 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MetaInfoNet: Learning Task-Guided Information for Sample Reweighting
Dec 09, 2020
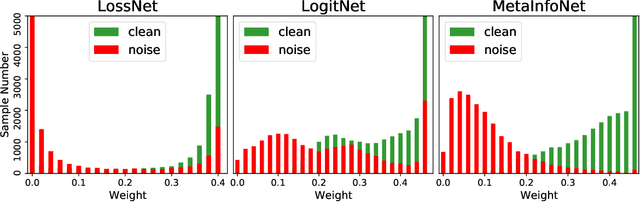

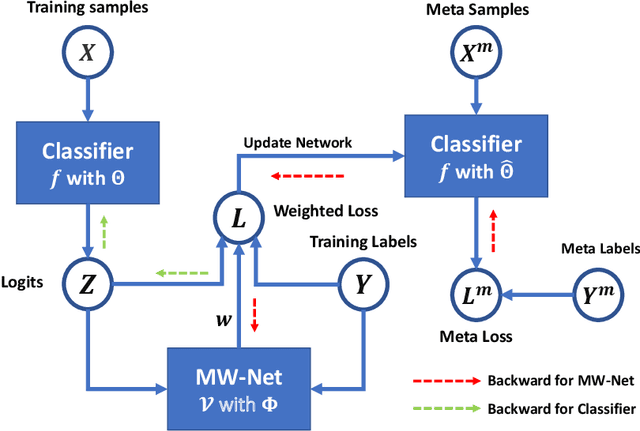
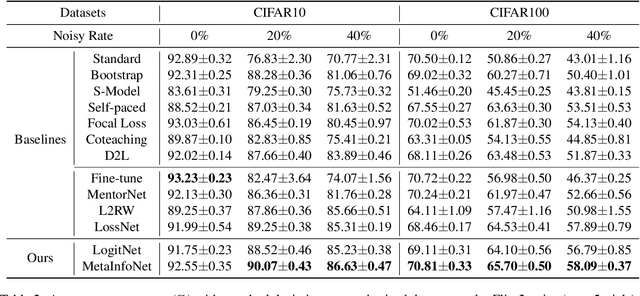
Deep neural networks have been shown to easily overfit to biased training data with label noise or class imbalance. Meta-learning algorithms are commonly designed to alleviate this issue in the form of sample reweighting, by learning a meta weighting network that takes training losses as inputs to generate sample weights. In this paper, we advocate that choosing proper inputs for the meta weighting network is crucial for desired sample weights in a specific task, while training loss is not always the correct answer. In view of this, we propose a novel meta-learning algorithm, MetaInfoNet, which automatically learns effective representations as inputs for the meta weighting network by emphasizing task-related information with an information bottleneck strategy. Extensive experimental results on benchmark datasets with label noise or class imbalance validate that MetaInfoNet is superior to many state-of-the-art methods.
Few-shot One-class Domain Adaptation Based on Frequency for Iris Presentation Attack Detection
Apr 01, 2022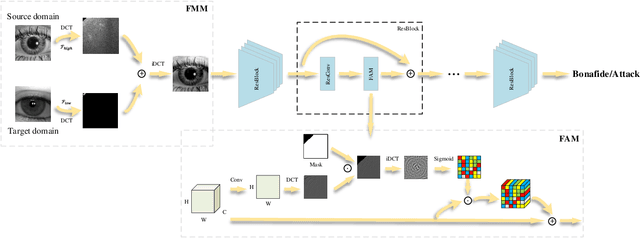
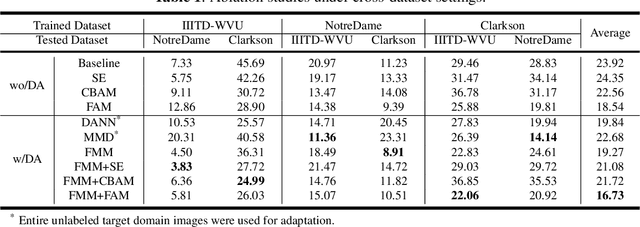
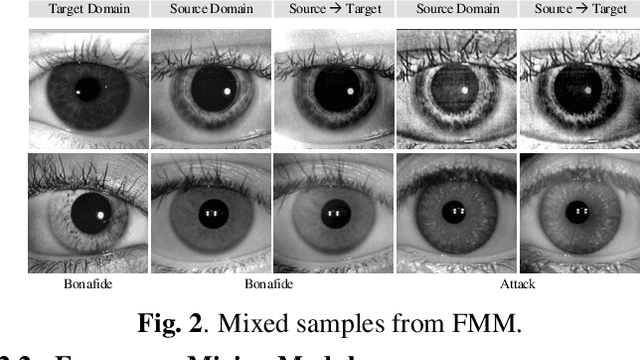
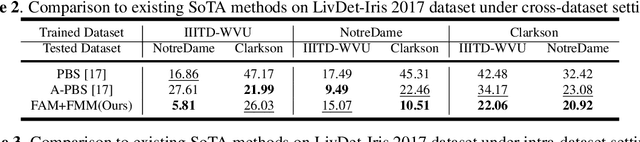
Iris presentation attack detection (PAD) has achieved remarkable success to ensure the reliability and security of iris recognition systems. Most existing methods exploit discriminative features in the spatial domain and report outstanding performance under intra-dataset settings. However, the degradation of performance is inevitable under cross-dataset settings, suffering from domain shift. In consideration of real-world applications, a small number of bonafide samples are easily accessible. We thus define a new domain adaptation setting called Few-shot One-class Domain Adaptation (FODA), where adaptation only relies on a limited number of target bonafide samples. To address this problem, we propose a novel FODA framework based on the expressive power of frequency information. Specifically, our method integrates frequency-related information through two proposed modules. Frequency-based Attention Module (FAM) aggregates frequency information into spatial attention and explicitly emphasizes high-frequency fine-grained features. Frequency Mixing Module (FMM) mixes certain frequency components to generate large-scale target-style samples for adaptation with limited target bonafide samples. Extensive experiments on LivDet-Iris 2017 dataset demonstrate the proposed method achieves state-of-the-art or competitive performance under both cross-dataset and intra-dataset settings.
Invertible Mask Network for Face Privacy-Preserving
Apr 19, 2022
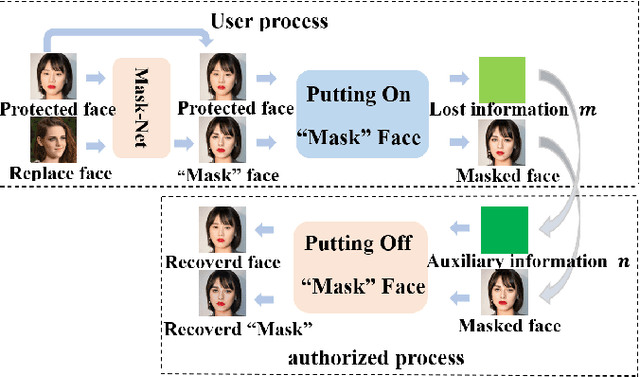
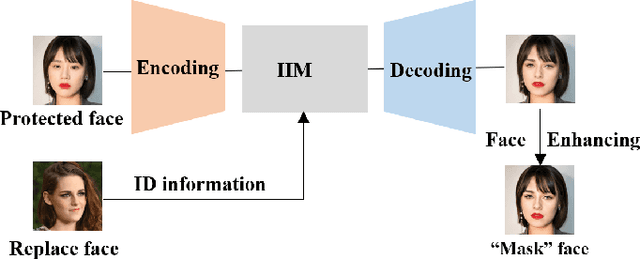
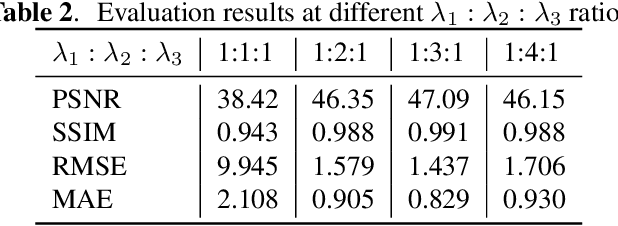
Face privacy-preserving is one of the hotspots that arises dramatic interests of research. However, the existing face privacy-preserving methods aim at causing the missing of semantic information of face and cannot preserve the reusability of original facial information. To achieve the naturalness of the processed face and the recoverability of the original protected face, this paper proposes face privacy-preserving method based on Invertible "Mask" Network (IMN). In IMN, we introduce a Mask-net to generate "Mask" face firstly. Then, put the "Mask" face onto the protected face and generate the masked face, in which the masked face is indistinguishable from "Mask" face. Finally, "Mask" face can be put off from the masked face and obtain the recovered face to the authorized users, in which the recovered face is visually indistinguishable from the protected face. The experimental results show that the proposed method can not only effectively protect the privacy of the protected face, but also almost perfectly recover the protected face from the masked face.
Collaborative Intelligence Orchestration: Inconsistency-Based Fusion of Semi-Supervised Learning and Active Learning
Jun 07, 2022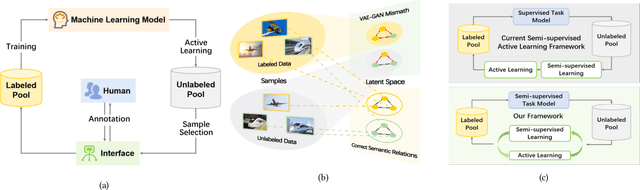
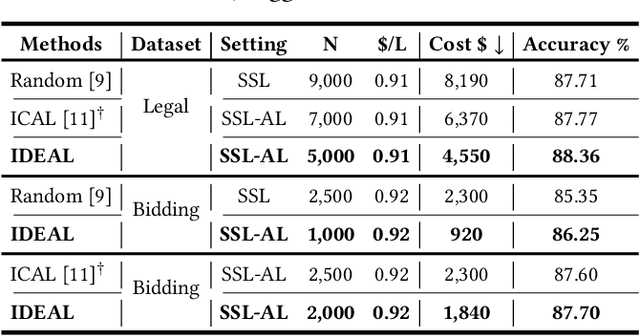
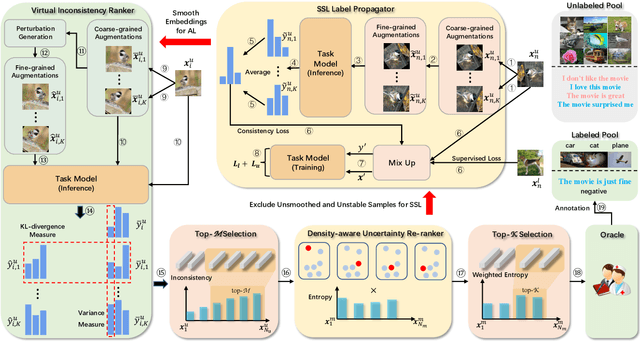
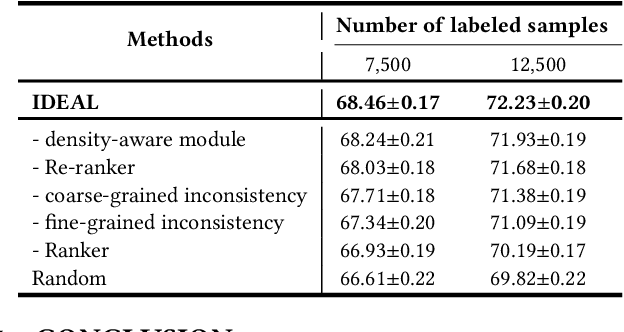
While annotating decent amounts of data to satisfy sophisticated learning models can be cost-prohibitive for many real-world applications. Active learning (AL) and semi-supervised learning (SSL) are two effective, but often isolated, means to alleviate the data-hungry problem. Some recent studies explored the potential of combining AL and SSL to better probe the unlabeled data. However, almost all these contemporary SSL-AL works use a simple combination strategy, ignoring SSL and AL's inherent relation. Further, other methods suffer from high computational costs when dealing with large-scale, high-dimensional datasets. Motivated by the industry practice of labeling data, we propose an innovative Inconsistency-based virtual aDvErsarial Active Learning (IDEAL) algorithm to further investigate SSL-AL's potential superiority and achieve mutual enhancement of AL and SSL, i.e., SSL propagates label information to unlabeled samples and provides smoothed embeddings for AL, while AL excludes samples with inconsistent predictions and considerable uncertainty for SSL. We estimate unlabeled samples' inconsistency by augmentation strategies of different granularities, including fine-grained continuous perturbation exploration and coarse-grained data transformations. Extensive experiments, in both text and image domains, validate the effectiveness of the proposed algorithm, comparing it against state-of-the-art baselines. Two real-world case studies visualize the practical industrial value of applying and deploying the proposed data sampling algorithm.
SUSing: SU-net for Singing Voice Synthesis
May 24, 2022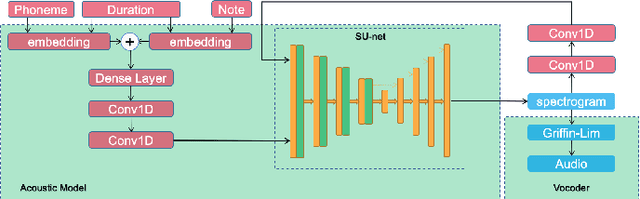
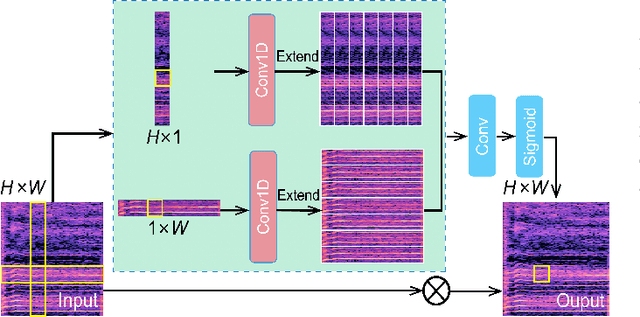
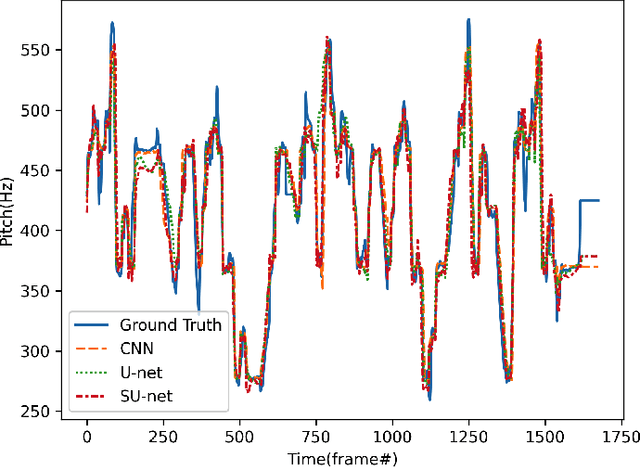
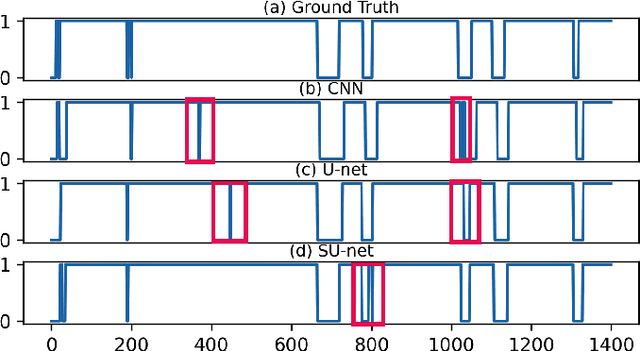
Singing voice synthesis is a generative task that involves multi-dimensional control of the singing model, including lyrics, pitch, and duration, and includes the timbre of the singer and singing skills such as vibrato. In this paper, we proposed SU-net for singing voice synthesis named SUSing. Synthesizing singing voice is treated as a translation task between lyrics and music score and spectrum. The lyrics and music score information is encoded into a two-dimensional feature representation through the convolution layer. The two-dimensional feature and its frequency spectrum are mapped to the target spectrum in an autoregressive manner through a SU-net network. Within the SU-net the stripe pooling method is used to replace the alternate global pooling method to learn the vertical frequency relationship in the spectrum and the changes of frequency in the time domain. The experimental results on the public dataset Kiritan show that the proposed method can synthesize more natural singing voices.
Separating Content from Speaker Identity in Speech for the Assessment of Cognitive Impairments
Mar 21, 2022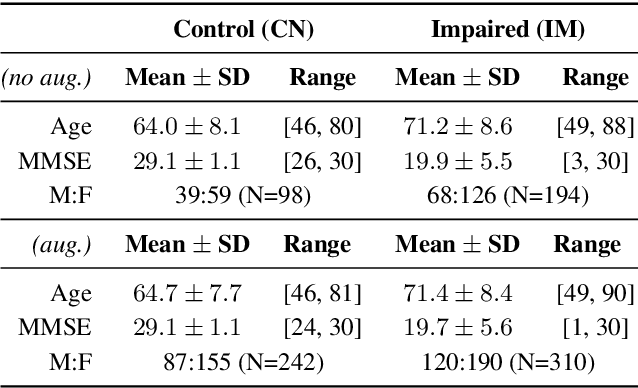
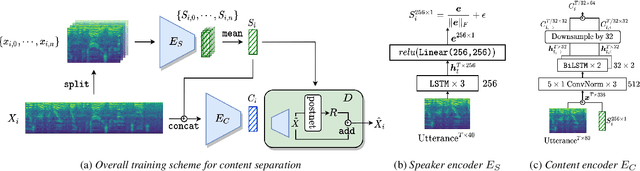
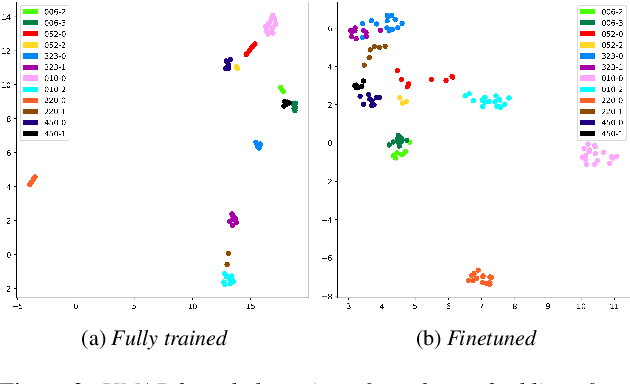
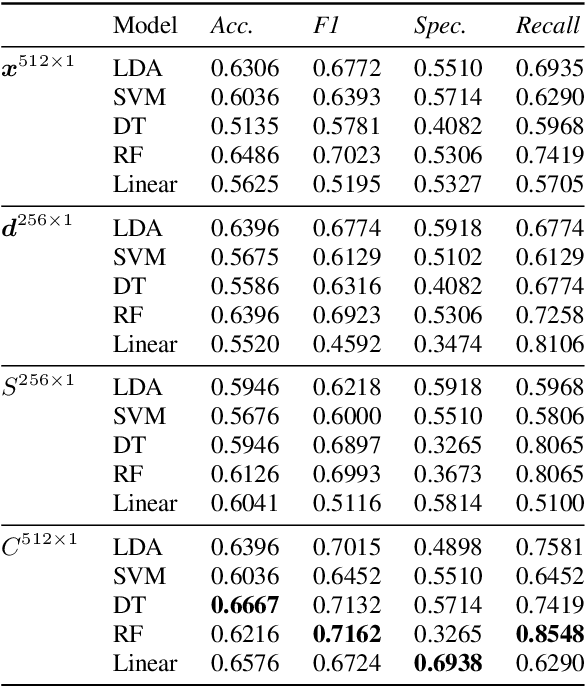
Deep speaker embeddings have been shown effective for assessing cognitive impairments aside from their original purpose of speaker verification. However, the research found that speaker embeddings encode speaker identity and an array of information, including speaker demographics, such as sex and age, and speech contents to an extent, which are known confounders in the assessment of cognitive impairments. In this paper, we hypothesize that content information separated from speaker identity using a framework for voice conversion is more effective for assessing cognitive impairments and train simple classifiers for the comparative analysis on the DementiaBank Pitt Corpus. Our results show that while content embeddings have an advantage over speaker embeddings for the defined problem, further experiments show their effectiveness depends on information encoded in speaker embeddings due to the inherent design of the architecture used for extracting contents.
Robust Face-Swap Detection Based on 3D Facial Shape Information
Apr 28, 2021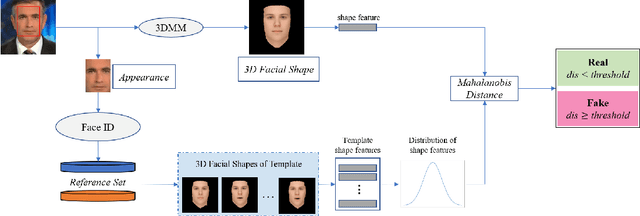

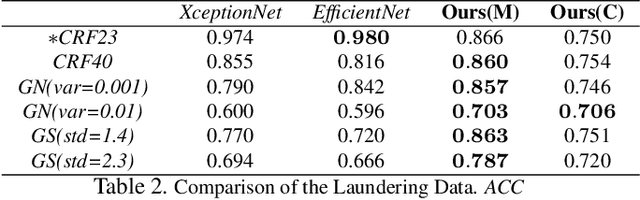
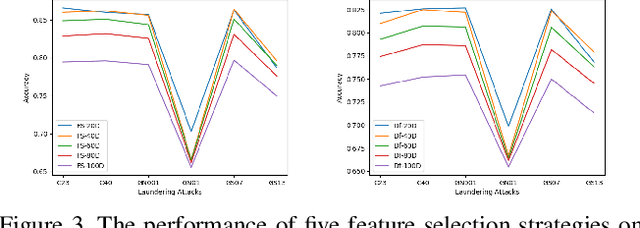
Maliciously-manipulated images or videos - so-called deep fakes - especially face-swap images and videos have attracted more and more malicious attackers to discredit some key figures. Previous pixel-level artifacts based detection techniques always focus on some unclear patterns but ignore some available semantic clues. Therefore, these approaches show weak interpretability and robustness. In this paper, we propose a biometric information based method to fully exploit the appearance and shape feature for face-swap detection of key figures. The key aspect of our method is obtaining the inconsistency of 3D facial shape and facial appearance, and the inconsistency based clue offers natural interpretability for the proposed face-swap detection method. Experimental results show the superiority of our method in robustness on various laundering and cross-domain data, which validates the effectiveness of the proposed method.
Cerebral Palsy Prediction with Frequency Attention Informed Graph Convolutional Networks
Apr 23, 2022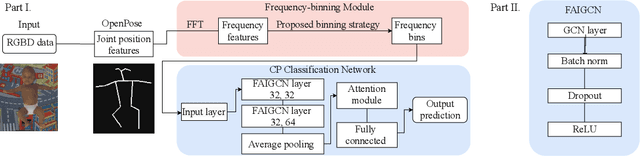

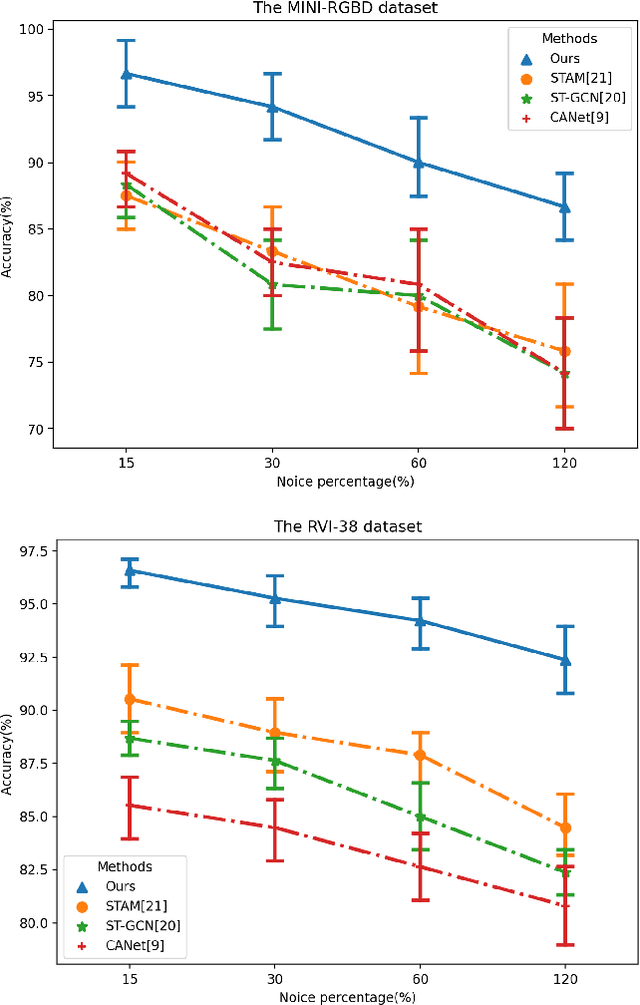

Early diagnosis and intervention are clinically considered the paramount part of treating cerebral palsy (CP), so it is essential to design an efficient and interpretable automatic prediction system for CP. We highlight a significant difference between CP infants' frequency of human movement and that of the healthy group, which improves prediction performance. However, the existing deep learning-based methods did not use the frequency information of infants' movement for CP prediction. This paper proposes a frequency attention informed graph convolutional network and validates it on two consumer-grade RGB video datasets, namely MINI-RGBD and RVI-38 datasets. Our proposed frequency attention module aids in improving both classification performance and system interpretability. In addition, we design a frequency-binning method that retains the critical frequency of the human joint position data while filtering the noise. Our prediction performance achieves state-of-the-art research on both datasets. Our work demonstrates the effectiveness of frequency information in supporting the prediction of CP non-intrusively and provides a way for supporting the early diagnosis of CP in the resource-limited regions where the clinical resources are not abundant.
Elucidating Meta-Structures of Noisy Labels in Semantic Segmentation by Deep Neural Networks
Apr 30, 2022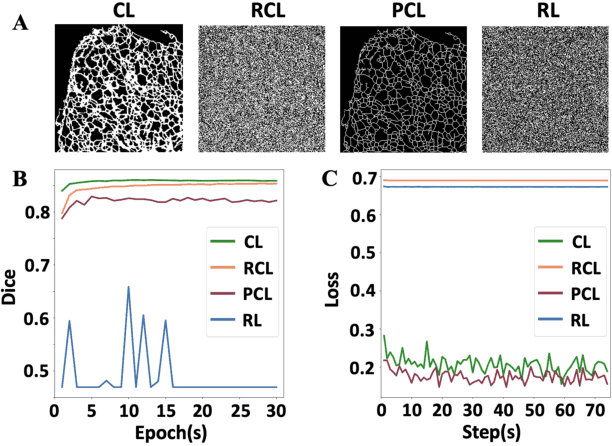

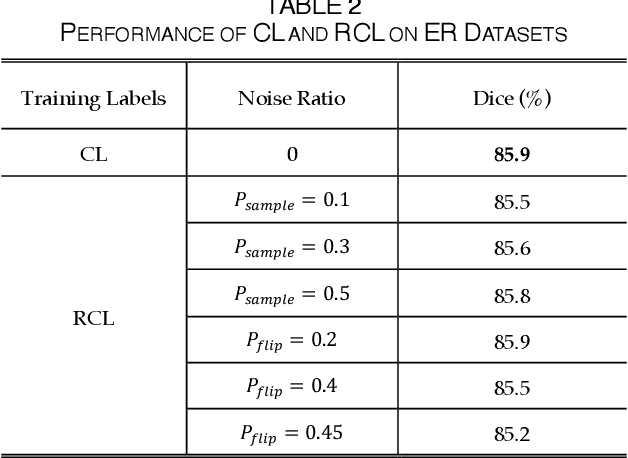

The supervised training of deep neural networks (DNNs) by noisy labels has been studied extensively in image classification but much less in image segmentation. So far, our understanding of the learning behavior of DNNs trained by noisy segmentation labels remains limited. In this study, we address this deficiency in both binary segmentation of biological microscopy images and multi-class segmentation of natural images. We classify segmentation labels according to their noise transition matrices (NTM) and compare performance of DNNs trained by different types of labels. When we randomly sample a small fraction (e.g., 10%) or flipping a large fraction (e.g., 90%) of the ground-truth labels to train DNNs, their segmentation performance remains largely the same. This indicates that DNNs learn structures hidden in labels rather than pixel-level labels per se in their supervised training for semantic segmentation. We call these hidden structures "meta-structures". When we use labels with different perturbations to the meta-structures to train DNNs, their performance in feature extraction and segmentation degrades consistently. In contrast, addition of meta-structure information substantially improves performance of an unsupervised model in binary semantic segmentation. We formulate meta-structures mathematically as spatial density distributions and quantify semantic information of different types of labels, which we find to correlate strongly with ranks of their NTM. We show theoretically and experimentally how this formulation explains key observed learning behavior of DNNs.
NAFSSR: Stereo Image Super-Resolution Using NAFNet
Apr 19, 2022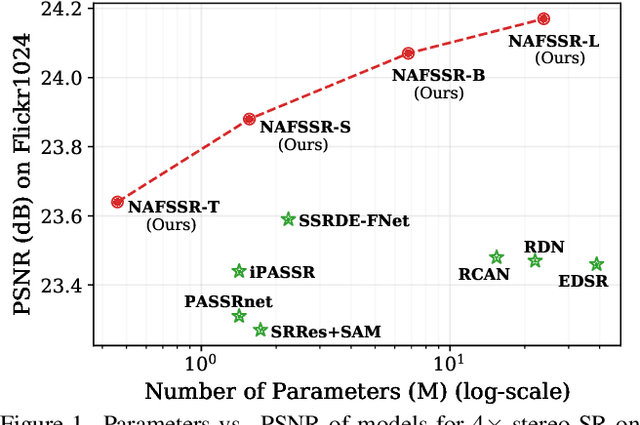
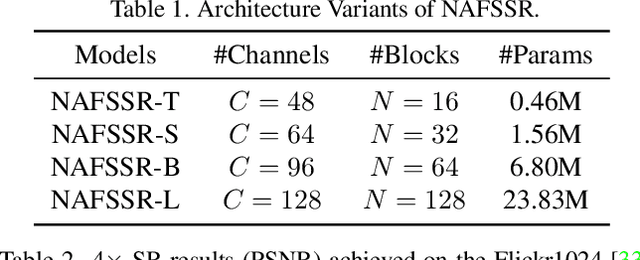
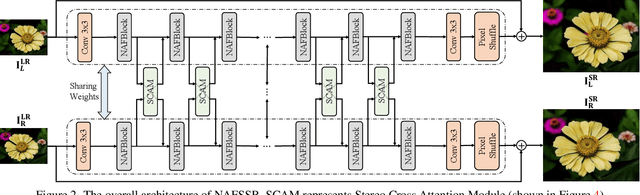
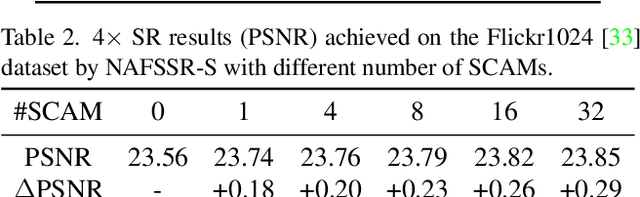
Stereo image super-resolution aims at enhancing the quality of super-resolution results by utilizing the complementary information provided by binocular systems. To obtain reasonable performance, most methods focus on finely designing modules, loss functions, and etc. to exploit information from another viewpoint. This has the side effect of increasing system complexity, making it difficult for researchers to evaluate new ideas and compare methods. This paper inherits a strong and simple image restoration model, NAFNet, for single-view feature extraction and extends it by adding cross attention modules to fuse features between views to adapt to binocular scenarios. The proposed baseline for stereo image super-resolution is noted as NAFSSR. Furthermore, training/testing strategies are proposed to fully exploit the performance of NAFSSR. Extensive experiments demonstrate the effectiveness of our method. In particular, NAFSSR outperforms the state-of-the-art methods on the KITTI 2012, KITTI 2015, Middlebury, and Flickr1024 datasets. With NAFSSR, we won 1st place in the NTIRE 2022 Stereo Image Super-resolution Challenge. Codes and models will be released at https://github.com/megvii-research/NAFNet.