 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A COVID-19 Search Engine (CO-SE) with Transformer-based Architecture
Jun 07, 2022
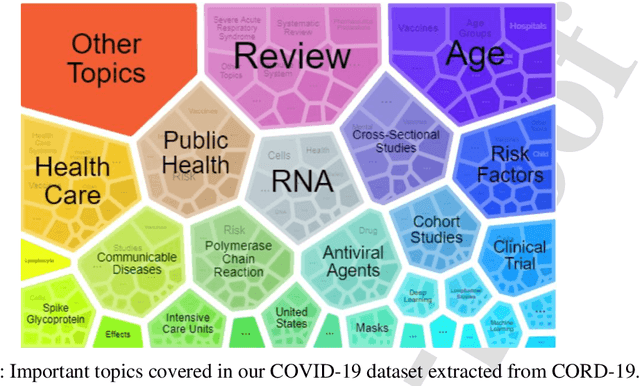
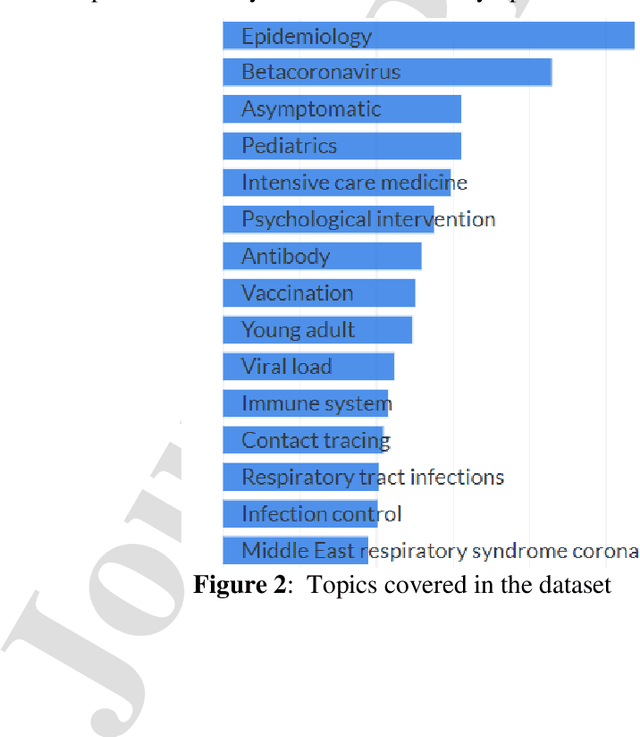
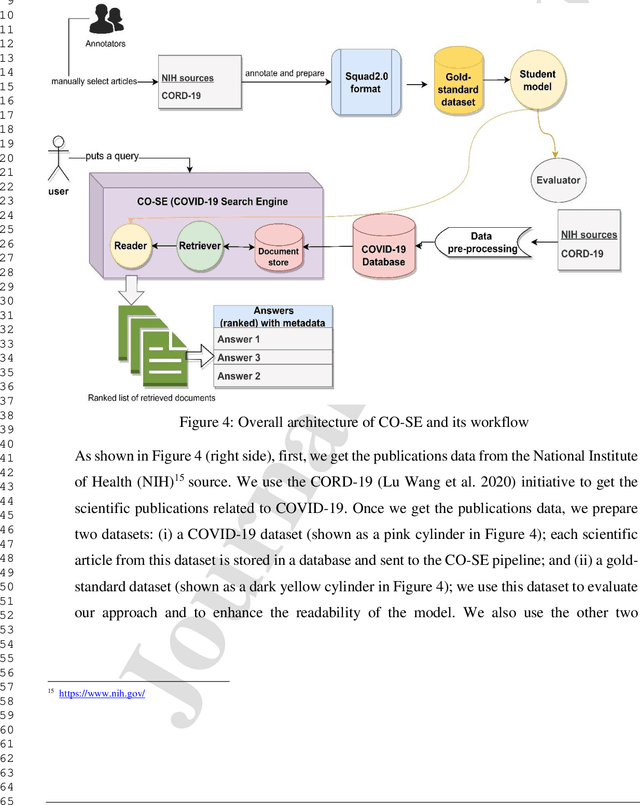
Coronavirus disease (COVID-19) is an infectious disease, which is caused by the SARS-CoV-2 virus. Due to the growing literature on COVID-19, it is hard to get precise, up-to-date information about the virus. Practitioners, front-line workers, and researchers require expert-specific methods to stay current on scientific knowledge and research findings. However, there are a lot of research papers being written on the subject, which makes it hard to keep up with the most recent research. This problem motivates us to propose the design of the COVID-19 Search Engine (CO-SE), which is an algorithmic system that finds relevant documents for each query (asked by a user) and answers complex questions by searching a large corpus of publications. The CO-SE has a retriever component trained on the TF-IDF vectorizer that retrieves the relevant documents from the system. It also consists of a reader component that consists of a Transformer-based model, which is used to read the paragraphs and find the answers related to the query from the retrieved documents. The proposed model has outperformed previous models, obtaining an exact match ratio score of 71.45% and a semantic answer similarity score of 78.55%. It also outperforms other benchmark datasets, demonstrating the generalizability of the proposed approach.
Towards Symbolic Time Series Representation Improved by Kernel Density Estimators
May 25, 2022This paper deals with symbolic time series representation. It builds up on the popular mapping technique Symbolic Aggregate approXimation algorithm (SAX), which is extensively utilized in sequence classification, pattern mining, anomaly detection, time series indexing and other data mining tasks. However, the disadvantage of this method is, that it works reliably only for time series with Gaussian-like distribution. In our previous work we have proposed an improvement of SAX, called dwSAX, which can deal with Gaussian as well as non-Gaussian data distribution. Recently we have made further progress in our solution - edwSAX. Our goal was to optimally cover the information space by means of sufficient alphabet utilization; and to satisfy lower bounding criterion as tight as possible. We describe here our approach, including evaluation on commonly employed tasks such as time series reconstruction error and Euclidean distance lower bounding with promising improvements over SAX.
Generalized Reference Kernel for One-class Classification
May 04, 2022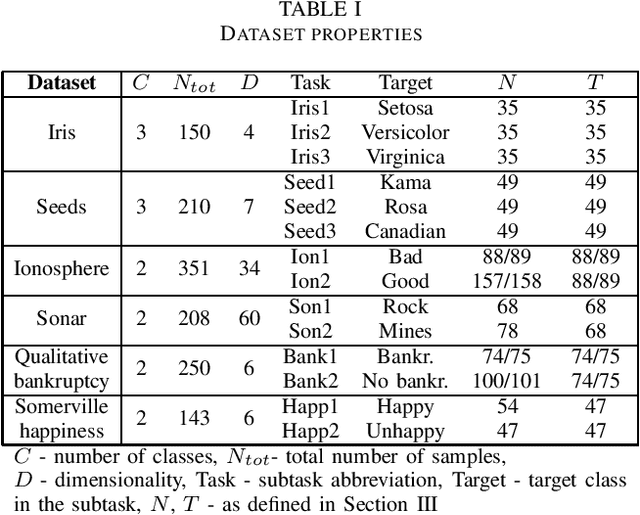
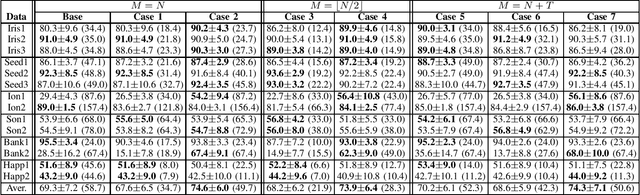
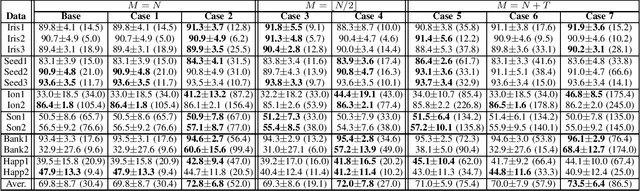
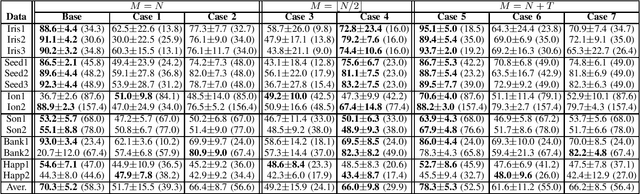
In this paper, we formulate a new generalized reference kernel hoping to improve the original base kernel using a set of reference vectors. Depending on the selected reference vectors, our formulation shows similarities to approximate kernels, random mappings, and Non-linear Projection Trick. Focusing on small-scale one-class classification, our analysis and experimental results show that the new formulation provides approaches to regularize, adjust the rank, and incorporate additional information into the kernel itself, leading to improved one-class classification accuracy.
Investigating Brain Connectivity with Graph Neural Networks and GNNExplainer
Jun 04, 2022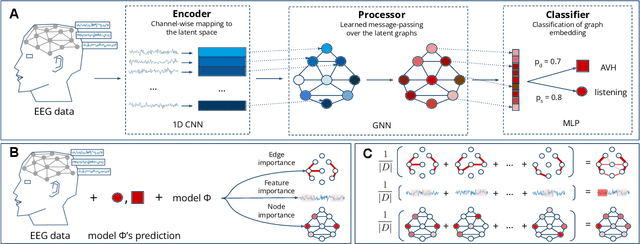
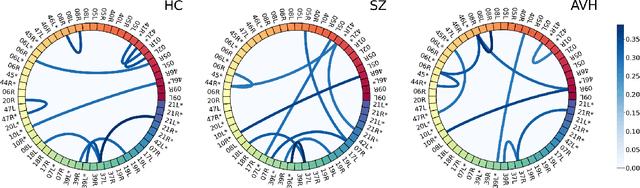
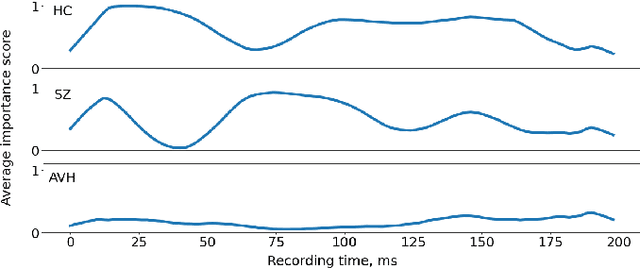
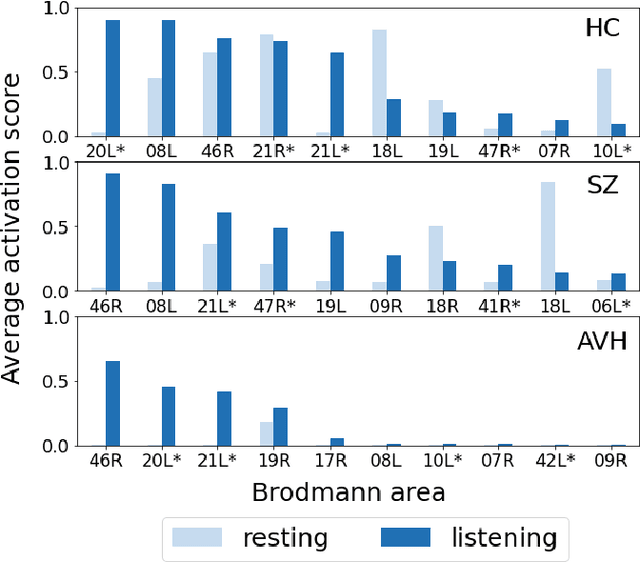
Functional connectivity plays an essential role in modern neuroscience. The modality sheds light on the brain's functional and structural aspects, including mechanisms behind multiple pathologies. One such pathology is schizophrenia which is often followed by auditory verbal hallucinations. The latter is commonly studied by observing functional connectivity during speech processing. In this work, we have made a step toward an in-depth examination of functional connectivity during a dichotic listening task via deep learning for three groups of people: schizophrenia patients with and without auditory verbal hallucinations and healthy controls. We propose a graph neural network-based framework within which we represent EEG data as signals in the graph domain. The framework allows one to 1) predict a brain mental disorder based on EEG recording, 2) differentiate the listening state from the resting state for each group and 3) recognize characteristic task-depending connectivity. Experimental results show that the proposed model can differentiate between the above groups with state-of-the-art performance. Besides, it provides a researcher with meaningful information regarding each group's functional connectivity, which we validated on the current domain knowledge.
Contrastive Siamese Network for Semi-supervised Speech Recognition
May 27, 2022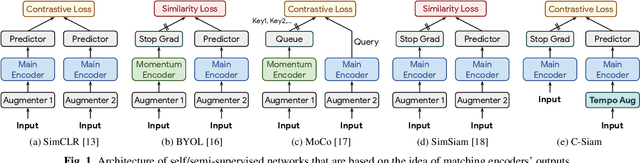
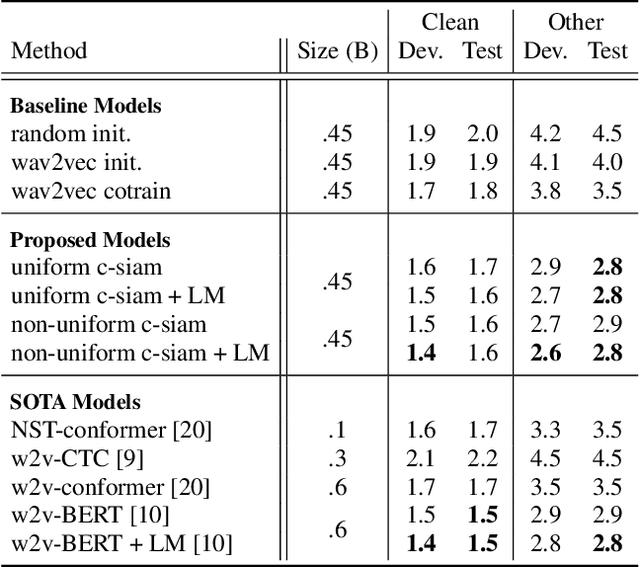
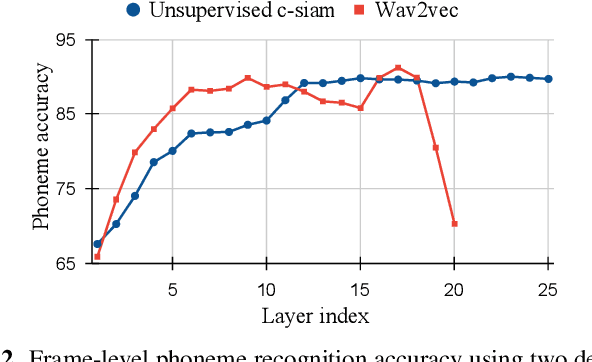
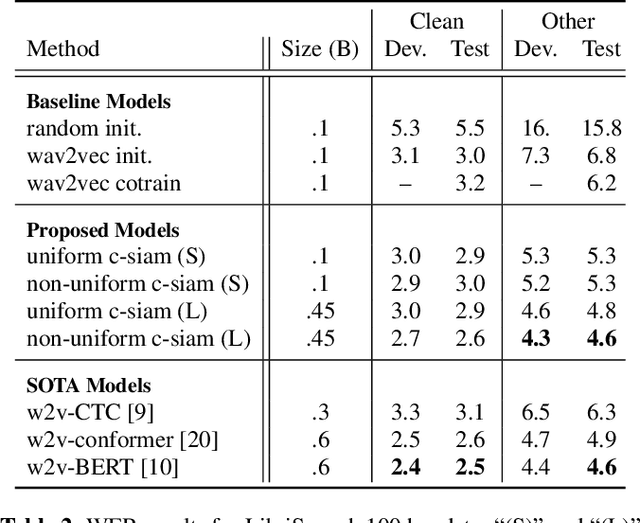
This paper introduces contrastive siamese (c-siam) network, an architecture for leveraging unlabeled acoustic data in speech recognition. c-siam is the first network that extracts high-level linguistic information from speech by matching outputs of two identical transformer encoders. It contains augmented and target branches which are trained by: (1) masking inputs and matching outputs with a contrastive loss, (2) incorporating a stop gradient operation on the target branch, (3) using an extra learnable transformation on the augmented branch, (4) introducing new temporal augment functions to prevent the shortcut learning problem. We use the Libri-light 60k unsupervised data and the LibriSpeech 100hrs/960hrs supervised data to compare c-siam and other best-performing systems. Our experiments show that c-siam provides 20% relative word error rate improvement over wav2vec baselines. A c-siam network with 450M parameters achieves competitive results compared to the state-of-the-art networks with 600M parameters.
Time Interval-enhanced Graph Neural Network for Shared-account Cross-domain Sequential Recommendation
Jun 16, 2022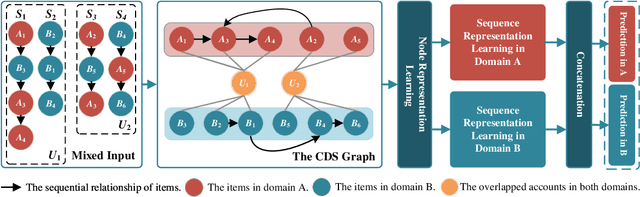
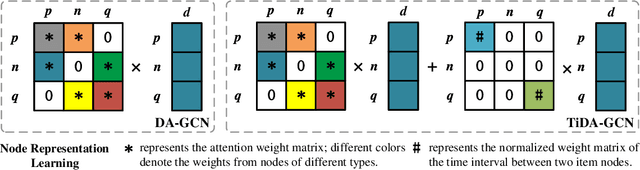
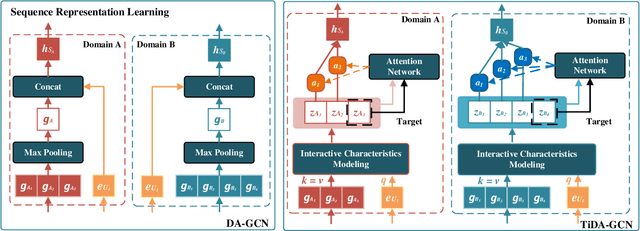
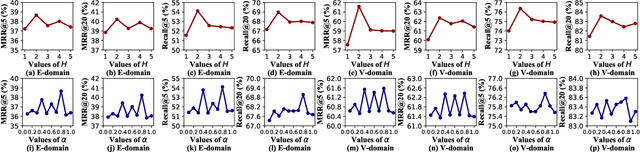
Shared-account Cross-domain Sequential Recommendation (SCSR) task aims to recommend the next item via leveraging the mixed user behaviors in multiple domains. It is gaining immense research attention as more and more users tend to sign up on different platforms and share accounts with others to access domain-specific services. Existing works on SCSR mainly rely on mining sequential patterns via Recurrent Neural Network (RNN)-based models, which suffer from the following limitations: 1) RNN-based methods overwhelmingly target discovering sequential dependencies in single-user behaviors. They are not expressive enough to capture the relationships among multiple entities in SCSR. 2) All existing methods bridge two domains via knowledge transfer in the latent space, and ignore the explicit cross-domain graph structure. 3) None existing studies consider the time interval information among items, which is essential in the sequential recommendation for characterizing different items and learning discriminative representations for them. In this work, we propose a new graph-based solution, namely TiDA-GCN, to address the above challenges. Specifically, we first link users and items in each domain as a graph. Then, we devise a domain-aware graph convolution network to learn userspecific node representations. To fully account for users' domainspecific preferences on items, two effective attention mechanisms are further developed to selectively guide the message passing process. Moreover, to further enhance item- and account-level representation learning, we incorporate the time interval into the message passing, and design an account-aware self-attention module for learning items' interactive characteristics. Experiments demonstrate the superiority of our proposed method from various aspects.
Memorability: An image-computable measure of information utility
Apr 01, 2021
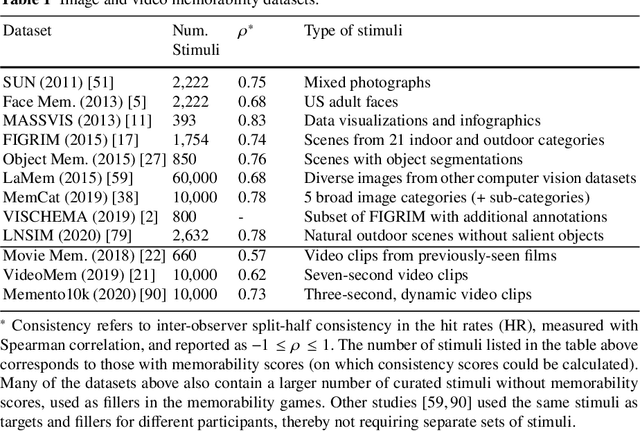

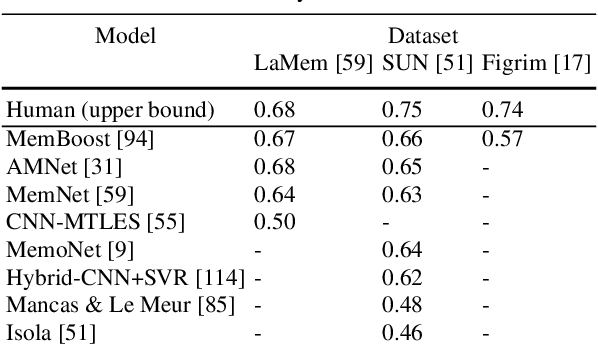
The pixels in an image, and the objects, scenes, and actions that they compose, determine whether an image will be memorable or forgettable. While memorability varies by image, it is largely independent of an individual observer. Observer independence is what makes memorability an image-computable measure of information, and eligible for automatic prediction. In this chapter, we zoom into memorability with a computational lens, detailing the state-of-the-art algorithms that accurately predict image memorability relative to human behavioral data, using image features at different scales from raw pixels to semantic labels. We discuss the design of algorithms and visualizations for face, object, and scene memorability, as well as algorithms that generalize beyond static scenes to actions and videos. We cover the state-of-the-art deep learning approaches that are the current front runners in the memorability prediction space. Beyond prediction, we show how recent A.I. approaches can be used to create and modify visual memorability. Finally, we preview the computational applications that memorability can power, from filtering visual streams to enhancing augmented reality interfaces.
A Review of Mobile Mapping Systems: From Sensors to Applications
May 31, 2022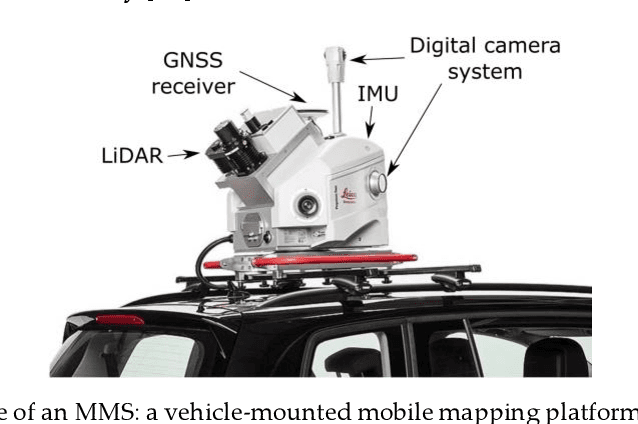
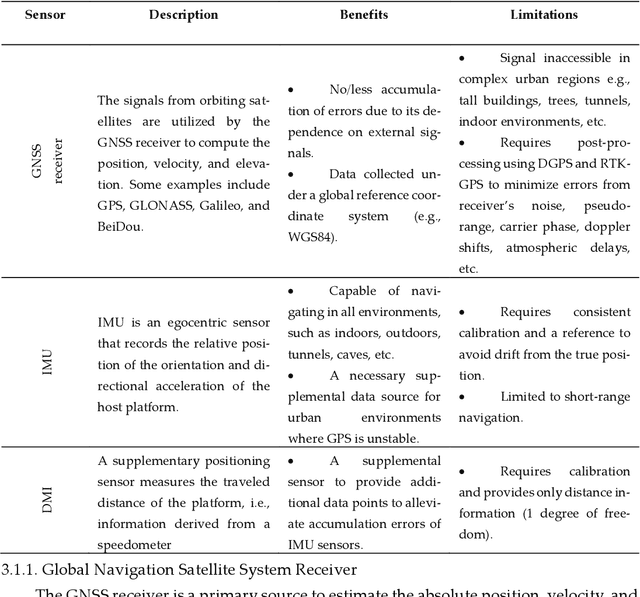
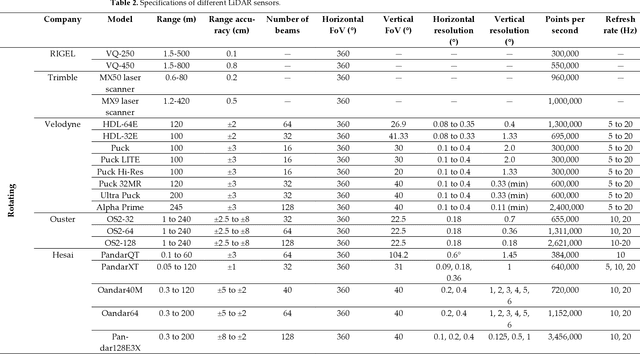

The evolution of mobile mapping systems (MMSs) has gained more attention in the past few decades. MMSs have been widely used to provide valuable assets in different applications. This has been facilitated by the wide availability of low-cost sensors, the advances in computational resources, the maturity of the mapping algorithms, and the need for accurate and on-demand geographic information system (GIS) data and digital maps. Many MMSs combine hybrid sensors to provide a more informative, robust, and stable solution by complementing each other. In this paper, we present a comprehensive review of the modern MMSs by focusing on 1) the types of sensors and platforms, where we discuss their capabilities, limitations, and also provide a comprehensive overview of recent MMS technologies available in the market, 2) highlighting the general workflow to process any MMS data, 3) identifying the different use cases of mobile mapping technology by reviewing some of the common applications, and 4) presenting a discussion on the benefits, challenges, and share our views on the potential research directions.
Improving Fairness in Graph Neural Networks via Mitigating Sensitive Attribute Leakage
Jun 07, 2022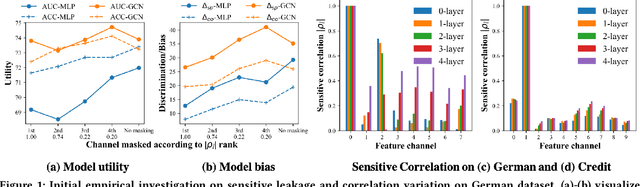
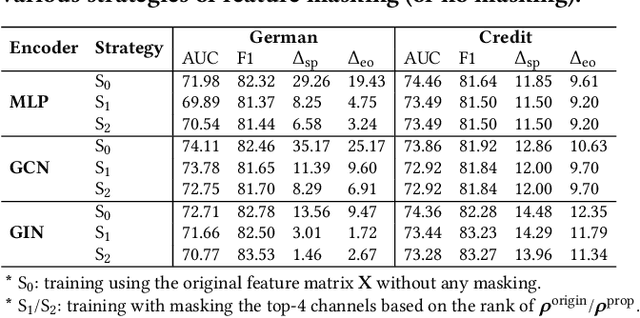
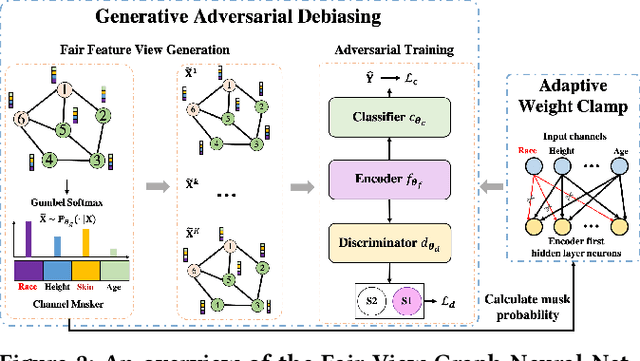

Graph Neural Networks (GNNs) have shown great power in learning node representations on graphs. However, they may inherit historical prejudices from training data, leading to discriminatory bias in predictions. Although some work has developed fair GNNs, most of them directly borrow fair representation learning techniques from non-graph domains without considering the potential problem of sensitive attribute leakage caused by feature propagation in GNNs. However, we empirically observe that feature propagation could vary the correlation of previously innocuous non-sensitive features to the sensitive ones. This can be viewed as a leakage of sensitive information which could further exacerbate discrimination in predictions. Thus, we design two feature masking strategies according to feature correlations to highlight the importance of considering feature propagation and correlation variation in alleviating discrimination. Motivated by our analysis, we propose Fair View Graph Neural Network (FairVGNN) to generate fair views of features by automatically identifying and masking sensitive-correlated features considering correlation variation after feature propagation. Given the learned fair views, we adaptively clamp weights of the encoder to avoid using sensitive-related features. Experiments on real-world datasets demonstrate that FairVGNN enjoys a better trade-off between model utility and fairness. Our code is publicly available at \href{https://github.com/YuWVandy/FairVGNN}{\textcolor{blue}{https://github.com/YuWVandy/FairVGNN}}.
Contrasting quadratic assignments for set-based representation learning
May 31, 2022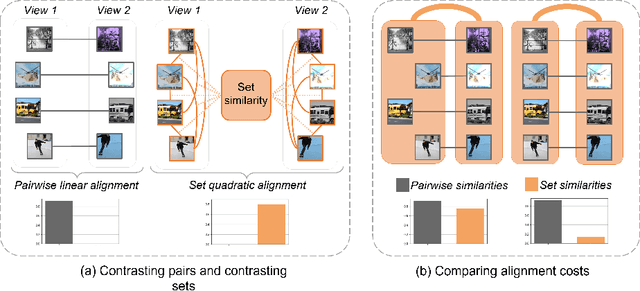

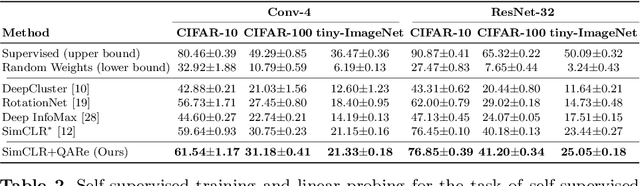
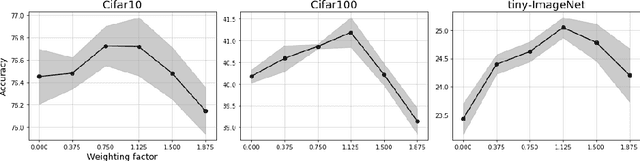
The standard approach to contrastive learning is to maximize the agreement between different views of the data. The views are ordered in pairs, such that they are either positive, encoding different views of the same object, or negative, corresponding to views of different objects. The supervisory signal comes from maximizing the total similarity over positive pairs, while the negative pairs are needed to avoid collapse. In this work, we note that the approach of considering individual pairs cannot account for both intra-set and inter-set similarities when the sets are formed from the views of the data. It thus limits the information content of the supervisory signal available to train representations. We propose to go beyond contrasting individual pairs of objects by focusing on contrasting objects as sets. For this, we use combinatorial quadratic assignment theory designed to evaluate set and graph similarities and derive set-contrastive objective as a regularizer for contrastive learning methods. We conduct experiments and demonstrate that our method improves learned representations for the tasks of metric learning and self-supervised classification.