 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Speech Augmentation Based Unsupervised Learning for Keyword Spotting
May 28, 2022
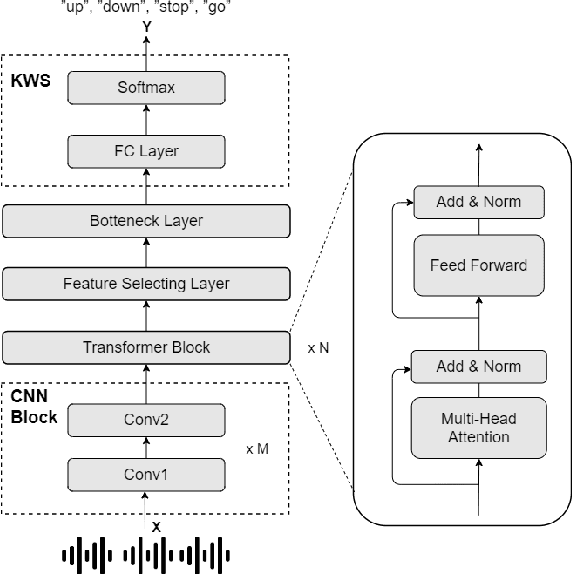
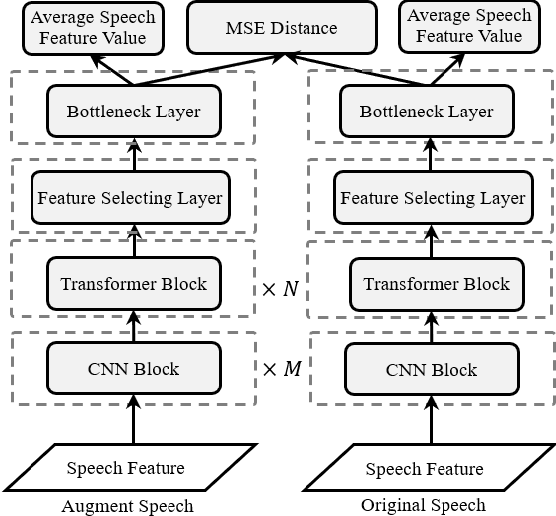
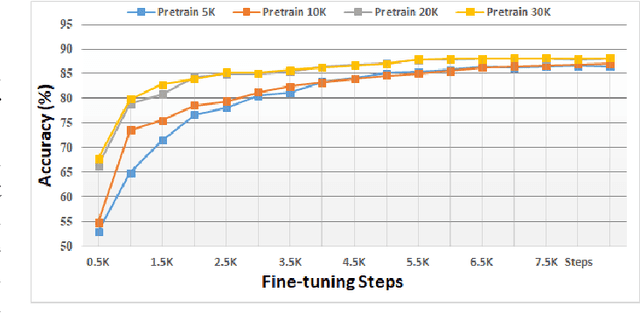

In this paper, we investigated a speech augmentation based unsupervised learning approach for keyword spotting (KWS) task. KWS is a useful speech application, yet also heavily depends on the labeled data. We designed a CNN-Attention architecture to conduct the KWS task. CNN layers focus on the local acoustic features, and attention layers model the long-time dependency. To improve the robustness of KWS model, we also proposed an unsupervised learning method. The unsupervised loss is based on the similarity between the original and augmented speech features, as well as the audio reconstructing information. Two speech augmentation methods are explored in the unsupervised learning: speed and intensity. The experiments on Google Speech Commands V2 Dataset demonstrated that our CNN-Attention model has competitive results. Moreover, the augmentation based unsupervised learning could further improve the classification accuracy of KWS task. In our experiments, with augmentation based unsupervised learning, our KWS model achieves better performance than other unsupervised methods, such as CPC, APC, and MPC.
Fault-Aware Neural Code Rankers
Jun 04, 2022

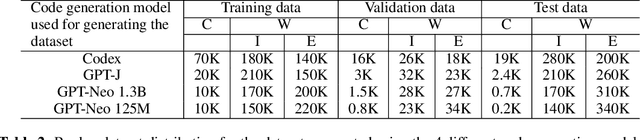

Large language models (LLMs) have demonstrated an impressive ability to generate code for various programming tasks. In many instances, LLMs can generate a correct program for a task when given numerous trials. Consequently, a recent trend is to do large scale sampling of programs using a model and then filtering/ranking the programs based on the program execution on a small number of known unit tests to select one candidate solution. However, these approaches assume that the unit tests are given and assume the ability to safely execute the generated programs (which can do arbitrary dangerous operations such as file manipulations). Both of the above assumptions are impractical in real-world software development. In this paper, we propose fault-aware neural code rankers that can predict the correctness of a sampled program without executing it. The fault-aware rankers are trained to predict different kinds of execution information such as predicting the exact compile/runtime error type (e.g., an IndexError or a TypeError). We show that our fault-aware rankers can significantly increase the pass@1 accuracy of various code generation models (including Codex, GPT-Neo, GPT-J) on APPS, HumanEval and MBPP datasets.
Fake News Detection Using Majority Voting Technique
Mar 27, 2022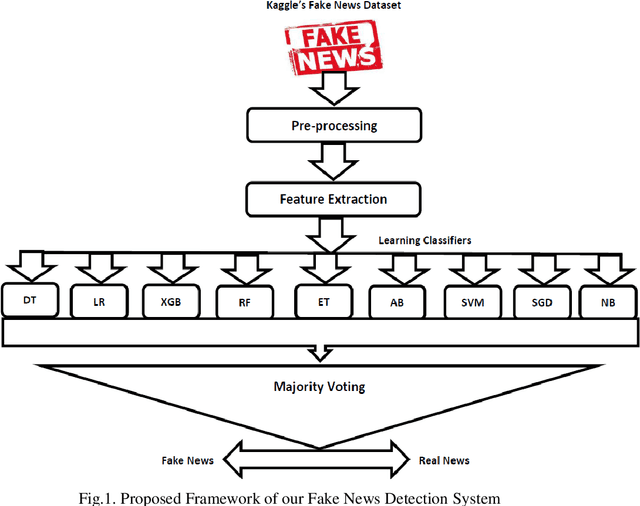
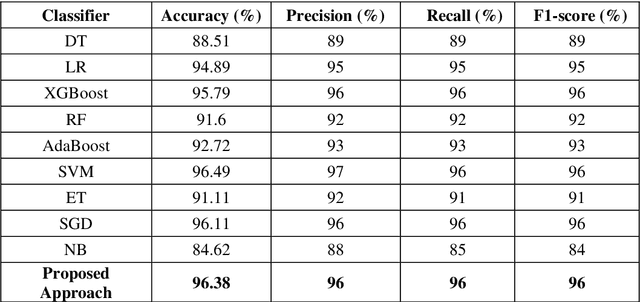
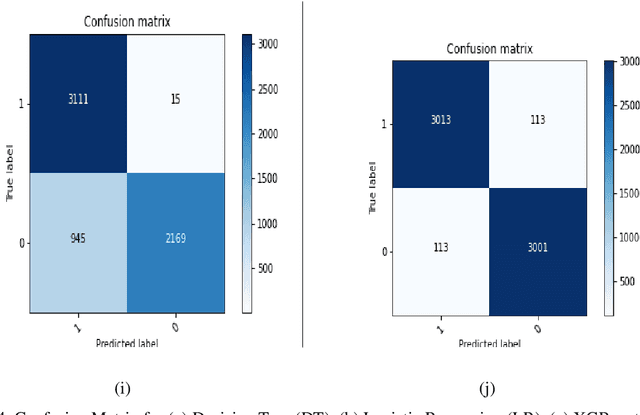
Due to the evolution of the Web and social network platforms it becomes very easy to disseminate the information. Peoples are creating and sharing more information than ever before, which may be misleading, misinformation or fake information. Fake news detection is a crucial and challenging task due to the unstructured nature of the available information. In the recent years, researchers have provided significant solutions to tackle with the problem of fake news detection, but due to its nature there are still many open issues. In this paper, we have proposed majority voting approach to detect fake news articles. We have used different textual properties of fake and real news. We have used publicly available fake news dataset, comprising of 20,800 news articles among which 10,387 are real and 10,413 are fake news labeled as binary 0 and 1. For the evaluation of our approach, we have used commonly used machine learning classifiers like, Decision Tree, Logistic Regression, XGBoost, Random Forest, Extra Trees, AdaBoost, SVM, SGD and Naive Bayes. Using the aforementioned classifiers, we built a multi-model fake news detection system using Majority Voting technique to achieve the more accurate results. The experimental results show that, our proposed approach achieved accuracy of 96.38%, precision of 96%, recall of 96% and F1-measure of 96%. The evaluation confirms that, Majority Voting technique achieved more acceptable results as compare to individual learning technique.
WT-MVSNet: Window-based Transformers for Multi-view Stereo
May 28, 2022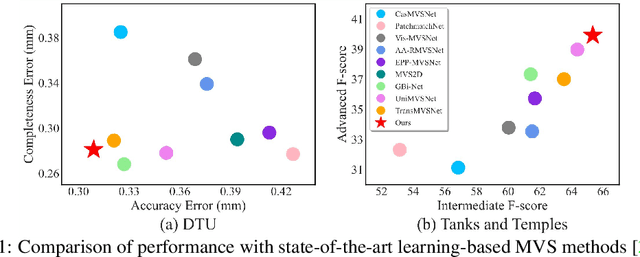
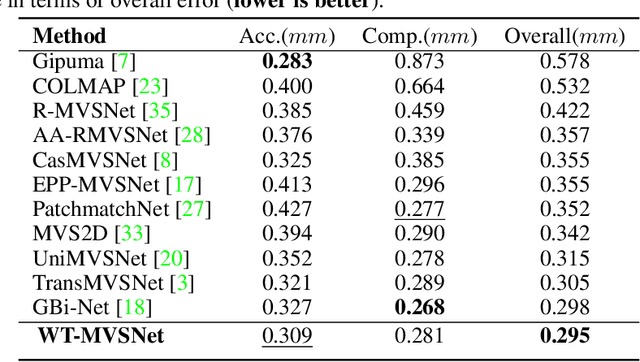
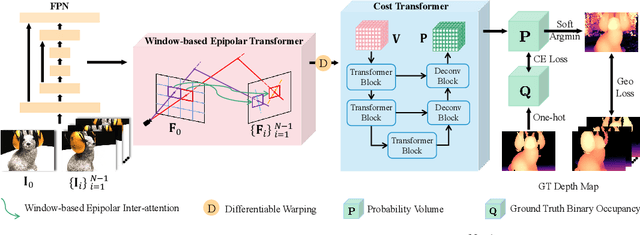
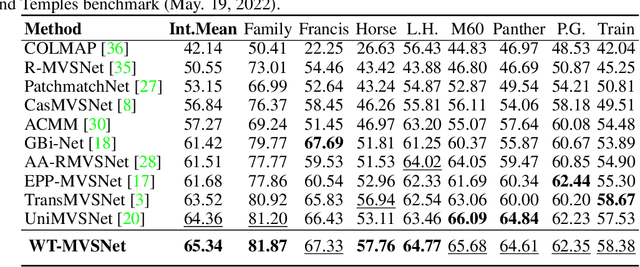
Recently, Transformers were shown to enhance the performance of multi-view stereo by enabling long-range feature interaction. In this work, we propose Window-based Transformers (WT) for local feature matching and global feature aggregation in multi-view stereo. We introduce a Window-based Epipolar Transformer (WET) which reduces matching redundancy by using epipolar constraints. Since point-to-line matching is sensitive to erroneous camera pose and calibration, we match windows near the epipolar lines. A second Shifted WT is employed for aggregating global information within cost volume. We present a novel Cost Transformer (CT) to replace 3D convolutions for cost volume regularization. In order to better constrain the estimated depth maps from multiple views, we further design a novel geometric consistency loss (Geo Loss) which punishes unreliable areas where multi-view consistency is not satisfied. Our WT multi-view stereo method (WT-MVSNet) achieves state-of-the-art performance across multiple datasets and ranks $1^{st}$ on Tanks and Temples benchmark.
DRAformer: Differentially Reconstructed Attention Transformer for Time-Series Forecasting
Jun 11, 2022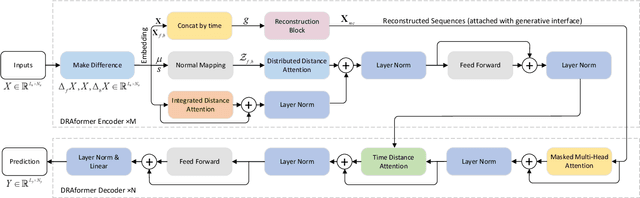
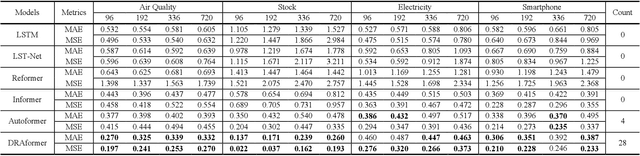
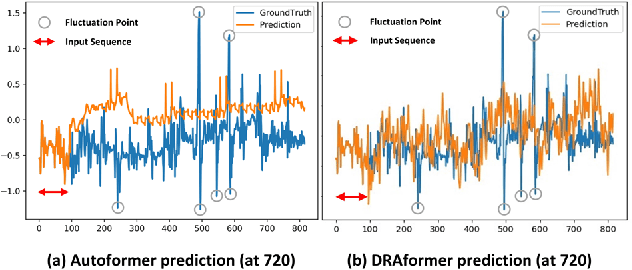

Time-series forecasting plays an important role in many real-world scenarios, such as equipment life cycle forecasting, weather forecasting, and traffic flow forecasting. It can be observed from recent research that a variety of transformer-based models have shown remarkable results in time-series forecasting. However, there are still some issues that limit the ability of transformer-based models on time-series forecasting tasks: (i) learning directly on raw data is susceptible to noise due to its complex and unstable feature representation; (ii) the self-attention mechanisms pay insufficient attention to changing features and temporal dependencies. In order to solve these two problems, we propose a transformer-based differentially reconstructed attention model DRAformer. Specifically, DRAformer has the following innovations: (i) learning against differenced sequences, which preserves clear and stable sequence features by differencing and highlights the changing properties of sequences; (ii) the reconstructed attention: integrated distance attention exhibits sequential distance through a learnable Gaussian kernel, distributed difference attention calculates distribution difference by mapping the difference sequence to the adaptive feature space, and the combination of the two effectively focuses on the sequences with prominent associations; (iii) the reconstructed decoder input, which extracts sequence features by integrating variation information and temporal correlations, thereby obtaining a more comprehensive sequence representation. Extensive experiments on four large-scale datasets demonstrate that DRAformer outperforms state-of-the-art baselines.
Position Tracking using Likelihood Modeling of Channel Features with Gaussian Processes
Mar 24, 2022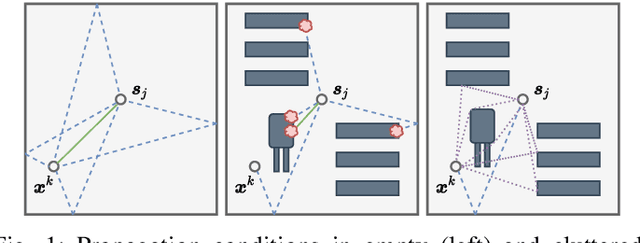
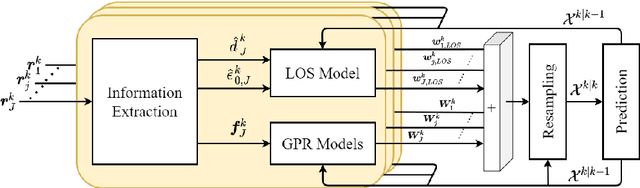
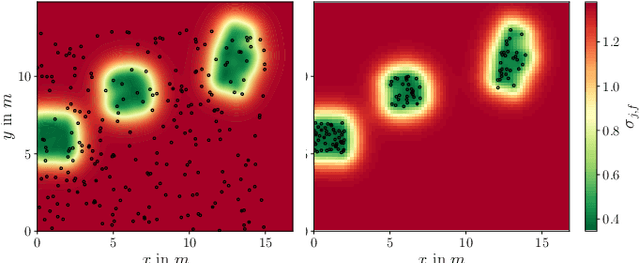

Recent localization frameworks exploit spatial information of complex channel measurements (CMs) to estimate accurate positions even in multipath propagation scenarios. State-of-the art CM fingerprinting(FP)-based methods employ convolutional neural networks (CNN) to extract the spatial information. However, they need spatially dense data sets (associated with high acquisition and maintenance efforts) to work well -- which is rarely the case in practical applications. If such data is not available (or its quality is low), we cannot compensate the performance degradation of CNN-based FP as they do not provide statistical position estimates, which prevents a fusion with other sources of information on the observation level. We propose a novel localization framework that adapts well to sparse datasets that only contain CMs of specific areas within the environment with strong multipath propagation. Our framework compresses CMs into informative features to unravel spatial information. It then regresses Gaussian processes (GPs) for each of them, which imply statistical observation models based on distance-dependent covariance kernels. Our framework combines the trained GPs with line-of-sight ranges and a dynamics model in a particle filter. Our measurements show that our approach outperforms state-of-the-art CNN fingerprinting (0.52 m vs. 1.3 m MAE) on spatially sparse data collected in a realistic industrial indoor environment.
Extracting Image Characteristics to Predict Crowdfunding Success
Mar 28, 2022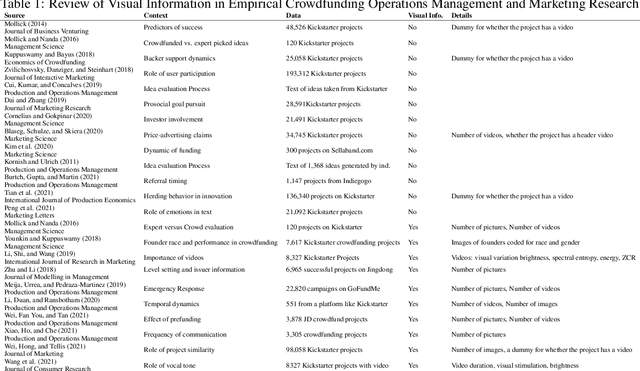
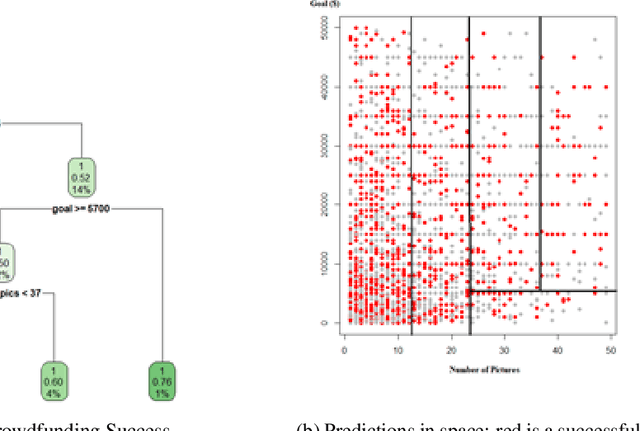
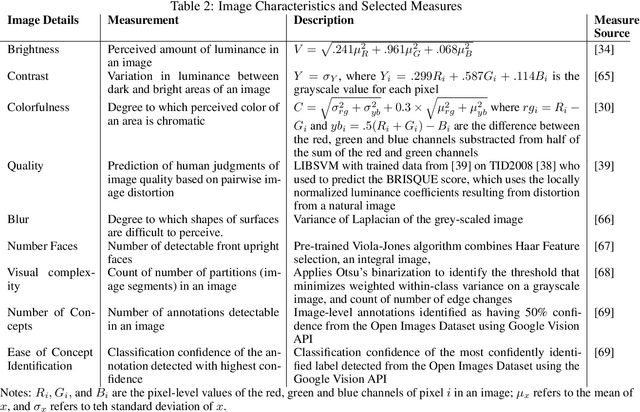
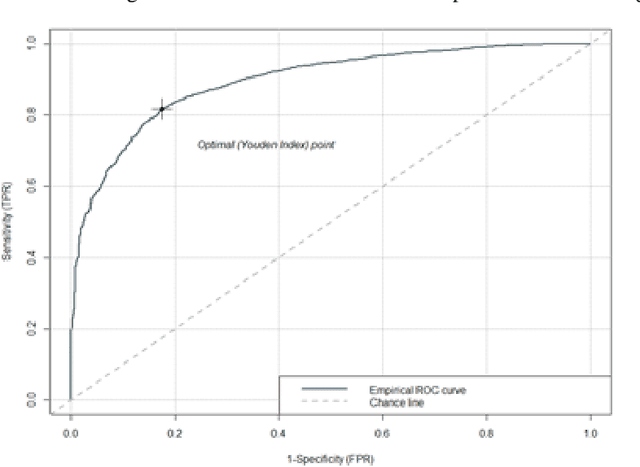
Despite an increase in the empirical study of crowdfunding platforms and the prevalence of visual information, operations management and marketing literature has yet to explore the role that image characteristics play in crowdfunding success. The authors of this manuscript begin by synthesizing literature on visual processing to identify several image characteristics that are likely to shape crowdfunding success. After detailing measures for each image characteristic, they use them as part of a machine-learning algorithm (Bayesian additive trees), along with project characteristics and textual information, to predict crowdfunding success. Results show that the inclusion of these image characteristics substantially improves prediction over baseline project variables, as well as textual features. Furthermore, image characteristic variables exhibit high importance, similar to variables linked to the number of pictures and number of videos. This research therefore offers valuable resources to researchers and managers who are interested in the role of visual information in ensuring new product success.
Many-Class Text Classification with Matching
May 23, 2022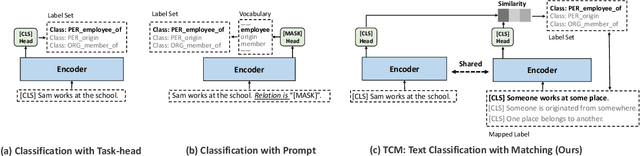
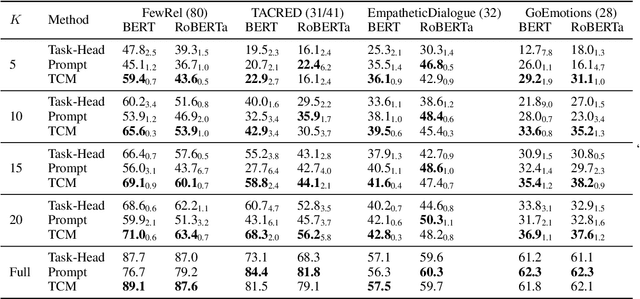
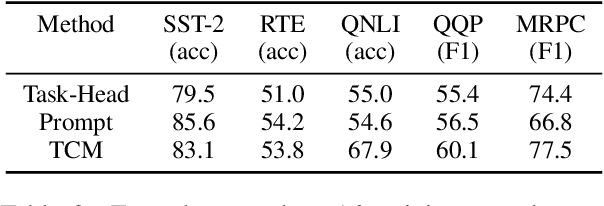
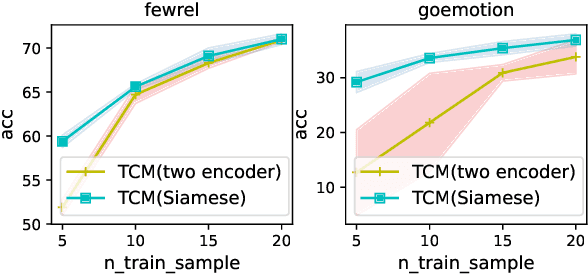
In this work, we formulate \textbf{T}ext \textbf{C}lassification as a \textbf{M}atching problem between the text and the labels, and propose a simple yet effective framework named TCM. Compared with previous text classification approaches, TCM takes advantage of the fine-grained semantic information of the classification labels, which helps distinguish each class better when the class number is large, especially in low-resource scenarios. TCM is also easy to implement and is compatible with various large pretrained language models. We evaluate TCM on 4 text classification datasets (each with 20+ labels) in both few-shot and full-data settings, and this model demonstrates significant improvements over other text classification paradigms. We also conduct extensive experiments with different variants of TCM and discuss the underlying factors of its success. Our method and analyses offer a new perspective on text classification.
Multi-Temporal Spatial-Spectral Comparison Network for Hyperspectral Anomalous Change Detection
May 23, 2022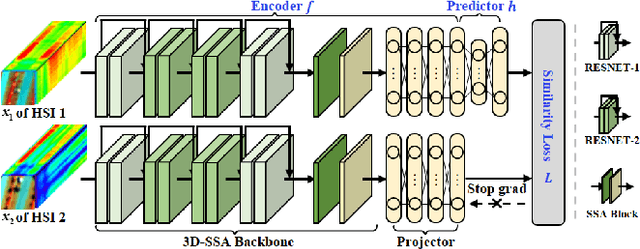
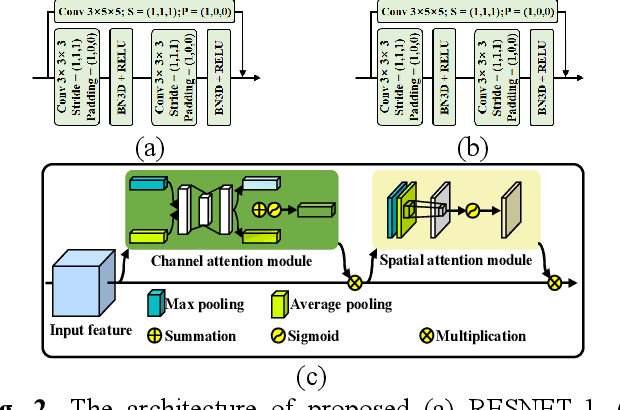


Hyperspectral anomalous change detection has been a challenging task for its emphasis on the dynamics of small and rare objects against the prevalent changes. In this paper, we have proposed a Multi-Temporal spatial-spectral Comparison Network for hyperspectral anomalous change detection (MTC-NET). The whole model is a deep siamese network, aiming at learning the prevalent spectral difference resulting from the complex imaging conditions from the hyperspectral images by contrastive learning. A three-dimensional spatial spectral attention module is designed to effectively extract the spatial semantic information and the key spectral differences. Then the gaps between the multi-temporal features are minimized, boosting the alignment of the semantic and spectral features and the suppression of the multi-temporal background spectral difference. The experiments on the "Viareggio 2013" datasets demonstrate the effectiveness of proposed MTC-NET.
Differentiable Invariant Causal Discovery
Jun 01, 2022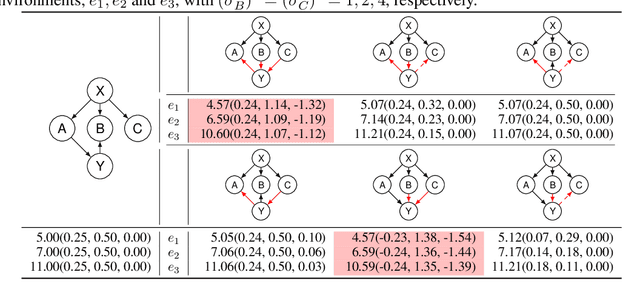
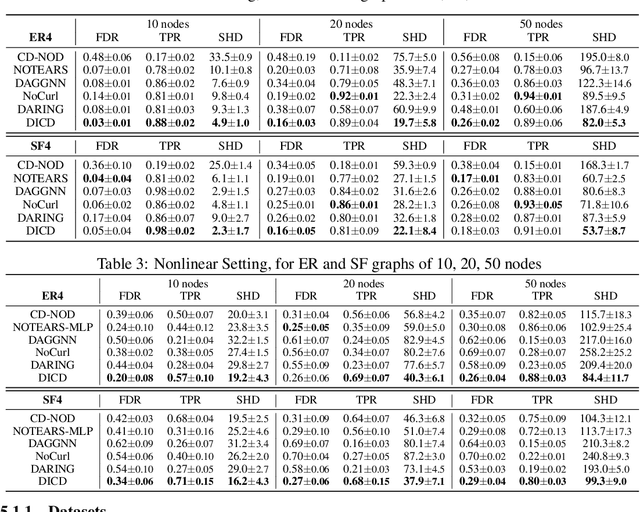
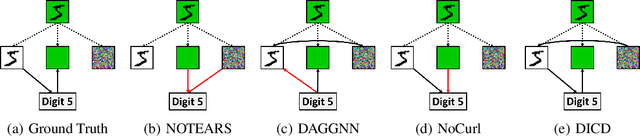

Learning causal structure from observational data is a fundamental challenge in machine learning. The majority of commonly used differentiable causal discovery methods are non-identifiable, turning this problem into a continuous optimization task prone to data biases. In many real-life situations, data is collected from different environments, in which the functional relations remain consistent across environments, while the distribution of additive noises may vary. This paper proposes Differentiable Invariant Causal Discovery (DICD), utilizing the multi-environment information based on a differentiable framework to avoid learning spurious edges and wrong causal directions. Specifically, DICD aims to discover the environment-invariant causation while removing the environment-dependent correlation. We further formulate the constraint that enforces the target structure equation model to maintain optimal across the environments. Theoretical guarantees for the identifiability of proposed DICD are provided under mild conditions with enough environments. Extensive experiments on synthetic and real-world datasets verify that DICD outperforms state-of-the-art causal discovery methods up to 36% in SHD. Our code will be open-sourced upon acceptance.