 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
[Re] Distilling Knowledge via Knowledge Review
May 18, 2022
![Figure 1 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F5-Table1-1.png&w=640&q=75)
![Figure 3 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F6-Table2-1.png&w=640&q=75)
![Figure 4 for [Re] Distilling Knowledge via Knowledge Review](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F01db18293fff2a0b1e6f3030e2a7c89133b9b089%2F3-Figure3-1.png&w=640&q=75)
This effort aims to reproduce the results of experiments and analyze the robustness of the review framework for knowledge distillation introduced in the CVPR '21 paper 'Distilling Knowledge via Knowledge Review' by Chen et al. Previous works in knowledge distillation only studied connections paths between the same levels of the student and the teacher, and cross-level connection paths had not been considered. Chen et al. propose a new residual learning framework to train a single student layer using multiple teacher layers. They also design a novel fusion module to condense feature maps across levels and a loss function to compare feature information stored across different levels to improve performance. In this work, we consistently verify the improvements in test accuracy across student models as reported in the original paper and study the effectiveness of the novel modules introduced by conducting ablation studies and new experiments.
Layer-wise Characterization of Latent Information Leakage in Federated Learning
Oct 17, 2020

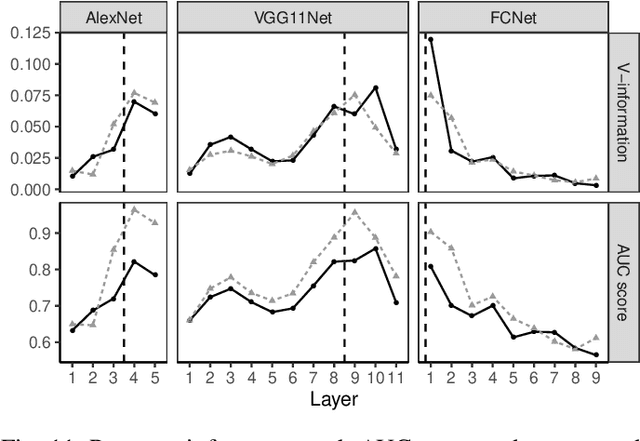
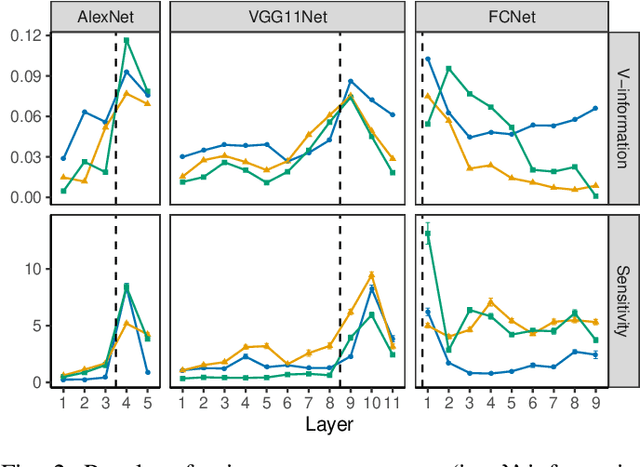
Training a deep neural network (DNN) via federated learning allows participants to share model updates (gradients), instead of the data itself. However, recent studies show that unintended latent information (e.g. gender or race) carried by the gradients can be discovered by attackers, compromising the promised privacy guarantee of federated learning. Existing privacy-preserving techniques (e.g. differential privacy) either have limited defensive capacity against the potential attacks, or suffer from considerable model utility loss. Moreover, characterizing the latent information carried by the gradients and the consequent privacy leakage has been a major theoretical and practical challenge. In this paper, we propose two new metrics to address these challenges: the empirical $\mathcal{V}$-information, a theoretically grounded notion of information which measures the amount of gradient information that is usable for an attacker, and the sensitivity analysis that utilizes the Jacobian matrix to measure the amount of changes in the gradients with respect to latent information which further quantifies private risk. We show that these metrics can localize the private information in each layer of a DNN and quantify the leakage depending on how sensitive the gradients are with respect to the latent information. As a practical application, we design LatenTZ: a federated learning framework that lets the most sensitive layers to run in the clients' Trusted Execution Environments (TEE). The implementation evaluation of LatenTZ shows that TEE-based approaches are promising for defending against powerful property inference attacks without a significant overhead in the clients' computing resources nor trading off the model's utility.
Dialog Inpainting: Turning Documents into Dialogs
May 31, 2022
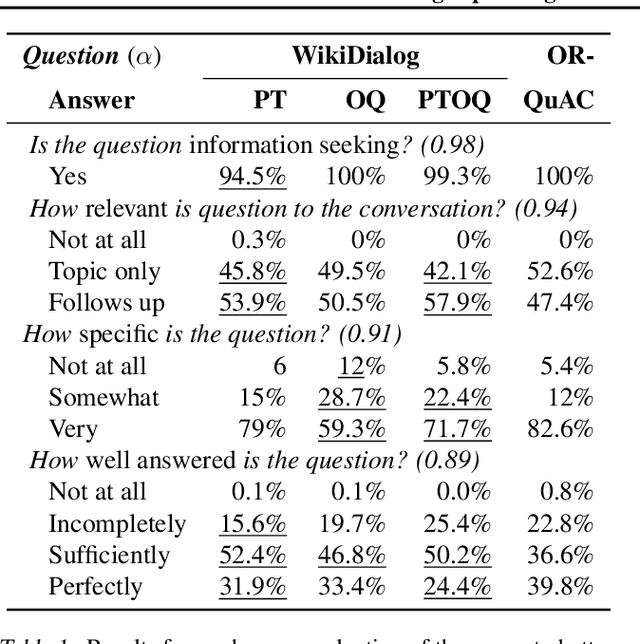
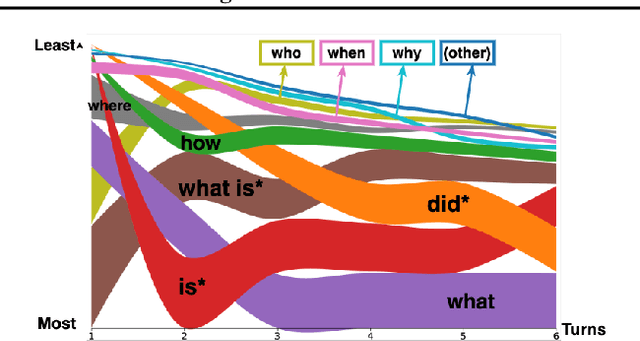
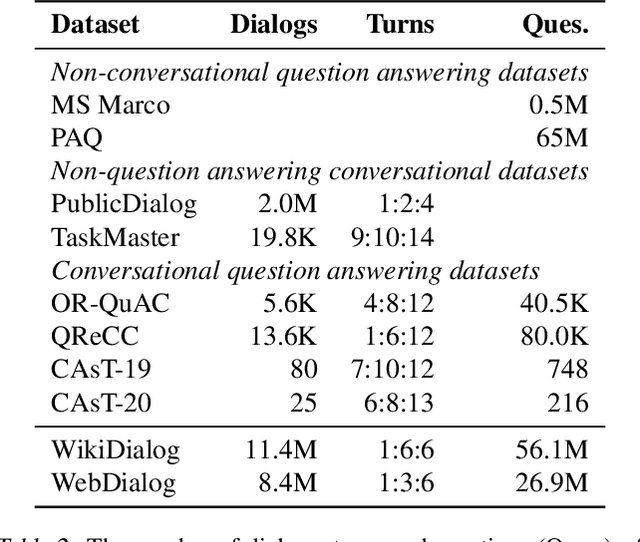
Many important questions (e.g. "How to eat healthier?") require conversation to establish context and explore in depth. However, conversational question answering (ConvQA) systems have long been stymied by scarce training data that is expensive to collect. To address this problem, we propose a new technique for synthetically generating diverse and high-quality dialog data: dialog inpainting. Our approach takes the text of any document and transforms it into a two-person dialog between the writer and an imagined reader: we treat sentences from the article as utterances spoken by the writer, and then use a dialog inpainter to predict what the imagined reader asked or said in between each of the writer's utterances. By applying this approach to passages from Wikipedia and the web, we produce WikiDialog and WebDialog, two datasets totalling 19 million diverse information-seeking dialogs -- 1,000x larger than the largest existing ConvQA dataset. Furthermore, human raters judge the answer adequacy and conversationality of WikiDialog to be as good or better than existing manually-collected datasets. Using our inpainted data to pre-train ConvQA retrieval systems, we significantly advance state-of-the-art across three benchmarks (QReCC, OR-QuAC, TREC CAsT) yielding up to 40% relative gains on standard evaluation metrics.
The Effect of Multi-Generational Selection in Geometric Semantic Genetic Programming
May 05, 2022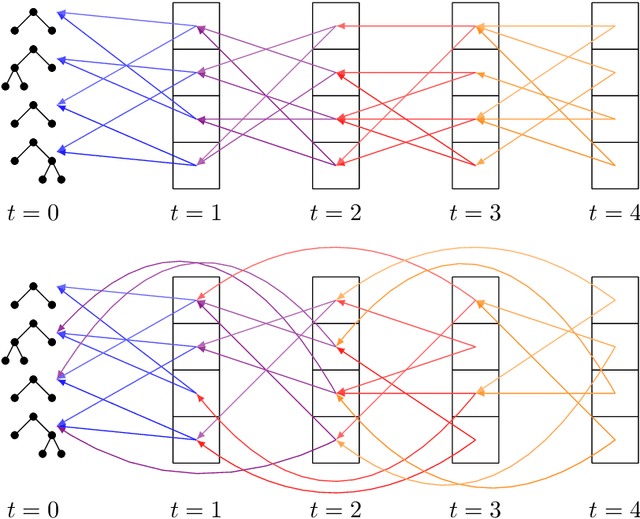
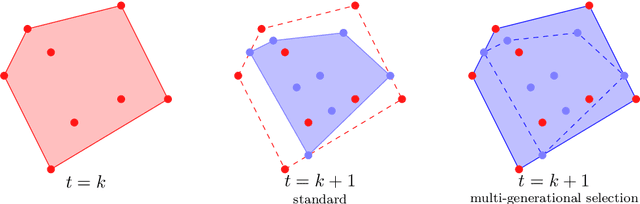

Among the evolutionary methods, one that is quite prominent is Genetic Programming, and, in recent years, a variant called Geometric Semantic Genetic Programming (GSGP) has shown to be successfully applicable to many real-world problems. Due to a peculiarity in its implementation, GSGP needs to store all the evolutionary history, i.e., all populations from the first one. We exploit this stored information to define a multi-generational selection scheme that is able to use individuals from older populations. We show that a limited ability to use "old" generations is actually useful for the search process, thus showing a zero-cost way of improving the performances of GSGP.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 24, 2022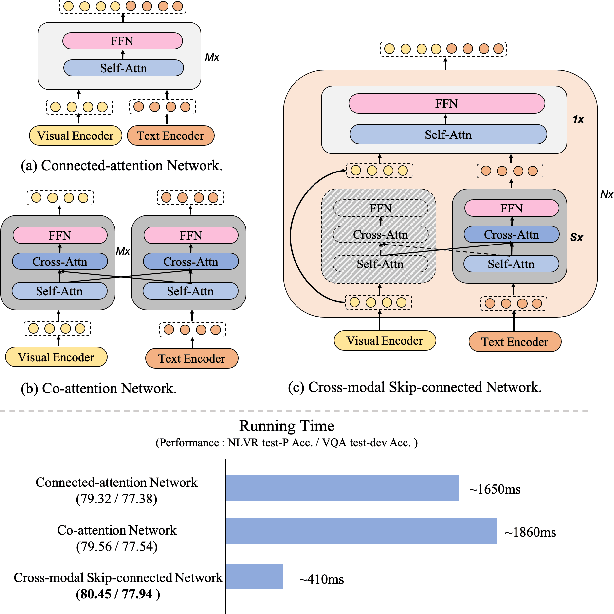
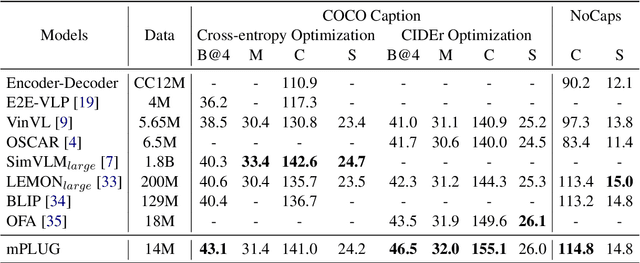
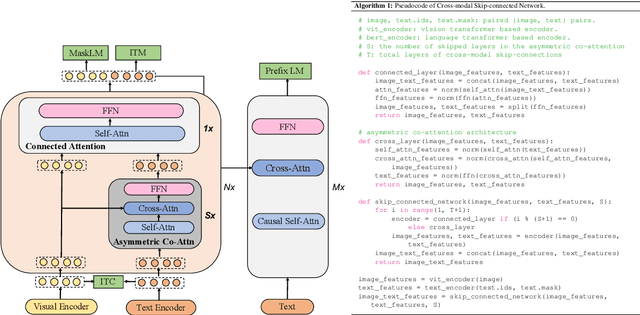
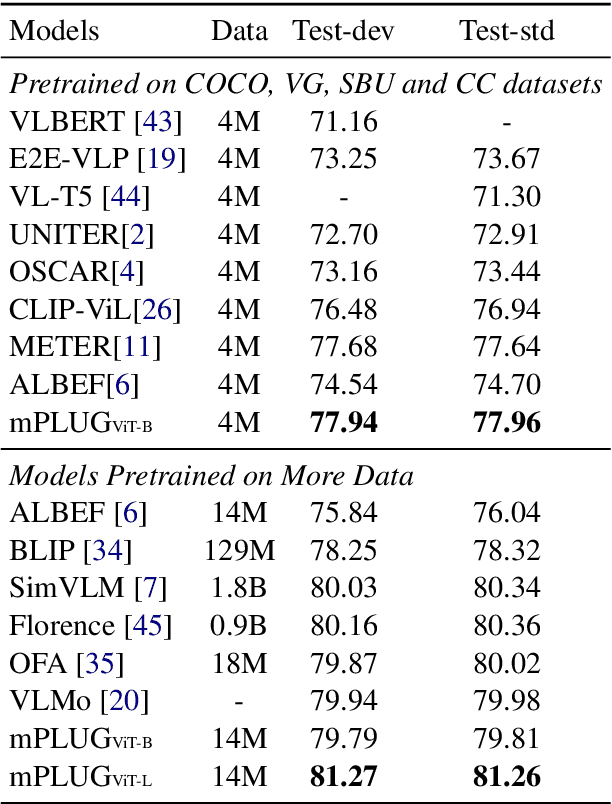
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
Multi-Level Modeling Units for End-to-End Mandarin Speech Recognition
May 24, 2022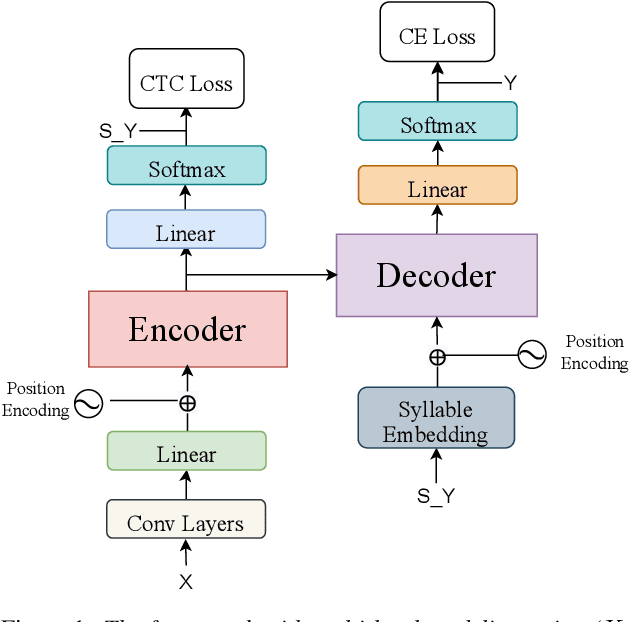

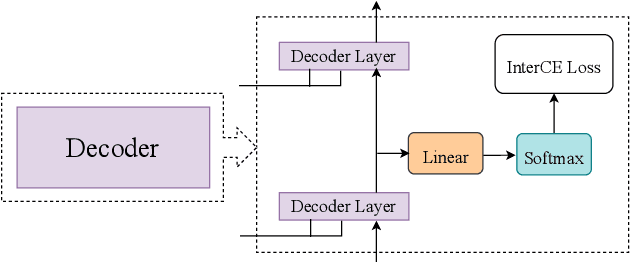
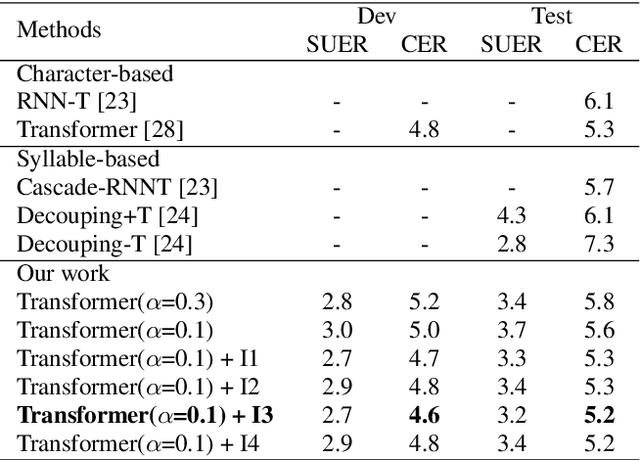
The choice of modeling units affects the performance of the acoustic modeling and plays an important role in automatic speech recognition (ASR). In mandarin scenarios, the Chinese characters represent meaning but are not directly related to the pronunciation. Thus only considering the writing of Chinese characters as modeling units is insufficient to capture speech features. In this paper, we present a novel method involves with multi-level modeling units, which integrates multi-level information for mandarin speech recognition. Specifically, the encoder block considers syllables as modeling units, and the decoder block deals with character modeling units. During inference, the input feature sequences are converted into syllable sequences by the encoder block and then converted into Chinese characters by the decoder block. This process is conducted by a unified end-to-end model without introducing additional conversion models. By introducing InterCE auxiliary task, our method achieves competitive results with CER of 4.1%/4.6% and 4.6%/5.2% on the widely used AISHELL-1 benchmark without a language model, using the Conformer and the Transformer backbones respectively.
InDistill: Transferring Knowledge From Pruned Intermediate Layers
May 20, 2022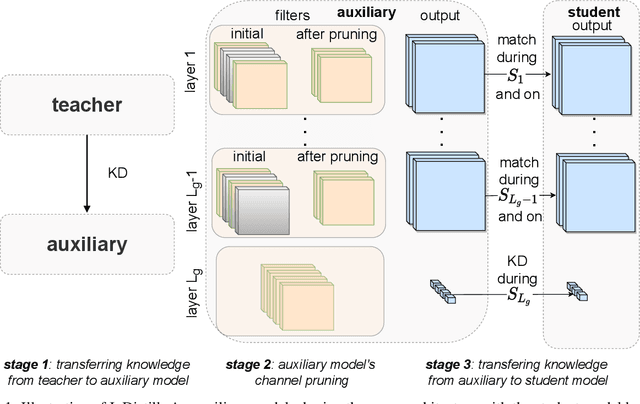
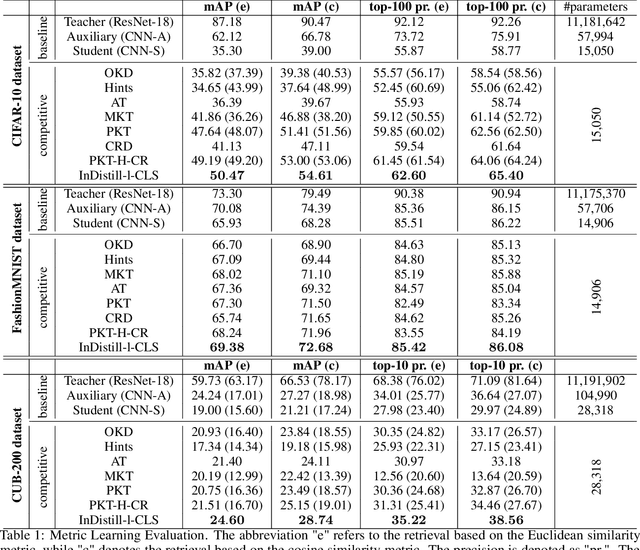
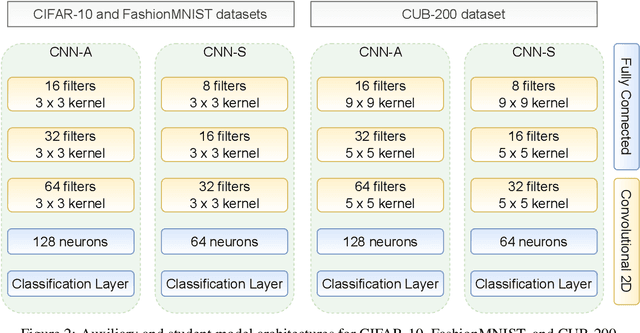
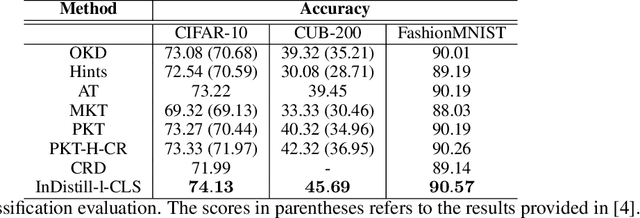
Deploying deep neural networks on hardware with limited resources, such as smartphones and drones, constitutes a great challenge due to their computational complexity. Knowledge distillation approaches aim at transferring knowledge from a large model to a lightweight one, also known as teacher and student respectively, while distilling the knowledge from intermediate layers provides an additional supervision to that task. The capacity gap between the models, the information encoding that collapses its architectural alignment, and the absence of appropriate learning schemes for transferring multiple layers restrict the performance of existing methods. In this paper, we propose a novel method, termed InDistill, that can drastically improve the performance of existing single-layer knowledge distillation methods by leveraging the properties of channel pruning to both reduce the capacity gap between the models and retain the architectural alignment. Furthermore, we propose a curriculum learning based scheme for enhancing the effectiveness of transferring knowledge from multiple intermediate layers. The proposed method surpasses state-of-the-art performance on three benchmark image datasets.
Chained Generalisation Bounds
Mar 02, 2022
This work discusses how to derive upper bounds for the expected generalisation error of supervised learning algorithms by means of the chaining technique. By developing a general theoretical framework, we establish a duality between generalisation bounds based on the regularity of the loss function, and their chained counterparts, which can be obtained by lifting the regularity assumption from the loss onto its gradient. This allows us to re-derive the chaining mutual information bound from the literature, and to obtain novel chained information-theoretic generalisation bounds, based on the Wasserstein distance and other probability metrics. We show on some toy examples that the chained generalisation bound can be significantly tighter than its standard counterpart, particularly when the distribution of the hypotheses selected by the algorithm is very concentrated. Keywords: Generalisation bounds; Chaining; Information-theoretic bounds; Mutual information; Wasserstein distance; PAC-Bayes.
Parallel Parking: Optimal Entry and Minimum Slot Dimensions
May 05, 2022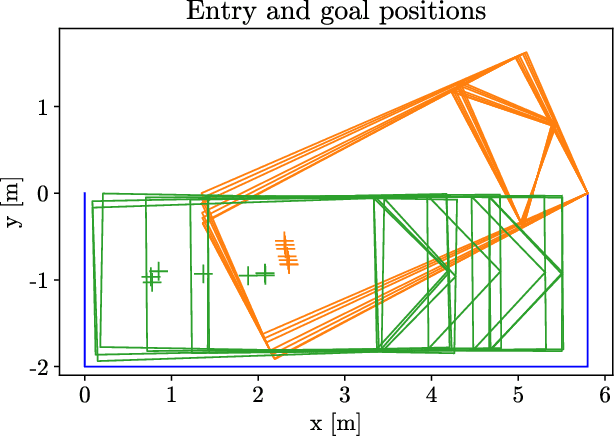
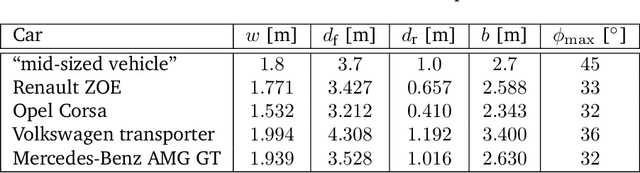
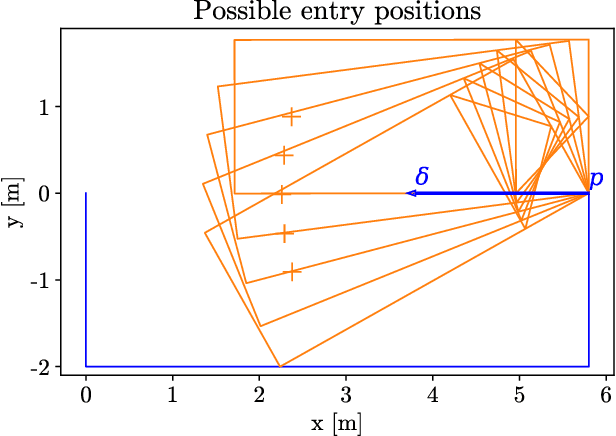
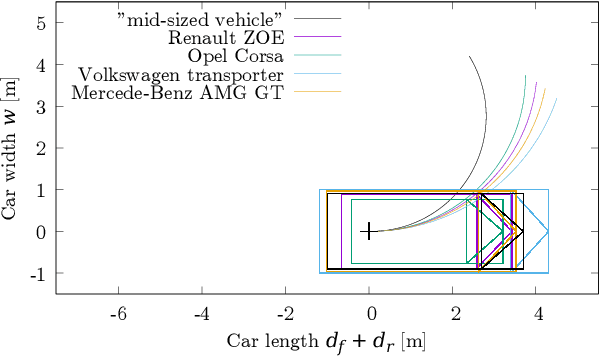
The problem of path planning for automated parking is usually presented as finding a collision-free path from initial to goal positions, where three out of four parking slot edges represent obstacles. We rethink the path planning problem for parallel parking by decomposing it into two independent parts. The topic of this paper is finding optimal parking slot entry positions. Path planning from initial to entry position is out of scope here. We show the relation between entry positions, parking slot dimensions, and the number of backward-forward direction changes. This information can be used as an input to optimize other parts of the automated parking process.
* 14 pages (title + 9 of paper + 4 of appendix), 11 (paper) + 4 (appendix) figures, sent to VEHITS 2022 conference
An Adaptive Contrastive Learning Model for Spike Sorting
May 24, 2022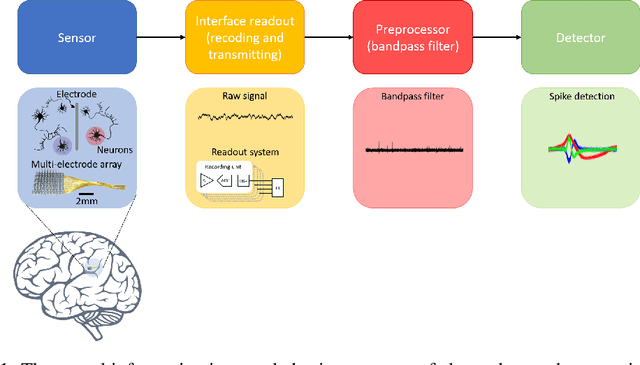
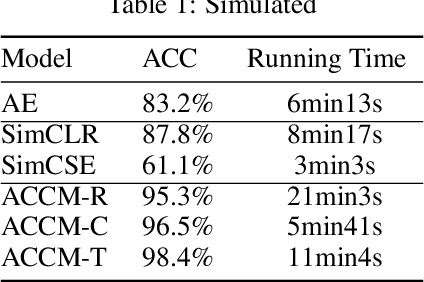
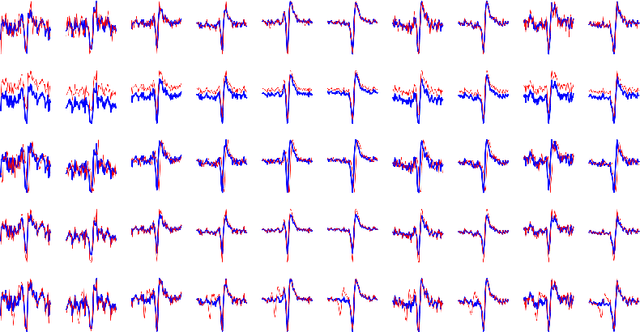
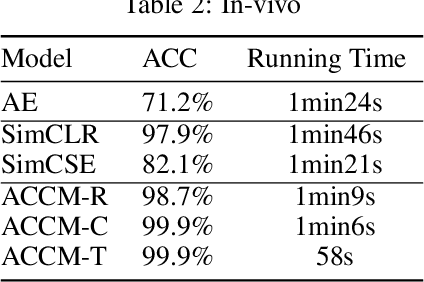
Brain-computer interfaces (BCIs), is ways for electronic devices to communicate directly with the brain. For most medical-type brain-computer interface tasks, the activity of multiple units of neurons or local field potentials is sufficient for decoding. But for BCIs used in neuroscience research, it is important to separate out the activity of individual neurons. With the development of large-scale silicon technology and the increasing number of probe channels, artificially interpreting and labeling spikes is becoming increasingly impractical. In this paper, we propose a novel modeling framework: Adaptive Contrastive Learning Model that learns representations from spikes through contrastive learning based on the maximizing mutual information loss function as a theoretical basis. Based on the fact that data with similar features share the same labels whether they are multi-classified or binary-classified. With this theoretical support, we simplify the multi-classification problem into multiple binary-classification, improving both the accuracy and the runtime efficiency. Moreover, we also introduce a series of enhancements for the spikes, while solving the problem that the classification effect is affected because of the overlapping spikes.