 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Private Eye: On the Limits of Textual Screen Peeking via Eyeglass Reflections in Video Conferencing
May 08, 2022


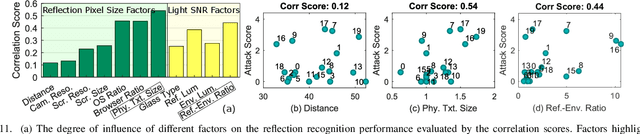

Personal video conferencing has become the new norm after COVID-19 caused a seismic shift from in-person meetings and phone calls to video conferencing for daily communications and sensitive business. Video leaks participants' on-screen information because eyeglasses and other reflective objects unwittingly expose partial screen contents. Using mathematical modeling and human subjects experiments, this research explores the extent to which emerging webcams might leak recognizable textual information gleamed from eyeglass reflections captured by webcams. The primary goal of our work is to measure, compute, and predict the factors, limits, and thresholds of recognizability as webcam technology evolves in the future. Our work explores and characterizes the viable threat models based on optical attacks using multi-frame super resolution techniques on sequences of video frames. Our experimental results and models show it is possible to reconstruct and recognize on-screen text with a height as small as 10 mm with a 720p webcam. We further apply this threat model to web textual content with varying attacker capabilities to find thresholds at which text becomes recognizable. Our user study with 20 participants suggests present-day 720p webcams are sufficient for adversaries to reconstruct textual content on big-font websites. Our models further show that the evolution toward 4K cameras will tip the threshold of text leakage to reconstruction of most header texts on popular websites. Our research proposes near-term mitigations, and justifies the importance of following the principle of least privilege for long-term defense against this attack. For privacy-sensitive scenarios, it's further recommended to develop technologies that blur all objects by default, then only unblur what is absolutely necessary to facilitate natural-looking conversations.
Robust Molecular Image Recognition: A Graph Generation Approach
May 28, 2022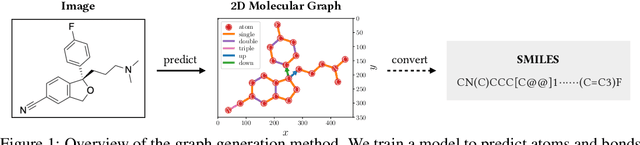
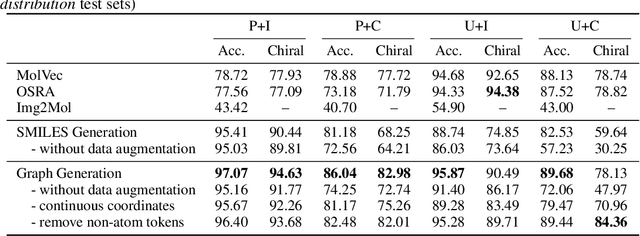
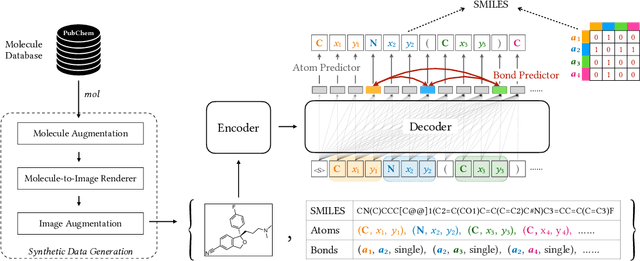
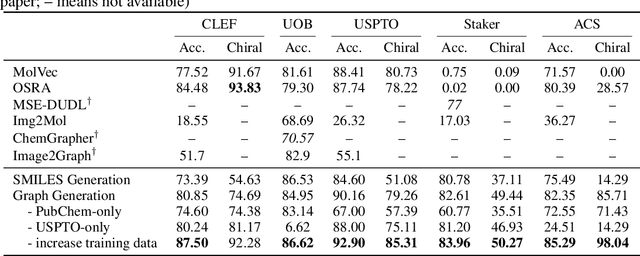
Molecular image recognition is a fundamental task in information extraction from chemistry literature. Previous data-driven models formulate it as an image-to-sequence task, to generate a sequential representation of the molecule (e.g. SMILES string) from its graphical representation. Although they perform adequately on certain benchmarks, these models are not robust in real-world situations, where molecular images differ in style, quality, and chemical patterns. In this paper, we propose a novel graph generation approach that explicitly predicts atoms and bonds, along with their geometric layouts, to construct the molecular graph. We develop data augmentation strategies for molecules and images to increase the robustness of our model against domain shifts. Our model is flexible to incorporate chemistry constraints, and produces more interpretable predictions than SMILES. In experiments on both synthetic and realistic molecular images, our model significantly outperforms previous models, achieving 84-93% accuracy on five benchmarks. We also conduct human evaluation and show that our model reduces the time for a chemist to extract molecular structures from images by roughly 50%.
Time-aware Graph Neural Networks for Entity Alignment between Temporal Knowledge Graphs
Mar 13, 2022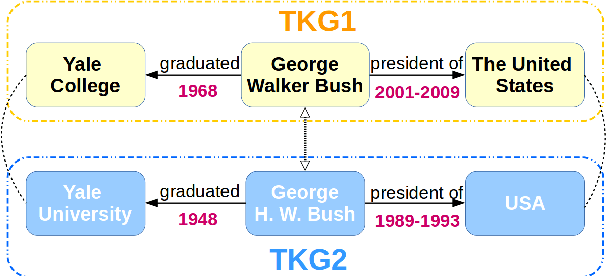

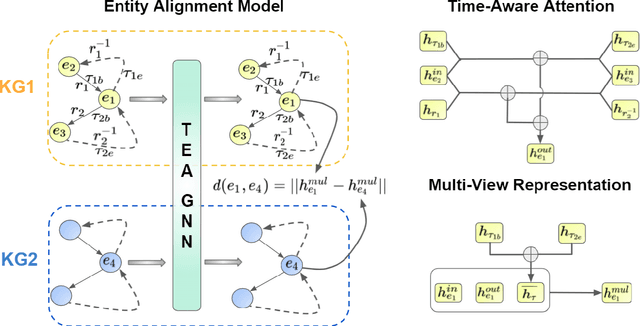
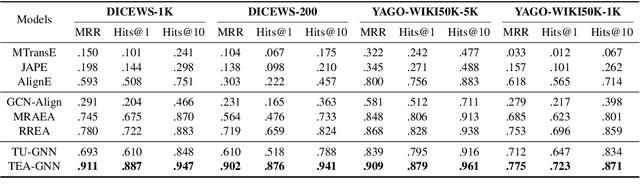
Entity alignment aims to identify equivalent entity pairs between different knowledge graphs (KGs). Recently, the availability of temporal KGs (TKGs) that contain time information created the need for reasoning over time in such TKGs. Existing embedding-based entity alignment approaches disregard time information that commonly exists in many large-scale KGs, leaving much room for improvement. In this paper, we focus on the task of aligning entity pairs between TKGs and propose a novel Time-aware Entity Alignment approach based on Graph Neural Networks (TEA-GNN). We embed entities, relations and timestamps of different KGs into a vector space and use GNNs to learn entity representations. To incorporate both relation and time information into the GNN structure of our model, we use a time-aware attention mechanism which assigns different weights to different nodes with orthogonal transformation matrices computed from embeddings of the relevant relations and timestamps in a neighborhood. Experimental results on multiple real-world TKG datasets show that our method significantly outperforms the state-of-the-art methods due to the inclusion of time information.
Heterogeneous Graph Collaborative Filtering using Textual Information
Oct 04, 2020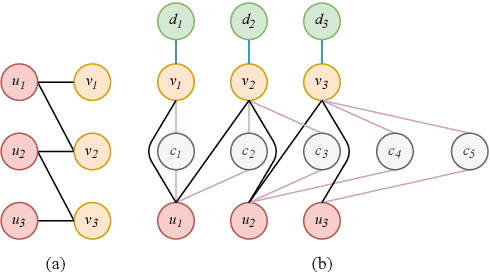
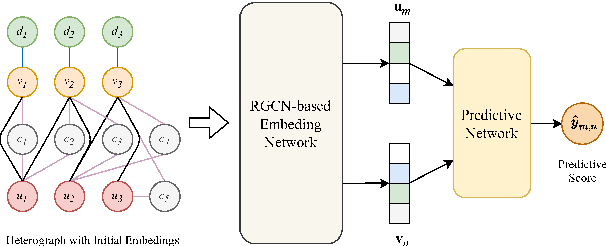

Due to the development of graph neural network models, like graph convolutional network (GCN), graph-based representation learning methods have made great progress in recommender systems. However, the data sparsity is still a challenging problem that graph-based methods are confronted with. Recent works try to solve this problem by utilizing the side information. In this paper, we introduce easily accessible textual information to alleviate the negative effects of data sparsity. Specifically, to incorporate with rich textual knowledge, we utilize a pre-trained context-awareness natural language processing model to initialize the embeddings of text nodes. By a GCN-based node information propagation on the constructed heterogeneous graph, the embeddings of users and items can finally be enriched by the textual knowledge. The matching function used by most graph-based representation learning methods is the inner product, this linear operation can not fit complex semantics well. We design a predictive network, which can combine the graph-based representation learning with the matching function learning, and demonstrate that this predictive architecture can gain significant improvements. Extensive experiments are conducted on three public datasets and the results verify the superior performance of our method over several baselines.
Deep Learning-based Automatic Player Identification and Logging in American Football Videos
Apr 26, 2022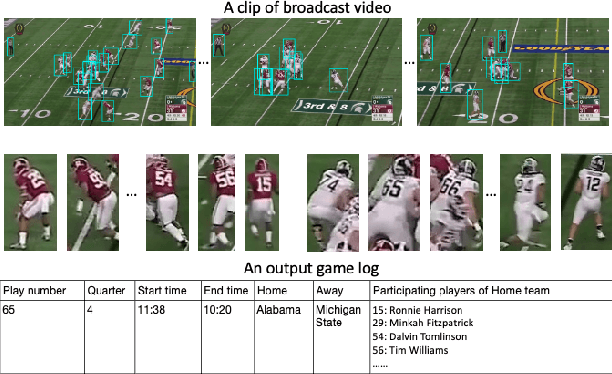
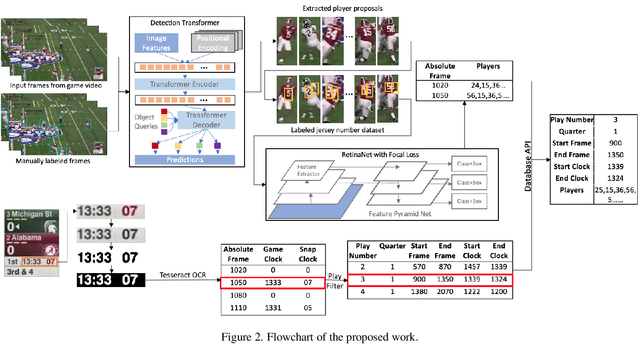
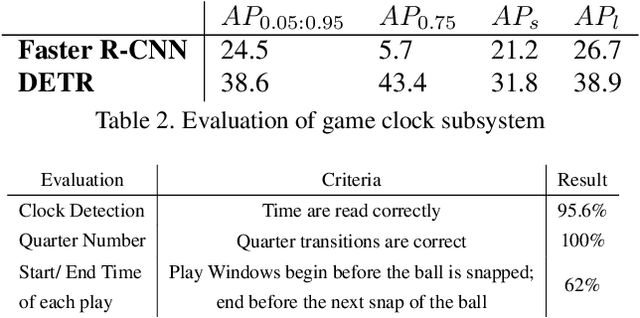

American football games attract significant worldwide attention every year. Game analysis systems generate crucial information that can help analyze the games by providing fans and coaches with a convenient means to track and evaluate player performance. Identifying participating players in each play is also important for the video indexing of player participation per play. Processing football game video presents challenges such as crowded setting, distorted objects, and imbalanced data for identifying players, especially jersey numbers. In this work, we propose a deep learning-based football video analysis system to automatically track players and index their participation per play. It is a multi-stage network design to highlight area of interest and identify jersey number information with high accuracy. First, we utilize an object detection network, a detection transformer, to tackle the player detection problem in crowded context. Second, we identify players using jersey number recognition with a secondary convolutional neural network, then synchronize it with a game clock subsystem. Finally, the system outputs a complete log in a database for play indexing. We demonstrate the effectiveness and reliability of player identification and the logging system by analyzing the qualitative and quantitative results on football videos. The proposed system shows great potential for implementation in and analysis of football broadcast video.
Reinforcement Learning-driven Information Seeking: A Quantum Probabilistic Approach
Aug 05, 2020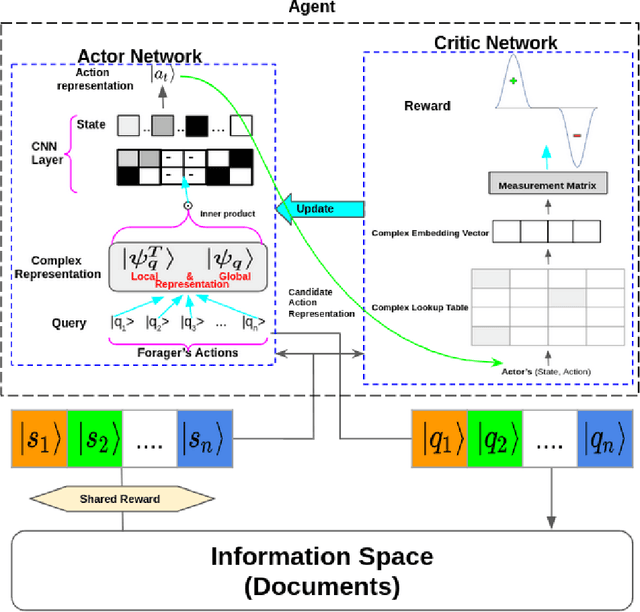
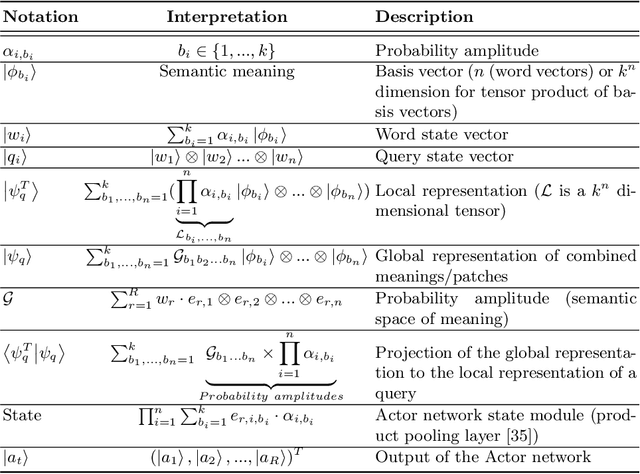
Understanding an information forager's actions during interaction is very important for the study of interactive information retrieval. Although information spread in uncertain information space is substantially complex due to the high entanglement of users interacting with information objects~(text, image, etc.). However, an information forager, in general, accompanies a piece of information (information diet) while searching (or foraging) alternative contents, typically subject to decisive uncertainty. Such types of uncertainty are analogous to measurements in quantum mechanics which follow the uncertainty principle. In this paper, we discuss information seeking as a reinforcement learning task. We then present a reinforcement learning-based framework to model forager exploration that treats the information forager as an agent to guide their behaviour. Also, our framework incorporates the inherent uncertainty of the foragers' action using the mathematical formalism of quantum mechanics.
Speaker Diarization with Lexical Information
Apr 13, 2020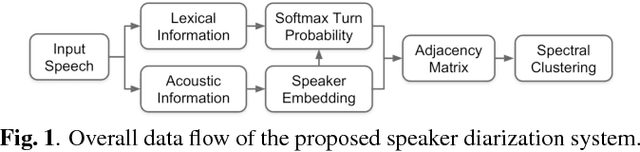
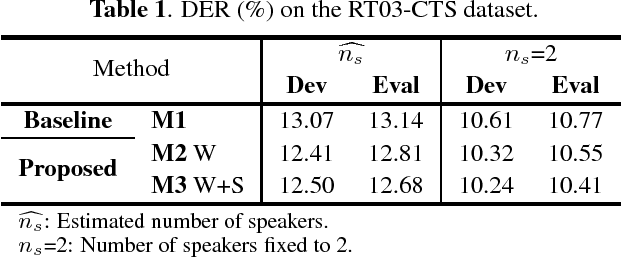
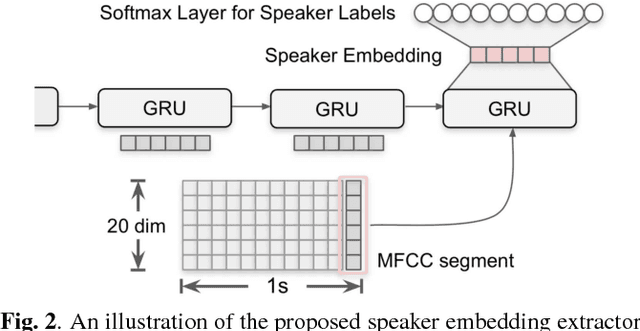
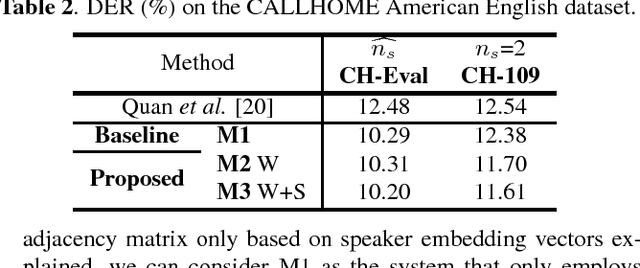
This work presents a novel approach for speaker diarization to leverage lexical information provided by automatic speech recognition. We propose a speaker diarization system that can incorporate word-level speaker turn probabilities with speaker embeddings into a speaker clustering process to improve the overall diarization accuracy. To integrate lexical and acoustic information in a comprehensive way during clustering, we introduce an adjacency matrix integration for spectral clustering. Since words and word boundary information for word-level speaker turn probability estimation are provided by a speech recognition system, our proposed method works without any human intervention for manual transcriptions. We show that the proposed method improves diarization performance on various evaluation datasets compared to the baseline diarization system using acoustic information only in speaker embeddings.
Weakly-supervised Temporal Path Representation Learning with Contrastive Curriculum Learning -- Extended Version
Apr 15, 2022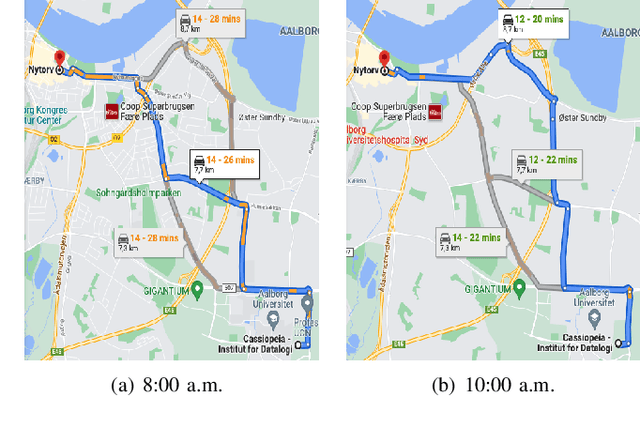
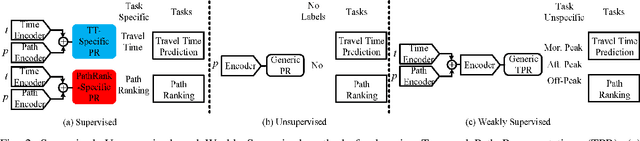
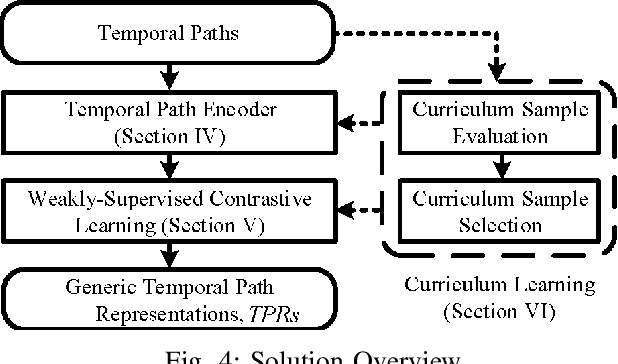
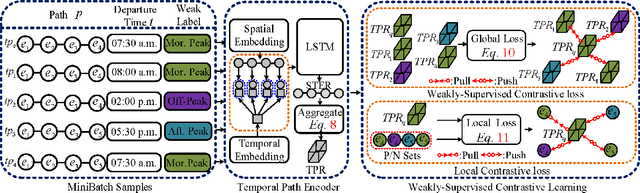
In step with the digitalization of transportation, we are witnessing a growing range of path-based smart-city applications, e.g., travel-time estimation and travel path ranking. A temporal path(TP) that includes temporal information, e.g., departure time, into the path is fundamental to enable such applications. In this setting, it is essential to learn generic temporal path representations(TPRs) that consider spatial and temporal correlations simultaneously and that can be used in different applications, i.e., downstream tasks. Existing methods fail to achieve the goal since (i) supervised methods require large amounts of task-specific labels when training and thus fail to generalize the obtained TPRs to other tasks; (ii) through unsupervised methods can learn generic representations, they disregard the temporal aspect, leading to sub-optimal results. To contend with the limitations of existing solutions, we propose a Weakly-Supervised Contrastive (WSC) learning model. We first propose a temporal path encoder that encodes both the spatial and temporal information of a temporal path into a TPR. To train the encoder, we introduce weak labels that are easy and inexpensive to obtain and are relevant to different tasks, e.g., temporal labels indicating peak vs. off-peak hours from departure times. Based on the weak labels, we construct meaningful positive and negative temporal path samples by considering both spatial and temporal information, which facilities training the encoder using contrastive learning by pulling closer to the positive samples' representations while pushing away the negative samples' representations. To better guide contrastive learning, we propose a learning strategy based on Curriculum Learning such that the learning performs from easy to hard training instances. Experiments studies verify the effectiveness of the proposed method.
LibriS2S: A German-English Speech-to-Speech Translation Corpus
Apr 22, 2022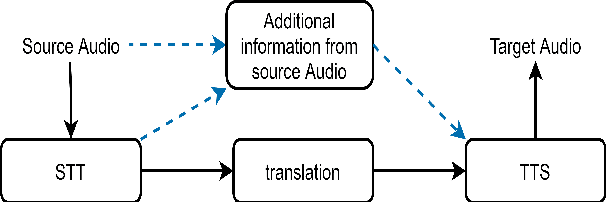
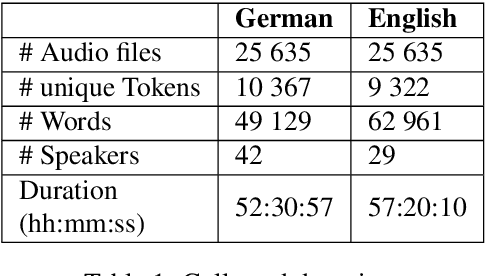
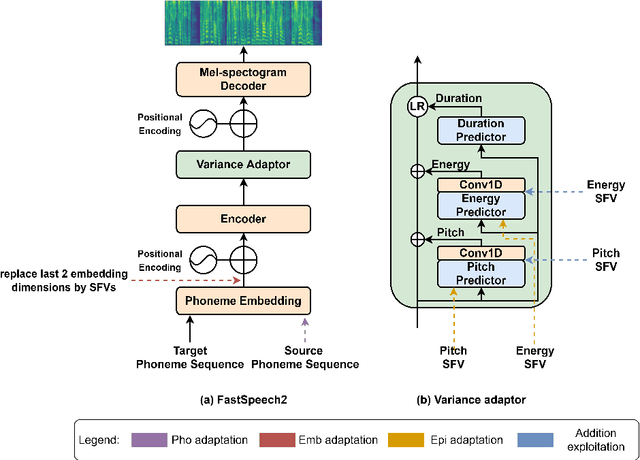
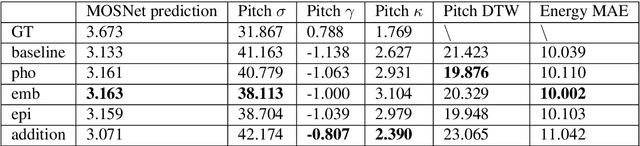
Recently, we have seen an increasing interest in the area of speech-to-text translation. This has led to astonishing improvements in this area. In contrast, the activities in the area of speech-to-speech translation is still limited, although it is essential to overcome the language barrier. We believe that one of the limiting factors is the availability of appropriate training data. We address this issue by creating LibriS2S, to our knowledge the first publicly available speech-to-speech training corpus between German and English. For this corpus, we used independently created audio for German and English leading to an unbiased pronunciation of the text in both languages. This allows the creation of a new text-to-speech and speech-to-speech translation model that directly learns to generate the speech signal based on the pronunciation of the source language. Using this created corpus, we propose Text-to-Speech models based on the example of the recently proposed FastSpeech 2 model that integrates source language information. We do this by adapting the model to take information such as the pitch, energy or transcript from the source speech as additional input.
What Knowledge Gets Distilled in Knowledge Distillation?
May 31, 2022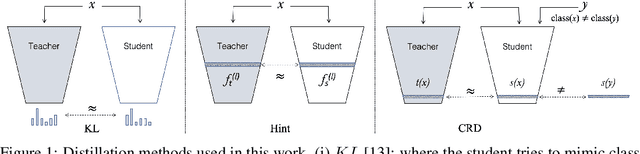
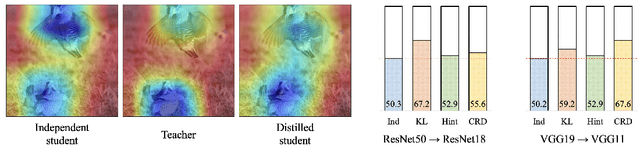
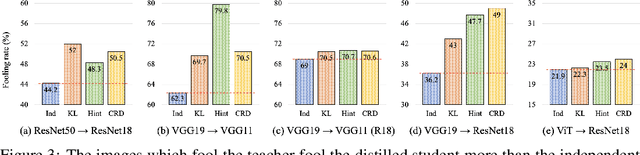
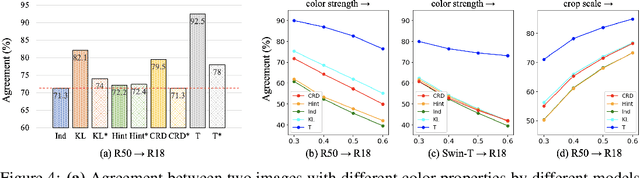
Knowledge distillation aims to transfer useful information from a teacher network to a student network, with the primary goal of improving the student's performance for the task at hand. Over the years, there has a been a deluge of novel techniques and use cases of knowledge distillation. Yet, despite the various improvements, there seems to be a glaring gap in the community's fundamental understanding of the process. Specifically, what is the knowledge that gets distilled in knowledge distillation? In other words, in what ways does the student become similar to the teacher? Does it start to localize objects in the same way? Does it get fooled by the same adversarial samples? Does its data invariance properties become similar? Our work presents a comprehensive study to try to answer these questions and more. Our results, using image classification as a case study and three state-of-the-art knowledge distillation techniques, show that knowledge distillation methods can indeed indirectly distill other kinds of properties beyond improving task performance. By exploring these questions, we hope for our work to provide a clearer picture of what happens during knowledge distillation.