 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Finding a Landing Site on an Urban Area: A Multi-Resolution Probabilistic Approach
Apr 26, 2022



This paper considers the problem of finding a landing spot for a drone in a dense urban environment. The conflicting requirement of fast exploration and high resolution is solved using a multi-resolution approach, by which visual information is collected by the drone at decreasing altitudes so that spatial resolution of the acquired images increases monotonically. A probability distribution is used to capture the uncertainty of the decision process for each terrain patch. The distributions are updated as information from different altitudes is collected. When the confidence level for one of the patches becomes larger than a pre-specified threshold, suitability for landing is declared. One of the main building blocks of the approach is a semantic segmentation algorithm that attaches probabilities to each pixel of a single view. The decision algorithm combines these probabilities with a priori data and previous measurements to obtain the best estimates. Feasibility is illustrated by presenting a number of examples generated by a realistic closed-loop simulator.
Indirect-Instant Attention Optimization for Crowd Counting in Dense Scenes
Jun 12, 2022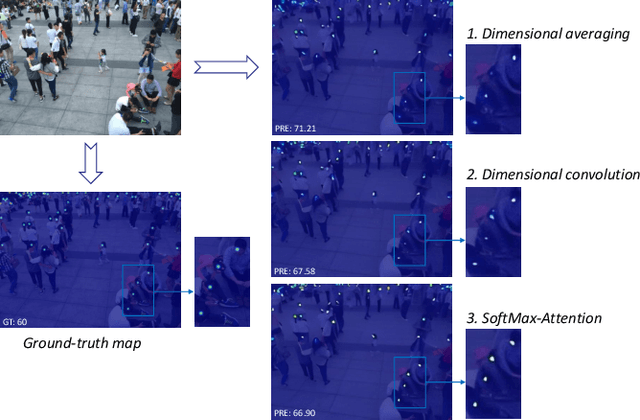
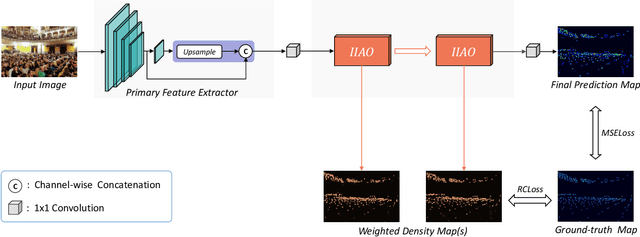
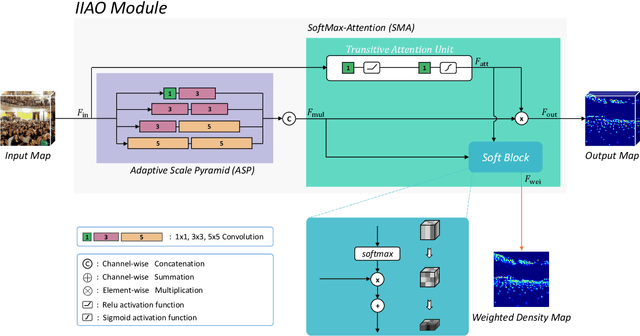
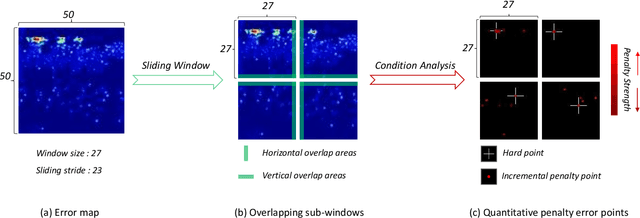
One of appealing approaches to guiding learnable parameter optimization, such as feature maps, is global attention, which enlightens network intelligence at a fraction of the cost. However, its loss calculation process still falls short: 1)We can only produce one-dimensional 'pseudo labels' for attention, since the artificial threshold involved in the procedure is not robust; 2) The attention awaiting loss calculation is necessarily high-dimensional, and decreasing it by convolution will inevitably introduce additional learnable parameters, thus confusing the source of the loss. To this end, we devise a simple but efficient Indirect-Instant Attention Optimization (IIAO) module based on SoftMax-Attention , which transforms high-dimensional attention map into a one-dimensional feature map in the mathematical sense for loss calculation midway through the network, while automatically providing adaptive multi-scale fusion to feature pyramid module. The special transformation yields relatively coarse features and, originally, the predictive fallibility of regions varies by crowd density distribution, so we tailor the Regional Correlation Loss (RCLoss) to retrieve continuous error-prone regions and smooth spatial information . Extensive experiments have proven that our approach surpasses previous SOTA methods in many benchmark datasets.
Enhancing Event-Level Sentiment Analysis with Structured Arguments
May 31, 2022

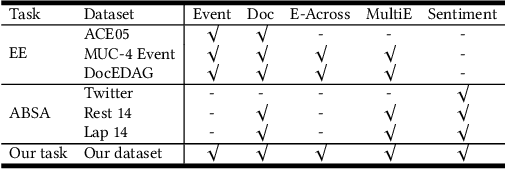
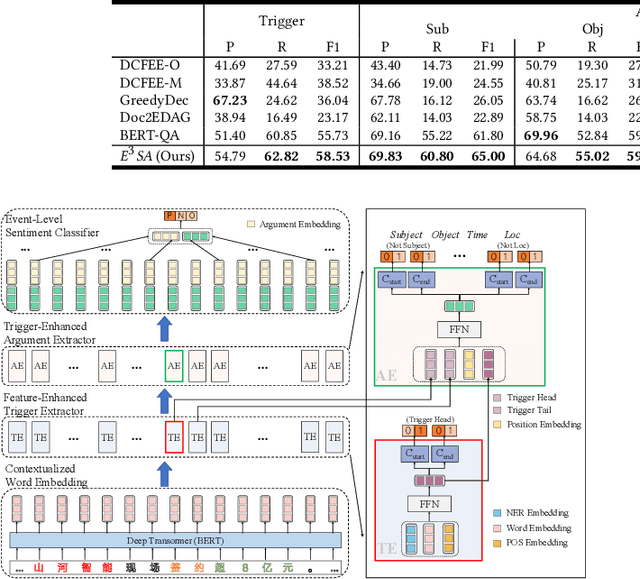
Previous studies about event-level sentiment analysis (SA) usually model the event as a topic, a category or target terms, while the structured arguments (e.g., subject, object, time and location) that have potential effects on the sentiment are not well studied. In this paper, we redefine the task as structured event-level SA and propose an End-to-End Event-level Sentiment Analysis ($\textit{E}^{3}\textit{SA}$) approach to solve this issue. Specifically, we explicitly extract and model the event structure information for enhancing event-level SA. Extensive experiments demonstrate the great advantages of our proposed approach over the state-of-the-art methods. Noting the lack of the dataset, we also release a large-scale real-world dataset with event arguments and sentiment labelling for promoting more researches\footnote{The dataset is available at https://github.com/zhangqi-here/E3SA}.
NeuralSympCheck: A Symptom Checking and Disease Diagnostic Neural Model with Logic Regularization
Jun 02, 2022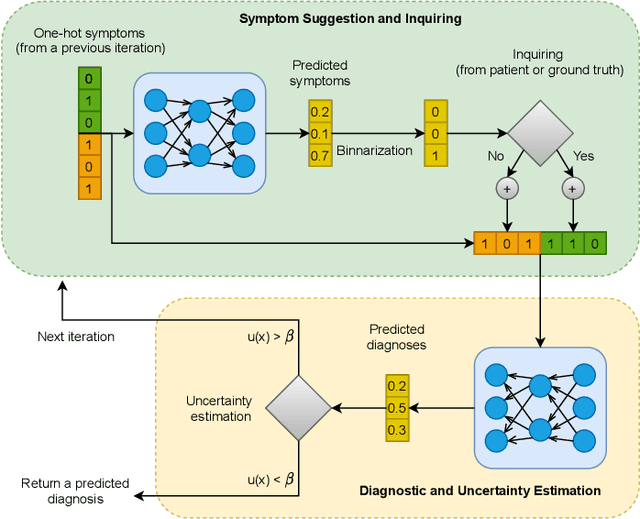
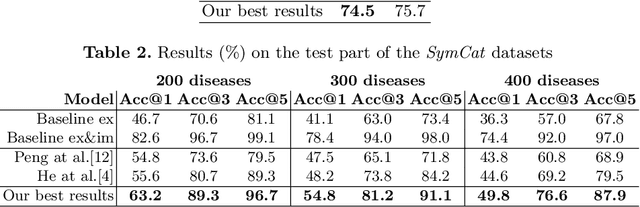
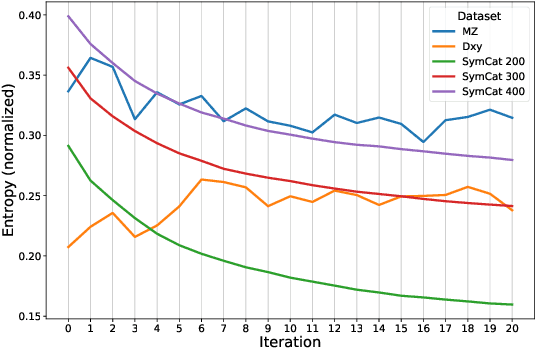
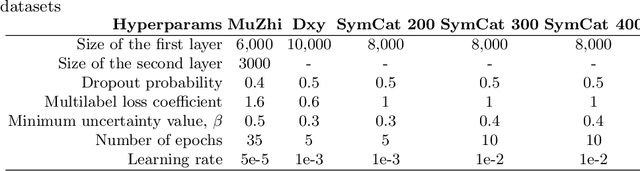
The symptom checking systems inquire users for their symptoms and perform a rapid and affordable medical assessment of their condition. The basic symptom checking systems based on Bayesian methods, decision trees, or information gain methods are easy to train and do not require significant computational resources. However, their drawbacks are low relevance of proposed symptoms and insufficient quality of diagnostics. The best results on these tasks are achieved by reinforcement learning models. Their weaknesses are the difficulty of developing and training such systems and limited applicability to cases with large and sparse decision spaces. We propose a new approach based on the supervised learning of neural models with logic regularization that combines the advantages of the different methods. Our experiments on real and synthetic data show that the proposed approach outperforms the best existing methods in the accuracy of diagnosis when the number of diagnoses and symptoms is large.
Multi-modal Sensor Data Fusion for In-situ Classification of Animal Behavior Using Accelerometry and GNSS Data
Jun 24, 2022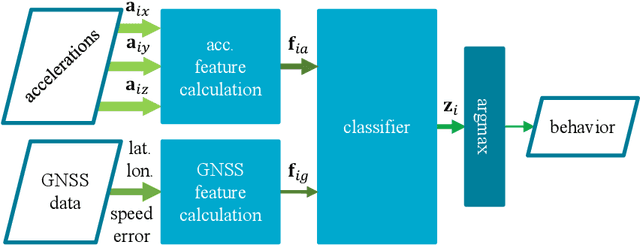
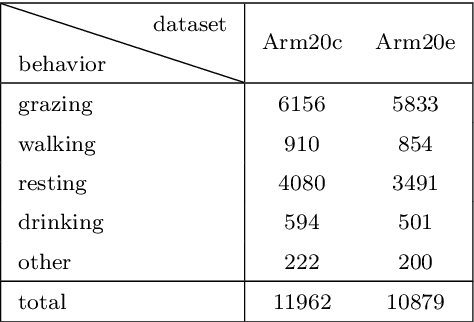
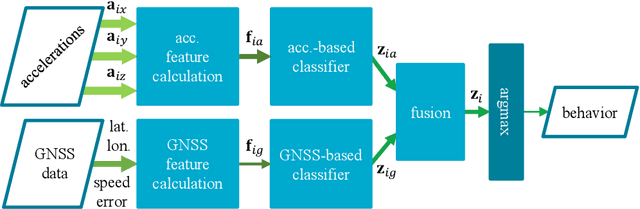
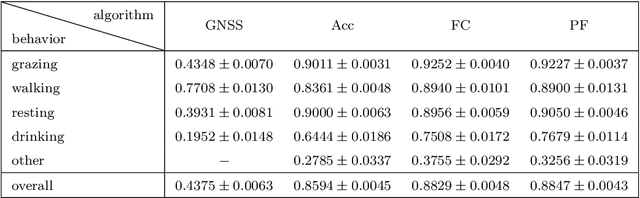
We examine using data from multiple sensing modes, i.e., accelerometry and global navigation satellite system (GNSS), for classifying animal behavior. We extract three new features from the GNSS data, namely, the distance from the water point, median speed, and median estimated horizontal position error. We consider two approaches for combining the information available from the accelerometry and GNSS data. The first approach is based on concatenating the features extracted from both sensor data and feeding the concatenated feature vector into a multi-layer perceptron (MLP) classifier. The second approach is based on fusing the posterior probabilities predicted by two MLP classifiers each taking the features extracted from the data of one sensor as input. We evaluate the performance of the developed multi-modal animal behavior classification algorithms using two real-world datasets collected via smart cattle collar and ear tags. The leave-one-animal-out cross-validation results show that both approaches improve the classification performance appreciably compared with using the data from only one sensing mode, in particular, for the infrequent but important behaviors of walking and drinking. The algorithms developed based on both approaches require rather small computational and memory resources hence are suitable for implementation on embedded systems of our collar and ear tags. However, the multi-modal animal behavior classification algorithm based on posterior probability fusion is preferable to the one based on feature concatenation as it delivers better classification accuracy, has less computational and memory complexity, is more robust to sensor data failure, and enjoys better modularity.
Dataset Condensation via Efficient Synthetic-Data Parameterization
Jun 02, 2022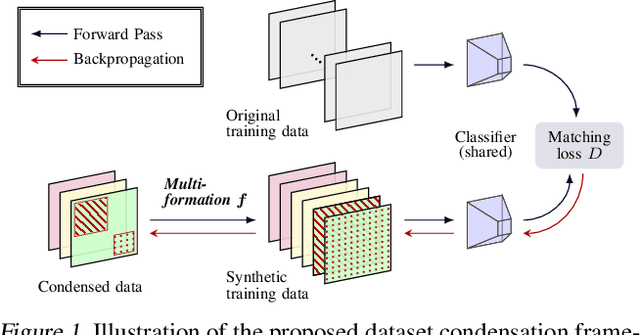
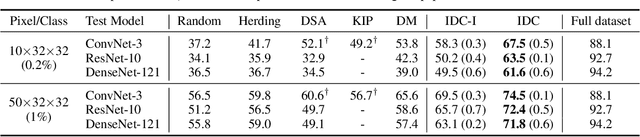
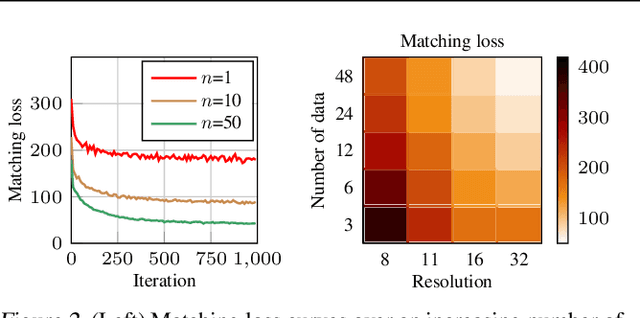
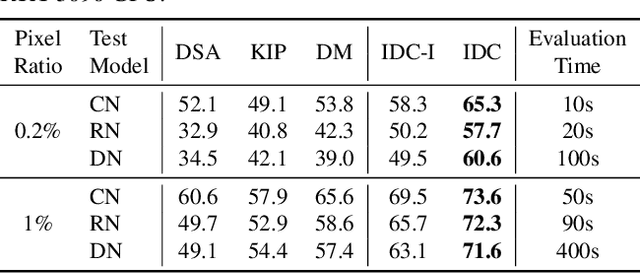
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.
An Information-Theoretic Perspective on Overfitting and Underfitting
Oct 12, 2020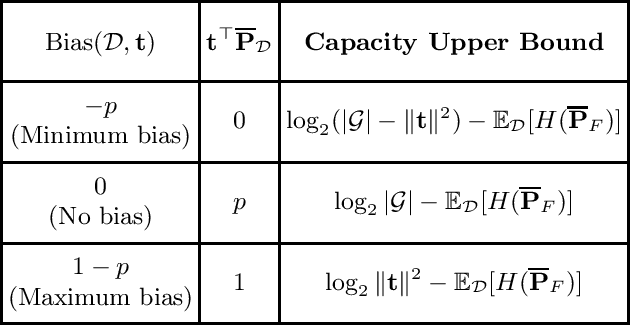
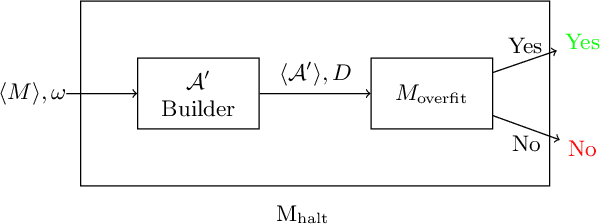
We present an information-theoretic framework for understanding overfitting and underfitting in machine learning and prove the formal undecidability of determining whether an arbitrary classification algorithm will overfit a dataset. Measuring algorithm capacity via the information transferred from datasets to models, we consider mismatches between algorithm capacities and datasets to provide a signature for when a model can overfit or underfit a dataset. We present results upper-bounding algorithm capacity, establish its relationship to quantities in the algorithmic search framework for machine learning, and relate our work to recent information-theoretic approaches to generalization.
MHSCNet: A Multimodal Hierarchical Shot-aware Convolutional Network for Video Summarization
Apr 19, 2022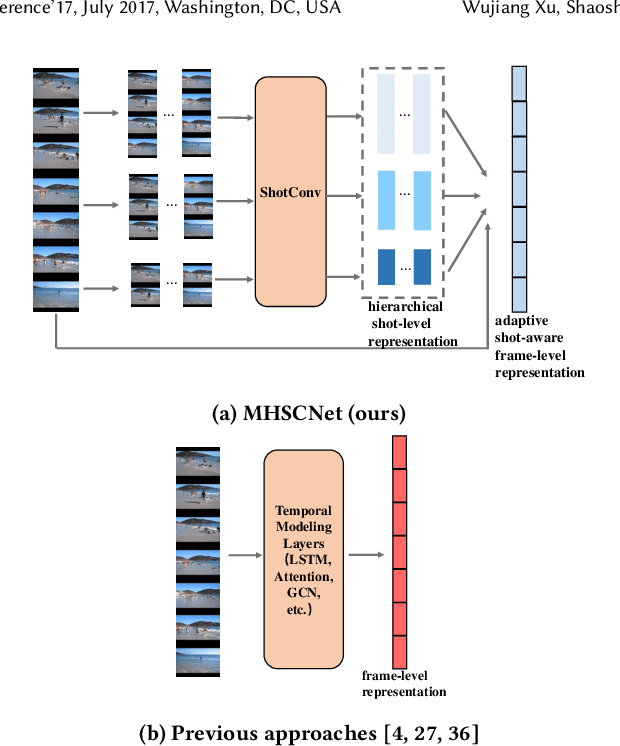
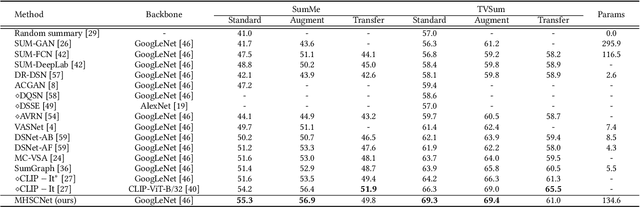
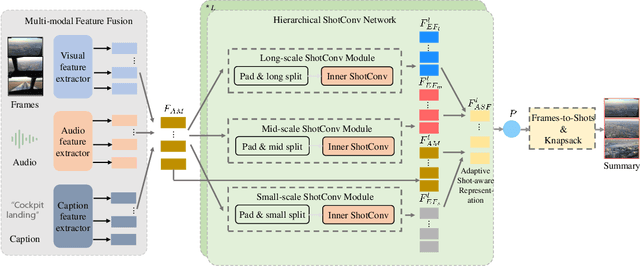
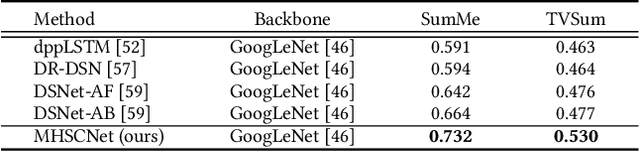
Video summarization intends to produce a concise video summary by effectively capturing and combining the most informative parts of the whole content. Existing approaches for video summarization regard the task as a frame-wise keyframe selection problem and generally construct the frame-wise representation by combining the long-range temporal dependency with the unimodal or bimodal information. However, the optimal video summaries need to reflect the most valuable keyframe with its own information, and one with semantic power of the whole content. Thus, it is critical to construct a more powerful and robust frame-wise representation and predict the frame-level importance score in a fair and comprehensive manner. To tackle the above issues, we propose a multimodal hierarchical shot-aware convolutional network, denoted as MHSCNet, to enhance the frame-wise representation via combining the comprehensive available multimodal information. Specifically, we design a hierarchical ShotConv network to incorporate the adaptive shot-aware frame-level representation by considering the short-range and long-range temporal dependency. Based on the learned shot-aware representations, MHSCNet can predict the frame-level importance score in the local and global view of the video. Extensive experiments on two standard video summarization datasets demonstrate that our proposed method consistently outperforms state-of-the-art baselines. Source code will be made publicly available.
Seismic Wavefield Reconstruction based on Compressed Sensing using Data-Driven Reduced-Order Model
Jun 24, 2022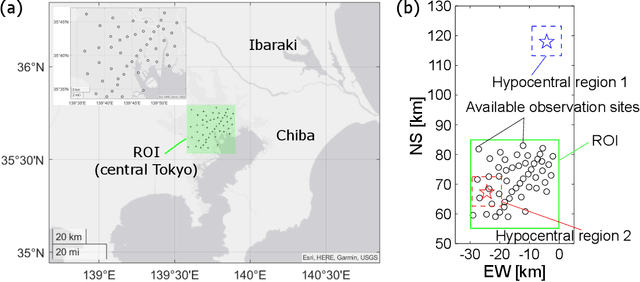
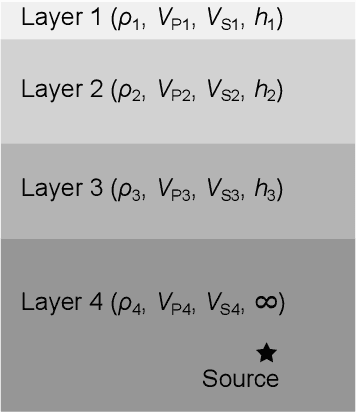
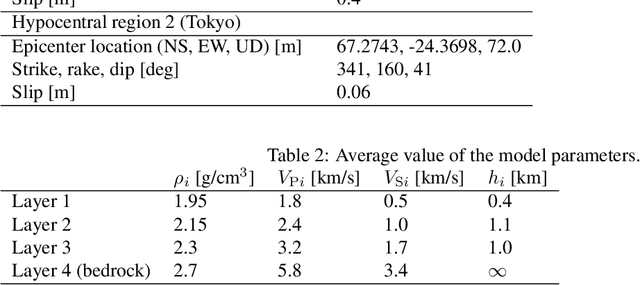
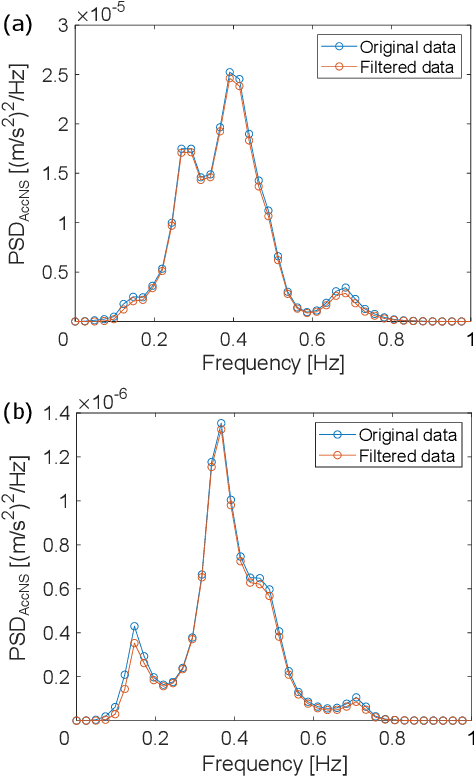
A seismic wavefield reconstruction framework based on compressed sensing using the data-driven reduced-order model (ROM) is proposed and its characteristics are investigated through numerical experiments. The data-driven ROM is generated from the dataset of the wavefield using the singular value decomposition. The spatially continuous seismic wavefield is reconstructed from the sparse and discrete observation and the data-driven ROM. The observation sites used for reconstruction are effectively selected by the sensor optimization method for linear inverse problems based on a greedy algorithm. The validity of the proposed method was confirmed by the reconstruction based on the noise-free observation. Since the ROM of the wavefield is used as prior information, the reconstruction error is reduced to an approximately lower error bound of the present framework, even though the number of sensors used for reconstruction is limited and randomly selected. In addition, the reconstruction error obtained by the proposed framework is much smaller than that obtained by the Gaussian process regression. For the numerical experiment with noise-contaminated observation, the reconstructed wavefield is degraded due to the observation noise, but the reconstruction error obtained by the present framework with all available observation sites is close to a lower error bound, even though the reconstructed wavefield using the Gaussian process regression is fully collapsed. Although the reconstruction error is larger than that obtained using all observation sites, the number of observation sites used for reconstruction can be reduced while minimizing the deterioration and scatter of the reconstructed data by combining it with the sensor optimization method.
PGD: A Large-scale Professional Go Dataset for Data-driven Analytics
Apr 30, 2022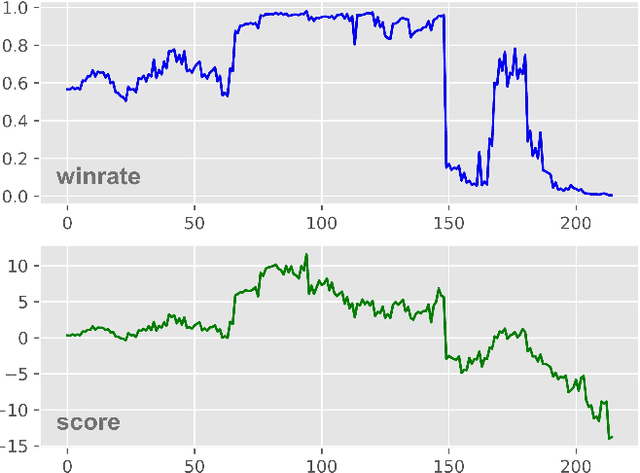
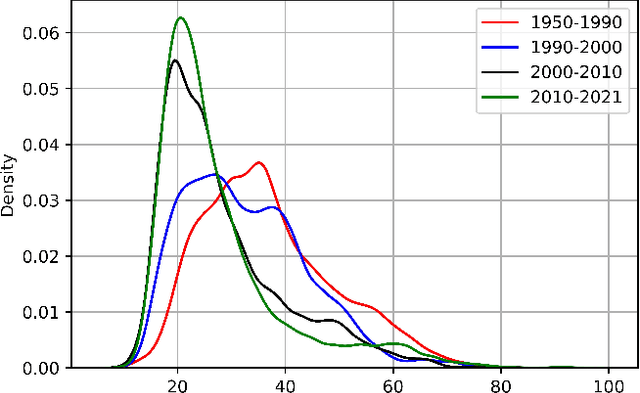
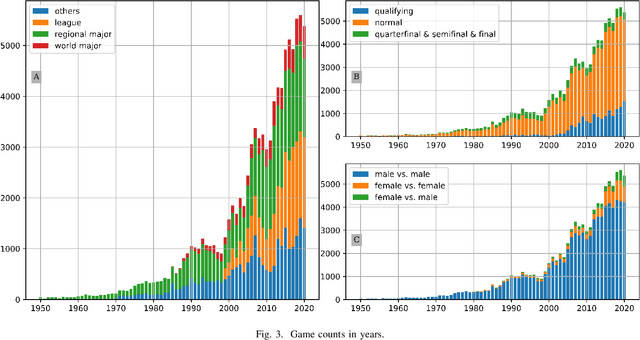
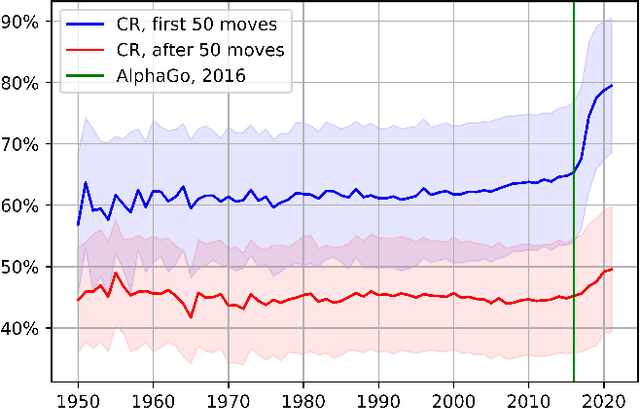
Lee Sedol is on a winning streak--does this legend rise again after the competition with AlphaGo? Ke Jie is invincible in the world championship--can he still win the title this time? Go is one of the most popular board games in East Asia, with a stable professional sports system that has lasted for decades in China, Japan, and Korea. There are mature data-driven analysis technologies for many sports, such as soccer, basketball, and esports. However, developing such technology for Go remains nontrivial and challenging due to the lack of datasets, meta-information, and in-game statistics. This paper creates the Professional Go Dataset (PGD), containing 98,043 games played by 2,148 professional players from 1950 to 2021. After manual cleaning and labeling, we provide detailed meta-information for each player, game, and tournament. Moreover, the dataset includes analysis results for each move in the match evaluated by advanced AlphaZero-based AI. To establish a benchmark for PGD, we further analyze the data and extract meaningful in-game features based on prior knowledge related to Go that can indicate the game status. With the help of complete meta-information and constructed in-game features, our results prediction system achieves an accuracy of 75.30%, much higher than several state-of-the-art approaches (64%-65%). As far as we know, PGD is the first dataset for data-driven analytics in Go and even in board games. Beyond this promising result, we provide more examples of tasks that benefit from our dataset. The ultimate goal of this paper is to bridge this ancient game and the modern data science community. It will advance research on Go-related analytics to enhance the fan experience, help players improve their ability, and facilitate other promising aspects. The dataset will be made publicly available.