 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Methodological Framework for the Comparative Evaluation of Multiple Imputation Methods: Multiple Imputation of Race, Ethnicity and Body Mass Index in the U.S. National COVID Cohort Collaborative
Jun 13, 2022
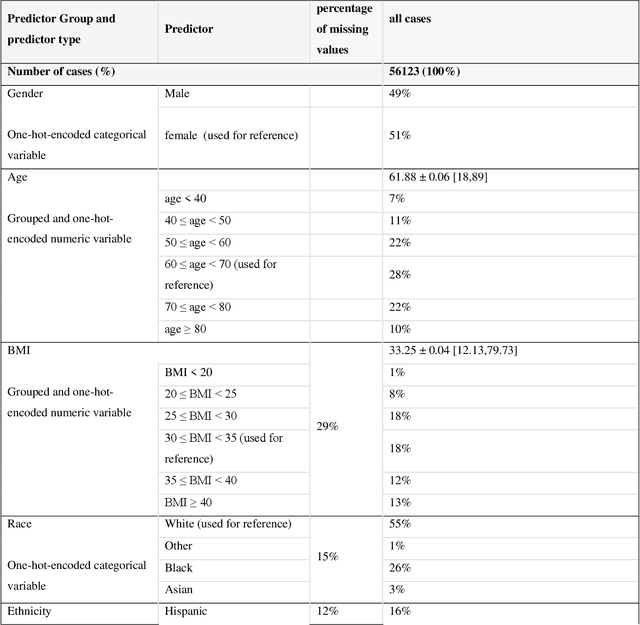
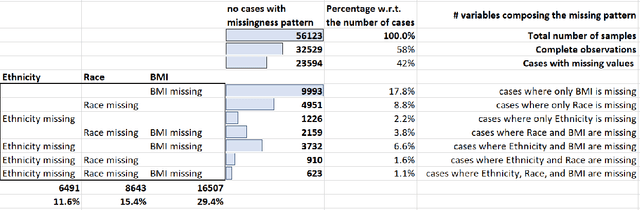

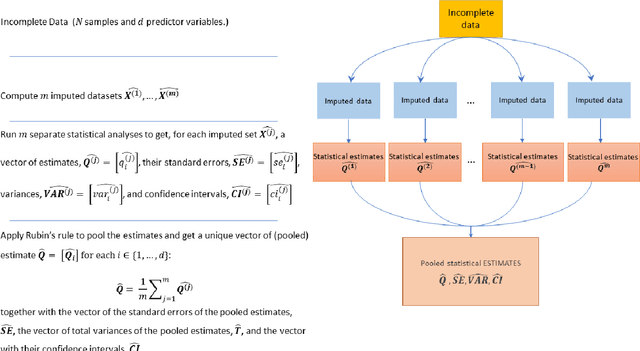
While electronic health records are a rich data source for biomedical research, these systems are not implemented uniformly across healthcare settings and significant data may be missing due to healthcare fragmentation and lack of interoperability between siloed electronic health records. Considering that the deletion of cases with missing data may introduce severe bias in the subsequent analysis, several authors prefer applying a multiple imputation strategy to recover the missing information. Unfortunately, although several literature works have documented promising results by using any of the different multiple imputation algorithms that are now freely available for research, there is no consensus on which MI algorithm works best. Beside the choice of the MI strategy, the choice of the imputation algorithm and its application settings are also both crucial and challenging. In this paper, inspired by the seminal works of Rubin and van Buuren, we propose a methodological framework that may be applied to evaluate and compare several multiple imputation techniques, with the aim to choose the most valid for computing inferences in a clinical research work. Our framework has been applied to validate, and extend on a larger cohort, the results we presented in a previous literature study, where we evaluated the influence of crucial patients' descriptors and COVID-19 severity in patients with type 2 diabetes mellitus whose data is provided by the National COVID Cohort Collaborative Enclave.
Latent Topology Induction for Understanding Contextualized Representations
Jun 03, 2022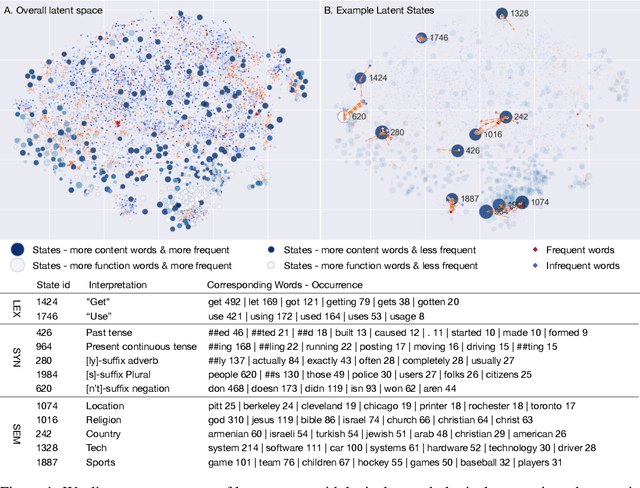
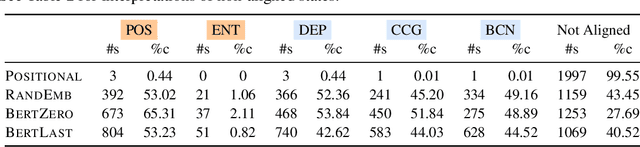
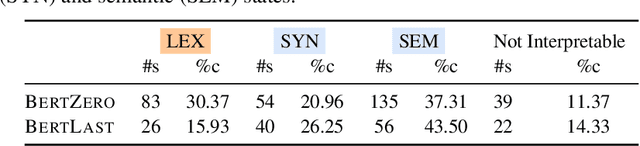
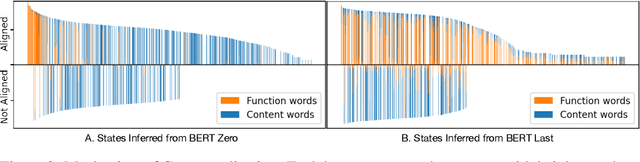
In this work, we study the representation space of contextualized embeddings and gain insight into the hidden topology of large language models. We show there exists a network of latent states that summarize linguistic properties of contextualized representations. Instead of seeking alignments to existing well-defined annotations, we infer this latent network in a fully unsupervised way using a structured variational autoencoder. The induced states not only serve as anchors that mark the topology (neighbors and connectivity) of the representation manifold but also reveal the internal mechanism of encoding sentences. With the induced network, we: (1). decompose the representation space into a spectrum of latent states which encode fine-grained word meanings with lexical, morphological, syntactic and semantic information; (2). show state-state transitions encode rich phrase constructions and serve as the backbones of the latent space. Putting the two together, we show that sentences are represented as a traversal over the latent network where state-state transition chains encode syntactic templates and state-word emissions fill in the content. We demonstrate these insights with extensive experiments and visualizations.
High-Resolution CMB Lensing Reconstruction with Deep Learning
May 15, 2022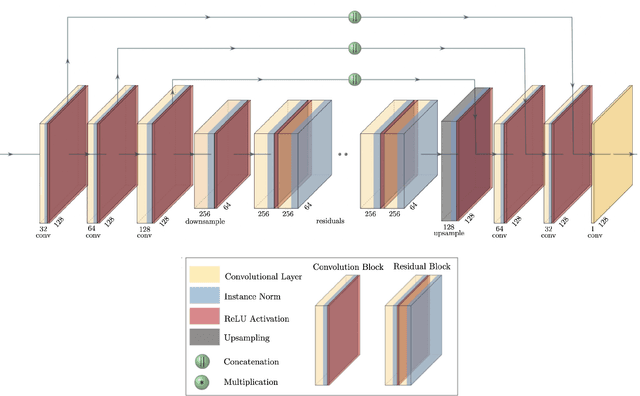
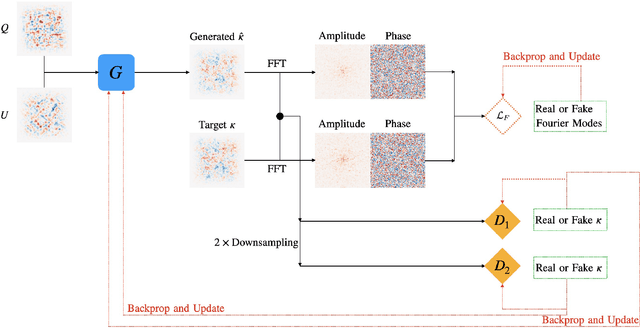
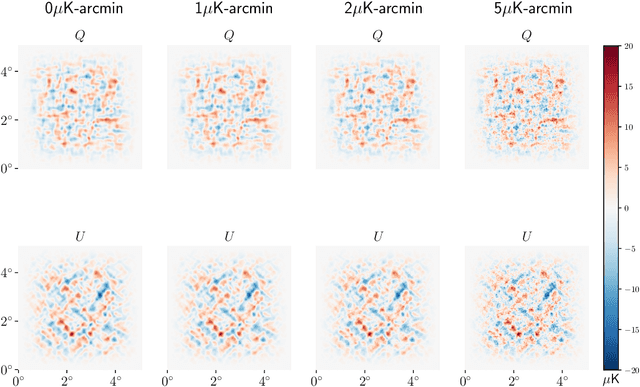
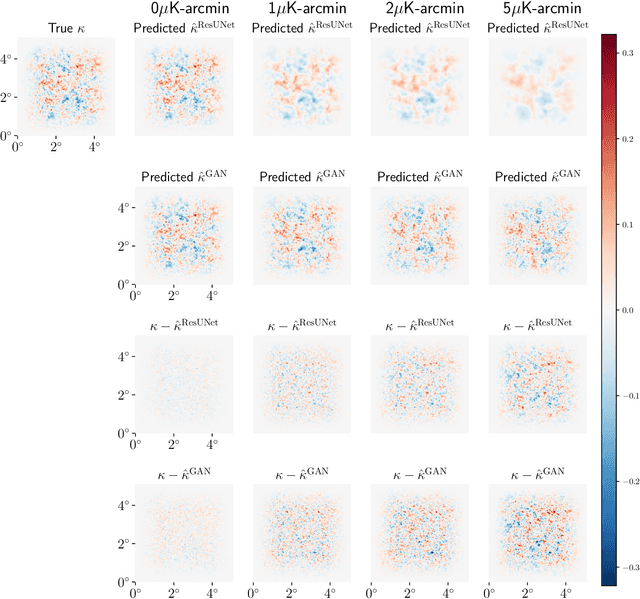
Next-generation cosmic microwave background (CMB) surveys are expected to provide valuable information about the primordial universe by creating maps of the mass along the line of sight. Traditional tools for creating these lensing convergence maps include the quadratic estimator and the maximum likelihood based iterative estimator. Here, we apply a generative adversarial network (GAN) to reconstruct the lensing convergence field. We compare our results with a previous deep learning approach -- Residual-UNet -- and discuss the pros and cons of each. In the process, we use training sets generated by a variety of power spectra, rather than the one used in testing the methods.
Unsupervised inter-frame motion correction for whole-body dynamic PET using convolutional long short-term memory in a convolutional neural network
Jun 13, 2022
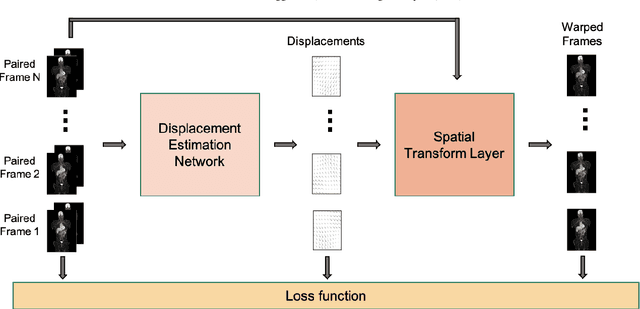
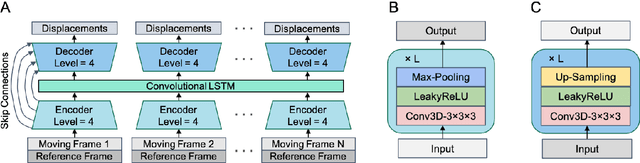
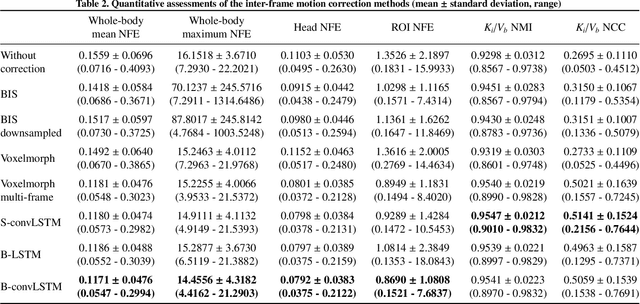
Subject motion in whole-body dynamic PET introduces inter-frame mismatch and seriously impacts parametric imaging. Traditional non-rigid registration methods are generally computationally intense and time-consuming. Deep learning approaches are promising in achieving high accuracy with fast speed, but have yet been investigated with consideration for tracer distribution changes or in the whole-body scope. In this work, we developed an unsupervised automatic deep learning-based framework to correct inter-frame body motion. The motion estimation network is a convolutional neural network with a combined convolutional long short-term memory layer, fully utilizing dynamic temporal features and spatial information. Our dataset contains 27 subjects each under a 90-min FDG whole-body dynamic PET scan. With 9-fold cross-validation, compared with both traditional and deep learning baselines, we demonstrated that the proposed network obtained superior performance in enhanced qualitative and quantitative spatial alignment between parametric $K_{i}$ and $V_{b}$ images and in significantly reduced parametric fitting error. We also showed the potential of the proposed motion correction method for impacting downstream analysis of the estimated parametric images, improving the ability to distinguish malignant from benign hypermetabolic regions of interest. Once trained, the motion estimation inference time of our proposed network was around 460 times faster than the conventional registration baseline, showing its potential to be easily applied in clinical settings.
Modeling Transformative AI Risks (MTAIR) Project -- Summary Report
Jun 19, 2022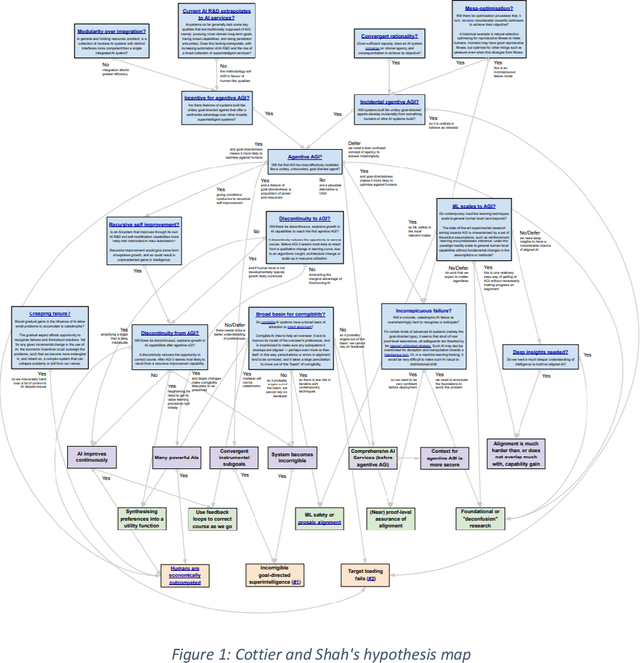
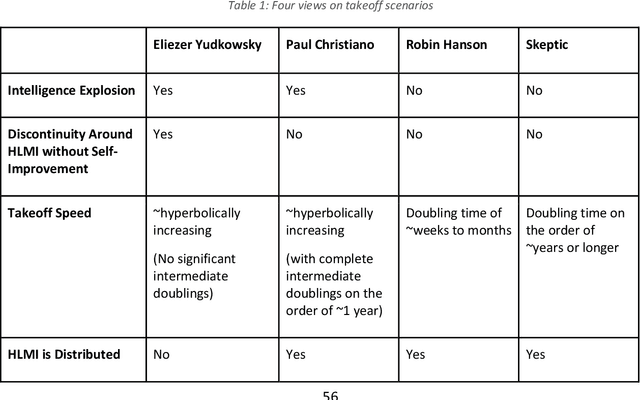
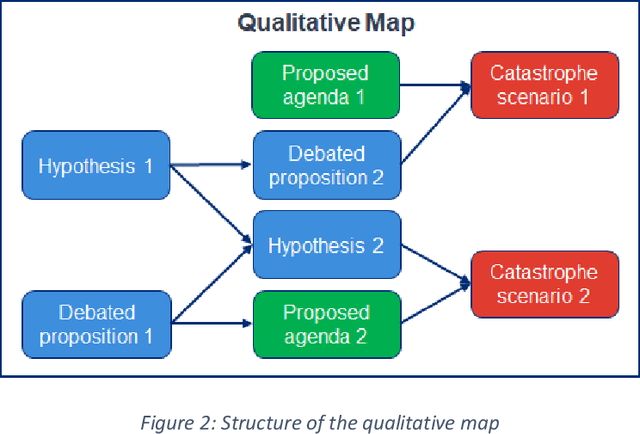
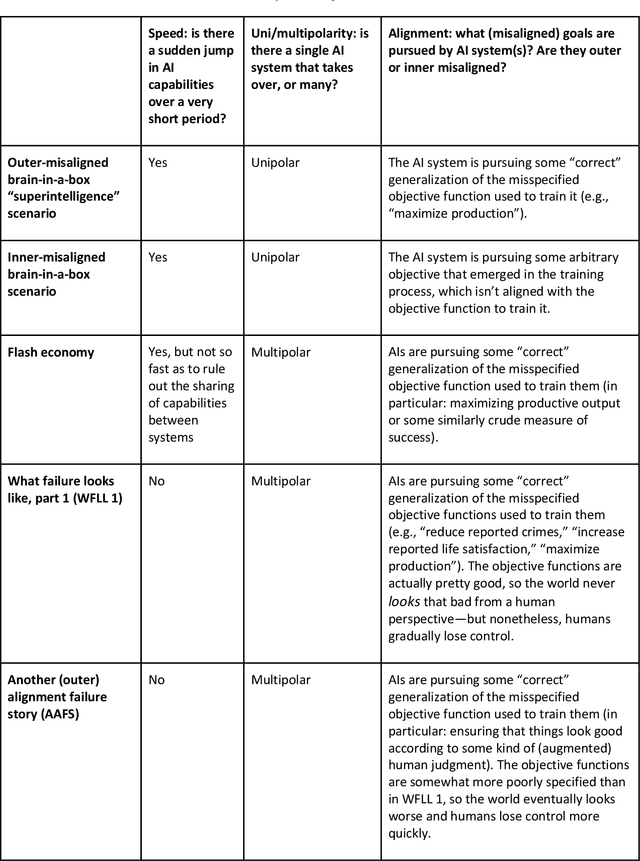
This report outlines work by the Modeling Transformative AI Risk (MTAIR) project, an attempt to map out the key hypotheses, uncertainties, and disagreements in debates about catastrophic risks from advanced AI, and the relationships between them. This builds on an earlier diagram by Ben Cottier and Rohin Shah which laid out some of the crucial disagreements ("cruxes") visually, with some explanation. Based on an extensive literature review and engagement with experts, the report explains a model of the issues involved, and the initial software-based implementation that can incorporate probability estimates or other quantitative factors to enable exploration, planning, and/or decision support. By gathering information from various debates and discussions into a single more coherent presentation, we hope to enable better discussions and debates about the issues involved. The model starts with a discussion of reasoning via analogies and general prior beliefs about artificial intelligence. Following this, it lays out a model of different paths and enabling technologies for high-level machine intelligence, and a model of how advances in the capabilities of these systems might proceed, including debates about self-improvement, discontinuous improvements, and the possibility of distributed, non-agentic high-level intelligence or slower improvements. The model also looks specifically at the question of learned optimization, and whether machine learning systems will create mesa-optimizers. The impact of different safety research on the previous sets of questions is then examined, to understand whether and how research could be useful in enabling safer systems. Finally, we discuss a model of different failure modes and loss of control or takeover scenarios.
From Labels to Priors in Capsule Endoscopy: A Prior Guided Approach for Improving Generalization with Few Labels
Jun 10, 2022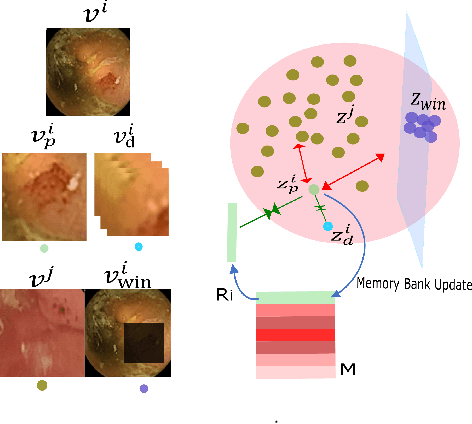

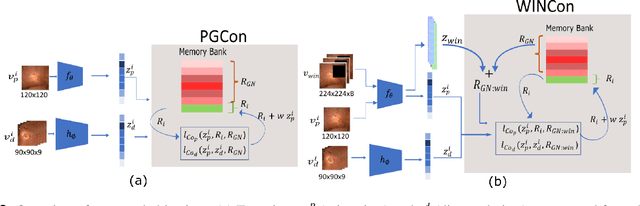

The lack of generalizability of deep learning approaches for the automated diagnosis of pathologies in Wireless Capsule Endoscopy (WCE) has prevented any significant advantages from trickling down to real clinical practices. As a result, disease management using WCE continues to depend on exhaustive manual investigations by medical experts. This explains its limited use despite several advantages. Prior works have considered using higher quality and quantity of labels as a way of tackling the lack of generalization, however this is hardly scalable considering pathology diversity not to mention that labeling large datasets encumbers the medical staff additionally. We propose using freely available domain knowledge as priors to learn more robust and generalizable representations. We experimentally show that domain priors can benefit representations by acting in proxy of labels, thereby significantly reducing the labeling requirement while still enabling fully unsupervised yet pathology-aware learning. We use the contrastive objective along with prior-guided views during pretraining, where the view choices inspire sensitivity to pathological information. Extensive experiments on three datasets show that our method performs better than (or closes gap with) the state-of-the-art in the domain, establishing a new benchmark in pathology classification and cross-dataset generalization, as well as scaling to unseen pathology categories.
Feature-aware Diversified Re-ranking with Disentangled Representations for Relevant Recommendation
Jun 10, 2022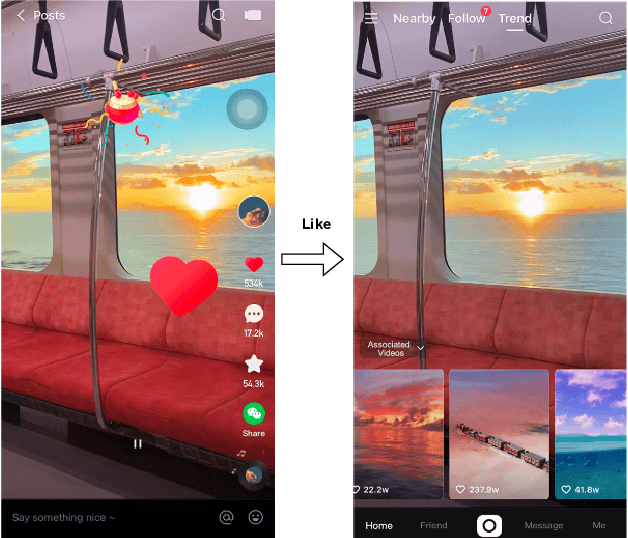

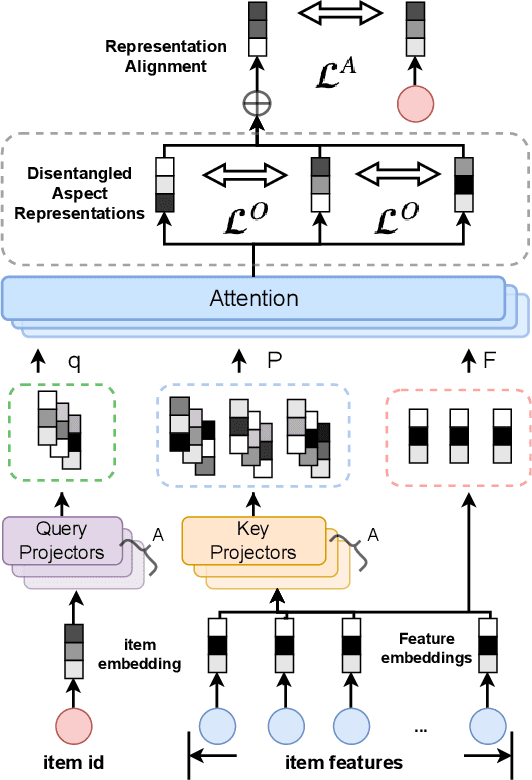
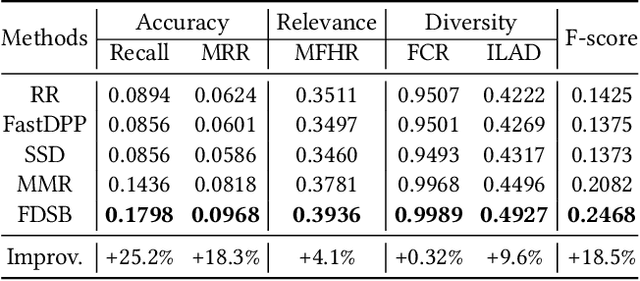
Relevant recommendation is a special recommendation scenario which provides relevant items when users express interests on one target item (e.g., click, like and purchase). Besides considering the relevance between recommendations and trigger item, the recommendations should also be diversified to avoid information cocoons. However, existing diversified recommendation methods mainly focus on item-level diversity which is insufficient when the recommended items are all relevant to the target item. Moreover, redundant or noisy item features might affect the performance of simple feature-aware recommendation approaches. Faced with these issues, we propose a Feature Disentanglement Self-Balancing Re-ranking framework (FDSB) to capture feature-aware diversity. The framework consists of two major modules, namely disentangled attention encoder (DAE) and self-balanced multi-aspect ranker. In DAE, we use multi-head attention to learn disentangled aspects from rich item features. In the ranker, we develop an aspect-specific ranking mechanism that is able to adaptively balance the relevance and diversity for each aspect. In experiments, we conduct offline evaluation on the collected dataset and deploy FDSB on KuaiShou app for online A/B test on the function of relevant recommendation. The significant improvements on both recommendation quality and user experience verify the effectiveness of our approach.
MLO: Multi-Object Tracking and Lidar Odometry in Dynamic Environment
Apr 29, 2022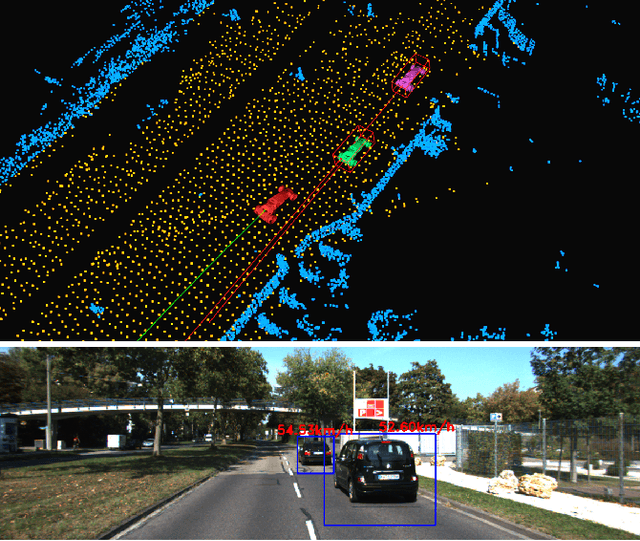
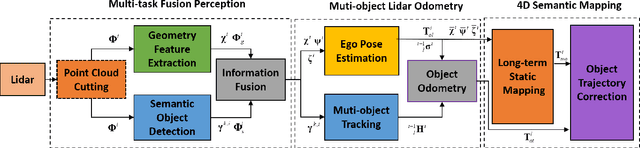
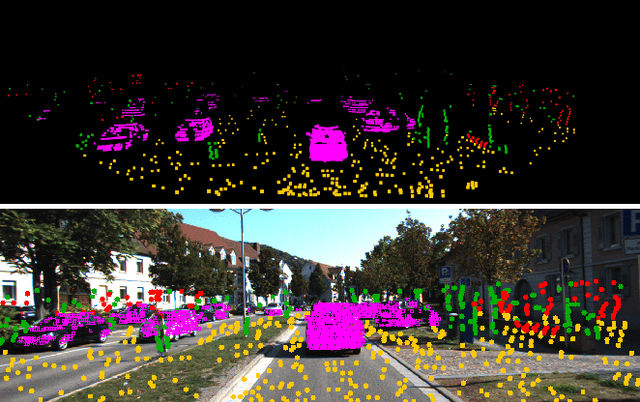
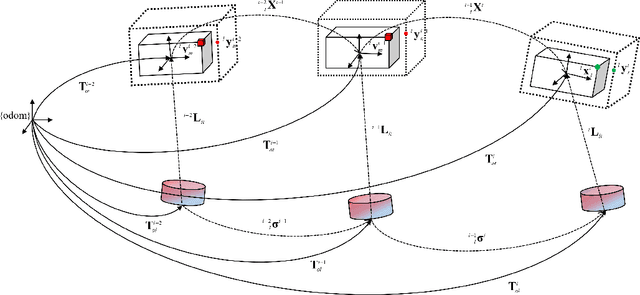
The SLAM system built on the static scene assumption will introduce significant estimation errors when a large number of moving objects appear in the field of view. Tracking and maintaining semantic objects is beneficial to understand the scene and provide rich decision information for planning and control modules. This paper introduces MLO , a multi-object Lidar odometry which tracks ego-motion and movable objects with only the lidar sensor. First, it achieves information extraction of foreground movable objects, surface road, and static background features based on geometry and object fusion perception module. While robustly estimating ego-motion, Multi-object tracking is accomplished through the least-squares method fused by 3D bounding boxes and geometric point clouds. Then, a continuous 4D semantic object map on the timeline can be created. Our approach is evaluated qualitatively and quantitatively under different scenarios on the public KITTI dataset. The experiment results show that the ego localization accuracy of MLO is better than A-LOAM system in highly dynamic, unstructured, and unknown semantic scenes. Meanwhile, the multi-object tracking method with semantic-geometry fusion also has apparent advantages in accuracy and tracking robustness compared with the single method.
Incorporating Temporal Information in Entailment Graph Mining
Sep 20, 2021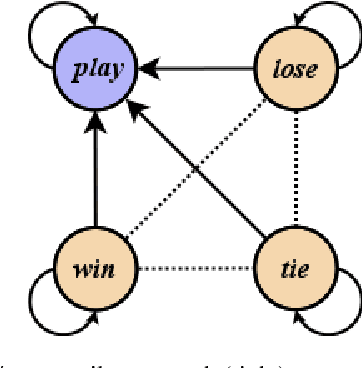
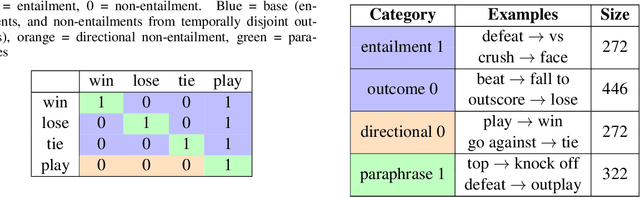
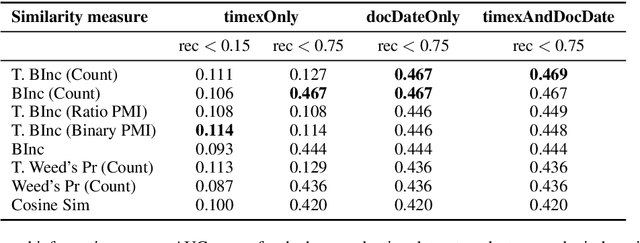
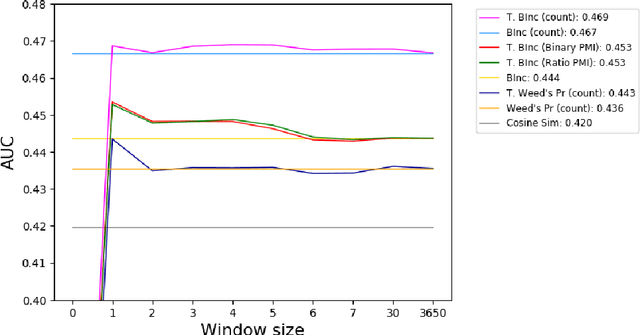
We present a novel method for injecting temporality into entailment graphs to address the problem of spurious entailments, which may arise from similar but temporally distinct events involving the same pair of entities. We focus on the sports domain in which the same pairs of teams play on different occasions, with different outcomes. We present an unsupervised model that aims to learn entailments such as win/lose $\rightarrow$ play, while avoiding the pitfall of learning non-entailments such as win $\not\rightarrow$ lose. We evaluate our model on a manually constructed dataset, showing that incorporating time intervals and applying a temporal window around them, are effective strategies.
* L. Guillou, S. Bijl de Vroe, M.J. Hosseini, M. Johnson, and M. Steedman. 2020. Incorporating temporal information in entailment graph mining. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 60-71, Barcelona, Spain (Online). Association for Computational Linguistics
RefCrowd: Grounding the Target in Crowd with Referring Expressions
Jun 16, 2022
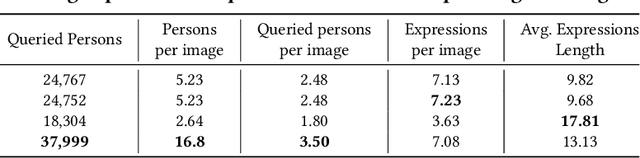

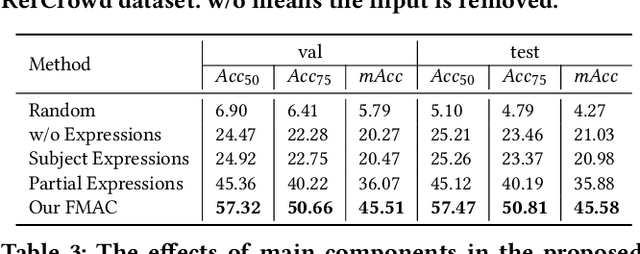
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.