 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Support-set based Multi-modal Representation Enhancement for Video Captioning
May 19, 2022
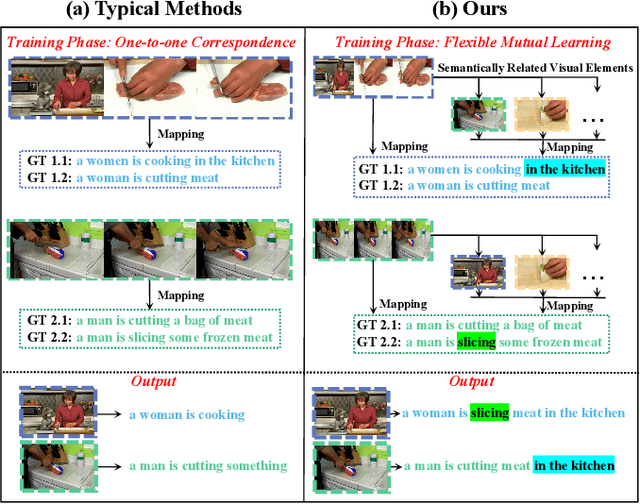
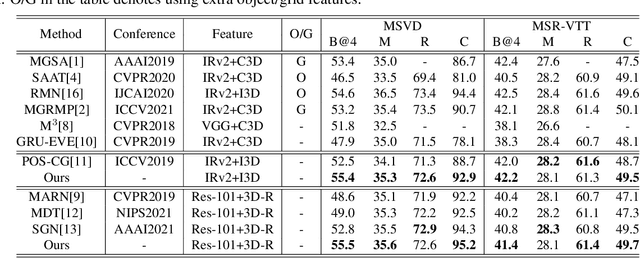
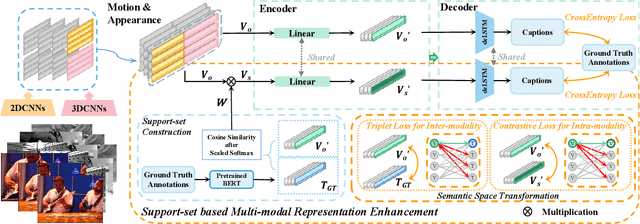
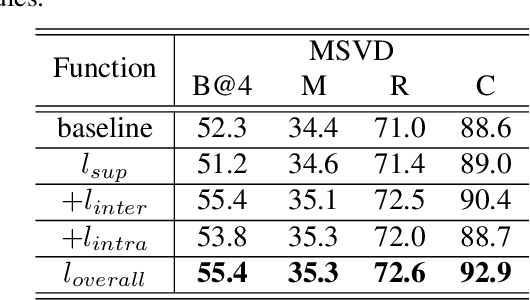
Video captioning is a challenging task that necessitates a thorough comprehension of visual scenes. Existing methods follow a typical one-to-one mapping, which concentrates on a limited sample space while ignoring the intrinsic semantic associations between samples, resulting in rigid and uninformative expressions. To address this issue, we propose a novel and flexible framework, namely Support-set based Multi-modal Representation Enhancement (SMRE) model, to mine rich information in a semantic subspace shared between samples. Specifically, we propose a Support-set Construction (SC) module to construct a support-set to learn underlying connections between samples and obtain semantic-related visual elements. During this process, we design a Semantic Space Transformation (SST) module to constrain relative distance and administrate multi-modal interactions in a self-supervised way. Extensive experiments on MSVD and MSR-VTT datasets demonstrate that our SMRE achieves state-of-the-art performance.
Algorithmic Foundation of Deep X-Risk Optimization
Jun 01, 2022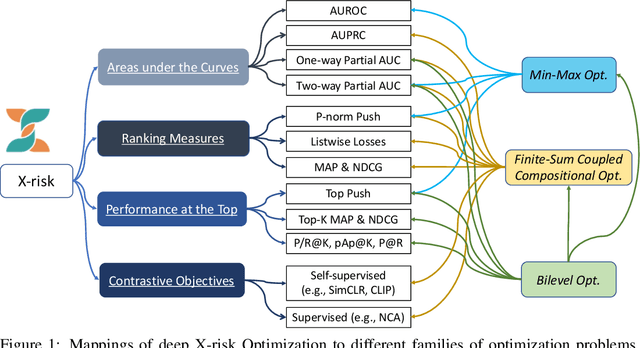

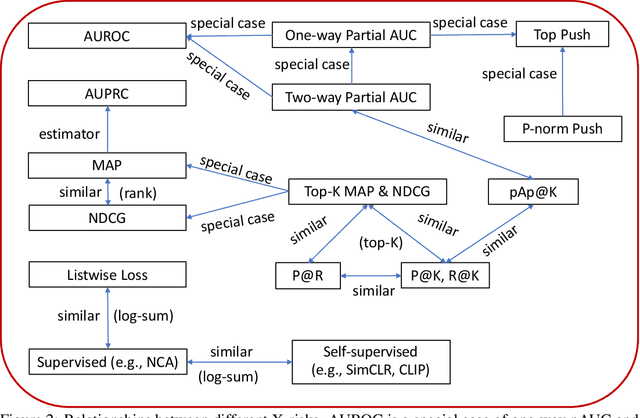
X-risk is a term introduced to represent a family of compositional measures or objectives, in which each data point is compared with a set of data points explicitly or implicitly for defining a risk function. It includes many widely used measures or objectives, e.g., AUROC, AUPRC, partial AUROC, NDCG, MAP, top-$K$ NDCG, top-$K$ MAP, listwise losses, p-norm push, top push, precision/recall at top $K$ positions, precision at a certain recall level, contrastive objectives, etc. While these measures/objectives and their optimization algorithms have been studied in the literature of machine learning, computer vision, information retrieval, and etc, optimizing these measures/objectives has encountered some unique challenges for deep learning. In this technical report, we survey our recent rigorous efforts for deep X-risk optimization (DXO) by focusing on its algorithmic foundation. We introduce a class of techniques for optimizing X-risk for deep learning. We formulate DXO into three special families of non-convex optimization problems belonging to non-convex min-max optimization, non-convex compositional optimization, and non-convex bilevel optimization, respectively. For each family of problems, we present some strong baseline algorithms and their complexities, which will motivate further research for improving the existing results. Discussions about the presented results and future studies are given at the end.
A Survey of Research on Fair Recommender Systems
May 25, 2022
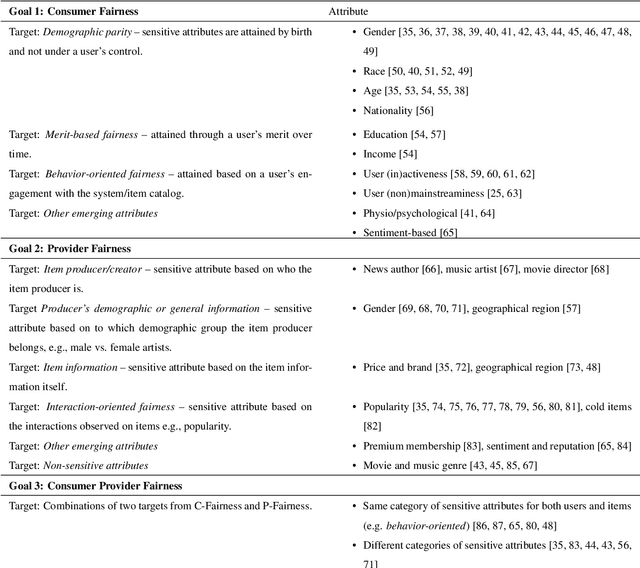
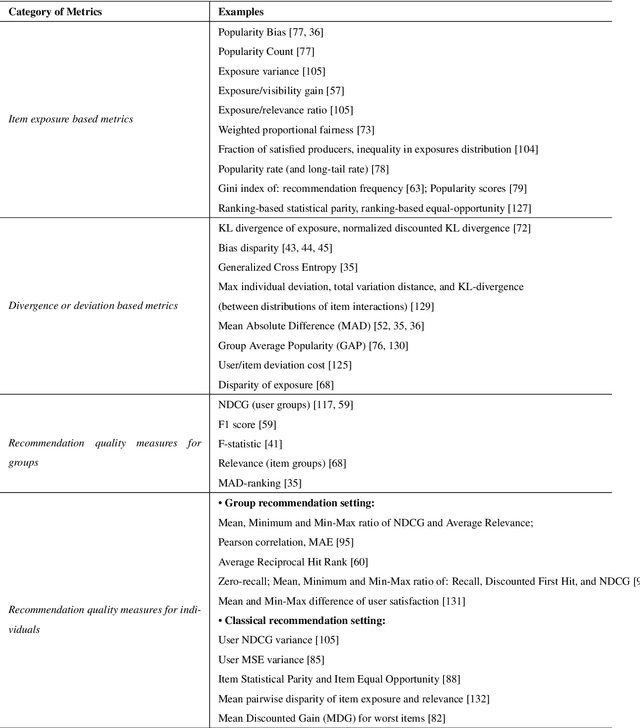
Recommender systems can strongly influence which information we see online, e.g, on social media, and thus impact our beliefs, decisions, and actions. At the same time, these systems can create substantial business value for different stakeholders. Given the growing potential impact of such AI-based systems on individuals, organizations, and society, questions of fairness have gained increased attention in recent years. However, research on fairness in recommender systems is still a developing area. In this survey, we first review the fundamental concepts and notions of fairness that were put forward in the area in the recent past. Afterward, we provide a survey of how research in this area is currently operationalized, for example, in terms of the general research methodology, fairness metrics, and algorithmic approaches. Overall, our analysis of recent works points to certain research gaps. In particular, we find that in many research works in computer science very abstract problem operationalizations are prevalent, which circumvent the fundamental and important question of what represents a fair recommendation in the context of a given application.
Helpfulness and Fairness of Task-Oriented Dialogue Systems
May 25, 2022
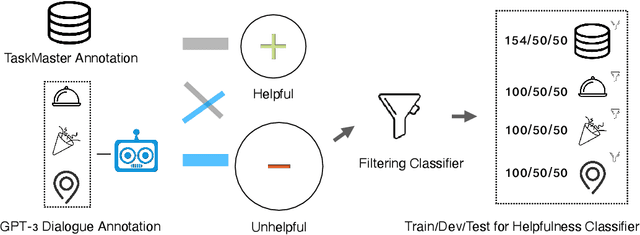

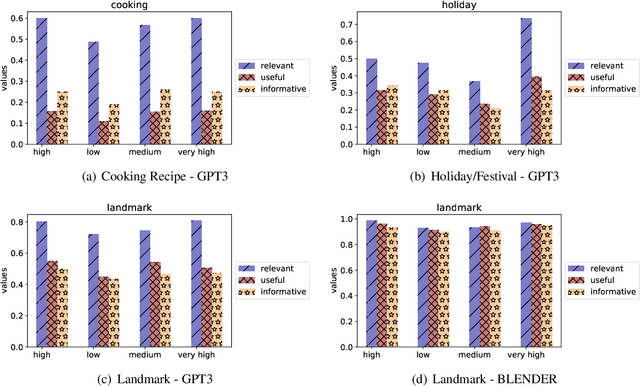
Task-oriented dialogue systems aim to answer questions from users and provide immediate help. Therefore, how humans perceive their helpfulness is important. However, neither the human-perceived helpfulness of task-oriented dialogue systems nor its fairness implication has been studied yet. In this paper, we define a dialogue response as helpful if it is relevant & coherent, useful, and informative to a query and study computational measurements of helpfulness. Then, we propose utilizing the helpfulness level of different groups to gauge the fairness of a dialogue system. To study this, we collect human annotations for the helpfulness of dialogue responses and build a classifier that can automatically determine the helpfulness of a response. We design experiments under 3 information-seeking scenarios and collect instances for each from Wikipedia. With collected instances, we use carefully-constructed questions to query the state-of-the-art dialogue systems. Through analysis, we find that dialogue systems tend to be more helpful for highly-developed countries than less-developed countries, uncovering a fairness issue underlying these dialogue systems.
A bio-inspired implementation of a sparse-learning spike-based hippocampus memory model
Jun 10, 2022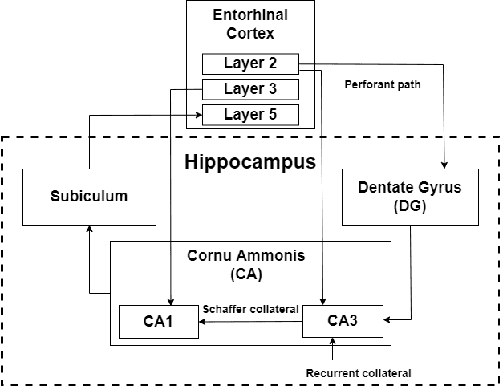
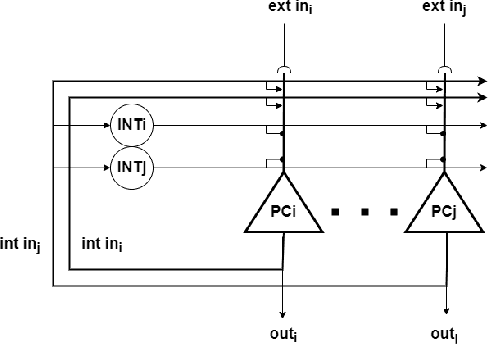
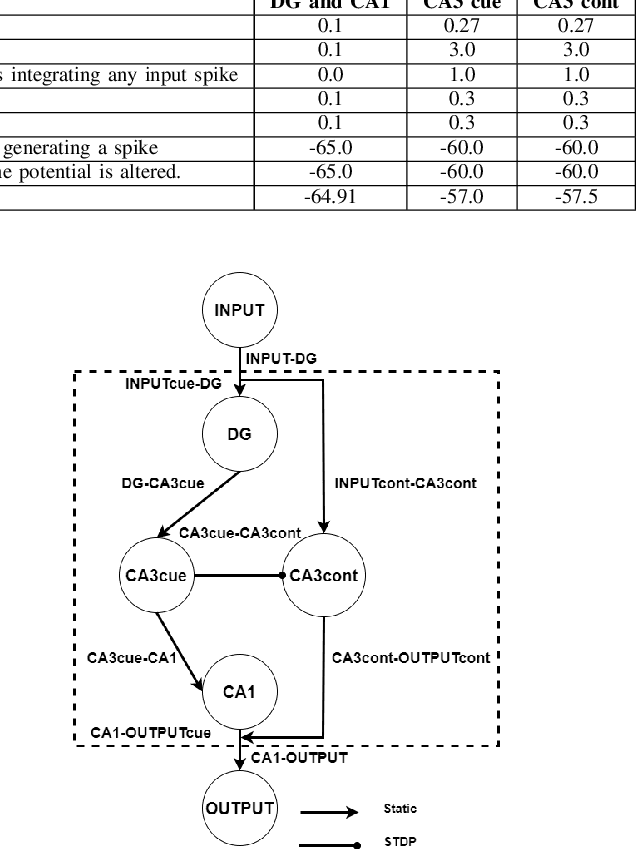
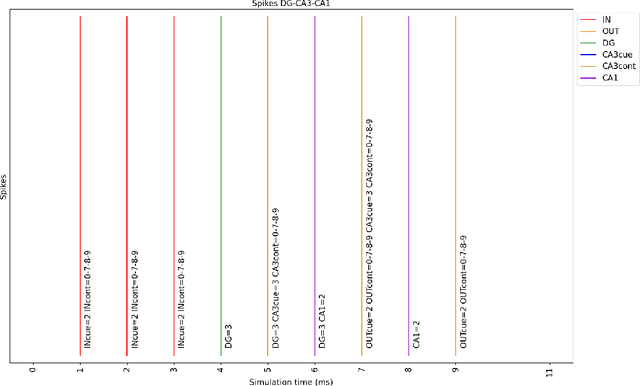
The nervous system, more specifically, the brain, is capable of solving complex problems simply and efficiently, far surpassing modern computers. In this regard, neuromorphic engineering is a research field that focuses on mimicking the basic principles that govern the brain in order to develop systems that achieve such computational capabilities. Within this field, bio-inspired learning and memory systems are still a challenge to be solved, and this is where the hippocampus is involved. It is the region of the brain that acts as a short-term memory, allowing the learning and unstructured and rapid storage of information from all the sensory nuclei of the cerebral cortex and its subsequent recall. In this work, we propose a novel bio-inspired memory model based on the hippocampus with the ability to learn memories, recall them from a cue (a part of the memory associated with the rest of the content) and even forget memories when trying to learn others with the same cue. This model has been implemented on the SpiNNaker hardware platform using Spiking Neural Networks, and a set of experiments and tests were performed to demonstrate its correct and expected operation. The proposed spike-based memory model generates spikes only when it receives an input, being energy efficient, and it needs 7 timesteps for the learning step and 6 timesteps for recalling a previously-stored memory. This work presents the first hardware implementation of a fully functional bio-inspired spike-based hippocampus memory model, paving the road for the development of future more complex neuromorphic systems.
ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval
Mar 31, 2022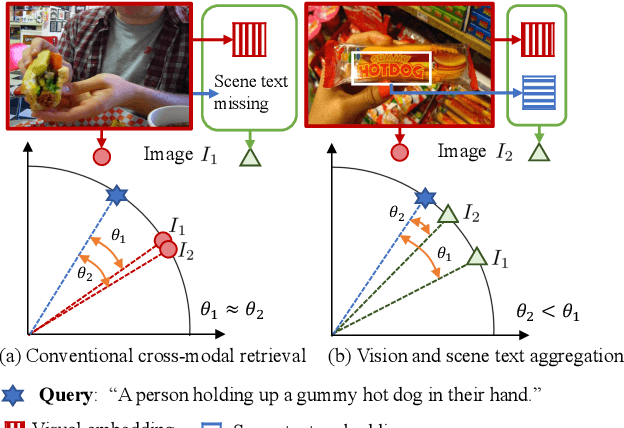

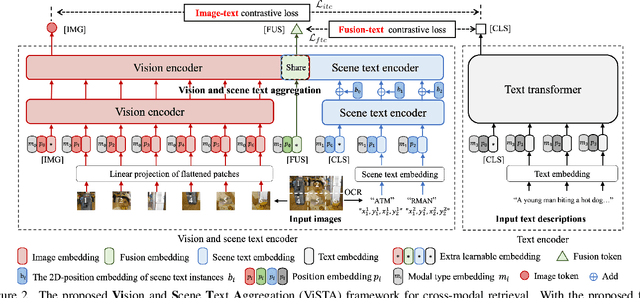

Visual appearance is considered to be the most important cue to understand images for cross-modal retrieval, while sometimes the scene text appearing in images can provide valuable information to understand the visual semantics. Most of existing cross-modal retrieval approaches ignore the usage of scene text information and directly adding this information may lead to performance degradation in scene text free scenarios. To address this issue, we propose a full transformer architecture to unify these cross-modal retrieval scenarios in a single $\textbf{Vi}$sion and $\textbf{S}$cene $\textbf{T}$ext $\textbf{A}$ggregation framework (ViSTA). Specifically, ViSTA utilizes transformer blocks to directly encode image patches and fuse scene text embedding to learn an aggregated visual representation for cross-modal retrieval. To tackle the modality missing problem of scene text, we propose a novel fusion token based transformer aggregation approach to exchange the necessary scene text information only through the fusion token and concentrate on the most important features in each modality. To further strengthen the visual modality, we develop dual contrastive learning losses to embed both image-text pairs and fusion-text pairs into a common cross-modal space. Compared to existing methods, ViSTA enables to aggregate relevant scene text semantics with visual appearance, and hence improve results under both scene text free and scene text aware scenarios. Experimental results show that ViSTA outperforms other methods by at least $\bf{8.4}\%$ at Recall@1 for scene text aware retrieval task. Compared with state-of-the-art scene text free retrieval methods, ViSTA can achieve better accuracy on Flicker30K and MSCOCO while running at least three times faster during the inference stage, which validates the effectiveness of the proposed framework.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022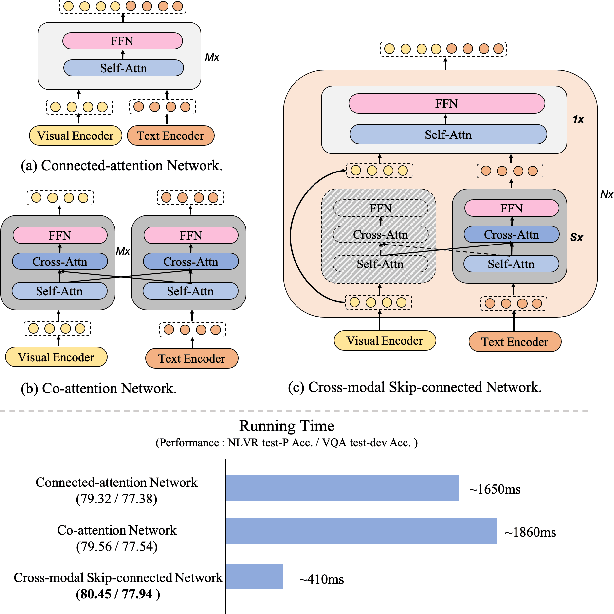
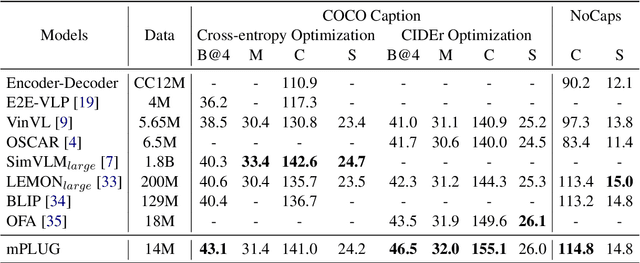
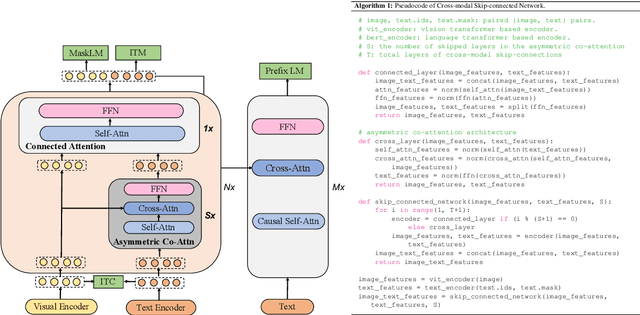
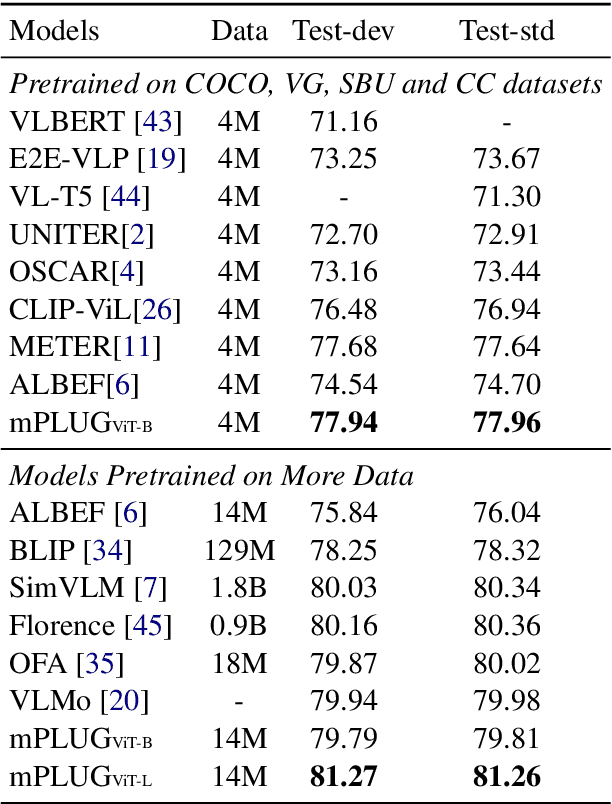
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
Fine-grained Contrastive Learning for Relation Extraction
May 25, 2022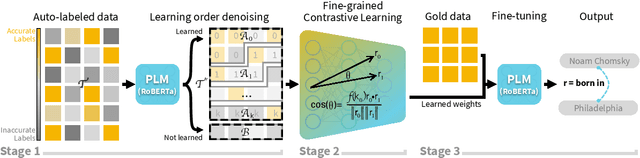

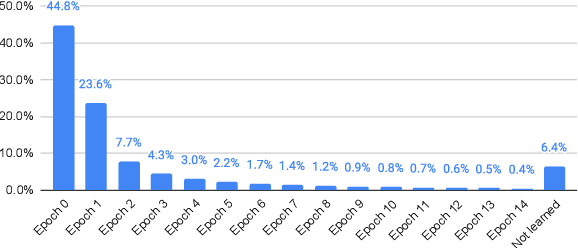
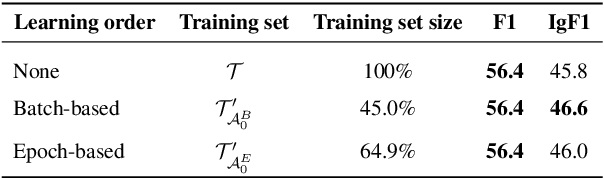
Recent relation extraction (RE) works have shown encouraging improvements by conducting contrastive learning on silver labels generated by distant supervision before fine-tuning on gold labels. Existing methods typically assume all these silver labels are accurate and therefore treat them equally in contrastive learning; however, distant supervision is inevitably noisy -- some silver labels are more reliable than others. In this paper, we first assess the quality of silver labels via a simple and automatic approach we call "learning order denoising," where we train a language model to learn these relations and record the order of learned training instances. We show that learning order largely corresponds to label accuracy -- early learned silver labels have, on average, more accurate labels compared to later learned silver labels. We then propose a novel fine-grained contrastive learning (FineCL) for RE, which leverages this additional, fine-grained information about which silver labels are and are not noisy to improve the quality of learned relationship representations for RE. Experiments on many RE benchmarks show consistent, significant performance gains of FineCL over state-of-the-art methods.
Unified Speech-Text Pre-training for Speech Translation and Recognition
Apr 11, 2022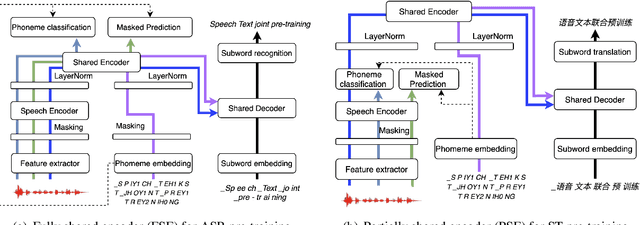

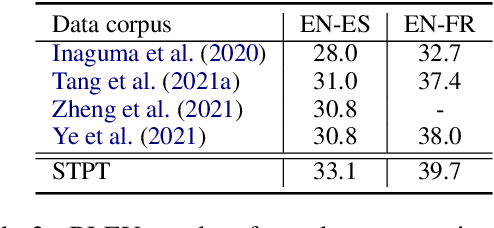
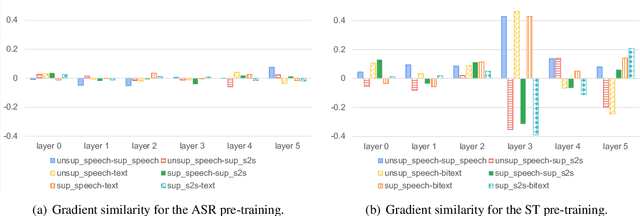
We describe a method to jointly pre-train speech and text in an encoder-decoder modeling framework for speech translation and recognition. The proposed method incorporates four self-supervised and supervised subtasks for cross modality learning. A self-supervised speech subtask leverages unlabelled speech data, and a (self-)supervised text to text subtask makes use of abundant text training data. Two auxiliary supervised speech tasks are included to unify speech and text modeling space. Our contribution lies in integrating linguistic information from the text corpus into the speech pre-training. Detailed analysis reveals learning interference among subtasks. Two pre-training configurations for speech translation and recognition, respectively, are presented to alleviate subtask interference. Our experiments show the proposed method can effectively fuse speech and text information into one model. It achieves between 1.7 and 2.3 BLEU improvement above the state of the art on the MuST-C speech translation dataset and comparable WERs to wav2vec 2.0 on the Librispeech speech recognition task.
Enriched Robust Multi-View Kernel Subspace Clustering
May 21, 2022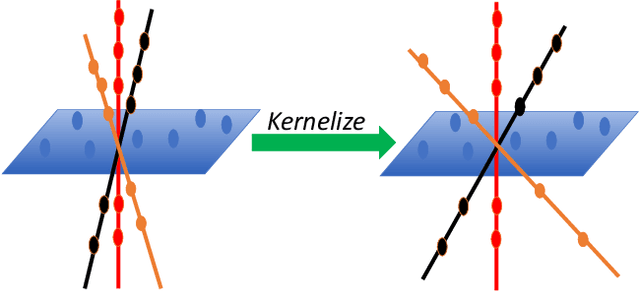
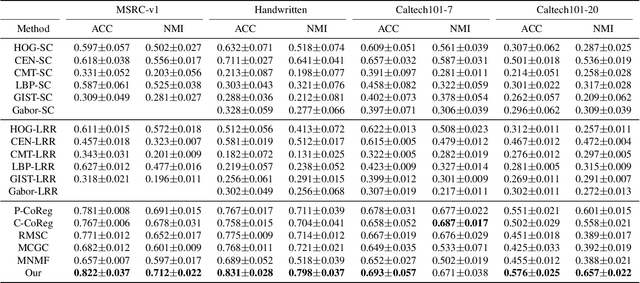
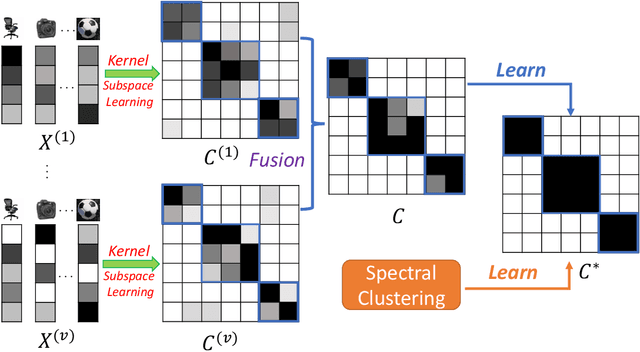
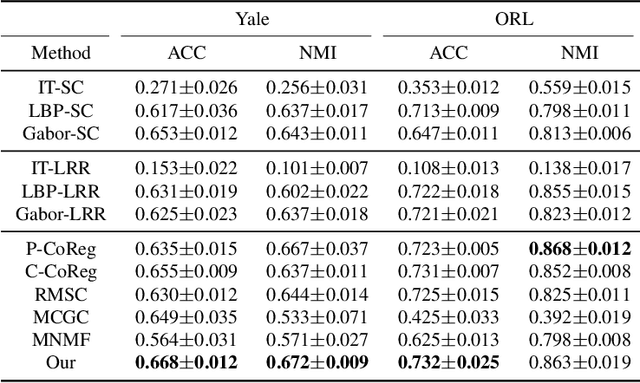
Subspace clustering is to find underlying low-dimensional subspaces and cluster the data points correctly. In this paper, we propose a novel multi-view subspace clustering method. Most existing methods suffer from two critical issues. First, they usually adopt a two-stage framework and isolate the processes of affinity learning, multi-view information fusion and clustering. Second, they assume the data lies in a linear subspace which may fail in practice as most real-world datasets may have non-linearity structures. To address the above issues, in this paper we propose a novel Enriched Robust Multi-View Kernel Subspace Clustering framework where the consensus affinity matrix is learned from both multi-view data and spectral clustering. Due to the objective and constraints which is difficult to optimize, we propose an iterative optimization method which is easy to implement and can yield closed solution in each step. Extensive experiments have validated the superiority of our method over state-of-the-art clustering methods.