 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EDIN: An End-to-end Benchmark and Pipeline for Unknown Entity Discovery and Indexing
May 25, 2022
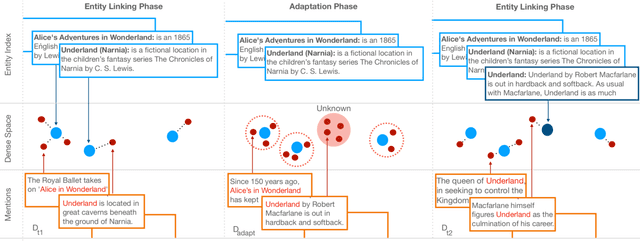
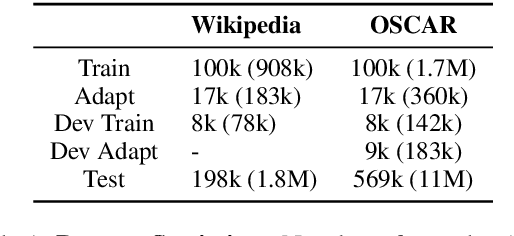
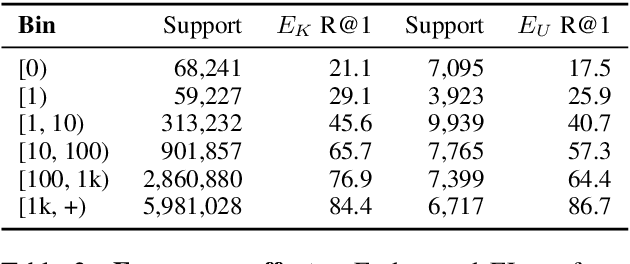
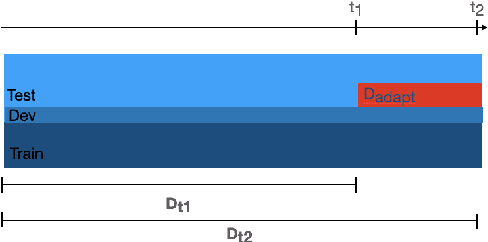
Existing work on Entity Linking mostly assumes that the reference knowledge base is complete, and therefore all mentions can be linked. In practice this is hardly ever the case, as knowledge bases are incomplete and because novel concepts arise constantly. This paper created the Unknown Entity Discovery and Indexing (EDIN) benchmark where unknown entities, that is entities without a description in the knowledge base and labeled mentions, have to be integrated into an existing entity linking system. By contrasting EDIN with zero-shot entity linking, we provide insight on the additional challenges it poses. Building on dense-retrieval based entity linking, we introduce the end-to-end EDIN pipeline that detects, clusters, and indexes mentions of unknown entities in context. Experiments show that indexing a single embedding per entity unifying the information of multiple mentions works better than indexing mentions independently.
Seismic Wavefield Reconstruction based on Compressed Sensing using Data-Driven Reduced-Order Model
Jun 18, 2022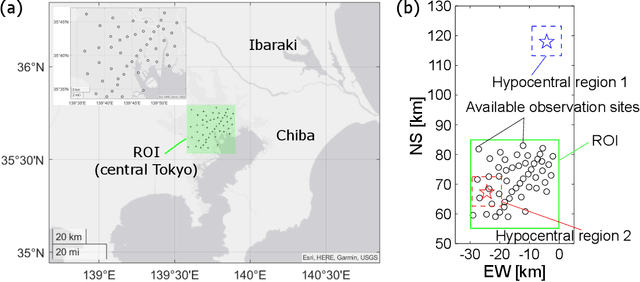
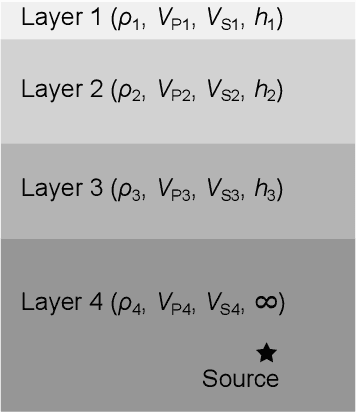
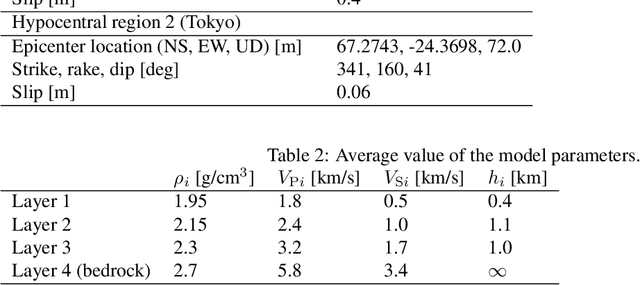
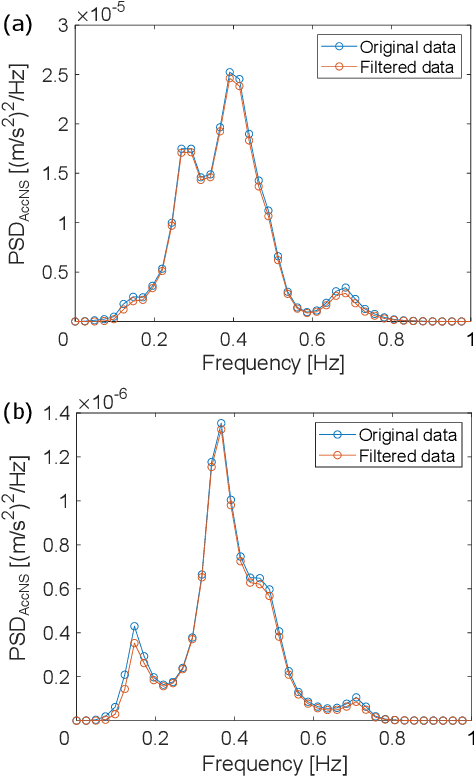
A seismic wavefield reconstruction framework based on compressed sensing using the data-driven reduced-order model (ROM) is proposed and its characteristics are investigated through numerical experiments. The data-driven ROM is generated from the dataset of the wavefield using the singular value decomposition. The spatially continuous seismic wavefield is reconstructed from the sparse and discrete observation and the data-driven ROM. The observation sites used for reconstruction are effectively selected by the sensor optimization method for linear inverse problems based on a greedy algorithm. The validity of the proposed method was confirmed by the reconstruction based on the noise-free observation. Since the ROM of the wavefield is used as prior information, the reconstruction error is reduced to an approximately lower error bound of the present framework, even though the number of sensors used for reconstruction is limited and randomly selected. In addition, the reconstruction error obtained by the proposed framework is much smaller than that obtained by the Gaussian process regression. For the numerical experiment with noise-contaminated observation, the reconstructed wavefield is degraded due to the observation noise, but the reconstruction error obtained by the present framework with all available observation sites is close to a lower error bound, even though the reconstructed wavefield using the Gaussian process regression is fully collapsed. Although the reconstruction error is larger than that obtained using all observation sites, the number of observation sites used for reconstruction can be reduced while minimizing the deterioration and scatter of the reconstructed data by combining it with the sensor optimization method.
Common Information Components Analysis
Feb 28, 2020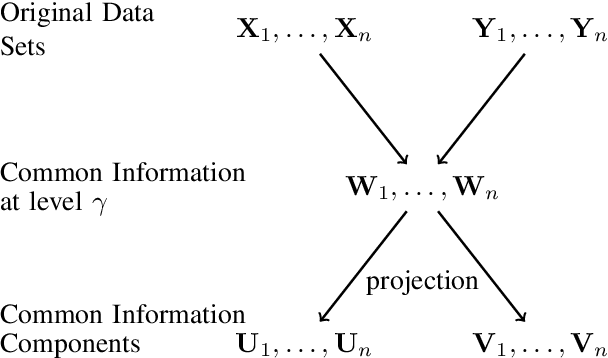
We give an information-theoretic interpretation of Canonical Correlation Analysis (CCA) via (relaxed) Wyner's common information. CCA permits to extract from two high-dimensional data sets low-dimensional descriptions (features) that capture the commonalities between the data sets, using a framework of correlations and linear transforms. Our interpretation first extracts the common information up to a pre-selected resolution level, and then projects this back onto each of the data sets. In the case of Gaussian statistics, this procedure precisely reduces to CCA, where the resolution level specifies the number of CCA components that are extracted. This also suggests a novel algorithm, Common Information Components Analysis (CICA), with several desirable features, including a natural extension to beyond just two data sets.
Domain Adaptive Monocular Depth Estimation With Semantic Information
Apr 12, 2021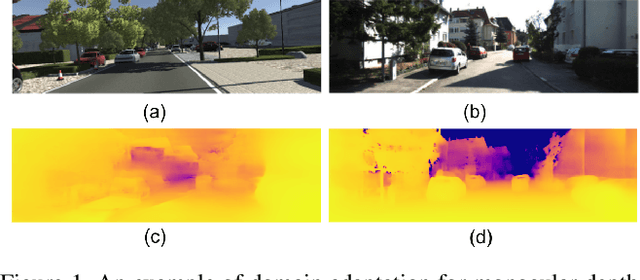
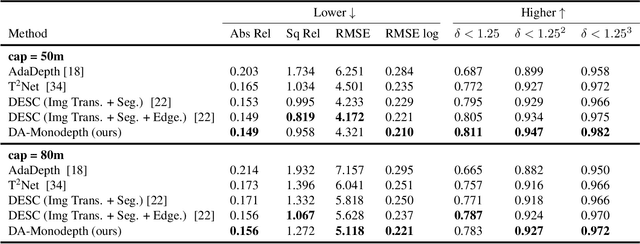
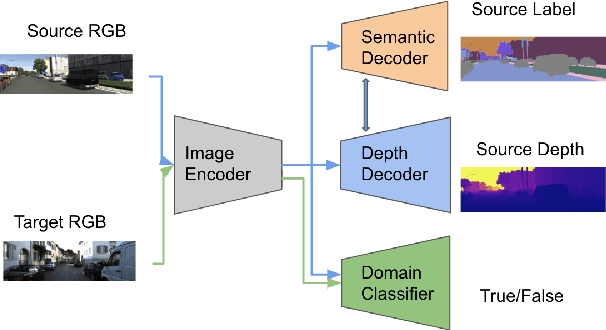
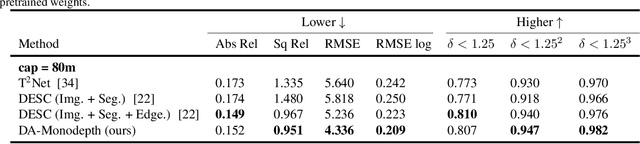
The advent of deep learning has brought an impressive advance to monocular depth estimation, e.g., supervised monocular depth estimation has been thoroughly investigated. However, the large amount of the RGB-to-depth dataset may not be always available since collecting accurate depth ground truth according to the RGB image is a time-consuming and expensive task. Although the network can be trained on an alternative dataset to overcome the dataset scale problem, the trained model is hard to generalize to the target domain due to the domain discrepancy. Adversarial domain alignment has demonstrated its efficacy to mitigate the domain shift on simple image classification tasks in previous works. However, traditional approaches hardly handle the conditional alignment as they solely consider the feature map of the network. In this paper, we propose an adversarial training model that leverages semantic information to narrow the domain gap. Based on the experiments conducted on the datasets for the monocular depth estimation task including KITTI and Cityscapes, the proposed compact model achieves state-of-the-art performance comparable to complex latest models and shows favorable results on boundaries and objects at far distances.
From Cognitive to Computational Modeling: Text-based Risky Decision-Making Guided by Fuzzy Trace Theory
May 15, 2022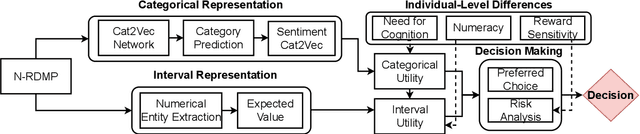
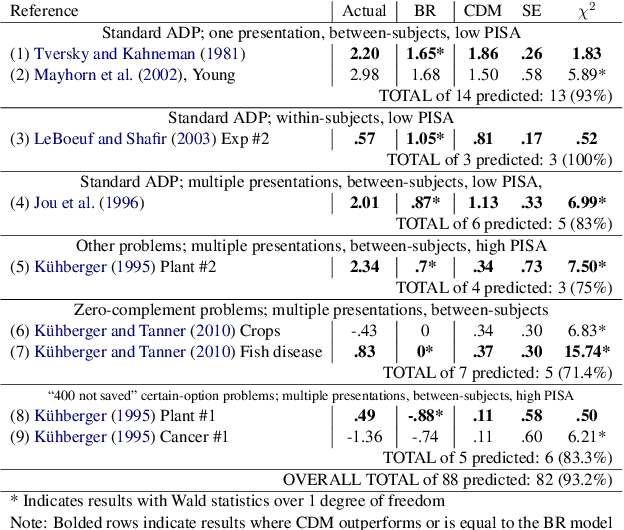
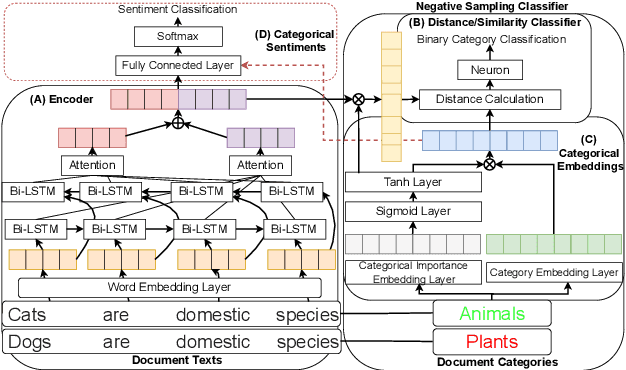
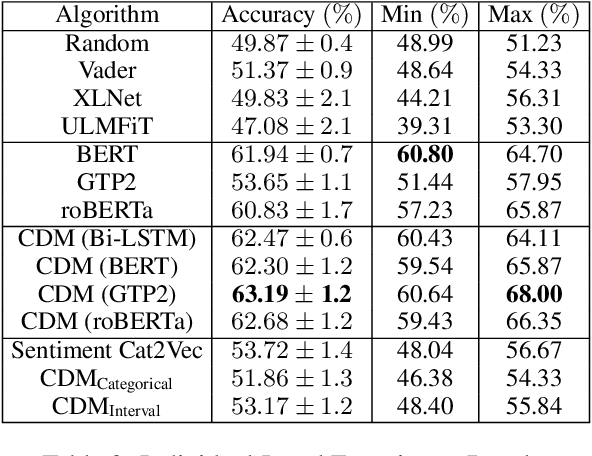
Understanding, modelling and predicting human risky decision-making is challenging due to intrinsic individual differences and irrationality. Fuzzy trace theory (FTT) is a powerful paradigm that explains human decision-making by incorporating gists, i.e., fuzzy representations of information which capture only its quintessential meaning. Inspired by Broniatowski and Reyna's FTT cognitive model, we propose a computational framework which combines the effects of the underlying semantics and sentiments on text-based decision-making. In particular, we introduce Category-2-Vector to learn categorical gists and categorical sentiments, and demonstrate how our computational model can be optimised to predict risky decision-making in groups and individuals.
MixFormer: End-to-End Tracking with Iterative Mixed Attention
Mar 29, 2022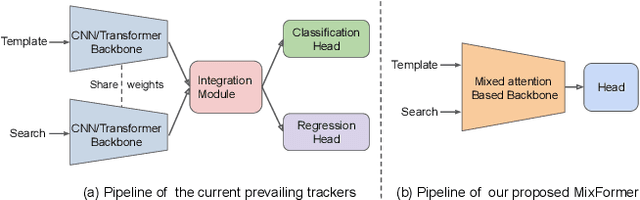

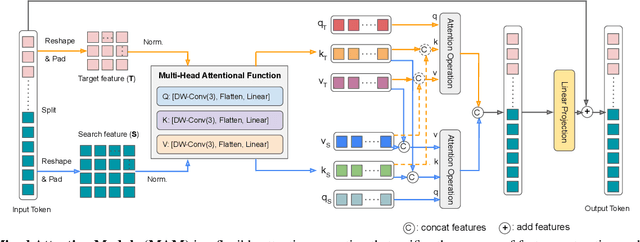
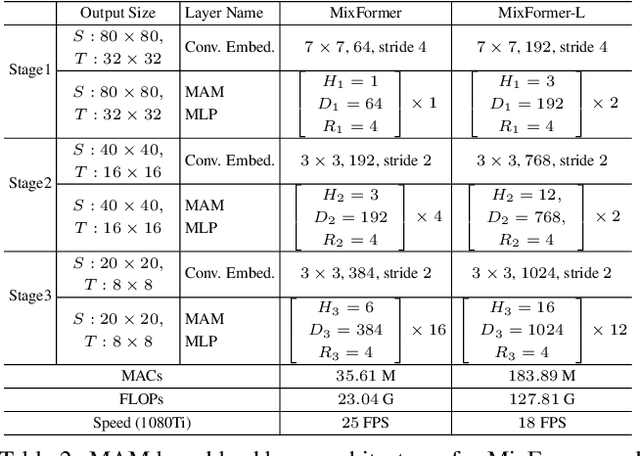
Tracking often uses a multi-stage pipeline of feature extraction, target information integration, and bounding box estimation. To simplify this pipeline and unify the process of feature extraction and target information integration, we present a compact tracking framework, termed as MixFormer, built upon transformers. Our core design is to utilize the flexibility of attention operations, and propose a Mixed Attention Module (MAM) for simultaneous feature extraction and target information integration. This synchronous modeling scheme allows to extract target-specific discriminative features and perform extensive communication between target and search area. Based on MAM, we build our MixFormer tracking framework simply by stacking multiple MAMs with progressive patch embedding and placing a localization head on top. In addition, to handle multiple target templates during online tracking, we devise an asymmetric attention scheme in MAM to reduce computational cost, and propose an effective score prediction module to select high-quality templates. Our MixFormer sets a new state-of-the-art performance on five tracking benchmarks, including LaSOT, TrackingNet, VOT2020, GOT-10k, and UAV123. In particular, our MixFormer-L achieves NP score of 79.9% on LaSOT, 88.9% on TrackingNet and EAO of 0.555 on VOT2020. We also perform in-depth ablation studies to demonstrate the effectiveness of simultaneous feature extraction and information integration. Code and trained models are publicly available at https://github.com/MCG-NJU/MixFormer.
Block-Parallel Systolic-Array Architecture for 2-D NTT-based Fragile Watermark Embedding
Jun 02, 2022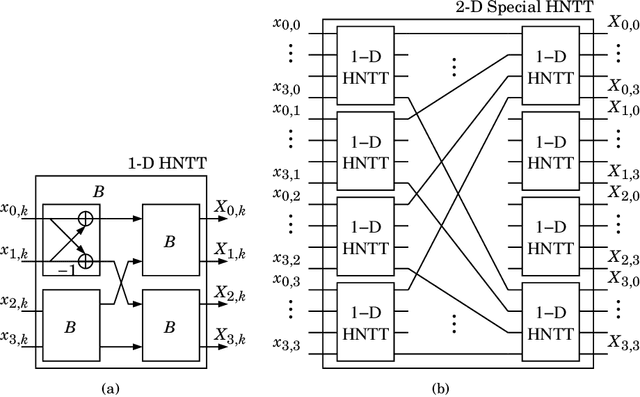
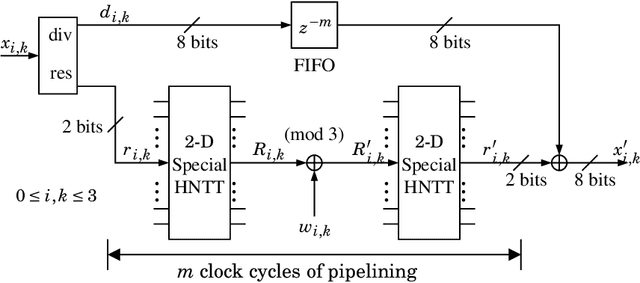
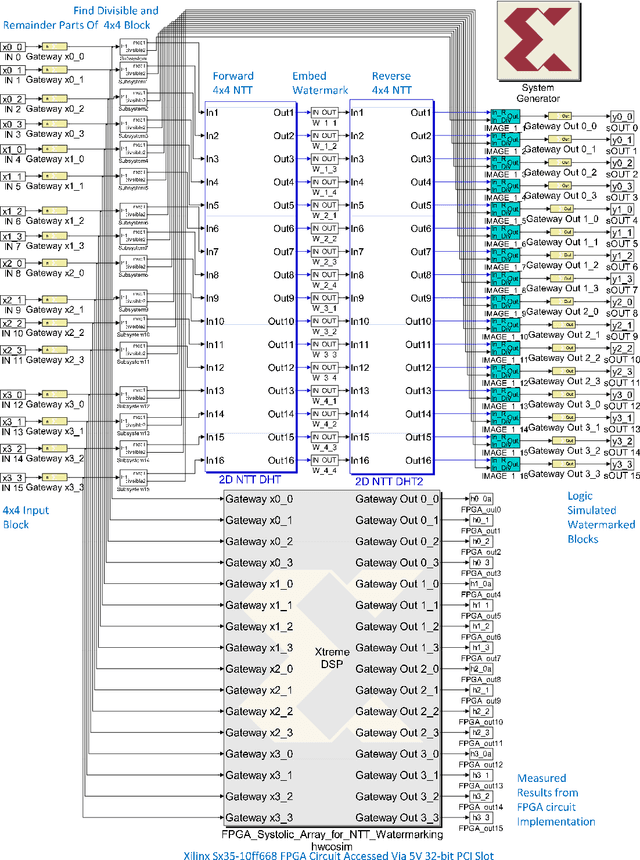

Number-theoretic transforms (NTTs) have been applied in the fragile watermarking of digital images. A block-parallel systolic-array architecture is proposed for watermarking based on the 2-D special Hartley NTT (HNTT). The proposed core employs two 2-D special HNTT hardware cores, each using digital arithmetic over $\mathrm{GF}(3)$, and processes $4\times4$ blocks of pixels in parallel every clock cycle. Prototypes are operational on a Xilinx Sx35-10ff668 FPGA device. The maximum estimated throughput of the FPGA circuit is 100 million $4\times4$ HNTT fragile watermarked blocks per second, when clocked at 100 MHz. Potential applications exist in high-traffic back-end servers dealing with large amounts of protected digital images requiring authentication, in remote-sensing for high-security surveillance applications, in real-time video processing of information of a sensitive nature or matters of national security, in video/photographic content management of corporate clients, in authenticating multimedia for the entertainment industry, in the authentication of electronic evidence material, and in real-time news streaming.
* 11 pages, 4 figures
Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation
Jun 21, 2022
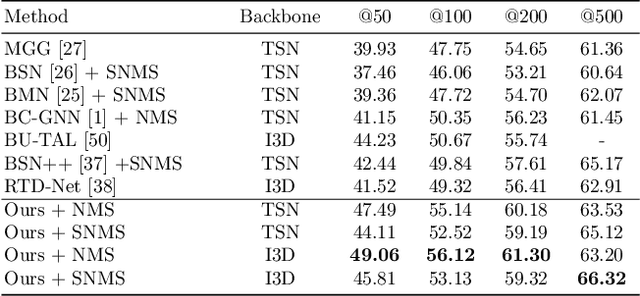
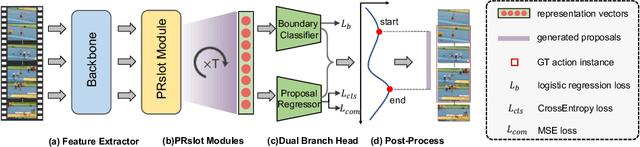

It has been found that temporal action proposal generation, which aims to discover the temporal action instances within the range of the start and end frames in the untrimmed videos, can largely benefit from proper temporal and semantic context exploitation. The latest efforts were dedicated to considering the temporal context and similarity-based semantic contexts through self-attention modules. However, they still suffer from cluttered background information and limited contextual feature learning. In this paper, we propose a novel Pyramid Region-based Slot Attention (PRSlot) module to address these issues. Instead of using the similarity computation, our PRSlot module directly learns the local relations in an encoder-decoder manner and generates the representation of a local region enhanced based on the attention over input features called \textit{slot}. Specifically, upon the input snippet-level features, PRSlot module takes the target snippet as \textit{query}, its surrounding region as \textit{key} and then generates slot representations for each \textit{query-key} slot by aggregating the local snippet context with a parallel pyramid strategy. Based on PRSlot modules, we present a novel Pyramid Region-based Slot Attention Network termed PRSA-Net to learn a unified visual representation with rich temporal and semantic context for better proposal generation. Extensive experiments are conducted on two widely adopted THUMOS14 and ActivityNet-1.3 benchmarks. Our PRSA-Net outperforms other state-of-the-art methods. In particular, we improve the AR@100 from the previous best 50.67% to 56.12% for proposal generation and raise the mAP under 0.5 tIoU from 51.9\% to 58.7\% for action detection on THUMOS14. \textit{Code is available at} \url{https://github.com/handhand123/PRSA-Net}
Weakly Supervised Representation Learning with Sparse Perturbations
Jun 02, 2022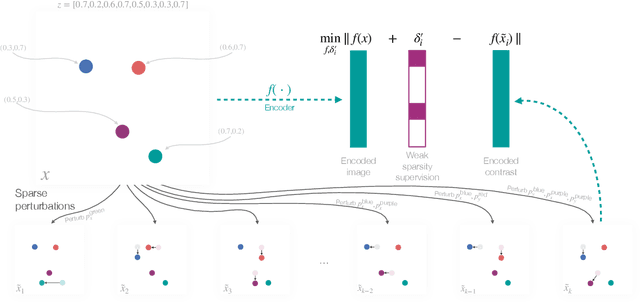
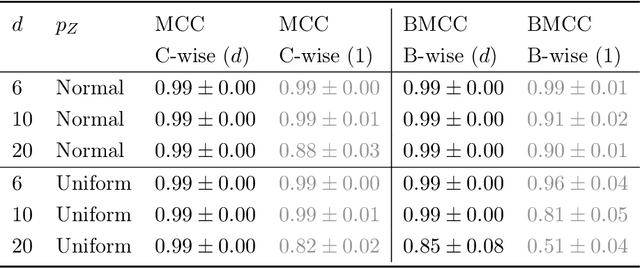
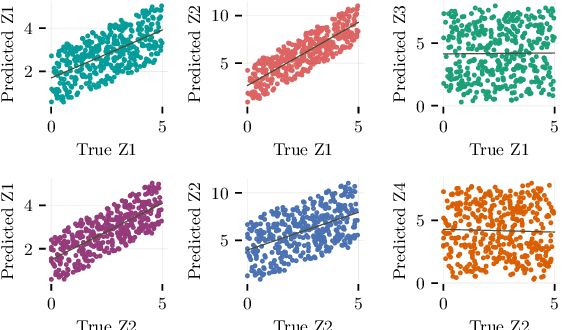
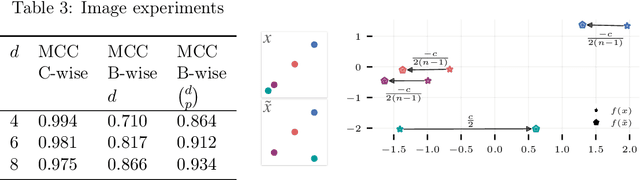
The theory of representation learning aims to build methods that provably invert the data generating process with minimal domain knowledge or any source of supervision. Most prior approaches require strong distributional assumptions on the latent variables and weak supervision (auxiliary information such as timestamps) to provide provable identification guarantees. In this work, we show that if one has weak supervision from observations generated by sparse perturbations of the latent variables--e.g. images in a reinforcement learning environment where actions move individual sprites--identification is achievable under unknown continuous latent distributions. We show that if the perturbations are applied only on mutually exclusive blocks of latents, we identify the latents up to those blocks. We also show that if these perturbation blocks overlap, we identify latents up to the smallest blocks shared across perturbations. Consequently, if there are blocks that intersect in one latent variable only, then such latents are identified up to permutation and scaling. We propose a natural estimation procedure based on this theory and illustrate it on low-dimensional synthetic and image-based experiments.
Speaker-conditioning Single-channel Target Speaker Extraction using Conformer-based Architectures
May 27, 2022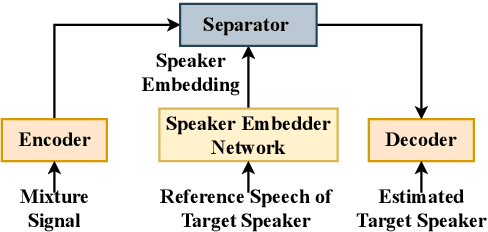
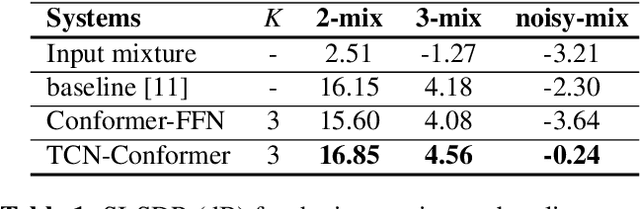
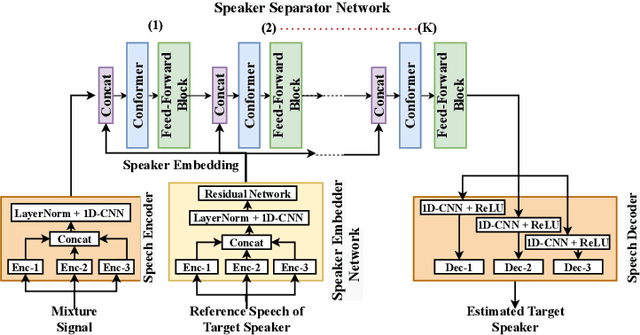
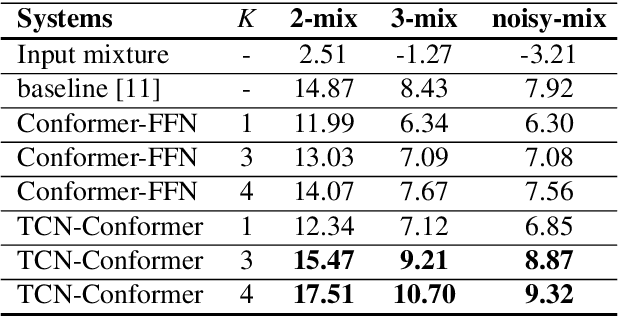
Target speaker extraction aims at extracting the target speaker from a mixture of multiple speakers exploiting auxiliary information about the target speaker. In this paper, we consider a complete time-domain target speaker extraction system consisting of a speaker embedder network and a speaker separator network which are jointly trained in an end-to-end learning process. We propose two different architectures for the speaker separator network which are based on the convolutional augmented transformer (conformer). The first architecture uses stacks of conformer and external feed-forward blocks (Conformer-FFN), while the second architecture uses stacks of temporal convolutional network (TCN) and conformer blocks (TCN-Conformer). Experimental results for 2-speaker mixtures, 3-speaker mixtures, and noisy mixtures of 2-speakers show that among the proposed separator networks, the TCN-Conformer significantly improves the target speaker extraction performance compared to the Conformer-FFN and a TCN-based baseline system.