 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DOTIN: Dropping Task-Irrelevant Nodes for GNNs
Apr 28, 2022
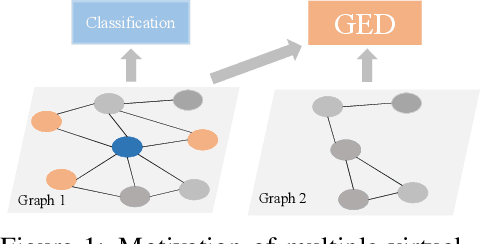

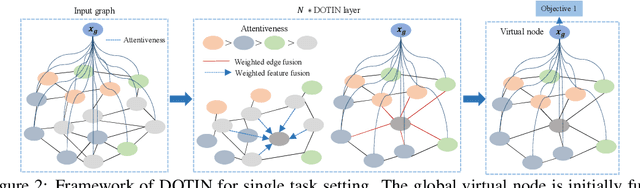

Scalability is an important consideration for deep graph neural networks. Inspired by the conventional pooling layers in CNNs, many recent graph learning approaches have introduced the pooling strategy to reduce the size of graphs for learning, such that the scalability and efficiency can be improved. However, these pooling-based methods are mainly tailored to a single graph-level task and pay more attention to local information, limiting their performance in multi-task settings which often require task-specific global information. In this paper, departure from these pooling-based efforts, we design a new approach called DOTIN (\underline{D}r\underline{o}pping \underline{T}ask-\underline{I}rrelevant \underline{N}odes) to reduce the size of graphs. Specifically, by introducing $K$ learnable virtual nodes to represent the graph embeddings targeted to $K$ different graph-level tasks, respectively, up to 90\% raw nodes with low attentiveness with an attention model -- a transformer in this paper, can be adaptively dropped without notable performance decreasing. Achieving almost the same accuracy, our method speeds up GAT by about 50\% on graph-level tasks including graph classification and graph edit distance (GED) with about 60\% less memory, on D\&D dataset. Code will be made publicly available in https://github.com/Sherrylone/DOTIN.
Linear Algorithms for Nonparametric Multiclass Probability Estimation
Jun 03, 2022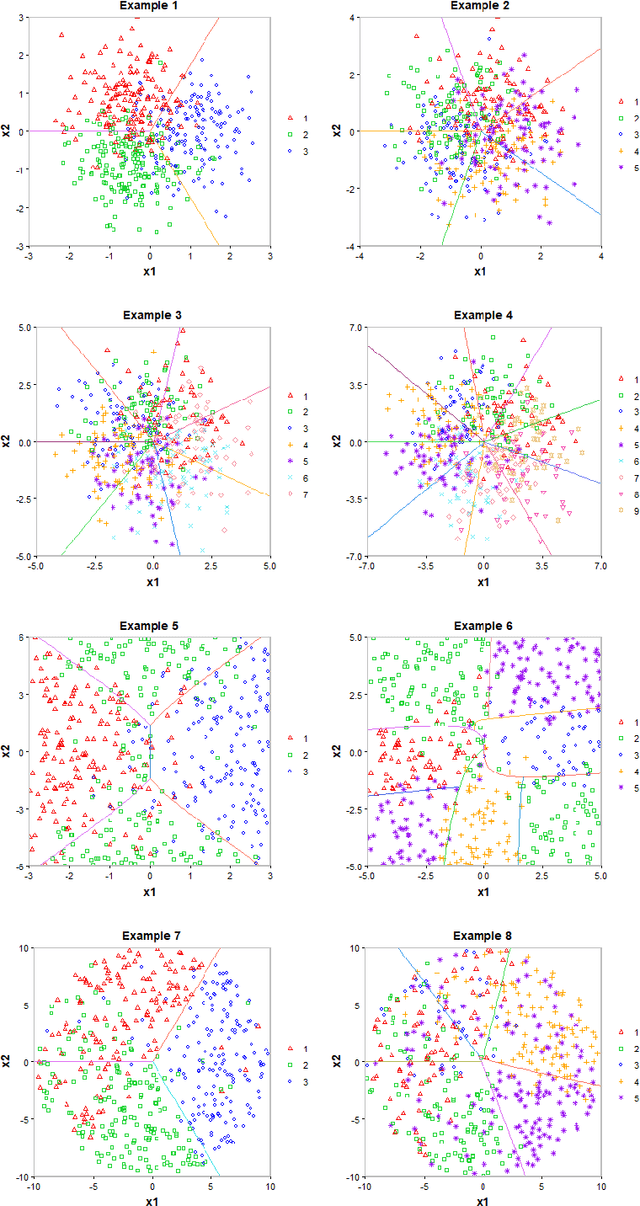
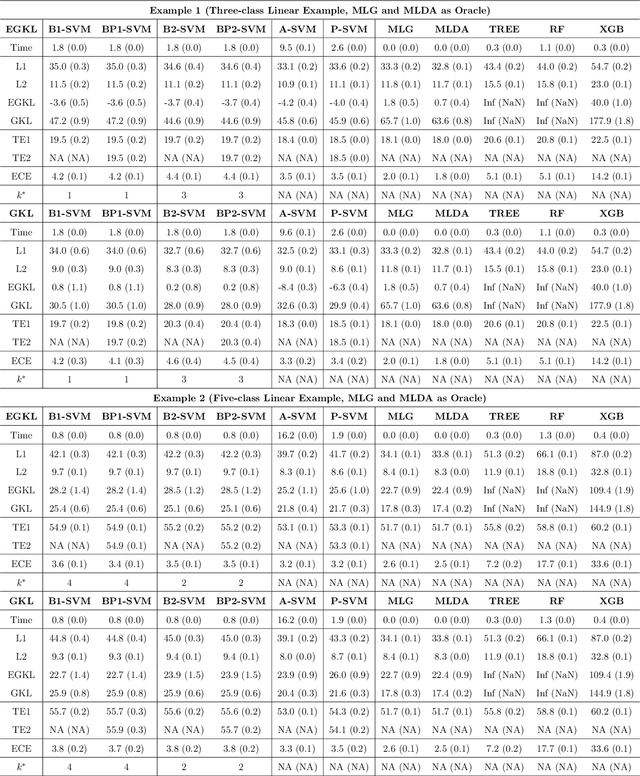
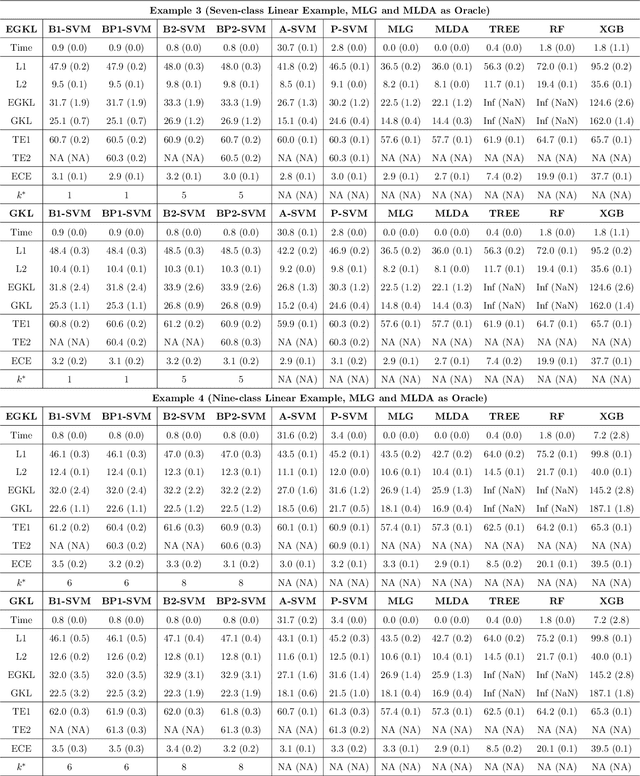
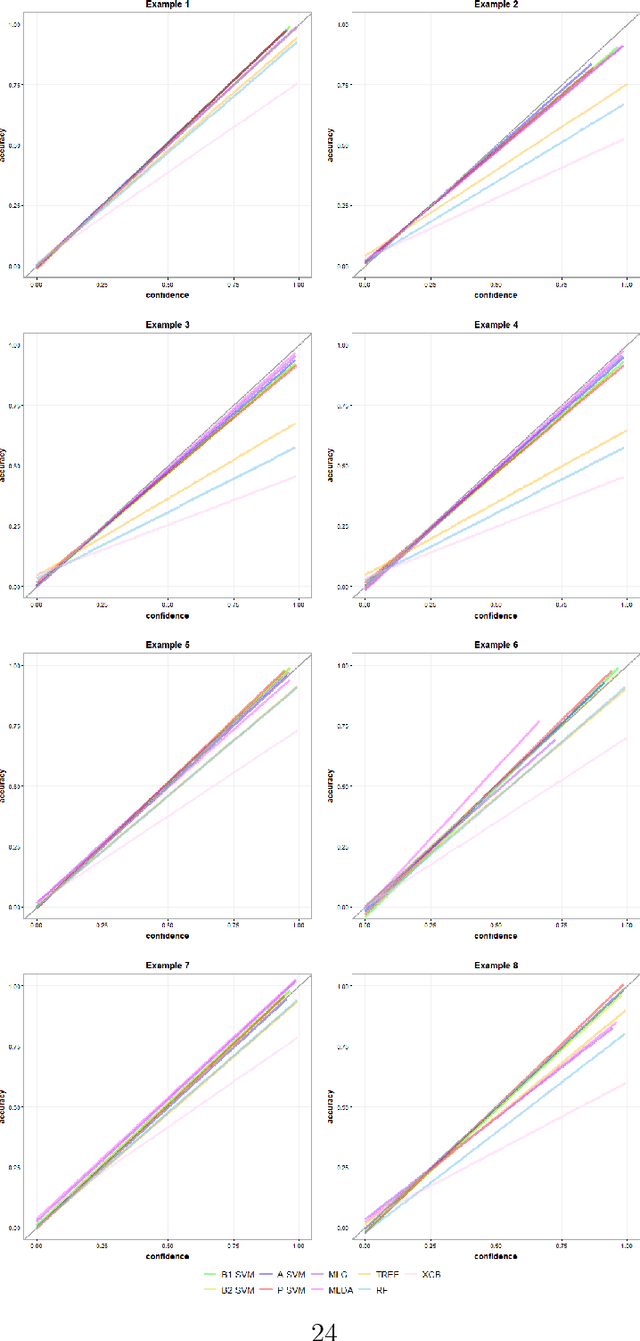
Multiclass probability estimation is the problem of estimating conditional probabilities of a data point belonging to a class given its covariate information. It has broad applications in statistical analysis and data science. Recently a class of weighted Support Vector Machines (wSVMs) has been developed to estimate class probabilities through ensemble learning for $K$-class problems (Wu, Zhang and Liu, 2010; Wang, Zhang and Wu, 2019), where $K$ is the number of classes. The estimators are robust and achieve high accuracy for probability estimation, but their learning is implemented through pairwise coupling, which demands polynomial time in $K$. In this paper, we propose two new learning schemes, the baseline learning and the One-vs-All (OVA) learning, to further improve wSVMs in terms of computational efficiency and estimation accuracy. In particular, the baseline learning has optimal computational complexity in the sense that it is linear in $K$. Though not being most efficient in computation, the OVA offers the best estimation accuracy among all the procedures under comparison. The resulting estimators are distribution-free and shown to be consistent. We further conduct extensive numerical experiments to demonstrate finite sample performance.
A Dataset for Sentence Retrieval for Open-Ended Dialogues
May 24, 2022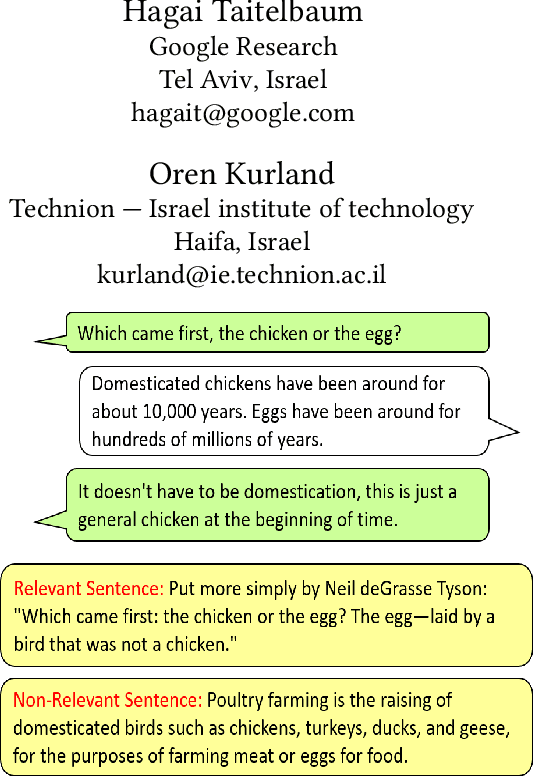

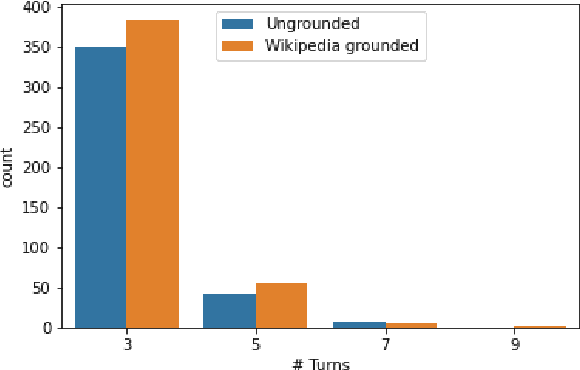
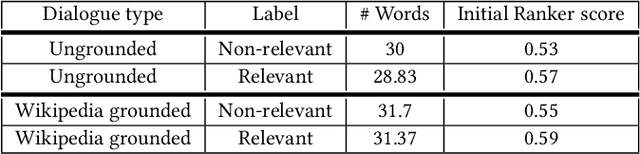
We address the task of sentence retrieval for open-ended dialogues. The goal is to retrieve sentences from a document corpus that contain information useful for generating the next turn in a given dialogue. Prior work on dialogue-based retrieval focused on specific types of dialogues: either conversational QA or conversational search. To address a broader scope of this task where any type of dialogue can be used, we constructed a dataset that includes open-ended dialogues from Reddit, candidate sentences from Wikipedia for each dialogue and human annotations for the sentences. We report the performance of several retrieval baselines, including neural retrieval models, over the dataset. To adapt neural models to the types of dialogues in the dataset, we explored an approach to induce a large-scale weakly supervised training data from Reddit. Using this training set significantly improved the performance over training on the MS MARCO dataset.
Coupling Deep Imputation with Multitask Learning for Downstream Tasks on Genomics Data
Apr 28, 2022
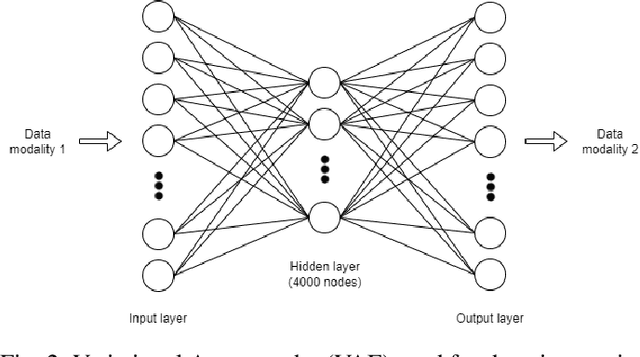
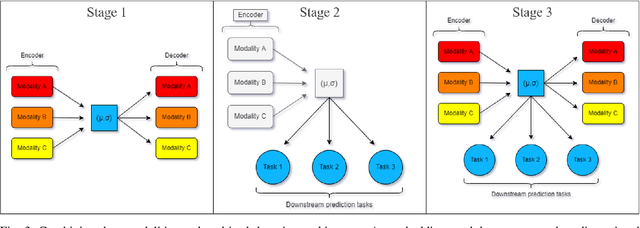
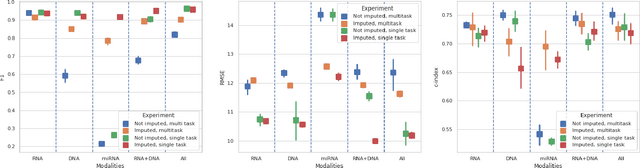
Genomics data such as RNA gene expression, methylation and micro RNA expression are valuable sources of information for various clinical predictive tasks. For example, predicting survival outcomes, cancer histology type and other patients' related information is possible using not only clinical data but molecular data as well. Moreover, using these data sources together, for example in multitask learning, can boost the performance. However, in practice, there are many missing data points which leads to significantly lower patient numbers when analysing full cases, which in our setting refers to all modalities being present. In this paper we investigate how imputing data with missing values using deep learning coupled with multitask learning can help to reach state-of-the-art performance results using combined genomics modalities, RNA, micro RNA and methylation. We propose a generalised deep imputation method to impute values where a patient has all modalities present except one. Interestingly enough, deep imputation alone outperforms multitask learning alone for the classification and regression tasks across most combinations of modalities. In contrast, when using all modalities for survival prediction we observe that multitask learning alone outperforms deep imputation alone with statistical significance (adjusted p-value 0.03). Thus, both approaches are complementary when optimising performance for downstream predictive tasks.
Atmospheric Turbulence Removal with Complex-Valued Convolutional Neural Network
Apr 14, 2022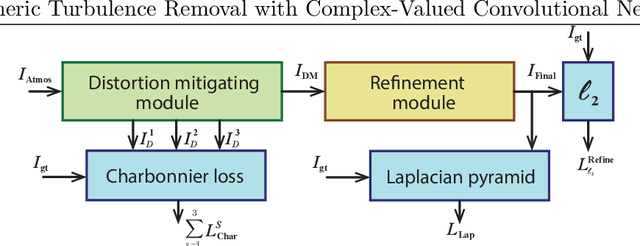
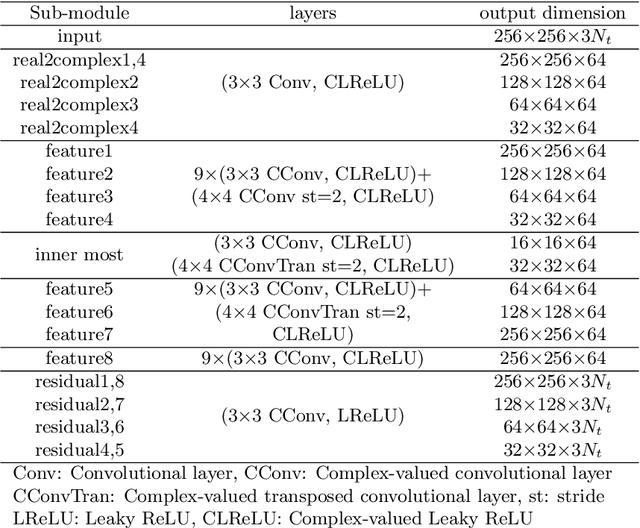
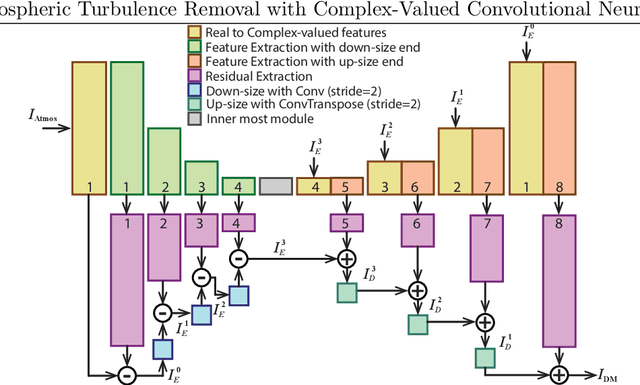
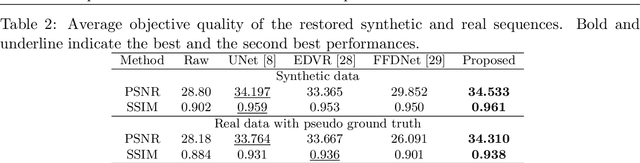
Atmospheric turbulence distorts visual imagery and is always problematic for information interpretation by both human and machine. Most well-developed approaches to remove atmospheric turbulence distortion are model-based. However, these methods require high computation and large memory preventing their feasibility of real-time operation. Deep learning-based approaches have hence gained more attention but currently work efficiently only on static scenes. This paper presents a novel learning-based framework offering short temporal spanning to support dynamic scenes. We exploit complex-valued convolutions as phase information, altered by atmospheric turbulence, is captured better than using ordinary real-valued convolutions. Two concatenated modules are proposed. The first module aims to remove geometric distortions and, if enough memory, the second module is applied to refine micro details of the videos. Experimental results show that our proposed framework efficiently mitigate the atmospheric turbulence distortion and significantly outperforms the existing methods.
COVIBOT: A Smart Chatbot for Assistance and E-Awareness during COVID-19 Pandemic
Apr 16, 2022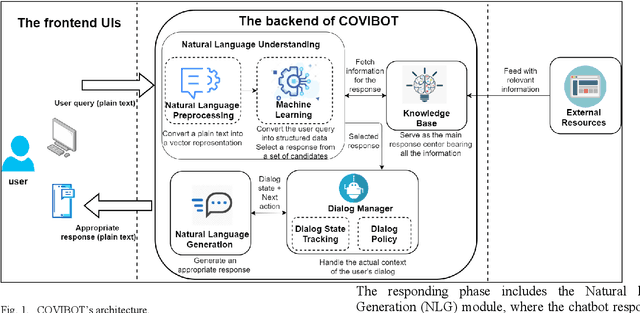
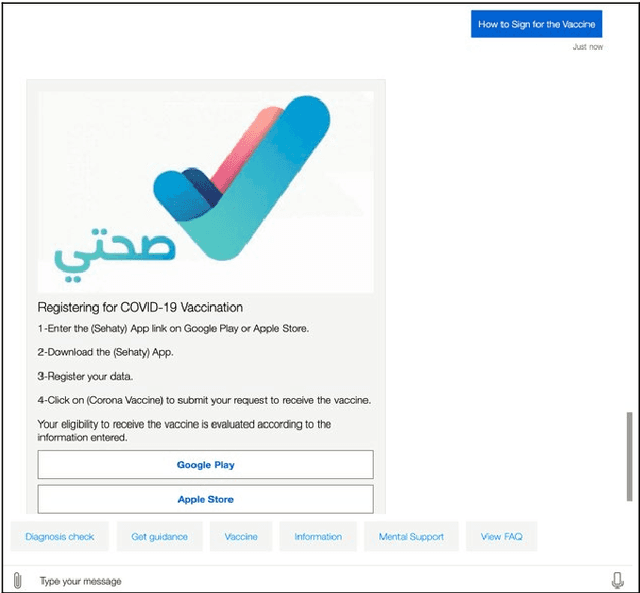

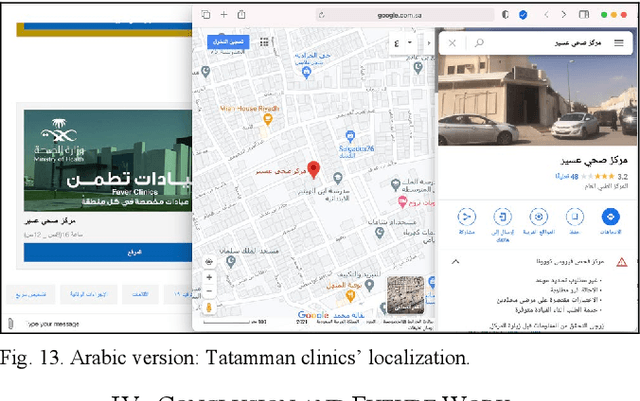
The coronavirus pandemic has spread over the past two years in our highly connected and information-dense society. Nonetheless, disseminating accurate and up-to-date information on the spread of this pandemic remains a challenge. In this context, opting for a solution based on conversational artificial intelligence, also known under the name of the chatbot, is proving to be an unavoidable solution, especially since it has already shown its effectiveness in fighting the coronavirus crisis in several countries. This work proposes to design and implement a smart chatbot on the theme of COVID-19, called COVIBOT, which will be useful in the context of Saudi Arabia. COVIBOT is a generative-based contextual chatbot, which is built using machine learning APIs that are offered by the cloud-based Azure Cognitive Services. Two versions of COVIBOT are offered: English and Arabic versions. Use cases of COVIBOT are tested and validated using a scenario-based approach.
Deep Generalized Unfolding Networks for Image Restoration
Apr 28, 2022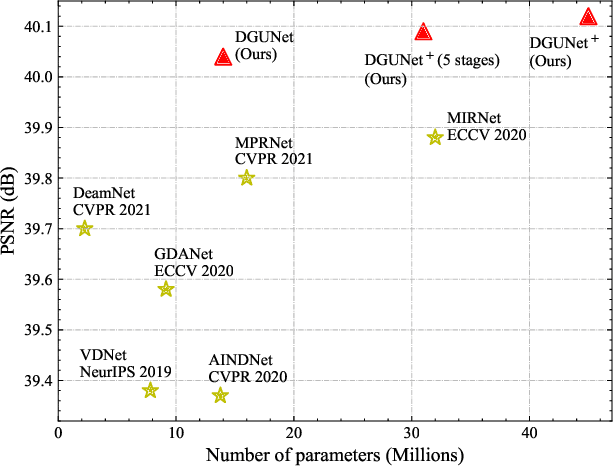
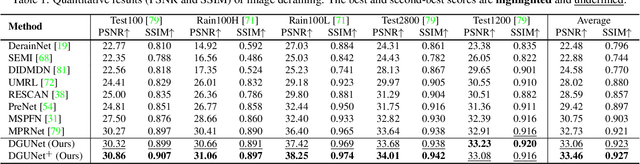
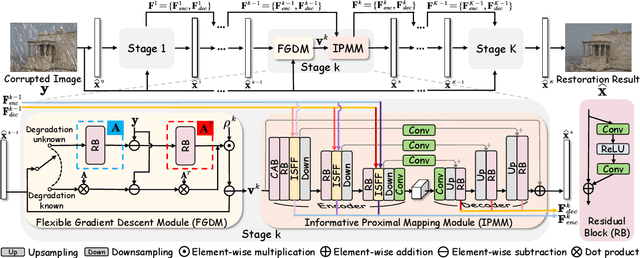
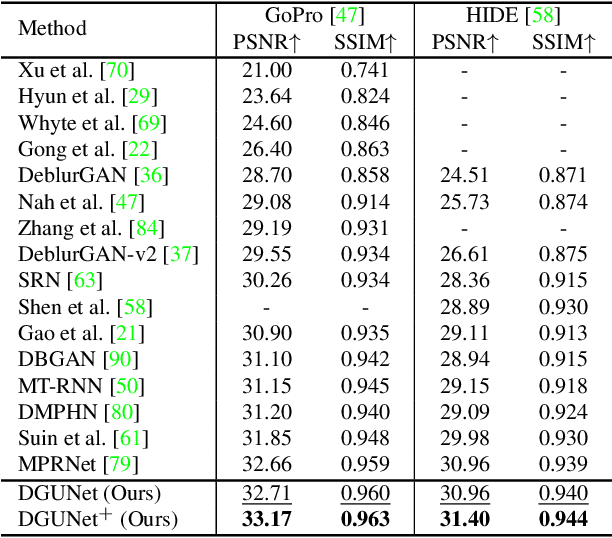
Deep neural networks (DNN) have achieved great success in image restoration. However, most DNN methods are designed as a black box, lacking transparency and interpretability. Although some methods are proposed to combine traditional optimization algorithms with DNN, they usually demand pre-defined degradation processes or handcrafted assumptions, making it difficult to deal with complex and real-world applications. In this paper, we propose a Deep Generalized Unfolding Network (DGUNet) for image restoration. Concretely, without loss of interpretability, we integrate a gradient estimation strategy into the gradient descent step of the Proximal Gradient Descent (PGD) algorithm, driving it to deal with complex and real-world image degradation. In addition, we design inter-stage information pathways across proximal mapping in different PGD iterations to rectify the intrinsic information loss in most deep unfolding networks (DUN) through a multi-scale and spatial-adaptive way. By integrating the flexible gradient descent and informative proximal mapping, we unfold the iterative PGD algorithm into a trainable DNN. Extensive experiments on various image restoration tasks demonstrate the superiority of our method in terms of state-of-the-art performance, interpretability, and generalizability. The source code is available at https://github.com/MC-E/Deep-Generalized-Unfolding-Networks-for-Image-Restoration.
Robust Face-Swap Detection Based on 3D Facial Shape Information
Apr 28, 2021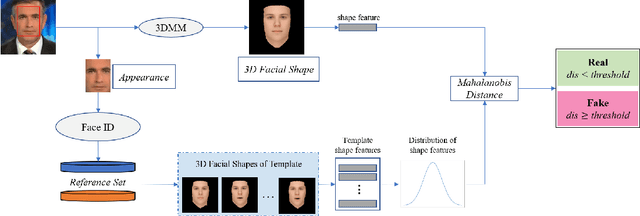

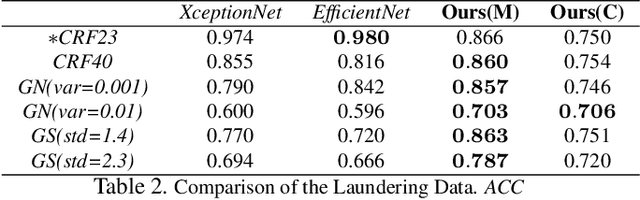
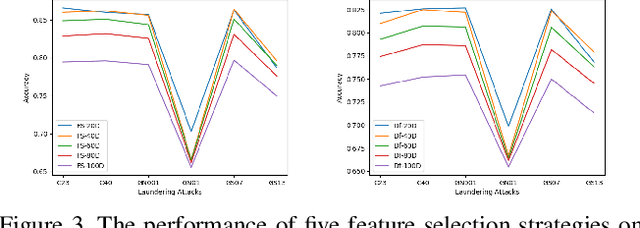
Maliciously-manipulated images or videos - so-called deep fakes - especially face-swap images and videos have attracted more and more malicious attackers to discredit some key figures. Previous pixel-level artifacts based detection techniques always focus on some unclear patterns but ignore some available semantic clues. Therefore, these approaches show weak interpretability and robustness. In this paper, we propose a biometric information based method to fully exploit the appearance and shape feature for face-swap detection of key figures. The key aspect of our method is obtaining the inconsistency of 3D facial shape and facial appearance, and the inconsistency based clue offers natural interpretability for the proposed face-swap detection method. Experimental results show the superiority of our method in robustness on various laundering and cross-domain data, which validates the effectiveness of the proposed method.
Individually Fair Learning with One-Sided Feedback
Jun 09, 2022
We consider an online learning problem with one-sided feedback, in which the learner is able to observe the true label only for positively predicted instances. On each round, $k$ instances arrive and receive classification outcomes according to a randomized policy deployed by the learner, whose goal is to maximize accuracy while deploying individually fair policies. We first extend the framework of Bechavod et al. (2020), which relies on the existence of a human fairness auditor for detecting fairness violations, to instead incorporate feedback from dynamically-selected panels of multiple, possibly inconsistent, auditors. We then construct an efficient reduction from our problem of online learning with one-sided feedback and a panel reporting fairness violations to the contextual combinatorial semi-bandit problem (Cesa-Bianchi & Lugosi, 2009, Gy\"{o}rgy et al., 2007). Finally, we show how to leverage the guarantees of two algorithms in the contextual combinatorial semi-bandit setting: Exp2 (Bubeck et al., 2012) and the oracle-efficient Context-Semi-Bandit-FTPL (Syrgkanis et al., 2016), to provide multi-criteria no regret guarantees simultaneously for accuracy and fairness. Our results eliminate two potential sources of bias from prior work: the "hidden outcomes" that are not available to an algorithm operating in the full information setting, and human biases that might be present in any single human auditor, but can be mitigated by selecting a well chosen panel.
A Variational Bayesian Perspective on Massive MIMO Detection
May 23, 2022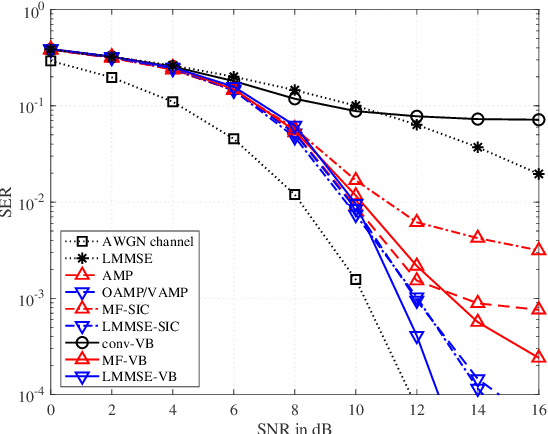
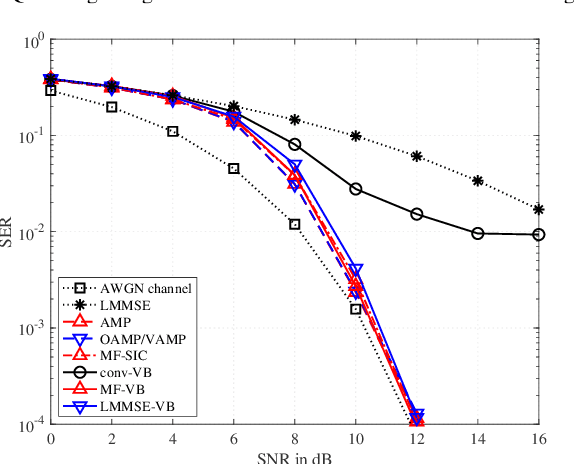
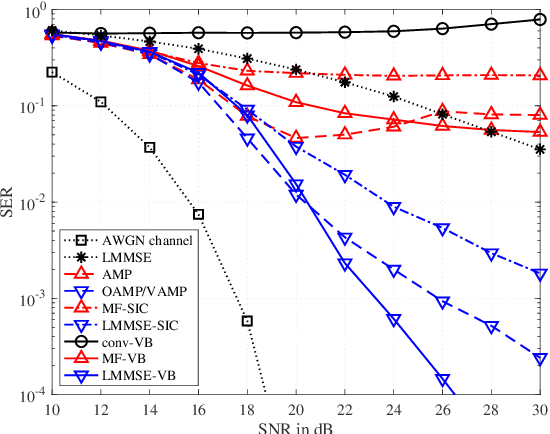
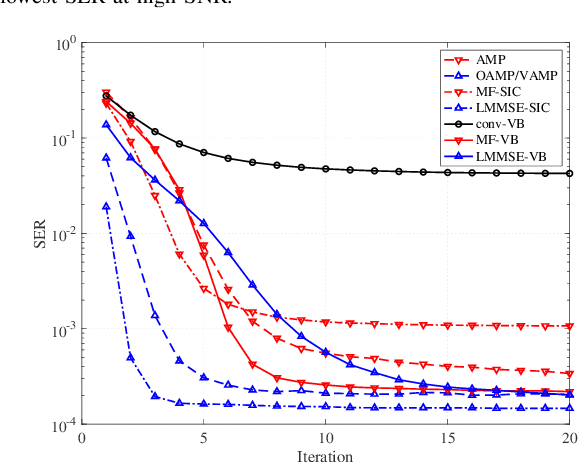
Optimal data detection in massive multiple-input multiple-output (MIMO) systems requires prohibitive computational complexity. A variety of detection algorithms have been proposed in the literature, offering different trade-offs between complexity and detection performance. In this paper, we build upon variational Bayes (VB) inference to design low-complexity multiuser detection algorithms for massive MIMO systems. We first examine the massive MIMO detection problem with perfect channel state information at the receiver (CSIR) and show that a conventional VB method with known noise variance yields poor detection performance. To address this limitation, we devise two new VB algorithms that use the noise variance and covariance matrix postulated by the algorithms themselves. We further develop the VB framework for massive MIMO detection with imperfect CSIR. Simulation results show that the proposed VB methods achieve significantly lower detection errors compared with existing schemes for a wide range of channel models.