 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A No-Reference Deep Learning Quality Assessment Method for Super-resolution Images Based on Frequency Maps
Jun 09, 2022

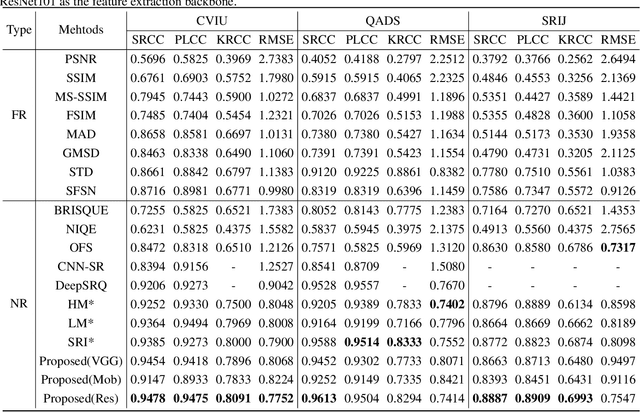
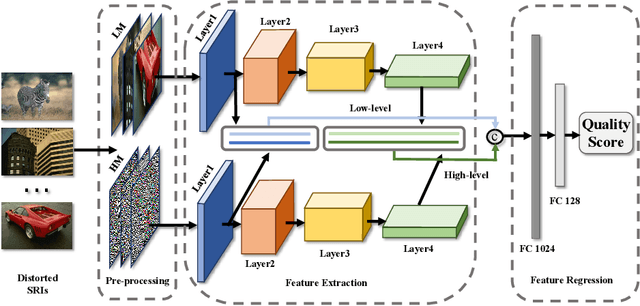
To support the application scenarios where high-resolution (HR) images are urgently needed, various single image super-resolution (SISR) algorithms are developed. However, SISR is an ill-posed inverse problem, which may bring artifacts like texture shift, blur, etc. to the reconstructed images, thus it is necessary to evaluate the quality of super-resolution images (SRIs). Note that most existing image quality assessment (IQA) methods were developed for synthetically distorted images, which may not work for SRIs since their distortions are more diverse and complicated. Therefore, in this paper, we propose a no-reference deep-learning image quality assessment method based on frequency maps because the artifacts caused by SISR algorithms are quite sensitive to frequency information. Specifically, we first obtain the high-frequency map (HM) and low-frequency map (LM) of SRI by using Sobel operator and piecewise smooth image approximation. Then, a two-stream network is employed to extract the quality-aware features of both frequency maps. Finally, the features are regressed into a single quality value using fully connected layers. The experimental results show that our method outperforms all compared IQA models on the selected three super-resolution quality assessment (SRQA) databases.
HPGNN: Using Hierarchical Graph Neural Networks for Outdoor Point Cloud Processing
Jun 05, 2022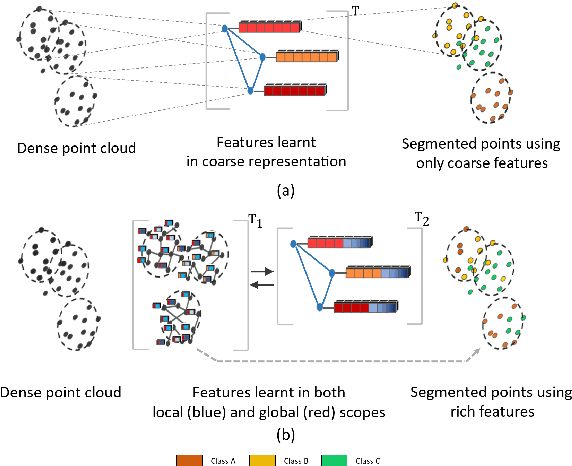
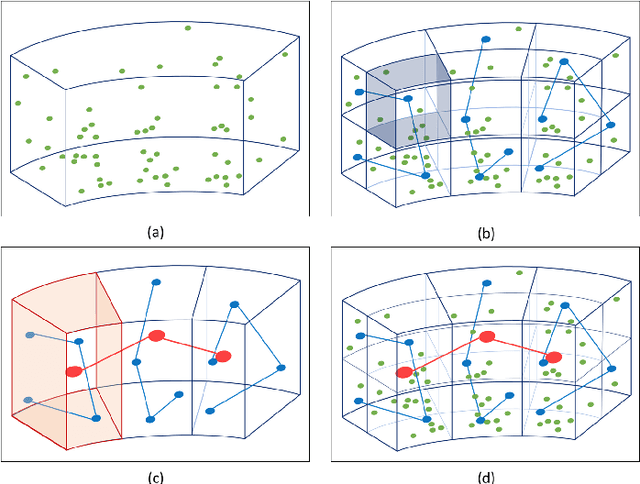
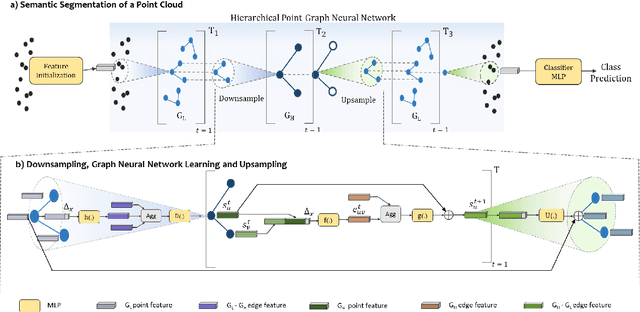
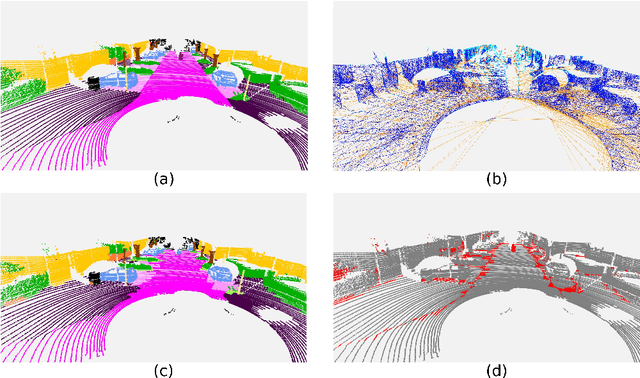
Inspired by recent improvements in point cloud processing for autonomous navigation, we focus on using hierarchical graph neural networks for processing and feature learning over large-scale outdoor LiDAR point clouds. We observe that existing GNN based methods fail to overcome challenges of scale and irregularity of points in outdoor datasets. Addressing the need to preserve structural details while learning over a larger volume efficiently, we propose Hierarchical Point Graph Neural Network (HPGNN). It learns node features at various levels of graph coarseness to extract information. This enables to learn over a large point cloud while retaining fine details that existing point-level graph networks struggle to achieve. Connections between multiple levels enable a point to learn features in multiple scales, in a few iterations. We design HPGNN as a purely GNN-based approach, so that it offers modular expandability as seen with other point-based and Graph network baselines. To illustrate the improved processing capability, we compare previous point based and GNN models for semantic segmentation with our HPGNN, achieving a significant improvement for GNNs (+36.7 mIoU) on the SemanticKITTI dataset.
Self-Supervised Deep Graph Embedding with High-Order Information Fusion for Community Discovery
Feb 08, 2021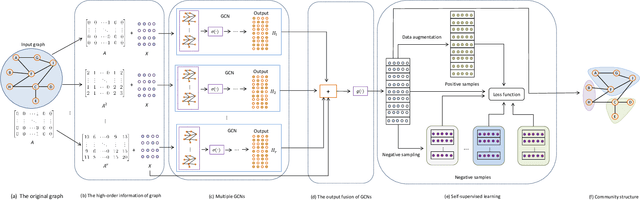

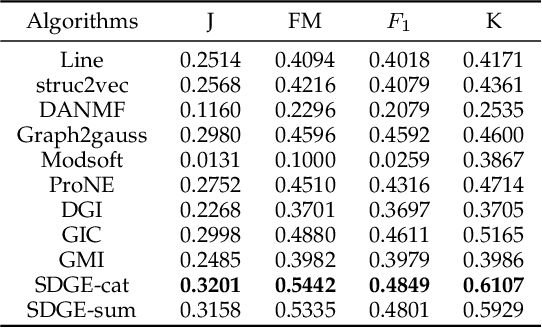
Deep graph embedding is an important approach for community discovery. Deep graph neural network with self-supervised mechanism can obtain the low-dimensional embedding vectors of nodes from unlabeled and unstructured graph data. The high-order information of graph can provide more abundant structure information for the representation learning of nodes. However, most self-supervised graph neural networks only use adjacency matrix as the input topology information of graph and cannot obtain too high-order information since the number of layers of graph neural network is fairly limited. If there are too many layers, the phenomenon of over smoothing will appear. Therefore how to obtain and fuse high-order information of graph by a shallow graph neural network is an important problem. In this paper, a deep graph embedding algorithm with self-supervised mechanism for community discovery is proposed. The proposed algorithm uses self-supervised mechanism and different high-order information of graph to train multiple deep graph convolution neural networks. The outputs of multiple graph convolution neural networks are fused to extract the representations of nodes which include the attribute and structure information of a graph. In addition, data augmentation and negative sampling are introduced into the training process to facilitate the improvement of embedding result. The proposed algorithm and the comparison algorithms are conducted on the five experimental data sets. The experimental results show that the proposed algorithm outperforms the comparison algorithms on the most experimental data sets. The experimental results demonstrate that the proposed algorithm is an effective algorithm for community discovery.
JNMR: Joint Non-linear Motion Regression for Video Frame Interpolation
Jun 09, 2022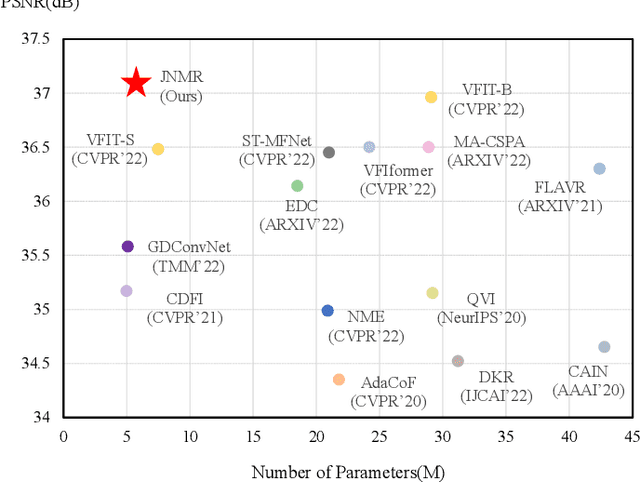

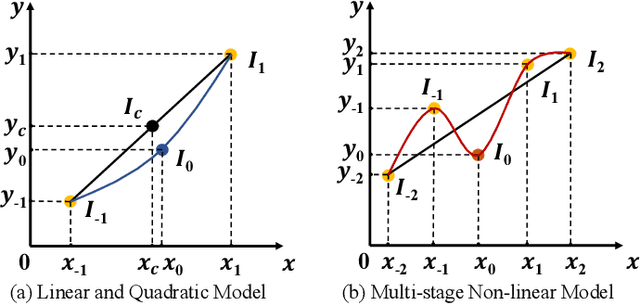
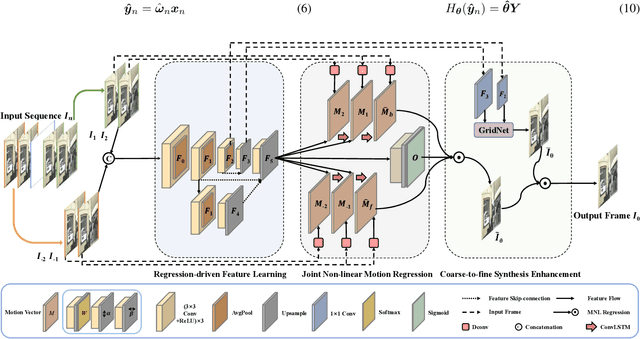
Video frame interpolation (VFI) aims to generate predictive frames by warping learnable motions from the bidirectional historical references. Most existing works utilize spatio-temporal semantic information extractor to realize motion estimation and interpolation modeling, not enough considering with the real mechanistic rationality of generated middle motions. In this paper, we reformulate VFI as a multi-variable non-linear (MNL) regression problem, and a Joint Non-linear Motion Regression (JNMR) strategy is proposed to model complicated motions of inter-frame. To establish the MNL regression, ConvLSTM is adopted to construct the distribution of complete motions in temporal dimension. The motion correlations between the target frame and multiple reference frames can be regressed by the modeled distribution. Moreover, the feature learning network is designed to optimize for the MNL regression modeling. A coarse-to-fine synthesis enhancement module is further conducted to learn visual dynamics at different resolutions through repetitive regression and interpolation. Highly competitive experimental results on frame interpolation show that the effectiveness and significant improvement compared with state-of-the-art performance, and the robustness of complicated motion estimation is improved by the MNL motion regression.
Incorporating Broad Phonetic Information for Speech Enhancement
Aug 13, 2020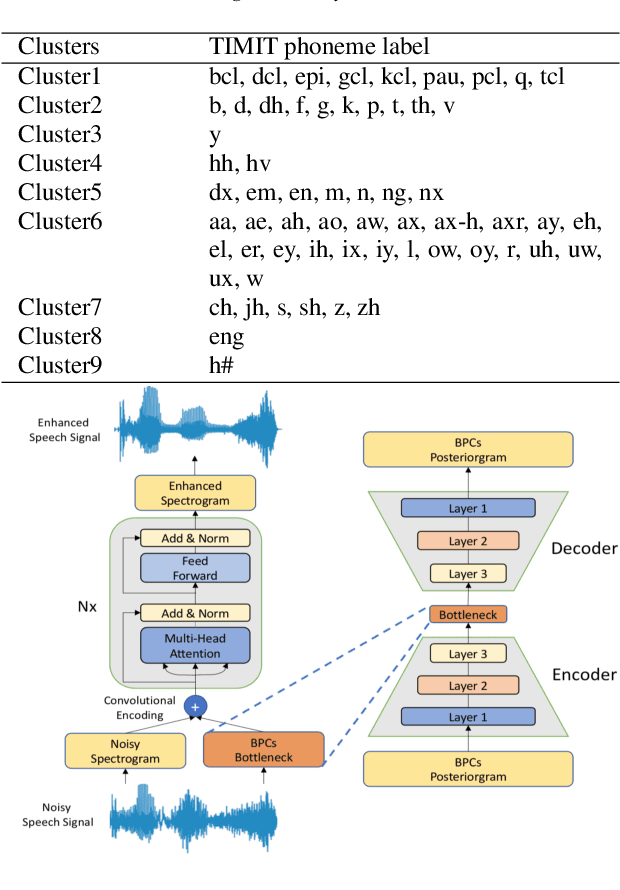
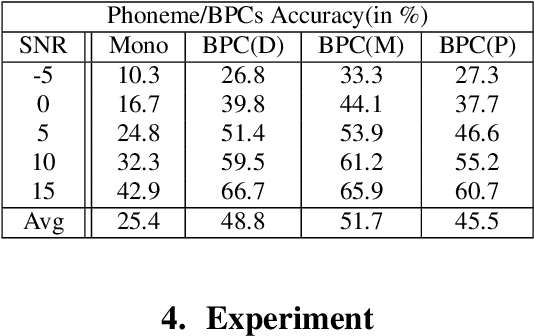
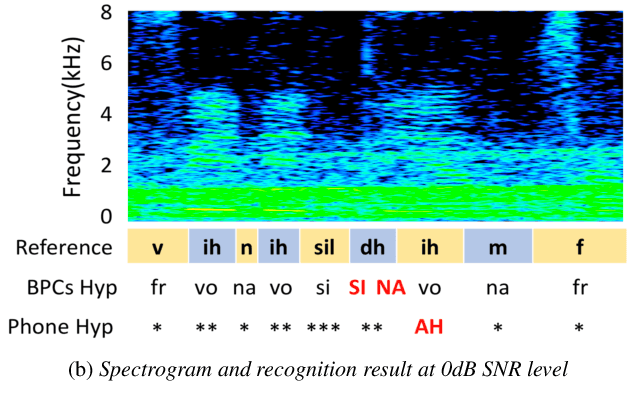

In noisy conditions, knowing speech contents facilitates listeners to more effectively suppress background noise components and to retrieve pure speech signals. Previous studies have also confirmed the benefits of incorporating phonetic information in a speech enhancement (SE) system to achieve better denoising performance. To obtain the phonetic information, we usually prepare a phoneme-based acoustic model, which is trained using speech waveforms and phoneme labels. Despite performing well in normal noisy conditions, when operating in very noisy conditions, however, the recognized phonemes may be erroneous and thus misguide the SE process. To overcome the limitation, this study proposes to incorporate the broad phonetic class (BPC) information into the SE process. We have investigated three criteria to build the BPC, including two knowledge-based criteria: place and manner of articulatory and one data-driven criterion. Moreover, the recognition accuracies of BPCs are much higher than that of phonemes, thus providing more accurate phonetic information to guide the SE process under very noisy conditions. Experimental results demonstrate that the proposed SE with the BPC information framework can achieve notable performance improvements over the baseline system and an SE system using monophonic information in terms of both speech quality intelligibility on the TIMIT dataset.
Control of Two-way Coupled Fluid Systems with Differentiable Solvers
Jun 01, 2022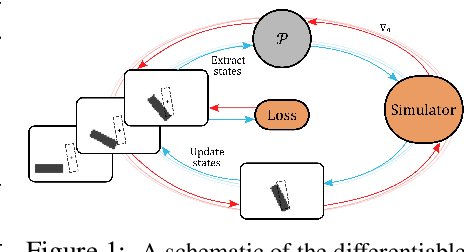
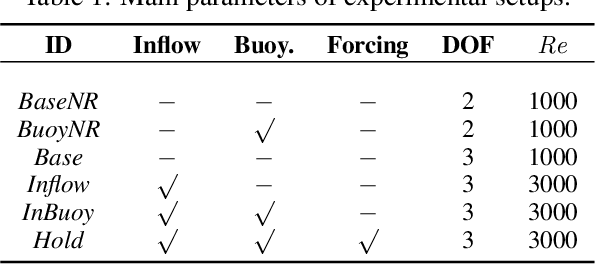
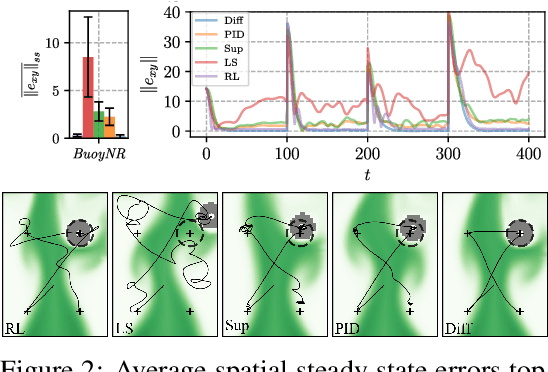
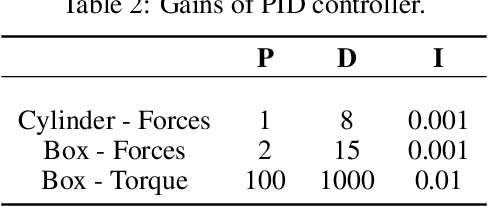
We investigate the use of deep neural networks to control complex nonlinear dynamical systems, specifically the movement of a rigid body immersed in a fluid. We solve the Navier Stokes equations with two way coupling, which gives rise to nonlinear perturbations that make the control task very challenging. Neural networks are trained in an unsupervised way to act as controllers with desired characteristics through a process of learning from a differentiable simulator. Here we introduce a set of physically interpretable loss terms to let the networks learn robust and stable interactions. We demonstrate that controllers trained in a canonical setting with quiescent initial conditions reliably generalize to varied and challenging environments such as previously unseen inflow conditions and forcing, although they do not have any fluid information as input. Further, we show that controllers trained with our approach outperform a variety of classical and learned alternatives in terms of evaluation metrics and generalization capabilities.
UoB at SemEval-2021 Task 5: Extending Pre-Trained Language Models to Include Task and Domain-Specific Information for Toxic Span Prediction
Oct 07, 2021

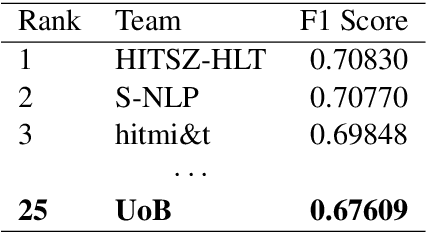

Toxicity is pervasive in social media and poses a major threat to the health of online communities. The recent introduction of pre-trained language models, which have achieved state-of-the-art results in many NLP tasks, has transformed the way in which we approach natural language processing. However, the inherent nature of pre-training means that they are unlikely to capture task-specific statistical information or learn domain-specific knowledge. Additionally, most implementations of these models typically do not employ conditional random fields, a method for simultaneous token classification. We show that these modifications can improve model performance on the Toxic Spans Detection task at SemEval-2021 to achieve a score within 4 percentage points of the top performing team.
* Published in Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021); Code available at: https://github.com/erikdyan/toxic_span_detection
CV4Code: Sourcecode Understanding via Visual Code Representations
May 11, 2022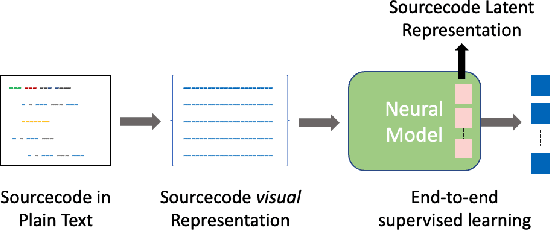
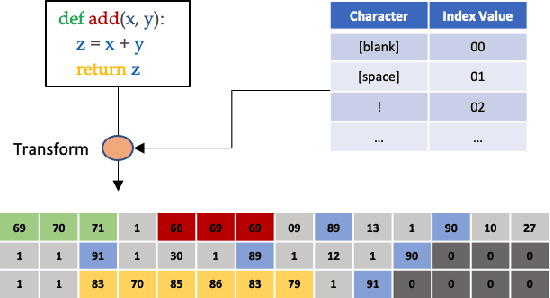

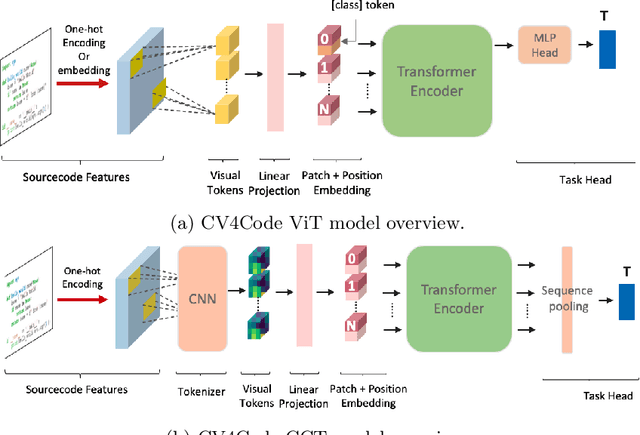
We present CV4Code, a compact and effective computer vision method for sourcecode understanding. Our method leverages the contextual and the structural information available from the code snippet by treating each snippet as a two-dimensional image, which naturally encodes the context and retains the underlying structural information through an explicit spatial representation. To codify snippets as images, we propose an ASCII codepoint-based image representation that facilitates fast generation of sourcecode images and eliminates redundancy in the encoding that would arise from an RGB pixel representation. Furthermore, as sourcecode is treated as images, neither lexical analysis (tokenisation) nor syntax tree parsing is required, which makes the proposed method agnostic to any particular programming language and lightweight from the application pipeline point of view. CV4Code can even featurise syntactically incorrect code which is not possible from methods that depend on the Abstract Syntax Tree (AST). We demonstrate the effectiveness of CV4Code by learning Convolutional and Transformer networks to predict the functional task, i.e. the problem it solves, of the source code directly from its two-dimensional representation, and using an embedding from its latent space to derive a similarity score of two code snippets in a retrieval setup. Experimental results show that our approach achieves state-of-the-art performance in comparison to other methods with the same task and data configurations. For the first time we show the benefits of treating sourcecode understanding as a form of image processing task.
Stochastic Gradient Methods with Preconditioned Updates
Jun 01, 2022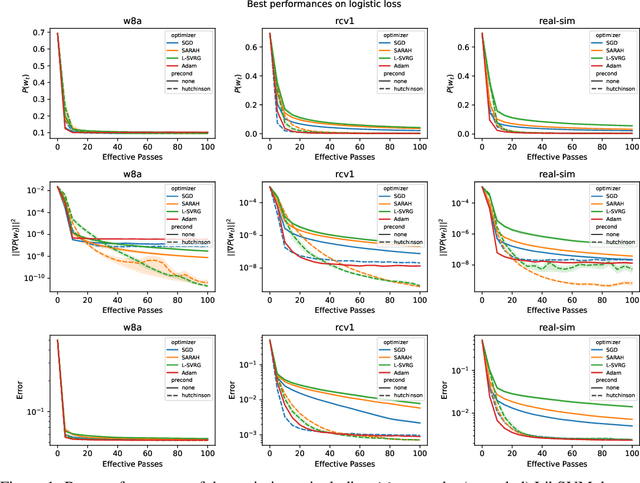
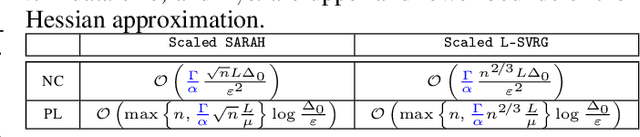
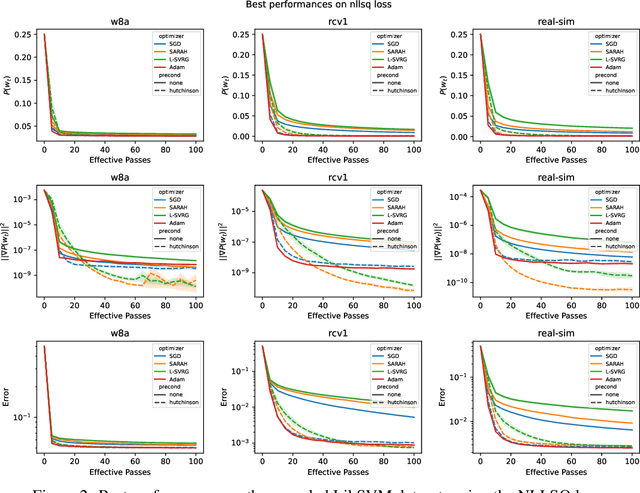

This work considers non-convex finite sum minimization. There are a number of algorithms for such problems, but existing methods often work poorly when the problem is badly scaled and/or ill-conditioned, and a primary goal of this work is to introduce methods that alleviate this issue. Thus, here we include a preconditioner that is based upon Hutchinson's approach to approximating the diagonal of the Hessian, and couple it with several gradient based methods to give new `scaled' algorithms: {\tt Scaled SARAH} and {\tt Scaled L-SVRG}. Theoretical complexity guarantees under smoothness assumptions are presented, and we prove linear convergence when both smoothness and the PL-condition is assumed. Because our adaptively scaled methods use approximate partial second order curvature information, they are better able to mitigate the impact of badly scaled problems, and this improved practical performance is demonstrated in the numerical experiments that are also presented in this work.
Intelligent Agent for Hurricane Emergency Identification and Text Information Extraction from Streaming Social Media Big Data
Jun 14, 2021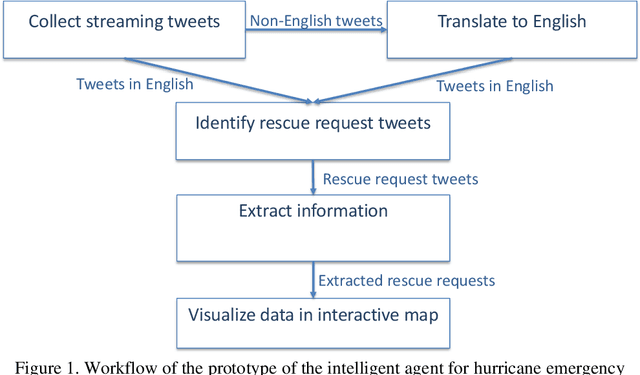
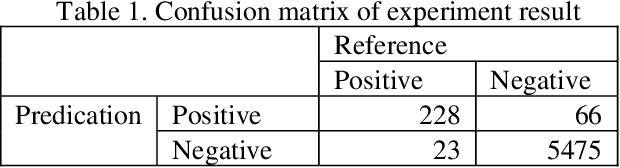
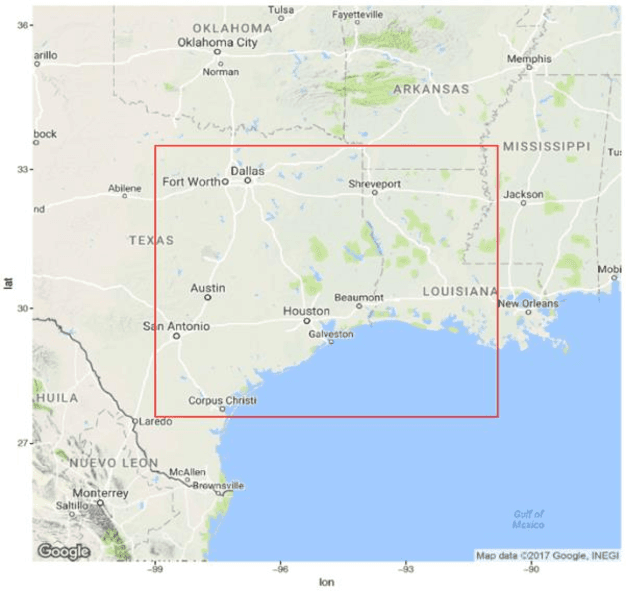
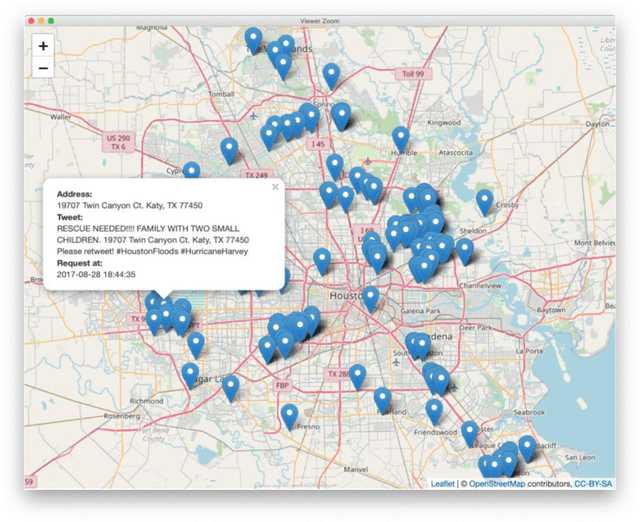
This paper presents our research on leveraging social media Big Data and AI to support hurricane disaster emergency response. The current practice of hurricane emergency response for rescue highly relies on emergency call centres. The more recent Hurricane Harvey event reveals the limitations of the current systems. We use Hurricane Harvey and the associated Houston flooding as the motivating scenario to conduct research and develop a prototype as a proof-of-concept of using an intelligent agent as a complementary role to support emergency centres in hurricane emergency response. This intelligent agent is used to collect real-time streaming tweets during a natural disaster event, to identify tweets requesting rescue, to extract key information such as address and associated geocode, and to visualize the extracted information in an interactive map in decision supports. Our experiment shows promising outcomes and the potential application of the research in support of hurricane emergency response.