 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
Sep 10, 2021

Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-training language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks--(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples--and demonstrates the superiority of BROS over previous methods. Our code will be open to the public.
Scalable Multi-view Clustering with Graph Filtering
May 18, 2022With the explosive growth of multi-source data, multi-view clustering has attracted great attention in recent years. Most existing multi-view methods operate in raw feature space and heavily depend on the quality of original feature representation. Moreover, they are often designed for feature data and ignore the rich topology structure information. Accordingly, in this paper, we propose a generic framework to cluster both attribute and graph data with heterogeneous features. It is capable of exploring the interplay between feature and structure. Specifically, we first adopt graph filtering technique to eliminate high-frequency noise to achieve a clustering-friendly smooth representation. To handle the scalability challenge, we develop a novel sampling strategy to improve the quality of anchors. Extensive experiments on attribute and graph benchmarks demonstrate the superiority of our approach with respect to state-of-the-art approaches.
Automated Imbalanced Classification via Layered Learning
May 05, 2022
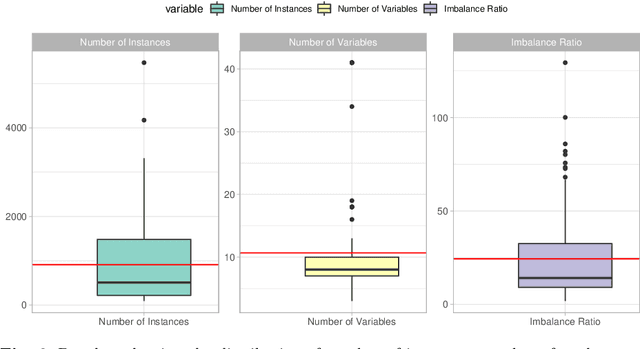
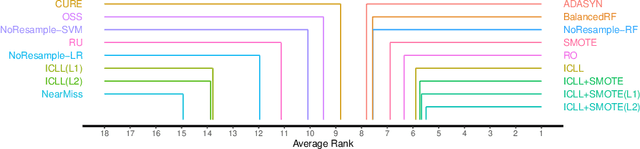
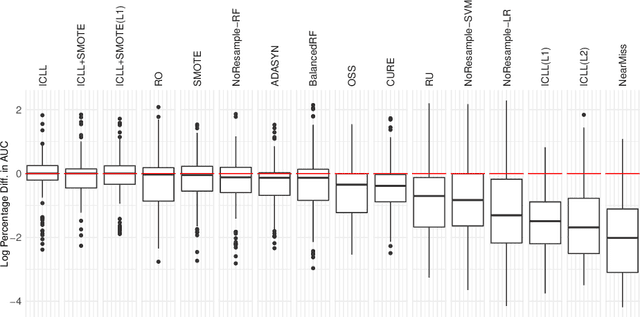
In this paper we address imbalanced binary classification (IBC) tasks. Applying resampling strategies to balance the class distribution of training instances is a common approach to tackle these problems. Many state-of-the-art methods find instances of interest close to the decision boundary to drive the resampling process. However, under-sampling the majority class may potentially lead to important information loss. Over-sampling also may increase the chance of overfitting by propagating the information contained in instances from the minority class. The main contribution of our work is a new method called ICLL for tackling IBC tasks which is not based on resampling training observations. Instead, ICLL follows a layered learning paradigm to model the data in two stages. In the first layer, ICLL learns to distinguish cases close to the decision boundary from cases which are clearly from the majority class, where this dichotomy is defined using a hierarchical clustering analysis. In the subsequent layer, we use instances close to the decision boundary and instances from the minority class to solve the original predictive task. A second contribution of our work is the automatic definition of the layers which comprise the layered learning strategy using a hierarchical clustering model. This is a relevant discovery as this process is usually performed manually according to domain knowledge. We carried out extensive experiments using 100 benchmark data sets. The results show that the proposed method leads to a better performance relatively to several state-of-the-art methods for IBC.
GINK: Graph-based Interaction-aware Kinodynamic Planning via Reinforcement Learning for Autonomous Driving
Jun 03, 2022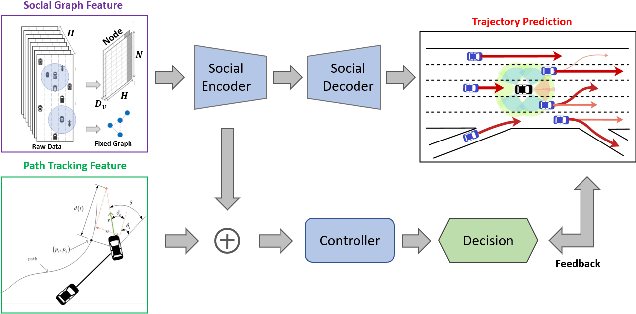

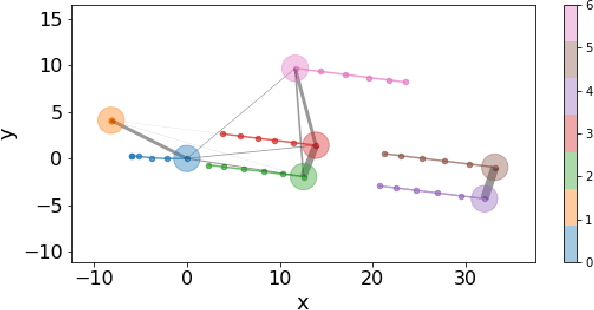
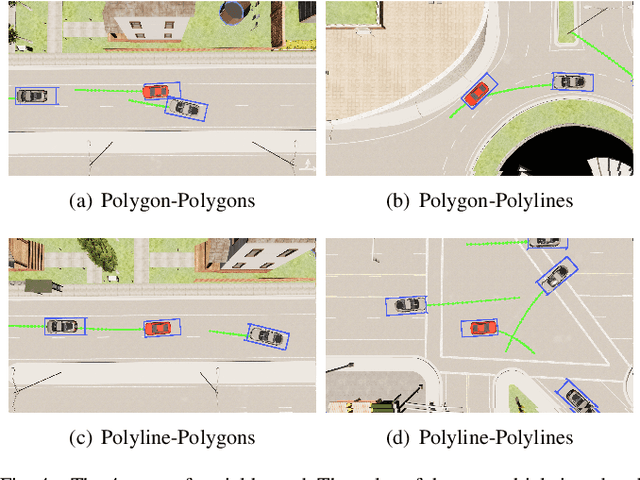
There are many challenges in applying deep reinforcement learning (DRL) to autonomous driving in a structured environment such as an urban area. This is because the massive traffic flows moving along the road network change dynamically. It is a key factor to detect changes in the intentions of surrounding vehicles and quickly find a response strategy. In this paper, we suggest a new framework that effectively combines graph-based intention representation learning and reinforcement learning for kinodynamic planning. Specifically, the movement of dynamic agents is expressed as a graph. The spatio-temporal locality of node features is conserved and the features are aggregated by considering the interaction between adjacent nodes. We simultaneously learn motion planner and controller that share the aggregated information via a safe RL framework. We intuitively interpret a given situation with predicted trajectories to generate additional cost signals. The dense cost signals encourage the policy to be safe for dynamic risk. Moreover, by utilizing the data obtained through the direct rollout of learned policy, robust intention inference is achieved for various situations encountered in training. We set up a navigation scenario in which various situations exist by using CARLA, an urban driving simulator. The experiments show the state-of-the-art performance of our approach compared to the existing baselines.
Deep Convolutional Sparse Coding Network for Pansharpening with Guidance of Side Information
Mar 10, 2021
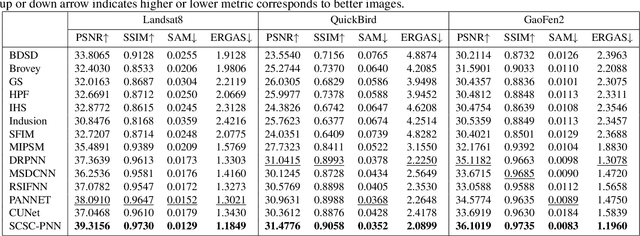
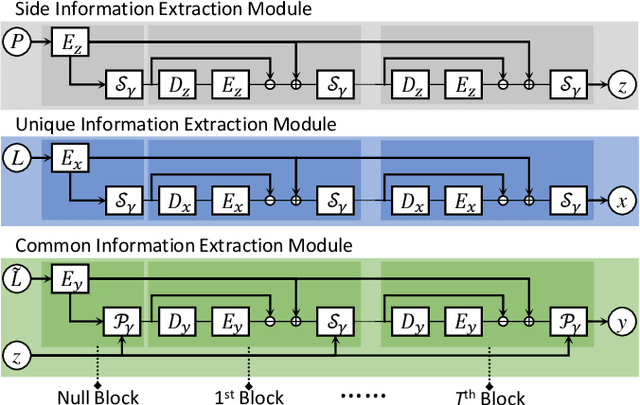
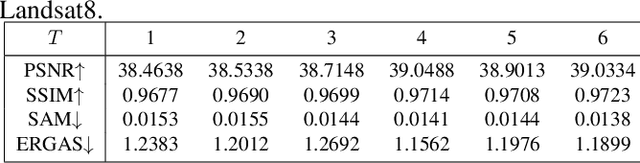
Pansharpening is a fundamental issue in remote sensing field. This paper proposes a side information partially guided convolutional sparse coding (SCSC) model for pansharpening. The key idea is to split the low resolution multispectral image into a panchromatic image related feature map and a panchromatic image irrelated feature map, where the former one is regularized by the side information from panchromatic images. With the principle of algorithm unrolling techniques, the proposed model is generalized as a deep neural network, called as SCSC pansharpening neural network (SCSC-PNN). Compared with 13 classic and state-of-the-art methods on three satellites, the numerical experiments show that SCSC-PNN is superior to others. The codes are available at https://github.com/xsxjtu/SCSC-PNN.
CATNet: Cross-event Attention-based Time-aware Network for Medical Event Prediction
Apr 29, 2022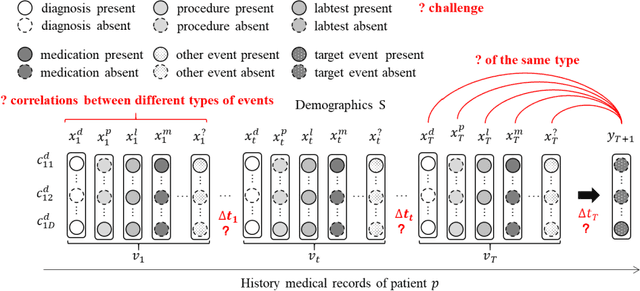

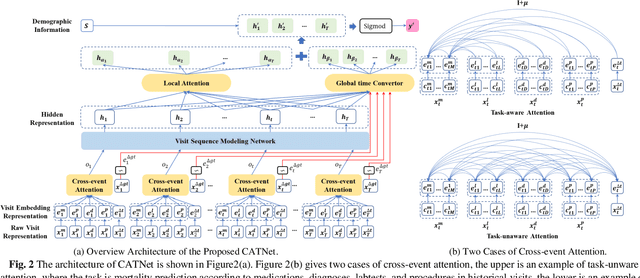
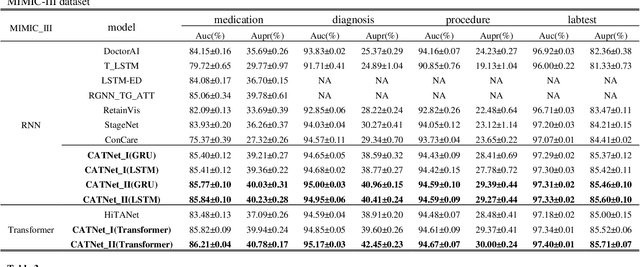
Medical event prediction (MEP) is a fundamental task in the medical domain, which needs to predict medical events, including medications, diagnosis codes, laboratory tests, procedures, outcomes, and so on, according to historical medical records. The task is challenging as medical data is a type of complex time series data with heterogeneous and temporal irregular characteristics. Many machine learning methods that consider the two characteristics have been proposed for medical event prediction. However, most of them consider the two characteristics separately and ignore the correlations among different types of medical events, especially relations between historical medical events and target medical events. In this paper, we propose a novel neural network based on attention mechanism, called cross-event attention-based time-aware network (CATNet), for medical event prediction. It is a time-aware, event-aware and task-adaptive method with the following advantages: 1) modeling heterogeneous information and temporal information in a unified way and considering temporal irregular characteristics locally and globally respectively, 2) taking full advantage of correlations among different types of events via cross-event attention. Experiments on two public datasets (MIMIC-III and eICU) show CATNet can be adaptive with different MEP tasks and outperforms other state-of-the-art methods on various MEP tasks. The source code of CATNet will be released after this manuscript is accepted.
Accurate 3D Body Shape Regression using Metric and Semantic Attributes
Jun 14, 2022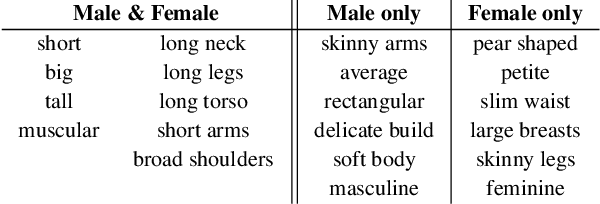

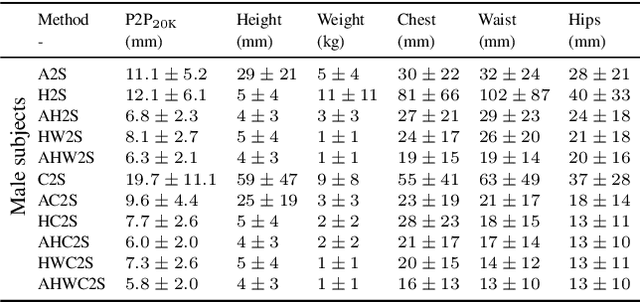
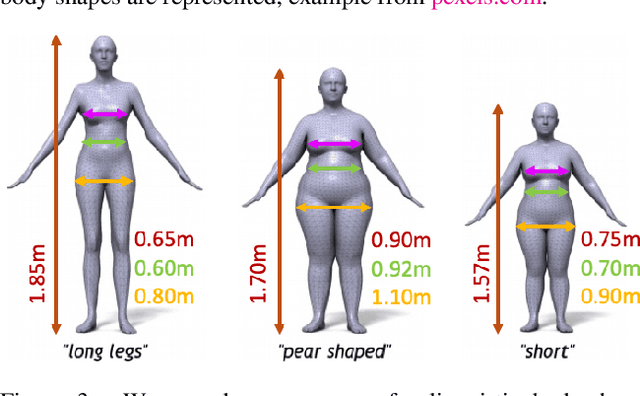
While methods that regress 3D human meshes from images have progressed rapidly, the estimated body shapes often do not capture the true human shape. This is problematic since, for many applications, accurate body shape is as important as pose. The key reason that body shape accuracy lags pose accuracy is the lack of data. While humans can label 2D joints, and these constrain 3D pose, it is not so easy to "label" 3D body shape. Since paired data with images and 3D body shape are rare, we exploit two sources of information: (1) we collect internet images of diverse "fashion" models together with a small set of anthropometric measurements; (2) we collect linguistic shape attributes for a wide range of 3D body meshes and the model images. Taken together, these datasets provide sufficient constraints to infer dense 3D shape. We exploit the anthropometric measurements and linguistic shape attributes in several novel ways to train a neural network, called SHAPY, that regresses 3D human pose and shape from an RGB image. We evaluate SHAPY on public benchmarks, but note that they either lack significant body shape variation, ground-truth shape, or clothing variation. Thus, we collect a new dataset for evaluating 3D human shape estimation, called HBW, containing photos of "Human Bodies in the Wild" for which we have ground-truth 3D body scans. On this new benchmark, SHAPY significantly outperforms state-of-the-art methods on the task of 3D body shape estimation. This is the first demonstration that 3D body shape regression from images can be trained from easy-to-obtain anthropometric measurements and linguistic shape attributes. Our model and data are available at: shapy.is.tue.mpg.de
* First two authors contributed equally
Numerical and geometrical aspects of flow-based variational quantum Monte Carlo
Mar 28, 2022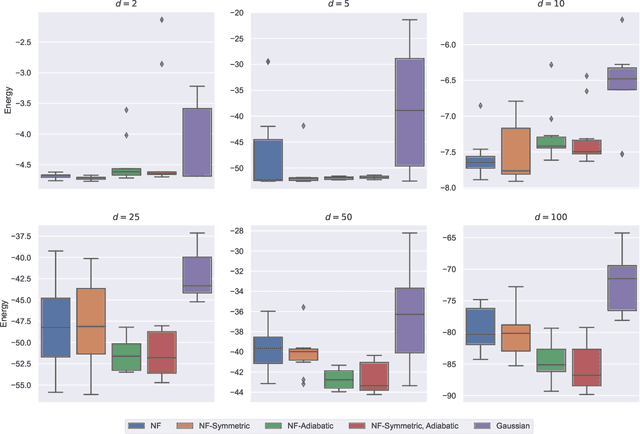
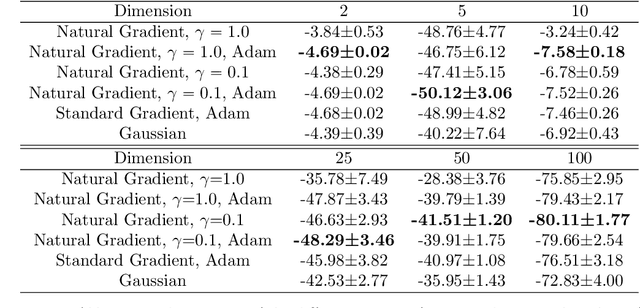
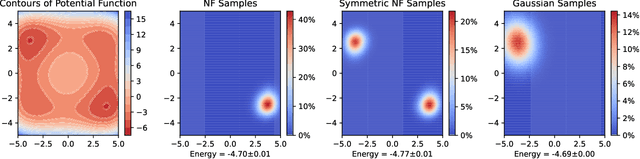
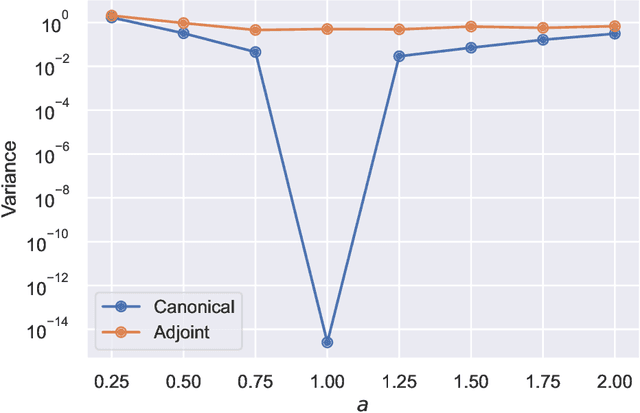
This article aims to summarize recent and ongoing efforts to simulate continuous-variable quantum systems using flow-based variational quantum Monte Carlo techniques, focusing for pedagogical purposes on the example of bosons in the field amplitude (quadrature) basis. Particular emphasis is placed on the variational real- and imaginary-time evolution problems, carefully reviewing the stochastic estimation of the time-dependent variational principles and their relationship with information geometry. Some practical instructions are provided to guide the implementation of a PyTorch code. The review is intended to be accessible to researchers interested in machine learning and quantum information science.
Contextualization for the Organization of Text Documents Streams
May 30, 2022


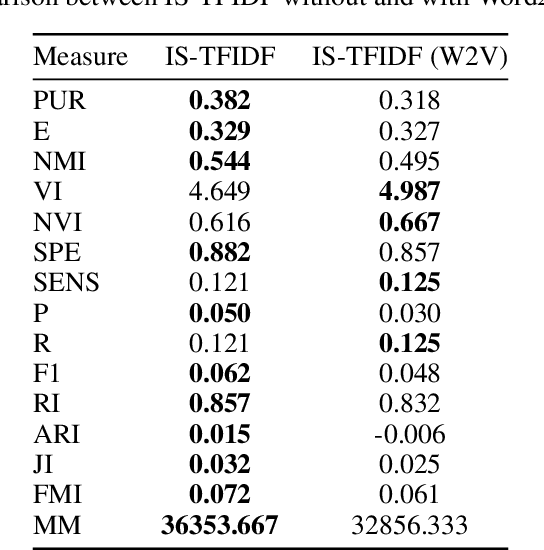
There has been a significant effort by the research community to address the problem of providing methods to organize documentation with the help of information Retrieval methods. In this report paper, we present several experiments with some stream analysis methods to explore streams of text documents. We use only dynamic algorithms to explore, analyze, and organize the flux of text documents. This document shows a case study with developed architectures of a Text Document Stream Organization, using incremental algorithms like Incremental TextRank, and IS-TFIDF. Both these algorithms are based on the assumption that the mapping of text documents and their document-term matrix in lower-dimensional evolving networks provides faster processing when compared to batch algorithms. With this architecture, and by using FastText Embedding to retrieve similarity between documents, we compare methods with large text datasets and ground truth evaluation of clustering capacities. The datasets used were Reuters and COVID-19 emotions. The results provide a new view for the contextualization of similarity when approaching flux of documents organization tasks, based on the similarity between documents in the flux, and by using mentioned algorithms.
Time-aware Graph Neural Networks for Entity Alignment between Temporal Knowledge Graphs
Mar 13, 2022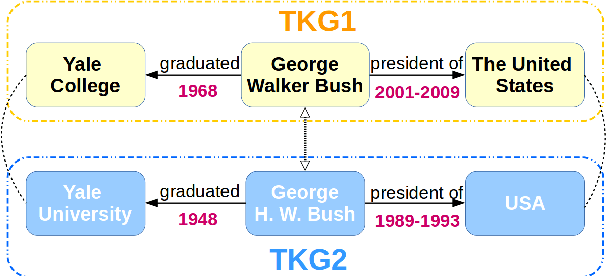

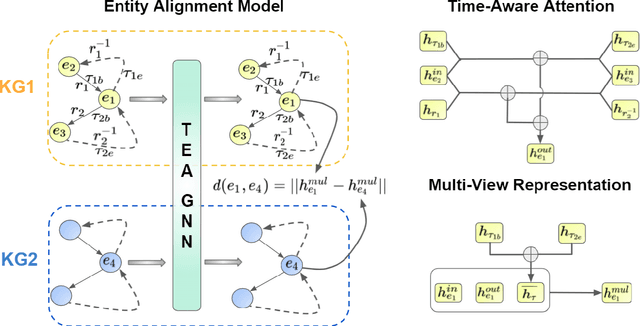
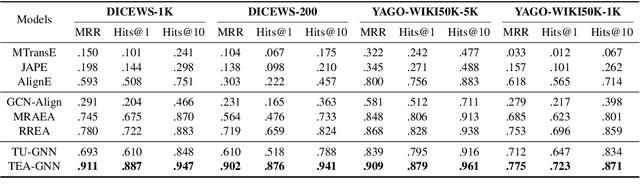
Entity alignment aims to identify equivalent entity pairs between different knowledge graphs (KGs). Recently, the availability of temporal KGs (TKGs) that contain time information created the need for reasoning over time in such TKGs. Existing embedding-based entity alignment approaches disregard time information that commonly exists in many large-scale KGs, leaving much room for improvement. In this paper, we focus on the task of aligning entity pairs between TKGs and propose a novel Time-aware Entity Alignment approach based on Graph Neural Networks (TEA-GNN). We embed entities, relations and timestamps of different KGs into a vector space and use GNNs to learn entity representations. To incorporate both relation and time information into the GNN structure of our model, we use a time-aware attention mechanism which assigns different weights to different nodes with orthogonal transformation matrices computed from embeddings of the relevant relations and timestamps in a neighborhood. Experimental results on multiple real-world TKG datasets show that our method significantly outperforms the state-of-the-art methods due to the inclusion of time information.