 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Colorectal cancer survival prediction using deep distribution based multiple-instance learning
Apr 24, 2022
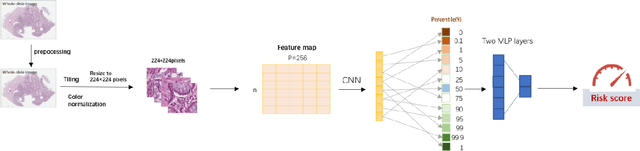
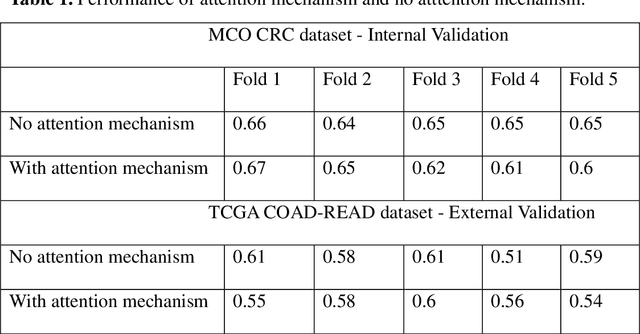
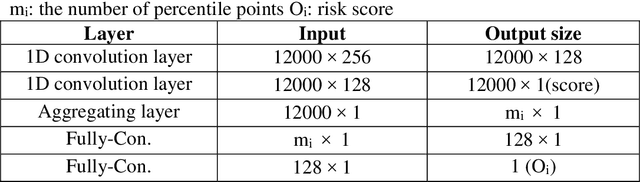
Several deep learning algorithms have been developed to predict survival of cancer patients using whole slide images (WSIs).However, identification of image phenotypes within the WSIs that are relevant to patient survival and disease progression is difficult for both clinicians, and deep learning algorithms. Most deep learning based Multiple Instance Learning (MIL) algorithms for survival prediction use either top instances (e.g., maxpooling) or top/bottom instances (e.g., MesoNet) to identify image phenotypes. In this study, we hypothesize that wholistic information of the distribution of the patch scores within a WSI can predict the cancer survival better. We developed a distribution based multiple-instance survival learning algorithm (DeepDisMISL) to validate this hypothesis. We designed and executed experiments using two large international colorectal cancer WSIs datasets - MCO CRC and TCGA COAD-READ. Our results suggest that the more information about the distribution of the patch scores for a WSI, the better is the prediction performance. Including multiple neighborhood instances around each selected distribution location (e.g., percentiles) could further improve the prediction. DeepDisMISL demonstrated superior predictive ability compared to other recently published, state-of-the-art algorithms. Furthermore, our algorithm is interpretable and could assist in understanding the relationship between cancer morphological phenotypes and patients cancer survival risk.
Learn to Cluster Faces via Pairwise Classification
May 26, 2022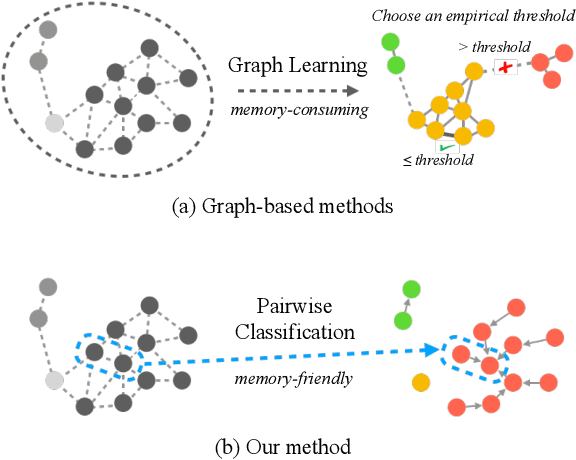
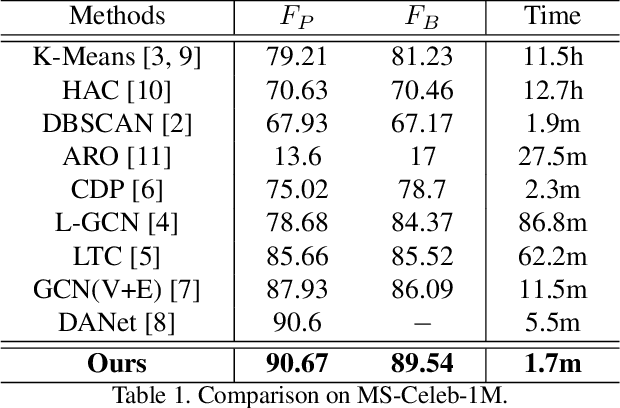
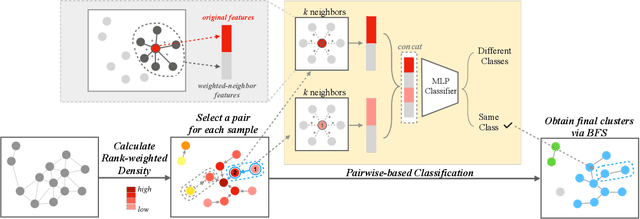
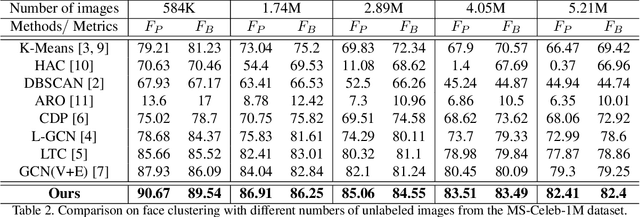
Face clustering plays an essential role in exploiting massive unlabeled face data. Recently, graph-based face clustering methods are getting popular for their satisfying performances. However, they usually suffer from excessive memory consumption especially on large-scale graphs, and rely on empirical thresholds to determine the connectivities between samples in inference, which restricts their applications in various real-world scenes. To address such problems, in this paper, we explore face clustering from the pairwise angle. Specifically, we formulate the face clustering task as a pairwise relationship classification task, avoiding the memory-consuming learning on large-scale graphs. The classifier can directly determine the relationship between samples and is enhanced by taking advantage of the contextual information. Moreover, to further facilitate the efficiency of our method, we propose a rank-weighted density to guide the selection of pairs sent to the classifier. Experimental results demonstrate that our method achieves state-of-the-art performances on several public clustering benchmarks at the fastest speed and shows a great advantage in comparison with graph-based clustering methods on memory consumption.
A Unified Model for Multi-class Anomaly Detection
Jun 08, 2022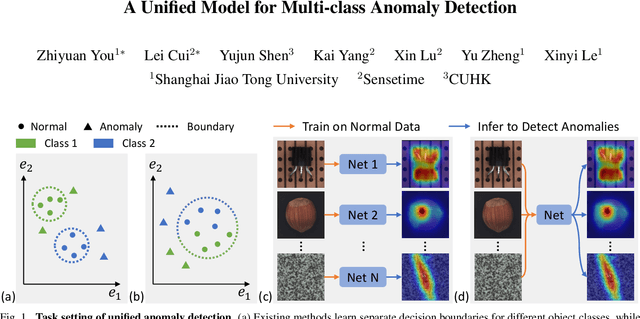
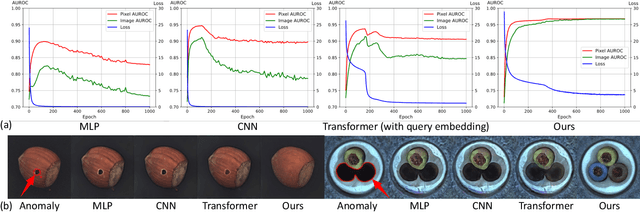
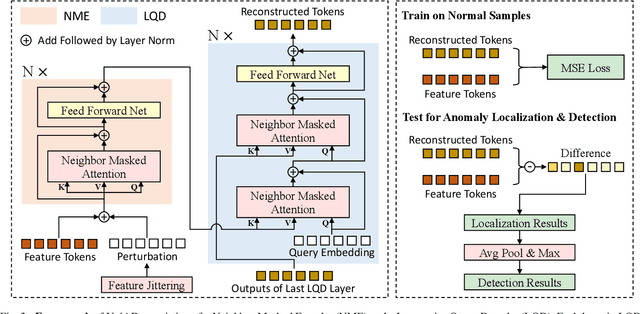
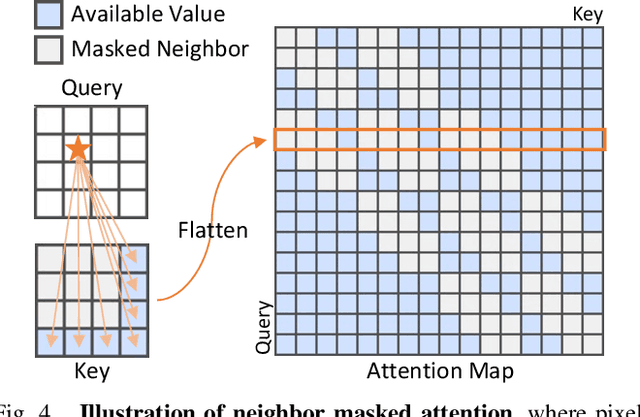
Despite the rapid advance of unsupervised anomaly detection, existing methods require to train separate models for different objects. In this work, we present UniAD that accomplishes anomaly detection for multiple classes with a unified framework. Under such a challenging setting, popular reconstruction networks may fall into an "identical shortcut", where both normal and anomalous samples can be well recovered, and hence fail to spot outliers. To tackle this obstacle, we make three improvements. First, we revisit the formulations of fully-connected layer, convolutional layer, as well as attention layer, and confirm the important role of query embedding (i.e., within attention layer) in preventing the network from learning the shortcut. We therefore come up with a layer-wise query decoder to help model the multi-class distribution. Second, we employ a neighbor masked attention module to further avoid the information leak from the input feature to the reconstructed output feature. Third, we propose a feature jittering strategy that urges the model to recover the correct message even with noisy inputs. We evaluate our algorithm on MVTec-AD and CIFAR-10 datasets, where we surpass the state-of-the-art alternatives by a sufficiently large margin. For example, when learning a unified model for 15 categories in MVTec-AD, we surpass the second competitor on the tasks of both anomaly detection (from 88.1% to 96.5%) and anomaly localization (from 89.5% to 96.8%). Code will be made publicly available.
Turing's cascade instability supports the coordination of the mind, brain, and behavior
Apr 17, 2022
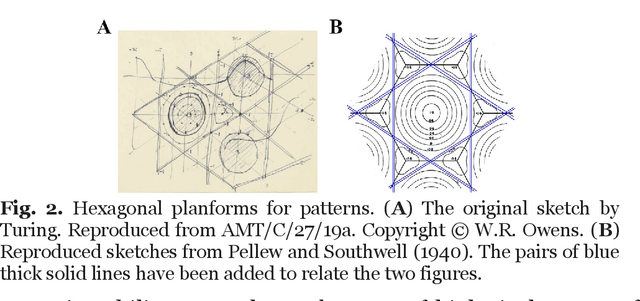

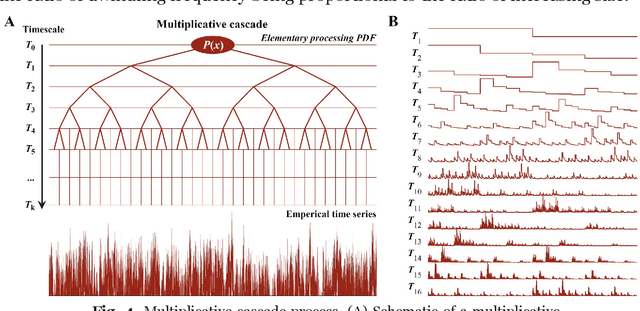
Turing inspired a computer metaphor of the mind and brain that has been handy and has spawned decades of empirical investigation, but he did much more and offered behavioral and cognitive sciences another metaphor--that of the cascade. The time has come to confront Turing's cascading instability, which suggests a geometrical framework driven by power laws and can be studied using multifractal formalism and multiscale probability density function analysis. Here, we review a rapidly growing body of scientific investigations revealing signatures of cascade instability and their consequences for a perceiving, acting, and thinking organism. We review work related to executive functioning (planning to act), postural control (bodily poise for turning plans into action), and effortful perception (action to gather information in a single modality and action to blend multimodal information). We also review findings on neuronal avalanches in the brain, specifically about neural participation in body-wide cascades. Turing's cascade instability blends the mind, brain, and behavior across space and time scales and provides an alternative to the dominant computer metaphor.
Learning Weakly-Supervised Contrastive Representations
Feb 14, 2022



We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
Learning Lip-Based Audio-Visual Speaker Embeddings with AV-HuBERT
May 15, 2022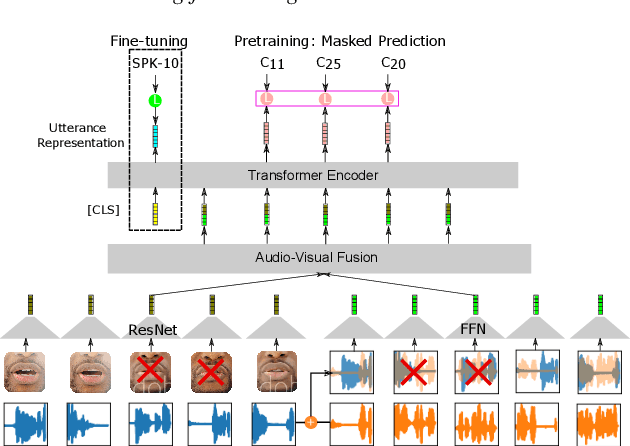
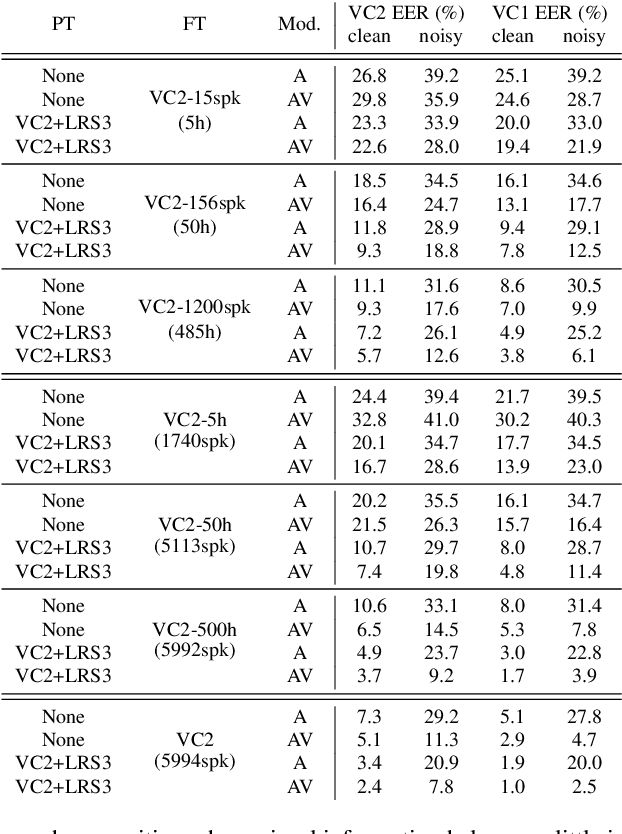
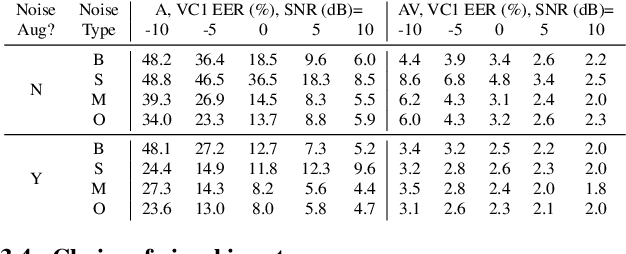
This paper investigates self-supervised pre-training for audio-visual speaker representation learning where a visual stream showing the speaker's mouth area is used alongside speech as inputs. Our study focuses on the Audio-Visual Hidden Unit BERT (AV-HuBERT) approach, a recently developed general-purpose audio-visual speech pre-training framework. We conducted extensive experiments probing the effectiveness of pre-training and visual modality. Experimental results suggest that AV-HuBERT generalizes decently to speaker related downstream tasks, improving label efficiency by roughly ten fold for both audio-only and audio-visual speaker verification. We also show that incorporating visual information, even just the lip area, greatly improves the performance and noise robustness, reducing EER by 38% in the clean condition and 75% in noisy conditions. Our code and models will be publicly available.
Open-domain Dialogue Generation Grounded with Dynamic Multi-form Knowledge Fusion
Apr 24, 2022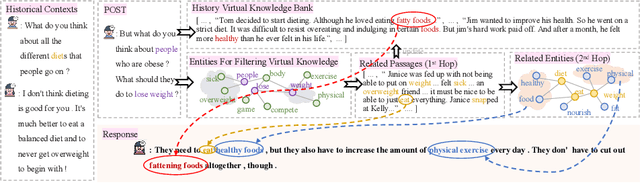

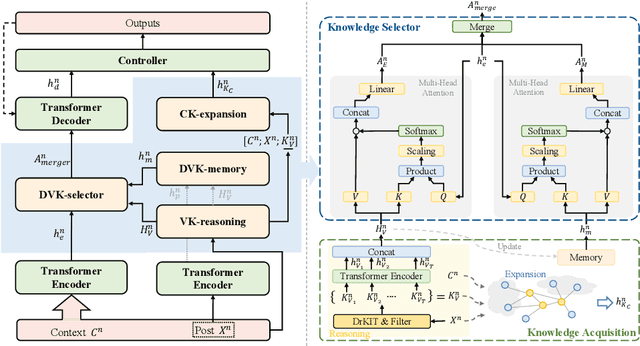
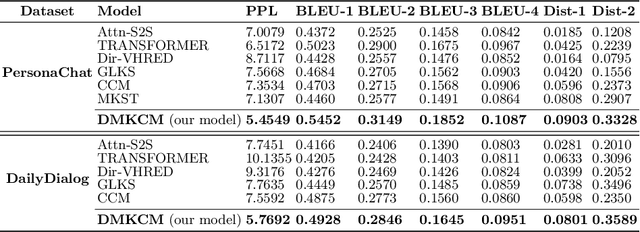
Open-domain multi-turn conversations normally face the challenges of how to enrich and expand the content of the conversation. Recently, many approaches based on external knowledge are proposed to generate rich semantic and information conversation. Two types of knowledge have been studied for knowledge-aware open-domain dialogue generation: structured triples from knowledge graphs and unstructured texts from documents. To take both advantages of abundant unstructured latent knowledge in the documents and the information expansion capabilities of the structured knowledge graph, this paper presents a new dialogue generation model, Dynamic Multi-form Knowledge Fusion based Open-domain Chatt-ing Machine (DMKCM).In particular, DMKCM applies an indexed text (a virtual Knowledge Base) to locate relevant documents as 1st hop and then expands the content of the dialogue and its 1st hop using a commonsense knowledge graph to get apposite triples as 2nd hop. To merge these two forms of knowledge into the dialogue effectively, we design a dynamic virtual knowledge selector and a controller that help to enrich and expand knowledge space. Moreover, DMKCM adopts a novel dynamic knowledge memory module that effectively uses historical reasoning knowledge to generate better responses. Experimental results indicate the effectiveness of our method in terms of dialogue coherence and informativeness.
Deep Convolutional Sparse Coding Network for Pansharpening with Guidance of Side Information
Mar 10, 2021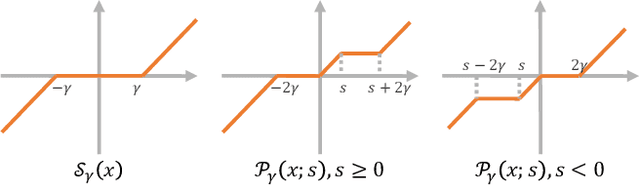
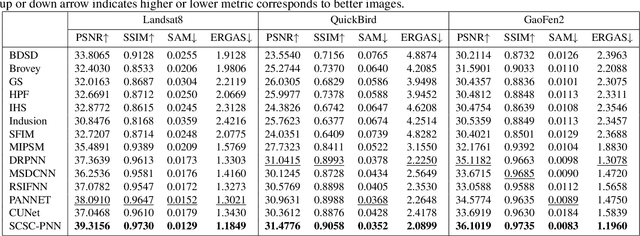
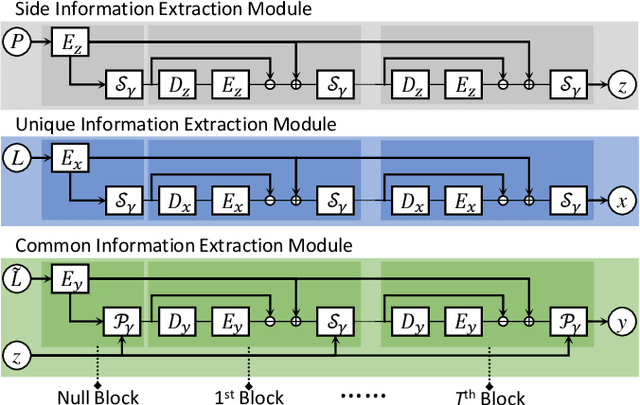
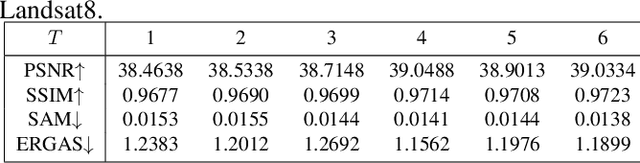
Pansharpening is a fundamental issue in remote sensing field. This paper proposes a side information partially guided convolutional sparse coding (SCSC) model for pansharpening. The key idea is to split the low resolution multispectral image into a panchromatic image related feature map and a panchromatic image irrelated feature map, where the former one is regularized by the side information from panchromatic images. With the principle of algorithm unrolling techniques, the proposed model is generalized as a deep neural network, called as SCSC pansharpening neural network (SCSC-PNN). Compared with 13 classic and state-of-the-art methods on three satellites, the numerical experiments show that SCSC-PNN is superior to others. The codes are available at https://github.com/xsxjtu/SCSC-PNN.
Localized Vision-Language Matching for Open-vocabulary Object Detection
May 12, 2022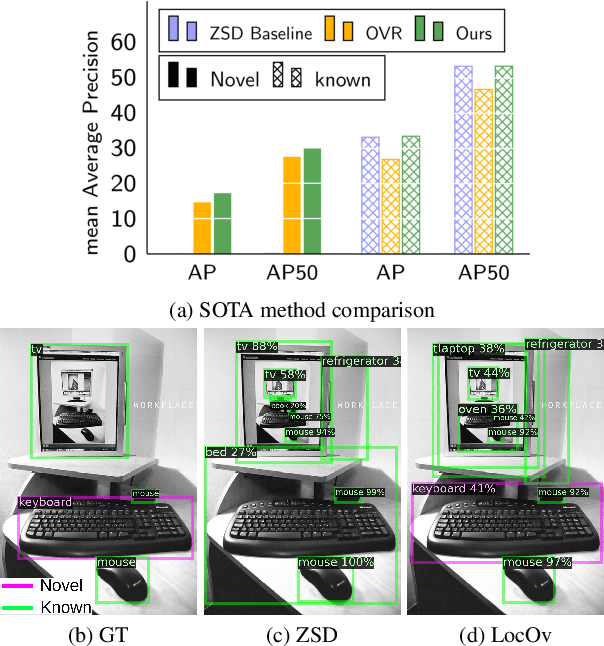
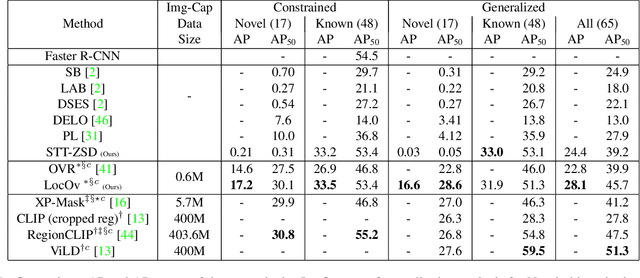
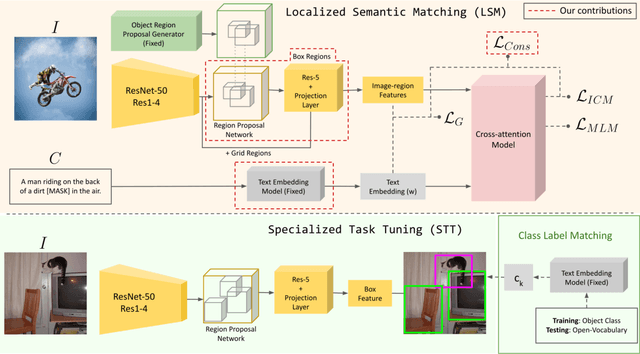
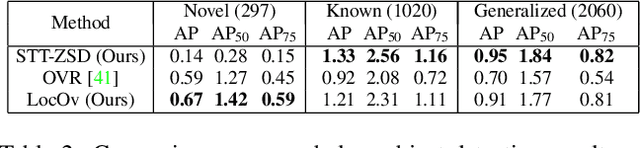
In this work, we propose an open-world object detection method that, based on image-caption pairs, learns to detect novel object classes along with a given set of known classes. It is a two-stage training approach that first uses a location-guided image-caption matching technique to learn class labels for both novel and known classes in a weakly-supervised manner and second specializes the model for the object detection task using known class annotations. We show that a simple language model fits better than a large contextualized language model for detecting novel objects. Moreover, we introduce a consistency-regularization technique to better exploit image-caption pair information. Our method compares favorably to existing open-world detection approaches while being data-efficient.
Diminishing Empirical Risk Minimization for Unsupervised Anomaly Detection
May 29, 2022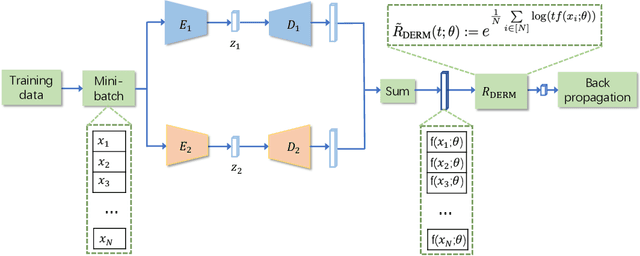
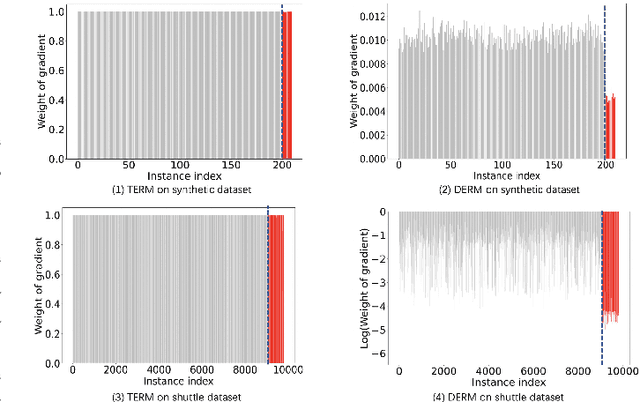
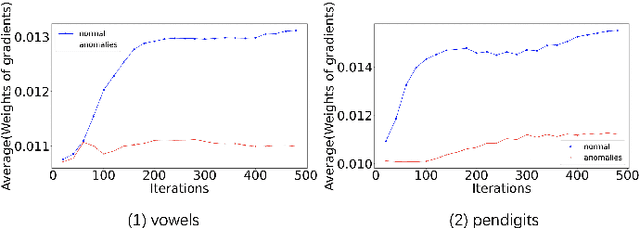
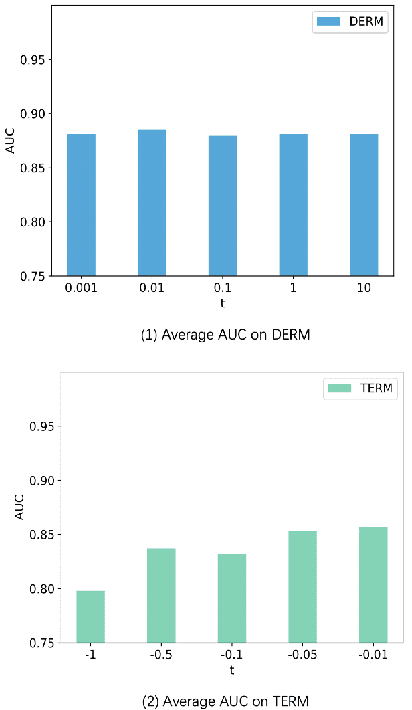
Unsupervised anomaly detection (AD) is a challenging task in realistic applications. Recently, there is an increasing trend to detect anomalies with deep neural networks (DNN). However, most popular deep AD detectors cannot protect the network from learning contaminated information brought by anomalous data, resulting in unsatisfactory detection performance and overfitting issues. In this work, we identify one reason that hinders most existing DNN-based anomaly detection methods from performing is the wide adoption of the Empirical Risk Minimization (ERM). ERM assumes that the performance of an algorithm on an unknown distribution can be approximated by averaging losses on the known training set. This averaging scheme thus ignores the distinctions between normal and anomalous instances. To break through the limitations of ERM, we propose a novel Diminishing Empirical Risk Minimization (DERM) framework. Specifically, DERM adaptively adjusts the impact of individual losses through a well-devised aggregation strategy. Theoretically, our proposed DERM can directly modify the gradient contribution of each individual loss in the optimization process to suppress the influence of outliers, leading to a robust anomaly detector. Empirically, DERM outperformed the state-of-the-art on the unsupervised AD benchmark consisting of 18 datasets.