 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Equipping Black-Box Policies with Model-Based Advice for Stable Nonlinear Control
Jun 02, 2022
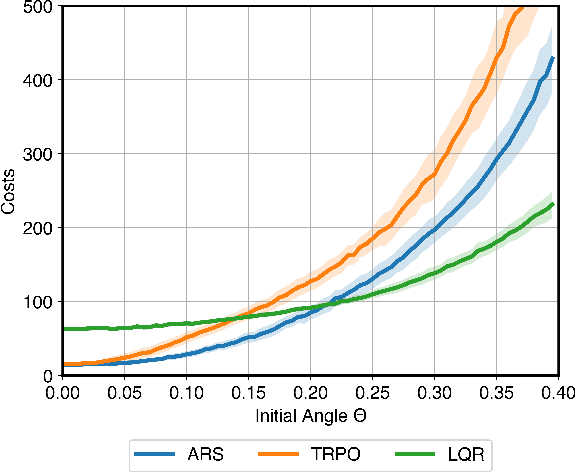

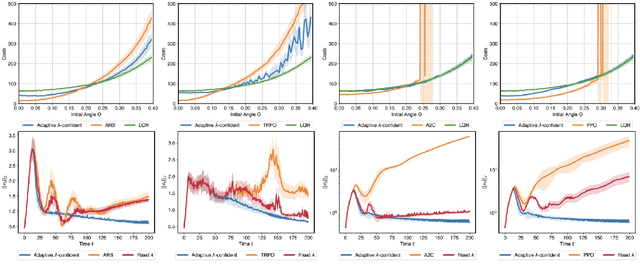
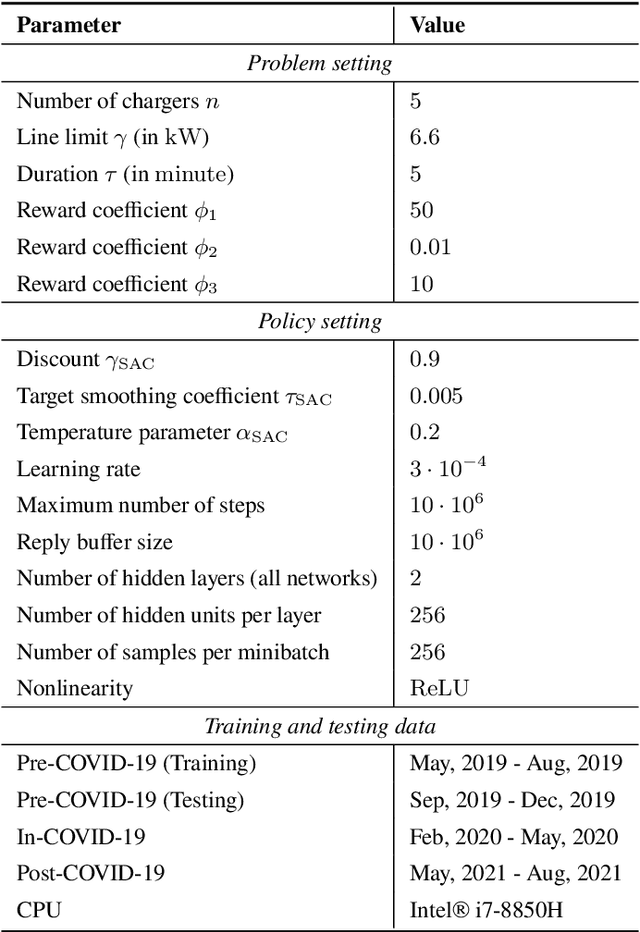
Machine-learned black-box policies are ubiquitous for nonlinear control problems. Meanwhile, crude model information is often available for these problems from, e.g., linear approximations of nonlinear dynamics. We study the problem of equipping a black-box control policy with model-based advice for nonlinear control on a single trajectory. We first show a general negative result that a naive convex combination of a black-box policy and a linear model-based policy can lead to instability, even if the two policies are both stabilizing. We then propose an adaptive $\lambda$-confident policy, with a coefficient $\lambda$ indicating the confidence in a black-box policy, and prove its stability. With bounded nonlinearity, in addition, we show that the adaptive $\lambda$-confident policy achieves a bounded competitive ratio when a black-box policy is near-optimal. Finally, we propose an online learning approach to implement the adaptive $\lambda$-confident policy and verify its efficacy in case studies about the CartPole problem and a real-world electric vehicle (EV) charging problem with data bias due to COVID-19.
Seismic Wavefield Reconstruction based on Compressed Sensing using Data-Driven Reduced-Order Model
Jun 18, 2022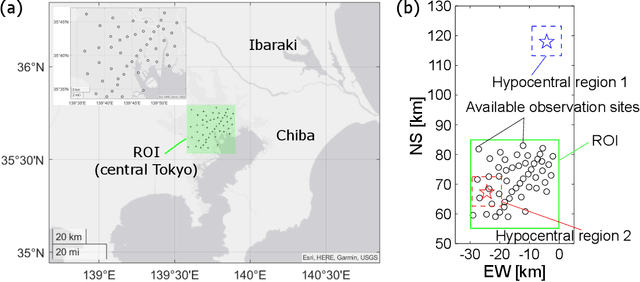
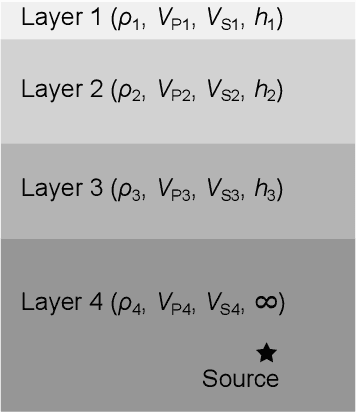
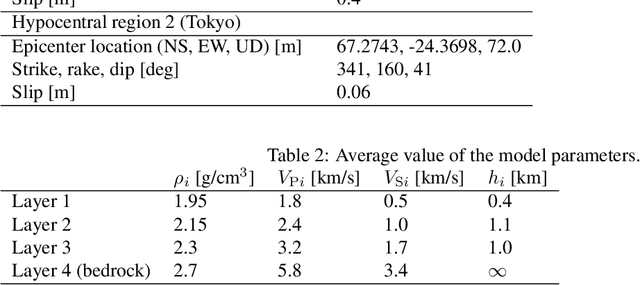
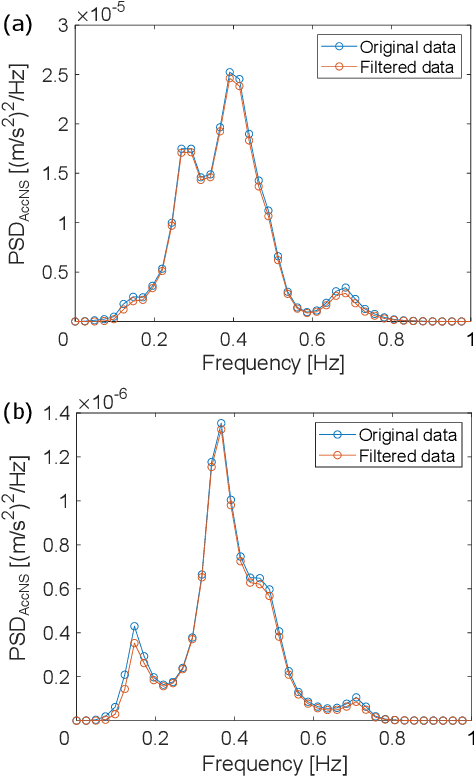
A seismic wavefield reconstruction framework based on compressed sensing using the data-driven reduced-order model (ROM) is proposed and its characteristics are investigated through numerical experiments. The data-driven ROM is generated from the dataset of the wavefield using the singular value decomposition. The spatially continuous seismic wavefield is reconstructed from the sparse and discrete observation and the data-driven ROM. The observation sites used for reconstruction are effectively selected by the sensor optimization method for linear inverse problems based on a greedy algorithm. The validity of the proposed method was confirmed by the reconstruction based on the noise-free observation. Since the ROM of the wavefield is used as prior information, the reconstruction error is reduced to an approximately lower error bound of the present framework, even though the number of sensors used for reconstruction is limited and randomly selected. In addition, the reconstruction error obtained by the proposed framework is much smaller than that obtained by the Gaussian process regression. For the numerical experiment with noise-contaminated observation, the reconstructed wavefield is degraded due to the observation noise, but the reconstruction error obtained by the present framework with all available observation sites is close to a lower error bound, even though the reconstructed wavefield using the Gaussian process regression is fully collapsed. Although the reconstruction error is larger than that obtained using all observation sites, the number of observation sites used for reconstruction can be reduced while minimizing the deterioration and scatter of the reconstructed data by combining it with the sensor optimization method.
Improving Fairness in Graph Neural Networks via Mitigating Sensitive Attribute Leakage
Jun 09, 2022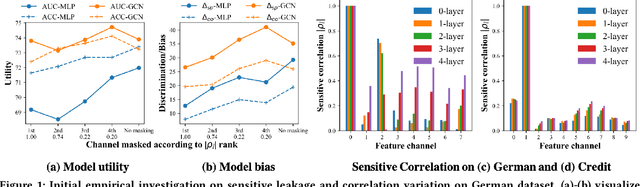
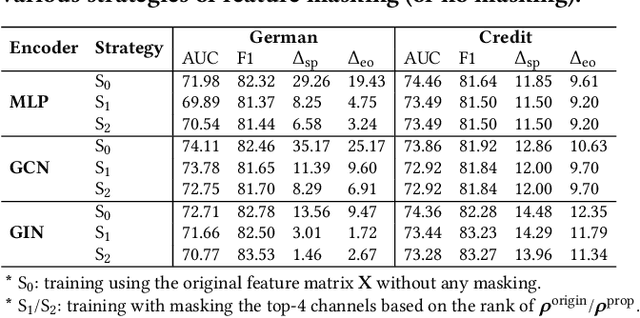
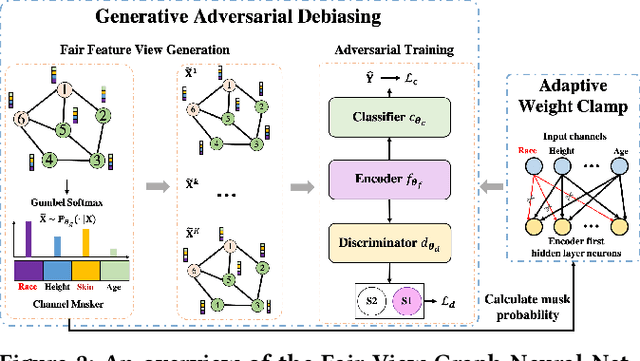

Graph Neural Networks (GNNs) have shown great power in learning node representations on graphs. However, they may inherit historical prejudices from training data, leading to discriminatory bias in predictions. Although some work has developed fair GNNs, most of them directly borrow fair representation learning techniques from non-graph domains without considering the potential problem of sensitive attribute leakage caused by feature propagation in GNNs. However, we empirically observe that feature propagation could vary the correlation of previously innocuous non-sensitive features to the sensitive ones. This can be viewed as a leakage of sensitive information which could further exacerbate discrimination in predictions. Thus, we design two feature masking strategies according to feature correlations to highlight the importance of considering feature propagation and correlation variation in alleviating discrimination. Motivated by our analysis, we propose Fair View Graph Neural Network (FairVGNN) to generate fair views of features by automatically identifying and masking sensitive-correlated features considering correlation variation after feature propagation. Given the learned fair views, we adaptively clamp weights of the encoder to avoid using sensitive-related features. Experiments on real-world datasets demonstrate that FairVGNN enjoys a better trade-off between model utility and fairness. Our code is publicly available at https://github.com/YuWVandy/FairVGNN.
Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation
Jun 21, 2022
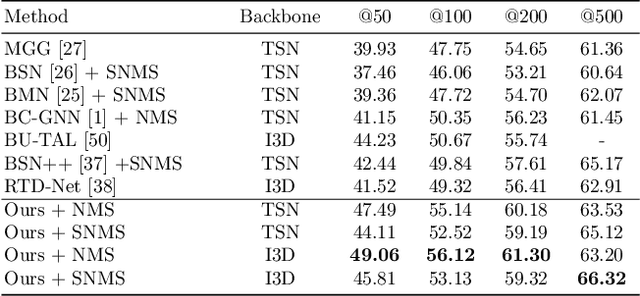
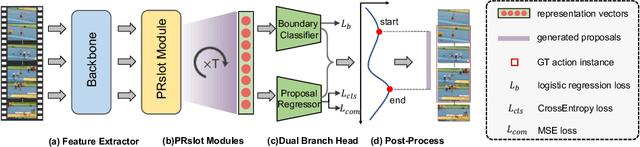

It has been found that temporal action proposal generation, which aims to discover the temporal action instances within the range of the start and end frames in the untrimmed videos, can largely benefit from proper temporal and semantic context exploitation. The latest efforts were dedicated to considering the temporal context and similarity-based semantic contexts through self-attention modules. However, they still suffer from cluttered background information and limited contextual feature learning. In this paper, we propose a novel Pyramid Region-based Slot Attention (PRSlot) module to address these issues. Instead of using the similarity computation, our PRSlot module directly learns the local relations in an encoder-decoder manner and generates the representation of a local region enhanced based on the attention over input features called \textit{slot}. Specifically, upon the input snippet-level features, PRSlot module takes the target snippet as \textit{query}, its surrounding region as \textit{key} and then generates slot representations for each \textit{query-key} slot by aggregating the local snippet context with a parallel pyramid strategy. Based on PRSlot modules, we present a novel Pyramid Region-based Slot Attention Network termed PRSA-Net to learn a unified visual representation with rich temporal and semantic context for better proposal generation. Extensive experiments are conducted on two widely adopted THUMOS14 and ActivityNet-1.3 benchmarks. Our PRSA-Net outperforms other state-of-the-art methods. In particular, we improve the AR@100 from the previous best 50.67% to 56.12% for proposal generation and raise the mAP under 0.5 tIoU from 51.9\% to 58.7\% for action detection on THUMOS14. \textit{Code is available at} \url{https://github.com/handhand123/PRSA-Net}
Interpolation-based Correlation Reduction Network for Semi-Supervised Graph Learning
Jun 06, 2022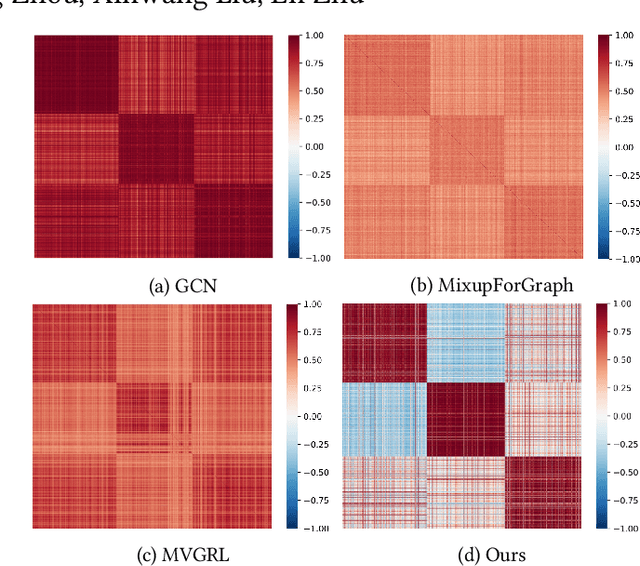

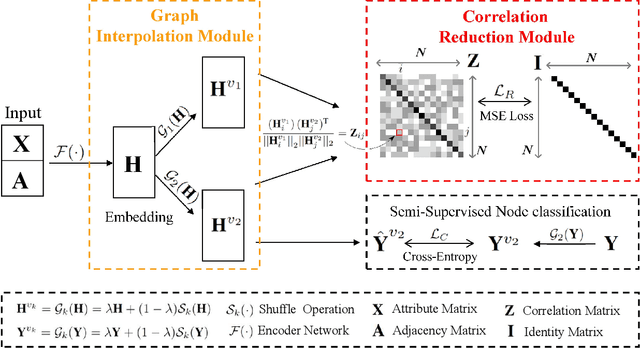
Graph Neural Networks (GNNs) have achieved promising performance in semi-supervised node classification in recent years. However, the problem of insufficient supervision, together with representation collapse, largely limits the performance of the GNNs in this field. To alleviate the collapse of node representations in semi-supervised scenario, we propose a novel graph contrastive learning method, termed Interpolation-based Correlation Reduction Network (ICRN). In our method, we improve the discriminative capability of the latent feature by enlarging the margin of decision boundaries and improving the cross-view consistency of the latent representation. Specifically, we first adopt an interpolation-based strategy to conduct data augmentation in the latent space and then force the prediction model to change linearly between samples. Second, we enable the learned network to tell apart samples across two interpolation-perturbed views through forcing the correlation matrix across views to approximate an identity matrix. By combining the two settings, we extract rich supervision information from both the abundant unlabeled nodes and the rare yet valuable labeled nodes for discriminative representation learning. Extensive experimental results on six datasets demonstrate the effectiveness and the generality of ICRN compared to the existing state-of-the-art methods.
Incorporating Temporal Information in Entailment Graph Mining
Sep 20, 2021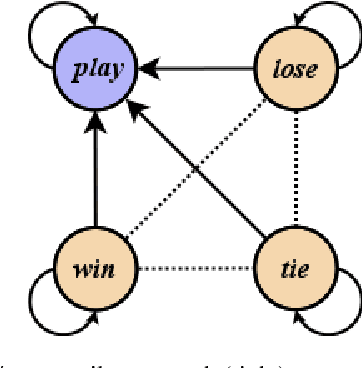
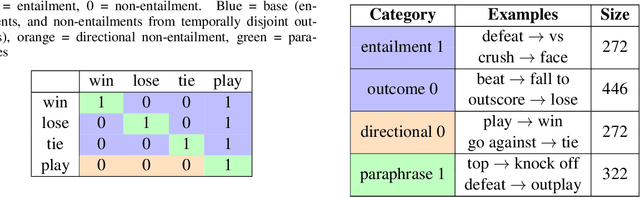
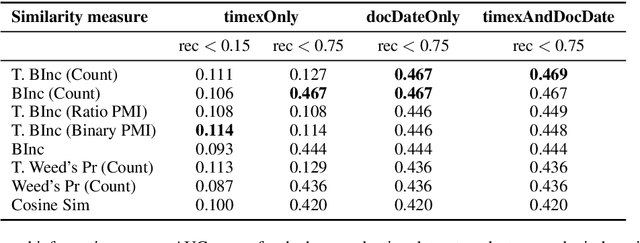
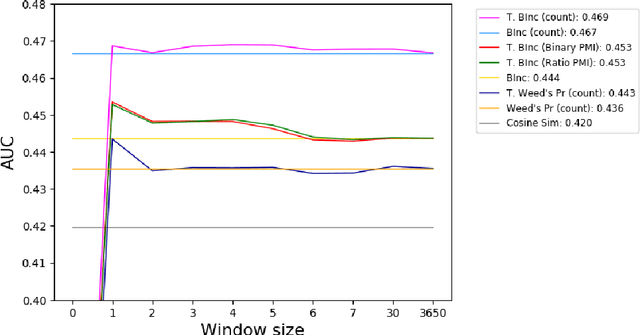
We present a novel method for injecting temporality into entailment graphs to address the problem of spurious entailments, which may arise from similar but temporally distinct events involving the same pair of entities. We focus on the sports domain in which the same pairs of teams play on different occasions, with different outcomes. We present an unsupervised model that aims to learn entailments such as win/lose $\rightarrow$ play, while avoiding the pitfall of learning non-entailments such as win $\not\rightarrow$ lose. We evaluate our model on a manually constructed dataset, showing that incorporating time intervals and applying a temporal window around them, are effective strategies.
* L. Guillou, S. Bijl de Vroe, M.J. Hosseini, M. Johnson, and M. Steedman. 2020. Incorporating temporal information in entailment graph mining. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 60-71, Barcelona, Spain (Online). Association for Computational Linguistics
Modeling Users' Contextualized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search
Mar 29, 2022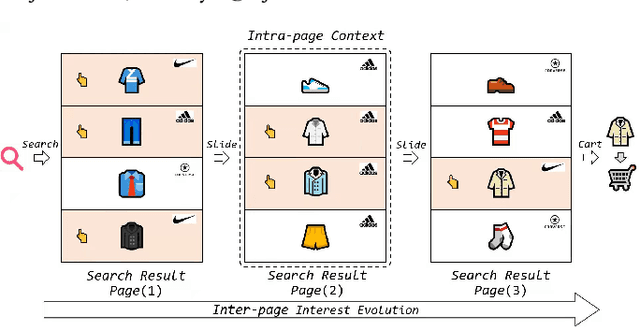

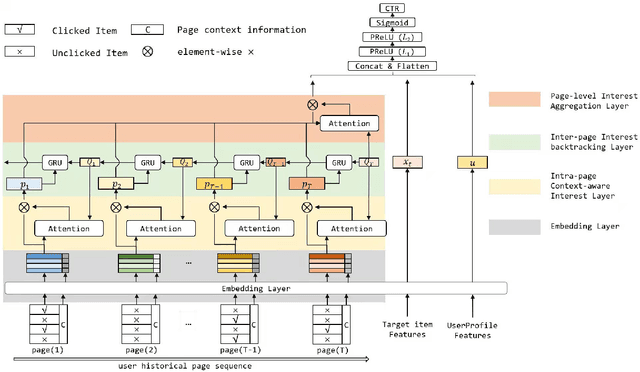
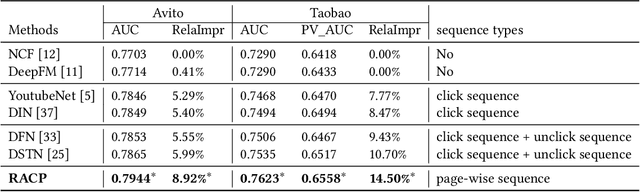
Modeling user's historical feedback is essential for Click-Through Rate Prediction in personalized search and recommendation. Existing methods usually only model users' positive feedback information such as click sequences which neglects the context information of the feedback. In this paper, we propose a new perspective for context-aware users' behavior modeling by including the whole page-wisely exposed products and the corresponding feedback as contextualized page-wise feedback sequence. The intra-page context information and inter-page interest evolution can be captured to learn more specific user preference. We design a novel neural ranking model RACP(i.e., Recurrent Attention over Contextualized Page sequence), which utilizes page-context aware attention to model the intra-page context. A recurrent attention process is used to model the cross-page interest convergence evolution as denoising the interest in the previous pages. Experiments on public and real-world industrial datasets verify our model's effectiveness.
MLO: Multi-Object Tracking and Lidar Odometry in Dynamic Environment
Apr 29, 2022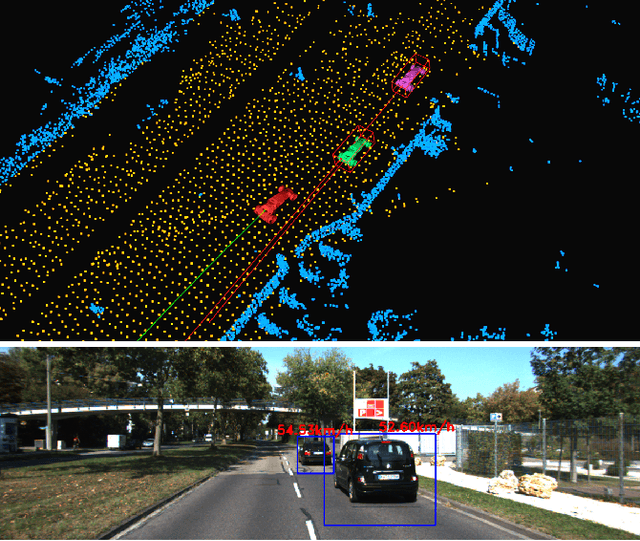
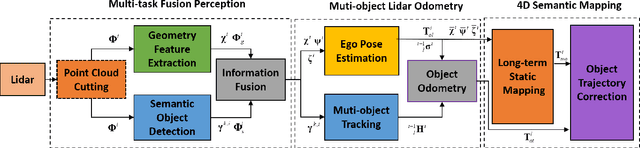
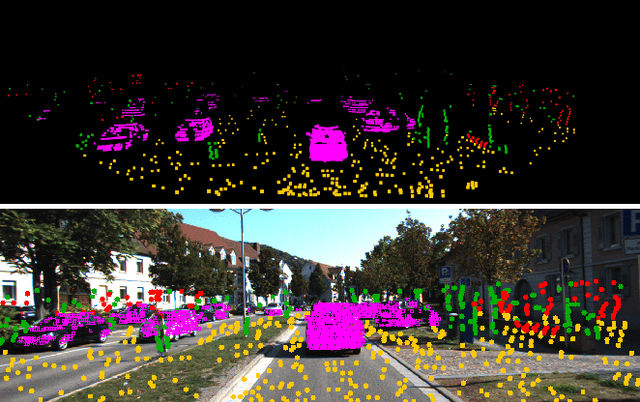
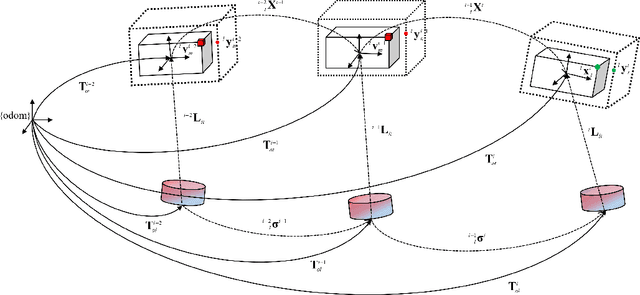
The SLAM system built on the static scene assumption will introduce significant estimation errors when a large number of moving objects appear in the field of view. Tracking and maintaining semantic objects is beneficial to understand the scene and provide rich decision information for planning and control modules. This paper introduces MLO , a multi-object Lidar odometry which tracks ego-motion and movable objects with only the lidar sensor. First, it achieves information extraction of foreground movable objects, surface road, and static background features based on geometry and object fusion perception module. While robustly estimating ego-motion, Multi-object tracking is accomplished through the least-squares method fused by 3D bounding boxes and geometric point clouds. Then, a continuous 4D semantic object map on the timeline can be created. Our approach is evaluated qualitatively and quantitatively under different scenarios on the public KITTI dataset. The experiment results show that the ego localization accuracy of MLO is better than A-LOAM system in highly dynamic, unstructured, and unknown semantic scenes. Meanwhile, the multi-object tracking method with semantic-geometry fusion also has apparent advantages in accuracy and tracking robustness compared with the single method.
Deep Coding Patterns Design for Compressive Near-Infrared Spectral Classification
May 27, 2022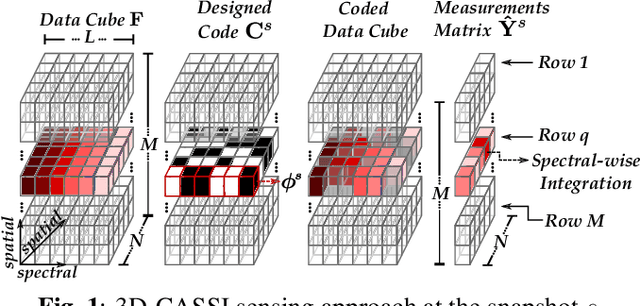
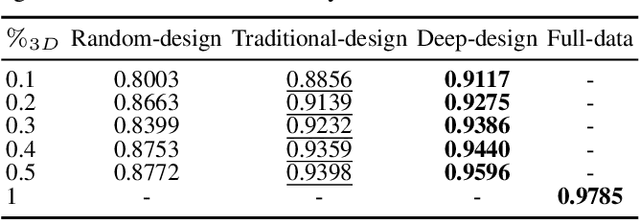
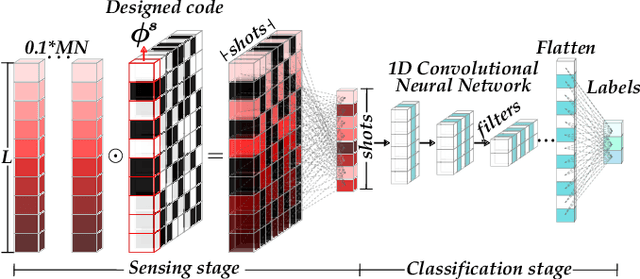

Compressive spectral imaging (CSI) has emerged as an attractive compression and sensing technique, primarily to sense spectral regions where traditional systems result in highly costly such as in the near-infrared spectrum. Recently, it has been shown that spectral classification can be performed directly in the compressive domain, considering the amount of spectral information embedded in the measurements, skipping the reconstruction step. Consequently, the classification quality directly depends on the set of coding patterns employed in the sensing step. Therefore, this work proposes an end-to-end approach to jointly design the coding patterns used in CSI and the network parameters to perform spectral classification directly from the embedded near-infrared compressive measurements. Extensive simulation on the three-dimensional coded aperture snapshot spectral imaging (3D-CASSI) system validates that the proposed design outperforms traditional and random design in up to 10% of classification accuracy.
* 5 pages, 5 figures
STRPM: A Spatiotemporal Residual Predictive Model for High-Resolution Video Prediction
Mar 30, 2022
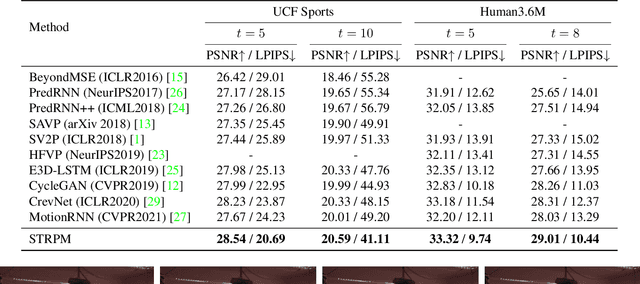
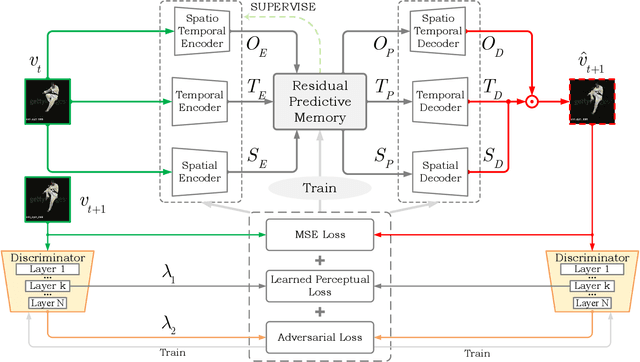
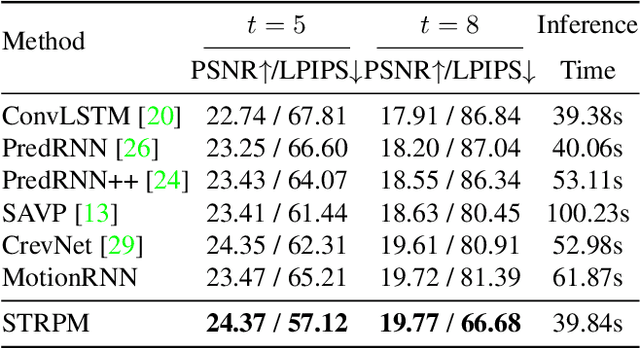
Although many video prediction methods have obtained good performance in low-resolution (64$\sim$128) videos, predictive models for high-resolution (512$\sim$4K) videos have not been fully explored yet, which are more meaningful due to the increasing demand for high-quality videos. Compared with low-resolution videos, high-resolution videos contain richer appearance (spatial) information and more complex motion (temporal) information. In this paper, we propose a Spatiotemporal Residual Predictive Model (STRPM) for high-resolution video prediction. On the one hand, we propose a Spatiotemporal Encoding-Decoding Scheme to preserve more spatiotemporal information for high-resolution videos. In this way, the appearance details for each frame can be greatly preserved. On the other hand, we design a Residual Predictive Memory (RPM) which focuses on modeling the spatiotemporal residual features (STRF) between previous and future frames instead of the whole frame, which can greatly help capture the complex motion information in high-resolution videos. In addition, the proposed RPM can supervise the spatial encoder and temporal encoder to extract different features in the spatial domain and the temporal domain, respectively. Moreover, the proposed model is trained using generative adversarial networks (GANs) with a learned perceptual loss (LP-loss) to improve the perceptual quality of the predictions. Experimental results show that STRPM can generate more satisfactory results compared with various existing methods.