 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PAS: A Position-Aware Similarity Measurement for Sequential Recommendation
May 19, 2022
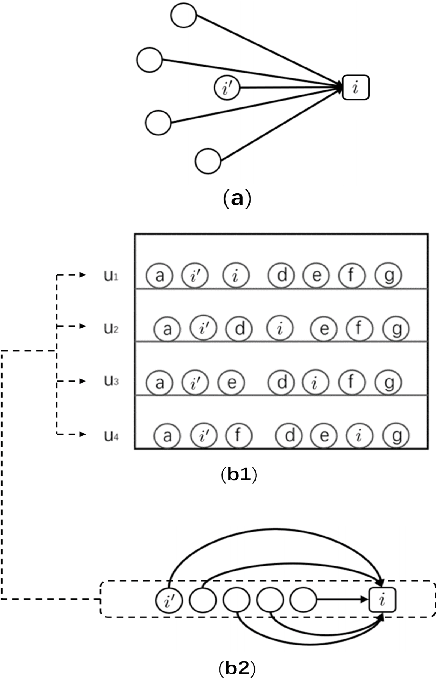
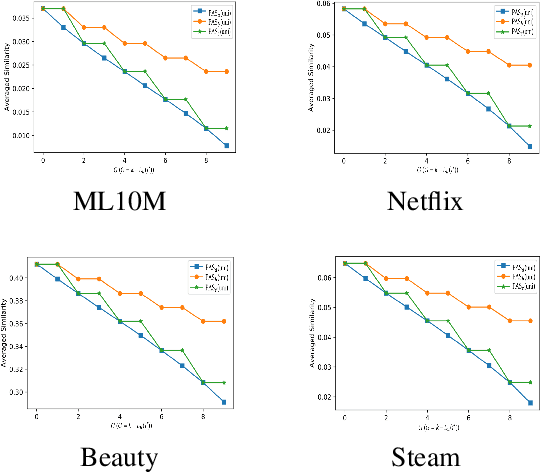
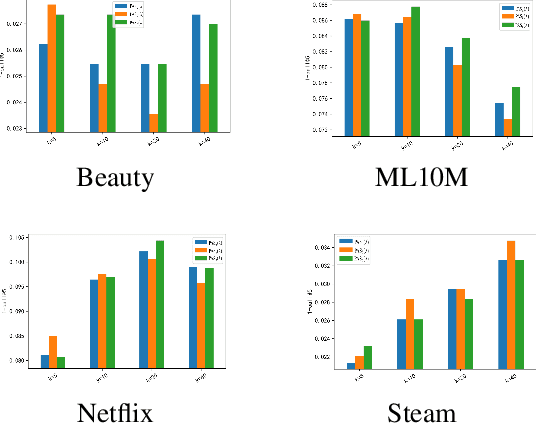
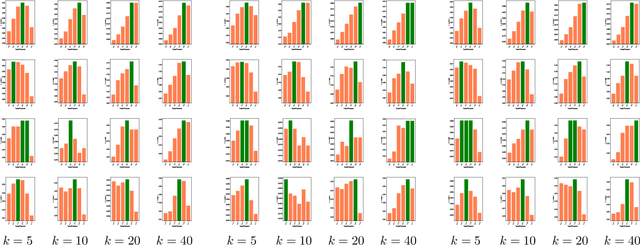
The common item-based collaborative filtering framework becomes a typical recommendation method when equipped with a certain item-to-item similarity measurement. On one hand, we realize that a well-designed similarity measurement is the key to providing satisfactory recommendation services. On the other hand, similarity measurements designed for sequential recommendation are rarely studied by the recommender systems community. Hence in this paper, we focus on devising a novel similarity measurement called position-aware similarity (PAS) for sequential recommendation. The proposed PAS is, to our knowledge, the first count-based similarity measurement that concurrently captures the sequential patterns from the historical user behavior data and from the item position information within the input sequences. We conduct extensive empirical studies on four public datasets, in which our proposed PAS-based method exhibits competitive performance even compared to the state-of-the-art sequential recommendation methods, including a very recent similarity-based method and two GNN-based methods.
ViViD++: Vision for Visibility Dataset
Apr 14, 2022
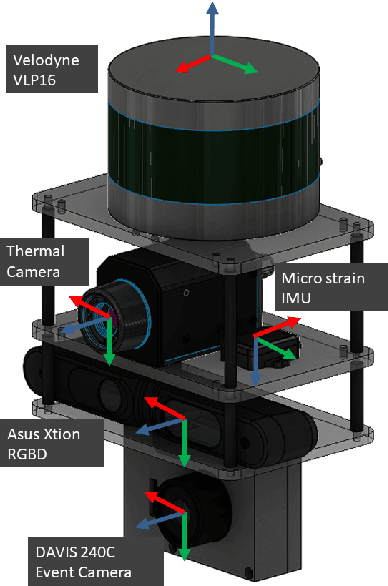

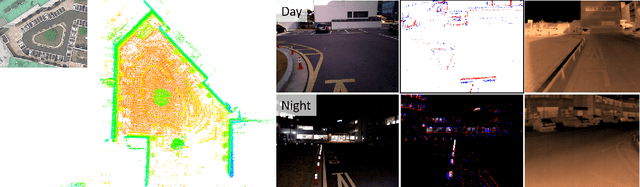
In this paper, we present a dataset capturing diverse visual data formats that target varying luminance conditions. While RGB cameras provide nourishing and intuitive information, changes in lighting conditions potentially result in catastrophic failure for robotic applications based on vision sensors. Approaches overcoming illumination problems have included developing more robust algorithms or other types of visual sensors, such as thermal and event cameras. Despite the alternative sensors' potential, there still are few datasets with alternative vision sensors. Thus, we provided a dataset recorded from alternative vision sensors, by handheld or mounted on a car, repeatedly in the same space but in different conditions. We aim to acquire visible information from co-aligned alternative vision sensors. Our sensor system collects data more independently from visible light intensity by measuring the amount of infrared dissipation, depth by structured reflection, and instantaneous temporal changes in luminance. We provide these measurements along with inertial sensors and ground-truth for developing robust visual SLAM under poor illumination. The full dataset is available at: https://visibilitydataset.github.io/
On Nested Justification Systems (full version)
May 09, 2022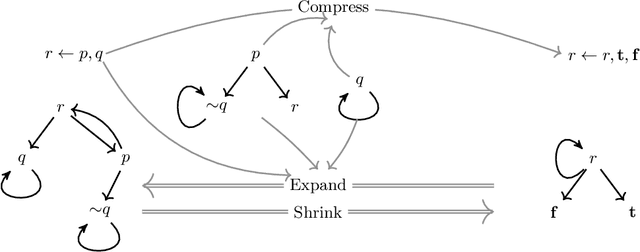
Justification theory is a general framework for the definition of semantics of rule-based languages that has a high explanatory potential. Nested justification systems, first introduced by Denecker et al. (2015), allow for the composition of justification systems. This notion of nesting thus enables the modular definition of semantics of rule-based languages, and increases the representational capacities of justification theory. As we show in this paper, the original semantics for nested justification systems lead to the loss of information relevant for explanations. In view of this problem, we provide an alternative characterization of semantics of nested justification systems and show that this characterization is equivalent to the original semantics. Furthermore, we show how nested justification systems allow representing fixpoint definitions (Hou and Denecker 2009).
Recurrent Video Restoration Transformer with Guided Deformable Attention
Jun 05, 2022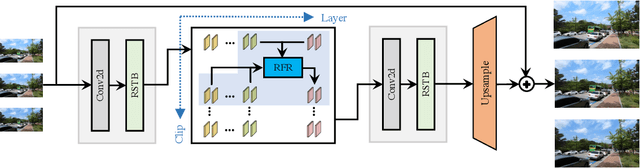
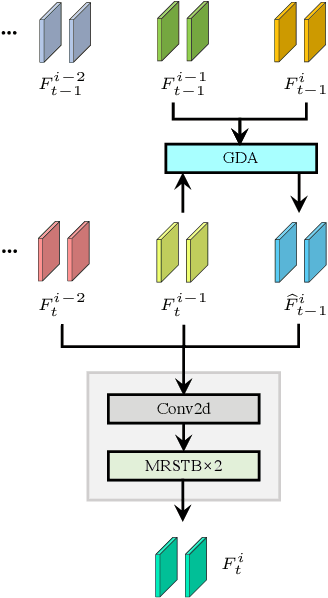
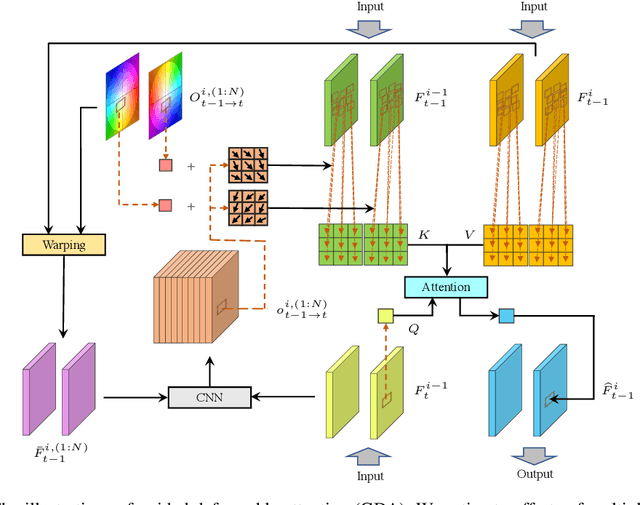
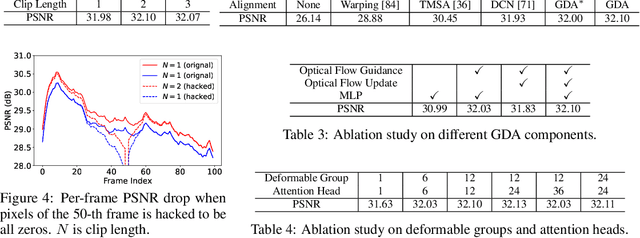
Video restoration aims at restoring multiple high-quality frames from multiple low-quality frames. Existing video restoration methods generally fall into two extreme cases, i.e., they either restore all frames in parallel or restore the video frame by frame in a recurrent way, which would result in different merits and drawbacks. Typically, the former has the advantage of temporal information fusion. However, it suffers from large model size and intensive memory consumption; the latter has a relatively small model size as it shares parameters across frames; however, it lacks long-range dependency modeling ability and parallelizability. In this paper, we attempt to integrate the advantages of the two cases by proposing a recurrent video restoration transformer, namely RVRT. RVRT processes local neighboring frames in parallel within a globally recurrent framework which can achieve a good trade-off between model size, effectiveness, and efficiency. Specifically, RVRT divides the video into multiple clips and uses the previously inferred clip feature to estimate the subsequent clip feature. Within each clip, different frame features are jointly updated with implicit feature aggregation. Across different clips, the guided deformable attention is designed for clip-to-clip alignment, which predicts multiple relevant locations from the whole inferred clip and aggregates their features by the attention mechanism. Extensive experiments on video super-resolution, deblurring, and denoising show that the proposed RVRT achieves state-of-the-art performance on benchmark datasets with balanced model size, testing memory and runtime.
Who Is Missing? Characterizing the Participation of Different Demographic Groups in a Korean Nationwide Daily Conversation Corpus
Apr 20, 2022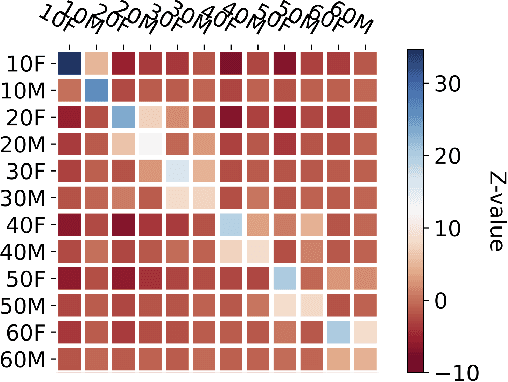
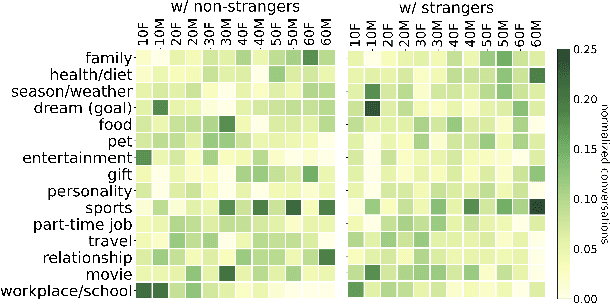
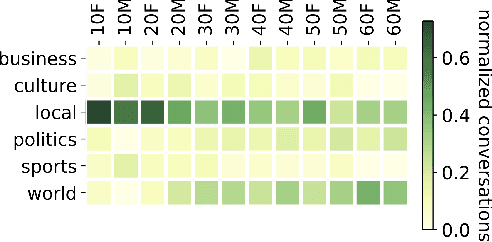
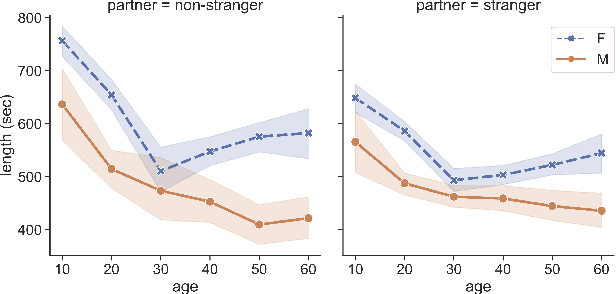
A conversation corpus is essential to build interactive AI applications. However, the demographic information of the participants in such corpora is largely underexplored mainly due to the lack of individual data in many corpora. In this work, we analyze a Korean nationwide daily conversation corpus constructed by the National Institute of Korean Language (NIKL) to characterize the participation of different demographic (age and sex) groups in the corpus.
Deep Posterior Distribution-based Embedding for Hyperspectral Image Super-resolution
May 30, 2022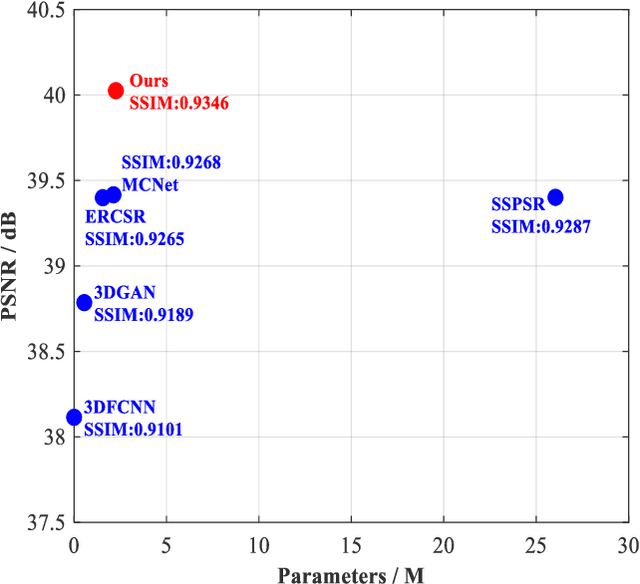
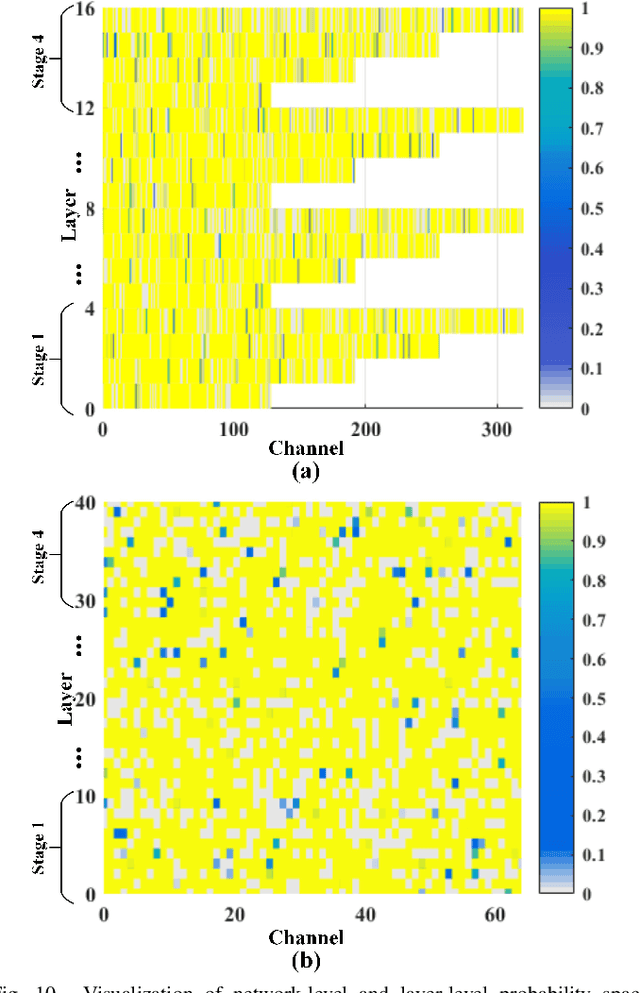
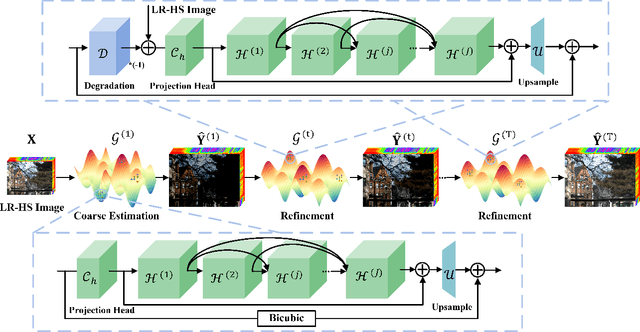
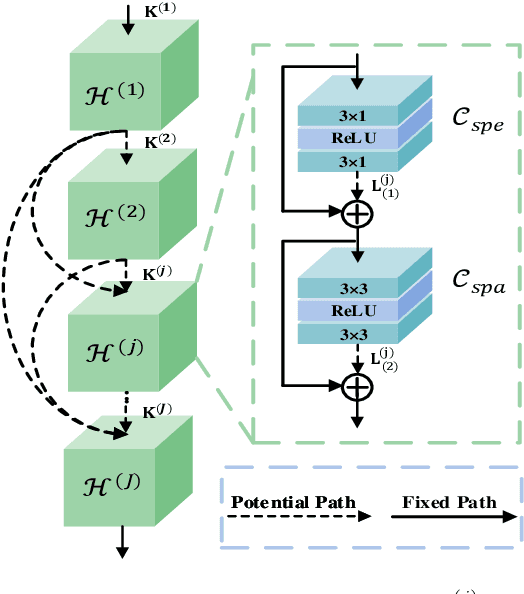
In this paper, we investigate the problem of hyperspectral (HS) image spatial super-resolution via deep learning. Particularly, we focus on how to embed the high-dimensional spatial-spectral information of HS images efficiently and effectively. Specifically, in contrast to existing methods adopting empirically-designed network modules, we formulate HS embedding as an approximation of the posterior distribution of a set of carefully-defined HS embedding events, including layer-wise spatial-spectral feature extraction and network-level feature aggregation. Then, we incorporate the proposed feature embedding scheme into a source-consistent super-resolution framework that is physically-interpretable, producing lightweight PDE-Net, in which high-resolution (HR) HS images are iteratively refined from the residuals between input low-resolution (LR) HS images and pseudo-LR-HS images degenerated from reconstructed HR-HS images via probability-inspired HS embedding. Extensive experiments over three common benchmark datasets demonstrate that PDE-Net achieves superior performance over state-of-the-art methods. Besides, the probabilistic characteristic of this kind of networks can provide the epistemic uncertainty of the network outputs, which may bring additional benefits when used for other HS image-based applications. The code will be publicly available at https://github.com/jinnh/PDE-Net.
Graph Representation Learning by Ensemble Aggregating Subgraphs via Mutual Information Maximization
Mar 24, 2021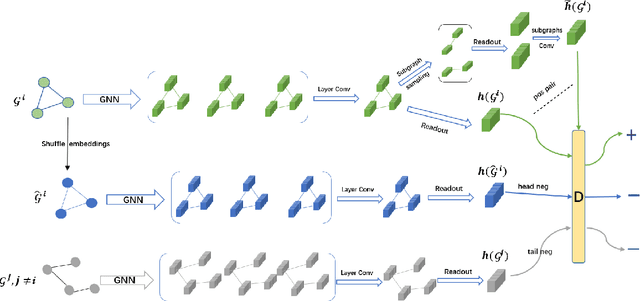

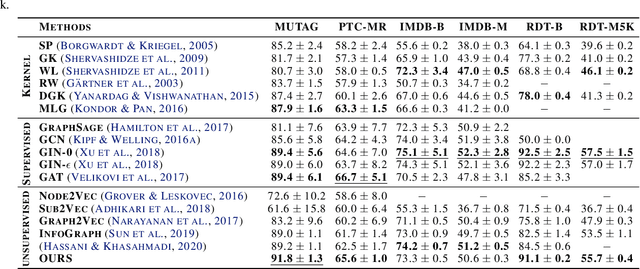
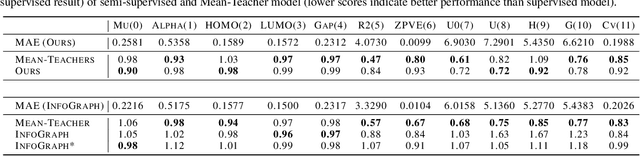
Graph Neural Networks have shown tremendous potential on dealing with garph data and achieved outstanding results in recent years. In some research areas, labelling data are hard to obtain for technical reasons, which necessitates the study of unsupervised and semi-superivsed learning on graphs. Therefore, whether the learned representations can capture the intrinsic feature of the original graphs will be the issue in this area. In this paper, we introduce a self-supervised learning method to enhance the representations of graph-level learned by Graph Neural Networks. To fully capture the original attributes of the graph, we use three information aggregators: attribute-conv, layer-conv and subgraph-conv to gather information from different aspects. To get a comprehensive understanding of the graph structure, we propose an ensemble-learning like subgraph method. And to achieve efficient and effective contrasive learning, a Head-Tail contrastive samples construction method is proposed to provide more abundant negative samples. By virtue of all proposed components which can be generalized to any Graph Neural Networks, in unsupervised case, we achieve new state of the art results in several benchmarks. We also evaluate our model on semi-supervised learning tasks and make a fair comparison to state of the art semi-supervised methods.
Collaborative Attention Memory Network for Video Object Segmentation
May 23, 2022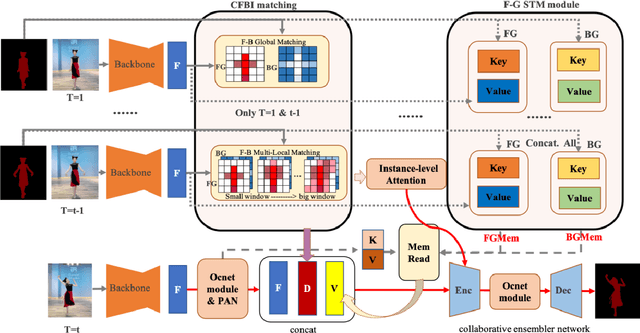
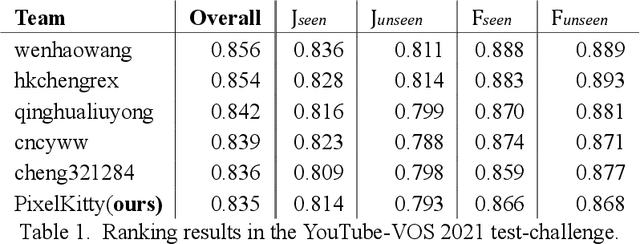

Semi-supervised video object segmentation is a fundamental yet Challenging task in computer vision. Embedding matching based CFBI series networks have achieved promising results by foreground-background integration approach. Despite its superior performance, these works exhibit distinct shortcomings, especially the false predictions caused by little appearance instances in first frame, even they could easily be recognized by previous frame. Moreover, they suffer from object's occlusion and error drifts. In order to overcome the shortcomings , we propose Collaborative Attention Memory Network with an enhanced segmentation head. We introduce a object context scheme that explicitly enhances the object information, which aims at only gathering the pixels that belong to the same category as a given pixel as its context. Additionally, a segmentation head with Feature Pyramid Attention(FPA) module is adopted to perform spatial pyramid attention structure on high-level output. Furthermore, we propose an ensemble network to combine STM network with all these new refined CFBI network. Finally, we evaluated our approach on the 2021 Youtube-VOS challenge where we obtain 6th place with an overall score of 83.5\%.
Less is More: Reweighting Important Spectral Graph Features for Recommendation
Apr 24, 2022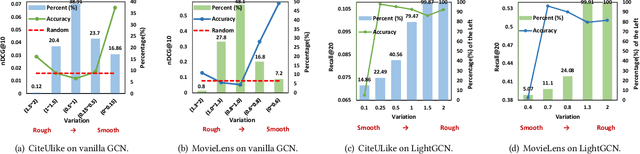
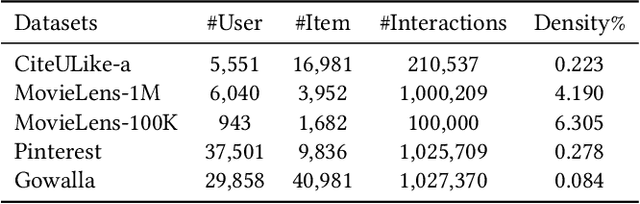
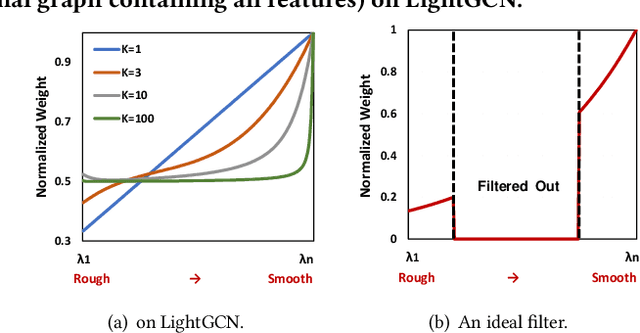
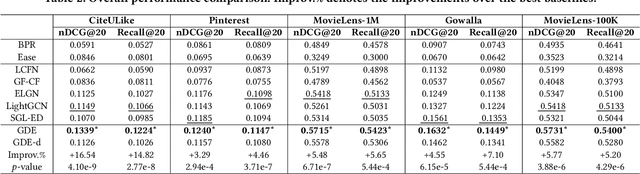
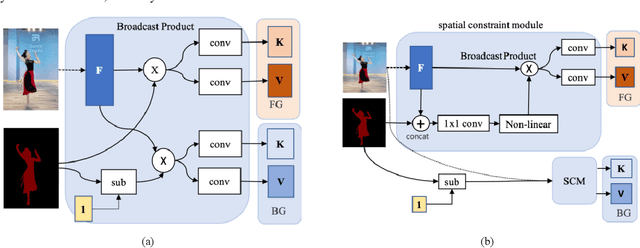
As much as Graph Convolutional Networks (GCNs) have shown tremendous success in recommender systems and collaborative filtering (CF), the mechanism of how they, especially the core components (\textit{i.e.,} neighborhood aggregation) contribute to recommendation has not been well studied. To unveil the effectiveness of GCNs for recommendation, we first analyze them in a spectral perspective and discover two important findings: (1) only a small portion of spectral graph features that emphasize the neighborhood smoothness and difference contribute to the recommendation accuracy, whereas most graph information can be considered as noise that even reduces the performance, and (2) repetition of the neighborhood aggregation emphasizes smoothed features and filters out noise information in an ineffective way. Based on the two findings above, we propose a new GCN learning scheme for recommendation by replacing neihgborhood aggregation with a simple yet effective Graph Denoising Encoder (GDE), which acts as a band pass filter to capture important graph features. We show that our proposed method alleviates the over-smoothing and is comparable to an indefinite-layer GCN that can take any-hop neighborhood into consideration. Finally, we dynamically adjust the gradients over the negative samples to expedite model training without introducing additional complexity. Extensive experiments on five real-world datasets show that our proposed method not only outperforms state-of-the-arts but also achieves 12x speedup over LightGCN.
A Spiking Neural Network based on Neural Manifold for Augmenting Intracortical Brain-Computer Interface Data
Mar 26, 2022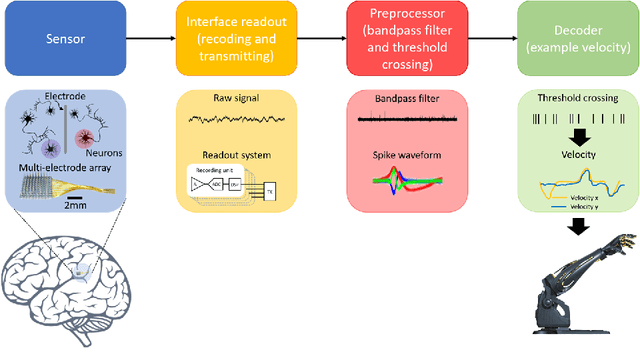
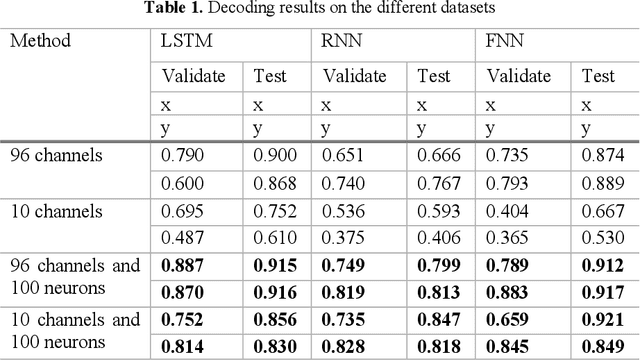
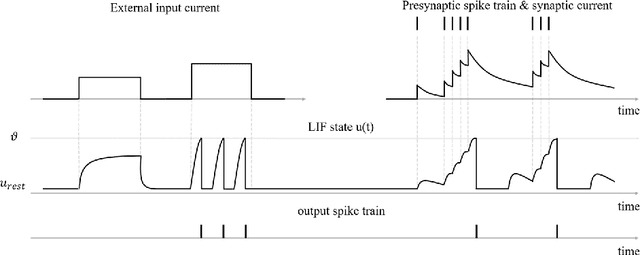
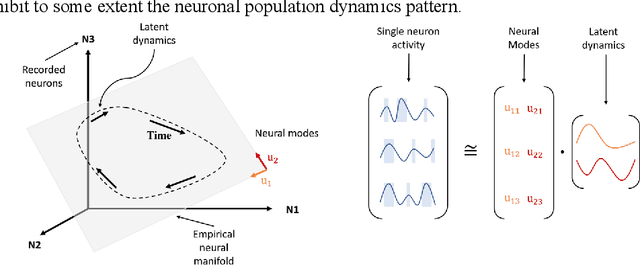
Brain-computer interfaces (BCIs), transform neural signals in the brain into in-structions to control external devices. However, obtaining sufficient training data is difficult as well as limited. With the advent of advanced machine learning methods, the capability of brain-computer interfaces has been enhanced like never before, however, these methods require a large amount of data for training and thus require data augmentation of the limited data available. Here, we use spiking neural networks (SNN) as data generators. It is touted as the next-generation neu-ral network and is considered as one of the algorithms oriented to general artifi-cial intelligence because it borrows the neural information processing from bio-logical neurons. We use the SNN to generate neural spike information that is bio-interpretable and conforms to the intrinsic patterns in the original neural data. Ex-periments show that the model can directly synthesize new spike trains, which in turn improves the generalization ability of the BCI decoder. Both the input and output of the spiking neural model are spike information, which is a brain-inspired intelligence approach that can be better integrated with BCI in the future.