 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fake News Detection Using Majority Voting Technique
Mar 27, 2022
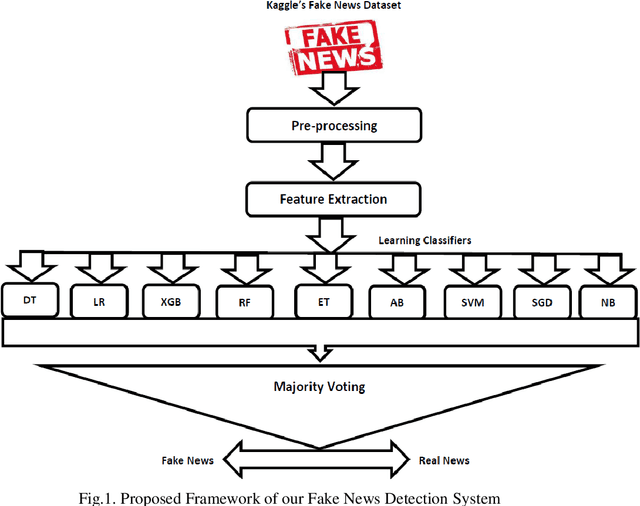
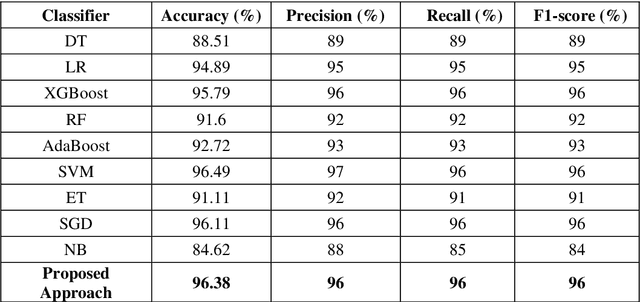
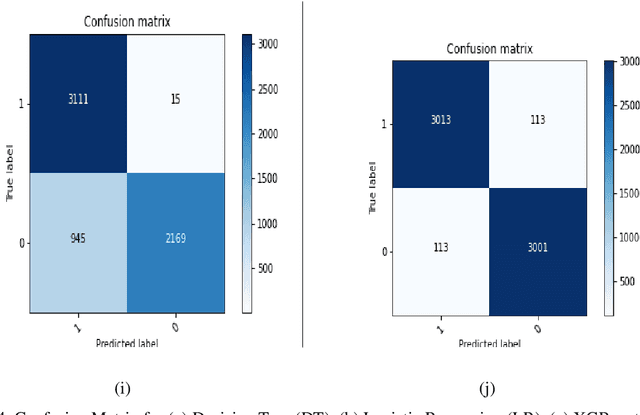
Due to the evolution of the Web and social network platforms it becomes very easy to disseminate the information. Peoples are creating and sharing more information than ever before, which may be misleading, misinformation or fake information. Fake news detection is a crucial and challenging task due to the unstructured nature of the available information. In the recent years, researchers have provided significant solutions to tackle with the problem of fake news detection, but due to its nature there are still many open issues. In this paper, we have proposed majority voting approach to detect fake news articles. We have used different textual properties of fake and real news. We have used publicly available fake news dataset, comprising of 20,800 news articles among which 10,387 are real and 10,413 are fake news labeled as binary 0 and 1. For the evaluation of our approach, we have used commonly used machine learning classifiers like, Decision Tree, Logistic Regression, XGBoost, Random Forest, Extra Trees, AdaBoost, SVM, SGD and Naive Bayes. Using the aforementioned classifiers, we built a multi-model fake news detection system using Majority Voting technique to achieve the more accurate results. The experimental results show that, our proposed approach achieved accuracy of 96.38%, precision of 96%, recall of 96% and F1-measure of 96%. The evaluation confirms that, Majority Voting technique achieved more acceptable results as compare to individual learning technique.
Deep morphological recognition of kidney stones using intra-operative endoscopic digital videos
May 12, 2022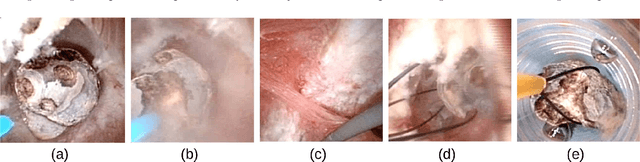

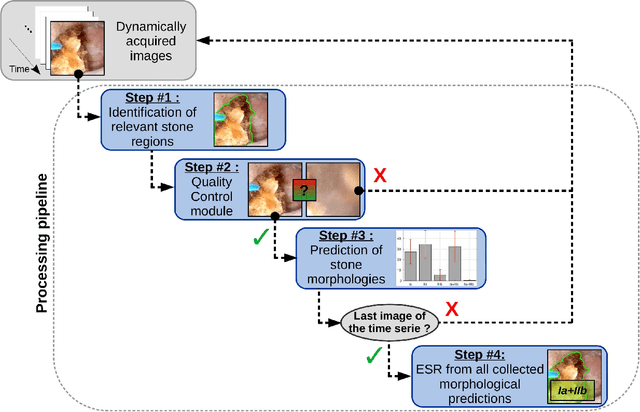
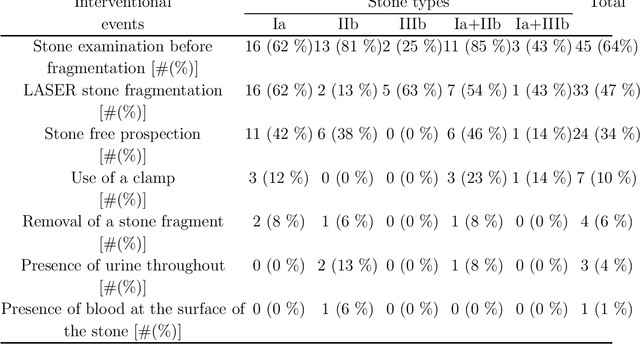
The collection and the analysis of kidney stone morphological criteria are essential for an aetiological diagnosis of stone disease. However, in-situ LASER-based fragmentation of urinary stones, which is now the most established chirurgical intervention, may destroy the morphology of the targeted stone. In the current study, we assess the performance and added value of processing complete digital endoscopic video sequences for the automatic recognition of stone morphological features during a standard-of-care intra-operative session. To this end, a computer-aided video classifier was developed to predict in-situ the morphology of stone using an intra-operative digital endoscopic video acquired in a clinical setting. The proposed technique was evaluated on pure (i.e. include one morphology) and mixed (i.e. include at least two morphologies) stones involving "Ia/Calcium Oxalate Monohydrate (COM)", "IIb/ Calcium Oxalate Dihydrate (COD)" and "IIIb/Uric Acid (UA)" morphologies. 71 digital endoscopic videos (50 exhibited only one morphological type and 21 displayed two) were analyzed using the proposed video classifier (56840 frames processed in total). Using the proposed approach, diagnostic performances (averaged over both pure and mixed stone types) were as follows: balanced accuracy=88%, sensitivity=80%, specificity=95%, precision=78% and F1-score=78%. The obtained results demonstrate that AI applied on digital endoscopic video sequences is a promising tool for collecting morphological information during the time-course of the stone fragmentation process without resorting to any human intervention for stone delineation or selection of good quality steady frames. To this end, irrelevant image information must be removed from the prediction process at both frame and pixel levels, which is now feasible thanks to the use of AI-dedicated networks.
Symmetric Private Information Retrieval with User-Side Common Randomness
May 12, 2021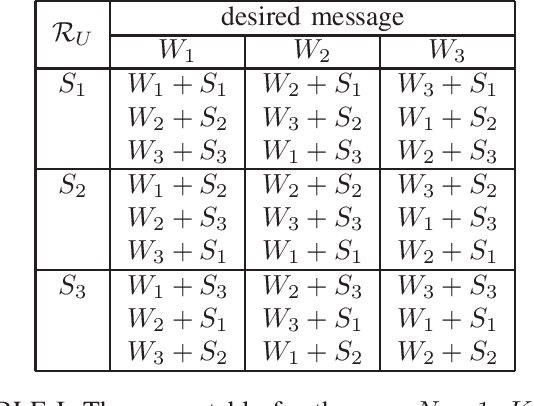
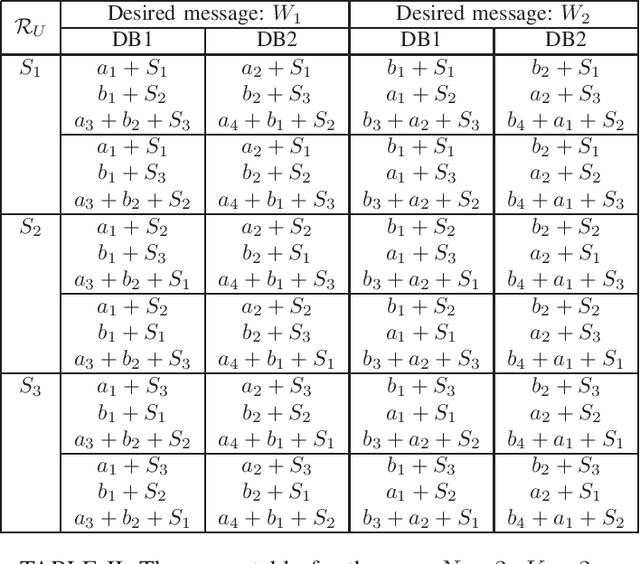
We consider the problem of symmetric private information retrieval (SPIR) with user-side common randomness. In SPIR, a user retrieves a message out of $K$ messages from $N$ non-colluding and replicated databases in such a way that no single database knows the retrieved message index (user privacy), and the user gets to know nothing further than the retrieved message (database privacy). SPIR has a capacity smaller than the PIR capacity which requires only user privacy, is infeasible in the case of a single database, and requires shared common randomness among the databases. We introduce a new variant of SPIR where the user is provided with a random subset of the shared database common randomness, which is unknown to the databases. We determine the exact capacity region of the triple $(d, \rho_S, \rho_U)$, where $d$ is the download cost, $\rho_S$ is the amount of shared database (server) common randomness, and $\rho_U$ is the amount of available user-side common randomness. We show that with a suitable amount of $\rho_U$, this new SPIR achieves the capacity of conventional PIR. As a corollary, single-database SPIR becomes feasible. Further, the presence of user-side $\rho_U$ reduces the amount of required server-side $\rho_S$.
Extracting Image Characteristics to Predict Crowdfunding Success
Mar 28, 2022
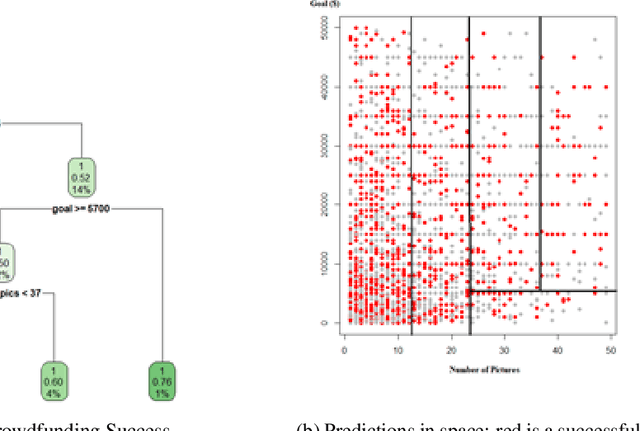
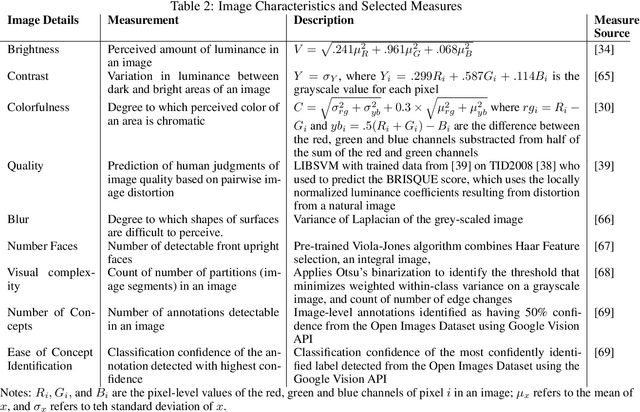
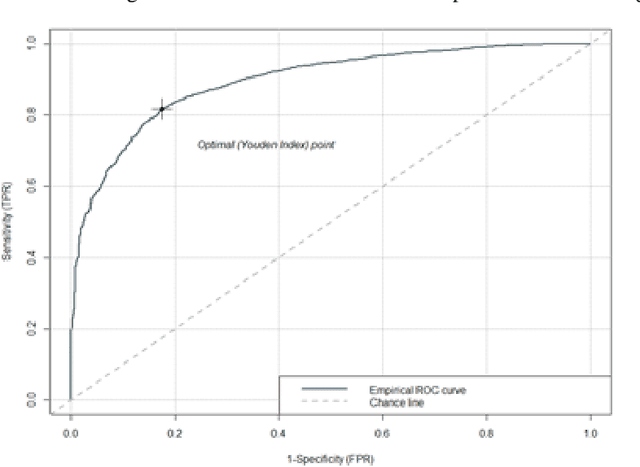
Despite an increase in the empirical study of crowdfunding platforms and the prevalence of visual information, operations management and marketing literature has yet to explore the role that image characteristics play in crowdfunding success. The authors of this manuscript begin by synthesizing literature on visual processing to identify several image characteristics that are likely to shape crowdfunding success. After detailing measures for each image characteristic, they use them as part of a machine-learning algorithm (Bayesian additive trees), along with project characteristics and textual information, to predict crowdfunding success. Results show that the inclusion of these image characteristics substantially improves prediction over baseline project variables, as well as textual features. Furthermore, image characteristic variables exhibit high importance, similar to variables linked to the number of pictures and number of videos. This research therefore offers valuable resources to researchers and managers who are interested in the role of visual information in ensuring new product success.
A Look at Improving Robustness in Visual-inertial SLAM by Moment Matching
May 27, 2022
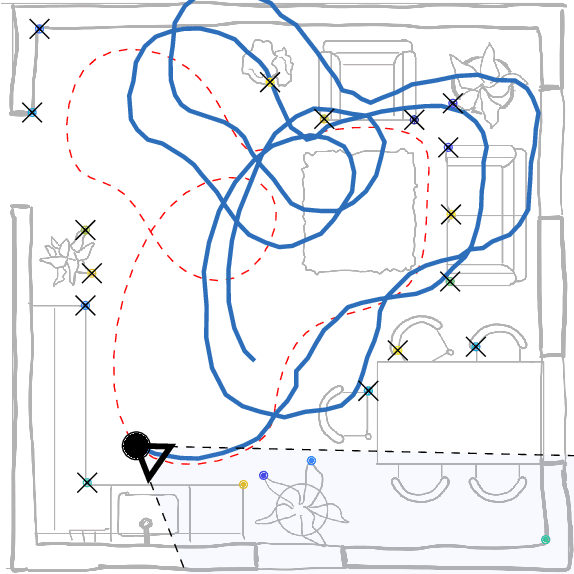
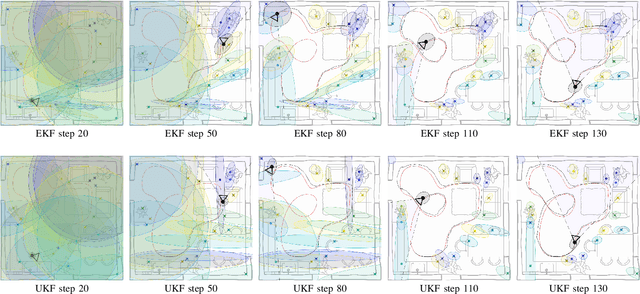
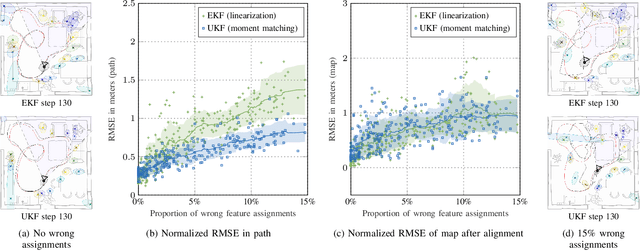
The fusion of camera sensor and inertial data is a leading method for ego-motion tracking in autonomous and smart devices. State estimation techniques that rely on non-linear filtering are a strong paradigm for solving the associated information fusion task. The de facto inference method in this space is the celebrated extended Kalman filter (EKF), which relies on first-order linearizations of both the dynamical and measurement model. This paper takes a critical look at the practical implications and limitations posed by the EKF, especially under faulty visual feature associations and the presence of strong confounding noise. As an alternative, we revisit the assumed density formulation of Bayesian filtering and employ a moment matching (unscented Kalman filtering) approach to both visual-inertial odometry and visual SLAM. Our results highlight important aspects in robustness both in dynamics propagation and visual measurement updates, and we show state-of-the-art results on EuRoC MAV drone data benchmark.
Learning Optimal Representations with the Decodable Information Bottleneck
Sep 27, 2020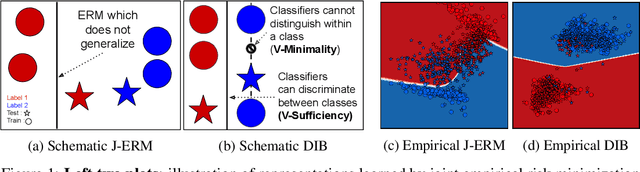
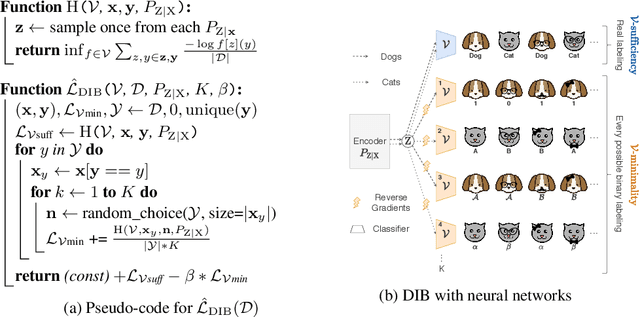

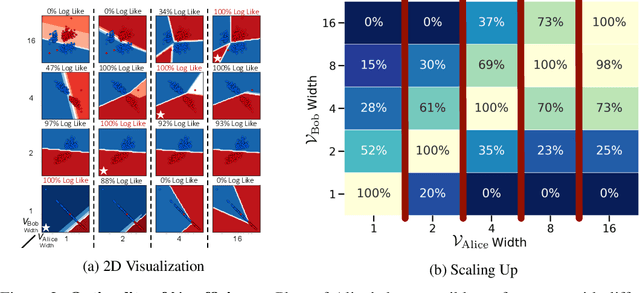
We address the question of characterizing and finding optimal representations for supervised learning. Traditionally, this question has been tackled using the Information Bottleneck, which compresses the inputs while retaining information about the targets, in a decoder-agnostic fashion. In machine learning, however, our goal is not compression but rather generalization, which is intimately linked to the predictive family or decoder of interest (e.g. linear classifier). We propose the Decodable Information Bottleneck (DIB) that considers information retention and compression from the perspective of the desired predictive family. As a result, DIB gives rise to representations that are optimal in terms of expected test performance and can be estimated with guarantees. Empirically, we show that the framework can be used to enforce a small generalization gap on downstream classifiers and to predict the generalization ability of neural networks.
Position Tracking using Likelihood Modeling of Channel Features with Gaussian Processes
Mar 24, 2022
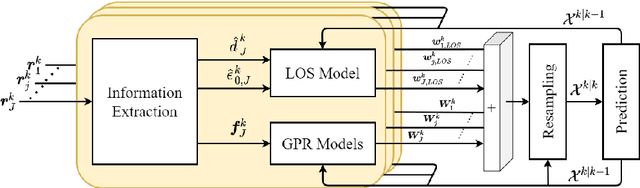
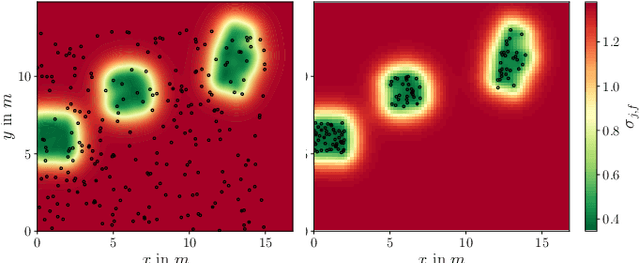

Recent localization frameworks exploit spatial information of complex channel measurements (CMs) to estimate accurate positions even in multipath propagation scenarios. State-of-the art CM fingerprinting(FP)-based methods employ convolutional neural networks (CNN) to extract the spatial information. However, they need spatially dense data sets (associated with high acquisition and maintenance efforts) to work well -- which is rarely the case in practical applications. If such data is not available (or its quality is low), we cannot compensate the performance degradation of CNN-based FP as they do not provide statistical position estimates, which prevents a fusion with other sources of information on the observation level. We propose a novel localization framework that adapts well to sparse datasets that only contain CMs of specific areas within the environment with strong multipath propagation. Our framework compresses CMs into informative features to unravel spatial information. It then regresses Gaussian processes (GPs) for each of them, which imply statistical observation models based on distance-dependent covariance kernels. Our framework combines the trained GPs with line-of-sight ranges and a dynamics model in a particle filter. Our measurements show that our approach outperforms state-of-the-art CNN fingerprinting (0.52 m vs. 1.3 m MAE) on spatially sparse data collected in a realistic industrial indoor environment.
Topological Data Analysis of Database Representations for Information Retrieval
Apr 04, 2021Appropriately representing elements in a database so that queries may be accurately matched is a central task in information retrieval. This recently has been achieved by embedding the graphical structure of the database into a manifold so that the hierarchy is preserved. Persistent homology provides a rigorous characterization for the database topology in terms of both its hierarchy and connectivity structure. We compute persistent homology on a variety of datasets and show that some commonly used embeddings fail to preserve the connectivity. Moreover, we show that embeddings which successfully retain the database topology coincide in persistent homology. We introduce the dilation-invariant bottleneck distance to capture this effect, which addresses metric distortion on manifolds. We use it to show that distances between topology-preserving embeddings of databases are small.
Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution
Jan 24, 2021

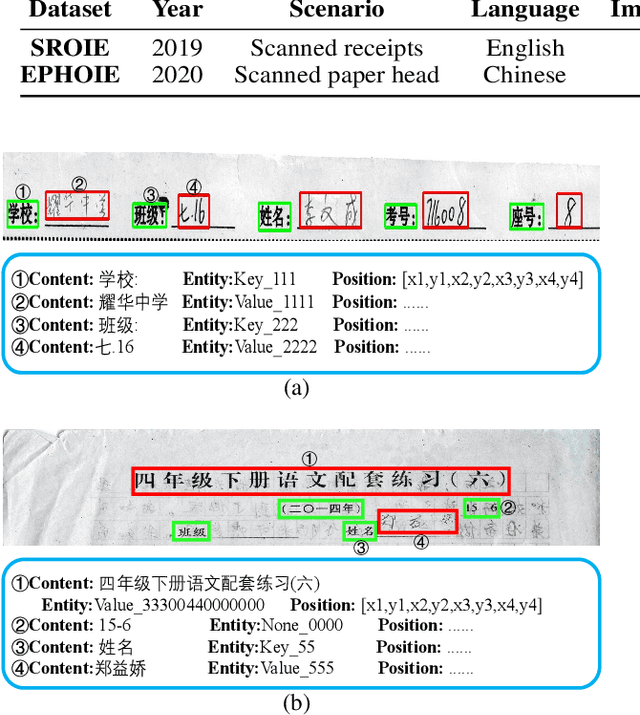
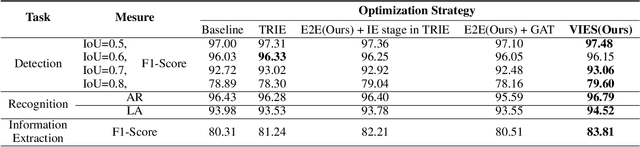
Visual information extraction (VIE) has attracted considerable attention recently owing to its various advanced applications such as document understanding, automatic marking and intelligent education. Most existing works decoupled this problem into several independent sub-tasks of text spotting (text detection and recognition) and information extraction, which completely ignored the high correlation among them during optimization. In this paper, we propose a robust visual information extraction system (VIES) towards real-world scenarios, which is a unified end-to-end trainable framework for simultaneous text detection, recognition and information extraction by taking a single document image as input and outputting the structured information. Specifically, the information extraction branch collects abundant visual and semantic representations from text spotting for multimodal feature fusion and conversely, provides higher-level semantic clues to contribute to the optimization of text spotting. Moreover, regarding the shortage of public benchmarks, we construct a fully-annotated dataset called EPHOIE (https://github.com/HCIILAB/EPHOIE), which is the first Chinese benchmark for both text spotting and visual information extraction. EPHOIE consists of 1,494 images of examination paper head with complex layouts and background, including a total of 15,771 Chinese handwritten or printed text instances. Compared with the state-of-the-art methods, our VIES shows significant superior performance on the EPHOIE dataset and achieves a 9.01% F-score gain on the widely used SROIE dataset under the end-to-end scenario.
MetaFormer: A Unified Meta Framework for Fine-Grained Recognition
Mar 05, 2022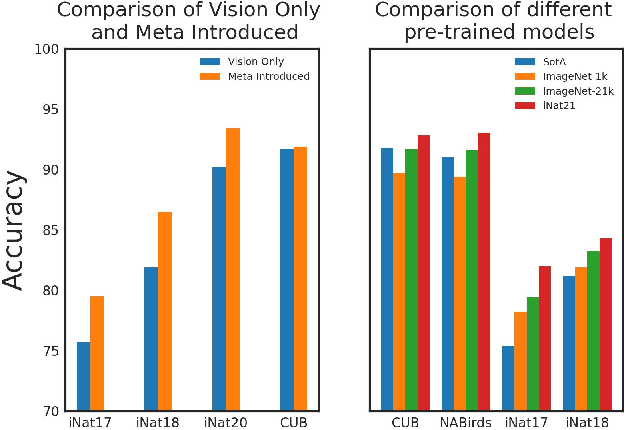
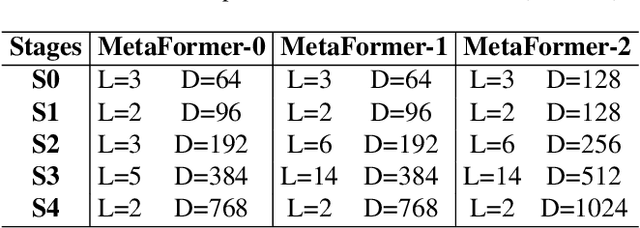
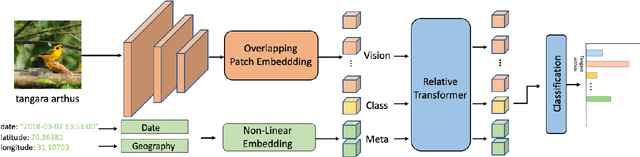
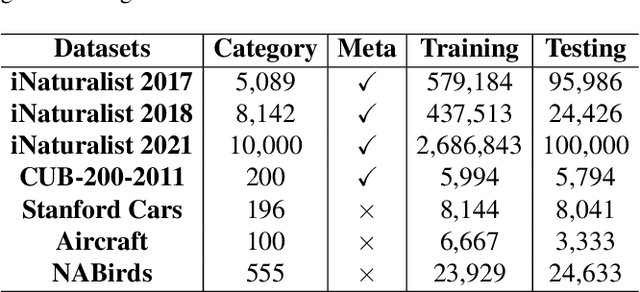
Fine-Grained Visual Classification(FGVC) is the task that requires recognizing the objects belonging to multiple subordinate categories of a super-category. Recent state-of-the-art methods usually design sophisticated learning pipelines to tackle this task. However, visual information alone is often not sufficient to accurately differentiate between fine-grained visual categories. Nowadays, the meta-information (e.g., spatio-temporal prior, attribute, and text description) usually appears along with the images. This inspires us to ask the question: Is it possible to use a unified and simple framework to utilize various meta-information to assist in fine-grained identification? To answer this problem, we explore a unified and strong meta-framework(MetaFormer) for fine-grained visual classification. In practice, MetaFormer provides a simple yet effective approach to address the joint learning of vision and various meta-information. Moreover, MetaFormer also provides a strong baseline for FGVC without bells and whistles. Extensive experiments demonstrate that MetaFormer can effectively use various meta-information to improve the performance of fine-grained recognition. In a fair comparison, MetaFormer can outperform the current SotA approaches with only vision information on the iNaturalist2017 and iNaturalist2018 datasets. Adding meta-information, MetaFormer can exceed the current SotA approaches by 5.9% and 5.3%, respectively. Moreover, MetaFormer can achieve 92.3% and 92.7% on CUB-200-2011 and NABirds, which significantly outperforms the SotA approaches. The source code and pre-trained models are released athttps://github.com/dqshuai/MetaFormer.