 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Supporting Intelligence in 5G/6G Core Networks: NWDAF Implementation and Initial Analysis
May 30, 2022
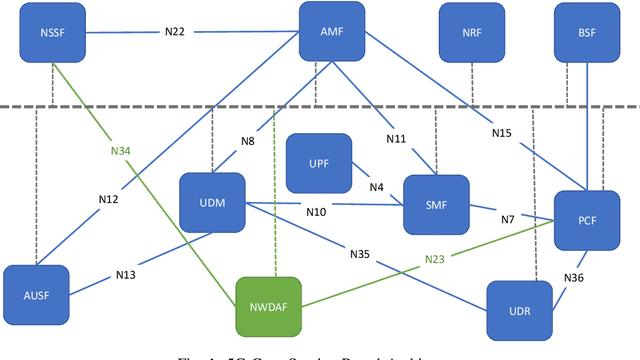
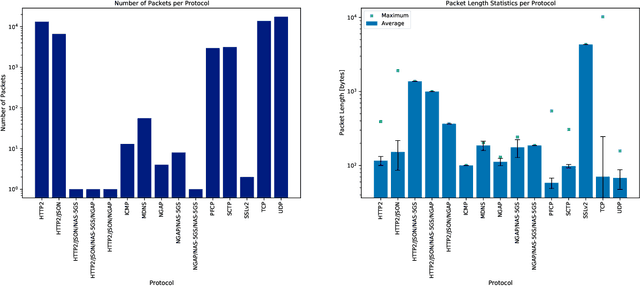
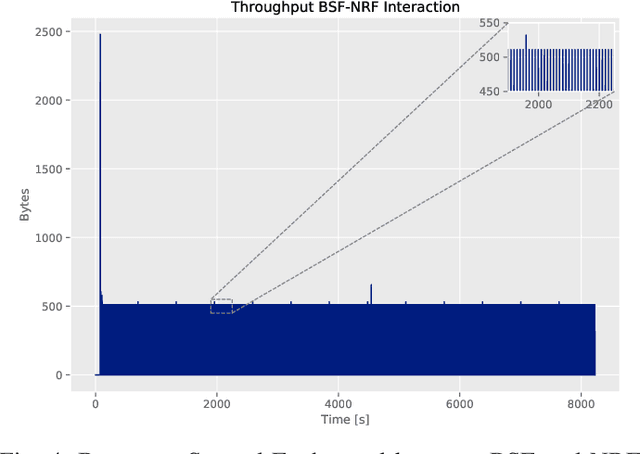
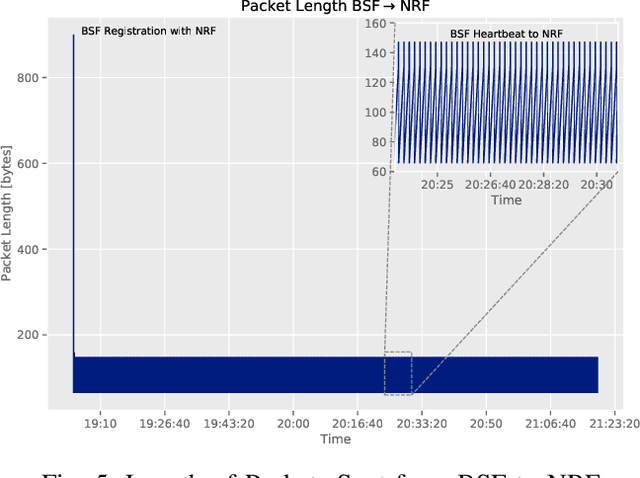
Wireless networks, in the fifth-generation and beyond, must support diverse network applications which will support the numerous and demanding connections of today's and tomorrow's devices. Requirements such as high data rates, low latencies, and reliability are crucial considerations and artificial intelligence is incorporated to achieve these requirements for a large number of connected devices. Specifically, intelligent methods and frameworks for advanced analysis are employed by the 5G Core Network Data Analytics Function (NWDAF) to detect patterns and ascribe detailed action information to accommodate end users and improve network performance. To this end, the work presented in this paper incorporates a functional NWDAF into a 5G network developed using open source software. Furthermore, an analysis of the network data collected by the NWDAF and the valuable insights which can be drawn from it have been presented with detailed Network Function interactions. An example application of such insights used for intelligent network management is outlined. Finally, the expected limitations of 5G networks are discussed as motivation for the development of 6G networks.
Collaborative Linear Bandits with Adversarial Agents: Near-Optimal Regret Bounds
Jun 06, 2022
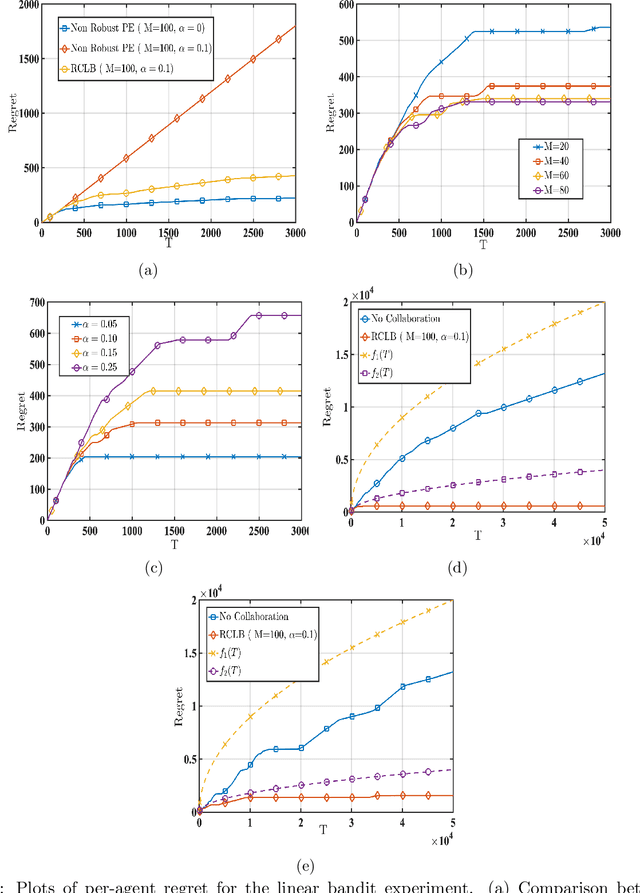
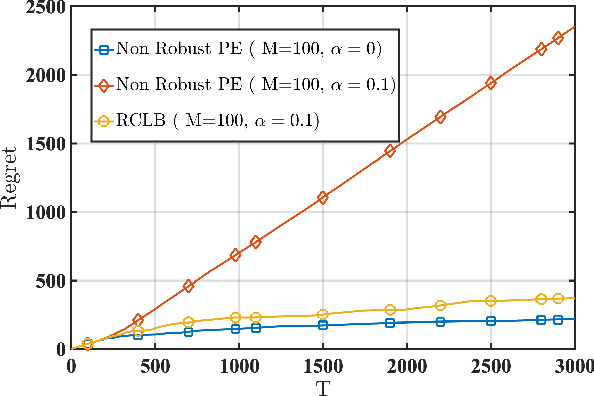
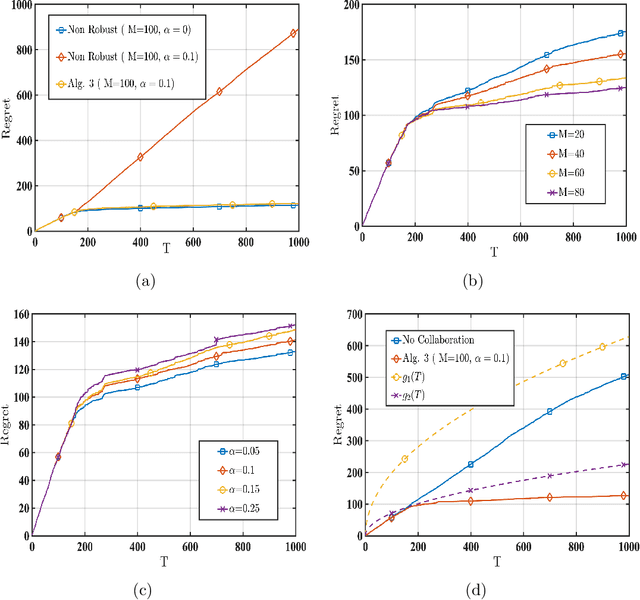
We consider a linear stochastic bandit problem involving $M$ agents that can collaborate via a central server to minimize regret. A fraction $\alpha$ of these agents are adversarial and can act arbitrarily, leading to the following tension: while collaboration can potentially reduce regret, it can also disrupt the process of learning due to adversaries. In this work, we provide a fundamental understanding of this tension by designing new algorithms that balance the exploration-exploitation trade-off via carefully constructed robust confidence intervals. We also complement our algorithms with tight analyses. First, we develop a robust collaborative phased elimination algorithm that achieves $\tilde{O}\left(\alpha+ 1/\sqrt{M}\right) \sqrt{dT}$ regret for each good agent; here, $d$ is the model-dimension and $T$ is the horizon. For small $\alpha$, our result thus reveals a clear benefit of collaboration despite adversaries. Using an information-theoretic argument, we then prove a matching lower bound, thereby providing the first set of tight, near-optimal regret bounds for collaborative linear bandits with adversaries. Furthermore, by leveraging recent advances in high-dimensional robust statistics, we significantly extend our algorithmic ideas and results to (i) the generalized linear bandit model that allows for non-linear observation maps; and (ii) the contextual bandit setting that allows for time-varying feature vectors.
Team VI-I2R Technical Report on EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2021
Jun 03, 2022

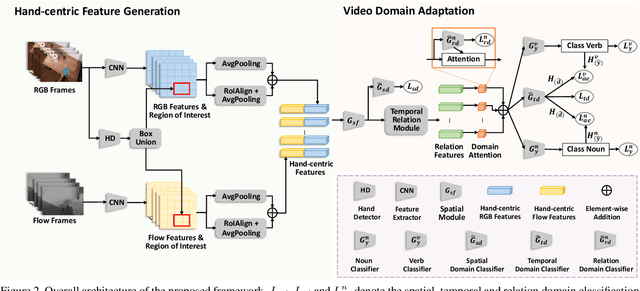

In this report, we present the technical details of our approach to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation (UDA) Challenge for Action Recognition. The EPIC-KITCHENS-100 dataset consists of daily kitchen activities focusing on the interaction between human hands and their surrounding objects. It is very challenging to accurately recognize these fine-grained activities, due to the presence of distracting objects and visually similar action classes, especially in the unlabelled target domain. Based on an existing method for video domain adaptation, i.e., TA3N, we propose to learn hand-centric features by leveraging the hand bounding box information for UDA on fine-grained action recognition. This helps reduce the distraction from background as well as facilitate the learning of domain-invariant features. To achieve high quality hand localization, we adopt an uncertainty-aware domain adaptation network, i.e., MEAA, to train a domain-adaptive hand detector, which only uses very limited hand bounding box annotations in the source domain but can generalize well to the unlabelled target domain. Our submission achieved the 1st place in terms of top-1 action recognition accuracy, using only RGB and optical flow modalities as input.
Spectral Algorithms Optimally Recover (Censored) Planted Dense Subgraphs
Mar 22, 2022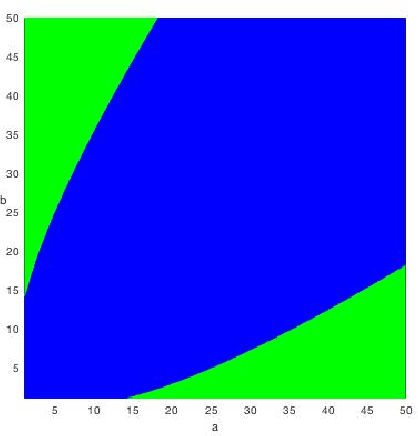
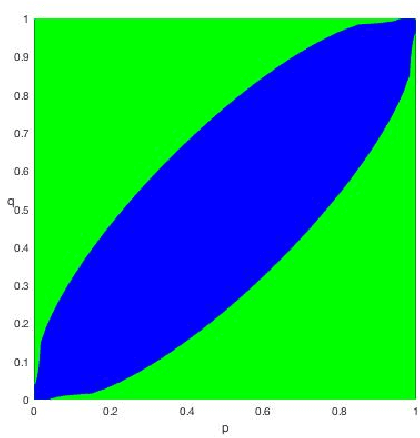
We study spectral algorithms for the planted dense subgraph problem (PDS), as well as for a censored variant (CPDS) of PDS, where the edge statuses are missing at random. More precisely, in the PDS model, we consider $n$ vertices and a random subset of vertices $S^{\star}$ of size $\Omega(n)$, such that two vertices share an edge with probability $p$ if both of them are in $S^{\star}$, and all other edges are present with probability $q$, independently. The goal is to recover $S^{\star}$ from one observation of the network. In the CPDS model, edge statuses are revealed with probability $\frac{t \log n}{n}$. For the PDS model, we show that a simple spectral algorithm based on the top two eigenvectors of the adjacency matrix can recover $S^{\star}$ up to the information theoretic threshold. Prior work by Hajek, Wu and Xu required a less efficient SDP based algorithm to recover $S^{\star}$ up to the information theoretic threshold. For the CDPS model, we obtain the information theoretic limit for the recovery problem, and further show that a spectral algorithm based on a special matrix called the signed adjacency matrix recovers $S^{\star}$ up to the information theoretic threshold.
Transformer Scale Gate for Semantic Segmentation
May 14, 2022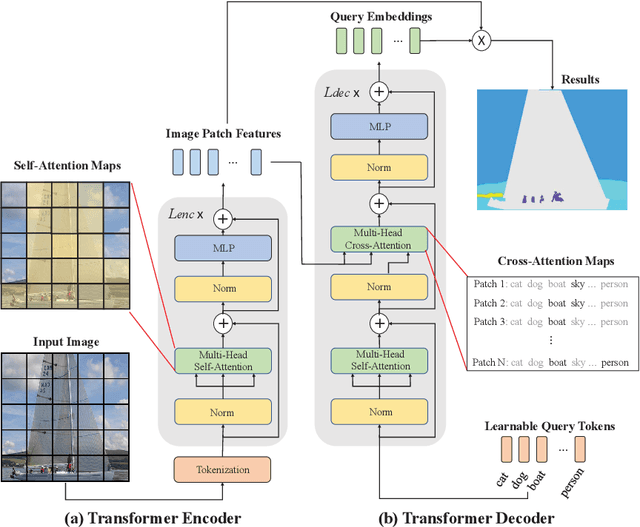
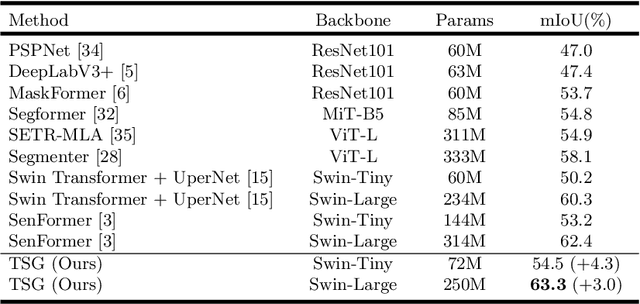

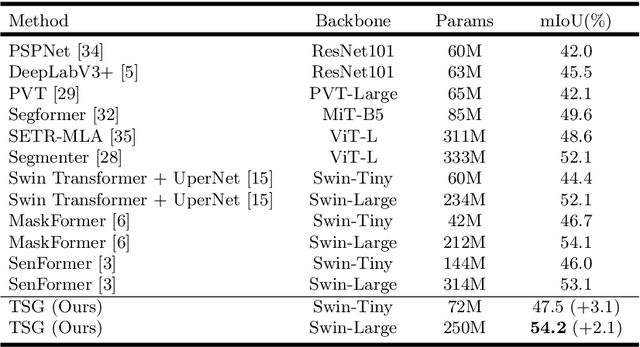
Effectively encoding multi-scale contextual information is crucial for accurate semantic segmentation. Existing transformer-based segmentation models combine features across scales without any selection, where features on sub-optimal scales may degrade segmentation outcomes. Leveraging from the inherent properties of Vision Transformers, we propose a simple yet effective module, Transformer Scale Gate (TSG), to optimally combine multi-scale features.TSG exploits cues in self and cross attentions in Vision Transformers for the scale selection. TSG is a highly flexible plug-and-play module, and can easily be incorporated with any encoder-decoder-based hierarchical vision Transformer architecture. Extensive experiments on the Pascal Context and ADE20K datasets demonstrate that our feature selection strategy achieves consistent gains.
Multiband Delay Estimation for Localization Using a Two-Stage Global Estimation Scheme
Jun 20, 2022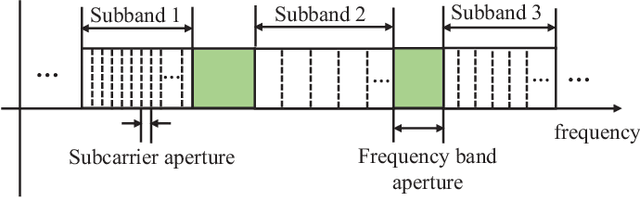
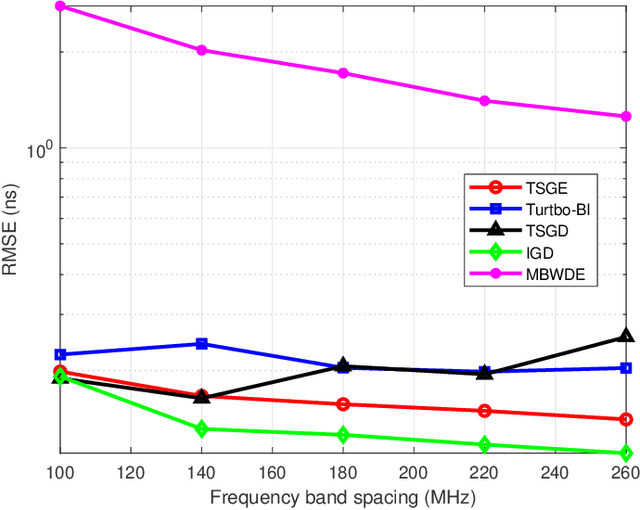
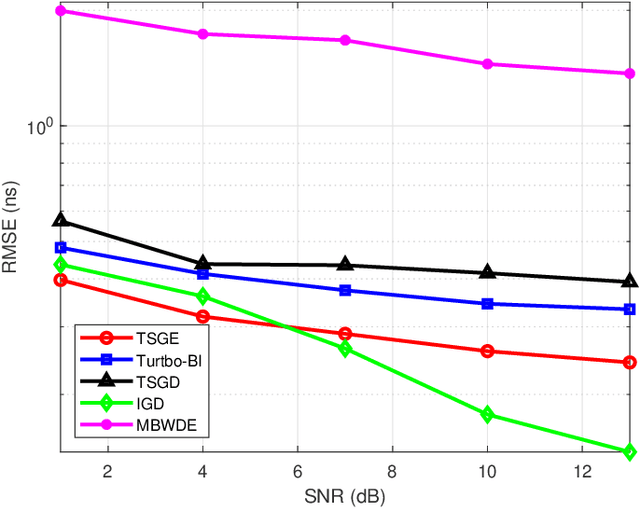
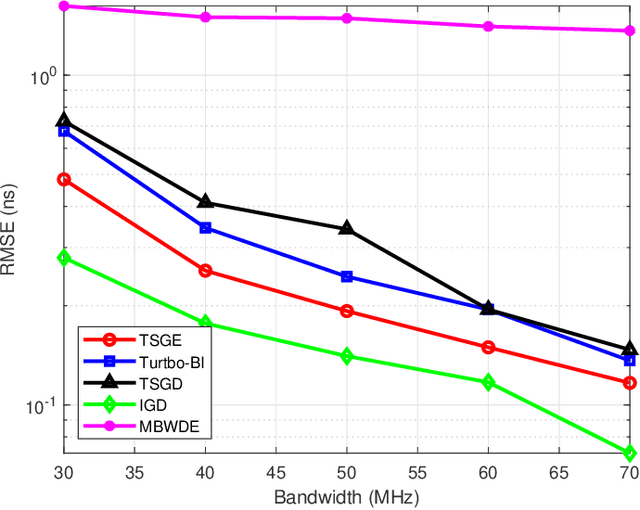
The time of arrival (TOA)-based localization techniques, which need to estimate the delay of the line-of-sight (LoS) path, have been widely employed in location-aware networks. To achieve a high-accuracy delay estimation, a number of multiband-based algorithms have been proposed recently, which exploit the channel state information (CSI) measurements over multiple non-contiguous frequency bands. However, to the best of our knowledge, there still lacks an efficient scheme that fully exploits the multiband gains when the phase distortion factors caused by hardware imperfections are considered, due to that the associated multi-parameter estimation problem contains many local optimums and the existing algorithms can easily get stuck in a "bad" local optimum. To address these issues, we propose a novel two-stage global estimation (TSGE) scheme for multiband delay estimation. In the coarse stage, we exploit the group sparsity structure of the multiband channel and propose a Turbo Bayesian inference (Turbo-BI) algorithm to achieve a good initial delay estimation based on a coarse signal model, which is transformed from the original multiband signal model by absorbing the carrier frequency terms. The estimation problem derived from the coarse signal model contains less local optimums and thus a more stable estimation can be achieved than directly using the original signal model. Then in the refined stage, with the help of coarse estimation results to narrow down the search range, we perform a global delay estimation using a particle swarm optimization-least square (PSO-LS) algorithm based on a refined multiband signal model to exploit the multiband gains to further improve the estimation accuracy. Simulation results show that the proposed TSGE significantly outperforms the benchmarks with comparative computational complexity.
Learning cosmology and clustering with cosmic graphs
Apr 28, 2022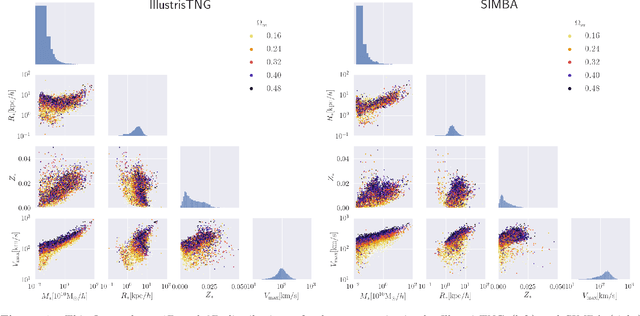
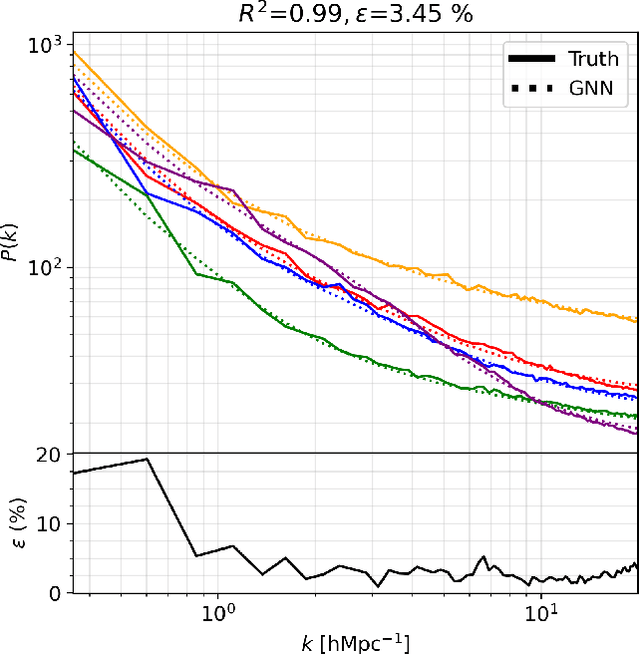
We train deep learning models on thousands of galaxy catalogues from the state-of-the-art hydrodynamic simulations of the CAMELS project to perform regression and inference. We employ Graph Neural Networks (GNNs), architectures designed to work with irregular and sparse data, like the distribution of galaxies in the Universe. We first show that GNNs can learn to compute the power spectrum of galaxy catalogues with a few percent accuracy. We then train GNNs to perform likelihood-free inference at the galaxy-field level. Our models are able to infer the value of $\Omega_{\rm m}$ with a $\sim12\%-13\%$ accuracy just from the positions of $\sim1000$ galaxies in a volume of $(25~h^{-1}{\rm Mpc})^3$ at $z=0$ while accounting for astrophysical uncertainties as modelled in CAMELS. Incorporating information from galaxy properties, such as stellar mass, stellar metallicity, and stellar radius, increases the accuracy to $4\%-8\%$. Our models are built to be translational and rotational invariant, and they can extract information from any scale larger than the minimum distance between two galaxies. However, our models are not completely robust: testing on simulations run with a different subgrid physics than the ones used for training does not yield as accurate results.
X-SCITLDR: Cross-Lingual Extreme Summarization of Scholarly Documents
May 30, 2022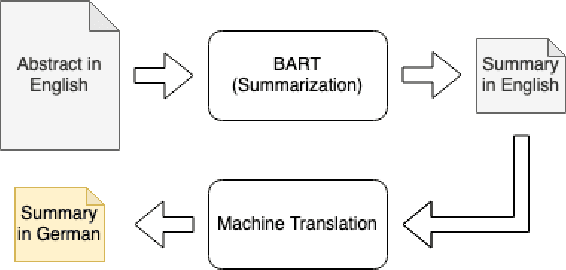

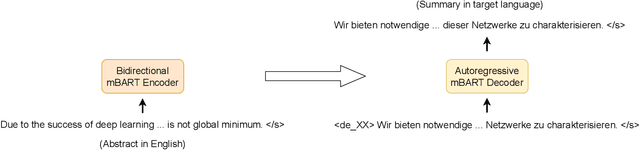

The number of scientific publications nowadays is rapidly increasing, causing information overload for researchers and making it hard for scholars to keep up to date with current trends and lines of work. Consequently, recent work on applying text mining technologies for scholarly publications has investigated the application of automatic text summarization technologies, including extreme summarization, for this domain. However, previous work has concentrated only on monolingual settings, primarily in English. In this paper, we fill this research gap and present an abstractive cross-lingual summarization dataset for four different languages in the scholarly domain, which enables us to train and evaluate models that process English papers and generate summaries in German, Italian, Chinese and Japanese. We present our new X-SCITLDR dataset for multilingual summarization and thoroughly benchmark different models based on a state-of-the-art multilingual pre-trained model, including a two-stage `summarize and translate' approach and a direct cross-lingual model. We additionally explore the benefits of intermediate-stage training using English monolingual summarization and machine translation as intermediate tasks and analyze performance in zero- and few-shot scenarios.
One-Way Matching of Datasets with Low Rank Signals
Apr 29, 2022
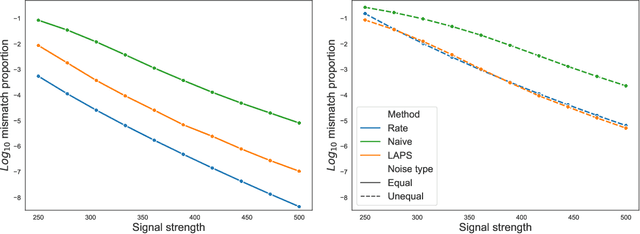
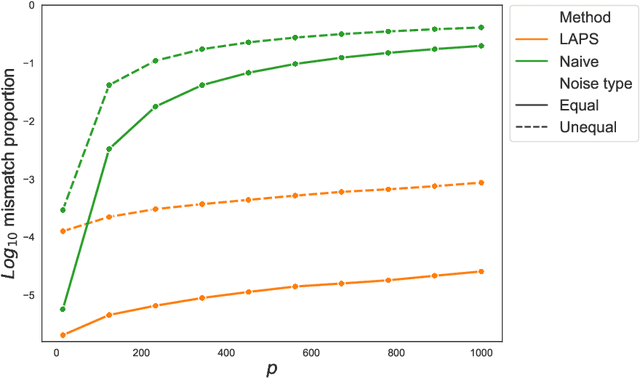
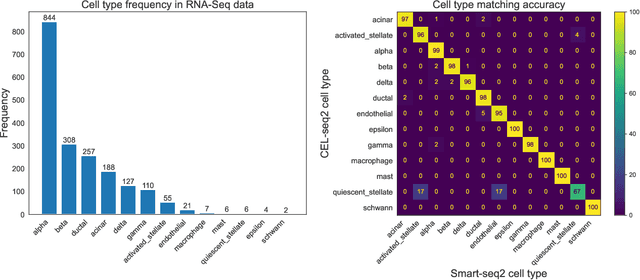
We study one-way matching of a pair of datasets with low rank signals. Under a stylized model, we first derive information-theoretic limits of matching. We then show that linear assignment with projected data achieves fast rates of convergence and sometimes even minimax rate optimality for this task. The theoretical error bounds are corroborated by simulated examples. Furthermore, we illustrate practical use of the matching procedure on two single-cell data examples.
Contrastive Learning with Boosted Memorization
Jun 03, 2022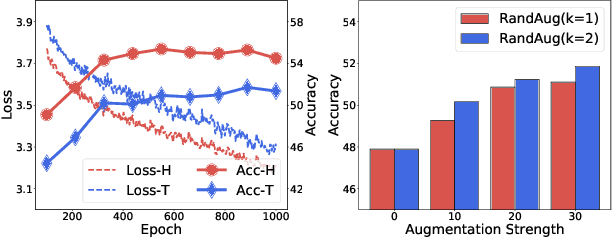
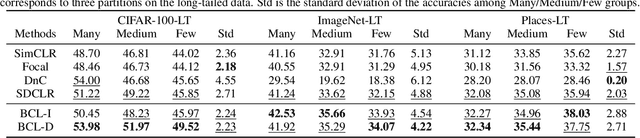
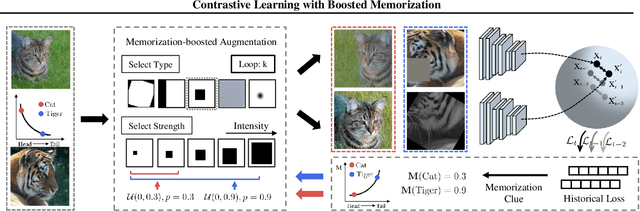
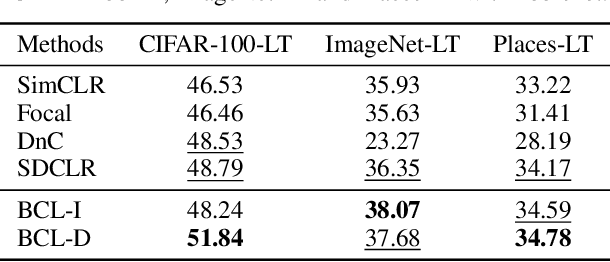
Self-supervised learning has achieved a great success in the representation learning of visual and textual data. However, the current methods are mainly validated on the well-curated datasets, which do not exhibit the real-world long-tailed distribution. Recent attempts to consider self-supervised long-tailed learning are made by rebalancing in the loss perspective or the model perspective, resembling the paradigms in the supervised long-tailed learning. Nevertheless, without the aid of labels, these explorations have not shown the expected significant promise due to the limitation in tail sample discovery or the heuristic structure design. Different from previous works, we explore this direction from an alternative perspective, i.e., the data perspective, and propose a novel Boosted Contrastive Learning (BCL) method. Specifically, BCL leverages the memorization effect of deep neural networks to automatically drive the information discrepancy of the sample views in contrastive learning, which is more efficient to enhance the long-tailed learning in the label-unaware context. Extensive experiments on a range of benchmark datasets demonstrate the effectiveness of BCL over several state-of-the-art methods. Our code is available at https://github.com/MediaBrain-SJTU/BCL.