 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Toward Unpaired Multi-modal Medical Image Segmentation via Learning Structured Semantic Consistency
Jun 21, 2022
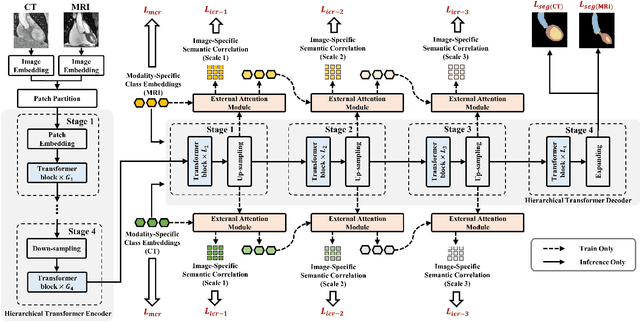
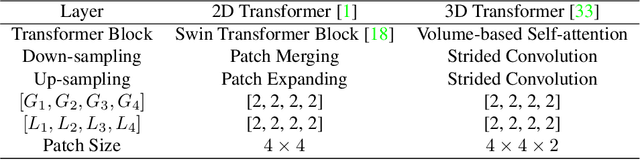
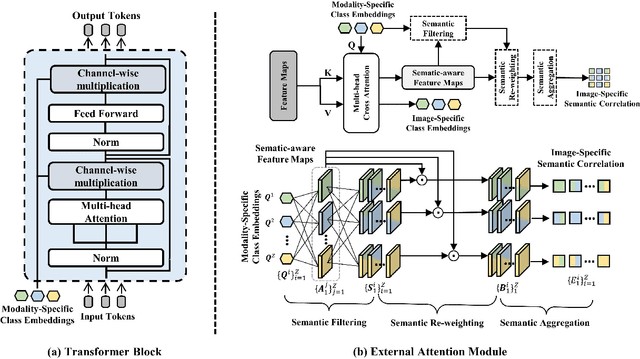
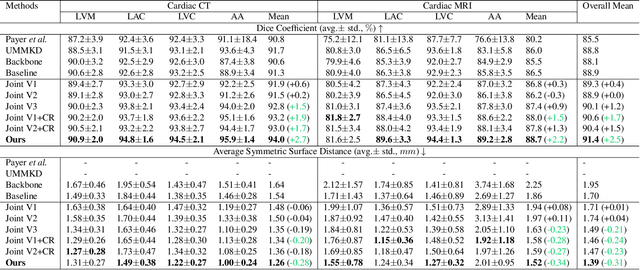
Integrating multi-modal data to improve medical image analysis has received great attention recently. However, due to the modal discrepancy, how to use a single model to process the data from multiple modalities is still an open issue. In this paper, we propose a novel scheme to achieve better pixel-level segmentation for unpaired multi-modal medical images. Different from previous methods which adopted both modality-specific and modality-shared modules to accommodate the appearance variance of different modalities while extracting the common semantic information, our method is based on a single Transformer with a carefully designed External Attention Module (EAM) to learn the structured semantic consistency (i.e. semantic class representations and their correlations) between modalities in the training phase. In practice, the above-mentioned structured semantic consistency across modalities can be progressively achieved by implementing the consistency regularization at the modality-level and image-level respectively. The proposed EAMs are adopted to learn the semantic consistency for different scale representations and can be discarded once the model is optimized. Therefore, during the testing phase, we only need to maintain one Transformer for all modal predictions, which nicely balances the model's ease of use and simplicity. To demonstrate the effectiveness of the proposed method, we conduct the experiments on two medical image segmentation scenarios: (1) cardiac structure segmentation, and (2) abdominal multi-organ segmentation. Extensive results show that the proposed method outperforms the state-of-the-art methods by a wide margin, and even achieves competitive performance with extremely limited training samples (e.g., 1 or 3 annotated CT or MRI images) for one specific modality.
End-to-End Information Extraction by Character-Level Embedding and Multi-Stage Attentional U-Net
Jun 02, 2021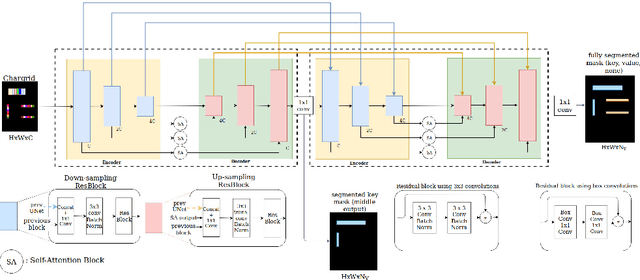

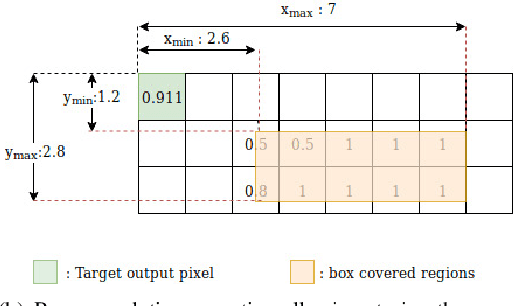
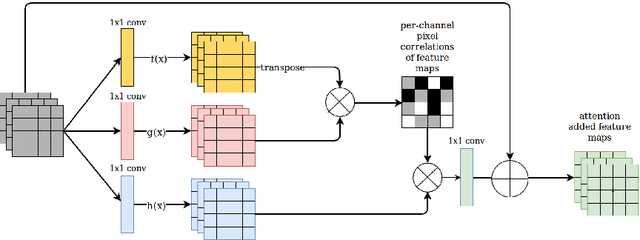
Information extraction from document images has received a lot of attention recently, due to the need for digitizing a large volume of unstructured documents such as invoices, receipts, bank transfers, etc. In this paper, we propose a novel deep learning architecture for end-to-end information extraction on the 2D character-grid embedding of the document, namely the \textit{Multi-Stage Attentional U-Net}. To effectively capture the textual and spatial relations between 2D elements, our model leverages a specialized multi-stage encoder-decoders design, in conjunction with efficient uses of the self-attention mechanism and the box convolution. Experimental results on different datasets show that our model outperforms the baseline U-Net architecture by a large margin while using 40\% fewer parameters. Moreover, it also significantly improved the baseline in erroneous OCR and limited training data scenario, thus becomes practical for real-world applications.
* Accepted to BMVC 2019
RefCrowd: Grounding the Target in Crowd with Referring Expressions
Jun 16, 2022
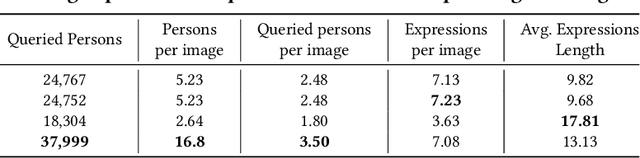

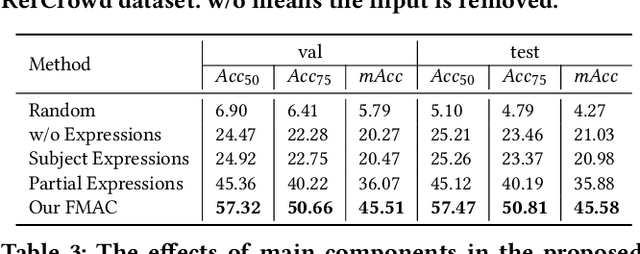
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.
Approach to Predicting News -- A Precise Multi-LSTM Network With BERT
Apr 26, 2022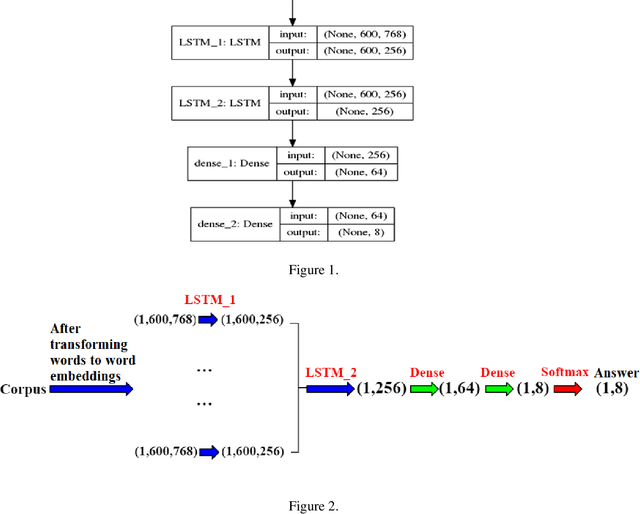
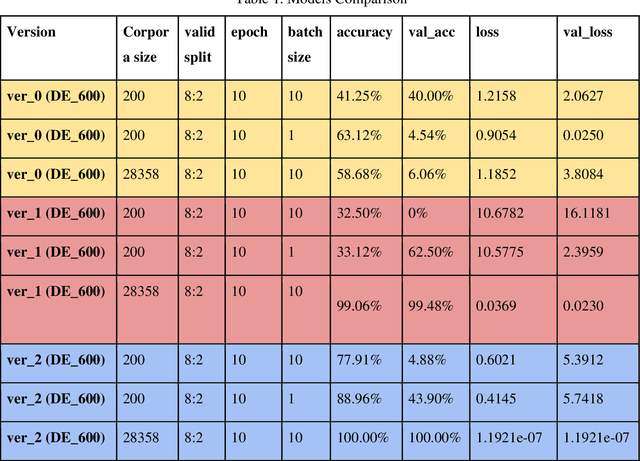
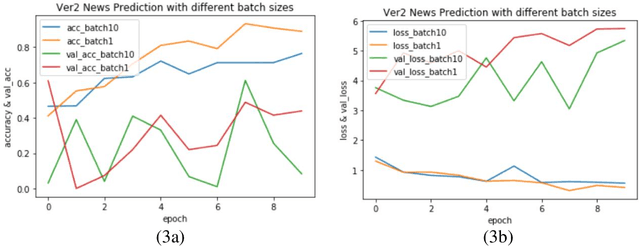
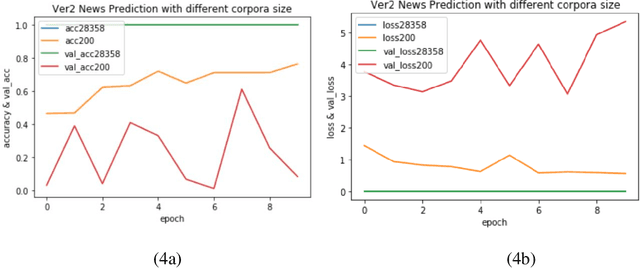
Varieties of Democracy (V-Dem) is a new approach to conceptualizing and measuring democracy and politics. It has information for 200 countries and is one of the biggest databases for political science. According to the V-Dem annual democracy report 2019, Taiwan is one of the two countries that got disseminated false information from foreign governments the most. It also shows that the "made-up news" has caused a great deal of confusion in Taiwanese society and has serious impacts on global stability. Although there are several applications helping distinguish the false information, we found out that the pre-processing of categorizing the news is still done by human labor. However, human labor may cause mistakes and cannot work for a long time. The growing demands for automatic machines in the near decades show that while the machine can do as good as humans or even better, using machines can reduce humans' burden and cut down costs. Therefore, in this work, we build a predictive model to classify the category of news. The corpora we used contains 28358 news and 200 news scraped from the online newspaper Liberty Times Net (LTN) website and includes 8 categories: Technology, Entertainment, Fashion, Politics, Sports, International, Finance, and Health. At first, we use Bidirectional Encoder Representations from Transformers (BERT) for word embeddings which transform each Chinese character into a (1,768) vector. Then, we use a Long Short-Term Memory (LSTM) layer to transform word embeddings into sentence embeddings and add another LSTM layer to transform them into document embeddings. Each document embedding is an input for the final predicting model, which contains two Dense layers and one Activation layer. And each document embedding is transformed into 1 vector with 8 real numbers, then the highest one will correspond to the 8 news categories with up to 99% accuracy.
* Accepted by The 25th International Conference on Information Management & Practice (IMP) 2019
Constructing Trajectory and Predicting Estimated Time of Arrival for Long Distance Travelling Vessels: A Probability Density-based Scanning Approach
May 13, 2022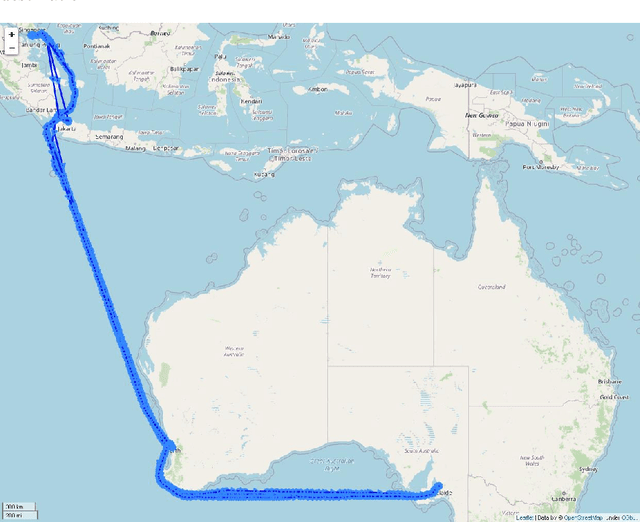
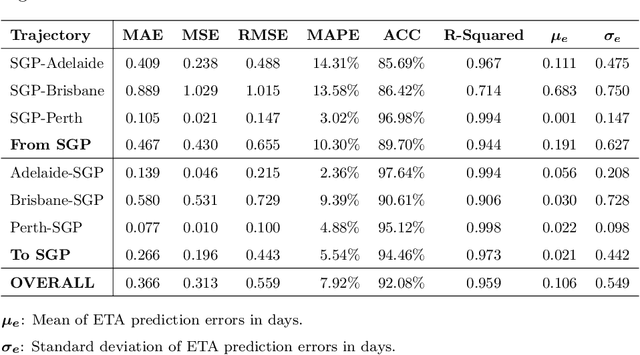
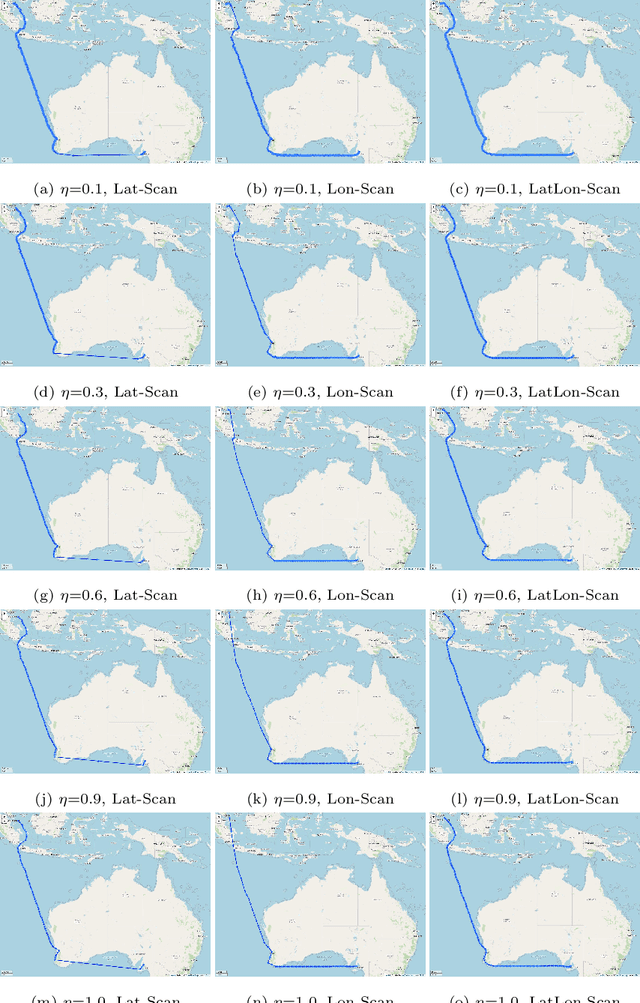
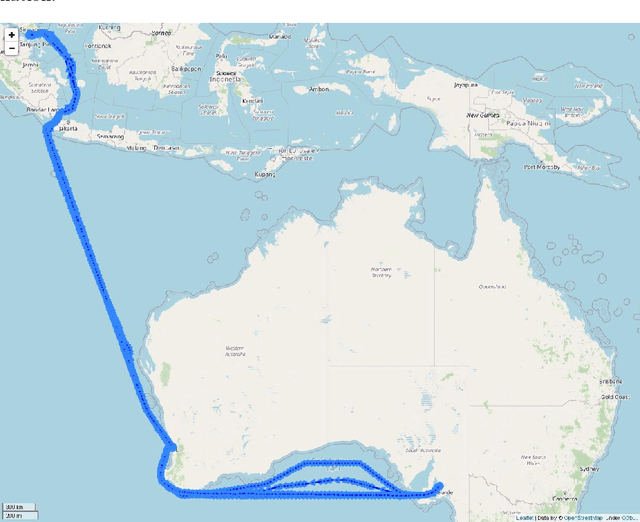
In this study, a probability density-based approach for constructing trajectories is proposed and validated through an typical use-case application: Estimated Time of Arrival (ETA) prediction given origin-destination pairs. The ETA prediction is based on physics and mathematical laws given by the extracted information of probability density-based trajectories constructed. The overall ETA prediction errors are about 0.106 days (i.e. 2.544 hours) on average with 0.549 days (i.e. 13.176 hours) standard deviation, and the proposed approach has an accuracy of 92.08% with 0.959 R-Squared value for overall trajectories between Singapore and Australia ports selected.
Automatic Quantification of Volumes and Biventricular Function in Cardiac Resonance. Validation of a New Artificial Intelligence Approach
Jun 03, 2022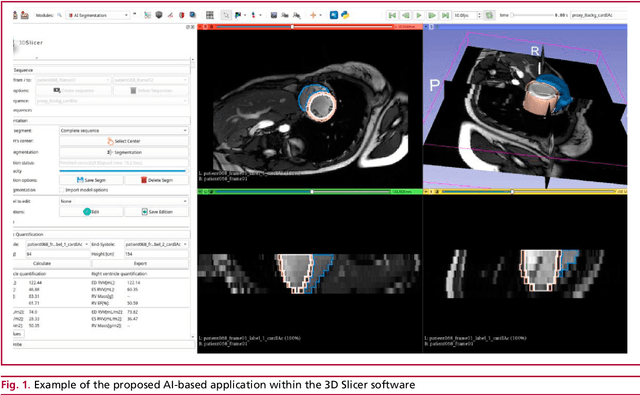
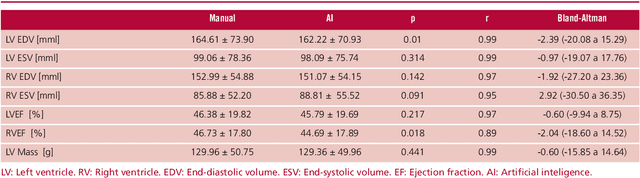
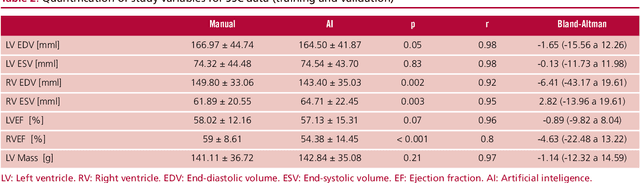
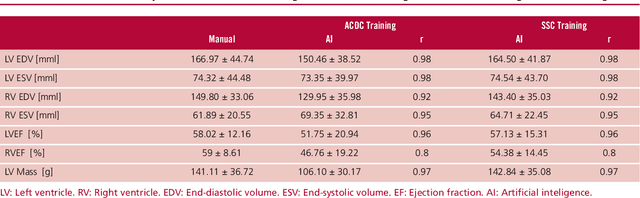
Background: Artificial intelligence techniques have shown great potential in cardiology, especially in quantifying cardiac biventricular function, volume, mass, and ejection fraction (EF). However, its use in clinical practice is not straightforward due to its poor reproducibility with cases from daily practice, among other reasons. Objectives: To validate a new artificial intelligence tool in order to quantify the cardiac biventricular function (volume, mass, and EF). To analyze its robustness in the clinical area, and the computational times compared with conventional methods. Methods: A total of 189 patients were analyzed: 89 from a regional center and 100 from a public center. The method proposes two convolutional networks that include anatomical information of the heart to reduce classification errors. Results: A high concordance (Pearson coefficient) was observed between manual quantification and the proposed quantification of cardiac function (0.98, 0.92, 0.96 and 0.8 for volumes and biventricular EF) in about 5 seconds per study. Conclusions: This method quantifies biventricular function and volumes in seconds with an accuracy equivalent to that of a specialist.
The Role of Mutual Information in Variational Classifiers
Oct 22, 2020
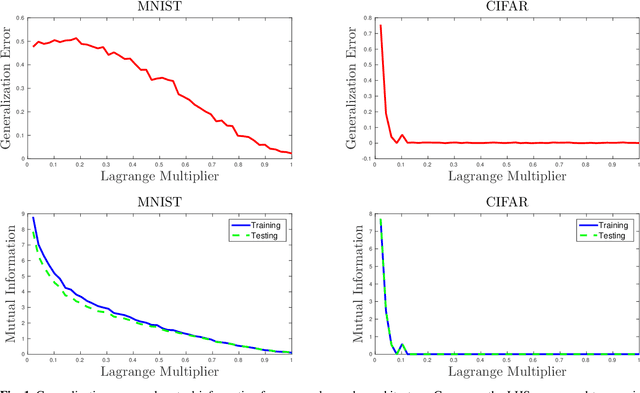
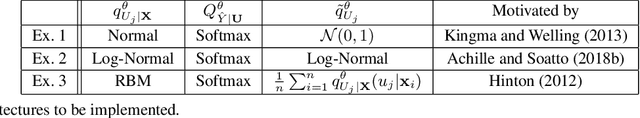
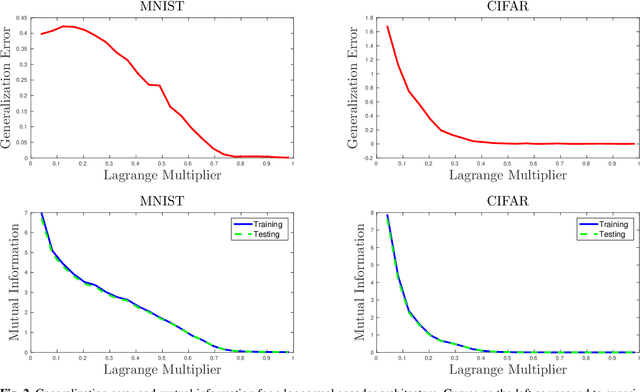
Overfitting data is a well-known phenomenon related with the generation of a model that mimics too closely (or exactly) a particular instance of data, and may therefore fail to predict future observations reliably. In practice, this behaviour is controlled by various--sometimes heuristics--regularization techniques, which are motivated by developing upper bounds to the generalization error. In this work, we study the generalization error of classifiers relying on stochastic encodings trained on the cross-entropy loss, which is often used in deep learning for classification problems. We derive bounds to the generalization error showing that there exists a regime where the generalization error is bounded by the mutual information between input features and the corresponding representations in the latent space, which are randomly generated according to the encoding distribution. Our bounds provide an information-theoretic understanding of generalization in the so-called class of variational classifiers, which are regularized by a Kullback-Leibler (KL) divergence term. These results give theoretical grounds for the highly popular KL term in variational inference methods that was already recognized to act effectively as a regularization penalty. We further observe connections with well studied notions such as Variational Autoencoders, Information Dropout, Information Bottleneck and Boltzmann Machines. Finally, we perform numerical experiments on MNIST and CIFAR datasets and show that mutual information is indeed highly representative of the behaviour of the generalization error.
From Labels to Priors in Capsule Endoscopy: A Prior Guided Approach for Improving Generalization with Few Labels
Jun 10, 2022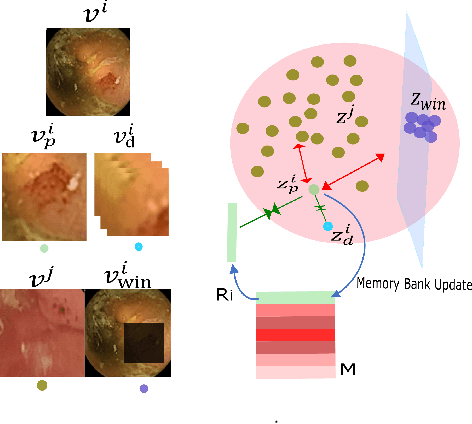

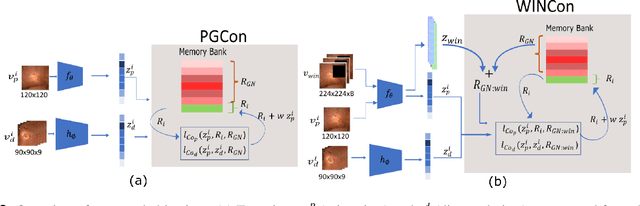

The lack of generalizability of deep learning approaches for the automated diagnosis of pathologies in Wireless Capsule Endoscopy (WCE) has prevented any significant advantages from trickling down to real clinical practices. As a result, disease management using WCE continues to depend on exhaustive manual investigations by medical experts. This explains its limited use despite several advantages. Prior works have considered using higher quality and quantity of labels as a way of tackling the lack of generalization, however this is hardly scalable considering pathology diversity not to mention that labeling large datasets encumbers the medical staff additionally. We propose using freely available domain knowledge as priors to learn more robust and generalizable representations. We experimentally show that domain priors can benefit representations by acting in proxy of labels, thereby significantly reducing the labeling requirement while still enabling fully unsupervised yet pathology-aware learning. We use the contrastive objective along with prior-guided views during pretraining, where the view choices inspire sensitivity to pathological information. Extensive experiments on three datasets show that our method performs better than (or closes gap with) the state-of-the-art in the domain, establishing a new benchmark in pathology classification and cross-dataset generalization, as well as scaling to unseen pathology categories.
Feature-aware Diversified Re-ranking with Disentangled Representations for Relevant Recommendation
Jun 10, 2022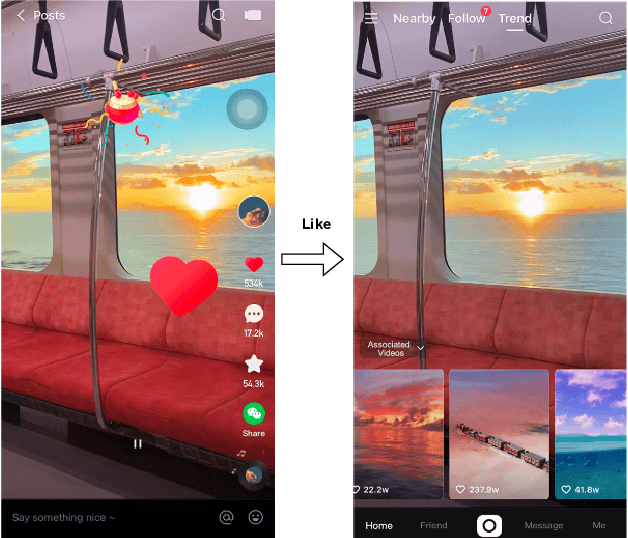

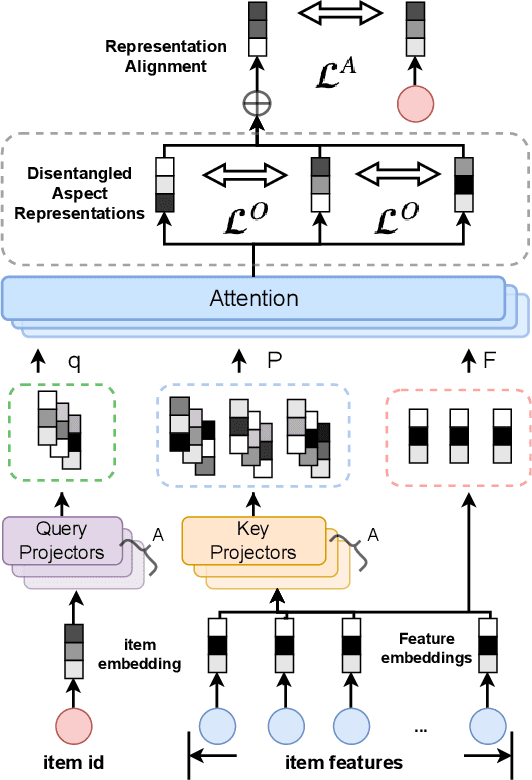
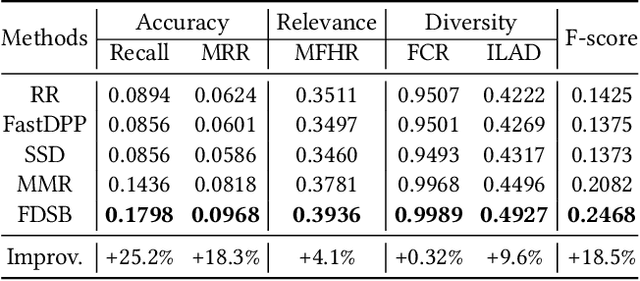
Relevant recommendation is a special recommendation scenario which provides relevant items when users express interests on one target item (e.g., click, like and purchase). Besides considering the relevance between recommendations and trigger item, the recommendations should also be diversified to avoid information cocoons. However, existing diversified recommendation methods mainly focus on item-level diversity which is insufficient when the recommended items are all relevant to the target item. Moreover, redundant or noisy item features might affect the performance of simple feature-aware recommendation approaches. Faced with these issues, we propose a Feature Disentanglement Self-Balancing Re-ranking framework (FDSB) to capture feature-aware diversity. The framework consists of two major modules, namely disentangled attention encoder (DAE) and self-balanced multi-aspect ranker. In DAE, we use multi-head attention to learn disentangled aspects from rich item features. In the ranker, we develop an aspect-specific ranking mechanism that is able to adaptively balance the relevance and diversity for each aspect. In experiments, we conduct offline evaluation on the collected dataset and deploy FDSB on KuaiShou app for online A/B test on the function of relevant recommendation. The significant improvements on both recommendation quality and user experience verify the effectiveness of our approach.
XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding
Mar 14, 2022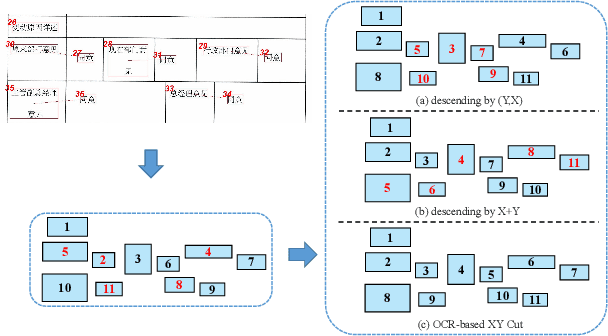
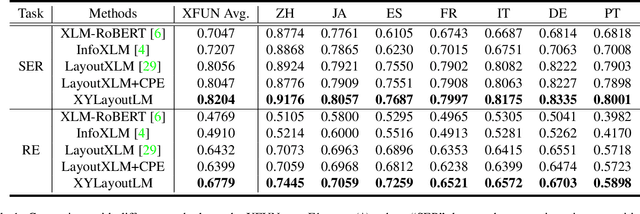
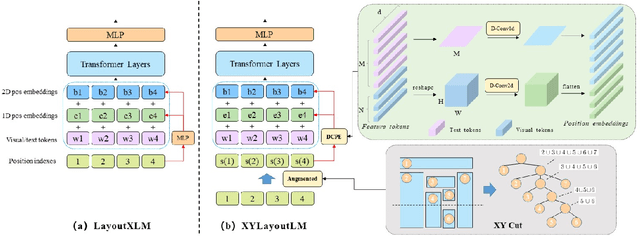
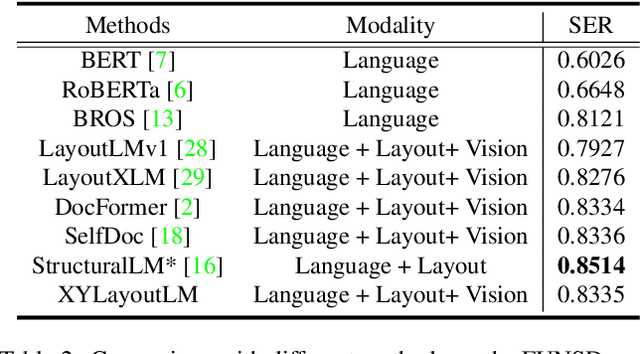
Recently, various multimodal networks for Visually-Rich Document Understanding(VRDU) have been proposed, showing the promotion of transformers by integrating visual and layout information with the text embeddings. However, most existing approaches utilize the position embeddings to incorporate the sequence information, neglecting the noisy improper reading order obtained by OCR tools. In this paper, we propose a robust layout-aware multimodal network named XYLayoutLM to capture and leverage rich layout information from proper reading orders produced by our Augmented XY Cut. Moreover, a Dilated Conditional Position Encoding module is proposed to deal with the input sequence of variable lengths, and it additionally extracts local layout information from both textual and visual modalities while generating position embeddings. Experiment results show that our XYLayoutLM achieves competitive results on document understanding tasks.