 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Siamese Network for Semi-supervised Speech Recognition
May 27, 2022
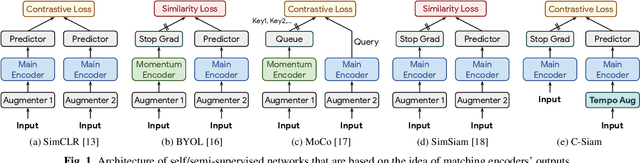
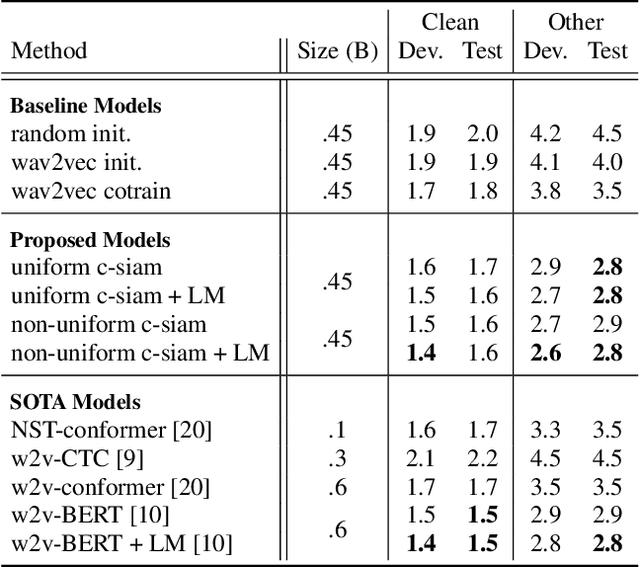
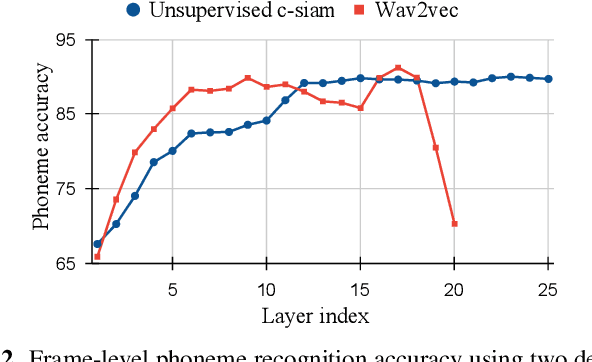
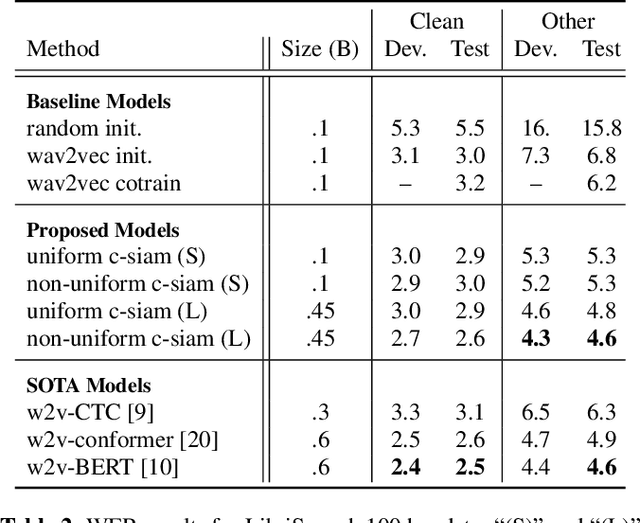
This paper introduces contrastive siamese (c-siam) network, an architecture for leveraging unlabeled acoustic data in speech recognition. c-siam is the first network that extracts high-level linguistic information from speech by matching outputs of two identical transformer encoders. It contains augmented and target branches which are trained by: (1) masking inputs and matching outputs with a contrastive loss, (2) incorporating a stop gradient operation on the target branch, (3) using an extra learnable transformation on the augmented branch, (4) introducing new temporal augment functions to prevent the shortcut learning problem. We use the Libri-light 60k unsupervised data and the LibriSpeech 100hrs/960hrs supervised data to compare c-siam and other best-performing systems. Our experiments show that c-siam provides 20% relative word error rate improvement over wav2vec baselines. A c-siam network with 450M parameters achieves competitive results compared to the state-of-the-art networks with 600M parameters.
Body Composition Estimation Based on Multimodal Multi-task Deep Neural Network
May 23, 2022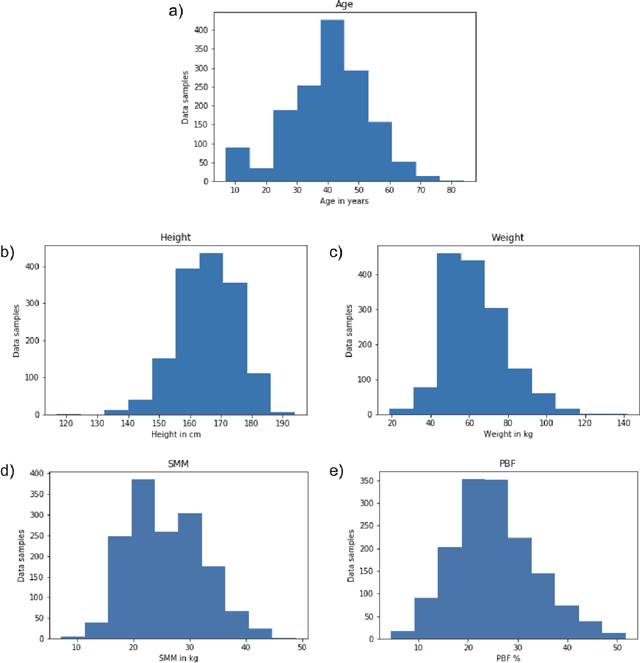
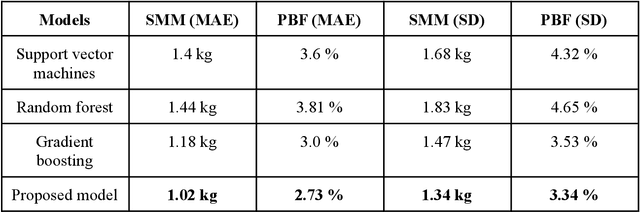
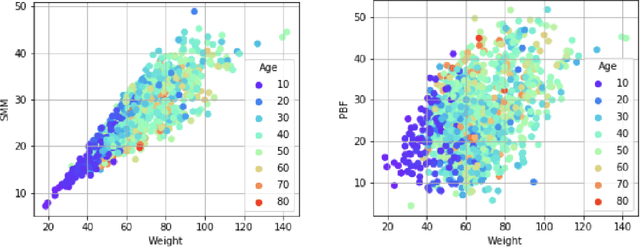
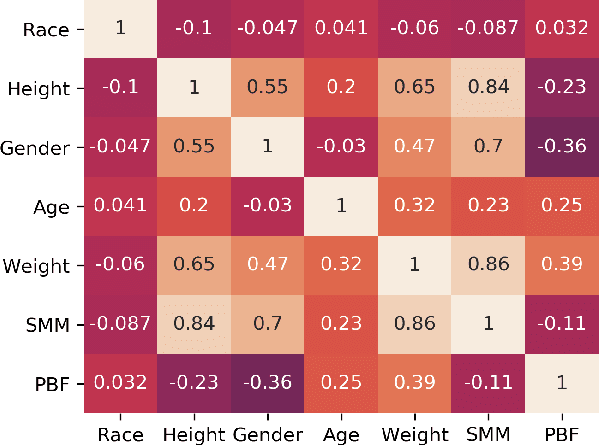
In addition to body weight and Body Mass Index (BMI), body composition is an essential data point that allows people to understand their overall health and body fitness. However, body composition is largely made up of muscle, fat, bones, and water, which makes estimation not as easy and straightforward as measuring body weight. In this paper, we introduce a multimodal multi-task deep neural network to estimate body fat percentage and skeletal muscle mass by analyzing facial images in addition to a person's height, gender, age, and weight information. Using a dataset representative of demographics in Japan, we confirmed that the proposed approach performed better compared to the existing methods. Moreover, the multi-task approach implemented in this study is also able to grasp the negative correlation between body fat percentage and skeletal muscle mass gain/loss.
Deep morphological recognition of kidney stones using intra-operative endoscopic digital videos
May 12, 2022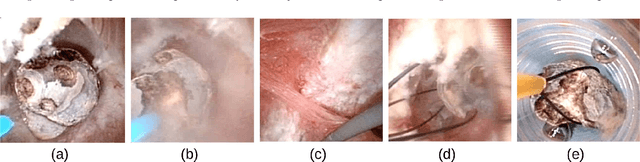

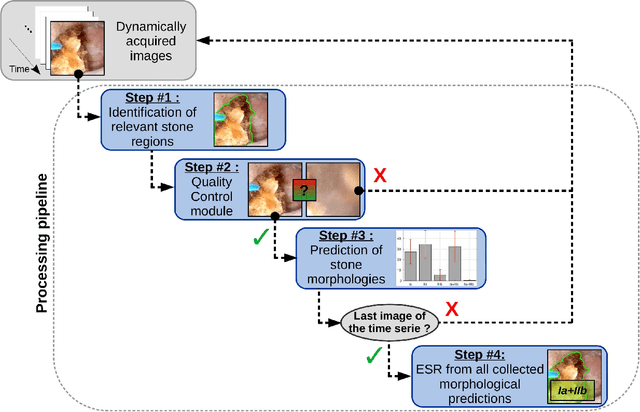
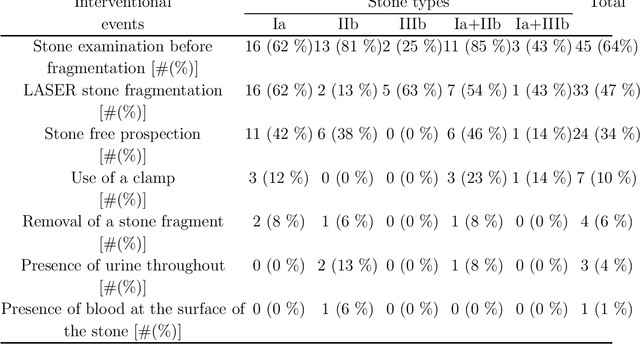
The collection and the analysis of kidney stone morphological criteria are essential for an aetiological diagnosis of stone disease. However, in-situ LASER-based fragmentation of urinary stones, which is now the most established chirurgical intervention, may destroy the morphology of the targeted stone. In the current study, we assess the performance and added value of processing complete digital endoscopic video sequences for the automatic recognition of stone morphological features during a standard-of-care intra-operative session. To this end, a computer-aided video classifier was developed to predict in-situ the morphology of stone using an intra-operative digital endoscopic video acquired in a clinical setting. The proposed technique was evaluated on pure (i.e. include one morphology) and mixed (i.e. include at least two morphologies) stones involving "Ia/Calcium Oxalate Monohydrate (COM)", "IIb/ Calcium Oxalate Dihydrate (COD)" and "IIIb/Uric Acid (UA)" morphologies. 71 digital endoscopic videos (50 exhibited only one morphological type and 21 displayed two) were analyzed using the proposed video classifier (56840 frames processed in total). Using the proposed approach, diagnostic performances (averaged over both pure and mixed stone types) were as follows: balanced accuracy=88%, sensitivity=80%, specificity=95%, precision=78% and F1-score=78%. The obtained results demonstrate that AI applied on digital endoscopic video sequences is a promising tool for collecting morphological information during the time-course of the stone fragmentation process without resorting to any human intervention for stone delineation or selection of good quality steady frames. To this end, irrelevant image information must be removed from the prediction process at both frame and pixel levels, which is now feasible thanks to the use of AI-dedicated networks.
A Review of Mobile Mapping Systems: From Sensors to Applications
May 31, 2022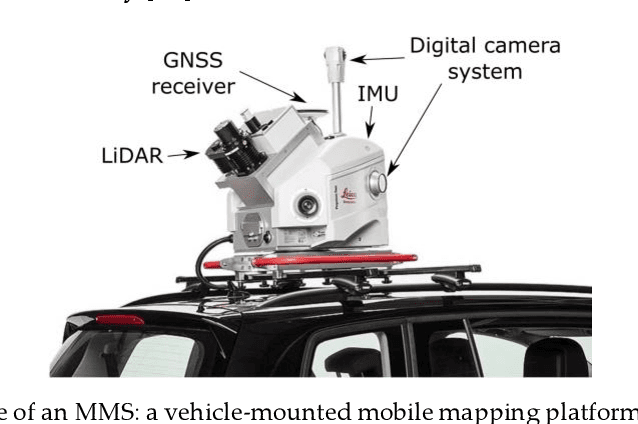
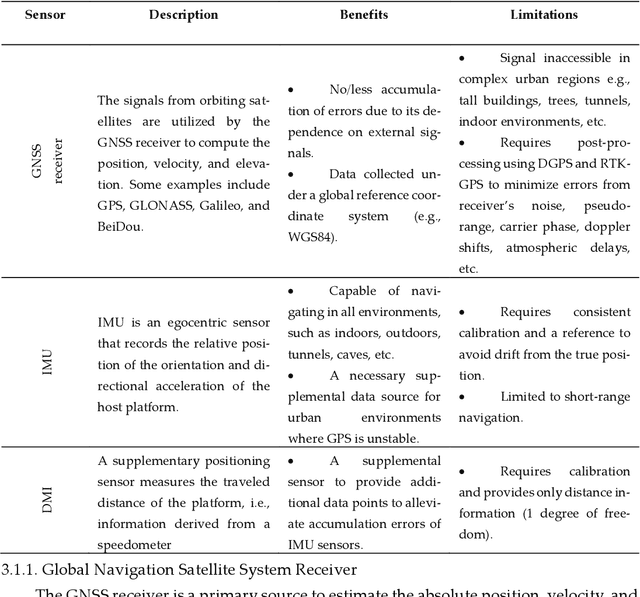
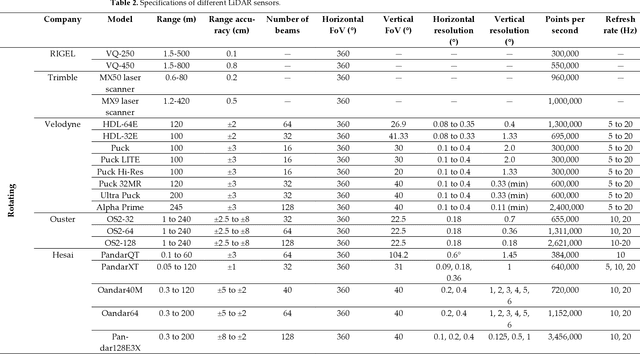

The evolution of mobile mapping systems (MMSs) has gained more attention in the past few decades. MMSs have been widely used to provide valuable assets in different applications. This has been facilitated by the wide availability of low-cost sensors, the advances in computational resources, the maturity of the mapping algorithms, and the need for accurate and on-demand geographic information system (GIS) data and digital maps. Many MMSs combine hybrid sensors to provide a more informative, robust, and stable solution by complementing each other. In this paper, we present a comprehensive review of the modern MMSs by focusing on 1) the types of sensors and platforms, where we discuss their capabilities, limitations, and also provide a comprehensive overview of recent MMS technologies available in the market, 2) highlighting the general workflow to process any MMS data, 3) identifying the different use cases of mobile mapping technology by reviewing some of the common applications, and 4) presenting a discussion on the benefits, challenges, and share our views on the potential research directions.
ORCA: Interpreting Prompted Language Models via Locating Supporting Data Evidence in the Ocean of Pretraining Data
May 25, 2022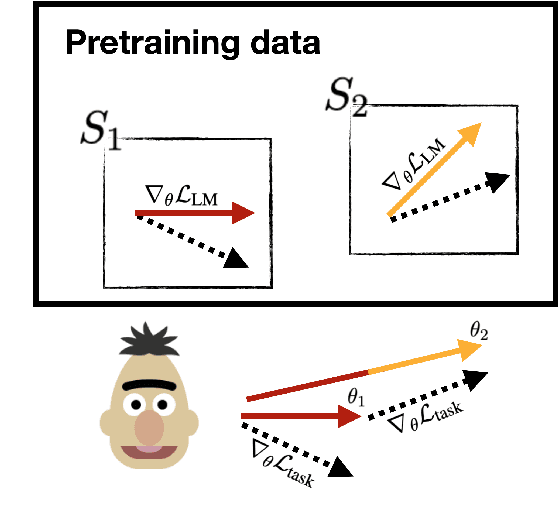

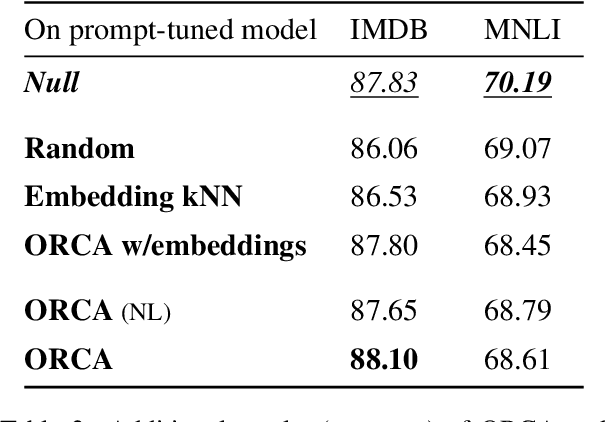
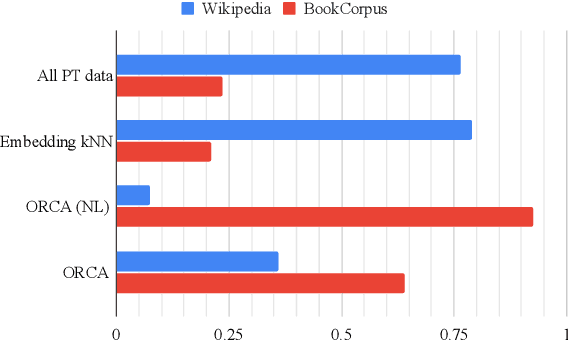
Large pretrained language models have been performing increasingly well in a variety of downstream tasks via prompting. However, it remains unclear from where the model learns the task-specific knowledge, especially in a zero-shot setup. In this work, we want to find evidence of the model's task-specific competence from pretraining and are specifically interested in locating a very small subset of pretraining data that directly supports the model in the task. We call such a subset supporting data evidence and propose a novel method ORCA to effectively identify it, by iteratively using gradient information related to the downstream task. This supporting data evidence offers interesting insights about the prompted language models: in the tasks of sentiment analysis and textual entailment, BERT shows a substantial reliance on BookCorpus, the smaller corpus of BERT's two pretraining corpora, as well as on pretraining examples that mask out synonyms to the task verbalizers.
Generalizable Neural Radiance Fields for Novel View Synthesis with Transformer
Jun 10, 2022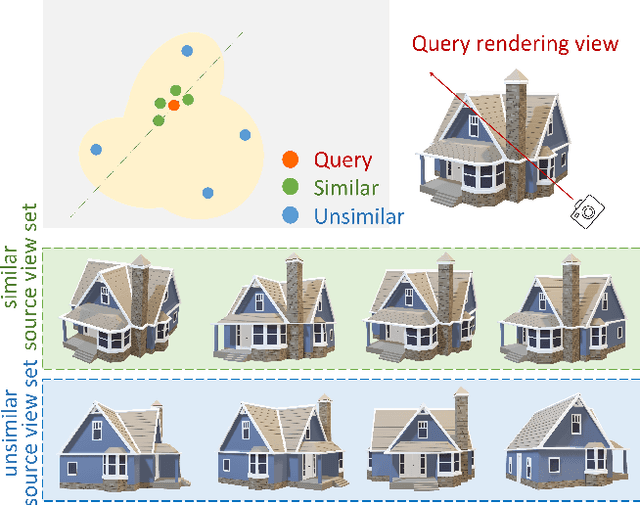

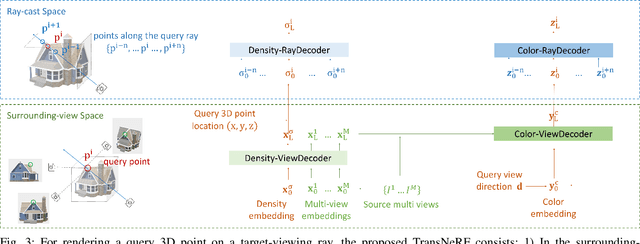

We propose a Transformer-based NeRF (TransNeRF) to learn a generic neural radiance field conditioned on observed-view images for the novel view synthesis task. By contrast, existing MLP-based NeRFs are not able to directly receive observed views with an arbitrary number and require an auxiliary pooling-based operation to fuse source-view information, resulting in the missing of complicated relationships between source views and the target rendering view. Furthermore, current approaches process each 3D point individually and ignore the local consistency of a radiance field scene representation. These limitations potentially can reduce their performance in challenging real-world applications where large differences between source views and a novel rendering view may exist. To address these challenges, our TransNeRF utilizes the attention mechanism to naturally decode deep associations of an arbitrary number of source views into a coordinate-based scene representation. Local consistency of shape and appearance are considered in the ray-cast space and the surrounding-view space within a unified Transformer network. Experiments demonstrate that our TransNeRF, trained on a wide variety of scenes, can achieve better performance in comparison to state-of-the-art image-based neural rendering methods in both scene-agnostic and per-scene finetuning scenarios especially when there is a considerable gap between source views and a rendering view.
Joint Multisided Exposure Fairness for Recommendation
Apr 29, 2022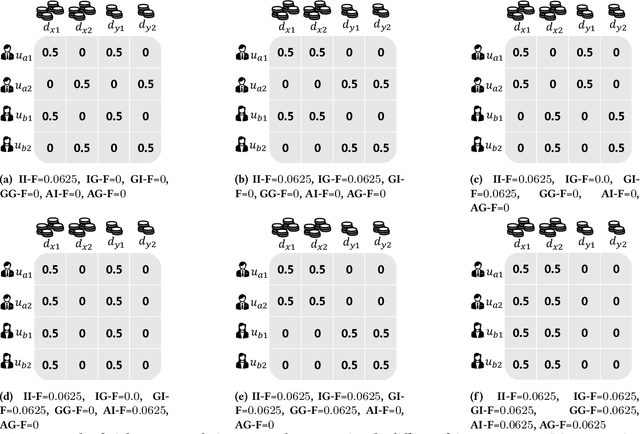
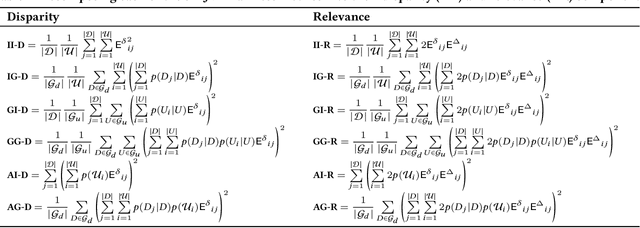
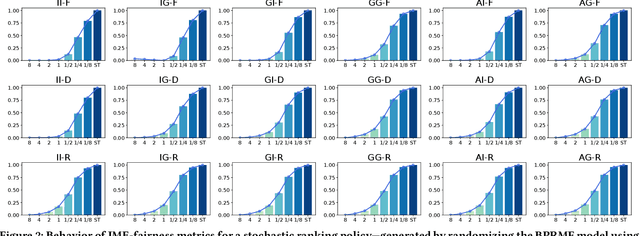
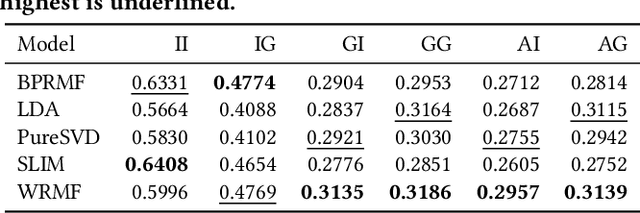
Prior research on exposure fairness in the context of recommender systems has focused mostly on disparities in the exposure of individual or groups of items to individual users of the system. The problem of how individual or groups of items may be systemically under or over exposed to groups of users, or even all users, has received relatively less attention. However, such systemic disparities in information exposure can result in observable social harms, such as withholding economic opportunities from historically marginalized groups (allocative harm) or amplifying gendered and racialized stereotypes (representational harm). Previously, Diaz et al. developed the expected exposure metric -- that incorporates existing user browsing models that have previously been developed for information retrieval -- to study fairness of content exposure to individual users. We extend their proposed framework to formalize a family of exposure fairness metrics that model the problem jointly from the perspective of both the consumers and producers. Specifically, we consider group attributes for both types of stakeholders to identify and mitigate fairness concerns that go beyond individual users and items towards more systemic biases in recommendation. Furthermore, we study and discuss the relationships between the different exposure fairness dimensions proposed in this paper, as well as demonstrate how stochastic ranking policies can be optimized towards said fairness goals.
Contrasting quadratic assignments for set-based representation learning
May 31, 2022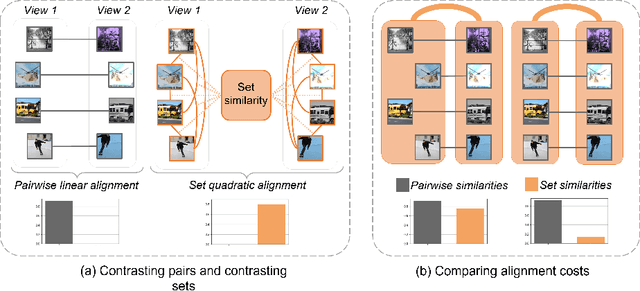

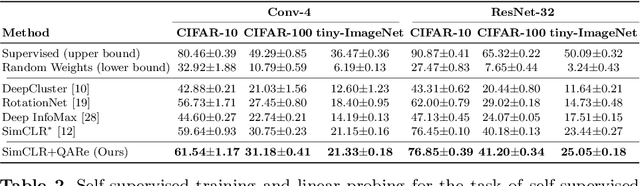
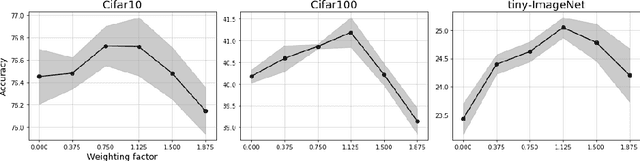
The standard approach to contrastive learning is to maximize the agreement between different views of the data. The views are ordered in pairs, such that they are either positive, encoding different views of the same object, or negative, corresponding to views of different objects. The supervisory signal comes from maximizing the total similarity over positive pairs, while the negative pairs are needed to avoid collapse. In this work, we note that the approach of considering individual pairs cannot account for both intra-set and inter-set similarities when the sets are formed from the views of the data. It thus limits the information content of the supervisory signal available to train representations. We propose to go beyond contrasting individual pairs of objects by focusing on contrasting objects as sets. For this, we use combinatorial quadratic assignment theory designed to evaluate set and graph similarities and derive set-contrastive objective as a regularizer for contrastive learning methods. We conduct experiments and demonstrate that our method improves learned representations for the tasks of metric learning and self-supervised classification.
Investigating Brain Connectivity with Graph Neural Networks and GNNExplainer
Jun 04, 2022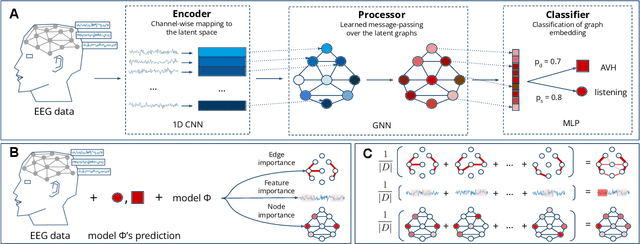
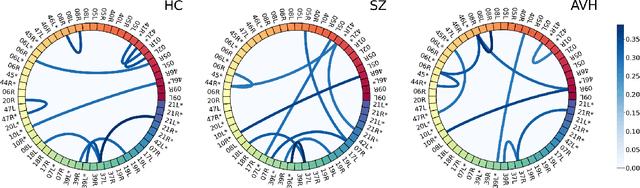
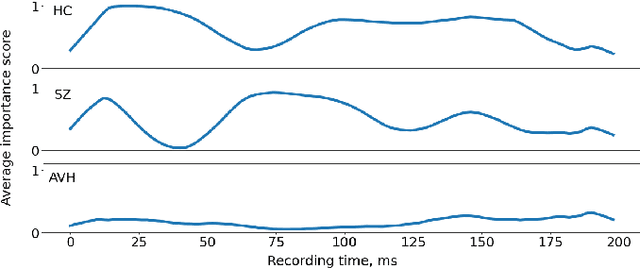
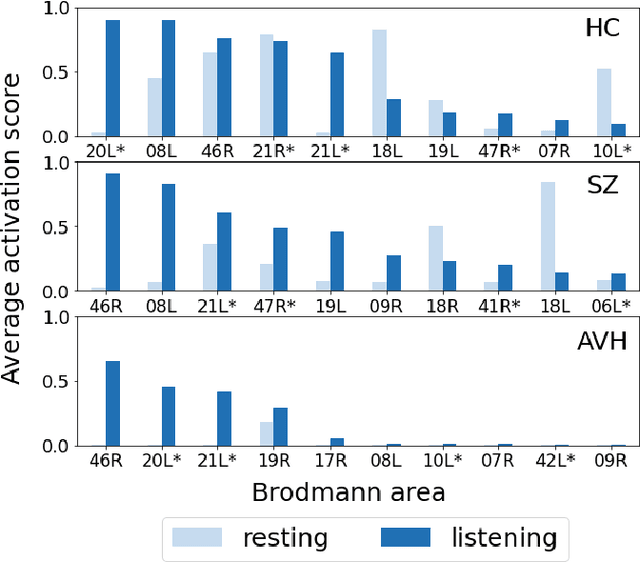
Functional connectivity plays an essential role in modern neuroscience. The modality sheds light on the brain's functional and structural aspects, including mechanisms behind multiple pathologies. One such pathology is schizophrenia which is often followed by auditory verbal hallucinations. The latter is commonly studied by observing functional connectivity during speech processing. In this work, we have made a step toward an in-depth examination of functional connectivity during a dichotic listening task via deep learning for three groups of people: schizophrenia patients with and without auditory verbal hallucinations and healthy controls. We propose a graph neural network-based framework within which we represent EEG data as signals in the graph domain. The framework allows one to 1) predict a brain mental disorder based on EEG recording, 2) differentiate the listening state from the resting state for each group and 3) recognize characteristic task-depending connectivity. Experimental results show that the proposed model can differentiate between the above groups with state-of-the-art performance. Besides, it provides a researcher with meaningful information regarding each group's functional connectivity, which we validated on the current domain knowledge.
A Linguistic Study on Relevance Modeling in Information Retrieval
Mar 01, 2021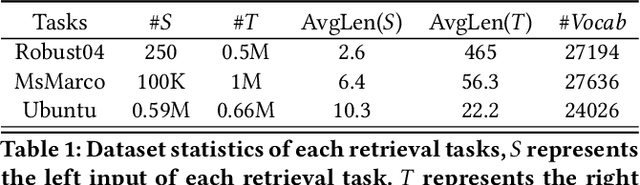
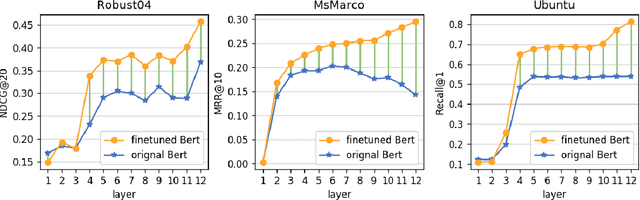
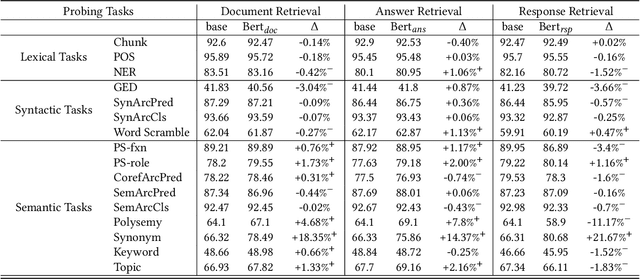
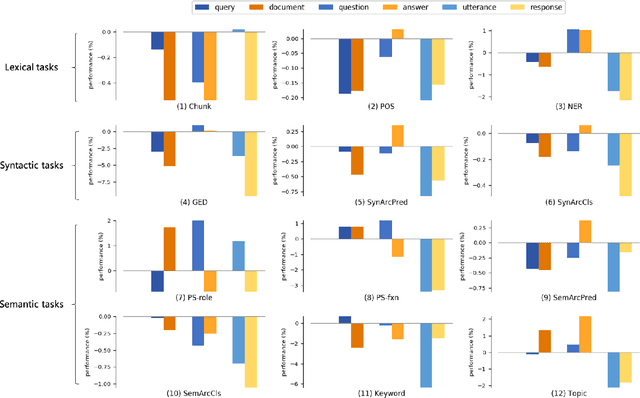
Relevance plays a central role in information retrieval (IR), which has received extensive studies starting from the 20th century. The definition and the modeling of relevance has always been critical challenges in both information science and computer science research areas. Along with the debate and exploration on relevance, IR has already become a core task in many real-world applications, such as Web search engines, question answering systems, conversational bots, and so on. While relevance acts as a unified concept in all these retrieval tasks, the inherent definitions are quite different due to the heterogeneity of these tasks. This raises a question to us: Do these different forms of relevance really lead to different modeling focuses? To answer this question, in this work, we conduct an empirical study on relevance modeling in three representative IR tasks, i.e., document retrieval, answer retrieval, and response retrieval. Specifically, we attempt to study the following two questions: 1) Does relevance modeling in these tasks really show differences in terms of natural language understanding (NLU)? We employ 16 linguistic tasks to probe a unified retrieval model over these three retrieval tasks to answer this question. 2) If there do exist differences, how can we leverage the findings to enhance the relevance modeling? We proposed three intervention methods to investigate how to leverage different modeling focuses of relevance to improve these IR tasks. We believe the way we study the problem as well as our findings would be beneficial to the IR community.