 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using consumer feedback from location-based services in PoI recommender systems for people with autism
Apr 21, 2022
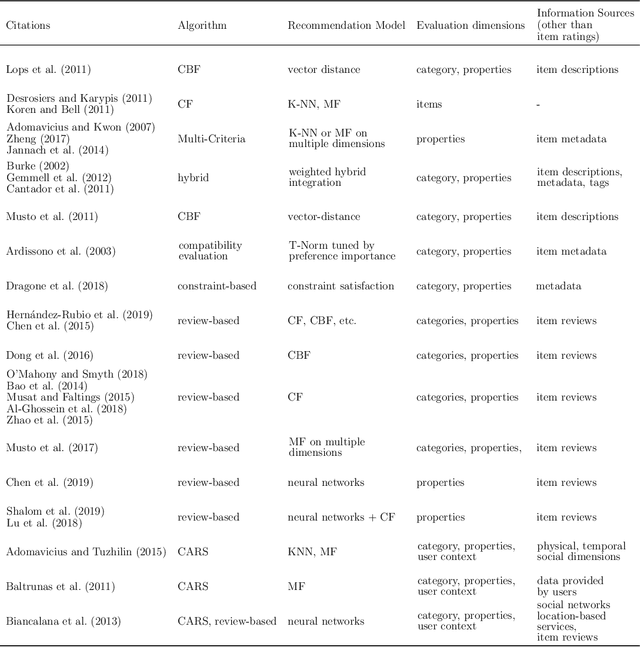
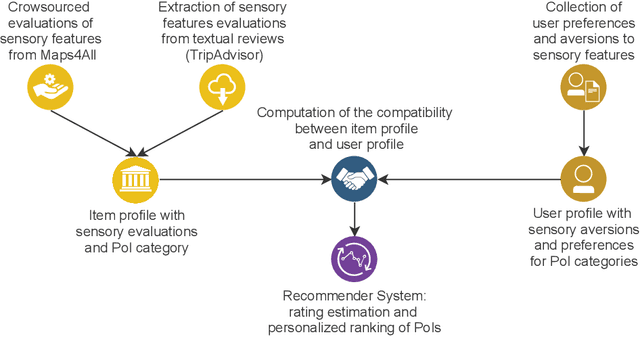
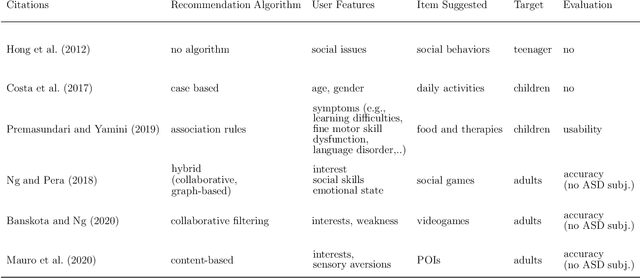
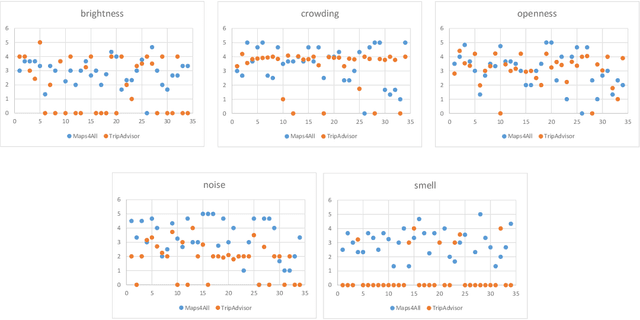
When suggesting Points of Interest (PoIs) to people with autism spectrum disorders, we must take into account that they have idiosyncratic sensory aversions to noise, brightness and other features that influence the way they perceive places. Therefore, recommender systems must deal with these aspects. However, the retrieval of sensory data about PoIs is a real challenge because most geographical information servers fail to provide this data. Moreover, ad-hoc crowdsourcing campaigns do not guarantee to cover large geographical areas and lack sustainability. Thus, we investigate the extraction of sensory data about places from the consumer feedback collected by location-based services, on which people spontaneously post reviews from all over the world. Specifically, we propose a model for the extraction of sensory data from the reviews about PoIs, and its integration in recommender systems to predict item ratings by considering both user preferences and compatibility information. We tested our approach with autistic and neurotypical people by integrating it into diverse recommendation algorithms. For the test, we used a dataset built in a crowdsourcing campaign and another one extracted from TripAdvisor reviews. The results show that the algorithms obtain the highest accuracy and ranking capability when using TripAdvisor data. Moreover, by jointly using these two datasets, the algorithms further improve their performance. These results encourage the use of consumer feedback as a reliable source of information about places in the development of inclusive recommender systems.
Shadow-Aware Dynamic Convolution for Shadow Removal
May 10, 2022
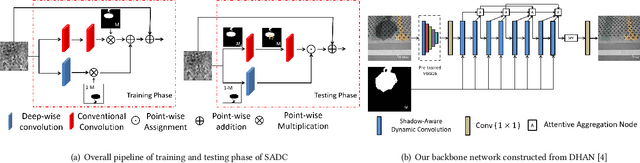
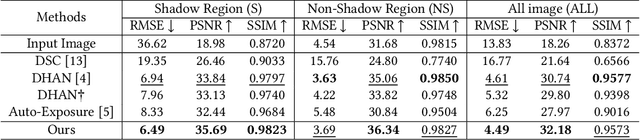
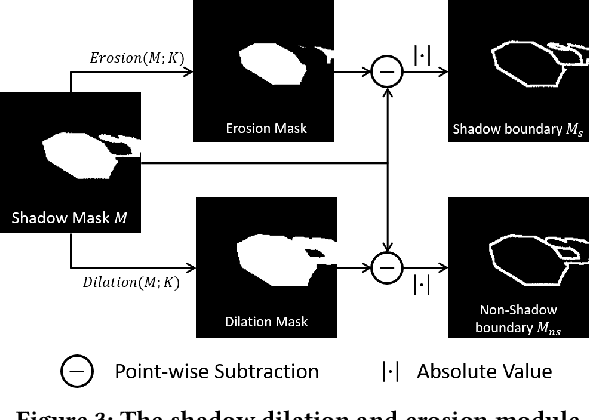
With a wide range of shadows in many collected images, shadow removal has aroused increasing attention since uncontaminated images are of vital importance for many downstream multimedia tasks. Current methods consider the same convolution operations for both shadow and non-shadow regions while ignoring the large gap between the color mappings for the shadow region and the non-shadow region, leading to poor quality of reconstructed images and a heavy computation burden. To solve this problem, this paper introduces a novel plug-and-play Shadow-Aware Dynamic Convolution (SADC) module to decouple the interdependence between the shadow region and the non-shadow region. Inspired by the fact that the color mapping of the non-shadow region is easier to learn, our SADC processes the non-shadow region with a lightweight convolution module in a computationally cheap manner and recovers the shadow region with a more complicated convolution module to ensure the quality of image reconstruction. Given that the non-shadow region often contains more background color information, we further develop a novel intra-convolution distillation loss to strengthen the information flow from the non-shadow region to the shadow region. Extensive experiments on the ISTD and SRD datasets show our method achieves better performance in shadow removal over many state-of-the-arts. Our code is available at https://github.com/xuyimin0926/SADC.
Entity-Graph Enhanced Cross-Modal Pretraining for Instance-level Product Retrieval
Jun 17, 2022

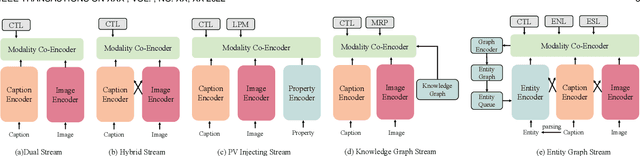

Our goal in this research is to study a more realistic environment in which we can conduct weakly-supervised multi-modal instance-level product retrieval for fine-grained product categories. We first contribute the Product1M datasets, and define two real practical instance-level retrieval tasks to enable the evaluations on the price comparison and personalized recommendations. For both instance-level tasks, how to accurately pinpoint the product target mentioned in the visual-linguistic data and effectively decrease the influence of irrelevant contents is quite challenging. To address this, we exploit to train a more effective cross-modal pertaining model which is adaptively capable of incorporating key concept information from the multi-modal data, by using an entity graph whose node and edge respectively denote the entity and the similarity relation between entities. Specifically, a novel Entity-Graph Enhanced Cross-Modal Pretraining (EGE-CMP) model is proposed for instance-level commodity retrieval, that explicitly injects entity knowledge in both node-based and subgraph-based ways into the multi-modal networks via a self-supervised hybrid-stream transformer, which could reduce the confusion between different object contents, thereby effectively guiding the network to focus on entities with real semantic. Experimental results well verify the efficacy and generalizability of our EGE-CMP, outperforming several SOTA cross-modal baselines like CLIP, UNITER and CAPTURE.
Exact Community Recovery in Correlated Stochastic Block Models
Mar 29, 2022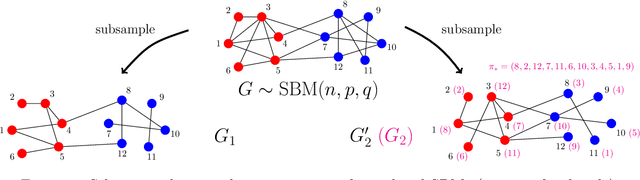
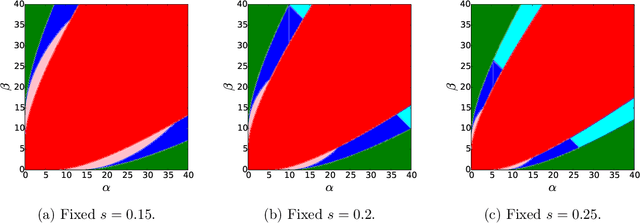
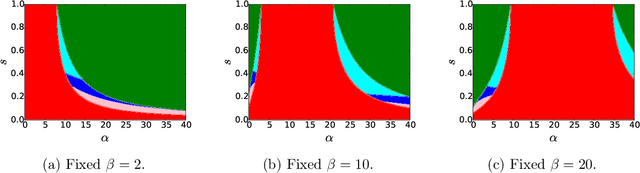
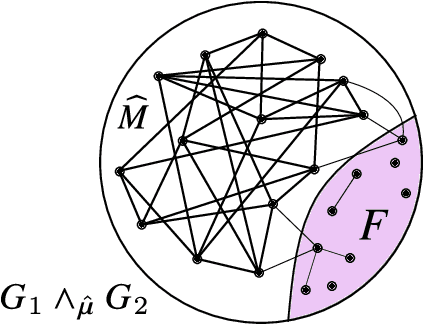
We consider the problem of learning latent community structure from multiple correlated networks. We study edge-correlated stochastic block models with two balanced communities, focusing on the regime where the average degree is logarithmic in the number of vertices. Our main result derives the precise information-theoretic threshold for exact community recovery using multiple correlated graphs. This threshold captures the interplay between the community recovery and graph matching tasks. In particular, we uncover and characterize a region of the parameter space where exact community recovery is possible using multiple correlated graphs, even though (1) this is information-theoretically impossible using a single graph and (2) exact graph matching is also information-theoretically impossible. In this regime, we develop a novel algorithm that carefully synthesizes algorithms from the community recovery and graph matching literatures.
The Role of Mutual Information in Variational Classifiers
Oct 22, 2020
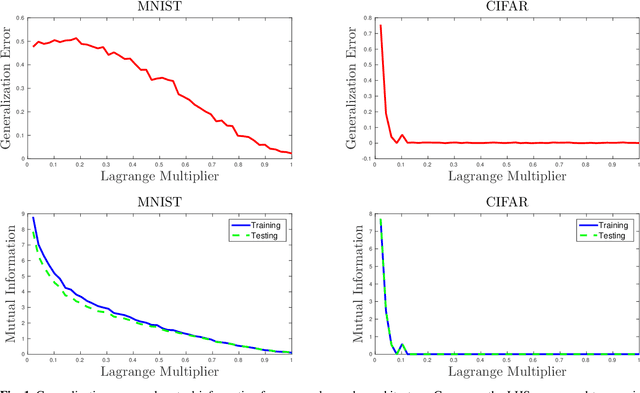
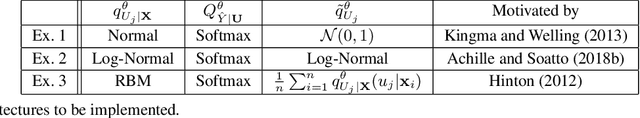
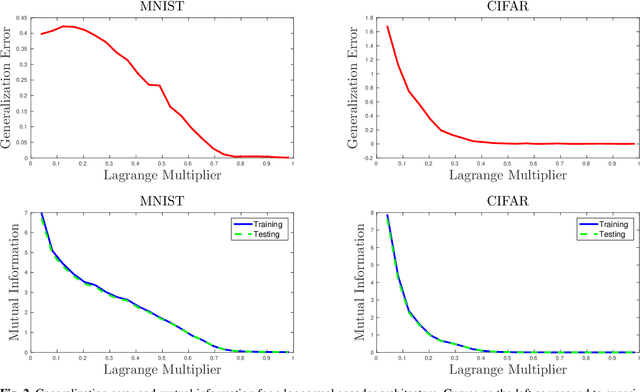
Overfitting data is a well-known phenomenon related with the generation of a model that mimics too closely (or exactly) a particular instance of data, and may therefore fail to predict future observations reliably. In practice, this behaviour is controlled by various--sometimes heuristics--regularization techniques, which are motivated by developing upper bounds to the generalization error. In this work, we study the generalization error of classifiers relying on stochastic encodings trained on the cross-entropy loss, which is often used in deep learning for classification problems. We derive bounds to the generalization error showing that there exists a regime where the generalization error is bounded by the mutual information between input features and the corresponding representations in the latent space, which are randomly generated according to the encoding distribution. Our bounds provide an information-theoretic understanding of generalization in the so-called class of variational classifiers, which are regularized by a Kullback-Leibler (KL) divergence term. These results give theoretical grounds for the highly popular KL term in variational inference methods that was already recognized to act effectively as a regularization penalty. We further observe connections with well studied notions such as Variational Autoencoders, Information Dropout, Information Bottleneck and Boltzmann Machines. Finally, we perform numerical experiments on MNIST and CIFAR datasets and show that mutual information is indeed highly representative of the behaviour of the generalization error.
Online Deep Clustering with Video Track Consistency
Jun 07, 2022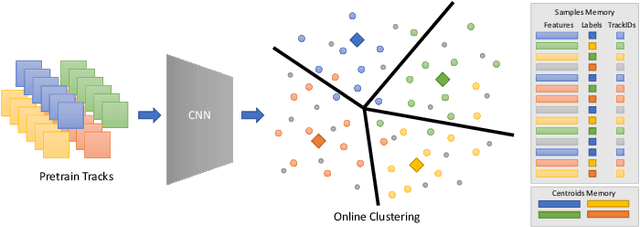
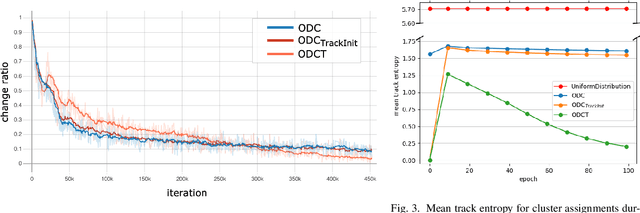


Several unsupervised and self-supervised approaches have been developed in recent years to learn visual features from large-scale unlabeled datasets. Their main drawback however is that these methods are hardly able to recognize visual features of the same object if it is simply rotated or the perspective of the camera changes. To overcome this limitation and at the same time exploit a useful source of supervision, we take into account video object tracks. Following the intuition that two patches in a track should have similar visual representations in a learned feature space, we adopt an unsupervised clustering-based approach and constrain such representations to be labeled as the same category since they likely belong to the same object or object part. Experimental results on two downstream tasks on different datasets demonstrate the effectiveness of our Online Deep Clustering with Video Track Consistency (ODCT) approach compared to prior work, which did not leverage temporal information. In addition we show that exploiting an unsupervised class-agnostic, yet noisy, track generator yields to better accuracy compared to relying on costly and precise track annotations.
Conversational Question Answering on Heterogeneous Sources
Apr 25, 2022
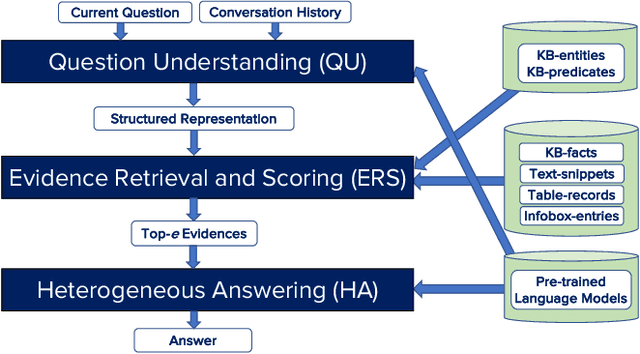
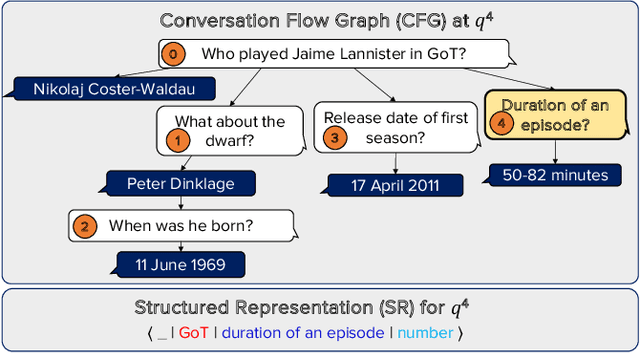

Conversational question answering (ConvQA) tackles sequential information needs where contexts in follow-up questions are left implicit. Current ConvQA systems operate over homogeneous sources of information: either a knowledge base (KB), or a text corpus, or a collection of tables. This paper addresses the novel issue of jointly tapping into all of these together, this way boosting answer coverage and confidence. We present CONVINSE, an end-to-end pipeline for ConvQA over heterogeneous sources, operating in three stages: i) learning an explicit structured representation of an incoming question and its conversational context, ii) harnessing this frame-like representation to uniformly capture relevant evidences from KB, text, and tables, and iii) running a fusion-in-decoder model to generate the answer. We construct and release the first benchmark, ConvMix, for ConvQA over heterogeneous sources, comprising 3000 real-user conversations with 16000 questions, along with entity annotations, completed question utterances, and question paraphrases. Experiments demonstrate the viability and advantages of our method, compared to state-of-the-art baselines.
Unsupervised Extractive Summarization using Pointwise Mutual Information
Feb 11, 2021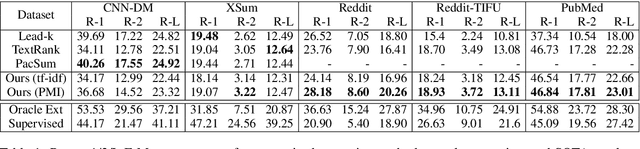
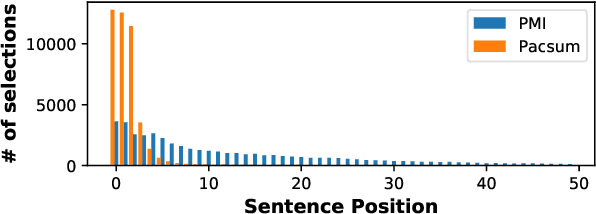

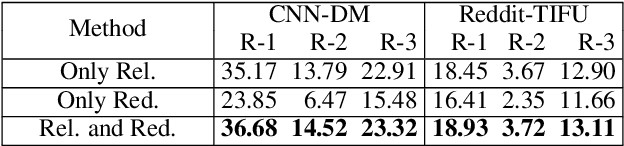
Unsupervised approaches to extractive summarization usually rely on a notion of sentence importance defined by the semantic similarity between a sentence and the document. We propose new metrics of relevance and redundancy using pointwise mutual information (PMI) between sentences, which can be easily computed by a pre-trained language model. Intuitively, a relevant sentence allows readers to infer the document content (high PMI with the document), and a redundant sentence can be inferred from the summary (high PMI with the summary). We then develop a greedy sentence selection algorithm to maximize relevance and minimize redundancy of extracted sentences. We show that our method outperforms similarity-based methods on datasets in a range of domains including news, medical journal articles, and personal anecdotes.
Learning from Natural Language Feedback
Apr 29, 2022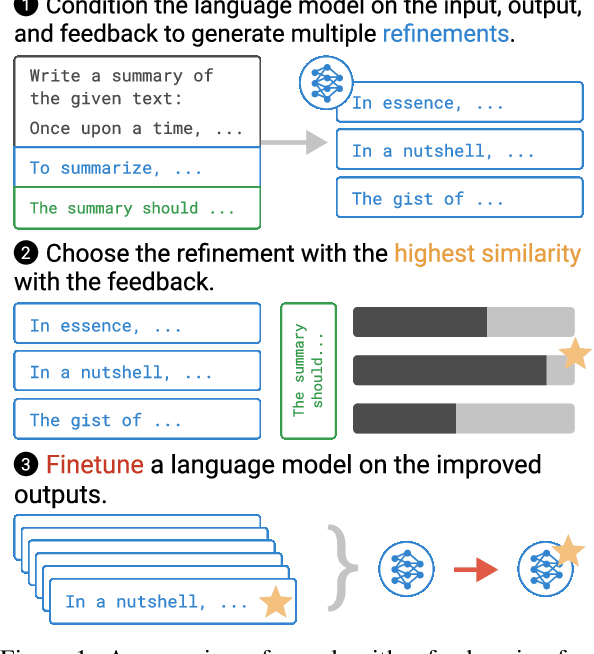
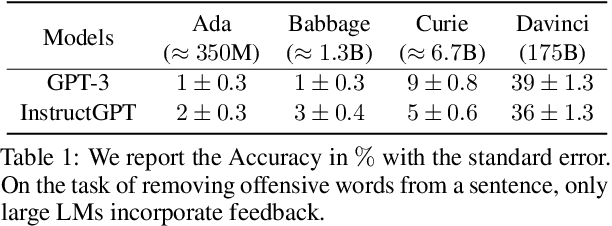
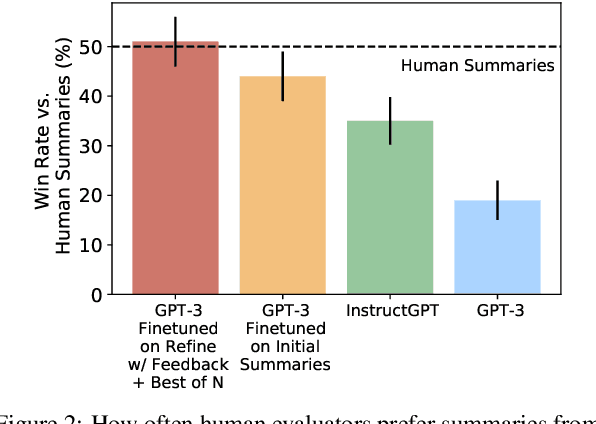
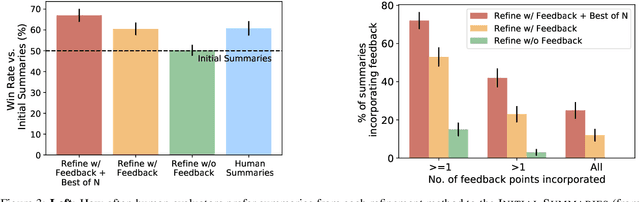
Pretrained language models often do not perform tasks in ways that are in line with our preferences, e.g., generating offensive text or factually incorrect summaries. Recent work approaches the above issue by learning from a simple form of human evaluation: comparisons between pairs of model-generated task outputs. Comparison feedback conveys limited information about human preferences per human evaluation. Here, we propose to learn from natural language feedback, which conveys more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm. First, we condition the language model on the initial output and feedback to generate many refinements. Second, we choose the refinement with the highest similarity to the feedback. Third, we finetune a language model to maximize the likelihood of the chosen refinement given the input. In synthetic experiments, we first evaluate whether language models accurately incorporate feedback to produce refinements, finding that only large language models (175B parameters) do so. Using only 100 samples of human-written feedback, our learning algorithm finetunes a GPT-3 model to roughly human-level summarization.
Class Balanced PixelNet for Neurological Image Segmentation
Apr 23, 2022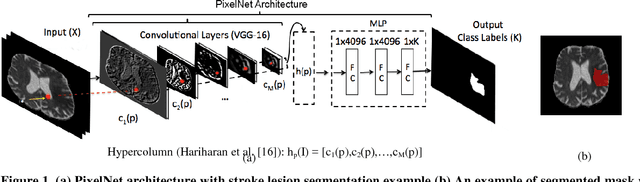
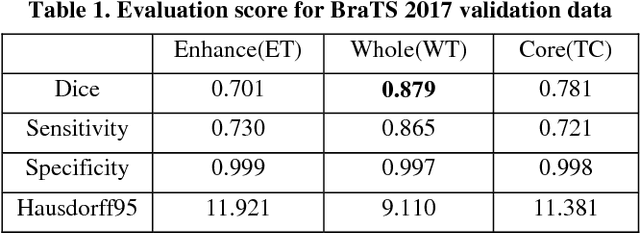
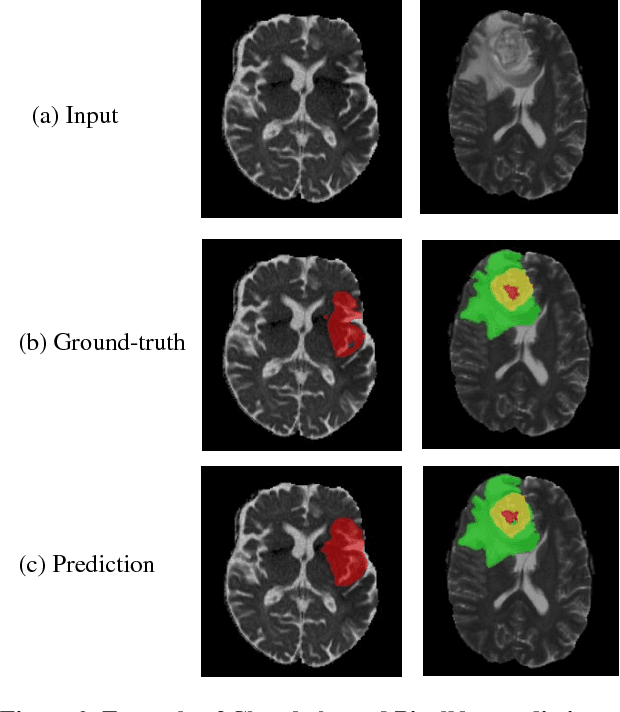
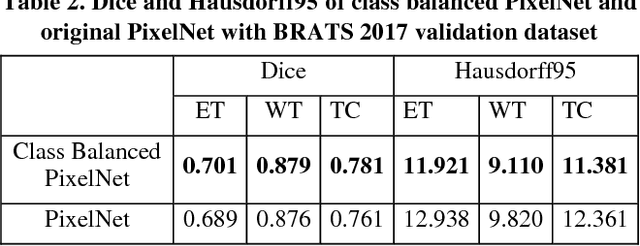
In this paper, we propose an automatic brain tumor segmentation approach (e.g., PixelNet) using a pixel-level convolutional neural network (CNN). The model extracts feature from multiple convolutional layers and concatenate them to form a hyper-column where samples a modest number of pixels for optimization. Hyper-column ensures both local and global contextual information for pixel-wise predictors. The model confirms the statistical efficiency by sampling a few pixels in the training phase where spatial redundancy limits the information learning among the neighboring pixels in conventional pixel-level semantic segmentation approaches. Besides, label skewness in training data leads the convolutional model often converge to certain classes which is a common problem in the medical dataset. We deal with this problem by selecting an equal number of pixels for all the classes in sampling time. The proposed model has achieved promising results in brain tumor and ischemic stroke lesion segmentation datasets.