 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Pre-Trained Language Models to Streamline Natural Language Interaction for Self-Tracking
Jun 01, 2022
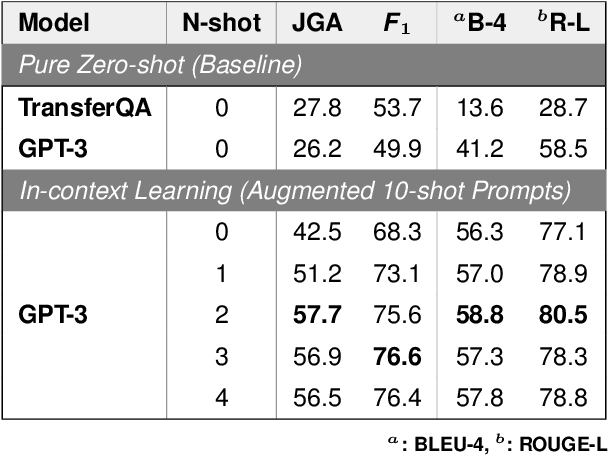
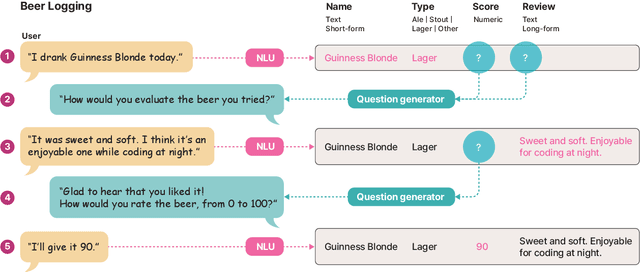
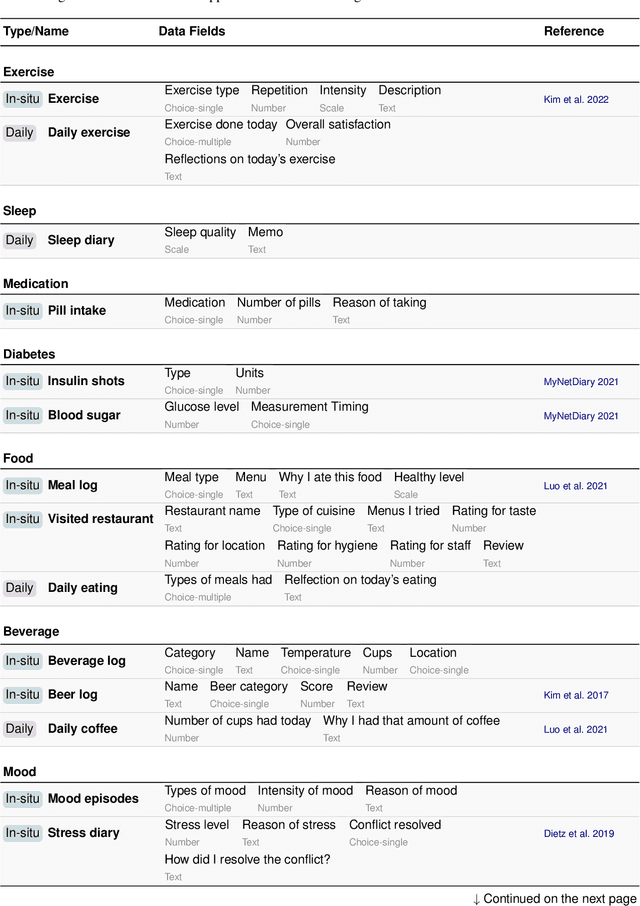
Current natural language interaction for self-tracking tools largely depends on bespoke implementation optimized for a specific tracking theme and data format, which is neither generalizable nor scalable to a tremendous design space of self-tracking. However, training machine learning models in the context of self-tracking is challenging due to the wide variety of tracking topics and data formats. In this paper, we propose a novel NLP task for self-tracking that extracts close- and open-ended information from a retrospective activity log described as a plain text, and a domain-agnostic, GPT-3-based NLU framework that performs this task. The framework augments the prompt using synthetic samples to transform the task into 10-shot learning, to address a cold-start problem in bootstrapping a new tracking topic. Our preliminary evaluation suggests that our approach significantly outperforms the baseline QA models. Going further, we discuss future application domains toward which the NLP and HCI researchers can collaborate.
Distant finetuning with discourse relations for stance classification
Apr 27, 2022
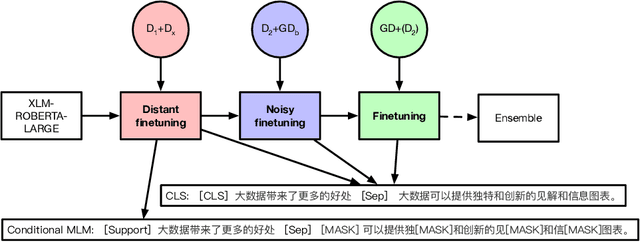

Approaches for the stance classification task, an important task for understanding argumentation in debates and detecting fake news, have been relying on models which deal with individual debate topics. In this paper, in order to train a system independent from topics, we propose a new method to extract data with silver labels from raw text to finetune a model for stance classification. The extraction relies on specific discourse relation information, which is shown as a reliable and accurate source for providing stance information. We also propose a 3-stage training framework where the noisy level in the data used for finetuning decreases over different stages going from the most noisy to the least noisy. Detailed experiments show that the automatically annotated dataset as well as the 3-stage training help improve model performance in stance classification. Our approach ranks 1st among 26 competing teams in the stance classification track of the NLPCC 2021 shared task Argumentative Text Understanding for AI Debater, which confirms the effectiveness of our approach.
XMorpher: Full Transformer for Deformable Medical Image Registration via Cross Attention
Jun 15, 2022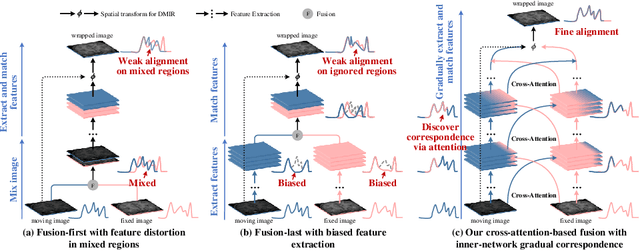
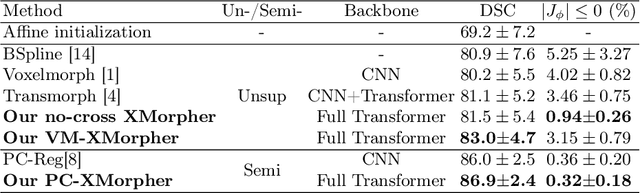
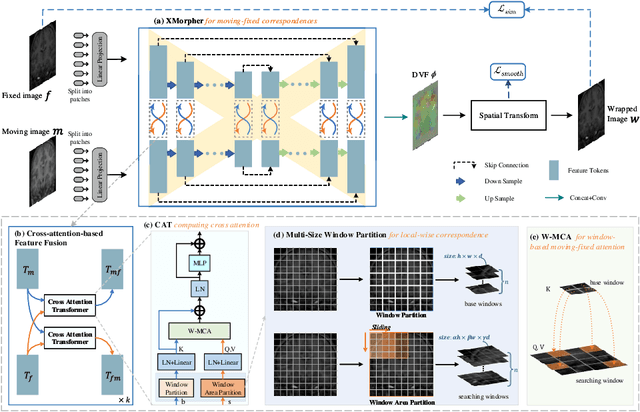
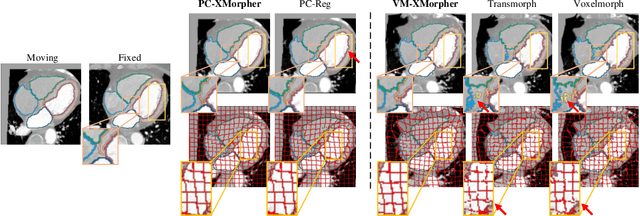
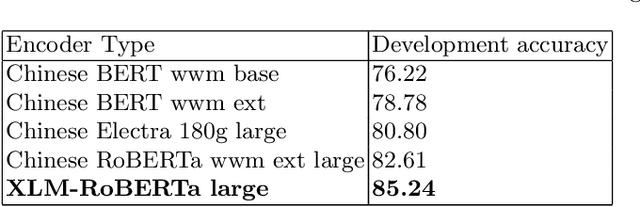
An effective backbone network is important to deep learning-based Deformable Medical Image Registration (DMIR), because it extracts and matches the features between two images to discover the mutual correspondence for fine registration. However, the existing deep networks focus on single image situation and are limited in registration task which is performed on paired images. Therefore, we advance a novel backbone network, XMorpher, for the effective corresponding feature representation in DMIR. 1) It proposes a novel full transformer architecture including dual parallel feature extraction networks which exchange information through cross attention, thus discovering multi-level semantic correspondence while extracting respective features gradually for final effective registration. 2) It advances the Cross Attention Transformer (CAT) blocks to establish the attention mechanism between images which is able to find the correspondence automatically and prompts the features to fuse efficiently in the network. 3) It constrains the attention computation between base windows and searching windows with different sizes, and thus focuses on the local transformation of deformable registration and enhances the computing efficiency at the same time. Without any bells and whistles, our XMorpher gives Voxelmorph 2.8% improvement on DSC , demonstrating its effective representation of the features from the paired images in DMIR. We believe that our XMorpher has great application potential in more paired medical images. Our XMorpher is open on https://github.com/Solemoon/XMorpher
Visual Place Recognition using LiDAR Intensity Information
Mar 17, 2021


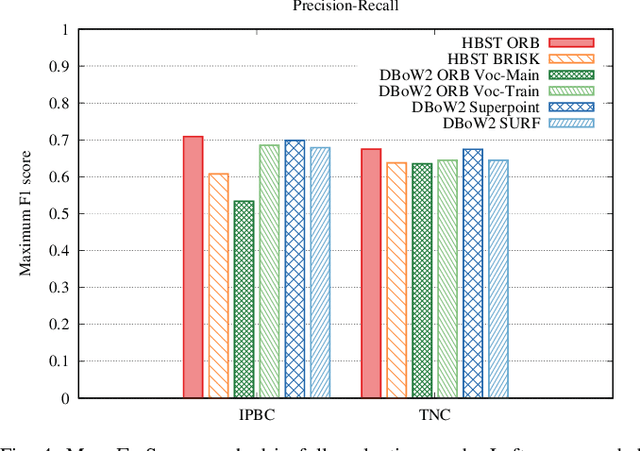
Robots and autonomous systems need to know where they are within a map to navigate effectively. Thus, simultaneous localization and mapping or SLAM is a common building block of robot navigation systems. When building a map via a SLAM system, robots need to re-recognize places to find loop closure and reduce the odometry drift. Image-based place recognition received a lot of attention in computer vision, and in this work, we investigate how such approaches can be used for 3D LiDAR data. Recent LiDAR sensors produce high-resolution 3D scans in combination with comparably stable intensity measurements. Through a cylindrical projection, we can turn this information into a panoramic image. As a result, we can apply techniques from visual place recognition to LiDAR intensity data. The question of how well this approach works in practice has not been answered so far. This paper provides an analysis of how such visual techniques can be with LiDAR data, and we provide an evaluation on different datasets. Our results suggest that this form of place recognition is possible and an effective means for determining loop closures.
FakeFlow: Fake News Detection by Modeling the Flow of Affective Information
Jan 24, 2021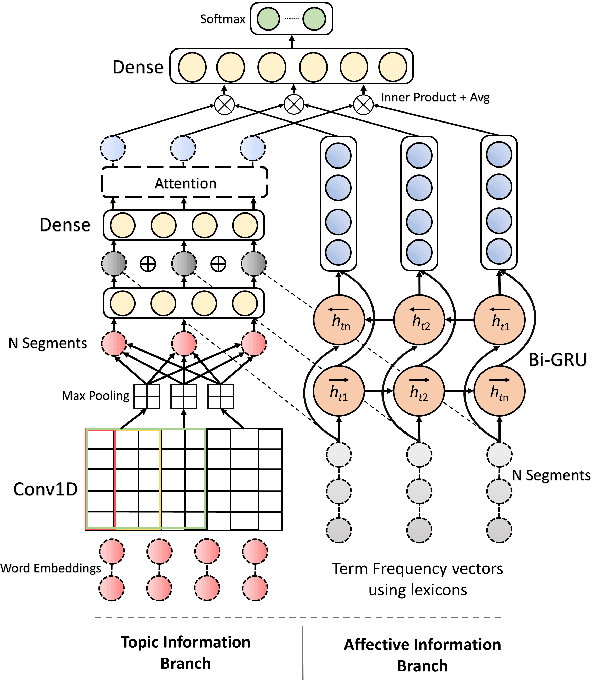

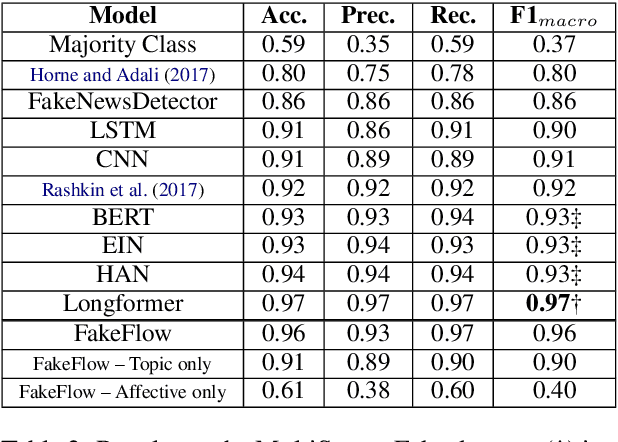
Fake news articles often stir the readers' attention by means of emotional appeals that arouse their feelings. Unlike in short news texts, authors of longer articles can exploit such affective factors to manipulate readers by adding exaggerations or fabricating events, in order to affect the readers' emotions. To capture this, we propose in this paper to model the flow of affective information in fake news articles using a neural architecture. The proposed model, FakeFlow, learns this flow by combining topic and affective information extracted from text. We evaluate the model's performance with several experiments on four real-world datasets. The results show that FakeFlow achieves superior results when compared against state-of-the-art methods, thus confirming the importance of capturing the flow of the affective information in news articles.
Variational Meta Reinforcement Learning for Social Robotics
Jun 23, 2022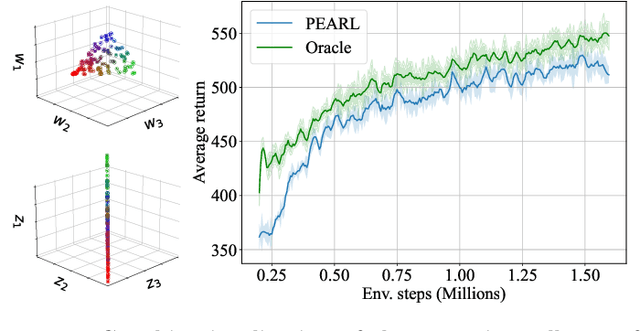
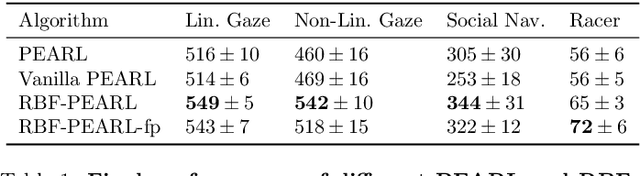
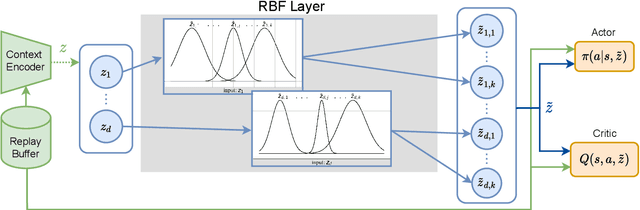

With the increasing presence of robots in our every-day environments, improving their social skills is of utmost importance. Nonetheless, social robotics still faces many challenges. One bottleneck is that robotic behaviors need to be often adapted as social norms depend strongly on the environment. For example, a robot should navigate more carefully around patients in a hospital compared to workers in an office. In this work, we investigate meta-reinforcement learning (meta-RL) as a potential solution. Here, robot behaviors are learned via reinforcement learning where a reward function needs to be chosen so that the robot learns an appropriate behavior for a given environment. We propose to use a variational meta-RL procedure that quickly adapts the robots' behavior to new reward functions. As a result, given a new environment different reward functions can be quickly evaluated and an appropriate one selected. The procedure learns a vectorized representation for reward functions and a meta-policy that can be conditioned on such a representation. Given observations from a new reward function, the procedure identifies its representation and conditions the meta-policy to it. While investigating the procedures' capabilities, we realized that it suffers from posterior collapse where only a subset of the dimensions in the representation encode useful information resulting in a reduced performance. Our second contribution, a radial basis function (RBF) layer, partially mitigates this negative effect. The RBF layer lifts the representation to a higher dimensional space, which is more easily exploitable for the meta-policy. We demonstrate the interest of the RBF layer and the usage of meta-RL for social robotics on four robotic simulation tasks.
Two-Timescale Optimization for Intelligent Reflecting Surface-Assisted MIMO Transmission in Fast-Changing Channels
Jun 15, 2022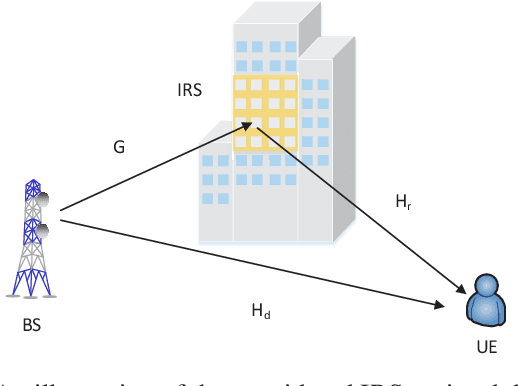
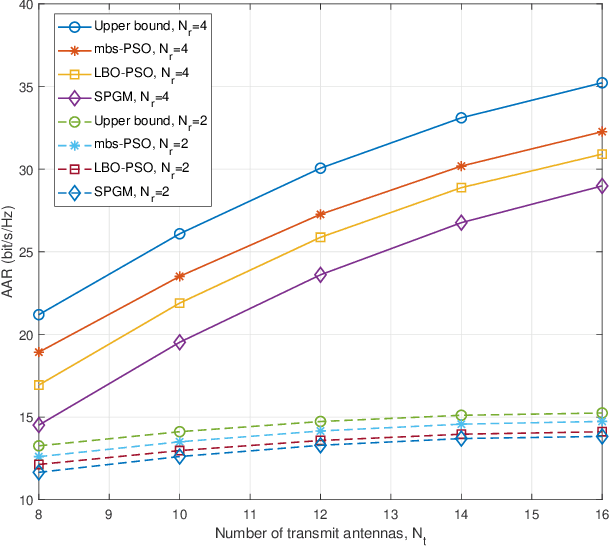
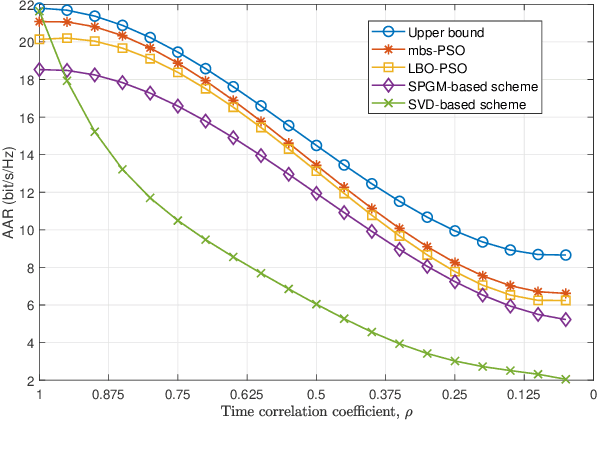
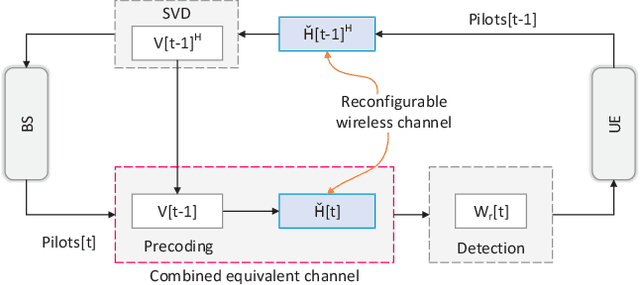
The application of intelligent reflecting surface (IRS) depends on the knowledge of channel state information (CSI), and has been hindered by the heavy overhead of channel training, estimation, and feedback in fast-changing channels. This paper presents a new two-timescale beamforming approach to maximizing the average achievable rate (AAR) of IRS-assisted MIMO systems, where the IRS is configured relatively infrequently based on statistical CSI (S-CSI) and the base station precoder and power allocation are updated frequently based on quickly outdated instantaneous CSI (I-CSI). The key idea is that we first reveal the optimal small-timescale power allocation based on outdated I-CSI yields a water-filling structure. Given the optimal power allocation, a new mini-batch sampling (mbs)- based particle swarm optimization (PSO) algorithm is developed to optimize the large-timescale IRS configuration with reduced channel samples. Another important aspect is that we develop a model-driven PSO algorithm to optimize the IRS configuration, which maximizes a lower bound of the AAR by only using the S-CSI and eliminates the need of channel samples. The modeldriven PSO serves as a dependable lower bound for the mbs-PSO. Simulations corroborate the superiority of the new two-timescale beamforming strategy to its alternatives in terms of the AAR and efficiency, with the benefits of the IRS demonstrated.
Optical Remote Sensing Image Understanding with Weak Supervision: Concepts, Methods, and Perspectives
Apr 18, 2022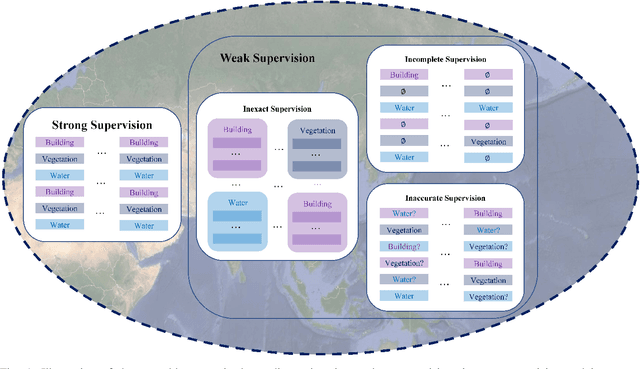
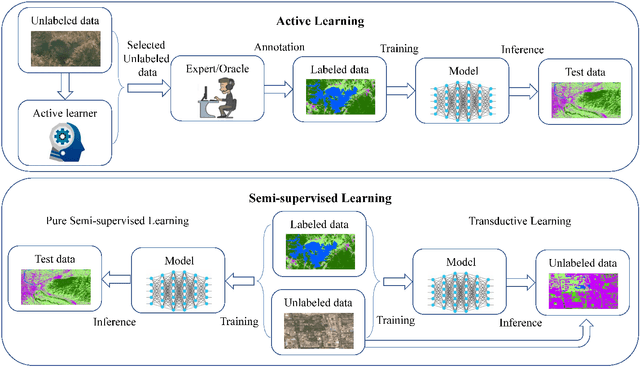
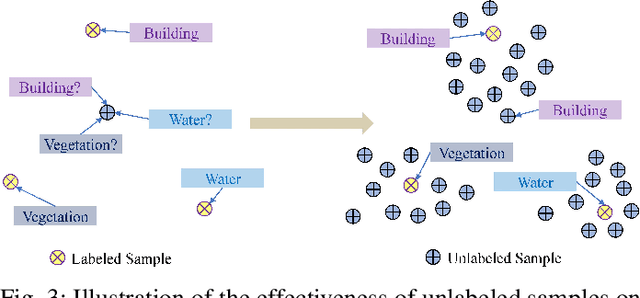

In recent years, supervised learning has been widely used in various tasks of optical remote sensing image understanding, including remote sensing image classification, pixel-wise segmentation, change detection, and object detection. The methods based on supervised learning need a large amount of high-quality training data and their performance highly depends on the quality of the labels. However, in practical remote sensing applications, it is often expensive and time-consuming to obtain large-scale data sets with high-quality labels, which leads to a lack of sufficient supervised information. In some cases, only coarse-grained labels can be obtained, resulting in the lack of exact supervision. In addition, the supervised information obtained manually may be wrong, resulting in a lack of accurate supervision. Therefore, remote sensing image understanding often faces the problems of incomplete, inexact, and inaccurate supervised information, which will affect the breadth and depth of remote sensing applications. In order to solve the above-mentioned problems, researchers have explored various tasks in remote sensing image understanding under weak supervision. This paper summarizes the research progress of weakly supervised learning in the field of remote sensing, including three typical weakly supervised paradigms: 1) Incomplete supervision, where only a subset of training data is labeled; 2) Inexact supervision, where only coarse-grained labels of training data are given; 3) Inaccurate supervision, where the labels given are not always true on the ground.
Generative Myocardial Motion Tracking via Latent Space Exploration with Biomechanics-informed Prior
Jun 08, 2022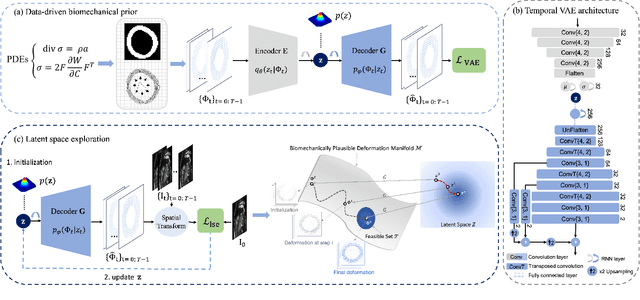
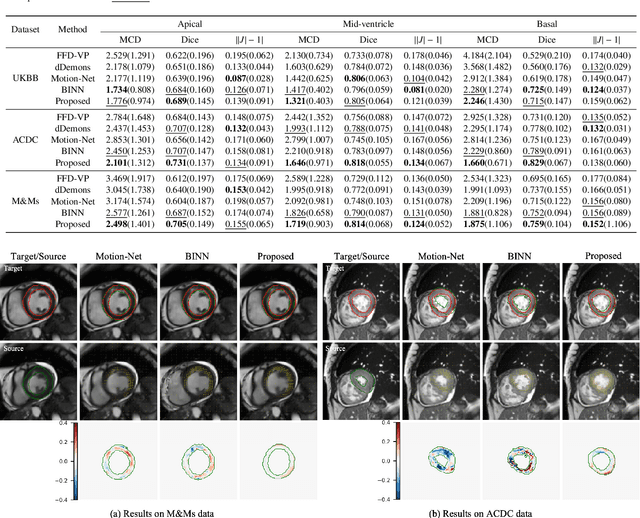
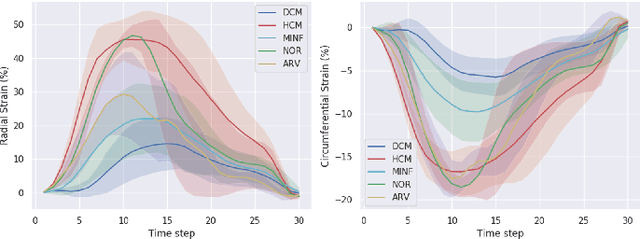
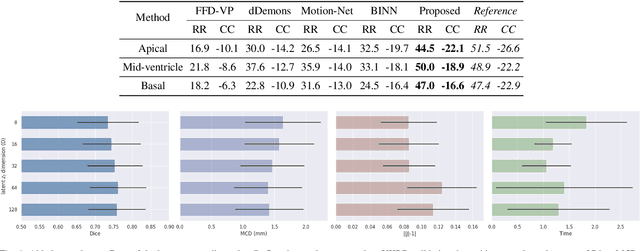
Myocardial motion and deformation are rich descriptors that characterize cardiac function. Image registration, as the most commonly used technique for myocardial motion tracking, is an ill-posed inverse problem which often requires prior assumptions on the solution space. In contrast to most existing approaches which impose explicit generic regularization such as smoothness, in this work we propose a novel method that can implicitly learn an application-specific biomechanics-informed prior and embed it into a neural network-parameterized transformation model. Particularly, the proposed method leverages a variational autoencoder-based generative model to learn a manifold for biomechanically plausible deformations. The motion tracking then can be performed via traversing the learnt manifold to search for the optimal transformations while considering the sequence information. The proposed method is validated on three public cardiac cine MRI datasets with comprehensive evaluations. The results demonstrate that the proposed method can outperform other approaches, yielding higher motion tracking accuracy with reasonable volume preservation and better generalizability to varying data distributions. It also enables better estimates of myocardial strains, which indicates the potential of the method in characterizing spatiotemporal signatures for understanding cardiovascular diseases.
Composition-aware Graphic Layout GAN for Visual-textual Presentation Designs
Apr 30, 2022

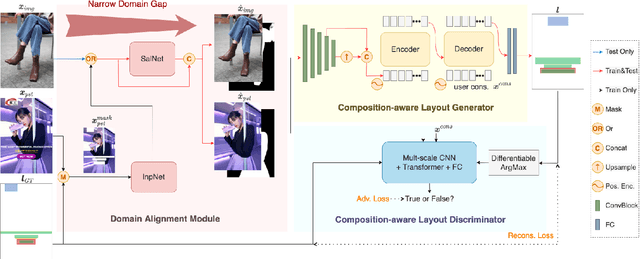

In this paper, we study the graphic layout generation problem of producing high-quality visual-textual presentation designs for given images. We note that image compositions, which contain not only global semantics but also spatial information, would largely affect layout results. Hence, we propose a deep generative model, dubbed as composition-aware graphic layout GAN (CGL-GAN), to synthesize layouts based on the global and spatial visual contents of input images. To obtain training images from images that already contain manually designed graphic layout data, previous work suggests masking design elements (e.g., texts and embellishments) as model inputs, which inevitably leaves hint of the ground truth. We study the misalignment between the training inputs (with hint masks) and test inputs (without masks), and design a novel domain alignment module (DAM) to narrow this gap. For training, we built a large-scale layout dataset which consists of 60,548 advertising posters with annotated layout information. To evaluate the generated layouts, we propose three novel metrics according to aesthetic intuitions. Through both quantitative and qualitative evaluations, we demonstrate that the proposed model can synthesize high-quality graphic layouts according to image compositions.