 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Same Author or Just Same Topic? Towards Content-Independent Style Representations
Apr 11, 2022
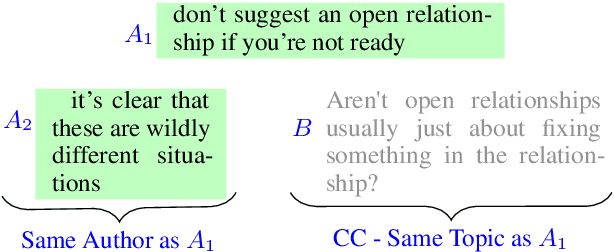
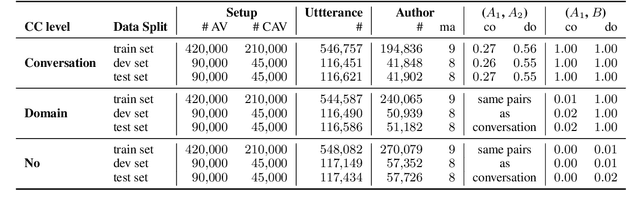
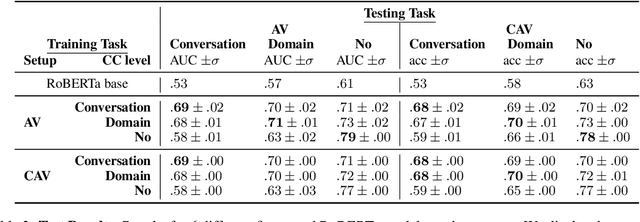

Linguistic style is an integral component of language. Recent advances in the development of style representations have increasingly used training objectives from authorship verification (AV): Do two texts have the same author? The assumption underlying the AV training task (same author approximates same writing style) enables self-supervised and, thus, extensive training. However, a good performance on the AV task does not ensure good "general-purpose" style representations. For example, as the same author might typically write about certain topics, representations trained on AV might also encode content information instead of style alone. We introduce a variation of the AV training task that controls for content using conversation or domain labels. We evaluate whether known style dimensions are represented and preferred over content information through an original variation to the recently proposed STEL framework. We find that representations trained by controlling for conversation are better than representations trained with domain or no content control at representing style independent from content.
E-Scooter Rider Detection and Classification in Dense Urban Environments
May 20, 2022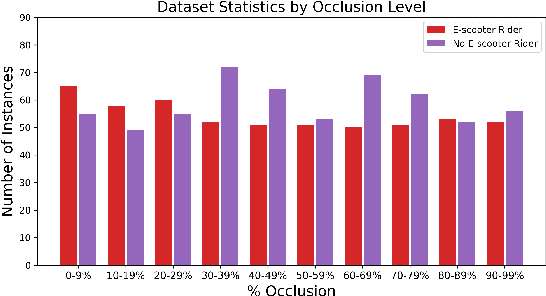

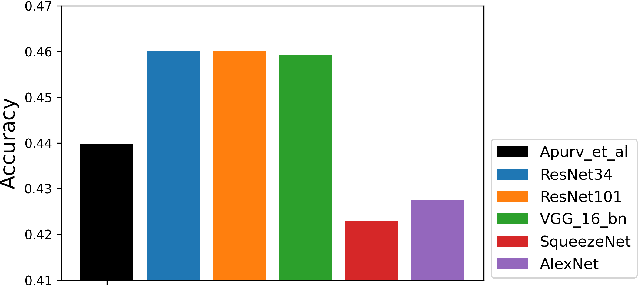
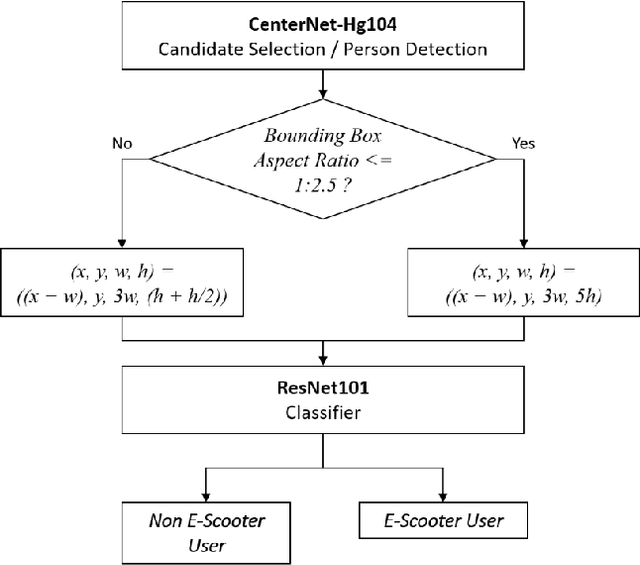
Accurate detection and classification of vulnerable road users is a safety critical requirement for the deployment of autonomous vehicles in heterogeneous traffic. Although similar in physical appearance to pedestrians, e-scooter riders follow distinctly different characteristics of movement and can reach speeds of up to 45kmph. The challenge of detecting e-scooter riders is exacerbated in urban environments where the frequency of partial occlusion is increased as riders navigate between vehicles, traffic infrastructure and other road users. This can lead to the non-detection or mis-classification of e-scooter riders as pedestrians, providing inaccurate information for accident mitigation and path planning in autonomous vehicle applications. This research introduces a novel benchmark for partially occluded e-scooter rider detection to facilitate the objective characterization of detection models. A novel, occlusion-aware method of e-scooter rider detection is presented that achieves a 15.93% improvement in detection performance over the current state of the art.
Video Sentiment Analysis with Bimodal Information-augmented Multi-Head Attention
Mar 09, 2021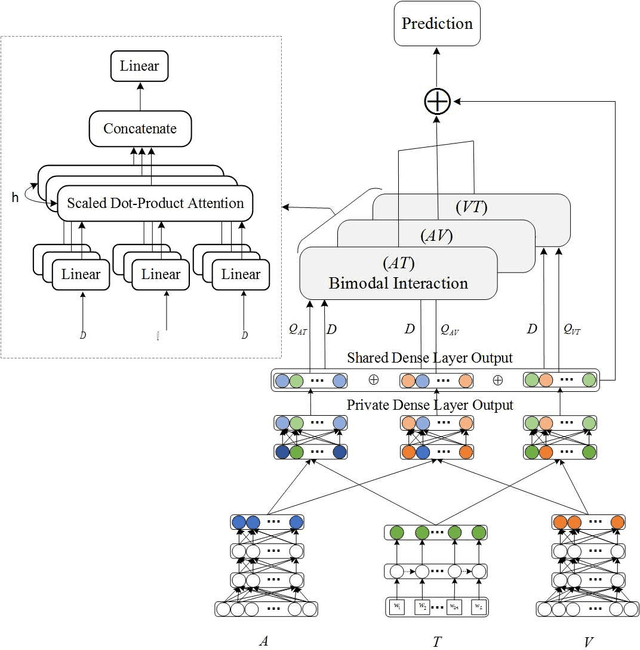
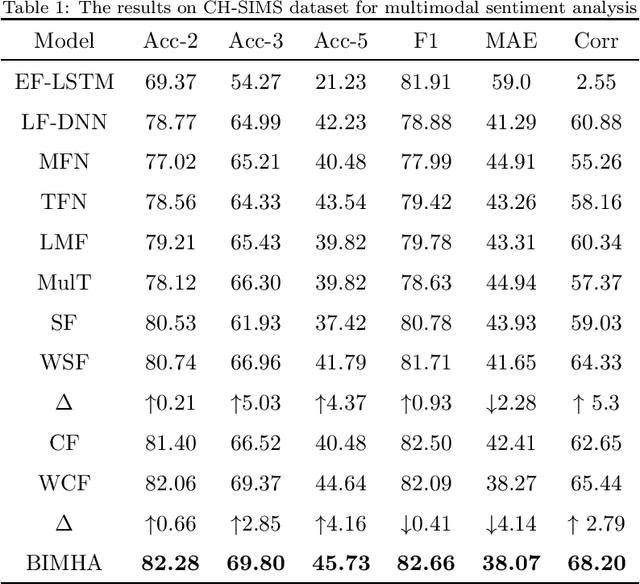
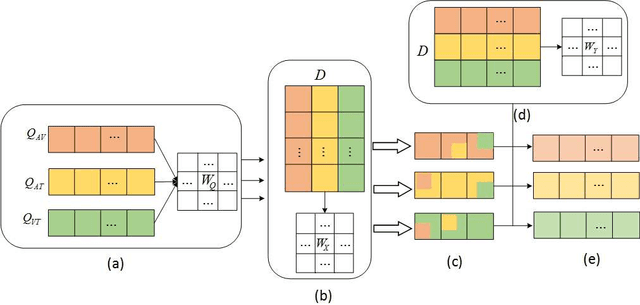
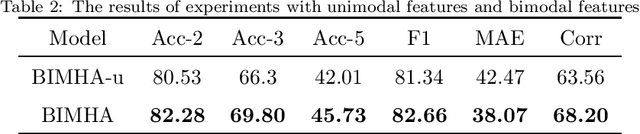
Sentiment analysis is the basis of intelligent human-computer interaction. As one of the frontier research directions of artificial intelligence, it can help computers better identify human intentions and emotional states so that provide more personalized services. However, as human present sentiments by spoken words, gestures, facial expressions and others which involve variable forms of data including text, audio, video, etc., it poses many challenges to this study. Due to the limitations of unimodal sentiment analysis, recent research has focused on the sentiment analysis of videos containing time series data of multiple modalities. When analyzing videos with multimodal data, the key problem is how to fuse these heterogeneous data. In consideration that the contribution of each modality is different, current fusion methods tend to extract the important information of single modality prior to fusion, which ignores the consistency and complementarity of bimodal interaction and has influences on the final decision. To solve this problem, a video sentiment analysis method using multi-head attention with bimodal information augmented is proposed. Based on bimodal interaction, more important bimodal features are assigned larger weights. In this way, different feature representations are adaptively assigned corresponding attention for effective multimodal fusion. Extensive experiments were conducted on both Chinese and English public datasets. The results show that our approach outperforms the existing methods and can give an insight into the contributions of bimodal interaction among three modalities.
Semantic system for searching of employees
Mar 24, 2022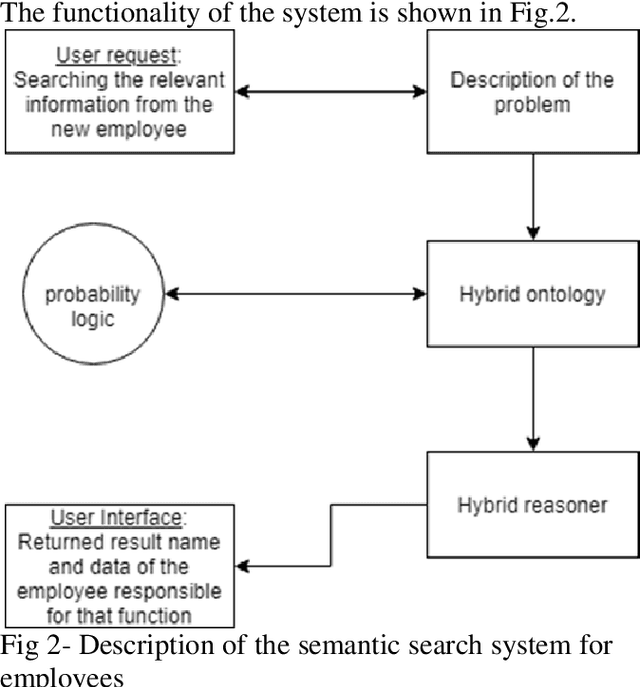
Many people have stress to leave their job and start a new one because of the new environment and not enough knowledge about the culture and structure about the new organization they are going to work in. New employees in company normally need to integrate in their working place environment quicker to start doing their job. That makes them ask a lot of questions to their colleagues and sometimes their colleagues are too busy to answer those questions. In the literature is defined that this problem could be solved when new employees use digital system for information as the proposed system for searching of information. Furthermore, the quality of the returned results from the searching system is defined as a standard for the efficiency of the searching systems. Because of this, it is proposed a semantic system for searching information of employees in a company that will help to better orient new employees in a company, to know the position and the function of each employee in the company
* 132-136 pages, 9 figures,International Conference on Applied Physics, Simulation and Computing (APSAC)Croatia, Dubrovnik, Sept.28-29 2018
Color Invariant Skin Segmentation
Apr 22, 2022
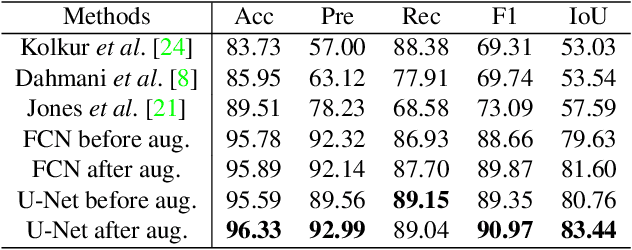
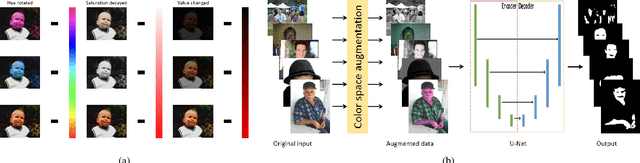
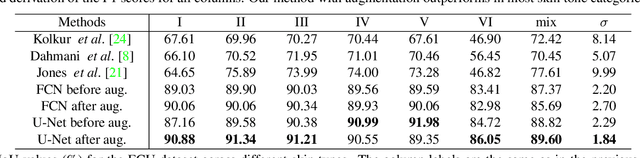
This paper addresses the problem of automatically detecting human skin in images without reliance on color information. A primary motivation of the work has been to achieve results that are consistent across the full range of skin tones, even while using a training dataset that is significantly biased toward lighter skin tones. Previous skin-detection methods have used color cues almost exclusively, and we present a new approach that performs well in the absence of such information. A key aspect of the work is dataset repair through augmentation that is applied strategically during training, with the goal of color invariant feature learning to enhance generalization. We have demonstrated the concept using two architectures, and experimental results show improvements in both precision and recall for most Fitzpatrick skin tones in the benchmark ECU dataset. We further tested the system with the RFW dataset to show that the proposed method performs much more consistently across different ethnicities, thereby reducing the chance of bias based on skin color. To demonstrate the effectiveness of our work, extensive experiments were performed on grayscale images as well as images obtained under unconstrained illumination and with artificial filters. Source code: https://github.com/HanXuMartin/Color-Invariant-Skin-Segmentation
Variational Information Bottleneck Model for Accurate Indoor Position Recognition
Jan 26, 2021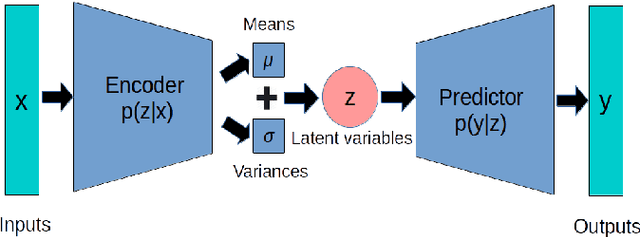
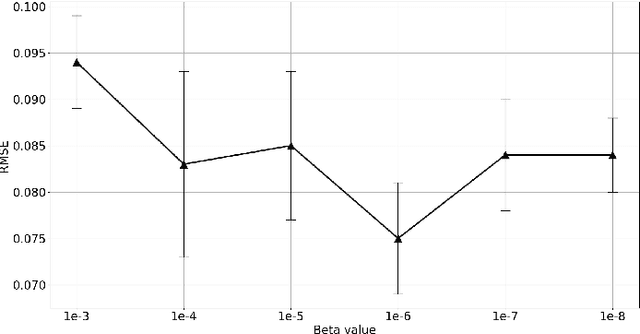

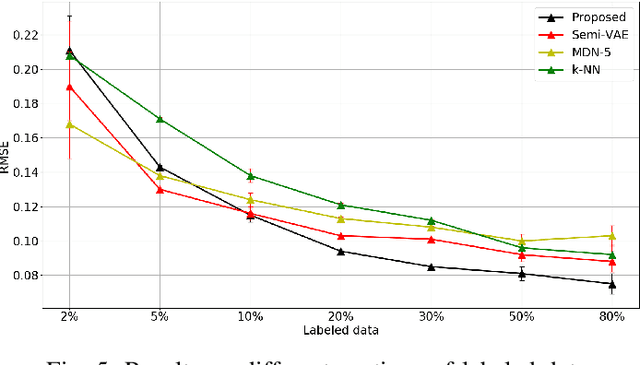
Recognizing user location with WiFi fingerprints is a popular approach for accurate indoor positioning problems. In this work, our goal is to interpret WiFi fingerprints into actual user locations. However, WiFi fingerprint data can be very high dimensional in some cases, we need to find a good representation of the input data for the learning task first. Otherwise, using neural networks will suffer from severe overfitting. In this work, we solve this issue by combining the Information Bottleneck method and Variational Inference. Based on these two approaches, we propose a Variational Information Bottleneck model for accurate indoor positioning. The proposed model consists of an encoder structure and a predictor structure. The encoder is to find a good representation in the input data for the learning task. The predictor is to use the latent representation to predict the final output. To enhance the generalization of our model, we also adopt the Dropout technique for each hidden layer of the decoder. We conduct the validation experiments on a real-world dataset. We also compare the proposed model to other existing methods so as to quantify the performances of our method.
Instantaneous GNSS Ambiguity Resolution and Attitude Determination via Riemannian Manifold Optimization
May 20, 2022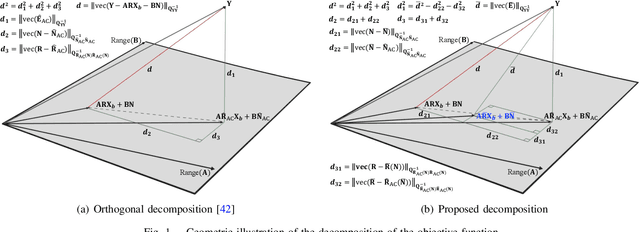
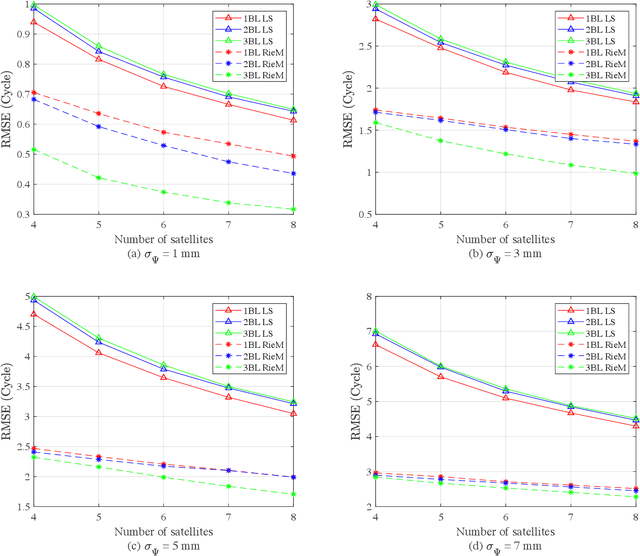
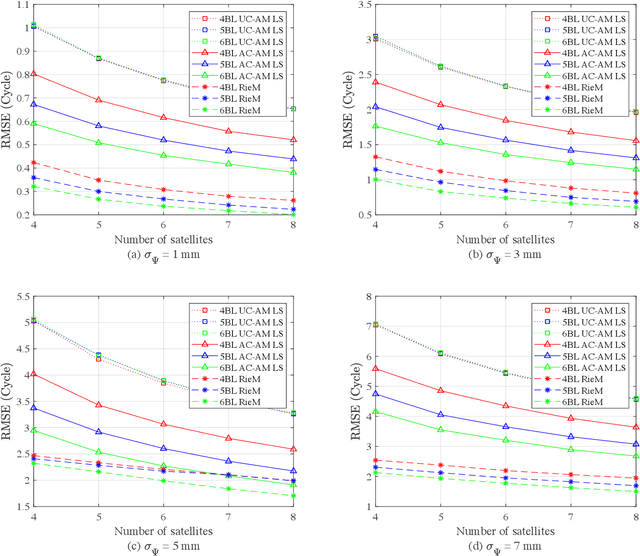
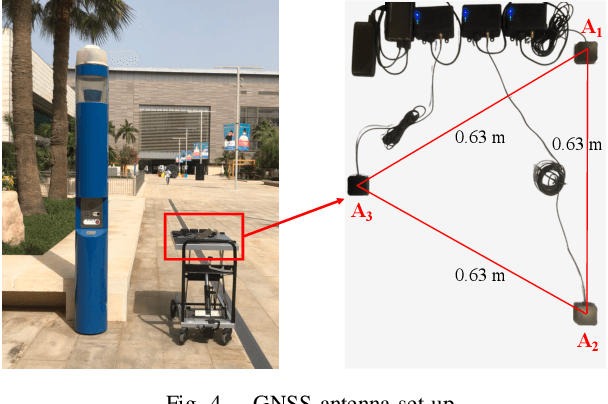
We present an ambiguity resolution method for Global Navigation Satellite System (GNSS)-based attitude determination. A GNSS attitude model with nonlinear constraints is used to rigorously incorporate a priori information. Given the characteristics of the employed nonlinear constraints, we formulate GNSS attitude determination as an optimization problem on a manifold. Then, Riemannian manifold optimization algorithms are utilized to aid ambiguity resolution based on a proposed decomposition of the objective function. The application of manifold geometry enables high-quality float solutions that are critical to reinforcing search-based integer ambiguity resolution in terms of efficiency, availability, and reliability. The proposed approach is characterized by a low computational complexity and a high probability of resolving the ambiguities correctly. The performance of the proposed ambiguity resolution method is tested through a series of simulations and real experiments. Comparisons with the principal benchmarks indicate the superiority of the proposed method as reflected by the high ambiguity resolution success rates.
Decoding Neural Correlation of Language-Specific Imagined Speech using EEG Signals
Apr 15, 2022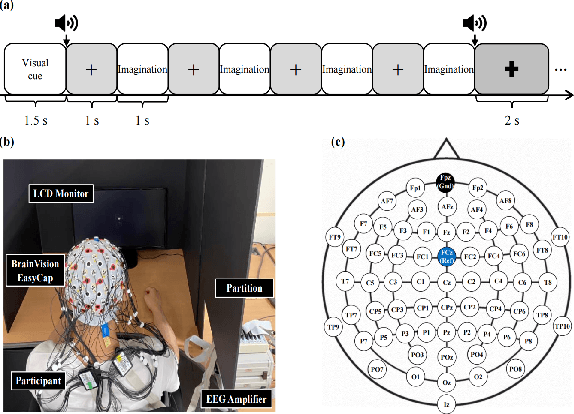
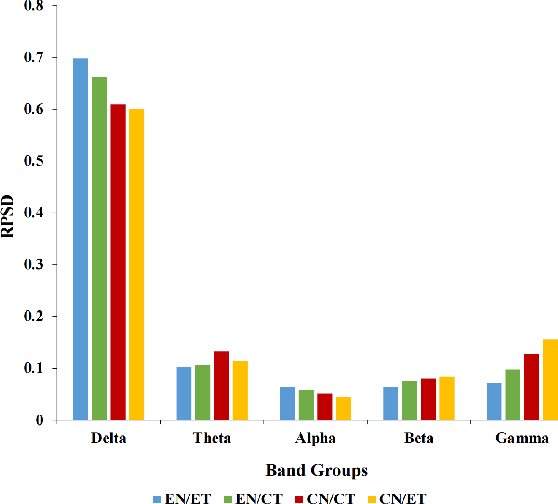
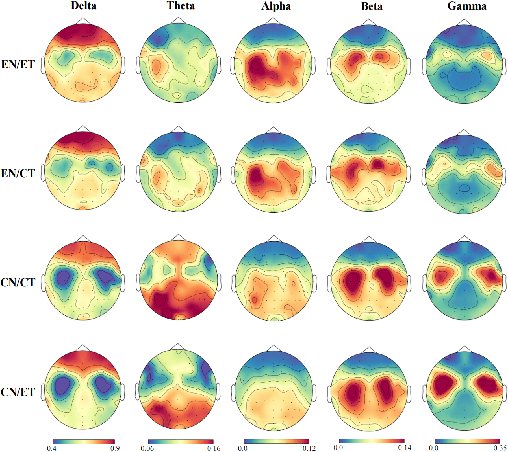
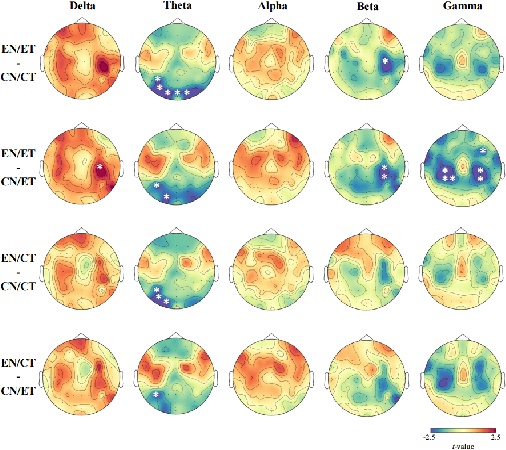
Speech impairments due to cerebral lesions and degenerative disorders can be devastating. For humans with severe speech deficits, imagined speech in the brain-computer interface has been a promising hope for reconstructing the neural signals of speech production. However, studies in the EEG-based imagined speech domain still have some limitations due to high variability in spatial and temporal information and low signal-to-noise ratio. In this paper, we investigated the neural signals for two groups of native speakers with two tasks with different languages, English and Chinese. Our assumption was that English, a non-tonal and phonogram-based language, would have spectral differences in neural computation compared to Chinese, a tonal and ideogram-based language. The results showed the significant difference in the relative power spectral density between English and Chinese in specific frequency band groups. Also, the spatial evaluation of Chinese native speakers in the theta band was distinctive during the imagination task. Hence, this paper would suggest the key spectral and spatial information of word imagination with specialized language while decoding the neural signals of speech.
Know Thy Student: Interactive Learning with Gaussian Processes
Apr 26, 2022
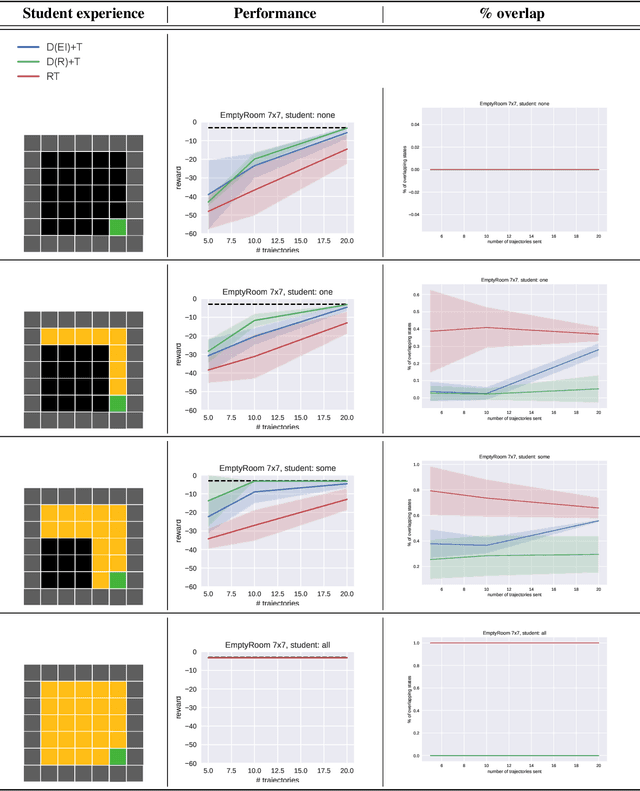

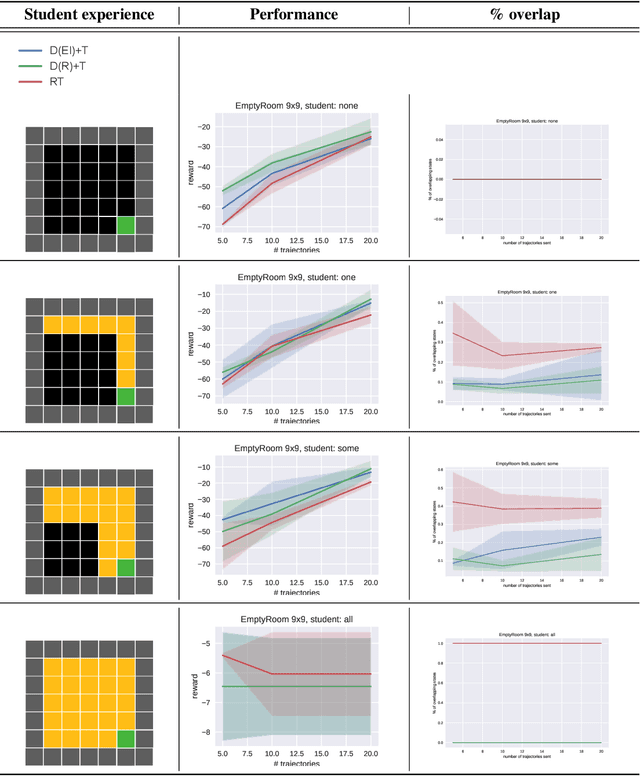
Learning often involves interaction between multiple agents. Human teacher-student settings best illustrate how interactions result in efficient knowledge passing where the teacher constructs a curriculum based on their students' abilities. Prior work in machine teaching studies how the teacher should construct optimal teaching datasets assuming the teacher knows everything about the student. However, in the real world, the teacher doesn't have complete information about the student. The teacher must interact and diagnose the student, before teaching. Our work proposes a simple diagnosis algorithm which uses Gaussian processes for inferring student-related information, before constructing a teaching dataset. We apply this to two settings. One is where the student learns from scratch and the teacher must figure out the student's learning algorithm parameters, eg. the regularization parameters in ridge regression or support vector machines. Two is where the student has partially explored the environment and the teacher must figure out the important areas the student has not explored; we study this in the offline reinforcement learning setting where the teacher must provide demonstrations to the student and avoid sending redundant trajectories. Our experiments highlight the importance of diagosing before teaching and demonstrate how students can learn more efficiently with the help of an interactive teacher. We conclude by outlining where diagnosing combined with teaching would be more desirable than passive learning.
Neural operator learning of heterogeneous mechanobiological insults contributing to aortic aneurysms
May 08, 2022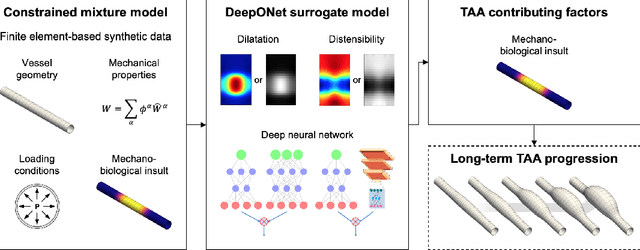

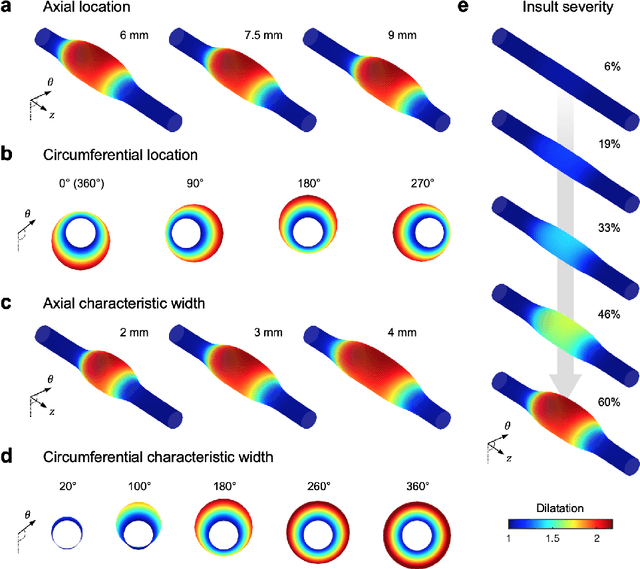

Thoracic aortic aneurysm (TAA) is a localized dilatation of the aorta resulting from compromised wall composition, structure, and function, which can lead to life-threatening dissection or rupture. Several genetic mutations and predisposing factors that contribute to TAA have been studied in mouse models to characterize specific changes in aortic microstructure and material properties that result from a wide range of mechanobiological insults. Assessments of TAA progression in vivo is largely limited to measurements of aneurysm size and growth rate. It has been shown that aortic geometry alone is not sufficient to predict the patient-specific progression of TAA but computational modeling of the evolving biomechanics of the aorta could predict future geometry and properties from initiating insults. In this work, we present an integrated framework to train a deep operator network (DeepONet)-based surrogate model to identify contributing factors for TAA by using FE-based datasets of aortic growth and remodeling resulting from prescribed insults. For training data, we investigate multiple types of TAA risk factors and spatial distributions within a constrained mixture model to generate axial--azimuthal maps of aortic dilatation and distensibility. The trained network is then capable of predicting the initial distribution and extent of the insult from a given set of dilatation and distensibility information. Two DeepONet frameworks are proposed, one trained on sparse information and one on full-field grayscale images, to gain insight into a preferred neural operator-based approach. Performance of the surrogate models is evaluated through multiple simulations carried out on insult distributions varying from fusiform to complex. We show that the proposed approach can predict patient-specific mechanobiological insult profile with a high accuracy, particularly when based on full-field images.