 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Position Tracking using Likelihood Modeling of Channel Features with Gaussian Processes
Mar 24, 2022
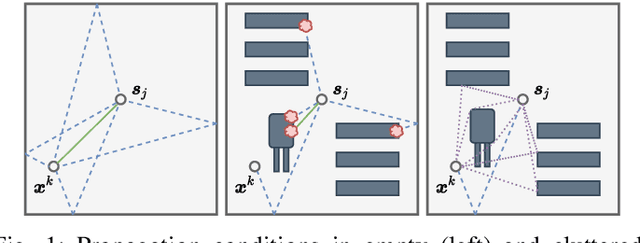
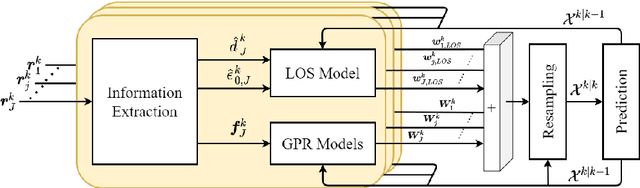
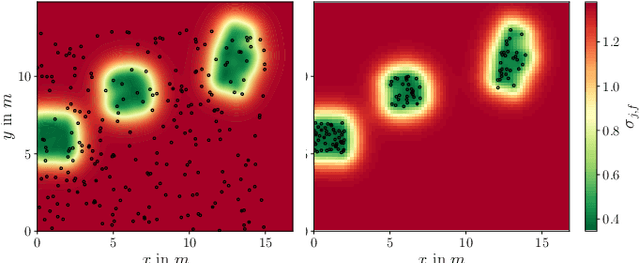

Recent localization frameworks exploit spatial information of complex channel measurements (CMs) to estimate accurate positions even in multipath propagation scenarios. State-of-the art CM fingerprinting(FP)-based methods employ convolutional neural networks (CNN) to extract the spatial information. However, they need spatially dense data sets (associated with high acquisition and maintenance efforts) to work well -- which is rarely the case in practical applications. If such data is not available (or its quality is low), we cannot compensate the performance degradation of CNN-based FP as they do not provide statistical position estimates, which prevents a fusion with other sources of information on the observation level. We propose a novel localization framework that adapts well to sparse datasets that only contain CMs of specific areas within the environment with strong multipath propagation. Our framework compresses CMs into informative features to unravel spatial information. It then regresses Gaussian processes (GPs) for each of them, which imply statistical observation models based on distance-dependent covariance kernels. Our framework combines the trained GPs with line-of-sight ranges and a dynamics model in a particle filter. Our measurements show that our approach outperforms state-of-the-art CNN fingerprinting (0.52 m vs. 1.3 m MAE) on spatially sparse data collected in a realistic industrial indoor environment.
Extracting Image Characteristics to Predict Crowdfunding Success
Mar 28, 2022
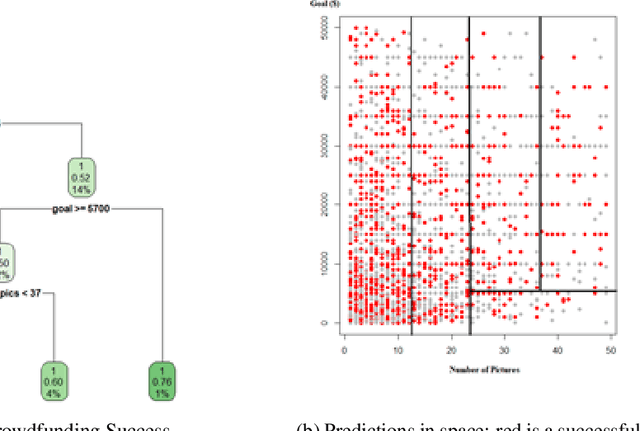
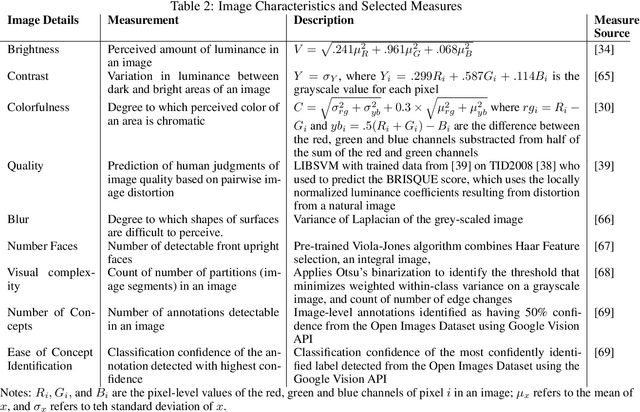
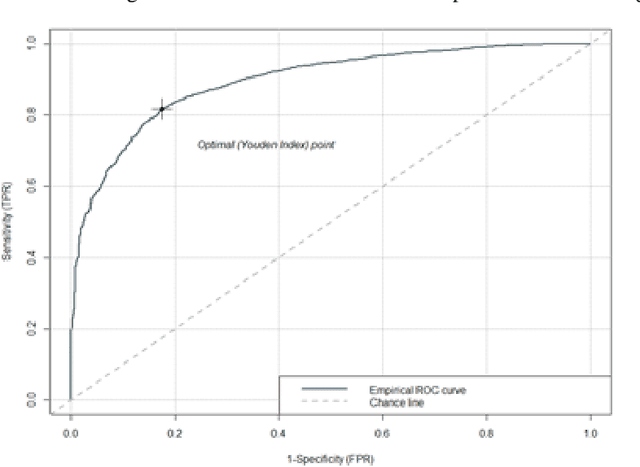
Despite an increase in the empirical study of crowdfunding platforms and the prevalence of visual information, operations management and marketing literature has yet to explore the role that image characteristics play in crowdfunding success. The authors of this manuscript begin by synthesizing literature on visual processing to identify several image characteristics that are likely to shape crowdfunding success. After detailing measures for each image characteristic, they use them as part of a machine-learning algorithm (Bayesian additive trees), along with project characteristics and textual information, to predict crowdfunding success. Results show that the inclusion of these image characteristics substantially improves prediction over baseline project variables, as well as textual features. Furthermore, image characteristic variables exhibit high importance, similar to variables linked to the number of pictures and number of videos. This research therefore offers valuable resources to researchers and managers who are interested in the role of visual information in ensuring new product success.
Random Walks with Erasure: Diversifying Personalized Recommendations on Social and Information Networks
Feb 18, 2021

Most existing personalization systems promote items that match a user's previous choices or those that are popular among similar users. This results in recommendations that are highly similar to the ones users are already exposed to, resulting in their isolation inside familiar but insulated information silos. In this context, we develop a novel recommendation framework with a goal of improving information diversity using a modified random walk exploration of the user-item graph. We focus on the problem of political content recommendation, while addressing a general problem applicable to personalization tasks in other social and information networks. For recommending political content on social networks, we first propose a new model to estimate the ideological positions for both users and the content they share, which is able to recover ideological positions with high accuracy. Based on these estimated positions, we generate diversified personalized recommendations using our new random-walk based recommendation algorithm. With experimental evaluations on large datasets of Twitter discussions, we show that our method based on \emph{random walks with erasure} is able to generate more ideologically diverse recommendations. Our approach does not depend on the availability of labels regarding the bias of users or content producers. With experiments on open benchmark datasets from other social and information networks, we also demonstrate the effectiveness of our method in recommending diverse long-tail items.
* Web Conference 2021 (WWW '21)
Adaptive Neural Network-based Unscented Kalman Filter for Spacecraft Pose Tracking at Rendezvous
Jun 08, 2022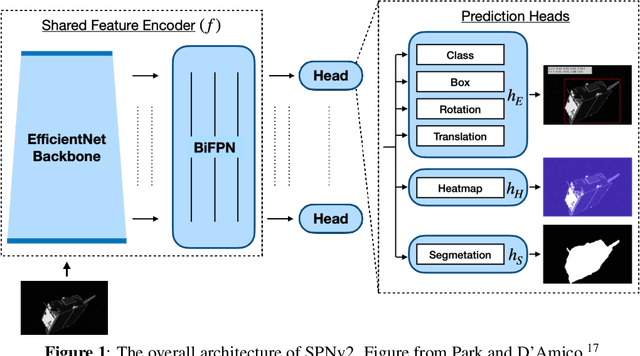

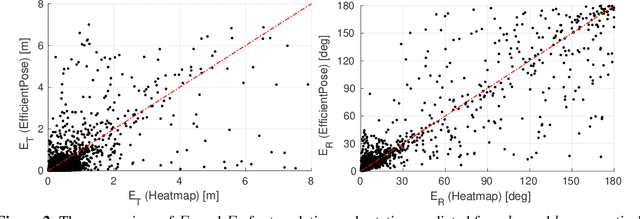

This paper presents a neural network-based Unscented Kalman Filter (UKF) to track the pose (i.e., position and orientation) of a known, noncooperative, tumbling target spacecraft in a close-proximity rendezvous scenario. The UKF estimates the relative orbital and attitude states of the target with respect to the servicer based on the pose information extracted from incoming monocular images of the target spacecraft with a Convolutional Neural Network (CNN). In order to enable reliable tracking, the process noise covariance matrix of the UKF is tuned online using adaptive state noise compensation. Specifically, the closed-form process noise model for the relative attitude dynamics is newly derived and implemented. In order to enable a comprehensive analysis of the performance and robustness of the proposed CNN-powered UKF, this paper also introduces the Satellite Hardware-In-the-loop Rendezvous Trajectories (SHIRT) dataset which comprises the labeled imagery of two representative rendezvous trajectories in low Earth orbit. For each trajectory, two sets of images are respectively created from a graphics renderer and a robotic testbed to allow testing the filter's robustness across domain gap. The proposed UKF is evaluated on both domains of the trajectories in SHIRT and is shown to have sub-decimeter-level position and degree-level orientation errors at steady-state.
Adversarially Robust Multi-Armed Bandit Algorithm with Variance-Dependent Regret Bounds
Jun 14, 2022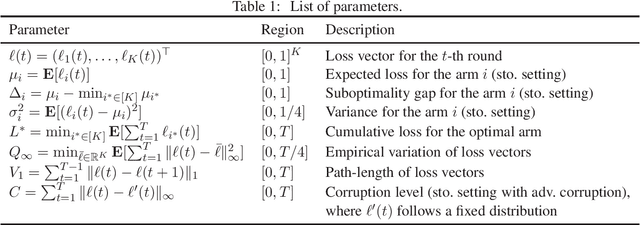



This paper considers the multi-armed bandit (MAB) problem and provides a new best-of-both-worlds (BOBW) algorithm that works nearly optimally in both stochastic and adversarial settings. In stochastic settings, some existing BOBW algorithms achieve tight gap-dependent regret bounds of $O(\sum_{i: \Delta_i>0} \frac{\log T}{\Delta_i})$ for suboptimality gap $\Delta_i$ of arm $i$ and time horizon $T$. As Audibert et al. [2007] have shown, however, that the performance can be improved in stochastic environments with low-variance arms. In fact, they have provided a stochastic MAB algorithm with gap-variance-dependent regret bounds of $O(\sum_{i: \Delta_i>0} (\frac{\sigma_i^2}{\Delta_i} + 1) \log T )$ for loss variance $\sigma_i^2$ of arm $i$. In this paper, we propose the first BOBW algorithm with gap-variance-dependent bounds, showing that the variance information can be used even in the possibly adversarial environment. Further, the leading constant factor in our gap-variance dependent bound is only (almost) twice the value for the lower bound. Additionally, the proposed algorithm enjoys multiple data-dependent regret bounds in adversarial settings and works well in stochastic settings with adversarial corruptions. The proposed algorithm is based on the follow-the-regularized-leader method and employs adaptive learning rates that depend on the empirical prediction error of the loss, which leads to gap-variance-dependent regret bounds reflecting the variance of the arms.
Enforcing Morphological Information in Fully Convolutional Networks to Improve Cell Instance Segmentation in Fluorescence Microscopy Images
Jun 10, 2021
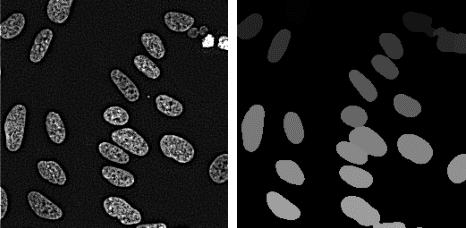
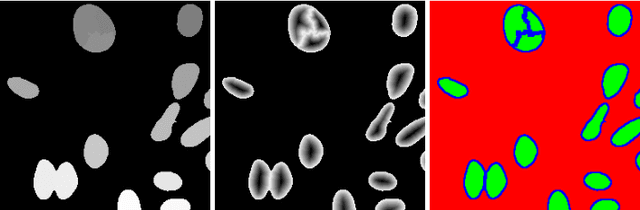
Cell instance segmentation in fluorescence microscopy images is becoming essential for cancer dynamics and prognosis. Data extracted from cancer dynamics allows to understand and accurately model different metabolic processes such as proliferation. This enables customized and more precise cancer treatments. However, accurate cell instance segmentation, necessary for further cell tracking and behavior analysis, is still challenging in scenarios with high cell concentration and overlapping edges. Within this framework, we propose a novel cell instance segmentation approach based on the well-known U-Net architecture. To enforce the learning of morphological information per pixel, a deep distance transformer (DDT) acts as a back-bone model. The DDT output is subsequently used to train a top-model. The following top-models are considered: a three-class (\emph{e.g.,} foreground, background and cell border) U-net, and a watershed transform. The obtained results suggest a performance boost over traditional U-Net architectures. This opens an interesting research line around the idea of injecting morphological information into a fully convolutional model.
Quasi Black-Box Variational Inference with Natural Gradients for Bayesian Learning
May 23, 2022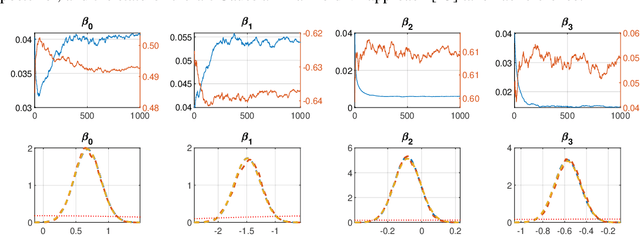
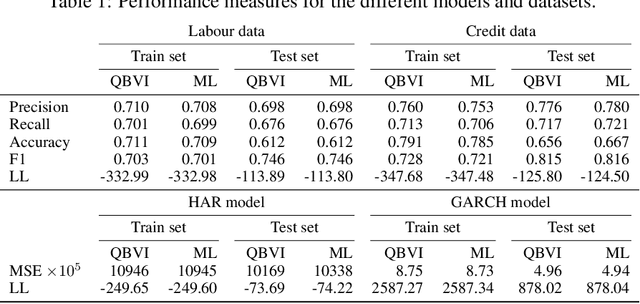
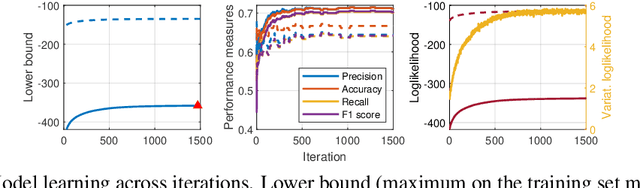
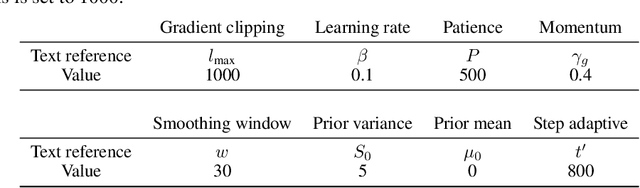
We develop an optimization algorithm suitable for Bayesian learning in complex models. Our approach relies on natural gradient updates within a general black-box framework for efficient training with limited model-specific derivations. It applies within the class of exponential-family variational posterior distributions, for which we extensively discuss the Gaussian case for which the updates have a rather simple form. Our Quasi Black-box Variational Inference (QBVI) framework is readily applicable to a wide class of Bayesian inference problems and is of simple implementation as the updates of the variational posterior do not involve gradients with respect to the model parameters, nor the prescription of the Fisher information matrix. We develop QBVI under different hypotheses for the posterior covariance matrix, discuss details about its robust and feasible implementation, and provide a number of real-world applications to demonstrate its effectiveness.
Speech Augmentation Based Unsupervised Learning for Keyword Spotting
May 28, 2022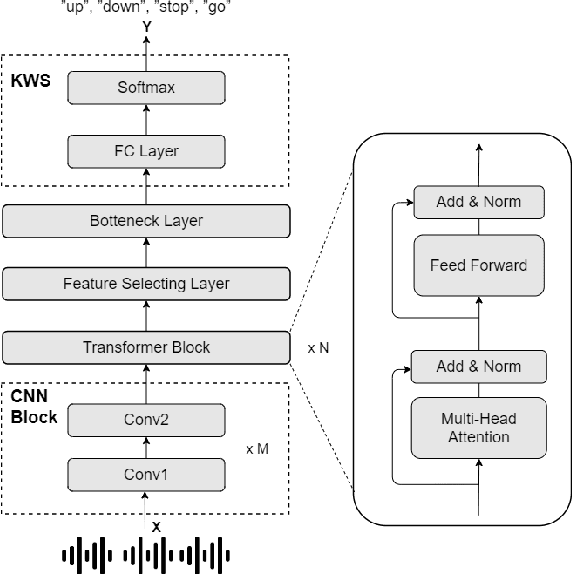
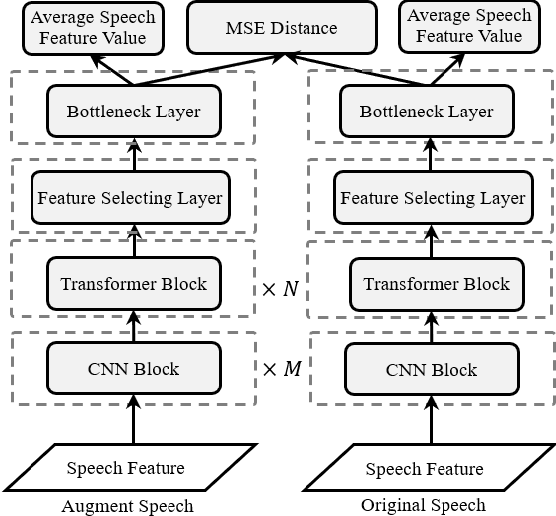

In this paper, we investigated a speech augmentation based unsupervised learning approach for keyword spotting (KWS) task. KWS is a useful speech application, yet also heavily depends on the labeled data. We designed a CNN-Attention architecture to conduct the KWS task. CNN layers focus on the local acoustic features, and attention layers model the long-time dependency. To improve the robustness of KWS model, we also proposed an unsupervised learning method. The unsupervised loss is based on the similarity between the original and augmented speech features, as well as the audio reconstructing information. Two speech augmentation methods are explored in the unsupervised learning: speed and intensity. The experiments on Google Speech Commands V2 Dataset demonstrated that our CNN-Attention model has competitive results. Moreover, the augmentation based unsupervised learning could further improve the classification accuracy of KWS task. In our experiments, with augmentation based unsupervised learning, our KWS model achieves better performance than other unsupervised methods, such as CPC, APC, and MPC.
WT-MVSNet: Window-based Transformers for Multi-view Stereo
May 28, 2022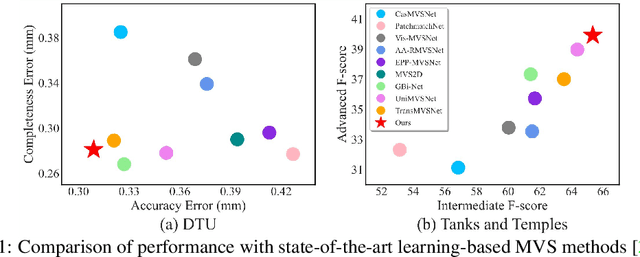
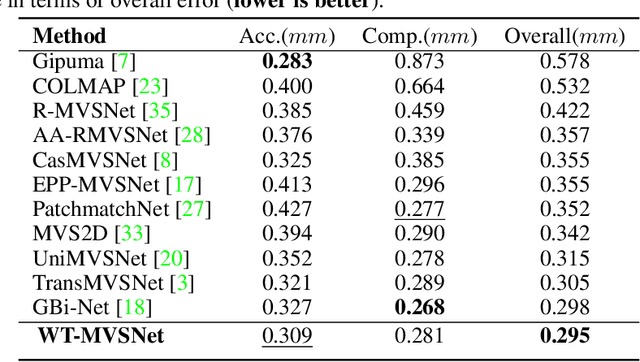
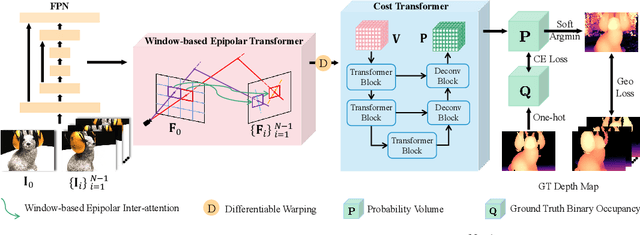
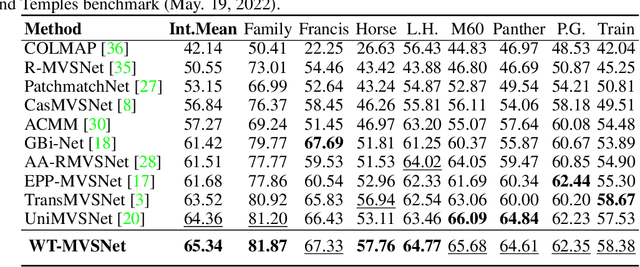
Recently, Transformers were shown to enhance the performance of multi-view stereo by enabling long-range feature interaction. In this work, we propose Window-based Transformers (WT) for local feature matching and global feature aggregation in multi-view stereo. We introduce a Window-based Epipolar Transformer (WET) which reduces matching redundancy by using epipolar constraints. Since point-to-line matching is sensitive to erroneous camera pose and calibration, we match windows near the epipolar lines. A second Shifted WT is employed for aggregating global information within cost volume. We present a novel Cost Transformer (CT) to replace 3D convolutions for cost volume regularization. In order to better constrain the estimated depth maps from multiple views, we further design a novel geometric consistency loss (Geo Loss) which punishes unreliable areas where multi-view consistency is not satisfied. Our WT multi-view stereo method (WT-MVSNet) achieves state-of-the-art performance across multiple datasets and ranks $1^{st}$ on Tanks and Temples benchmark.
Fault-Aware Neural Code Rankers
Jun 04, 2022

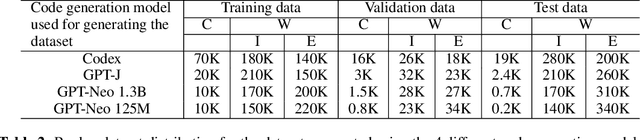

Large language models (LLMs) have demonstrated an impressive ability to generate code for various programming tasks. In many instances, LLMs can generate a correct program for a task when given numerous trials. Consequently, a recent trend is to do large scale sampling of programs using a model and then filtering/ranking the programs based on the program execution on a small number of known unit tests to select one candidate solution. However, these approaches assume that the unit tests are given and assume the ability to safely execute the generated programs (which can do arbitrary dangerous operations such as file manipulations). Both of the above assumptions are impractical in real-world software development. In this paper, we propose fault-aware neural code rankers that can predict the correctness of a sampled program without executing it. The fault-aware rankers are trained to predict different kinds of execution information such as predicting the exact compile/runtime error type (e.g., an IndexError or a TypeError). We show that our fault-aware rankers can significantly increase the pass@1 accuracy of various code generation models (including Codex, GPT-Neo, GPT-J) on APPS, HumanEval and MBPP datasets.