 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Implicit Sample Extension for Unsupervised Person Re-Identification
Apr 14, 2022
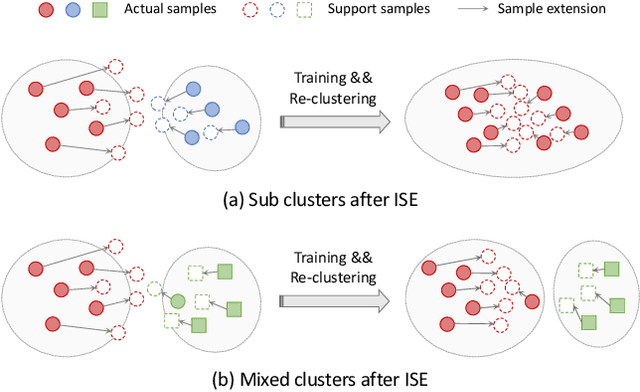
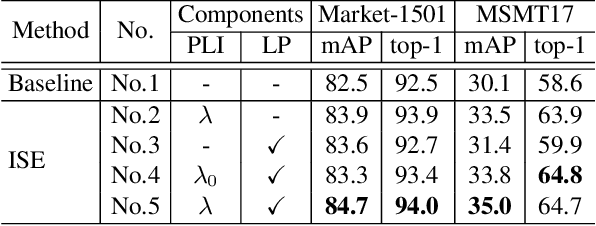
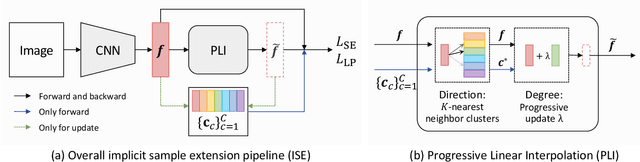
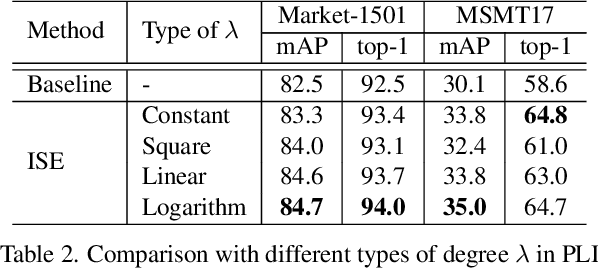
Most existing unsupervised person re-identification (Re-ID) methods use clustering to generate pseudo labels for model training. Unfortunately, clustering sometimes mixes different true identities together or splits the same identity into two or more sub clusters. Training on these noisy clusters substantially hampers the Re-ID accuracy. Due to the limited samples in each identity, we suppose there may lack some underlying information to well reveal the accurate clusters. To discover these information, we propose an Implicit Sample Extension (\OurWholeMethod) method to generate what we call support samples around the cluster boundaries. Specifically, we generate support samples from actual samples and their neighbouring clusters in the embedding space through a progressive linear interpolation (PLI) strategy. PLI controls the generation with two critical factors, i.e., 1) the direction from the actual sample towards its K-nearest clusters and 2) the degree for mixing up the context information from the K-nearest clusters. Meanwhile, given the support samples, ISE further uses a label-preserving loss to pull them towards their corresponding actual samples, so as to compact each cluster. Consequently, ISE reduces the "sub and mixed" clustering errors, thus improving the Re-ID performance. Extensive experiments demonstrate that the proposed method is effective and achieves state-of-the-art performance for unsupervised person Re-ID. Code is available at: \url{https://github.com/PaddlePaddle/PaddleClas}.
Unsupervised inter-frame motion correction for whole-body dynamic PET using convolutional long short-term memory in a convolutional neural network
Jun 13, 2022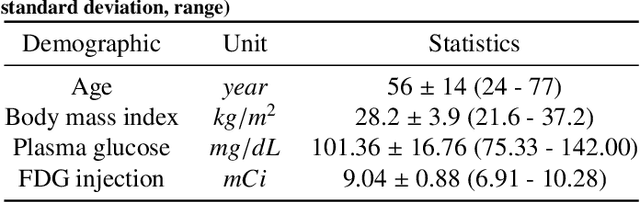
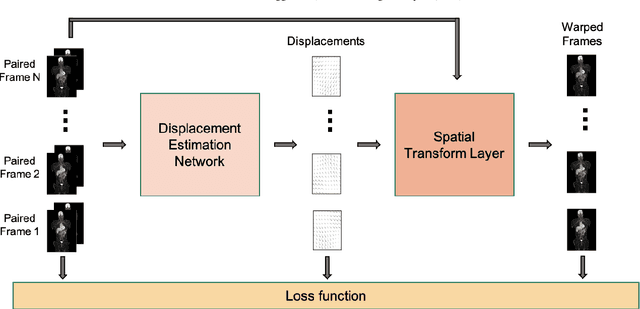
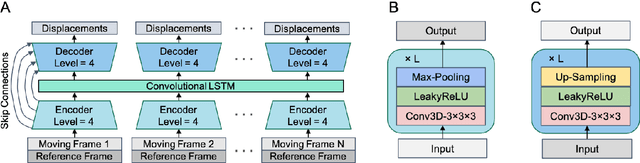
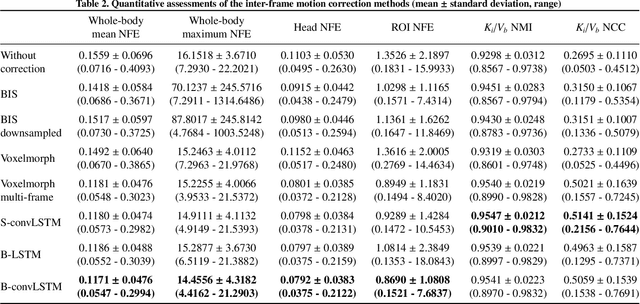
Subject motion in whole-body dynamic PET introduces inter-frame mismatch and seriously impacts parametric imaging. Traditional non-rigid registration methods are generally computationally intense and time-consuming. Deep learning approaches are promising in achieving high accuracy with fast speed, but have yet been investigated with consideration for tracer distribution changes or in the whole-body scope. In this work, we developed an unsupervised automatic deep learning-based framework to correct inter-frame body motion. The motion estimation network is a convolutional neural network with a combined convolutional long short-term memory layer, fully utilizing dynamic temporal features and spatial information. Our dataset contains 27 subjects each under a 90-min FDG whole-body dynamic PET scan. With 9-fold cross-validation, compared with both traditional and deep learning baselines, we demonstrated that the proposed network obtained superior performance in enhanced qualitative and quantitative spatial alignment between parametric $K_{i}$ and $V_{b}$ images and in significantly reduced parametric fitting error. We also showed the potential of the proposed motion correction method for impacting downstream analysis of the estimated parametric images, improving the ability to distinguish malignant from benign hypermetabolic regions of interest. Once trained, the motion estimation inference time of our proposed network was around 460 times faster than the conventional registration baseline, showing its potential to be easily applied in clinical settings.
InfoDCL: A Distantly Supervised Contrastive Learning Framework for Social Meaning
Mar 15, 2022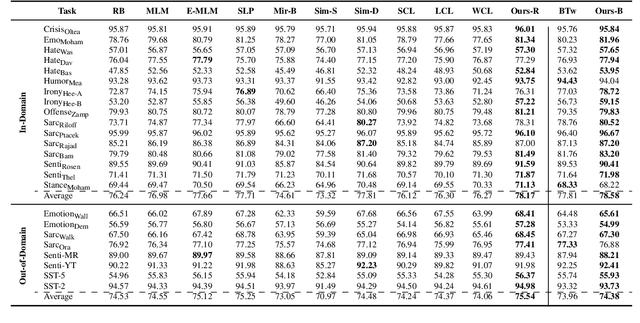
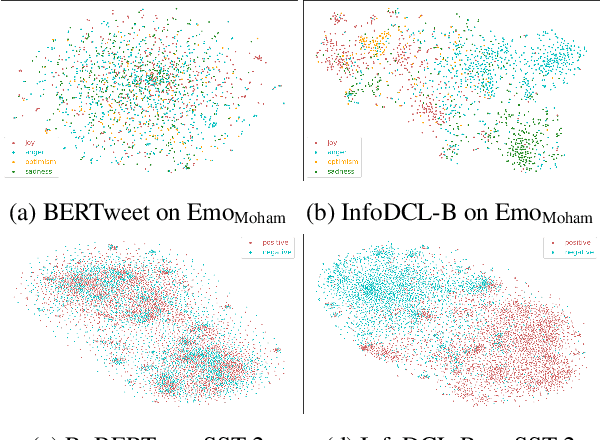
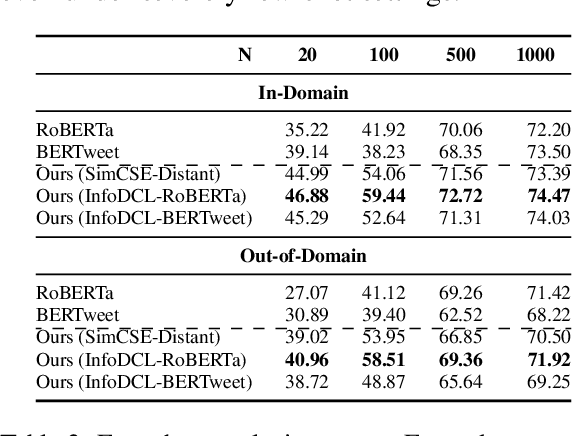
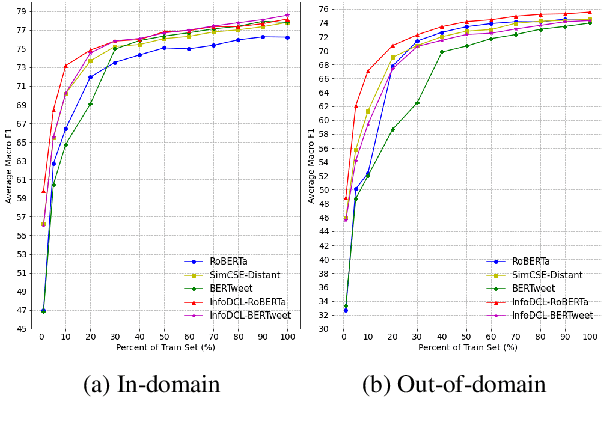
Existing supervised contrastive learning frameworks suffer from two major drawbacks: (i) they depend on labeled data, which is limited for the majority of tasks in real-world, and (ii) they incorporate inter-class relationships based on instance-level information, while ignoring corpus-level information, for weighting negative samples. To mitigate these challenges, we propose an effective distantly supervised contrastive learning framework (InfoDCL) that makes use of naturally occurring surrogate labels in the context of contrastive learning and employs pointwise mutual information to leverage corpus-level information. Our framework outperforms an extensive set of existing contrastive learning methods (self-supervised, supervised, and weakly supervised) on a wide range of social meaning tasks (in-domain and out-of-domain), in both the general and few-shot settings. Our method is also language-agnostic, as we demonstrate on three languages in addition to English.
Accurate Portraits of Scientific Resources and Knowledge Service Components
Apr 11, 2022With the advent of the cloud computing era, the cost of creating, capturing and managing information has gradually decreased. The amount of data in the Internet is also showing explosive growth, and more and more scientific and technological resources are uploaded to the network. Different from news and social media data ubiquitous in the Internet, the main body of scientific and technological resources is composed of academic-style resources or entities such as papers, patents, authors, and research institutions. There is a rich relationship network between resources, from which a large amount of cutting-edge scientific and technological information can be mined. There are a large number of management and classification standards for existing scientific and technological resources, but these standards are difficult to completely cover all entities and associations of scientific and technological resources, and cannot accurately extract important information contained in scientific and technological resources. How to construct a complete and accurate representation of scientific and technological resources from structured and unstructured reports and texts in the network, and how to tap the potential value of scientific and technological resources is an urgent problem. The solution is to construct accurate portraits of scientific and technological resources in combination with knowledge graph related technologies.
RefCrowd: Grounding the Target in Crowd with Referring Expressions
Jun 16, 2022
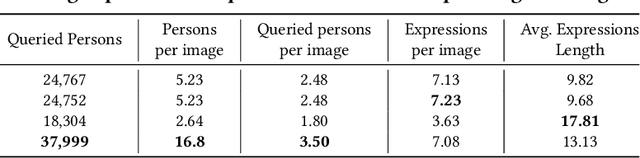

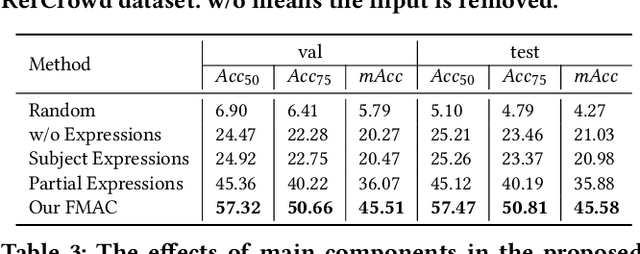
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.
From Labels to Priors in Capsule Endoscopy: A Prior Guided Approach for Improving Generalization with Few Labels
Jun 10, 2022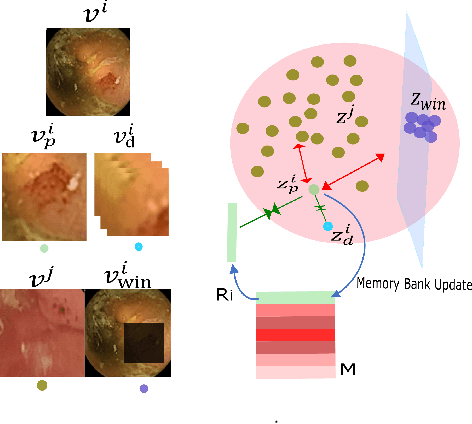

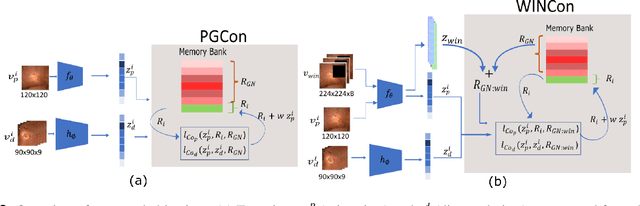

The lack of generalizability of deep learning approaches for the automated diagnosis of pathologies in Wireless Capsule Endoscopy (WCE) has prevented any significant advantages from trickling down to real clinical practices. As a result, disease management using WCE continues to depend on exhaustive manual investigations by medical experts. This explains its limited use despite several advantages. Prior works have considered using higher quality and quantity of labels as a way of tackling the lack of generalization, however this is hardly scalable considering pathology diversity not to mention that labeling large datasets encumbers the medical staff additionally. We propose using freely available domain knowledge as priors to learn more robust and generalizable representations. We experimentally show that domain priors can benefit representations by acting in proxy of labels, thereby significantly reducing the labeling requirement while still enabling fully unsupervised yet pathology-aware learning. We use the contrastive objective along with prior-guided views during pretraining, where the view choices inspire sensitivity to pathological information. Extensive experiments on three datasets show that our method performs better than (or closes gap with) the state-of-the-art in the domain, establishing a new benchmark in pathology classification and cross-dataset generalization, as well as scaling to unseen pathology categories.
Toward Unpaired Multi-modal Medical Image Segmentation via Learning Structured Semantic Consistency
Jun 21, 2022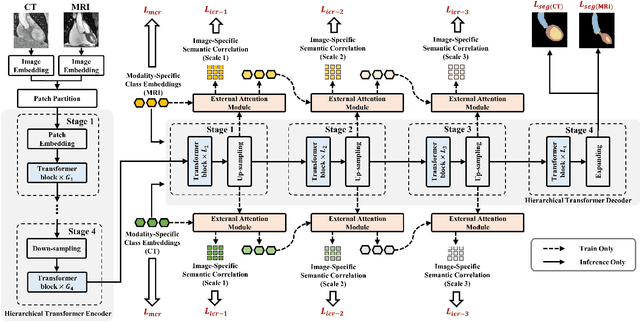
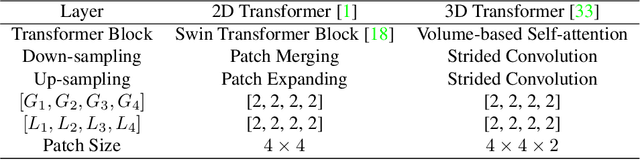
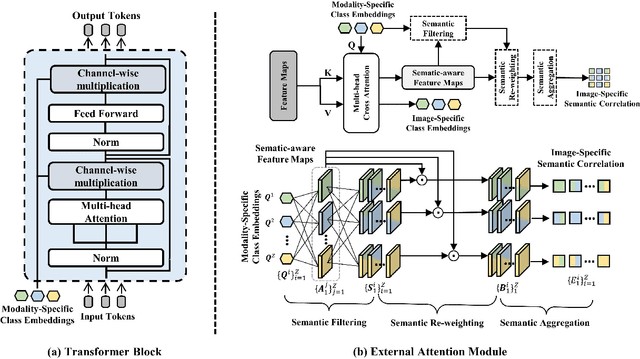
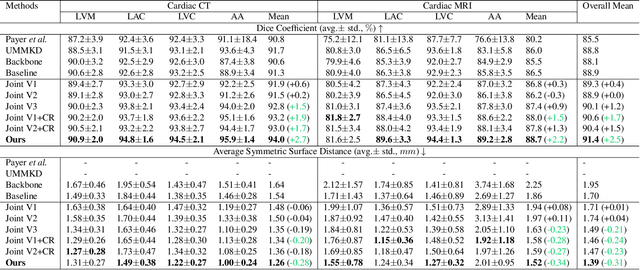
Integrating multi-modal data to improve medical image analysis has received great attention recently. However, due to the modal discrepancy, how to use a single model to process the data from multiple modalities is still an open issue. In this paper, we propose a novel scheme to achieve better pixel-level segmentation for unpaired multi-modal medical images. Different from previous methods which adopted both modality-specific and modality-shared modules to accommodate the appearance variance of different modalities while extracting the common semantic information, our method is based on a single Transformer with a carefully designed External Attention Module (EAM) to learn the structured semantic consistency (i.e. semantic class representations and their correlations) between modalities in the training phase. In practice, the above-mentioned structured semantic consistency across modalities can be progressively achieved by implementing the consistency regularization at the modality-level and image-level respectively. The proposed EAMs are adopted to learn the semantic consistency for different scale representations and can be discarded once the model is optimized. Therefore, during the testing phase, we only need to maintain one Transformer for all modal predictions, which nicely balances the model's ease of use and simplicity. To demonstrate the effectiveness of the proposed method, we conduct the experiments on two medical image segmentation scenarios: (1) cardiac structure segmentation, and (2) abdominal multi-organ segmentation. Extensive results show that the proposed method outperforms the state-of-the-art methods by a wide margin, and even achieves competitive performance with extremely limited training samples (e.g., 1 or 3 annotated CT or MRI images) for one specific modality.
Latent Topology Induction for Understanding Contextualized Representations
Jun 03, 2022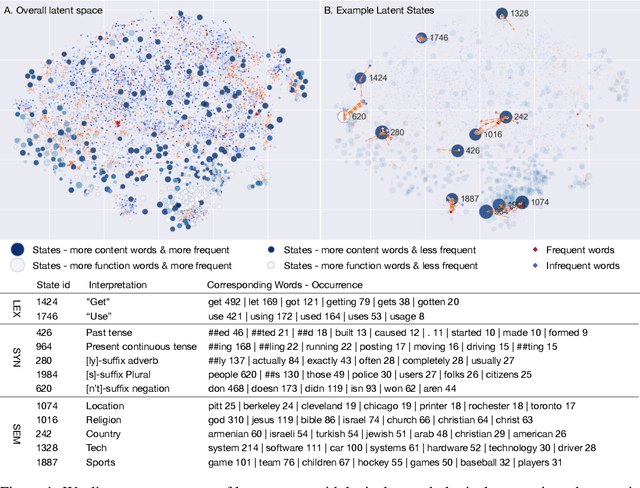
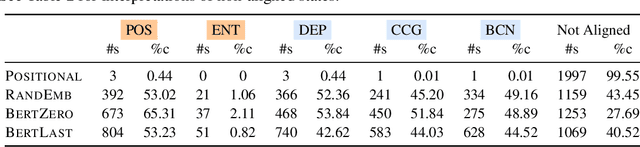
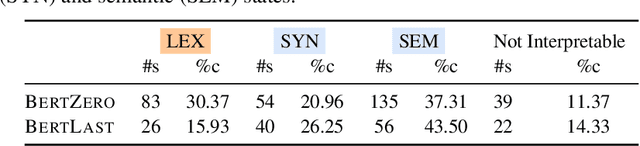
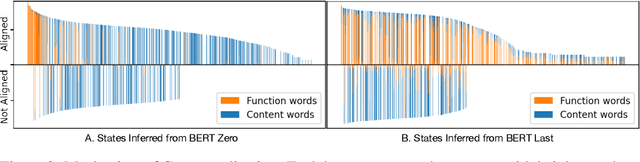
In this work, we study the representation space of contextualized embeddings and gain insight into the hidden topology of large language models. We show there exists a network of latent states that summarize linguistic properties of contextualized representations. Instead of seeking alignments to existing well-defined annotations, we infer this latent network in a fully unsupervised way using a structured variational autoencoder. The induced states not only serve as anchors that mark the topology (neighbors and connectivity) of the representation manifold but also reveal the internal mechanism of encoding sentences. With the induced network, we: (1). decompose the representation space into a spectrum of latent states which encode fine-grained word meanings with lexical, morphological, syntactic and semantic information; (2). show state-state transitions encode rich phrase constructions and serve as the backbones of the latent space. Putting the two together, we show that sentences are represented as a traversal over the latent network where state-state transition chains encode syntactic templates and state-word emissions fill in the content. We demonstrate these insights with extensive experiments and visualizations.
Feature-aware Diversified Re-ranking with Disentangled Representations for Relevant Recommendation
Jun 10, 2022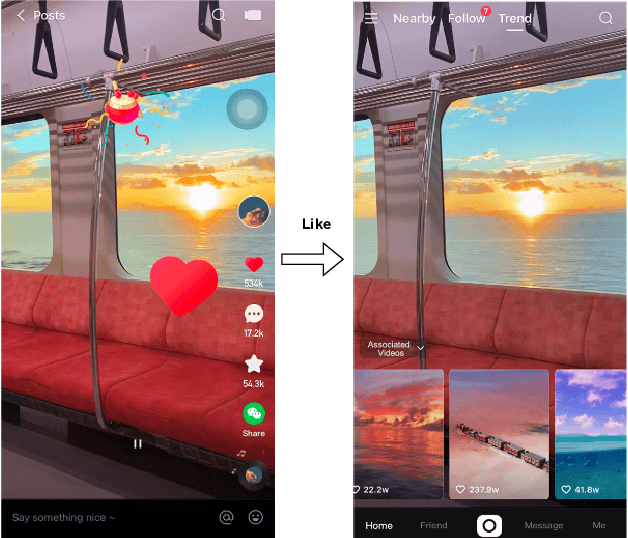

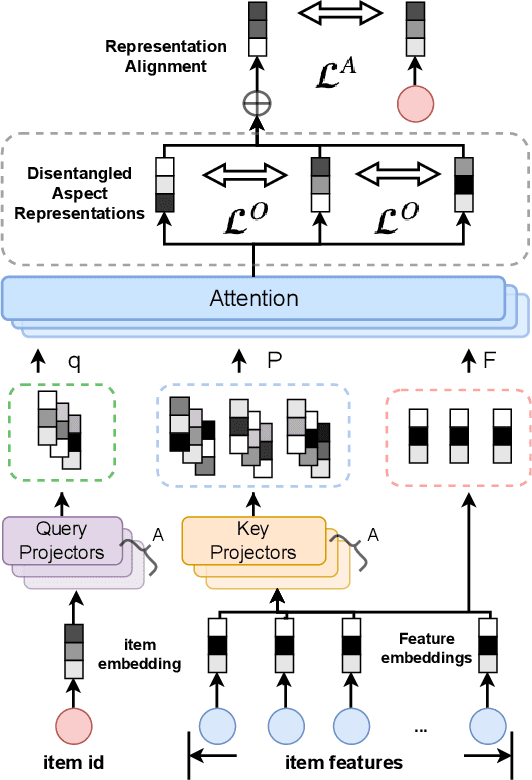
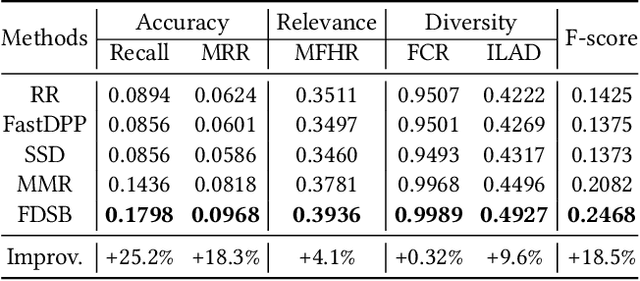
Relevant recommendation is a special recommendation scenario which provides relevant items when users express interests on one target item (e.g., click, like and purchase). Besides considering the relevance between recommendations and trigger item, the recommendations should also be diversified to avoid information cocoons. However, existing diversified recommendation methods mainly focus on item-level diversity which is insufficient when the recommended items are all relevant to the target item. Moreover, redundant or noisy item features might affect the performance of simple feature-aware recommendation approaches. Faced with these issues, we propose a Feature Disentanglement Self-Balancing Re-ranking framework (FDSB) to capture feature-aware diversity. The framework consists of two major modules, namely disentangled attention encoder (DAE) and self-balanced multi-aspect ranker. In DAE, we use multi-head attention to learn disentangled aspects from rich item features. In the ranker, we develop an aspect-specific ranking mechanism that is able to adaptively balance the relevance and diversity for each aspect. In experiments, we conduct offline evaluation on the collected dataset and deploy FDSB on KuaiShou app for online A/B test on the function of relevant recommendation. The significant improvements on both recommendation quality and user experience verify the effectiveness of our approach.
On-device modeling of user's social context and familiar places from smartphone-embedded sensor data
May 18, 2022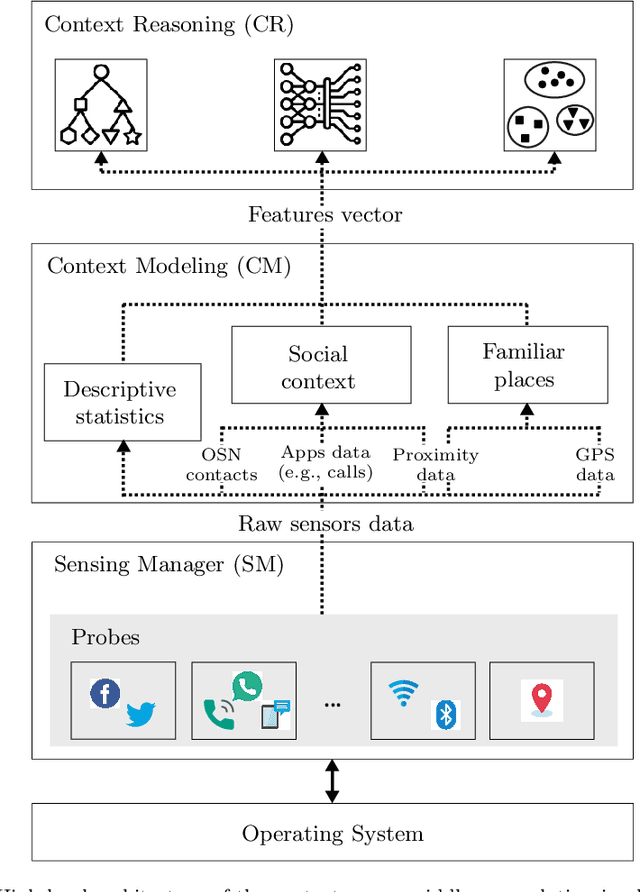

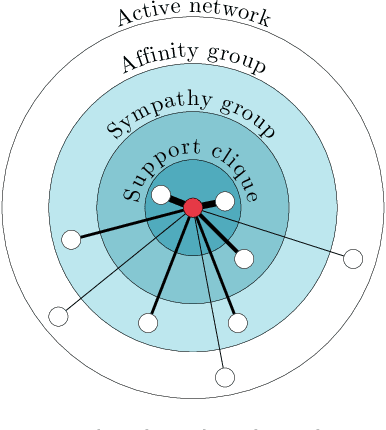
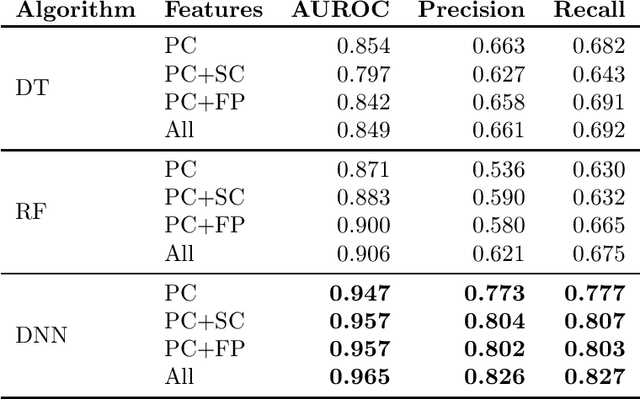
Context modeling and recognition represent complex tasks that allow mobile and ubiquitous computing applications to adapt to the user's situation. Current solutions mainly focus on limited context information generally processed on centralized architectures, potentially exposing users' personal data to privacy leakage, and missing personalization features. For these reasons on-device context modeling and recognition represent the current research trend in this area. Among the different information characterizing the user's context in mobile environments, social interactions and visited locations remarkably contribute to the characterization of daily life scenarios. In this paper we propose a novel, unsupervised and lightweight approach to model the user's social context and her locations based on ego networks directly on the user mobile device. Relying on this model, the system is able to extract high-level and semantic-rich context features from smartphone-embedded sensors data. Specifically, for the social context it exploits data related to both physical and cyber social interactions among users and their devices. As far as location context is concerned, we assume that it is more relevant to model the familiarity degree of a specific location for the user's context than the raw location data, both in terms of GPS coordinates and proximity devices. By using 5 real-world datasets, we assess the structure of the social and location ego networks, we provide a semantic evaluation of the proposed models and a complexity evaluation in terms of mobile computing performance. Finally, we demonstrate the relevance of the extracted features by showing the performance of 3 machine learning algorithms to recognize daily-life situations, obtaining an improvement of 3% of AUROC, 9% of Precision, and 5% in terms of Recall with respect to use only features related to physical context.