 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learn to Cluster Faces via Pairwise Classification
May 26, 2022
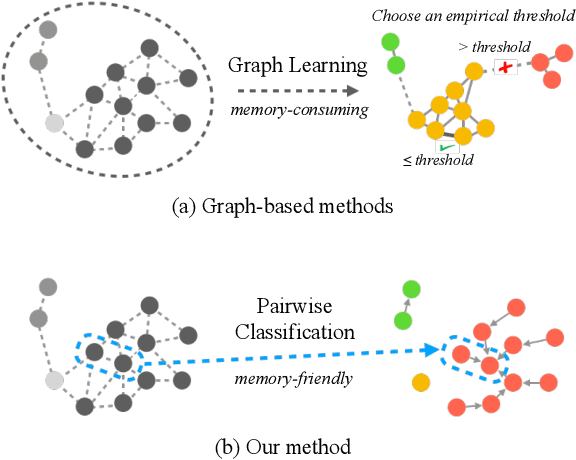
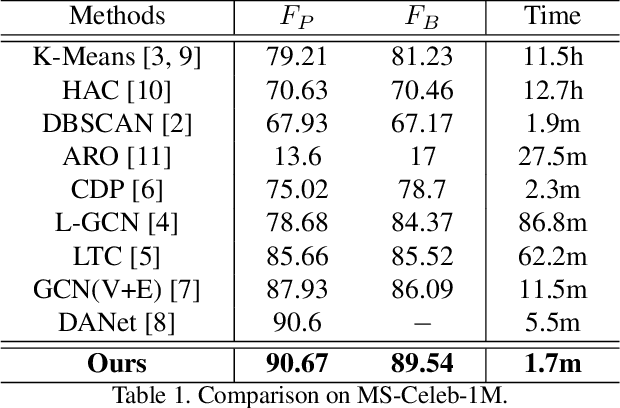
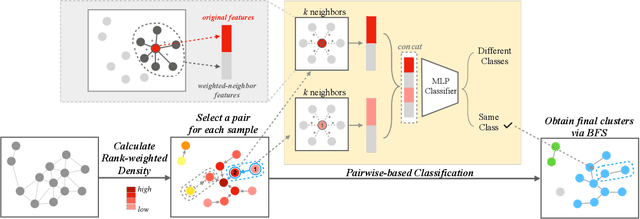
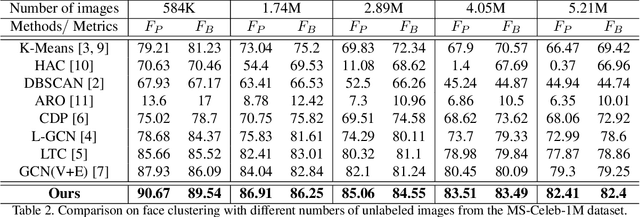
Face clustering plays an essential role in exploiting massive unlabeled face data. Recently, graph-based face clustering methods are getting popular for their satisfying performances. However, they usually suffer from excessive memory consumption especially on large-scale graphs, and rely on empirical thresholds to determine the connectivities between samples in inference, which restricts their applications in various real-world scenes. To address such problems, in this paper, we explore face clustering from the pairwise angle. Specifically, we formulate the face clustering task as a pairwise relationship classification task, avoiding the memory-consuming learning on large-scale graphs. The classifier can directly determine the relationship between samples and is enhanced by taking advantage of the contextual information. Moreover, to further facilitate the efficiency of our method, we propose a rank-weighted density to guide the selection of pairs sent to the classifier. Experimental results demonstrate that our method achieves state-of-the-art performances on several public clustering benchmarks at the fastest speed and shows a great advantage in comparison with graph-based clustering methods on memory consumption.
Open-domain Dialogue Generation Grounded with Dynamic Multi-form Knowledge Fusion
Apr 24, 2022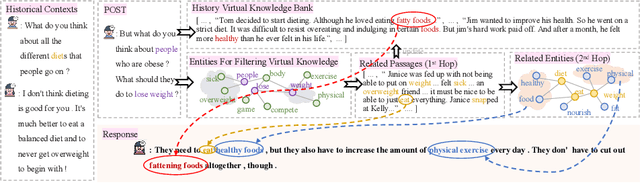

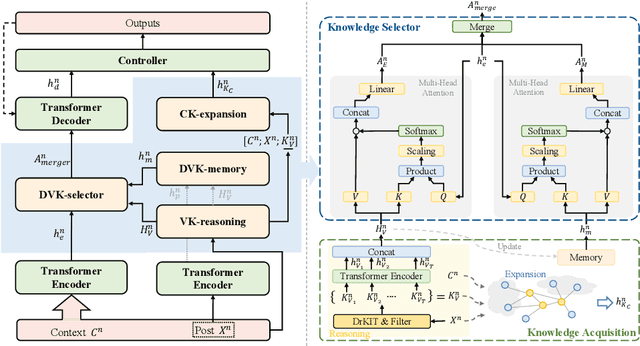
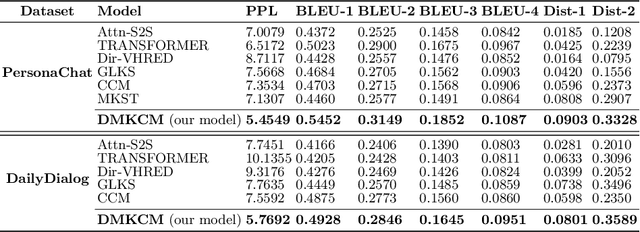
Open-domain multi-turn conversations normally face the challenges of how to enrich and expand the content of the conversation. Recently, many approaches based on external knowledge are proposed to generate rich semantic and information conversation. Two types of knowledge have been studied for knowledge-aware open-domain dialogue generation: structured triples from knowledge graphs and unstructured texts from documents. To take both advantages of abundant unstructured latent knowledge in the documents and the information expansion capabilities of the structured knowledge graph, this paper presents a new dialogue generation model, Dynamic Multi-form Knowledge Fusion based Open-domain Chatt-ing Machine (DMKCM).In particular, DMKCM applies an indexed text (a virtual Knowledge Base) to locate relevant documents as 1st hop and then expands the content of the dialogue and its 1st hop using a commonsense knowledge graph to get apposite triples as 2nd hop. To merge these two forms of knowledge into the dialogue effectively, we design a dynamic virtual knowledge selector and a controller that help to enrich and expand knowledge space. Moreover, DMKCM adopts a novel dynamic knowledge memory module that effectively uses historical reasoning knowledge to generate better responses. Experimental results indicate the effectiveness of our method in terms of dialogue coherence and informativeness.
Fact Checking with Insufficient Evidence
Apr 05, 2022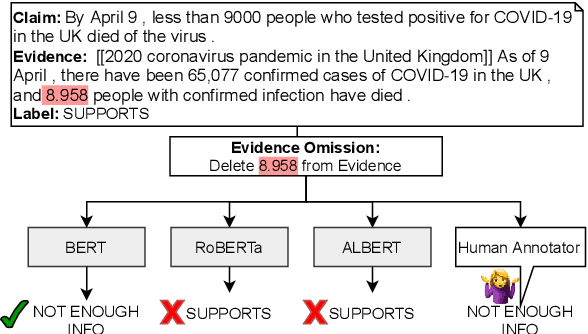



Automating the fact checking (FC) process relies on information obtained from external sources. In this work, we posit that it is crucial for FC models to make veracity predictions only when there is sufficient evidence and otherwise indicate when it is not enough. To this end, we are the first to study what information FC models consider sufficient by introducing a novel task and advancing it with three main contributions. First, we conduct an in-depth empirical analysis of the task with a new fluency-preserving method for omitting information from the evidence at the constituent and sentence level. We identify when models consider the remaining evidence (in)sufficient for FC, based on three trained models with different Transformer architectures and three FC datasets. Second, we ask annotators whether the omitted evidence was important for FC, resulting in a novel diagnostic dataset, SufficientFacts, for FC with omitted evidence. We find that models are least successful in detecting missing evidence when adverbial modifiers are omitted (21% accuracy), whereas it is easiest for omitted date modifiers (63% accuracy). Finally, we propose a novel data augmentation strategy for contrastive self-learning of missing evidence by employing the proposed omission method combined with tri-training. It improves performance for Evidence Sufficiency Prediction by up to 17.8 F1 score, which in turn improves FC performance by up to 2.6 F1 score.
Beyond Fixation: Dynamic Window Visual Transformer
Apr 08, 2022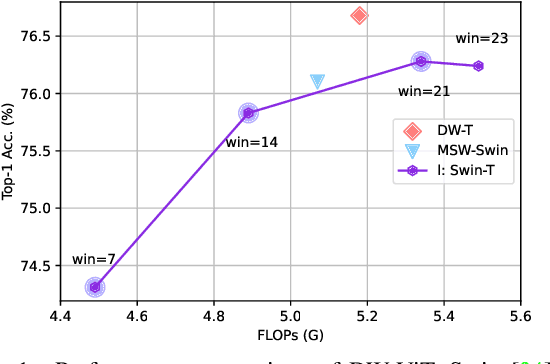
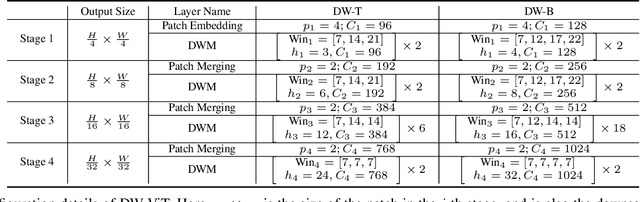
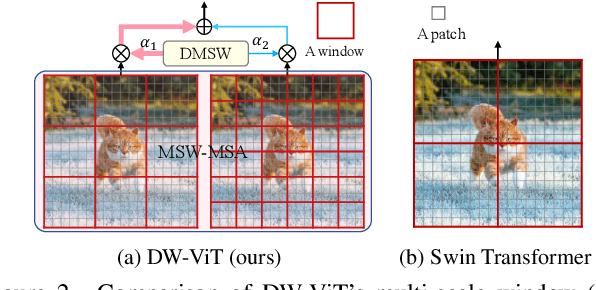
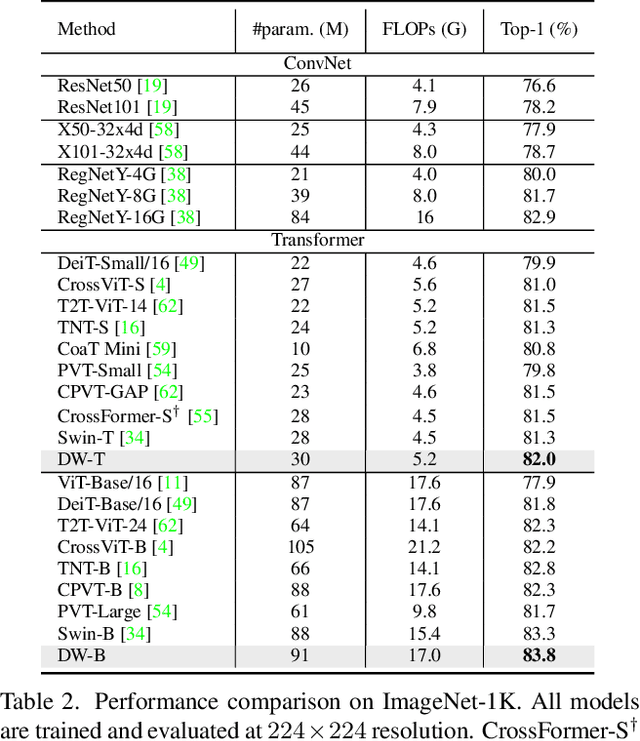
Recently, a surge of interest in visual transformers is to reduce the computational cost by limiting the calculation of self-attention to a local window. Most current work uses a fixed single-scale window for modeling by default, ignoring the impact of window size on model performance. However, this may limit the modeling potential of these window-based models for multi-scale information. In this paper, we propose a novel method, named Dynamic Window Vision Transformer (DW-ViT). The dynamic window strategy proposed by DW-ViT goes beyond the model that employs a fixed single window setting. To the best of our knowledge, we are the first to use dynamic multi-scale windows to explore the upper limit of the effect of window settings on model performance. In DW-ViT, multi-scale information is obtained by assigning windows of different sizes to different head groups of window multi-head self-attention. Then, the information is dynamically fused by assigning different weights to the multi-scale window branches. We conducted a detailed performance evaluation on three datasets, ImageNet-1K, ADE20K, and COCO. Compared with related state-of-the-art (SoTA) methods, DW-ViT obtains the best performance. Specifically, compared with the current SoTA Swin Transformers \cite{liu2021swin}, DW-ViT has achieved consistent and substantial improvements on all three datasets with similar parameters and computational costs. In addition, DW-ViT exhibits good scalability and can be easily inserted into any window-based visual transformers.
Learning Lip-Based Audio-Visual Speaker Embeddings with AV-HuBERT
May 15, 2022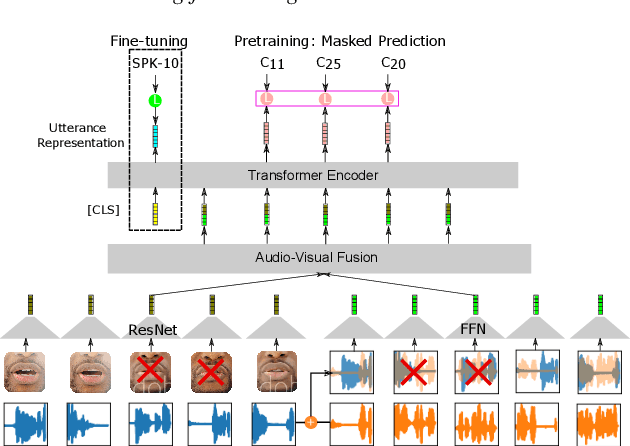
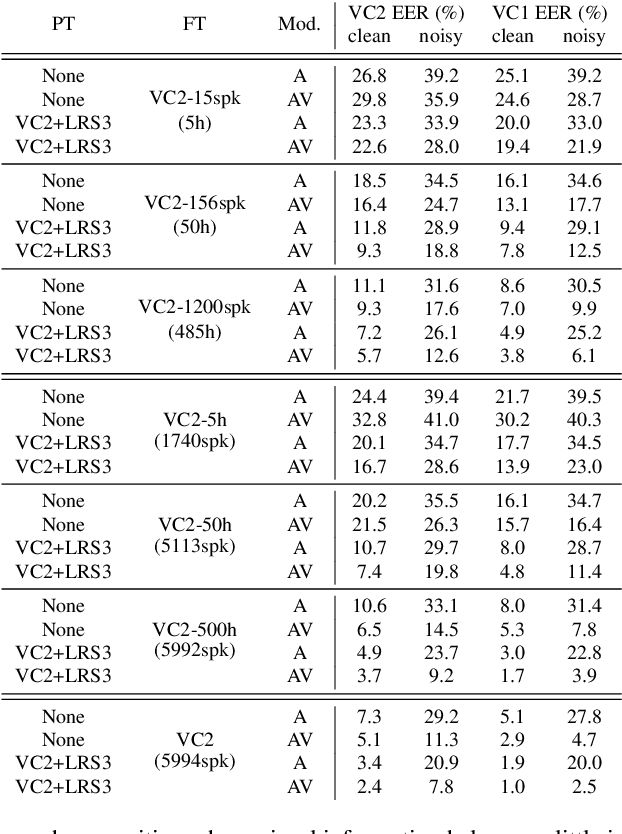
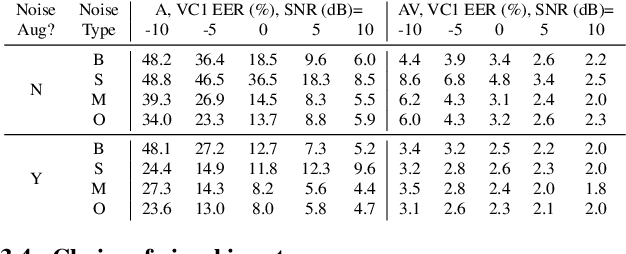
This paper investigates self-supervised pre-training for audio-visual speaker representation learning where a visual stream showing the speaker's mouth area is used alongside speech as inputs. Our study focuses on the Audio-Visual Hidden Unit BERT (AV-HuBERT) approach, a recently developed general-purpose audio-visual speech pre-training framework. We conducted extensive experiments probing the effectiveness of pre-training and visual modality. Experimental results suggest that AV-HuBERT generalizes decently to speaker related downstream tasks, improving label efficiency by roughly ten fold for both audio-only and audio-visual speaker verification. We also show that incorporating visual information, even just the lip area, greatly improves the performance and noise robustness, reducing EER by 38% in the clean condition and 75% in noisy conditions. Our code and models will be publicly available.
A Unified Model for Multi-class Anomaly Detection
Jun 08, 2022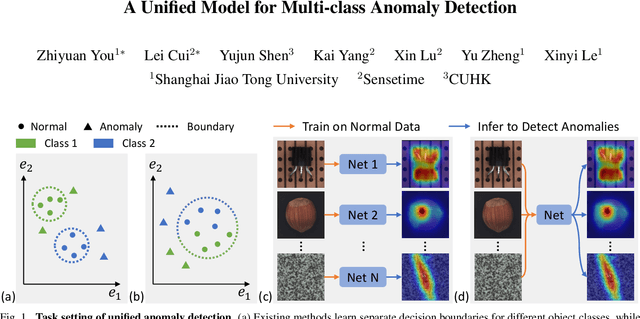
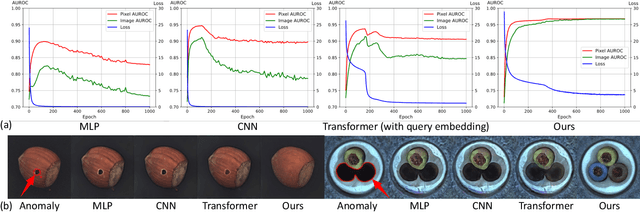
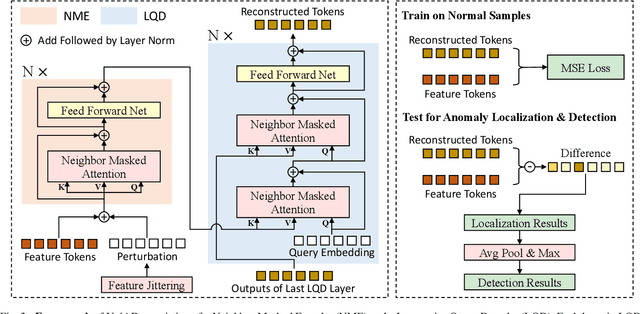
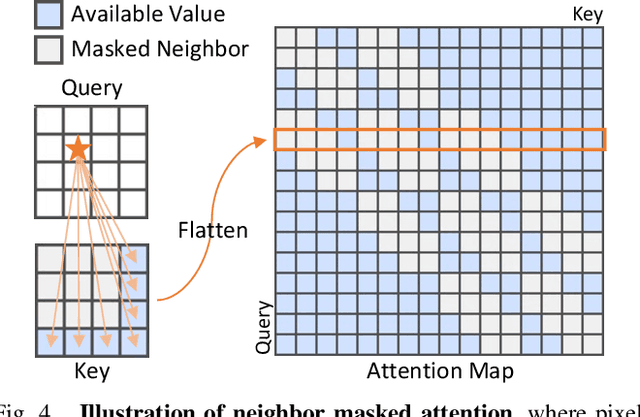
Despite the rapid advance of unsupervised anomaly detection, existing methods require to train separate models for different objects. In this work, we present UniAD that accomplishes anomaly detection for multiple classes with a unified framework. Under such a challenging setting, popular reconstruction networks may fall into an "identical shortcut", where both normal and anomalous samples can be well recovered, and hence fail to spot outliers. To tackle this obstacle, we make three improvements. First, we revisit the formulations of fully-connected layer, convolutional layer, as well as attention layer, and confirm the important role of query embedding (i.e., within attention layer) in preventing the network from learning the shortcut. We therefore come up with a layer-wise query decoder to help model the multi-class distribution. Second, we employ a neighbor masked attention module to further avoid the information leak from the input feature to the reconstructed output feature. Third, we propose a feature jittering strategy that urges the model to recover the correct message even with noisy inputs. We evaluate our algorithm on MVTec-AD and CIFAR-10 datasets, where we surpass the state-of-the-art alternatives by a sufficiently large margin. For example, when learning a unified model for 15 categories in MVTec-AD, we surpass the second competitor on the tasks of both anomaly detection (from 88.1% to 96.5%) and anomaly localization (from 89.5% to 96.8%). Code will be made publicly available.
On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views
Jan 31, 2020
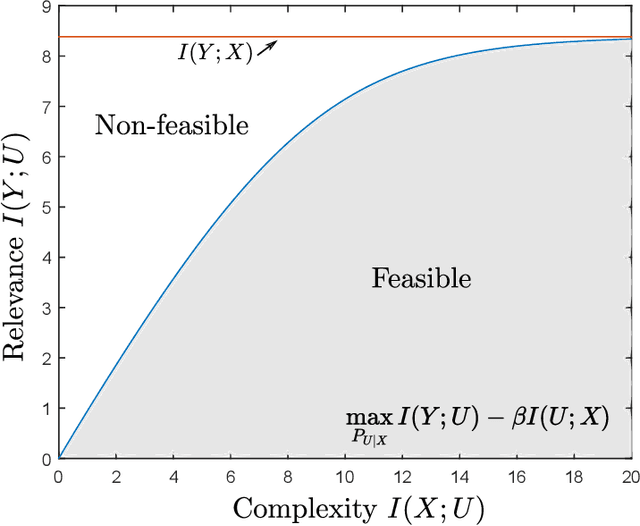
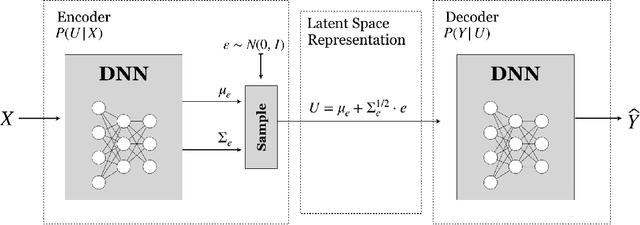

This tutorial paper focuses on the variants of the bottleneck problem taking an information theoretic perspective and discusses practical methods to solve it, as well as its connection to coding and learning aspects. The intimate connections of this setting to remote source-coding under logarithmic loss distortion measure, information combining, common reconstruction, the Wyner-Ahlswede-Korner problem, the efficiency of investment information, as well as, generalization, variational inference, representation learning, autoencoders, and others are highlighted. We discuss its extension to the distributed information bottleneck problem with emphasis on the Gaussian model and highlight the basic connections to the uplink Cloud Radio Access Networks (CRAN) with oblivious processing. For this model, the optimal trade-offs between relevance (i.e., information) and complexity (i.e., rates) in the discrete and vector Gaussian frameworks is determined. In the concluding outlook, some interesting problems are mentioned such as the characterization of the optimal inputs ("features") distributions under power limitations maximizing the "relevance" for the Gaussian information bottleneck, under "complexity" constraints.
Localized Vision-Language Matching for Open-vocabulary Object Detection
May 12, 2022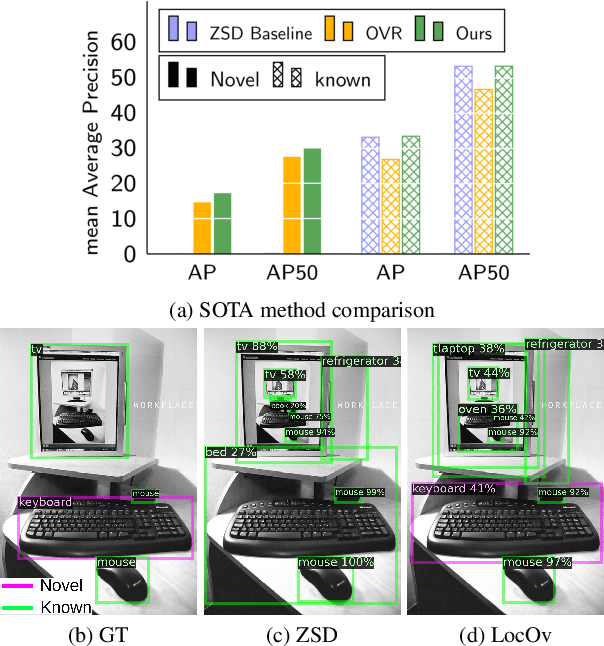
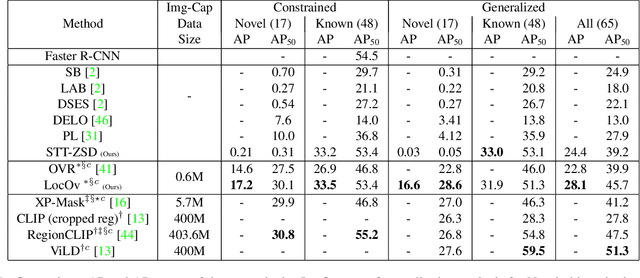
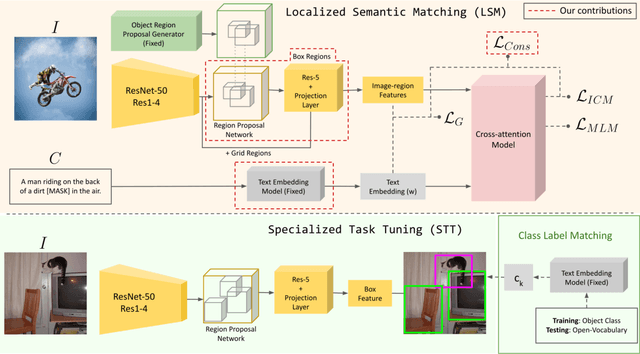
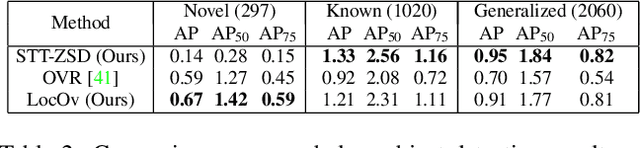
In this work, we propose an open-world object detection method that, based on image-caption pairs, learns to detect novel object classes along with a given set of known classes. It is a two-stage training approach that first uses a location-guided image-caption matching technique to learn class labels for both novel and known classes in a weakly-supervised manner and second specializes the model for the object detection task using known class annotations. We show that a simple language model fits better than a large contextualized language model for detecting novel objects. Moreover, we introduce a consistency-regularization technique to better exploit image-caption pair information. Our method compares favorably to existing open-world detection approaches while being data-efficient.
Coarse-to-fine Airway Segmentation Using Multi information Fusion Network and CNN-based Region Growing
Feb 25, 2021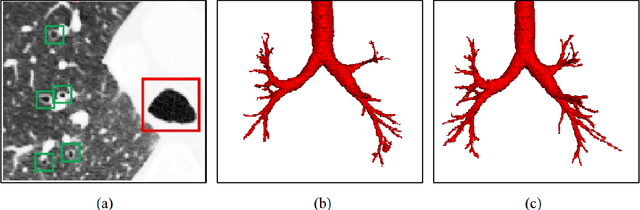
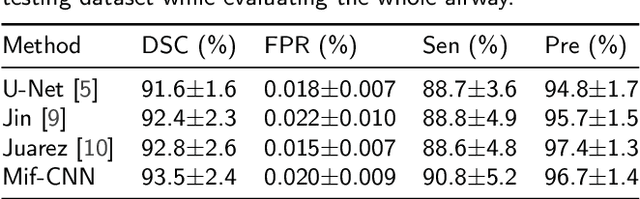
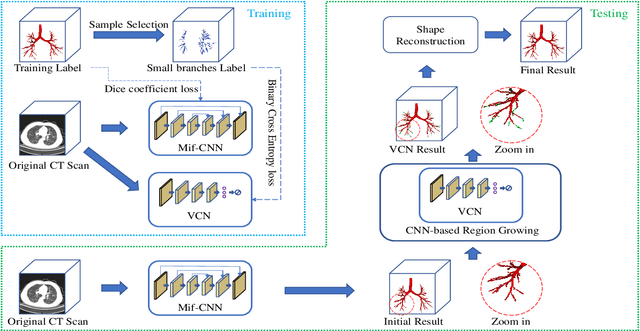
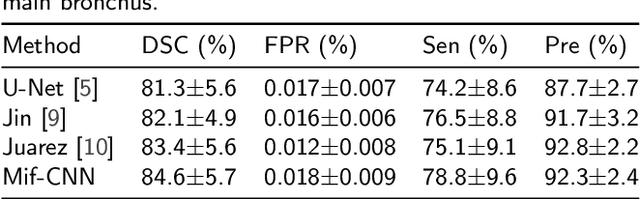
Automatic airway segmentation from chest computed tomography (CT) scans plays an important role in pulmonary disease diagnosis and computer-assisted therapy. However, low contrast at peripheral branches and complex tree-like structures remain as two mainly challenges for airway segmentation. Recent research has illustrated that deep learning methods perform well in segmentation tasks. Motivated by these works, a coarse-to-fine segmentation framework is proposed to obtain a complete airway tree. Our framework segments the overall airway and small branches via the multi-information fusion convolution neural network (Mif-CNN) and the CNN-based region growing, respectively. In Mif-CNN, atrous spatial pyramid pooling (ASPP) is integrated into a u-shaped network, and it can expend the receptive field and capture multi-scale information. Meanwhile, boundary and location information are incorporated into semantic information. These information are fused to help Mif-CNN utilize additional context knowledge and useful features. To improve the performance of the segmentation result, the CNN-based region growing method is designed to focus on obtaining small branches. A voxel classification network (VCN), which can entirely capture the rich information around each voxel, is applied to classify the voxels into airway and non-airway. In addition, a shape reconstruction method is used to refine the airway tree.
Classifying Cyber-Risky Clinical Notes by Employing Natural Language Processing
Mar 24, 2022

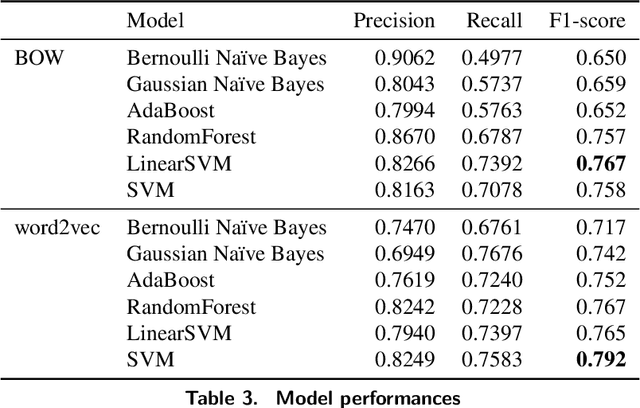
Clinical notes, which can be embedded into electronic medical records, document patient care delivery and summarize interactions between healthcare providers and patients. These clinical notes directly inform patient care and can also indirectly inform research and quality/safety metrics, among other indirect metrics. Recently, some states within the United States of America require patients to have open access to their clinical notes to improve the exchange of patient information for patient care. Thus, developing methods to assess the cyber risks of clinical notes before sharing and exchanging data is critical. While existing natural language processing techniques are geared to de-identify clinical notes, to the best of our knowledge, few have focused on classifying sensitive-information risk, which is a fundamental step toward developing effective, widespread protection of patient health information. To bridge this gap, this research investigates methods for identifying security/privacy risks within clinical notes. The classification either can be used upstream to identify areas within notes that likely contain sensitive information or downstream to improve the identification of clinical notes that have not been entirely de-identified. We develop several models using unigram and word2vec features with different classifiers to categorize sentence risk. Experiments on i2b2 de-identification dataset show that the SVM classifier using word2vec features obtained a maximum F1-score of 0.792. Future research involves articulation and differentiation of risk in terms of different global regulatory requirements.