 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrasting quadratic assignments for set-based representation learning
May 31, 2022
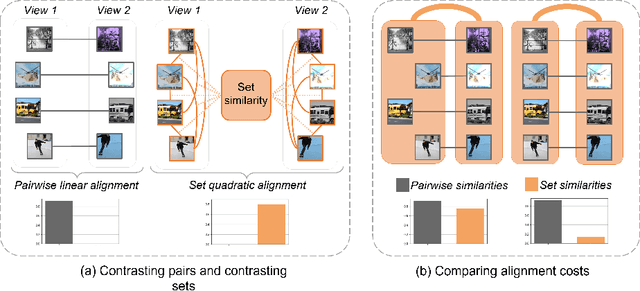

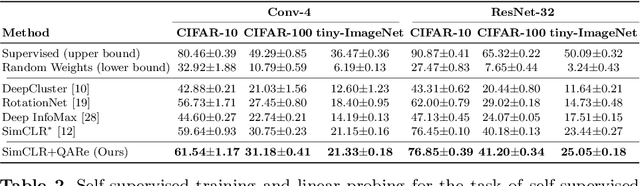
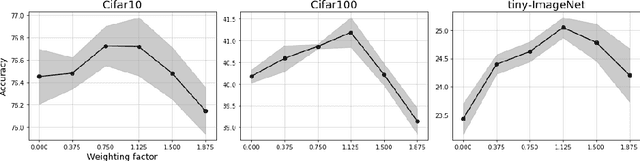
The standard approach to contrastive learning is to maximize the agreement between different views of the data. The views are ordered in pairs, such that they are either positive, encoding different views of the same object, or negative, corresponding to views of different objects. The supervisory signal comes from maximizing the total similarity over positive pairs, while the negative pairs are needed to avoid collapse. In this work, we note that the approach of considering individual pairs cannot account for both intra-set and inter-set similarities when the sets are formed from the views of the data. It thus limits the information content of the supervisory signal available to train representations. We propose to go beyond contrasting individual pairs of objects by focusing on contrasting objects as sets. For this, we use combinatorial quadratic assignment theory designed to evaluate set and graph similarities and derive set-contrastive objective as a regularizer for contrastive learning methods. We conduct experiments and demonstrate that our method improves learned representations for the tasks of metric learning and self-supervised classification.
Neural Maximum A Posteriori Estimation on Unpaired Data for Motion Deblurring
Apr 26, 2022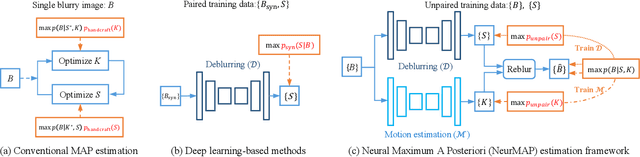
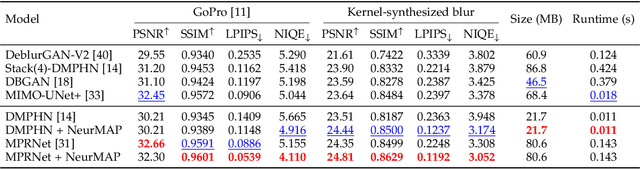

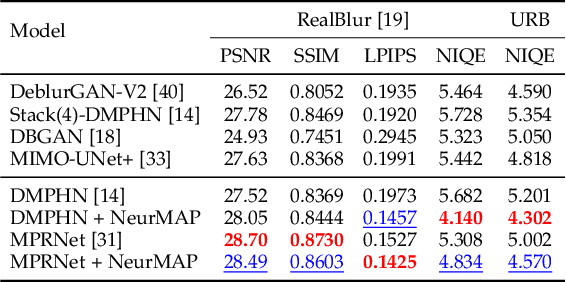
Real-world dynamic scene deblurring has long been a challenging task since paired blurry-sharp training data is unavailable. Conventional Maximum A Posteriori estimation and deep learning-based deblurring methods are restricted by handcrafted priors and synthetic blurry-sharp training pairs respectively, thereby failing to generalize to real dynamic blurriness. To this end, we propose a Neural Maximum A Posteriori (NeurMAP) estimation framework for training neural networks to recover blind motion information and sharp content from unpaired data. The proposed NeruMAP consists of a motion estimation network and a deblurring network which are trained jointly to model the (re)blurring process (i.e. likelihood function). Meanwhile, the motion estimation network is trained to explore the motion information in images by applying implicit dynamic motion prior, and in return enforces the deblurring network training (i.e. providing sharp image prior). The proposed NeurMAP is an orthogonal approach to existing deblurring neural networks, and is the first framework that enables training image deblurring networks on unpaired datasets. Experiments demonstrate our superiority on both quantitative metrics and visual quality over state-of-the-art methods. Codes are available on https://github.com/yjzhang96/NeurMAP-deblur.
Deep morphological recognition of kidney stones using intra-operative endoscopic digital videos
May 12, 2022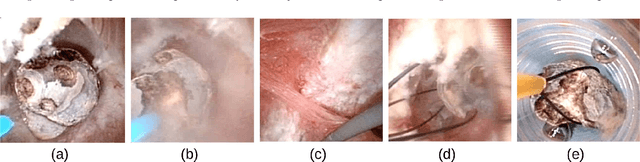

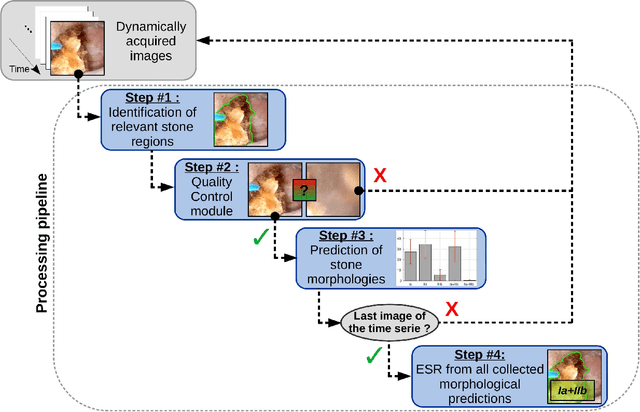
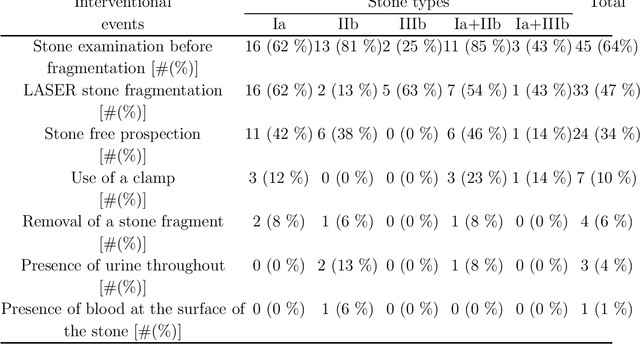
The collection and the analysis of kidney stone morphological criteria are essential for an aetiological diagnosis of stone disease. However, in-situ LASER-based fragmentation of urinary stones, which is now the most established chirurgical intervention, may destroy the morphology of the targeted stone. In the current study, we assess the performance and added value of processing complete digital endoscopic video sequences for the automatic recognition of stone morphological features during a standard-of-care intra-operative session. To this end, a computer-aided video classifier was developed to predict in-situ the morphology of stone using an intra-operative digital endoscopic video acquired in a clinical setting. The proposed technique was evaluated on pure (i.e. include one morphology) and mixed (i.e. include at least two morphologies) stones involving "Ia/Calcium Oxalate Monohydrate (COM)", "IIb/ Calcium Oxalate Dihydrate (COD)" and "IIIb/Uric Acid (UA)" morphologies. 71 digital endoscopic videos (50 exhibited only one morphological type and 21 displayed two) were analyzed using the proposed video classifier (56840 frames processed in total). Using the proposed approach, diagnostic performances (averaged over both pure and mixed stone types) were as follows: balanced accuracy=88%, sensitivity=80%, specificity=95%, precision=78% and F1-score=78%. The obtained results demonstrate that AI applied on digital endoscopic video sequences is a promising tool for collecting morphological information during the time-course of the stone fragmentation process without resorting to any human intervention for stone delineation or selection of good quality steady frames. To this end, irrelevant image information must be removed from the prediction process at both frame and pixel levels, which is now feasible thanks to the use of AI-dedicated networks.
Instance-Specific Feature Propagation for Referring Segmentation
Apr 26, 2022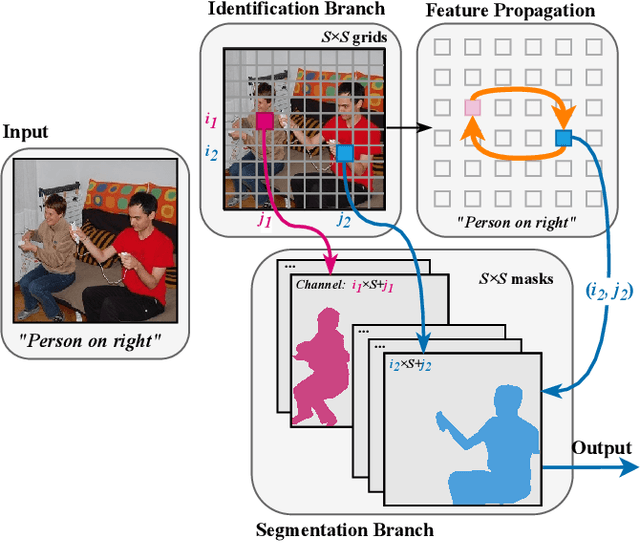

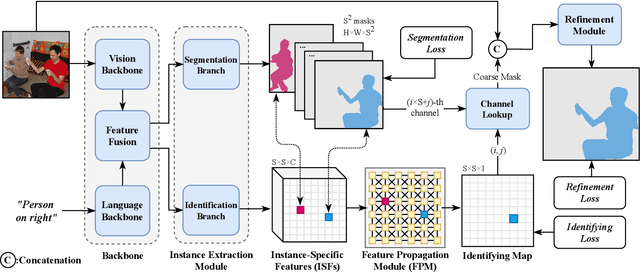
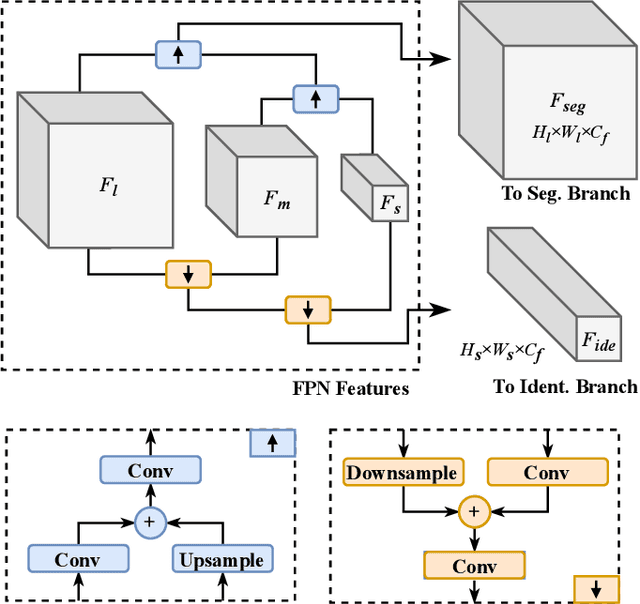
Referring segmentation aims to generate a segmentation mask for the target instance indicated by a natural language expression. There are typically two kinds of existing methods: one-stage methods that directly perform segmentation on the fused vision and language features; and two-stage methods that first utilize an instance segmentation model for instance proposal and then select one of these instances via matching them with language features. In this work, we propose a novel framework that simultaneously detects the target-of-interest via feature propagation and generates a fine-grained segmentation mask. In our framework, each instance is represented by an Instance-Specific Feature (ISF), and the target-of-referring is identified by exchanging information among all ISFs using our proposed Feature Propagation Module (FPM). Our instance-aware approach learns the relationship among all objects, which helps to better locate the target-of-interest than one-stage methods. Comparing to two-stage methods, our approach collaboratively and interactively utilizes both vision and language information for synchronous identification and segmentation. In the experimental tests, our method outperforms previous state-of-the-art methods on all three RefCOCO series datasets.
Improving Fairness in Graph Neural Networks via Mitigating Sensitive Attribute Leakage
Jun 07, 2022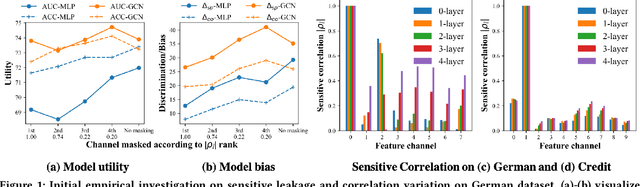
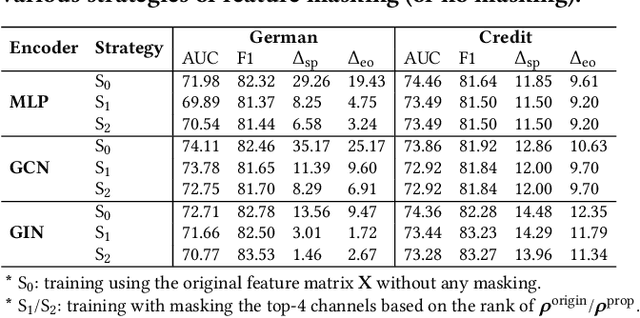
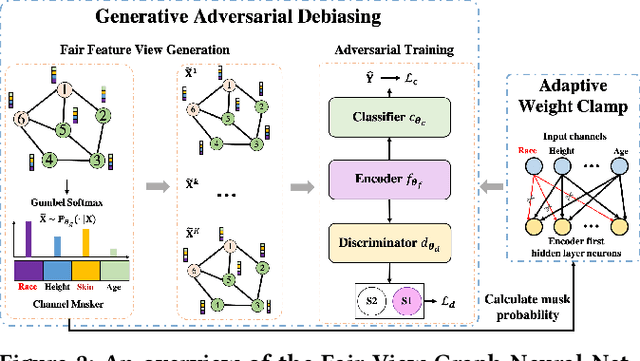

Graph Neural Networks (GNNs) have shown great power in learning node representations on graphs. However, they may inherit historical prejudices from training data, leading to discriminatory bias in predictions. Although some work has developed fair GNNs, most of them directly borrow fair representation learning techniques from non-graph domains without considering the potential problem of sensitive attribute leakage caused by feature propagation in GNNs. However, we empirically observe that feature propagation could vary the correlation of previously innocuous non-sensitive features to the sensitive ones. This can be viewed as a leakage of sensitive information which could further exacerbate discrimination in predictions. Thus, we design two feature masking strategies according to feature correlations to highlight the importance of considering feature propagation and correlation variation in alleviating discrimination. Motivated by our analysis, we propose Fair View Graph Neural Network (FairVGNN) to generate fair views of features by automatically identifying and masking sensitive-correlated features considering correlation variation after feature propagation. Given the learned fair views, we adaptively clamp weights of the encoder to avoid using sensitive-related features. Experiments on real-world datasets demonstrate that FairVGNN enjoys a better trade-off between model utility and fairness. Our code is publicly available at \href{https://github.com/YuWVandy/FairVGNN}{\textcolor{blue}{https://github.com/YuWVandy/FairVGNN}}.
A Span Extraction Approach for Information Extraction on Visually-Rich Documents
Jun 02, 2021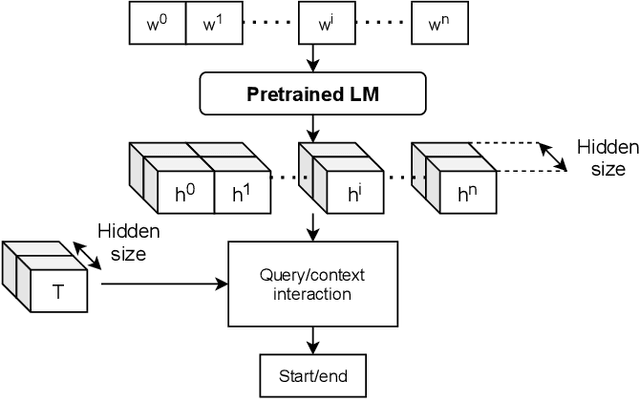

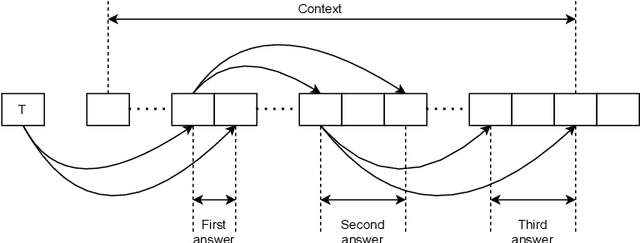

Information extraction (IE) from visually-rich documents (VRDs) has achieved SOTA performance recently thanks to the adaptation of Transformer-based language models, which demonstrates great potential of pre-training methods. In this paper, we present a new approach to improve the capability of language model pre-training on VRDs. Firstly, we introduce a new IE model that is query-based and employs the span extraction formulation instead of the commonly used sequence labelling approach. Secondly, to further extend the span extraction formulation, we propose a new training task which focuses on modelling the relationships between semantic entities within a document. This task enables the spans to be extracted recursively and can be used as both a pre-training objective as well as an IE downstream task. Evaluation on various datasets of popular business documents (invoices, receipts) shows that our proposed method can improve the performance of existing models significantly, while providing a mechanism to accumulate model knowledge from multiple downstream IE tasks.
Out-of-Domain Evaluation of Finnish Dependency Parsing
Apr 22, 2022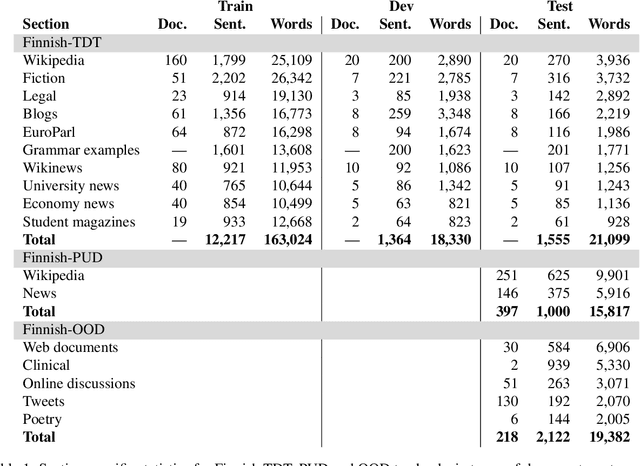

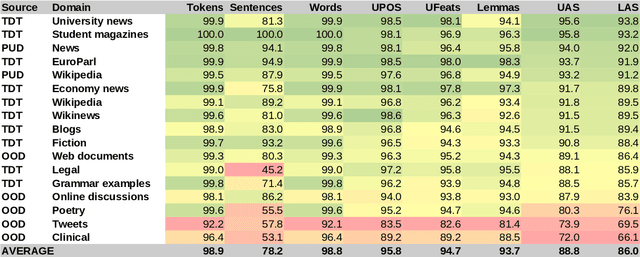
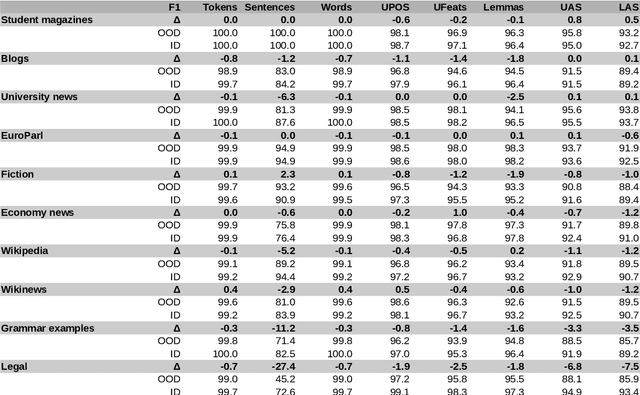
The prevailing practice in the academia is to evaluate the model performance on in-domain evaluation data typically set aside from the training corpus. However, in many real world applications the data on which the model is applied may very substantially differ from the characteristics of the training data. In this paper, we focus on Finnish out-of-domain parsing by introducing a novel UD Finnish-OOD out-of-domain treebank including five very distinct data sources (web documents, clinical, online discussions, tweets, and poetry), and a total of 19,382 syntactic words in 2,122 sentences released under the Universal Dependencies framework. Together with the new treebank, we present extensive out-of-domain parsing evaluation utilizing the available section-level information from three different Finnish UD treebanks (TDT, PUD, OOD). Compared to the previously existing treebanks, the new Finnish-OOD is shown include sections more challenging for the general parser, creating an interesting evaluation setting and yielding valuable information for those applying the parser outside of its training domain.
Adversarial Mutual Information for Text Generation
Jun 30, 2020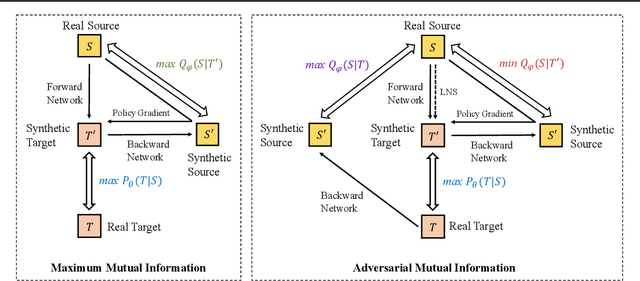
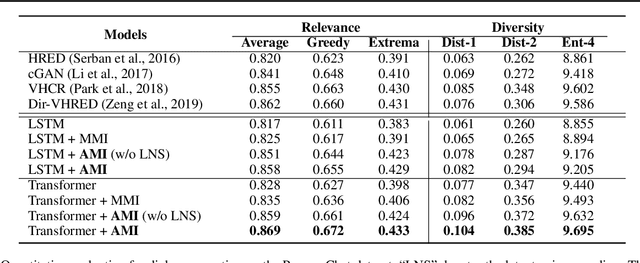

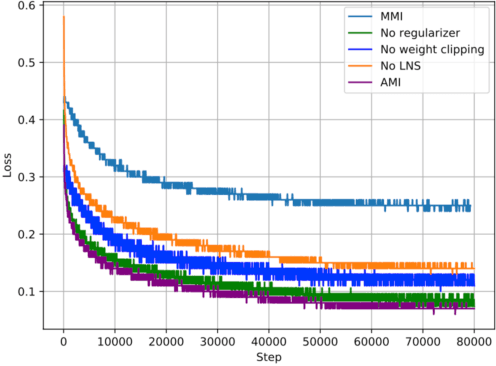
Recent advances in maximizing mutual information (MI) between the source and target have demonstrated its effectiveness in text generation. However, previous works paid little attention to modeling the backward network of MI (i.e., dependency from the target to the source), which is crucial to the tightness of the variational information maximization lower bound. In this paper, we propose Adversarial Mutual Information (AMI): a text generation framework which is formed as a novel saddle point (min-max) optimization aiming to identify joint interactions between the source and target. Within this framework, the forward and backward networks are able to iteratively promote or demote each other's generated instances by comparing the real and synthetic data distributions. We also develop a latent noise sampling strategy that leverages random variations at the high-level semantic space to enhance the long term dependency in the generation process. Extensive experiments based on different text generation tasks demonstrate that the proposed AMI framework can significantly outperform several strong baselines, and we also show that AMI has potential to lead to a tighter lower bound of maximum mutual information for the variational information maximization problem.
Asymmetric Learned Image Compression with Multi-Scale Residual Block, Importance Map, and Post-Quantization Filtering
Jun 21, 2022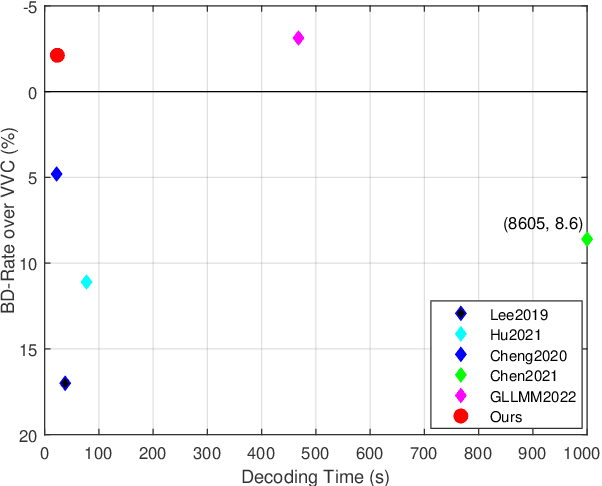
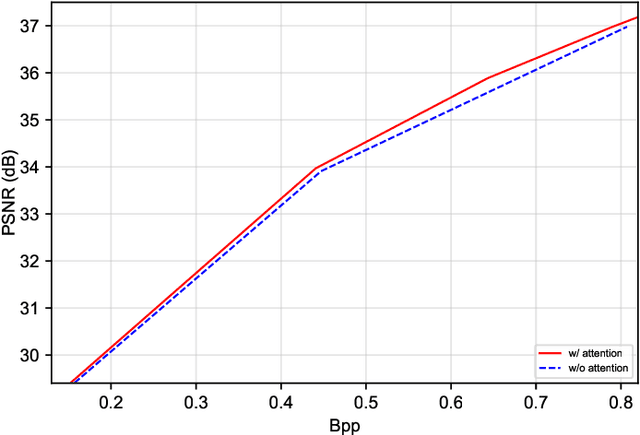


Recently, deep learning-based image compression has made signifcant progresses, and has achieved better ratedistortion (R-D) performance than the latest traditional method, H.266/VVC, in both subjective metric and the more challenging objective metric. However, a major problem is that many leading learned schemes cannot maintain a good trade-off between performance and complexity. In this paper, we propose an effcient and effective image coding framework, which achieves similar R-D performance with lower complexity than the state of the art. First, we develop an improved multi-scale residual block (MSRB) that can expand the receptive feld and is easier to obtain global information. It can further capture and reduce the spatial correlation of the latent representations. Second, a more advanced importance map network is introduced to adaptively allocate bits to different regions of the image. Third, we apply a 2D post-quantization flter (PQF) to reduce the quantization error, motivated by the Sample Adaptive Offset (SAO) flter in video coding. Moreover, We fnd that the complexity of encoder and decoder have different effects on image compression performance. Based on this observation, we design an asymmetric paradigm, in which the encoder employs three stages of MSRBs to improve the learning capacity, whereas the decoder only needs one stage of MSRB to yield satisfactory reconstruction, thereby reducing the decoding complexity without sacrifcing performance. Experimental results show that compared to the state-of-the-art method, the encoding and decoding time of the proposed method are about 17 times faster, and the R-D performance is only reduced by less than 1% on both Kodak and Tecnick datasets, which is still better than H.266/VVC(4:4:4) and other recent learning-based methods. Our source code is publicly available at https://github.com/fengyurenpingsheng.
LILE: Look In-Depth before Looking Elsewhere -- A Dual Attention Network using Transformers for Cross-Modal Information Retrieval in Histopathology Archives
Mar 04, 2022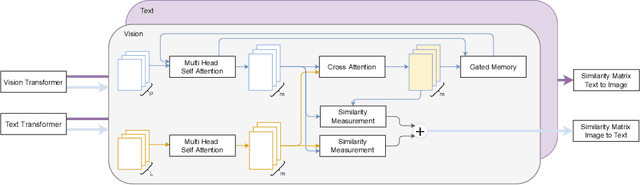
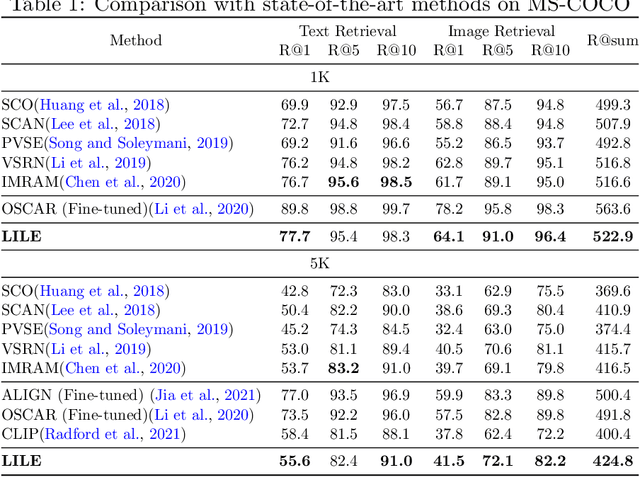
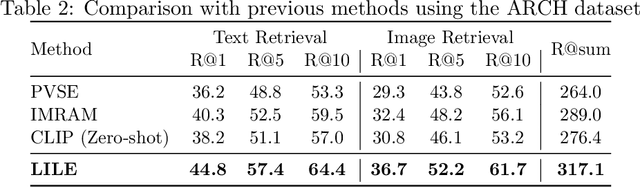
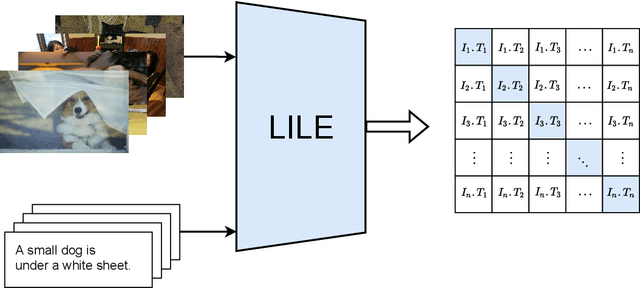
The volume of available data has grown dramatically in recent years in many applications. Furthermore, the age of networks that used multiple modalities separately has practically ended. Therefore, enabling bidirectional cross-modality data retrieval capable of processing has become a requirement for many domains and disciplines of research. This is especially true in the medical field, as data comes in a multitude of types, including various types of images and reports as well as molecular data. Most contemporary works apply cross attention to highlight the essential elements of an image or text in relation to the other modalities and try to match them together. However, regardless of their importance in their own modality, these approaches usually consider features of each modality equally. In this study, self-attention as an additional loss term will be proposed to enrich the internal representation provided into the cross attention module. This work suggests a novel architecture with a new loss term to help represent images and texts in the joint latent space. Experiment results on two benchmark datasets, i.e. MS-COCO and ARCH, show the effectiveness of the proposed method.