 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learn from Structural Scope: Improving Aspect-Level Sentiment Analysis with Hybrid Graph Convolutional Networks
Apr 27, 2022
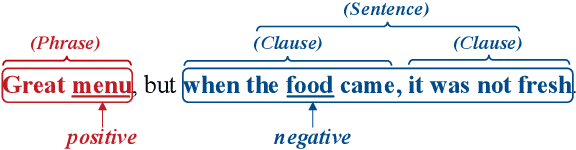
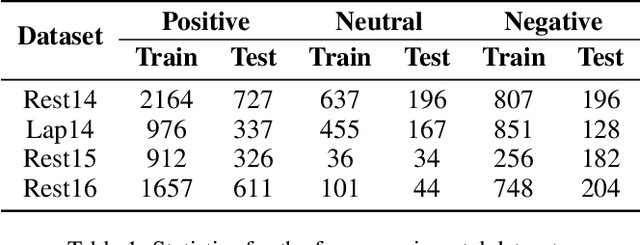
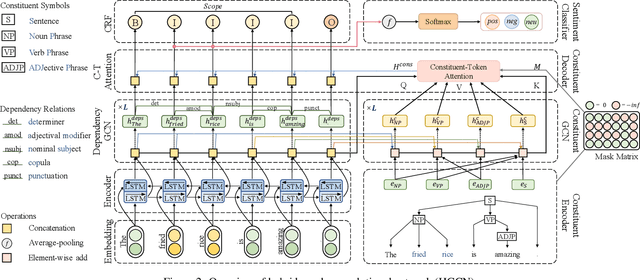
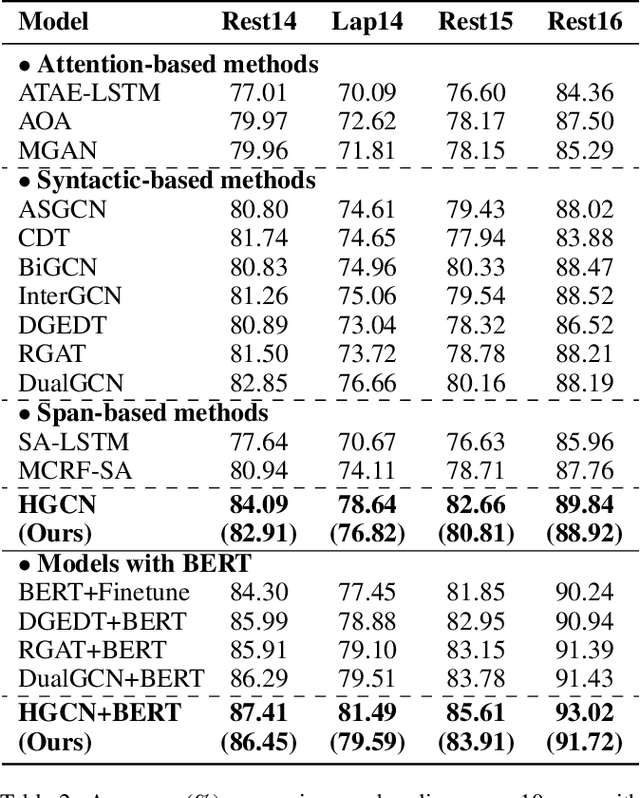
Aspect-level sentiment analysis aims to determine the sentiment polarity towards a specific target in a sentence. The main challenge of this task is to effectively model the relation between targets and sentiments so as to filter out noisy opinion words from irrelevant targets. Most recent efforts capture relations through target-sentiment pairs or opinion spans from a word-level or phrase-level perspective. Based on the observation that targets and sentiments essentially establish relations following the grammatical hierarchy of phrase-clause-sentence structure, it is hopeful to exploit comprehensive syntactic information for better guiding the learning process. Therefore, we introduce the concept of Scope, which outlines a structural text region related to a specific target. To jointly learn structural Scope and predict the sentiment polarity, we propose a hybrid graph convolutional network (HGCN) to synthesize information from constituency tree and dependency tree, exploring the potential of linking two syntax parsing methods to enrich the representation. Experimental results on four public datasets illustrate that our HGCN model outperforms current state-of-the-art baselines.
Collaborative Sensing in Perceptive Mobile Networks: Opportunities and Challenges
May 31, 2022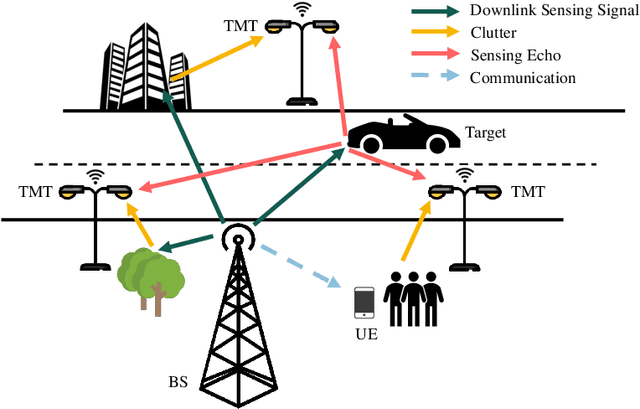
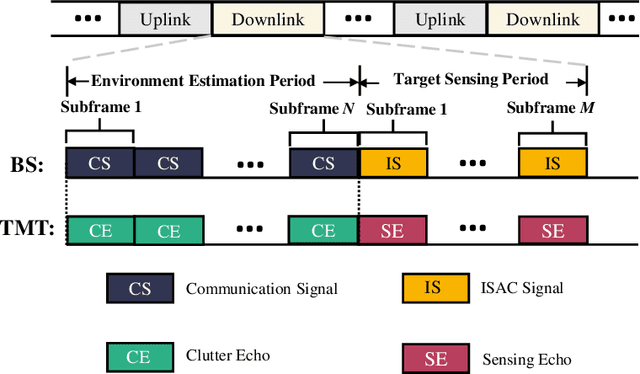
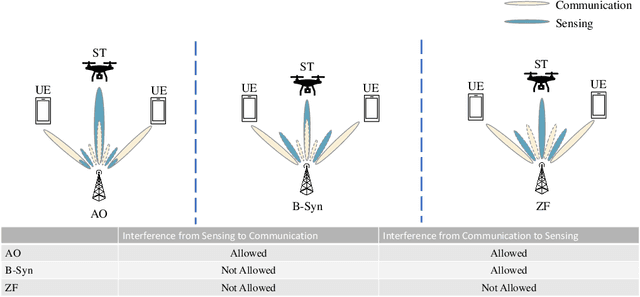
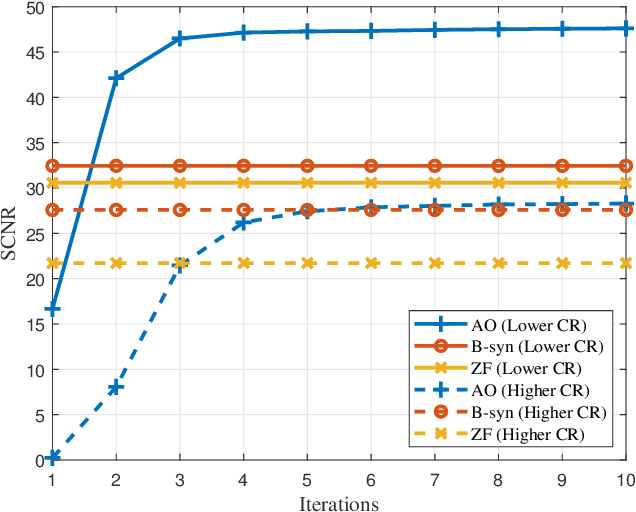
With the development of innovative applications that demand accurate environment information, e.g., autonomous driving, sensing becomes an important requirement for future wireless networks. To this end, integrated sensing and communication (ISAC) provides a promising platform to exploit the synergy between sensing and communication, where perceptive mobile networks (PMNs) were proposed to add accurate sensing capability to existing wireless networks. The well-developed cellular networks offer exciting opportunities for sensing, including large coverage, strong computation and communication power, and most importantly networked sensing, where the perspectives from multiple sensing nodes can be collaboratively utilized for sensing the same target. However, PMNs also face big challenges such as the inherent interference between sensing and communication, the complex sensing environment, and the tracking of high-speed targets by cellular networks. This paper provides a comprehensive review on the design of PMNs, covering the popular network architectures, sensing protocols, standing research problems, and available solutions. Several future research directions that are critical for the development of PMNs are also discussed.
Bounded rationality for relaxing best response and mutual consistency: An information-theoretic model of partial self-reference
Jun 30, 2021
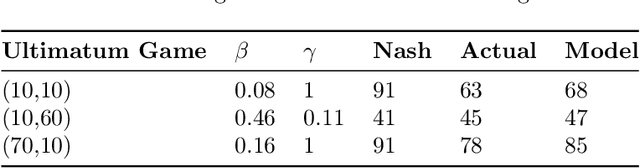
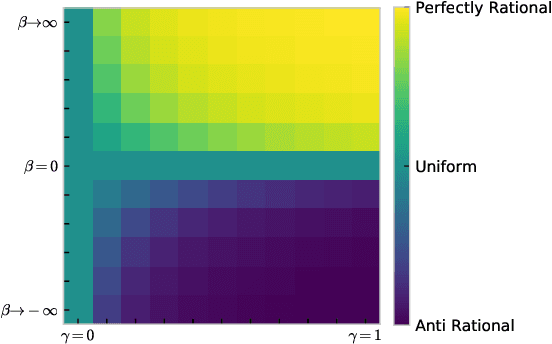
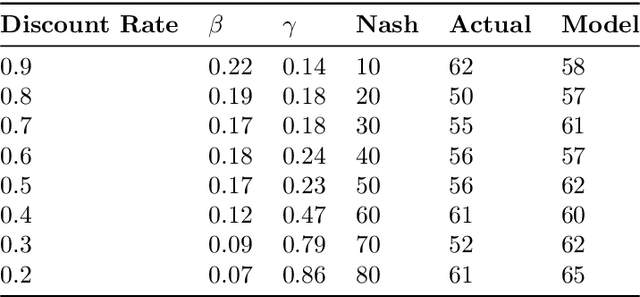
While game theory has been transformative for decision-making, the assumptions made can be overly restrictive in certain instances. In this work, we focus on some of the assumptions underlying rationality such as mutual consistency and best-response, and consider ways to relax these assumptions using concepts from level-$k$ reasoning and quantal response equilibrium (QRE) respectively. Specifically, we provide an information-theoretic two-parameter model that can relax both mutual consistency and best-response, but can recover approximations of level-$k$, QRE, or typical Nash equilibrium behaviour in the limiting cases. The proposed approach is based on a recursive form of the variational free energy principle, representing self-referential games as (pseudo) sequential decisions. Bounds in player processing abilities are captured as information costs, where future chains of reasoning are discounted, implying a hierarchy of players where lower-level players have fewer processing resources.
Neurodynamical Role of STDP in Storage and Retrieval of Associative Information
Apr 25, 2021


Spike-timing-dependent plasticity (STDP) is a biological process in which the precise order and timing of neuronal spikes affect the degree of synaptic modification. While there has been numerous research focusing on the role of STDP in neural coding, the functional implications of STDP at the macroscopic level in the brain have not been fully explored yet. In this work, we propose that STDP in an ensemble of spiking neurons renders storing high dimensional information in the form of a `memory plane'. Neural activity based on STDP transforms periodic spatio-temporal input patterns into the corresponding memory plane, where the stored information can be dynamically revived with a proper cue. Using the dynamical systems theory that shows the analytic relation between the input and the memory plane, we were able to demonstrate a specific memory process for high-dimensional associative data sets. In the auto-associative memory task, a group of images that were continuously streamed to the system can be retrieved from the oscillating neural state. The second application deals with the process of semantic memory components that are embedded from sentences. The results show that words can recall multiple sentences simultaneously or one exclusively, depending on their grammatical relations. This implies that the proposed framework is apt to process multiple groups of associative memories with a composite structure.
Instance-wise Prompt Tuning for Pretrained Language Models
Jun 04, 2022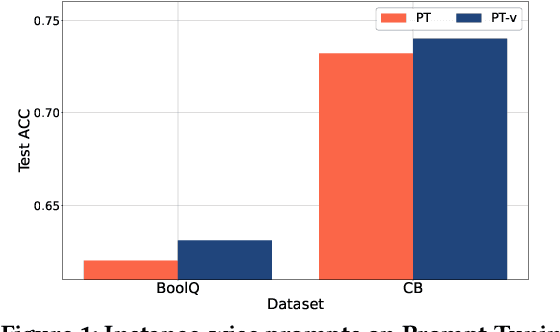

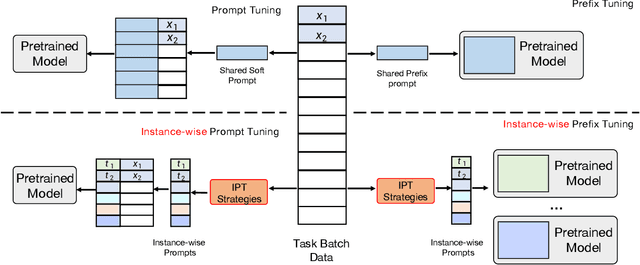
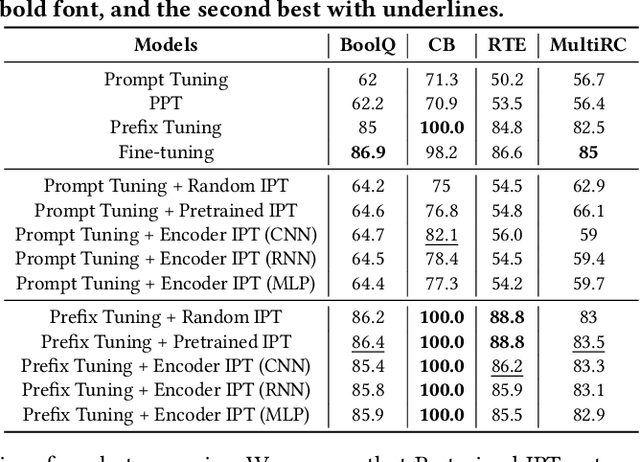
Prompt Learning has recently gained great popularity in bridging the gap between pretraining tasks and various downstream tasks. It freezes Pretrained Language Models (PLMs) and only tunes a few task-related parameters (prompts) for downstream tasks, greatly reducing the cost of tuning giant models. The key enabler of this is the idea of querying PLMs with task-specific knowledge implicated in prompts. This paper reveals a major limitation of existing methods that the indiscriminate prompts for all input data in a task ignore the intrinsic knowledge from input data, resulting in sub-optimal performance. We introduce Instance-wise Prompt Tuning (IPT), the first prompt learning paradigm that injects knowledge from the input data instances to the prompts, thereby providing PLMs with richer and more concrete context information. We devise a series of strategies to produce instance-wise prompts, addressing various concerns like model quality and cost-efficiency. Across multiple tasks and resource settings, IPT significantly outperforms task-based prompt learning methods, and achieves comparable performance to conventional finetuning with only 0.5% - 1.5% of tuned parameters.
Subject Granular Differential Privacy in Federated Learning
Jun 07, 2022This paper introduces subject granular privacy in the Federated Learning (FL) setting, where a subject is an individual whose private information is embodied by several data items either confined within a single federation user or distributed across multiple federation users. We formally define the notion of subject level differential privacy for FL. We propose three new algorithms that enforce subject level DP. Two of these algorithms are based on notions of user level local differential privacy (LDP) and group differential privacy respectively. The third algorithm is based on a novel idea of hierarchical gradient averaging (HiGradAvgDP) for subjects participating in a training mini-batch. We also introduce horizontal composition of privacy loss for a subject across multiple federation users. We show that horizontal composition is equivalent to sequential composition in the worst case. We prove the subject level DP guarantee for all our algorithms and empirically analyze them using the FEMNIST and Shakespeare datasets. Our evaluation shows that, of our three algorithms, HiGradAvgDP delivers the best model performance, approaching that of a model trained using a DP-SGD based algorithm that provides a weaker item level privacy guarantee.
Distant finetuning with discourse relations for stance classification
Apr 27, 2022
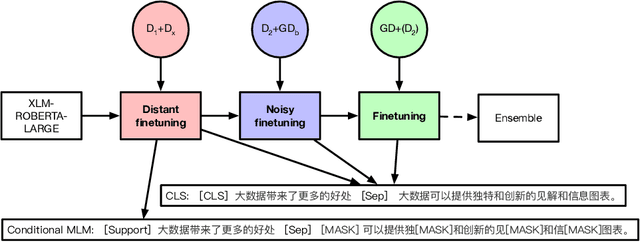

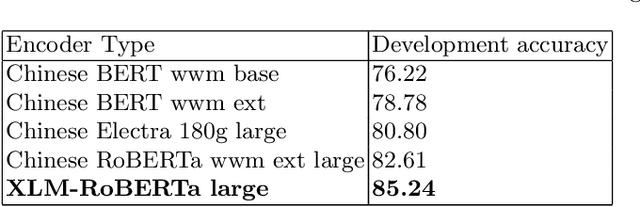
Approaches for the stance classification task, an important task for understanding argumentation in debates and detecting fake news, have been relying on models which deal with individual debate topics. In this paper, in order to train a system independent from topics, we propose a new method to extract data with silver labels from raw text to finetune a model for stance classification. The extraction relies on specific discourse relation information, which is shown as a reliable and accurate source for providing stance information. We also propose a 3-stage training framework where the noisy level in the data used for finetuning decreases over different stages going from the most noisy to the least noisy. Detailed experiments show that the automatically annotated dataset as well as the 3-stage training help improve model performance in stance classification. Our approach ranks 1st among 26 competing teams in the stance classification track of the NLPCC 2021 shared task Argumentative Text Understanding for AI Debater, which confirms the effectiveness of our approach.
Enhancing Slot Tagging with Intent Features for Task Oriented Natural Language Understanding using BERT
May 19, 2022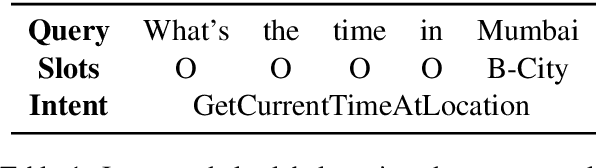
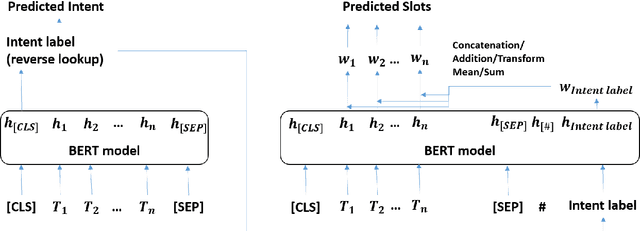

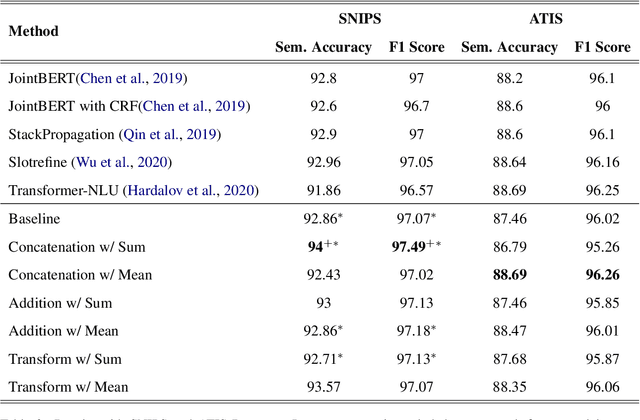
Recent joint intent detection and slot tagging models have seen improved performance when compared to individual models. In many real-world datasets, the slot labels and values have a strong correlation with their intent labels. In such cases, the intent label information may act as a useful feature to the slot tagging model. In this paper, we examine the effect of leveraging intent label features through 3 techniques in the slot tagging task of joint intent and slot detection models. We evaluate our techniques on benchmark spoken language datasets SNIPS and ATIS, as well as over a large private Bixby dataset and observe an improved slot-tagging performance over state-of-the-art models.
VAC2: Visual Analysis of Combined Causality in Event Sequences
Jun 11, 2022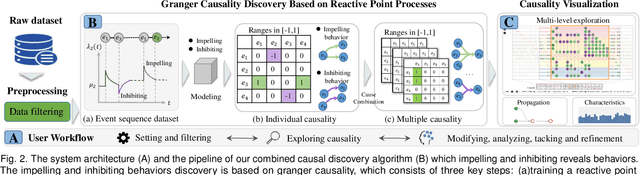
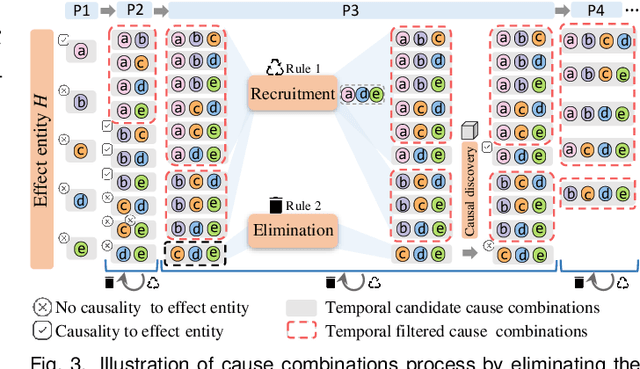

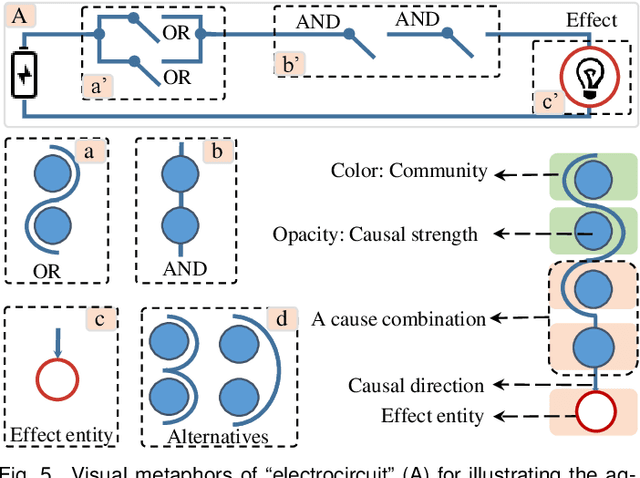
Identifying causality behind complex systems plays a significant role in different domains, such as decision making, policy implementations, and management recommendations. However, existing causality studies on temporal event sequences data mainly focus on individual causal discovery, which is incapable of exploiting combined causality. To fill the absence of combined causes discovery on temporal event sequence data,eliminating and recruiting principles are defined to balance the effectiveness and controllability on cause combinations. We also leverage the Granger causality algorithm based on the reactive point processes to describe impelling or inhibiting behavior patterns among entities. In addition, we design an informative and aesthetic visual metaphor of "electrocircuit" to encode aggregated causality for ensuring our causality visualization is non-overlapping and non-intersecting. Diverse sorting strategies and aggregation layout are also embedded into our parallel-based, directed and weighted hypergraph for illustrating combined causality. Our developed combined causality visual analysis system can help users effectively explore combined causes as well as an individual cause. This interactive system supports multi-level causality exploration with diverse ordering strategies and a focus and context technique to help users obtain different levels of information abstraction. The usefulness and effectiveness of the system are further evaluated by conducting a pilot user study and two case studies on event sequence data.
Phylogeny-Inspired Adaptation of Multilingual Models to New Languages
May 19, 2022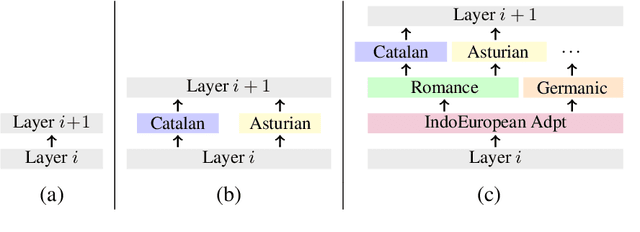
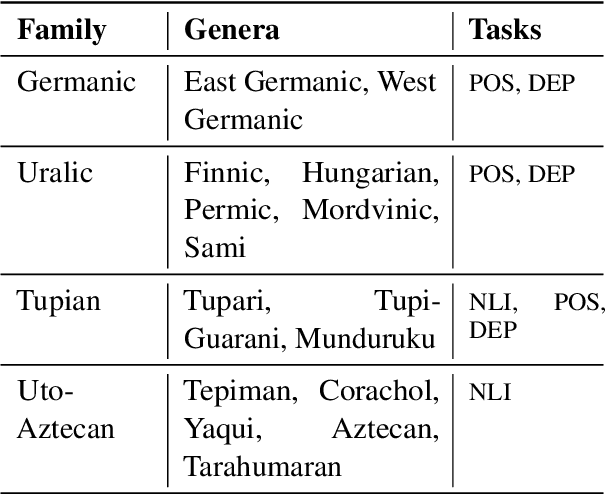
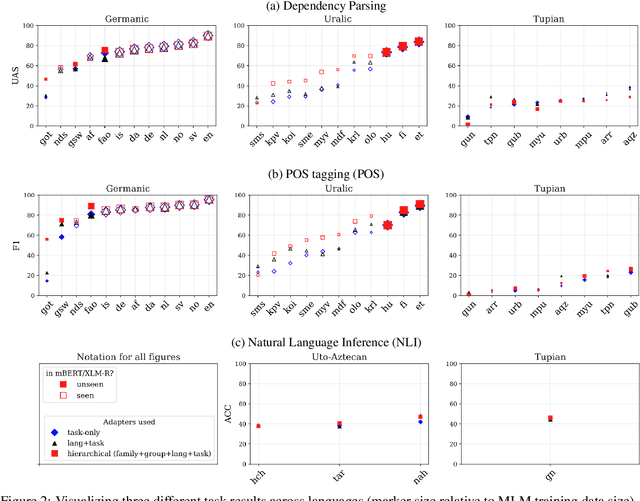
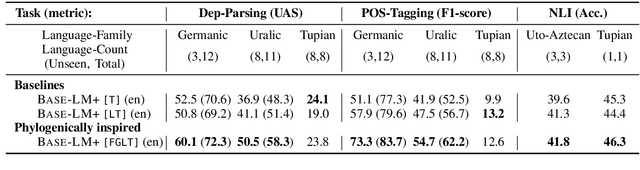
Large pretrained multilingual models, trained on dozens of languages, have delivered promising results due to cross-lingual learning capabilities on variety of language tasks. Further adapting these models to specific languages, especially ones unseen during pre-training, is an important goal towards expanding the coverage of language technologies. In this study, we show how we can use language phylogenetic information to improve cross-lingual transfer leveraging closely related languages in a structured, linguistically-informed manner. We perform adapter-based training on languages from diverse language families (Germanic, Uralic, Tupian, Uto-Aztecan) and evaluate on both syntactic and semantic tasks, obtaining more than 20% relative performance improvements over strong commonly used baselines, especially on languages unseen during pre-training.