 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bridge-Tower: Building Bridges Between Encoders in Vision-Language Representation Learning
Jun 17, 2022
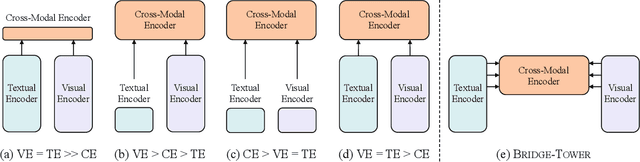

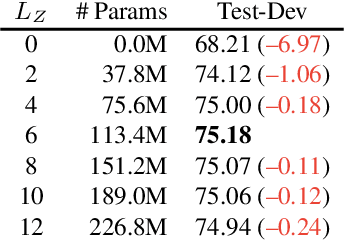
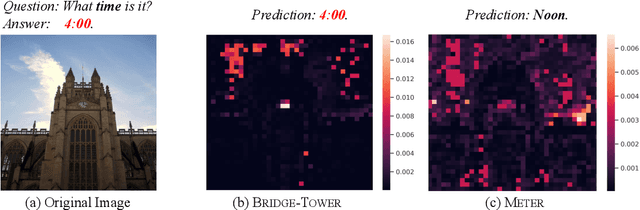
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a cross-modal encoder, or feed the last-layer uni-modal features directly into the top cross-modal encoder, ignoring the semantic information at the different levels in the deep uni-modal encoders. Both approaches possibly restrict vision-language representation learning and limit model performance. In this paper, we introduce multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables comprehensive bottom-up interactions between visual and textual representations at different semantic levels, resulting in more effective cross-modal alignment and fusion. Our proposed Bridge-Tower, pre-trained with only $4$M images, achieves state-of-the-art performance on various downstream vision-language tasks. On the VQAv2 test-std set, Bridge-Tower achieves an accuracy of $78.73\%$, outperforming the previous state-of-the-art METER model by $1.09\%$ with the same pre-training data and almost no additional parameters and computational cost. Notably, when further scaling the model, Bridge-Tower achieves an accuracy of $81.15\%$, surpassing models that are pre-trained on orders-of-magnitude larger datasets. Code is available at https://github.com/microsoft/BridgeTower.
All Mistakes Are Not Equal: Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP)
Jun 17, 2022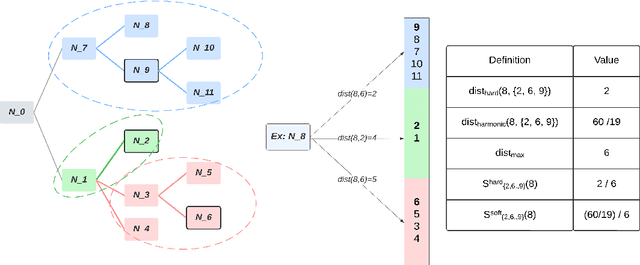
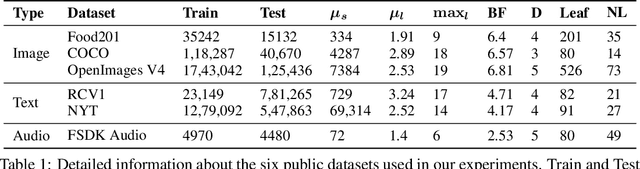
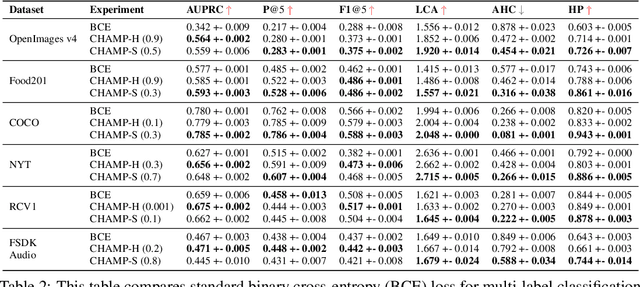
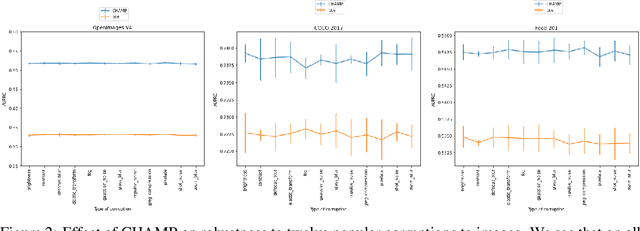
This paper considers the problem of Hierarchical Multi-Label Classification (HMC), where (i) several labels can be present for each example, and (ii) labels are related via a domain-specific hierarchy tree. Guided by the intuition that all mistakes are not equal, we present Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP), a framework that penalizes a misprediction depending on its severity as per the hierarchy tree. While there have been works that apply such an idea to single-label classification, to the best of our knowledge, there are limited such works for multilabel classification focusing on the severity of mistakes. The key reason is that there is no clear way of quantifying the severity of a misprediction a priori in the multilabel setting. In this work, we propose a simple but effective metric to quantify the severity of a mistake in HMC, naturally leading to CHAMP. Extensive experiments on six public HMC datasets across modalities (image, audio, and text) demonstrate that incorporating hierarchical information leads to substantial gains as CHAMP improves both AUPRC (2.6% median percentage improvement) and hierarchical metrics (2.85% median percentage improvement), over stand-alone hierarchical or multilabel classification methods. Compared to standard multilabel baselines, CHAMP provides improved AUPRC in both robustness (8.87% mean percentage improvement ) and less data regimes. Further, our method provides a framework to enhance existing multilabel classification algorithms with better mistakes (18.1% mean percentage increment).
ecpc: An R-package for generic co-data models for high-dimensional prediction
May 16, 2022
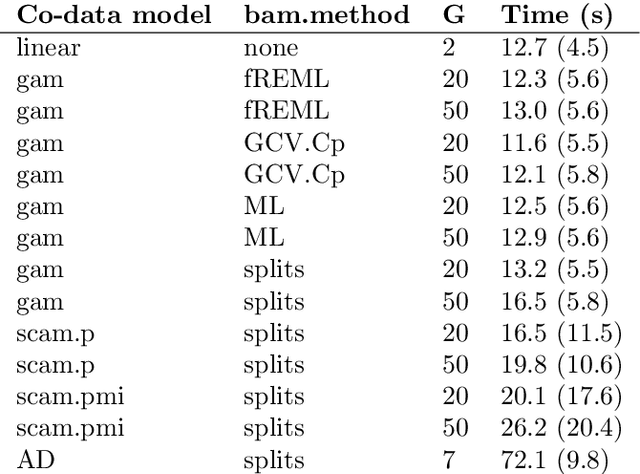
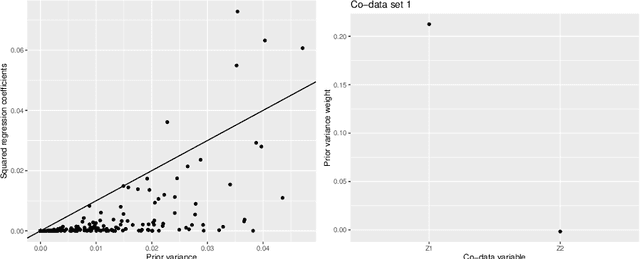
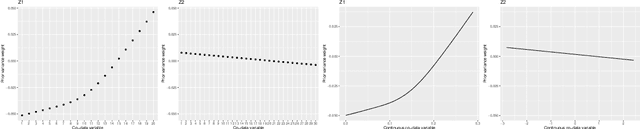
High-dimensional prediction considers data with more variables than samples. Generic research goals are to find the best predictor or to select variables. Results may be improved by exploiting prior information in the form of co-data, providing complementary data not on the samples, but on the variables. We consider adaptive ridge penalised generalised linear and Cox models, in which the variable specific ridge penalties are adapted to the co-data to give a priori more weight to more important variables. The R-package ecpc originally accommodated various and possibly multiple co-data sources, including categorical co-data, i.e. groups of variables, and continuous co-data. Continuous co-data, however, was handled by adaptive discretisation, potentially inefficiently modelling and losing information. Here, we present an extension to the method and software for generic co-data models, particularly for continuous co-data. At the basis lies a classical linear regression model, regressing prior variance weights on the co-data. Co-data variables are then estimated with empirical Bayes moment estimation. After placing the estimation procedure in the classical regression framework, extension to generalised additive and shape constrained co-data models is straightforward. Besides, we show how ridge penalties may be transformed to elastic net penalties with the R-package squeezy. In simulation studies we first compare various co-data models for continuous co-data from the extension to the original method. Secondly, we compare variable selection performance to other variable selection methods. Moreover, we demonstrate use of the package in several examples throughout the paper.
Byzantine-Robust Online and Offline Distributed Reinforcement Learning
Jun 01, 2022We consider a distributed reinforcement learning setting where multiple agents separately explore the environment and communicate their experiences through a central server. However, $\alpha$-fraction of agents are adversarial and can report arbitrary fake information. Critically, these adversarial agents can collude and their fake data can be of any sizes. We desire to robustly identify a near-optimal policy for the underlying Markov decision process in the presence of these adversarial agents. Our main technical contribution is Weighted-Clique, a novel algorithm for the robust mean estimation from batches problem, that can handle arbitrary batch sizes. Building upon this new estimator, in the offline setting, we design a Byzantine-robust distributed pessimistic value iteration algorithm; in the online setting, we design a Byzantine-robust distributed optimistic value iteration algorithm. Both algorithms obtain near-optimal sample complexities and achieve superior robustness guarantee than prior works.
Hindsight is 20/20: Leveraging Past Traversals to Aid 3D Perception
Mar 22, 2022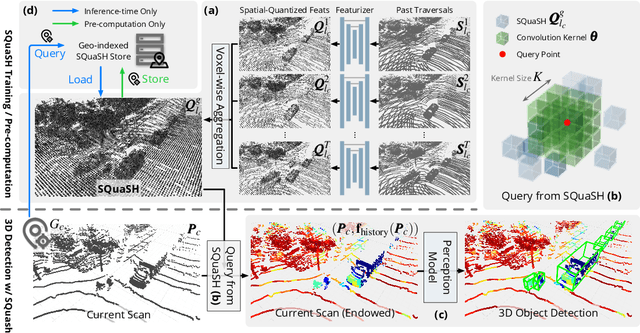
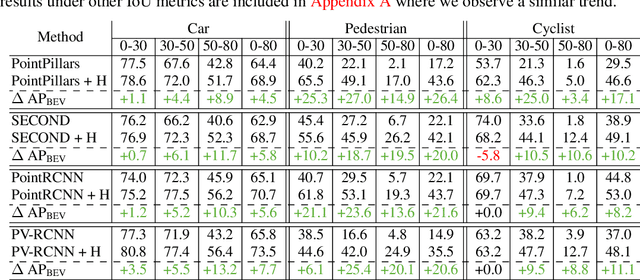
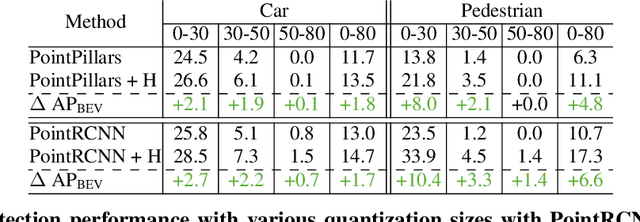
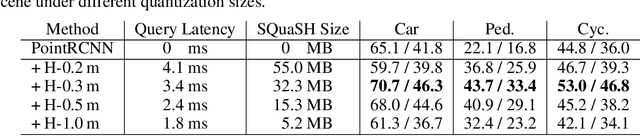
Self-driving cars must detect vehicles, pedestrians, and other traffic participants accurately to operate safely. Small, far-away, or highly occluded objects are particularly challenging because there is limited information in the LiDAR point clouds for detecting them. To address this challenge, we leverage valuable information from the past: in particular, data collected in past traversals of the same scene. We posit that these past data, which are typically discarded, provide rich contextual information for disambiguating the above-mentioned challenging cases. To this end, we propose a novel, end-to-end trainable Hindsight framework to extract this contextual information from past traversals and store it in an easy-to-query data structure, which can then be leveraged to aid future 3D object detection of the same scene. We show that this framework is compatible with most modern 3D detection architectures and can substantially improve their average precision on multiple autonomous driving datasets, most notably by more than 300% on the challenging cases.
Structured Context Transformer for Generic Event Boundary Detection
Jun 07, 2022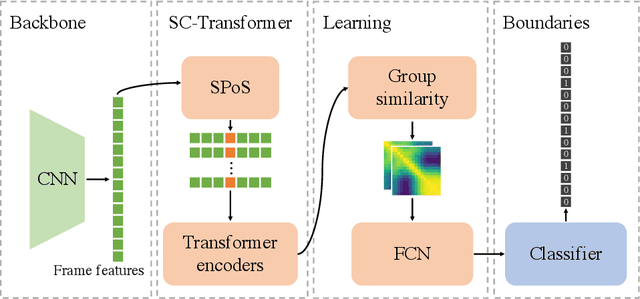
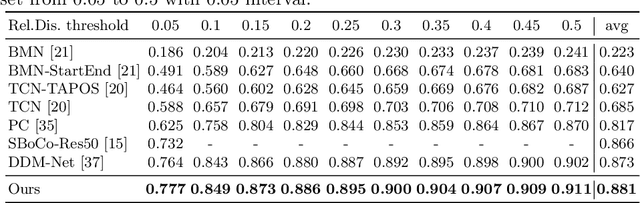
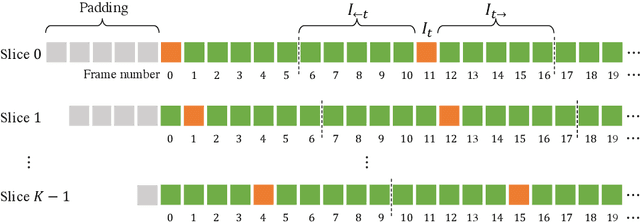
Generic Event Boundary Detection (GEBD) aims to detect moments where humans naturally perceive as event boundaries. In this paper, we present Structured Context Transformer (or SC-Transformer) to solve the GEBD task, which can be trained in an end-to-end fashion. Specifically, we use the backbone convolutional neural network (CNN) to extract the features of each video frame. To capture temporal context information of each frame, we design the structure context transformer (SC-Transformer) by re-partitioning input frame sequence. Note that, the overall computation complexity of SC-Transformer is linear to the video length. After that, the group similarities are computed to capture the differences between frames. Then, a lightweight fully convolutional network is used to determine the event boundaries based on the grouped similarity maps. To remedy the ambiguities of boundary annotations, the Gaussian kernel is adopted to preprocess the ground-truth event boundaries to further boost the accuracy. Extensive experiments conducted on the challenging Kinetics-GEBD and TAPOS datasets demonstrate the effectiveness of the proposed method compared to the state-of-the-art methods.
Disentangled and Side-aware Unsupervised Domain Adaptation for Cross-dataset Subjective Tinnitus Diagnosis
May 03, 2022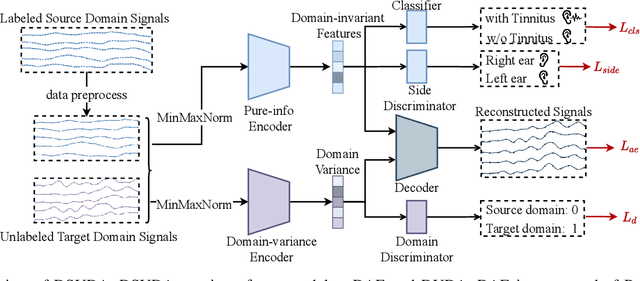
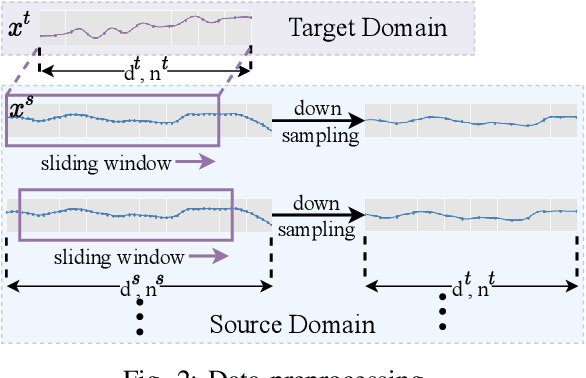
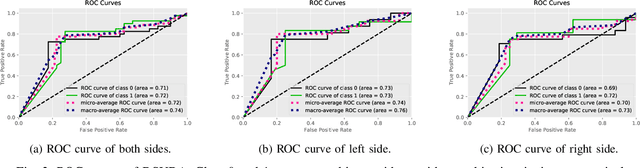
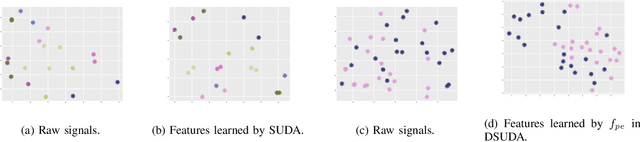
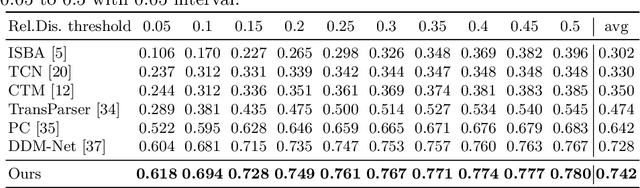
EEG-based tinnitus classification is a valuable tool for tinnitus diagnosis, research, and treatments. Most current works are limited to a single dataset where data patterns are similar. But EEG signals are highly non-stationary, resulting in model's poor generalization to new users, sessions or datasets. Thus, designing a model that can generalize to new datasets is beneficial and indispensable. To mitigate distribution discrepancy across datasets, we propose to achieve Disentangled and Side-aware Unsupervised Domain Adaptation (DSUDA) for cross-dataset tinnitus diagnosis. A disentangled auto-encoder is developed to decouple class-irrelevant information from the EEG signals to improve the classifying ability. The side-aware unsupervised domain adaptation module adapts the class-irrelevant information as domain variance to a new dataset and excludes the variance to obtain the class-distill features for the new dataset classification. It also align signals of left and right ears to overcome inherent EEG pattern difference. We compare DSUDA with state-of-the-art methods, and our model achieves significant improvements over competitors regarding comprehensive evaluation criteria. The results demonstrate our model can successfully generalize to a new dataset and effectively diagnose tinnitus.
Jacobian Granger Causal Neural Networks for Analysis of Stationary and Nonstationary Data
May 19, 2022
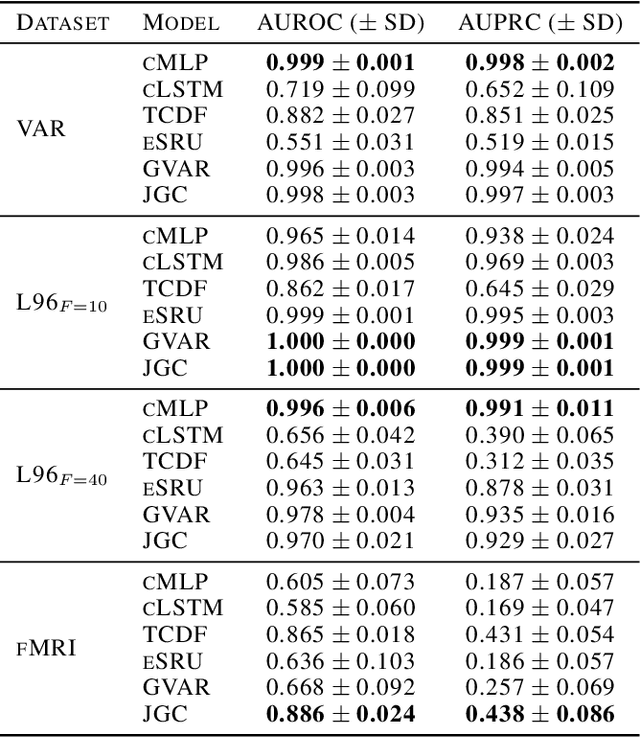
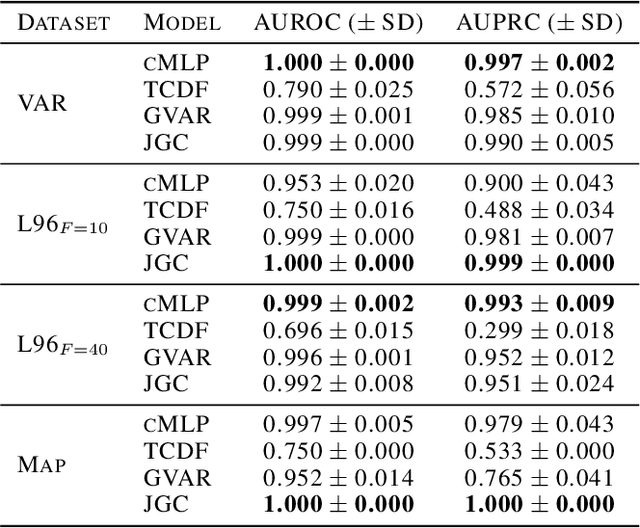
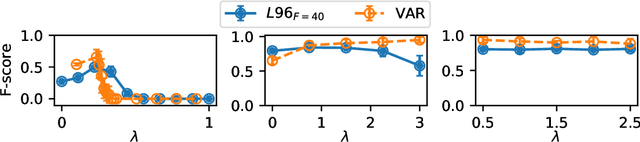
Granger causality is a commonly used method for uncovering information flow and dependencies in a time series. Here we introduce JGC (Jacobian Granger Causality), a neural network-based approach to Granger causality using the Jacobian as a measure of variable importance, and propose a thresholding procedure for inferring Granger causal variables using this measure. The resulting approach performs consistently well compared to other approaches in identifying Granger causal variables, the associated time lags, as well as interaction signs. Lastly, through the inclusion of a time variable, we show that this approach is able to learn the temporal dependencies for nonstationary systems whose Granger causal structures change in time.
Efficient Annotation and Learning for 3D Hand Pose Estimation: A Survey
Jun 07, 2022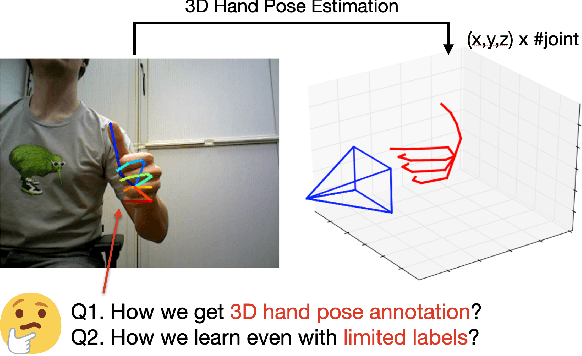
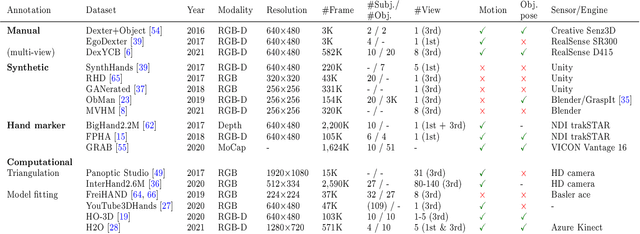
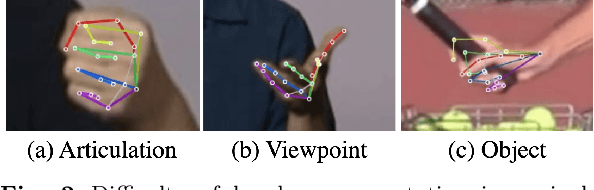
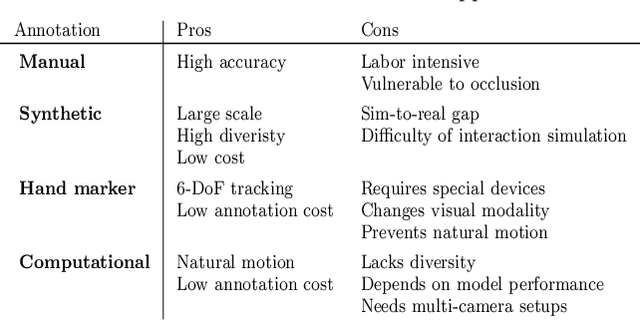
In this survey, we present comprehensive analysis of 3D hand pose estimation from the perspective of efficient annotation and learning. In particular, we study recent approaches for 3D hand pose annotation and learning methods with limited annotated data. In 3D hand pose estimation, collecting 3D hand pose annotation is a key step in developing hand pose estimators and their applications, such as video understanding, AR/VR, and robotics. However, acquiring annotated 3D hand poses is cumbersome, e.g., due to the difficulty of accessing 3D information and occlusion. Motivated by elucidating how recent works address the annotation issue, we investigated annotation methods classified as manual, synthetic-model-based, hand-sensor-based, and computational approaches. Since these annotation methods are not always available on a large scale, we examined methods of learning 3D hand poses when we do not have enough annotated data, namely self-supervised pre-training, semi-supervised learning, and domain adaptation. Based on the analysis of these efficient annotation and learning, we further discuss limitations and possible future directions of this field.
Multi-Modal Mutual Information (MuMMI) Training for Robust Self-Supervised Deep Reinforcement Learning
Jul 06, 2021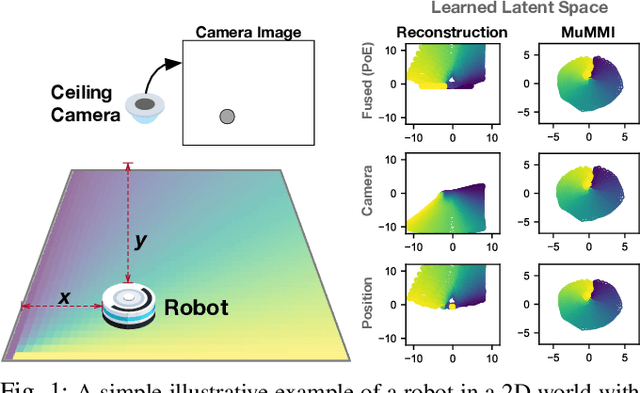
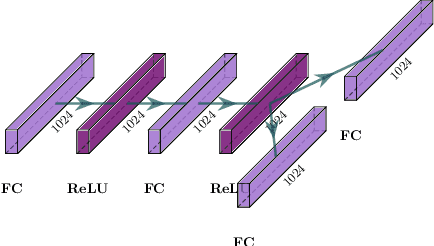
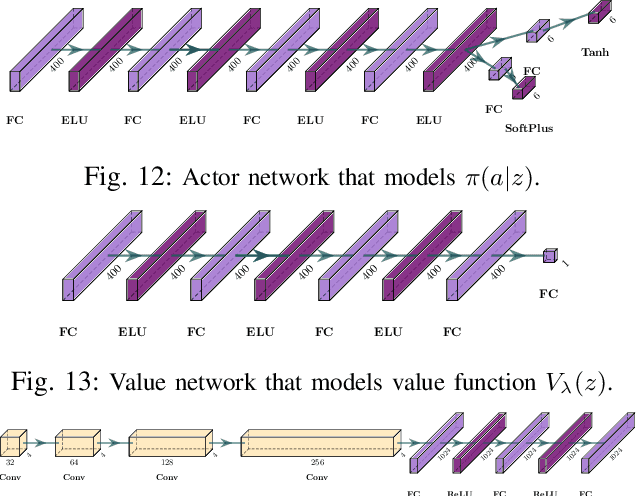
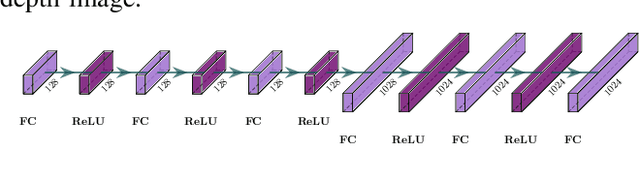
This work focuses on learning useful and robust deep world models using multiple, possibly unreliable, sensors. We find that current methods do not sufficiently encourage a shared representation between modalities; this can cause poor performance on downstream tasks and over-reliance on specific sensors. As a solution, we contribute a new multi-modal deep latent state-space model, trained using a mutual information lower-bound. The key innovation is a specially-designed density ratio estimator that encourages consistency between the latent codes of each modality. We tasked our method to learn policies (in a self-supervised manner) on multi-modal Natural MuJoCo benchmarks and a challenging Table Wiping task. Experiments show our method significantly outperforms state-of-the-art deep reinforcement learning methods, particularly in the presence of missing observations.