 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Intelligent Agent for Hurricane Emergency Identification and Text Information Extraction from Streaming Social Media Big Data
Jun 14, 2021
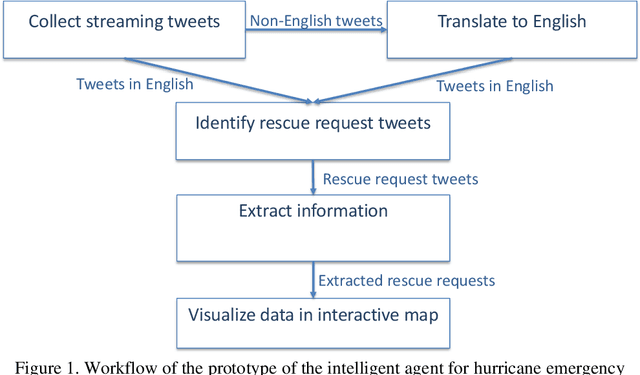
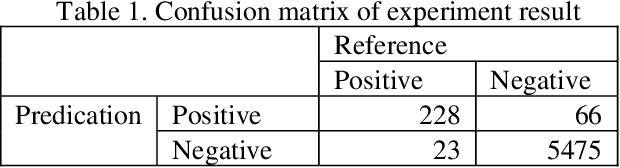
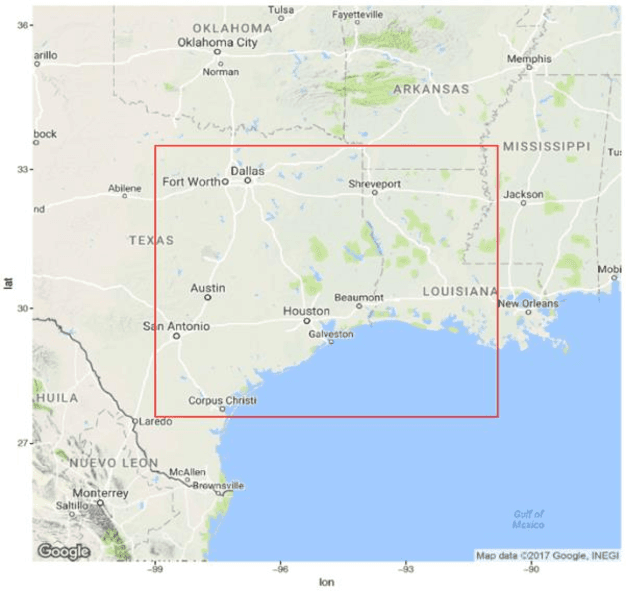
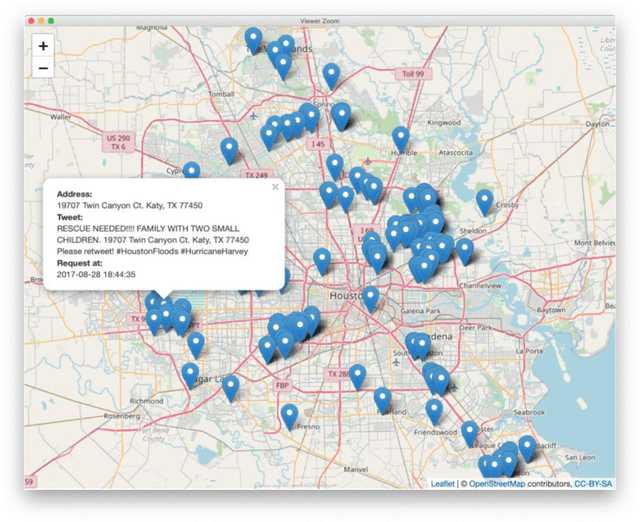
This paper presents our research on leveraging social media Big Data and AI to support hurricane disaster emergency response. The current practice of hurricane emergency response for rescue highly relies on emergency call centres. The more recent Hurricane Harvey event reveals the limitations of the current systems. We use Hurricane Harvey and the associated Houston flooding as the motivating scenario to conduct research and develop a prototype as a proof-of-concept of using an intelligent agent as a complementary role to support emergency centres in hurricane emergency response. This intelligent agent is used to collect real-time streaming tweets during a natural disaster event, to identify tweets requesting rescue, to extract key information such as address and associated geocode, and to visualize the extracted information in an interactive map in decision supports. Our experiment shows promising outcomes and the potential application of the research in support of hurricane emergency response.
Evaluating Fairness of Machine Learning Models Under Uncertain and Incomplete Information
Feb 16, 2021
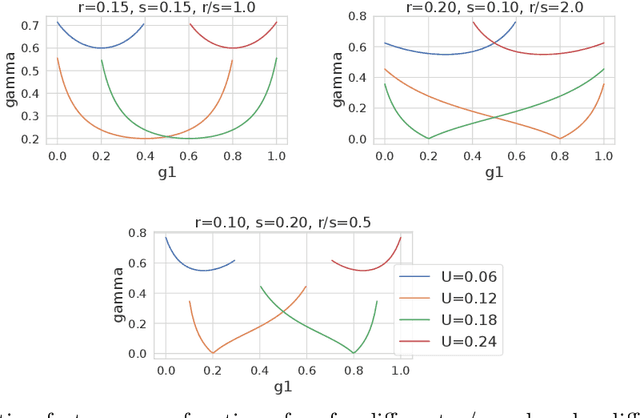


Training and evaluation of fair classifiers is a challenging problem. This is partly due to the fact that most fairness metrics of interest depend on both the sensitive attribute information and label information of the data points. In many scenarios it is not possible to collect large datasets with such information. An alternate approach that is commonly used is to separately train an attribute classifier on data with sensitive attribute information, and then use it later in the ML pipeline to evaluate the bias of a given classifier. While such decoupling helps alleviate the problem of demographic scarcity, it raises several natural questions such as: how should the attribute classifier be trained?, and how should one use a given attribute classifier for accurate bias estimation? In this work we study this question from both theoretical and empirical perspectives. We first experimentally demonstrate that the test accuracy of the attribute classifier is not always correlated with its effectiveness in bias estimation for a downstream model. In order to further investigate this phenomenon, we analyze an idealized theoretical model and characterize the structure of the optimal classifier. Our analysis has surprising and counter-intuitive implications where in certain regimes one might want to distribute the error of the attribute classifier as unevenly as possible among the different subgroups. Based on our analysis we develop heuristics for both training and using attribute classifiers for bias estimation in the data scarce regime. We empirically demonstrate the effectiveness of our approach on real and simulated data.
UAS Imagery and Computer Vision for Site-Specific Weed Control in Corn
Apr 28, 2022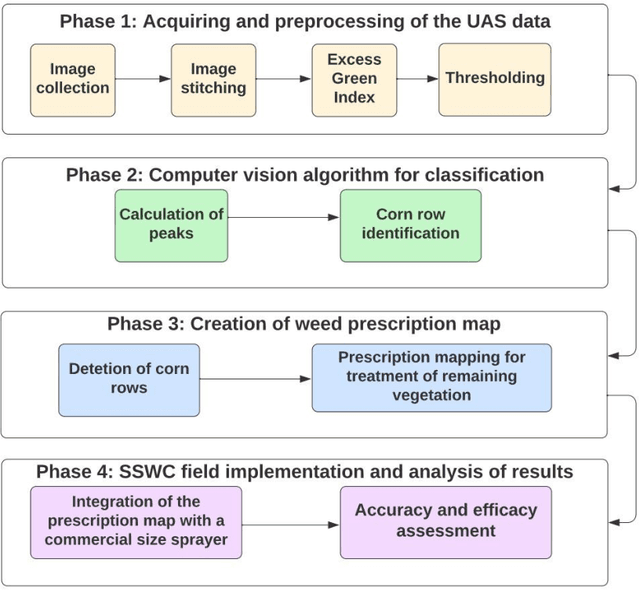
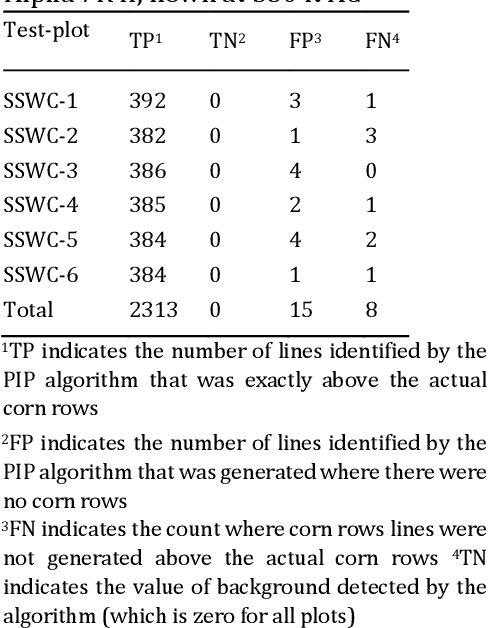

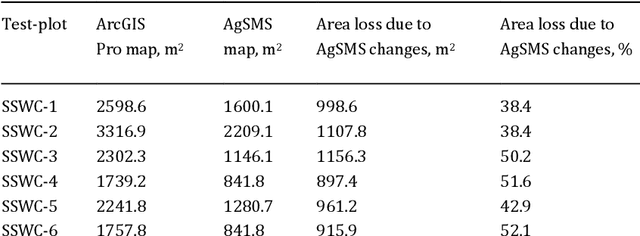
Currently, weed control in a corn field is performed by a blanket application of herbicides which do not consider spatial distribution information of weeds and also uses an extensive amount of chemical herbicides. In order to reduce the amount of chemicals, we used drone based high-resolution imagery and computer-vision techniwue to perform site-specific weed control in corn.
Implicit Sample Extension for Unsupervised Person Re-Identification
Apr 14, 2022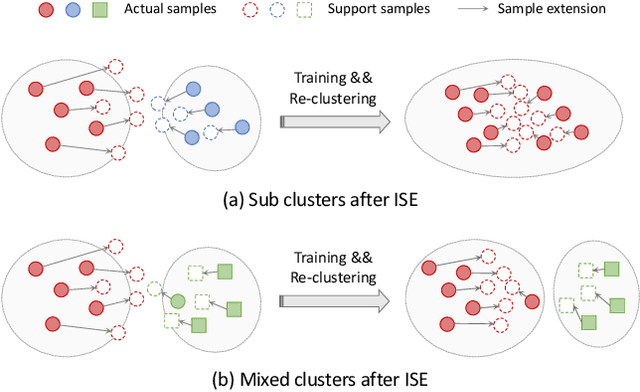
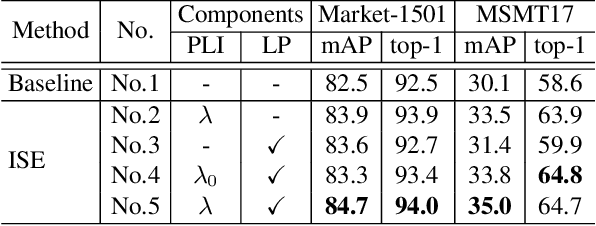
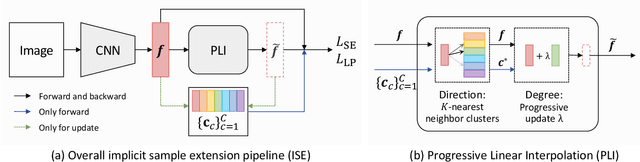
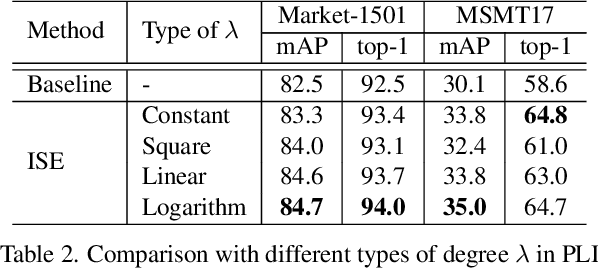
Most existing unsupervised person re-identification (Re-ID) methods use clustering to generate pseudo labels for model training. Unfortunately, clustering sometimes mixes different true identities together or splits the same identity into two or more sub clusters. Training on these noisy clusters substantially hampers the Re-ID accuracy. Due to the limited samples in each identity, we suppose there may lack some underlying information to well reveal the accurate clusters. To discover these information, we propose an Implicit Sample Extension (\OurWholeMethod) method to generate what we call support samples around the cluster boundaries. Specifically, we generate support samples from actual samples and their neighbouring clusters in the embedding space through a progressive linear interpolation (PLI) strategy. PLI controls the generation with two critical factors, i.e., 1) the direction from the actual sample towards its K-nearest clusters and 2) the degree for mixing up the context information from the K-nearest clusters. Meanwhile, given the support samples, ISE further uses a label-preserving loss to pull them towards their corresponding actual samples, so as to compact each cluster. Consequently, ISE reduces the "sub and mixed" clustering errors, thus improving the Re-ID performance. Extensive experiments demonstrate that the proposed method is effective and achieves state-of-the-art performance for unsupervised person Re-ID. Code is available at: \url{https://github.com/PaddlePaddle/PaddleClas}.
On-device modeling of user's social context and familiar places from smartphone-embedded sensor data
May 18, 2022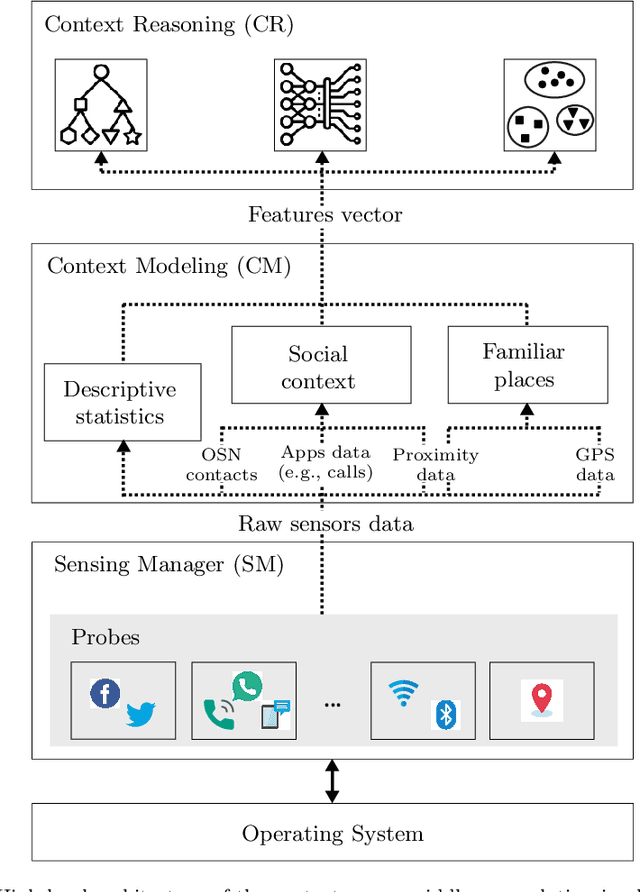

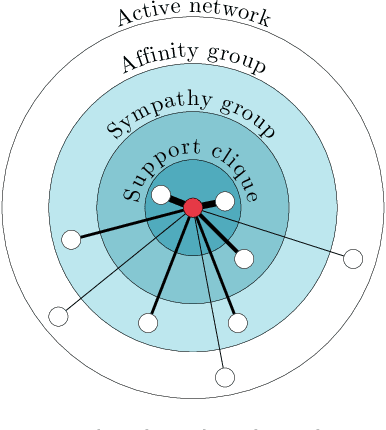
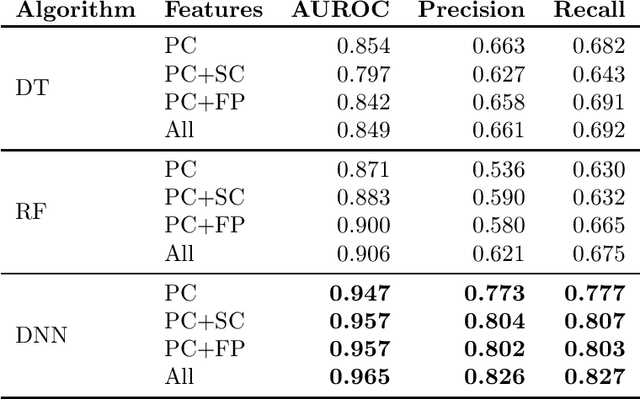
Context modeling and recognition represent complex tasks that allow mobile and ubiquitous computing applications to adapt to the user's situation. Current solutions mainly focus on limited context information generally processed on centralized architectures, potentially exposing users' personal data to privacy leakage, and missing personalization features. For these reasons on-device context modeling and recognition represent the current research trend in this area. Among the different information characterizing the user's context in mobile environments, social interactions and visited locations remarkably contribute to the characterization of daily life scenarios. In this paper we propose a novel, unsupervised and lightweight approach to model the user's social context and her locations based on ego networks directly on the user mobile device. Relying on this model, the system is able to extract high-level and semantic-rich context features from smartphone-embedded sensors data. Specifically, for the social context it exploits data related to both physical and cyber social interactions among users and their devices. As far as location context is concerned, we assume that it is more relevant to model the familiarity degree of a specific location for the user's context than the raw location data, both in terms of GPS coordinates and proximity devices. By using 5 real-world datasets, we assess the structure of the social and location ego networks, we provide a semantic evaluation of the proposed models and a complexity evaluation in terms of mobile computing performance. Finally, we demonstrate the relevance of the extracted features by showing the performance of 3 machine learning algorithms to recognize daily-life situations, obtaining an improvement of 3% of AUROC, 9% of Precision, and 5% in terms of Recall with respect to use only features related to physical context.
Visual Place Recognition using LiDAR Intensity Information
Mar 17, 2021


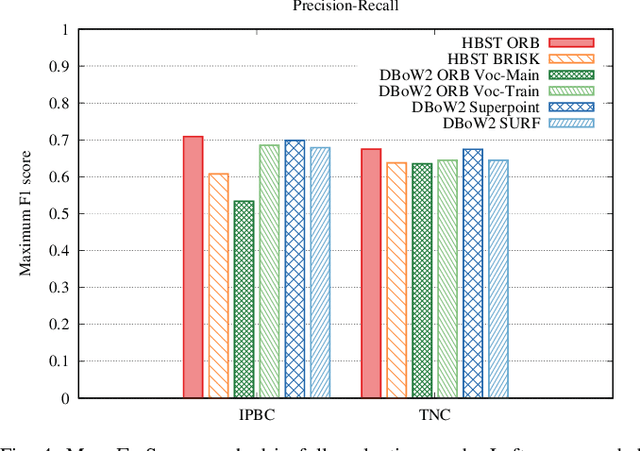
Robots and autonomous systems need to know where they are within a map to navigate effectively. Thus, simultaneous localization and mapping or SLAM is a common building block of robot navigation systems. When building a map via a SLAM system, robots need to re-recognize places to find loop closure and reduce the odometry drift. Image-based place recognition received a lot of attention in computer vision, and in this work, we investigate how such approaches can be used for 3D LiDAR data. Recent LiDAR sensors produce high-resolution 3D scans in combination with comparably stable intensity measurements. Through a cylindrical projection, we can turn this information into a panoramic image. As a result, we can apply techniques from visual place recognition to LiDAR intensity data. The question of how well this approach works in practice has not been answered so far. This paper provides an analysis of how such visual techniques can be with LiDAR data, and we provide an evaluation on different datasets. Our results suggest that this form of place recognition is possible and an effective means for determining loop closures.
A Synapse-Threshold Synergistic Learning Approach for Spiking Neural Networks
Jun 10, 2022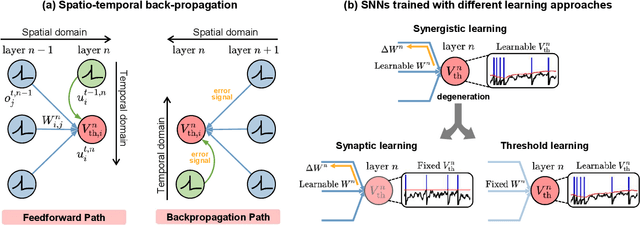
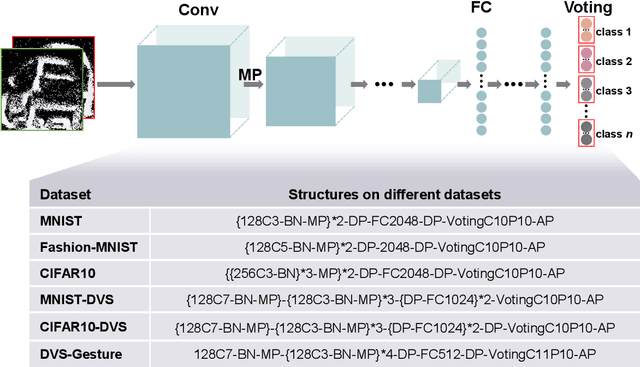
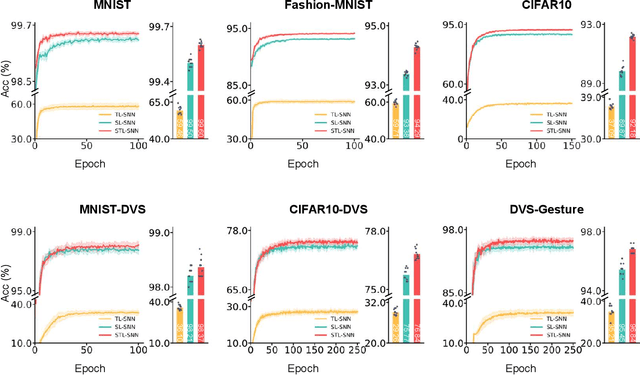
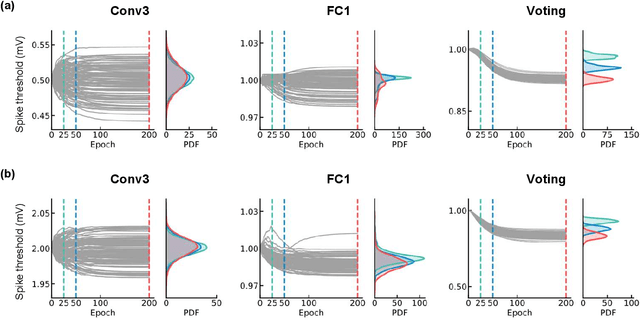
Spiking neural networks (SNNs) have demonstrated excellent capabilities in various intelligent scenarios. Most existing methods for training SNNs are based on the concept of synaptic plasticity; however, learning in the realistic brain also utilizes intrinsic non-synaptic mechanisms of neurons. The spike threshold of biological neurons is a critical intrinsic neuronal feature that exhibits rich dynamics on a millisecond timescale and has been proposed as an underlying mechanism that facilitates neural information processing. In this study, we develop a novel synergistic learning approach that simultaneously trains synaptic weights and spike thresholds in SNNs. SNNs trained with synapse-threshold synergistic learning (STL-SNNs) achieve significantly higher accuracies on various static and neuromorphic datasets than SNNs trained with two single-learning models of the synaptic learning (SL) and the threshold learning (TL). During training, the synergistic learning approach optimizes neural thresholds, providing the network with stable signal transmission via appropriate firing rates. Further analysis indicates that STL-SNNs are robust to noisy data and exhibit low energy consumption for deep network structures. Additionally, the performance of STL-SNN can be further improved by introducing a generalized joint decision framework (JDF). Overall, our findings indicate that biologically plausible synergies between synaptic and intrinsic non-synaptic mechanisms may provide a promising approach for developing highly efficient SNN learning methods.
Accurate Portraits of Scientific Resources and Knowledge Service Components
Apr 11, 2022With the advent of the cloud computing era, the cost of creating, capturing and managing information has gradually decreased. The amount of data in the Internet is also showing explosive growth, and more and more scientific and technological resources are uploaded to the network. Different from news and social media data ubiquitous in the Internet, the main body of scientific and technological resources is composed of academic-style resources or entities such as papers, patents, authors, and research institutions. There is a rich relationship network between resources, from which a large amount of cutting-edge scientific and technological information can be mined. There are a large number of management and classification standards for existing scientific and technological resources, but these standards are difficult to completely cover all entities and associations of scientific and technological resources, and cannot accurately extract important information contained in scientific and technological resources. How to construct a complete and accurate representation of scientific and technological resources from structured and unstructured reports and texts in the network, and how to tap the potential value of scientific and technological resources is an urgent problem. The solution is to construct accurate portraits of scientific and technological resources in combination with knowledge graph related technologies.
Remember the Past: Distilling Datasets into Addressable Memories for Neural Networks
Jun 06, 2022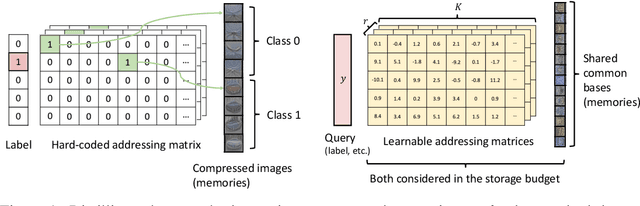

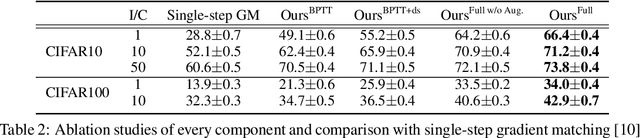
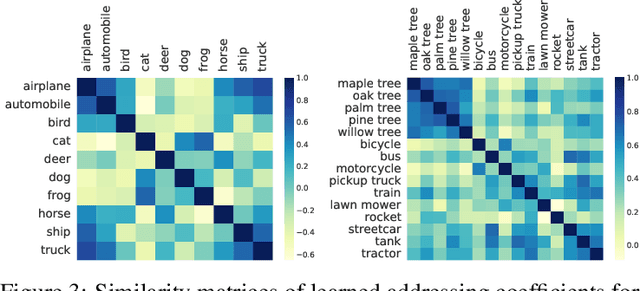
We propose an algorithm that compresses the critical information of a large dataset into compact addressable memories. These memories can then be recalled to quickly re-train a neural network and recover the performance (instead of storing and re-training on the full original dataset). Building upon the dataset distillation framework, we make a key observation that a shared common representation allows for more efficient and effective distillation. Concretely, we learn a set of bases (aka "memories") which are shared between classes and combined through learned flexible addressing functions to generate a diverse set of training examples. This leads to several benefits: 1) the size of compressed data does not necessarily grow linearly with the number of classes; 2) an overall higher compression rate with more effective distillation is achieved; and 3) more generalized queries are allowed beyond recalling the original classes. We demonstrate state-of-the-art results on the dataset distillation task across five benchmarks, including up to 16.5% and 9.7% in retained accuracy improvement when distilling CIFAR10 and CIFAR100 respectively. We then leverage our framework to perform continual learning, achieving state-of-the-art results on four benchmarks, with 23.2% accuracy improvement on MANY.
DrugEHRQA: A Question Answering Dataset on Structured and Unstructured Electronic Health Records For Medicine Related Queries
May 03, 2022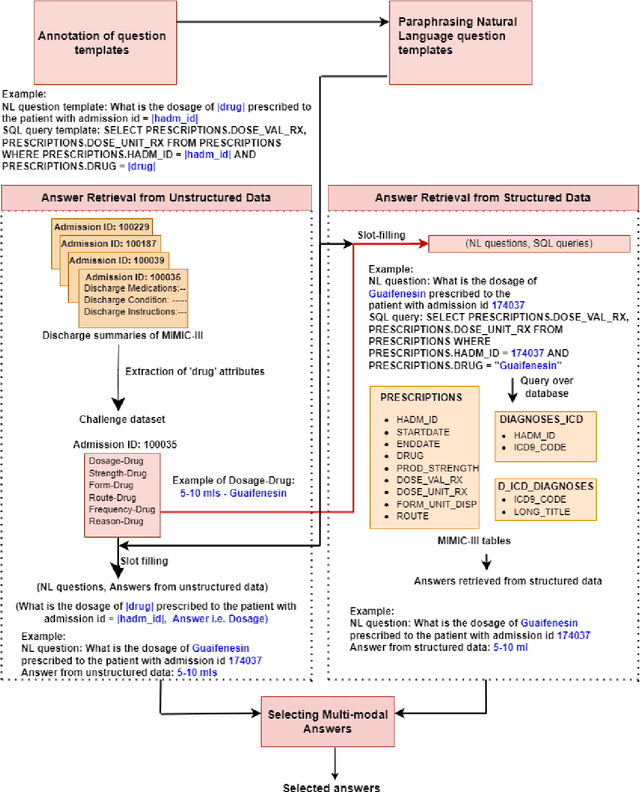
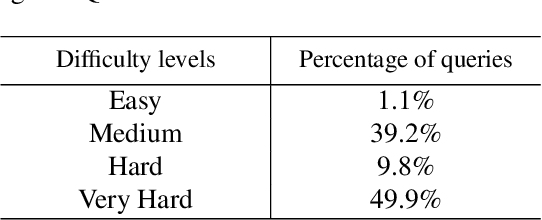


This paper develops the first question answering dataset (DrugEHRQA) containing question-answer pairs from both structured tables and unstructured notes from a publicly available Electronic Health Record (EHR). EHRs contain patient records, stored in structured tables and unstructured clinical notes. The information in structured and unstructured EHRs is not strictly disjoint: information may be duplicated, contradictory, or provide additional context between these sources. Our dataset has medication-related queries, containing over 70,000 question-answer pairs. To provide a baseline model and help analyze the dataset, we have used a simple model (MultimodalEHRQA) which uses the predictions of a modality selection network to choose between EHR tables and clinical notes to answer the questions. This is used to direct the questions to the table-based or text-based state-of-the-art QA model. In order to address the problem arising from complex, nested queries, this is the first time Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers (RAT-SQL) has been used to test the structure of query templates in EHR data. Our goal is to provide a benchmark dataset for multi-modal QA systems, and to open up new avenues of research in improving question answering over EHR structured data by using context from unstructured clinical data.