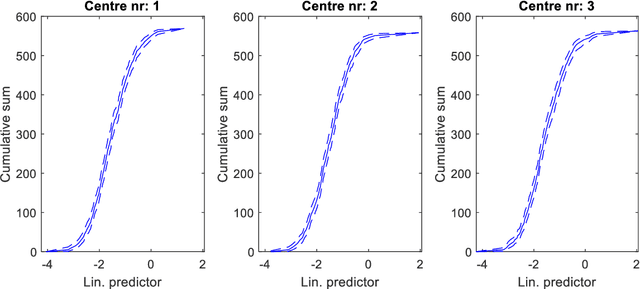
Medical data are often highly sensitive, and frequently there are missing data. Due to the data's sensitive nature, there is an interest in creating modelling methods where the data are kept in each local centre to preserve their privacy, but yet the model can be trained on and learn from data across multiple centres. Such an approach might be distributed machine learning (federated learning, collaborative learning) in which a model is iteratively calculated based on aggregated local model information from each centre. However, even though no specific data are leaving the centre, there is a potential risk that the exchanged information is sufficient to reconstruct all or part of the patient data, which would hamper the safety-protecting rationale idea of distributed learning. This paper demonstrates that the optimisation of a Cox survival model can lead to patient data leakage. Following this, we suggest a way to optimise and validate a Cox model that avoids these problems in a secure way. The feasibility of the suggested method is demonstrated in a provided Matlab code that also includes methods for handling missing data.