 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
X-SCITLDR: Cross-Lingual Extreme Summarization of Scholarly Documents
May 30, 2022
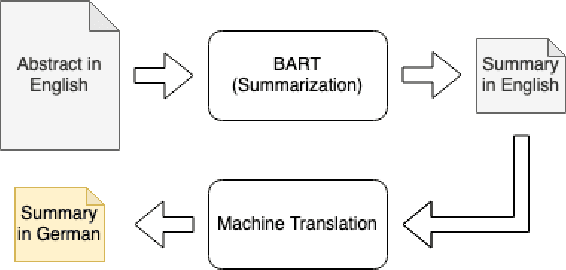

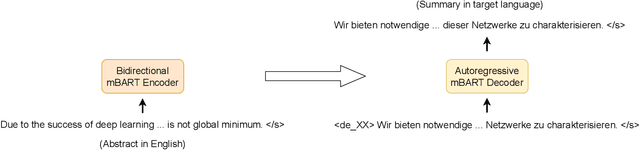

The number of scientific publications nowadays is rapidly increasing, causing information overload for researchers and making it hard for scholars to keep up to date with current trends and lines of work. Consequently, recent work on applying text mining technologies for scholarly publications has investigated the application of automatic text summarization technologies, including extreme summarization, for this domain. However, previous work has concentrated only on monolingual settings, primarily in English. In this paper, we fill this research gap and present an abstractive cross-lingual summarization dataset for four different languages in the scholarly domain, which enables us to train and evaluate models that process English papers and generate summaries in German, Italian, Chinese and Japanese. We present our new X-SCITLDR dataset for multilingual summarization and thoroughly benchmark different models based on a state-of-the-art multilingual pre-trained model, including a two-stage `summarize and translate' approach and a direct cross-lingual model. We additionally explore the benefits of intermediate-stage training using English monolingual summarization and machine translation as intermediate tasks and analyze performance in zero- and few-shot scenarios.
MISO-wiLDCosts: Multi Information Source Optimization with Location Dependent Costs
Feb 09, 2021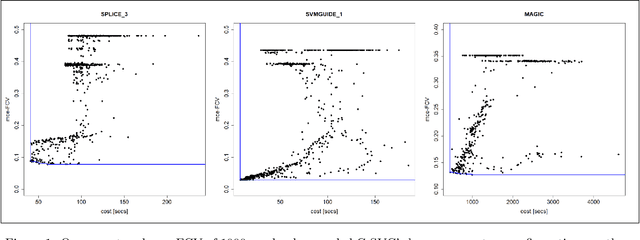
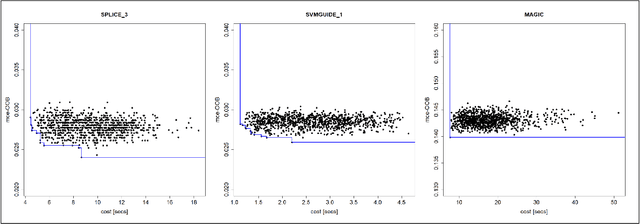
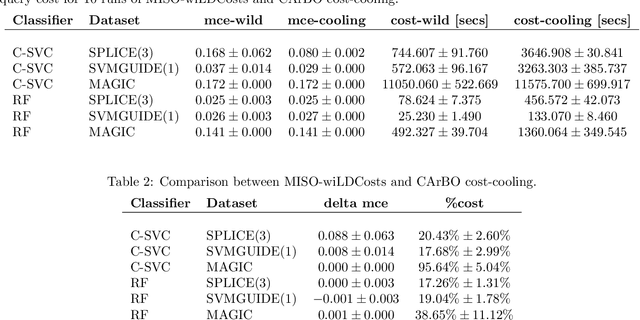
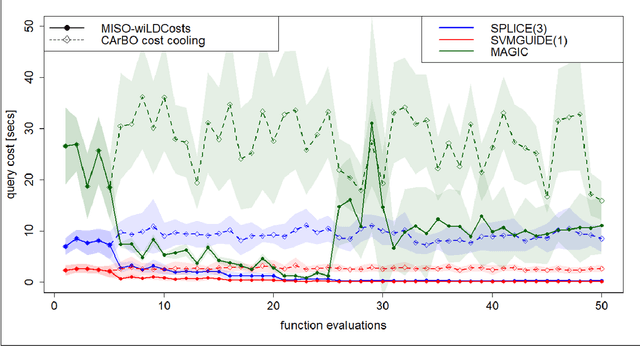
This paper addresses black-box optimization over multiple information sources whose both fidelity and query cost change over the search space, that is they are location dependent. The approach uses: (i) an Augmented Gaussian Process, recently proposed in multi-information source optimization as a single model of the objective function over search space and sources, and (ii) a Gaussian Process to model the location-dependent cost of each source. The former is used into a Confidence Bound based acquisition function to select the next source and location to query, while the latter is used to penalize the value of the acquisition depending on the expected query cost for any source-location pair. The proposed approach is evaluated on a set of Hyperparameters Optimization tasks, consisting of two Machine Learning classifiers and three datasets of different sizes.
Actionable Guidance for High-Consequence AI Risk Management: Towards Standards Addressing AI Catastrophic Risks
Jun 17, 2022Artificial intelligence (AI) systems can provide many beneficial capabilities but also risks of adverse events. Some AI systems could present risks of events with very high or catastrophic consequences at societal scale. The US National Institute of Standards and Technology (NIST) is developing the NIST Artificial Intelligence Risk Management Framework (AI RMF) as voluntary guidance on AI risk assessment and management for AI developers and others. For addressing risks of events with catastrophic consequences, NIST indicated a need to translate from high level principles to actionable risk management guidance. In this document, we provide detailed actionable-guidance recommendations focused on identifying and managing risks of events with very high or catastrophic consequences, intended as a risk management practices resource for NIST for AI RMF version 1.0 (scheduled for release in early 2023), or for AI RMF users, or for other AI risk management guidance and standards as appropriate. We also provide our methodology for our recommendations. We provide actionable-guidance recommendations for AI RMF 1.0 on: identifying risks from potential unintended uses and misuses of AI systems; including catastrophic-risk factors within the scope of risk assessments and impact assessments; identifying and mitigating human rights harms; and reporting information on AI risk factors including catastrophic-risk factors. In addition, we provide recommendations on additional issues for a roadmap for later versions of the AI RMF or supplementary publications. These include: providing an AI RMF Profile with supplementary guidance for cutting-edge increasingly multi-purpose or general-purpose AI. We aim for this work to be a concrete risk-management practices contribution, and to stimulate constructive dialogue on how to address catastrophic risks and associated issues in AI standards.
Rethinking Saliency Map: An Context-aware Perturbation Method to Explain EEG-based Deep Learning Model
May 30, 2022
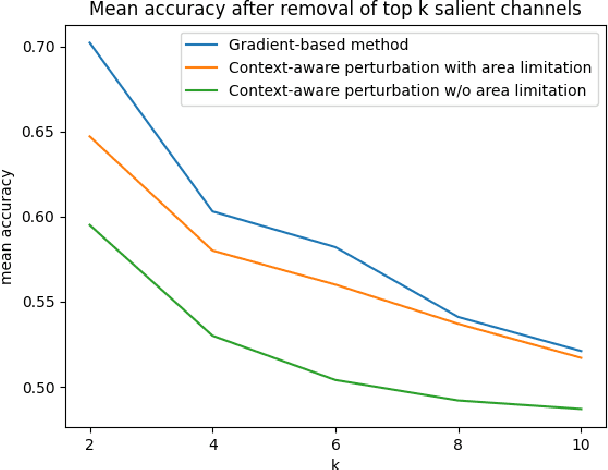
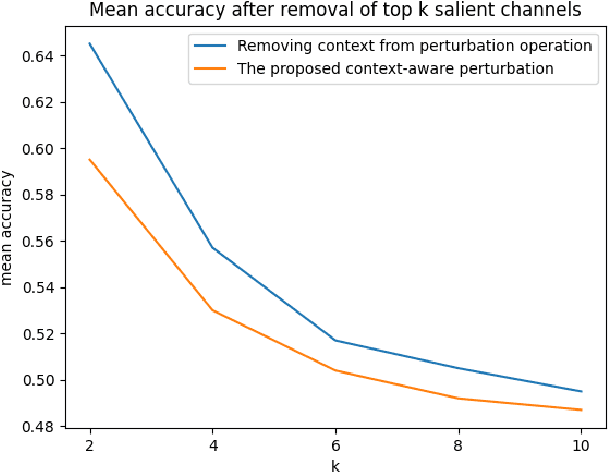
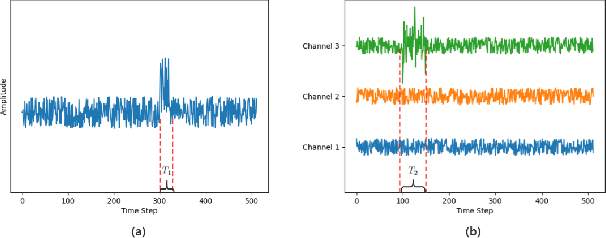
Deep learning is widely used to decode the electroencephalogram (EEG) signal. However, there are few attempts to specifically investigate how to explain the EEG-based deep learning models. We conduct a review to summarize the existing works explaining the EEG-based deep learning model. Unfortunately, we find that there is no appropriate method to explain them. Based on the characteristic of EEG data, we suggest a context-aware perturbation method to generate a saliency map from the perspective of the raw EEG signal. Moreover, we also justify that the context information can be used to suppress the artifacts in the EEG-based deep learning model. In practice, some users might want a simple version of the explanation, which only indicates a few features as salient points. To this end, we propose an optional area limitation strategy to restrict the highlighted region. To validate our idea and make a comparison with the other methods, we select three representative EEG-based models to implement experiments on the emotional EEG dataset DEAP. The results of the experiments support the advantages of our method.
XAI for Cybersecurity: State of the Art, Challenges, Open Issues and Future Directions
Jun 03, 2022

In the past few years, artificial intelligence (AI) techniques have been implemented in almost all verticals of human life. However, the results generated from the AI models often lag explainability. AI models often appear as a blackbox wherein developers are unable to explain or trace back the reasoning behind a specific decision. Explainable AI (XAI) is a rapid growing field of research which helps to extract information and also visualize the results generated with an optimum transparency. The present study provides and extensive review of the use of XAI in cybersecurity. Cybersecurity enables protection of systems, networks and programs from different types of attacks. The use of XAI has immense potential in predicting such attacks. The paper provides a brief overview on cybersecurity and the various forms of attack. Then the use of traditional AI techniques and its associated challenges are discussed which opens its doors towards use of XAI in various applications. The XAI implementations of various research projects and industry are also presented. Finally, the lessons learnt from these applications are highlighted which act as a guide for future scope of research.
Psychologically-Inspired, Unsupervised Inference of Perceptual Groups of GUI Widgets from GUI Images
Jun 15, 2022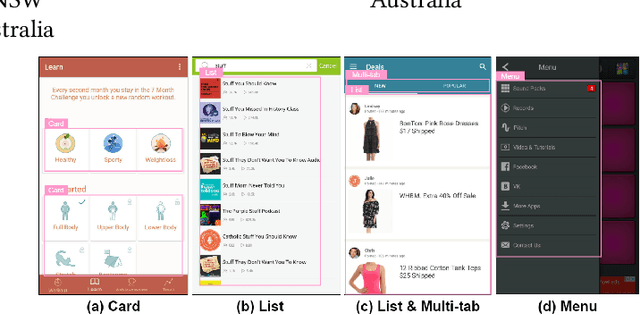
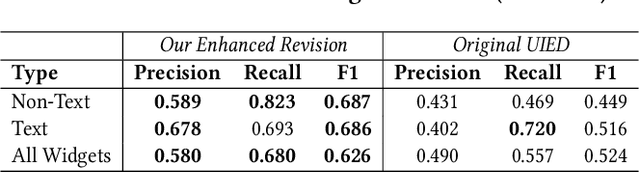
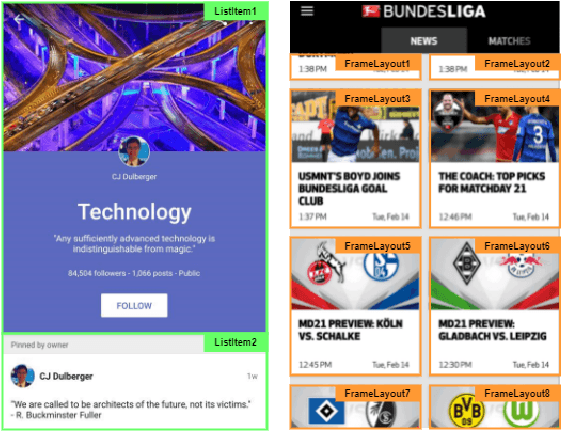
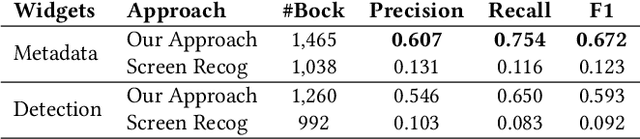
Graphical User Interface (GUI) is not merely a collection of individual and unrelated widgets, but rather partitions discrete widgets into groups by various visual cues, thus forming higher-order perceptual units such as tab, menu, card or list. The ability to automatically segment a GUI into perceptual groups of widgets constitutes a fundamental component of visual intelligence to automate GUI design, implementation and automation tasks. Although humans can partition a GUI into meaningful perceptual groups of widgets in a highly reliable way, perceptual grouping is still an open challenge for computational approaches. Existing methods rely on ad-hoc heuristics or supervised machine learning that is dependent on specific GUI implementations and runtime information. Research in psychology and biological vision has formulated a set of principles (i.e., Gestalt theory of perception) that describe how humans group elements in visual scenes based on visual cues like connectivity, similarity, proximity and continuity. These principles are domain-independent and have been widely adopted by practitioners to structure content on GUIs to improve aesthetic pleasant and usability. Inspired by these principles, we present a novel unsupervised image-based method for inferring perceptual groups of GUI widgets. Our method requires only GUI pixel images, is independent of GUI implementation, and does not require any training data. The evaluation on a dataset of 1,091 GUIs collected from 772 mobile apps and 20 UI design mockups shows that our method significantly outperforms the state-of-the-art ad-hoc heuristics-based baseline. Our perceptual grouping method creates the opportunities for improving UI-related software engineering tasks.
Linear Algorithms for Nonparametric Multiclass Probability Estimation
Jun 03, 2022
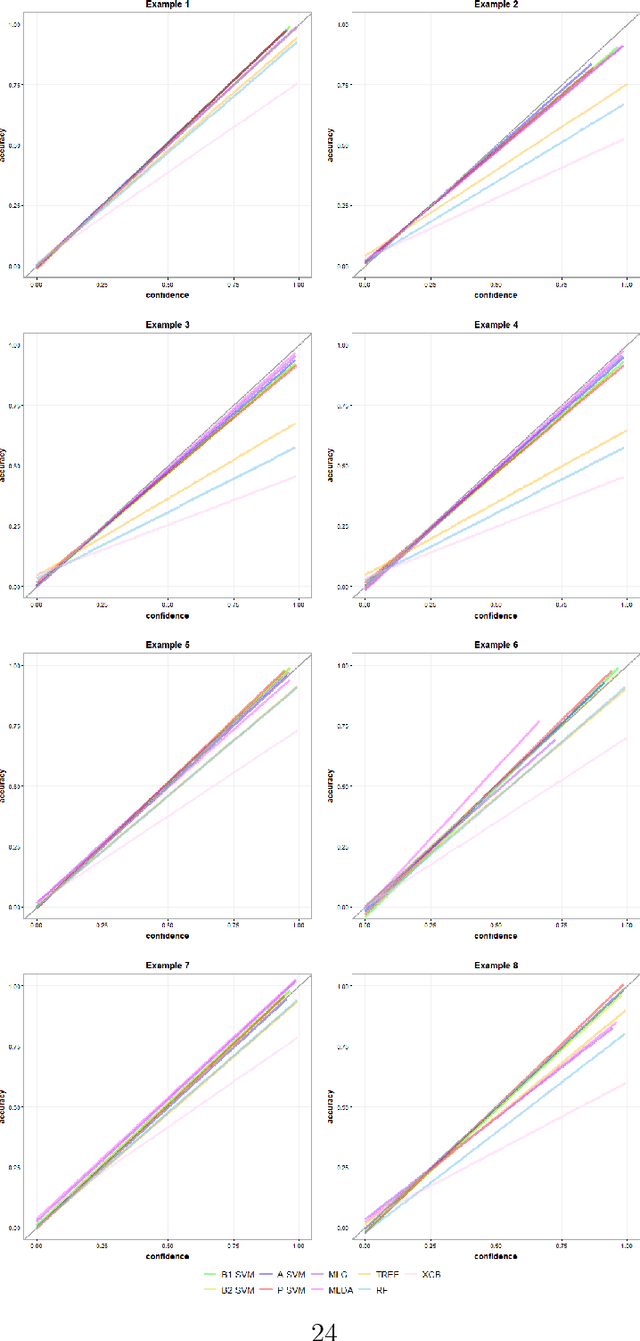
Multiclass probability estimation is the problem of estimating conditional probabilities of a data point belonging to a class given its covariate information. It has broad applications in statistical analysis and data science. Recently a class of weighted Support Vector Machines (wSVMs) has been developed to estimate class probabilities through ensemble learning for $K$-class problems (Wu, Zhang and Liu, 2010; Wang, Zhang and Wu, 2019), where $K$ is the number of classes. The estimators are robust and achieve high accuracy for probability estimation, but their learning is implemented through pairwise coupling, which demands polynomial time in $K$. In this paper, we propose two new learning schemes, the baseline learning and the One-vs-All (OVA) learning, to further improve wSVMs in terms of computational efficiency and estimation accuracy. In particular, the baseline learning has optimal computational complexity in the sense that it is linear in $K$. Though not being most efficient in computation, the OVA offers the best estimation accuracy among all the procedures under comparison. The resulting estimators are distribution-free and shown to be consistent. We further conduct extensive numerical experiments to demonstrate finite sample performance.
Random Walks with Erasure: Diversifying Personalized Recommendations on Social and Information Networks
Feb 18, 2021
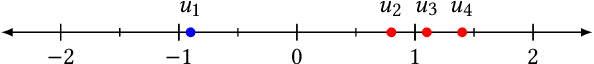

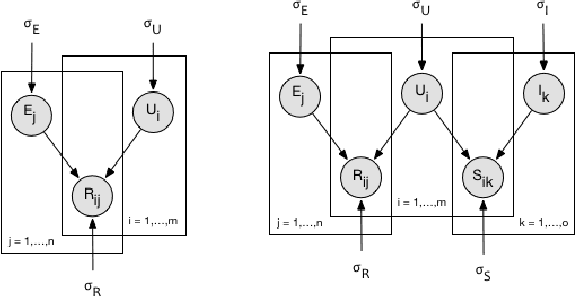
Most existing personalization systems promote items that match a user's previous choices or those that are popular among similar users. This results in recommendations that are highly similar to the ones users are already exposed to, resulting in their isolation inside familiar but insulated information silos. In this context, we develop a novel recommendation framework with a goal of improving information diversity using a modified random walk exploration of the user-item graph. We focus on the problem of political content recommendation, while addressing a general problem applicable to personalization tasks in other social and information networks. For recommending political content on social networks, we first propose a new model to estimate the ideological positions for both users and the content they share, which is able to recover ideological positions with high accuracy. Based on these estimated positions, we generate diversified personalized recommendations using our new random-walk based recommendation algorithm. With experimental evaluations on large datasets of Twitter discussions, we show that our method based on \emph{random walks with erasure} is able to generate more ideologically diverse recommendations. Our approach does not depend on the availability of labels regarding the bias of users or content producers. With experiments on open benchmark datasets from other social and information networks, we also demonstrate the effectiveness of our method in recommending diverse long-tail items.
* Web Conference 2021 (WWW '21)
From Little Things Big Things Grow: A Collection with Seed Studies for Medical Systematic Review Literature Search
Apr 06, 2022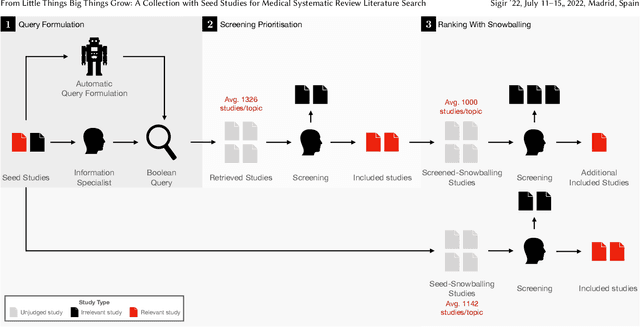

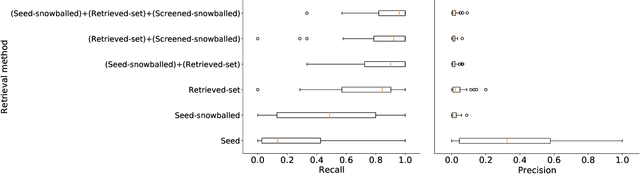
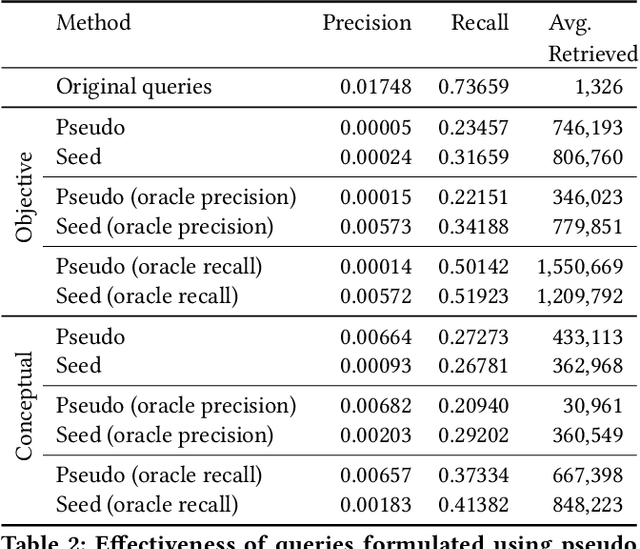
Medical systematic review query formulation is a highly complex task done by trained information specialists. Complexity comes from the reliance on lengthy Boolean queries, which express a detailed research question. To aid query formulation, information specialists use a set of exemplar documents, called `seed studies', prior to query formulation. Seed studies help verify the effectiveness of a query prior to the full assessment of retrieved studies. Beyond this use of seeds, specific IR methods can exploit seed studies for guiding both automatic query formulation and new retrieval models. One major limitation of work to date is that these methods exploit `pseudo seed studies' through retrospective use of included studies (i.e., relevance assessments). However, we show pseudo seed studies are not representative of real seed studies used by information specialists. Hence, we provide a test collection with real world seed studies used to assist with the formulation of queries. To support our collection, we provide an analysis, previously not possible, on how seed studies impact retrieval and perform several experiments using seed-study based methods to compare the effectiveness of using seed studies versus pseudo seed studies. We make our test collection and the results of all of our experiments and analysis available at http://github.com/ielab/sysrev-seed-collection
Individually Fair Learning with One-Sided Feedback
Jun 09, 2022
We consider an online learning problem with one-sided feedback, in which the learner is able to observe the true label only for positively predicted instances. On each round, $k$ instances arrive and receive classification outcomes according to a randomized policy deployed by the learner, whose goal is to maximize accuracy while deploying individually fair policies. We first extend the framework of Bechavod et al. (2020), which relies on the existence of a human fairness auditor for detecting fairness violations, to instead incorporate feedback from dynamically-selected panels of multiple, possibly inconsistent, auditors. We then construct an efficient reduction from our problem of online learning with one-sided feedback and a panel reporting fairness violations to the contextual combinatorial semi-bandit problem (Cesa-Bianchi & Lugosi, 2009, Gy\"{o}rgy et al., 2007). Finally, we show how to leverage the guarantees of two algorithms in the contextual combinatorial semi-bandit setting: Exp2 (Bubeck et al., 2012) and the oracle-efficient Context-Semi-Bandit-FTPL (Syrgkanis et al., 2016), to provide multi-criteria no regret guarantees simultaneously for accuracy and fairness. Our results eliminate two potential sources of bias from prior work: the "hidden outcomes" that are not available to an algorithm operating in the full information setting, and human biases that might be present in any single human auditor, but can be mitigated by selecting a well chosen panel.