 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Micro-video Recommendation via Contrastive Multiple Interests
May 19, 2022
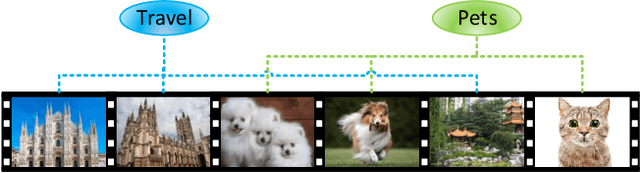

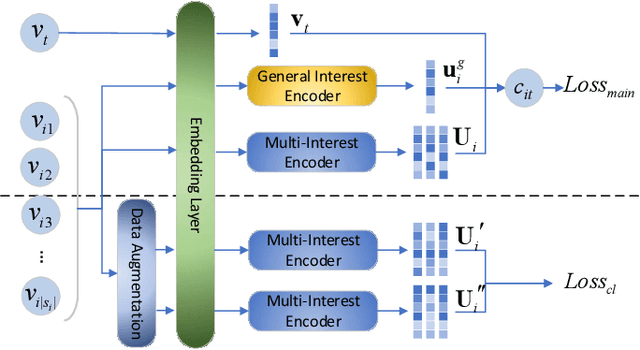
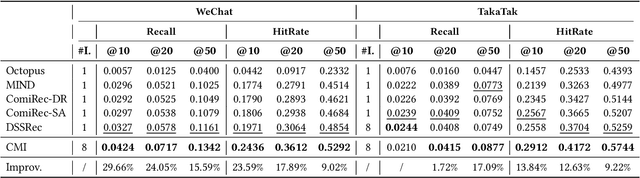
With the rapid increase of micro-video creators and viewers, how to make personalized recommendations from a large number of candidates to viewers begins to attract more and more attention. However, existing micro-video recommendation models rely on expensive multi-modal information and learn an overall interest embedding that cannot reflect the user's multiple interests in micro-videos. Recently, contrastive learning provides a new opportunity for refining the existing recommendation techniques. Therefore, in this paper, we propose to extract contrastive multi-interests and devise a micro-video recommendation model CMI. Specifically, CMI learns multiple interest embeddings for each user from his/her historical interaction sequence, in which the implicit orthogonal micro-video categories are used to decouple multiple user interests. Moreover, it establishes the contrastive multi-interest loss to improve the robustness of interest embeddings and the performance of recommendations. The results of experiments on two micro-video datasets demonstrate that CMI achieves state-of-the-art performance over existing baselines.
A Computational Inflection for Scientific Discovery
May 04, 2022
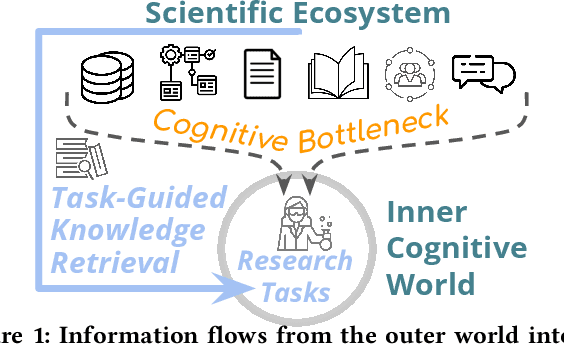
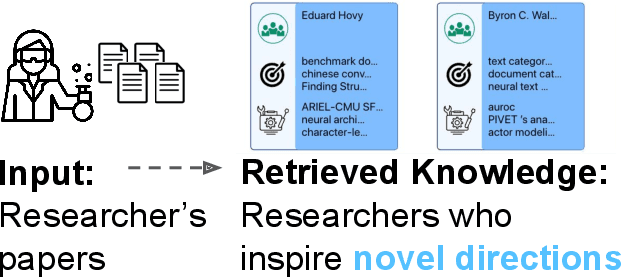
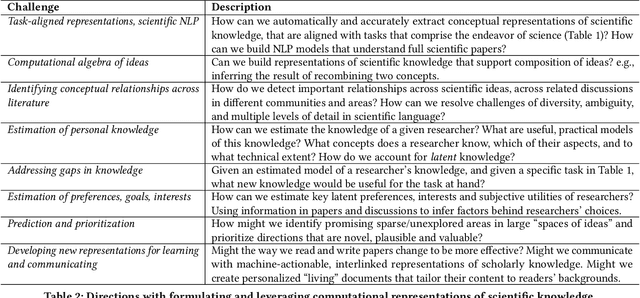
We stand at the foot of a significant inflection in the trajectory of scientific discovery. As society continues on its fast-paced digital transformation, so does humankind's collective scientific knowledge and discourse. We now read and write papers in digitized form, and a great deal of the formal and informal processes of science are captured digitally -- including papers, preprints and books, code and datasets, conference presentations, and interactions in social networks and communication platforms. The transition has led to the growth of a tremendous amount of information, opening exciting opportunities for computational models and systems that analyze and harness it. In parallel, exponential growth in data processing power has fueled remarkable advances in AI, including self-supervised neural models capable of learning powerful representations from large-scale unstructured text without costly human supervision. The confluence of societal and computational trends suggests that computer science is poised to ignite a revolution in the scientific process itself. However, the explosion of scientific data, results and publications stands in stark contrast to the constancy of human cognitive capacity. While scientific knowledge is expanding with rapidity, our minds have remained static, with severe limitations on the capacity for finding, assimilating and manipulating information. We propose a research agenda of task-guided knowledge retrieval, in which systems counter humans' bounded capacity by ingesting corpora of scientific knowledge and retrieving inspirations, explanations, solutions and evidence synthesized to directly augment human performance on salient tasks in scientific endeavors. We present initial progress on methods and prototypes, and lay out important opportunities and challenges ahead with computational approaches that have the potential to revolutionize science.
Pulling back information geometry
Jun 09, 2021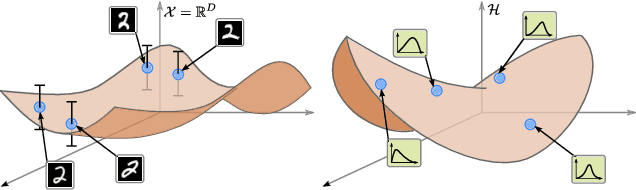

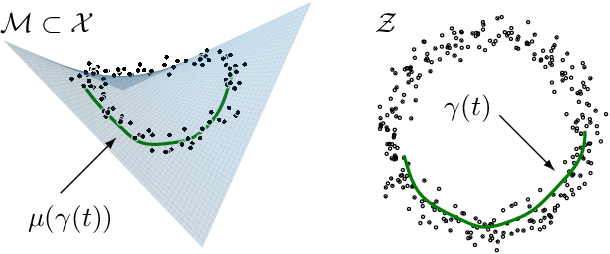

Latent space geometry has shown itself to provide a rich and rigorous framework for interacting with the latent variables of deep generative models. The existing theory, however, relies on the decoder being a Gaussian distribution as its simple reparametrization allows us to interpret the generating process as a random projection of a deterministic manifold. Consequently, this approach breaks down when applied to decoders that are not as easily reparametrized. We here propose to use the Fisher-Rao metric associated with the space of decoder distributions as a reference metric, which we pull back to the latent space. We show that we can achieve meaningful latent geometries for a wide range of decoder distributions for which the previous theory was not applicable, opening the door to `black box' latent geometries.
Chained Generalisation Bounds
Mar 02, 2022
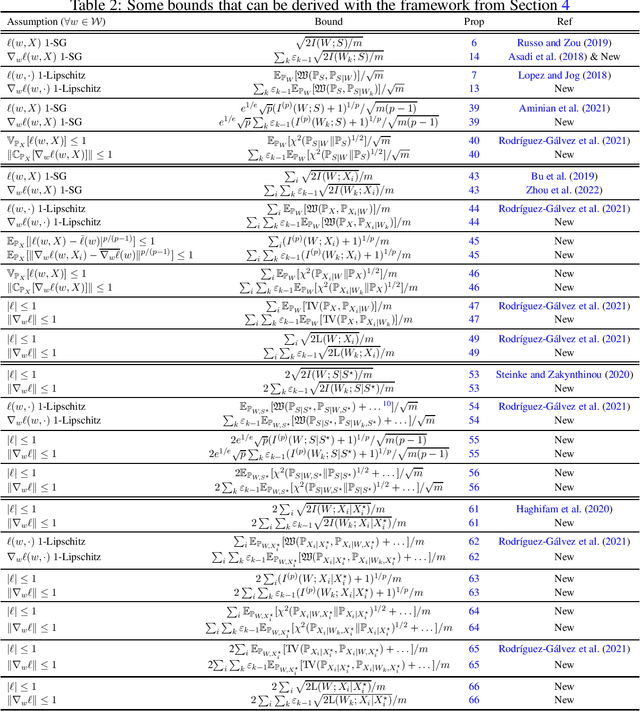
This work discusses how to derive upper bounds for the expected generalisation error of supervised learning algorithms by means of the chaining technique. By developing a general theoretical framework, we establish a duality between generalisation bounds based on the regularity of the loss function, and their chained counterparts, which can be obtained by lifting the regularity assumption from the loss onto its gradient. This allows us to re-derive the chaining mutual information bound from the literature, and to obtain novel chained information-theoretic generalisation bounds, based on the Wasserstein distance and other probability metrics. We show on some toy examples that the chained generalisation bound can be significantly tighter than its standard counterpart, particularly when the distribution of the hypotheses selected by the algorithm is very concentrated. Keywords: Generalisation bounds; Chaining; Information-theoretic bounds; Mutual information; Wasserstein distance; PAC-Bayes.
Multi-Agent Distributed Reinforcement Learning for Making Decentralized Offloading Decisions
Apr 05, 2022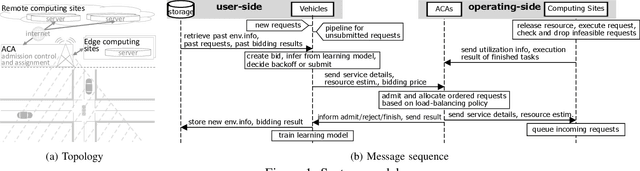
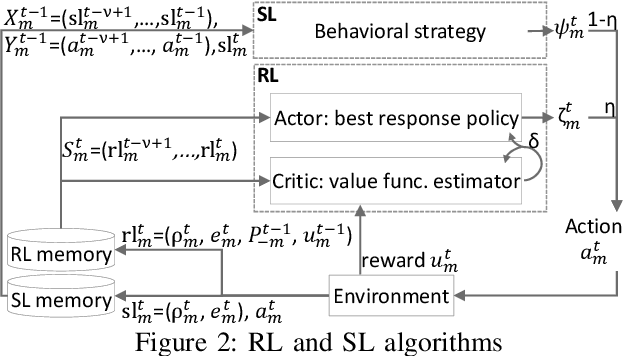
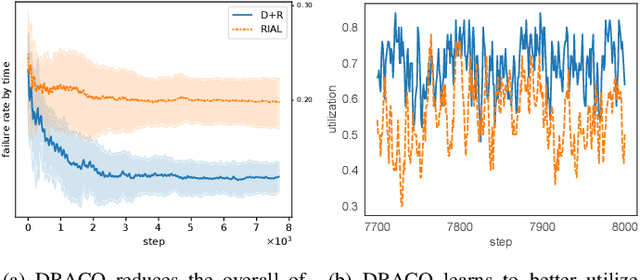

We formulate computation offloading as a decentralized decision-making problem with autonomous agents. We design an interaction mechanism that incentivizes agents to align private and system goals by balancing between competition and cooperation. The mechanism provably has Nash equilibria with optimal resource allocation in the static case. For a dynamic environment, we propose a novel multi-agent online learning algorithm that learns with partial, delayed and noisy state information, and a reward signal that reduces information need to a great extent. Empirical results confirm that through learning, agents significantly improve both system and individual performance, e.g., 40% offloading failure rate reduction, 32% communication overhead reduction, up to 38% computation resource savings in low contention, 18% utilization increase with reduced load variation in high contention, and improvement in fairness. Results also confirm the algorithm's good convergence and generalization property in significantly different environments.
SDS-200: A Swiss German Speech to Standard German Text Corpus
May 19, 2022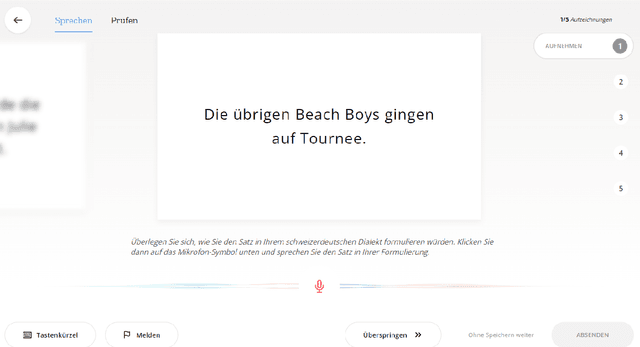
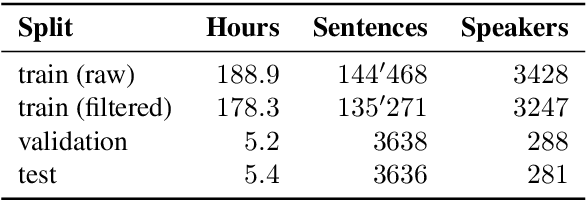
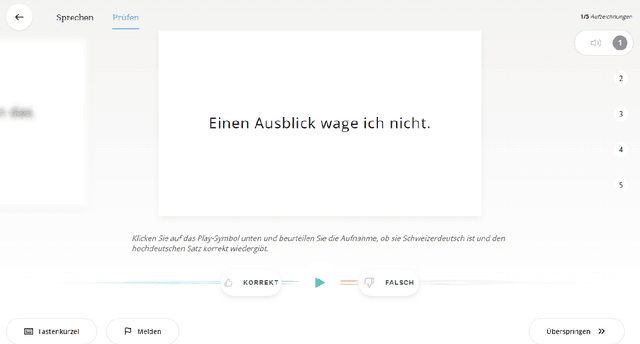
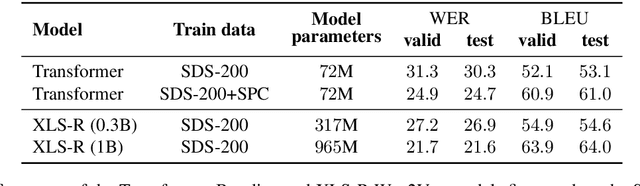
We present SDS-200, a corpus of Swiss German dialectal speech with Standard German text translations, annotated with dialect, age, and gender information of the speakers. The dataset allows for training speech translation, dialect recognition, and speech synthesis systems, among others. The data was collected using a web recording tool that is open to the public. Each participant was given a text in Standard German and asked to translate it to their Swiss German dialect before recording it. To increase the corpus quality, recordings were validated by other participants. The data consists of 200 hours of speech by around 4000 different speakers and covers a large part of the Swiss-German dialect landscape. We release SDS-200 alongside a baseline speech translation model, which achieves a word error rate (WER) of 30.3 and a BLEU score of 53.1 on the SDS-200 test set. Furthermore, we use SDS-200 to fine-tune a pre-trained XLS-R model, achieving 21.6 WER and 64.0 BLEU.
A Spiking Neural Network based on Neural Manifold for Augmenting Intracortical Brain-Computer Interface Data
Mar 26, 2022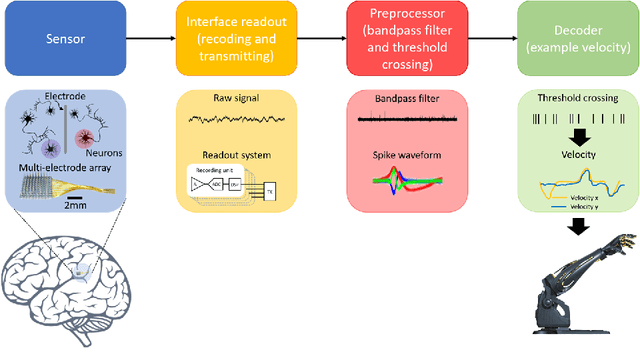
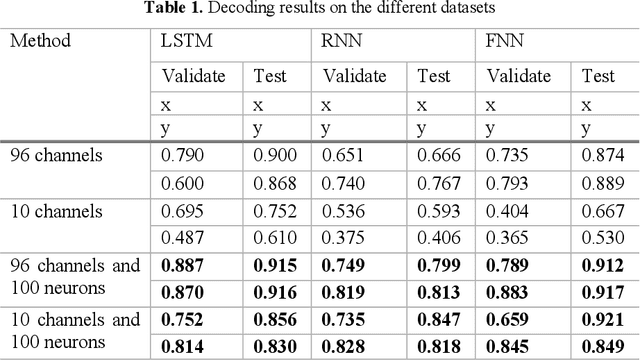
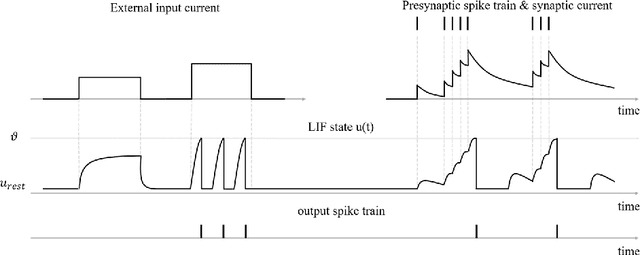
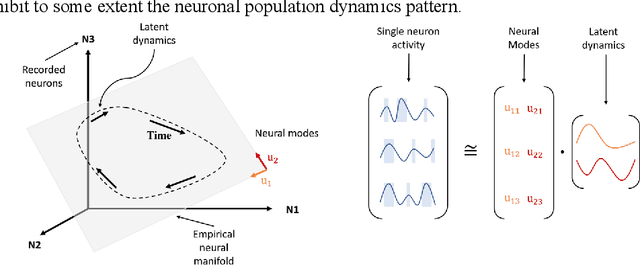
Brain-computer interfaces (BCIs), transform neural signals in the brain into in-structions to control external devices. However, obtaining sufficient training data is difficult as well as limited. With the advent of advanced machine learning methods, the capability of brain-computer interfaces has been enhanced like never before, however, these methods require a large amount of data for training and thus require data augmentation of the limited data available. Here, we use spiking neural networks (SNN) as data generators. It is touted as the next-generation neu-ral network and is considered as one of the algorithms oriented to general artifi-cial intelligence because it borrows the neural information processing from bio-logical neurons. We use the SNN to generate neural spike information that is bio-interpretable and conforms to the intrinsic patterns in the original neural data. Ex-periments show that the model can directly synthesize new spike trains, which in turn improves the generalization ability of the BCI decoder. Both the input and output of the spiking neural model are spike information, which is a brain-inspired intelligence approach that can be better integrated with BCI in the future.
Adapting Rapid Motor Adaptation for Bipedal Robots
May 30, 2022
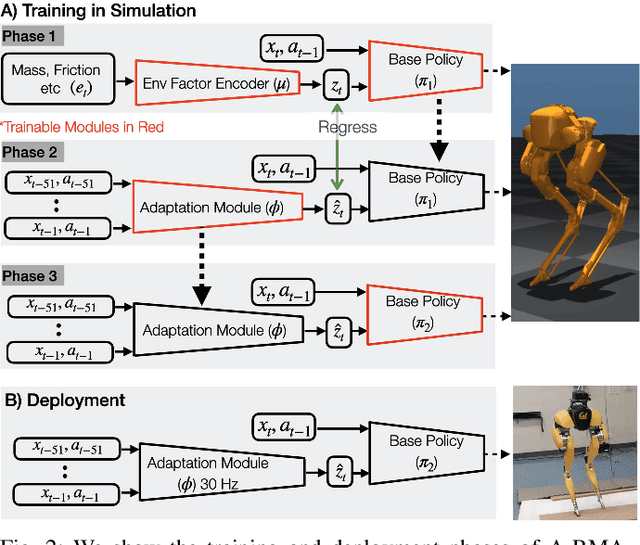
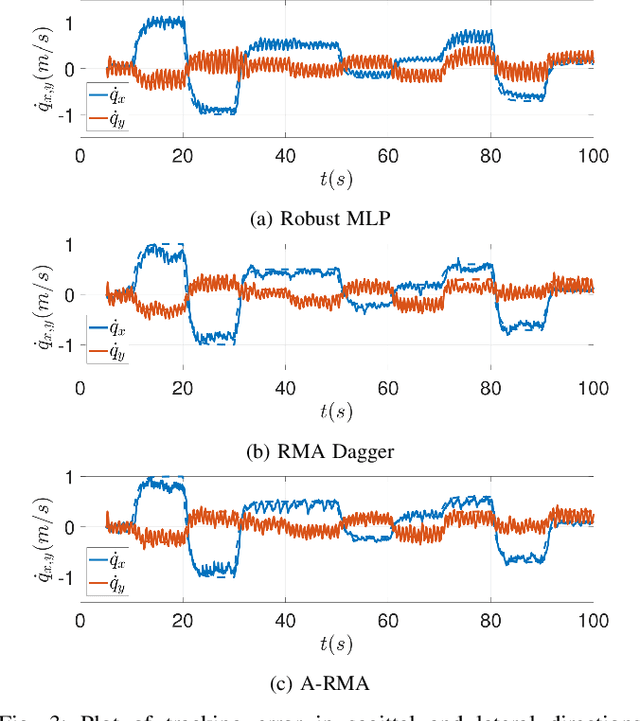
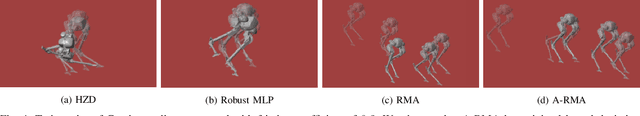
Recent advances in legged locomotion have enabled quadrupeds to walk on challenging terrains. However, bipedal robots are inherently more unstable and hence it's harder to design walking controllers for them. In this work, we leverage recent advances in rapid adaptation for locomotion control, and extend them to work on bipedal robots. Similar to existing works, we start with a base policy which produces actions while taking as input an estimated extrinsics vector from an adaptation module. This extrinsics vector contains information about the environment and enables the walking controller to rapidly adapt online. However, the extrinsics estimator could be imperfect, which might lead to poor performance of the base policy which expects a perfect estimator. In this paper, we propose A-RMA (Adapting RMA), which additionally adapts the base policy for the imperfect extrinsics estimator by finetuning it using model-free RL. We demonstrate that A-RMA outperforms a number of RL-based baseline controllers and model-based controllers in simulation, and show zero-shot deployment of a single A-RMA policy to enable a bipedal robot, Cassie, to walk in a variety of different scenarios in the real world beyond what it has seen during training. Videos and results at https://ashish-kmr.github.io/a-rma/
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
May 27, 2022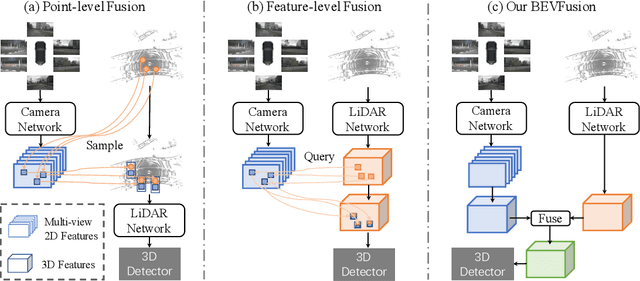

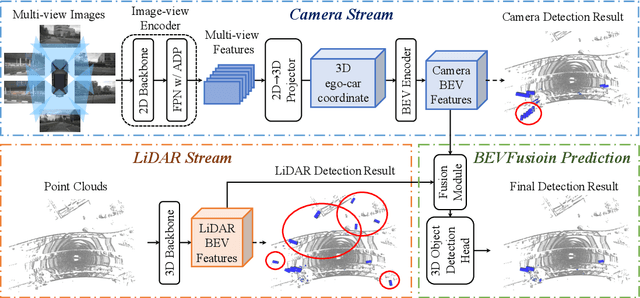
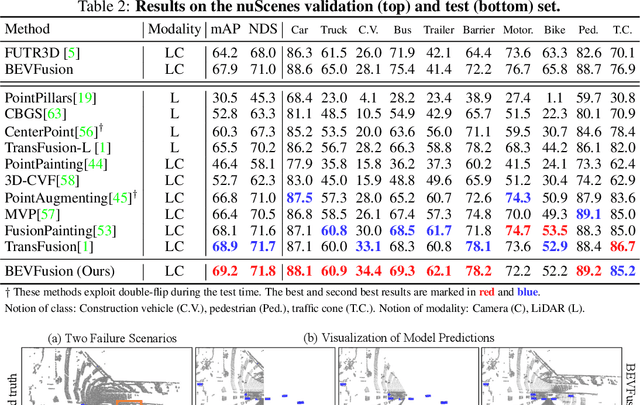
Fusing the camera and LiDAR information has become a de-facto standard for 3D object detection tasks. Current methods rely on point clouds from the LiDAR sensor as queries to leverage the feature from the image space. However, people discover that this underlying assumption makes the current fusion framework infeasible to produce any prediction when there is a LiDAR malfunction, regardless of minor or major. This fundamentally limits the deployment capability to realistic autonomous driving scenarios. In contrast, we propose a surprisingly simple yet novel fusion framework, dubbed BEVFusion, whose camera stream does not depend on the input of LiDAR data, thus addressing the downside of previous methods. We empirically show that our framework surpasses the state-of-the-art methods under the normal training settings. Under the robustness training settings that simulate various LiDAR malfunctions, our framework significantly surpasses the state-of-the-art methods by 15.7% to 28.9% mAP. To the best of our knowledge, we are the first to handle realistic LiDAR malfunction and can be deployed to realistic scenarios without any post-processing procedure. The code is available at https://github.com/ADLab-AutoDrive/BEVFusion.
ViViD++: Vision for Visibility Dataset
Apr 14, 2022
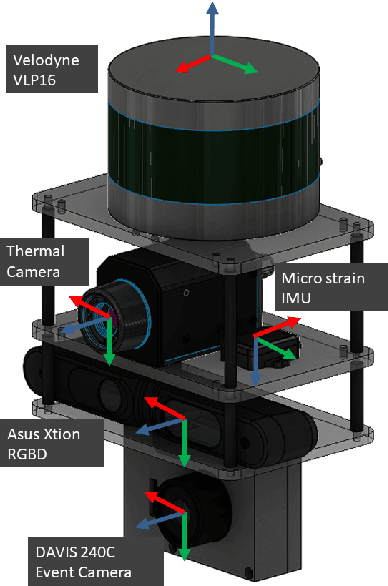

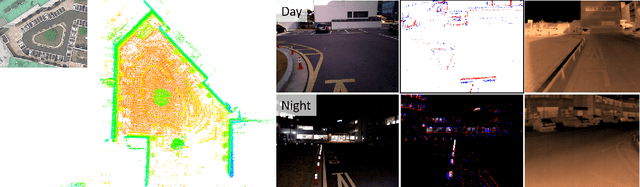
In this paper, we present a dataset capturing diverse visual data formats that target varying luminance conditions. While RGB cameras provide nourishing and intuitive information, changes in lighting conditions potentially result in catastrophic failure for robotic applications based on vision sensors. Approaches overcoming illumination problems have included developing more robust algorithms or other types of visual sensors, such as thermal and event cameras. Despite the alternative sensors' potential, there still are few datasets with alternative vision sensors. Thus, we provided a dataset recorded from alternative vision sensors, by handheld or mounted on a car, repeatedly in the same space but in different conditions. We aim to acquire visible information from co-aligned alternative vision sensors. Our sensor system collects data more independently from visible light intensity by measuring the amount of infrared dissipation, depth by structured reflection, and instantaneous temporal changes in luminance. We provide these measurements along with inertial sensors and ground-truth for developing robust visual SLAM under poor illumination. The full dataset is available at: https://visibilitydataset.github.io/