 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improved Gaussian-Bernoulli Restricted Boltzmann Machines for UAV-Ground Communication Systems
Jun 16, 2022
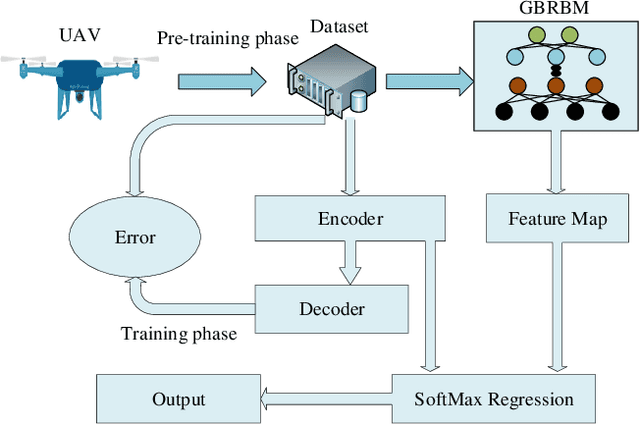
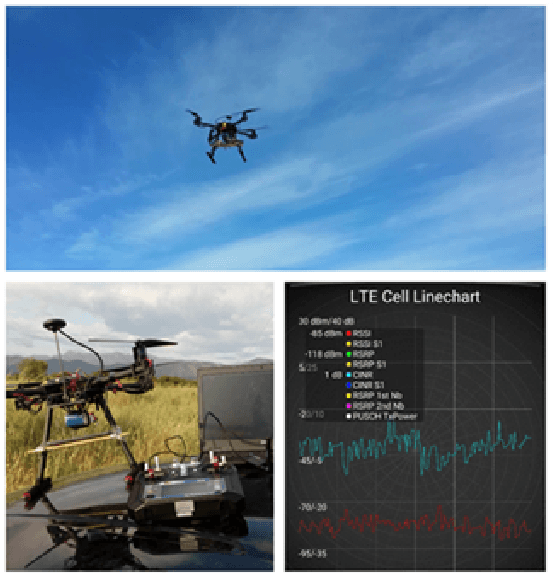
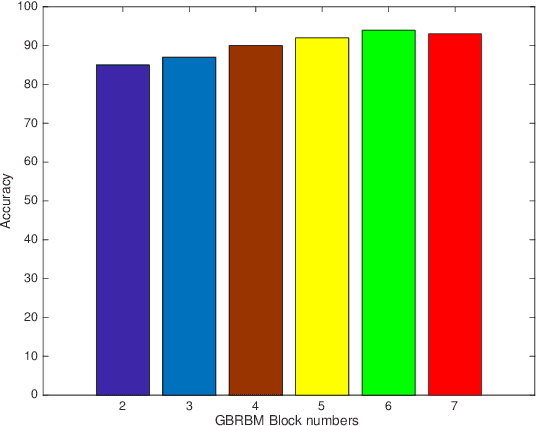
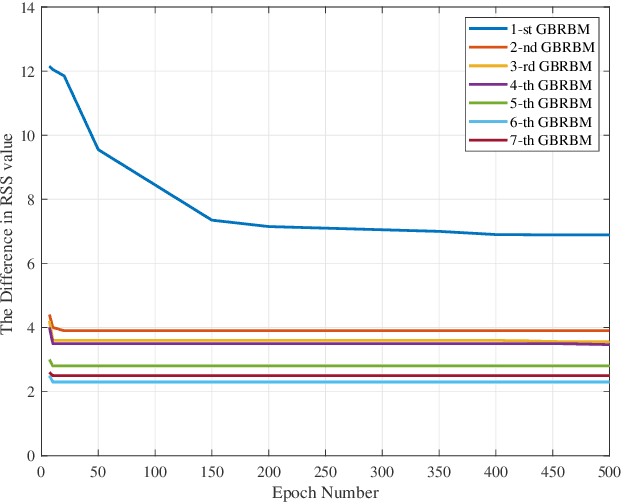
Unmanned aerial vehicle (UAV) is steadily growing as a promising technology for next-generation communication systems due to their appealing features such as wide coverage with high altitude, on-demand low-cost deployment, and fast responses. UAV communications are fundamentally different from the conventional terrestrial and satellite communications owing to the high mobility and the unique channel characteristics of air-ground links. However, obtaining effective channel state information (CSI) is challenging because of the dynamic propagation environment and variable transmission delay. In this paper, a deep learning (DL)-based CSI prediction framework is proposed to address channel aging problem by extracting the most discriminative features from the UAV wireless signals. Specifically, we develop a procedure of multiple Gaussian Bernoulli restricted Boltzmann machines (GBRBM) for dimension reduction and pre-training utilization incorporated with an autoencoder-based deep neural networks (DNNs). To evaluate the proposed approach, real data measurements from an UAV communicating with base-stations within a commercial cellular network are obtained and used for training and validation. Numerical results demonstrate that the proposed method is accurate in channel acquisition for various UAV flying scenarios and outperforms the conventional DNNs.
Less is More: Learning to Refine Dialogue History for Personalized Dialogue Generation
Apr 18, 2022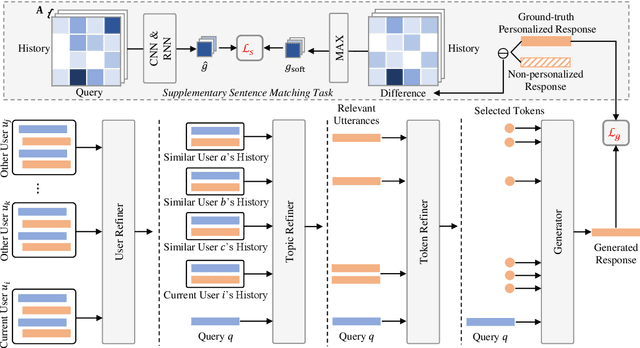
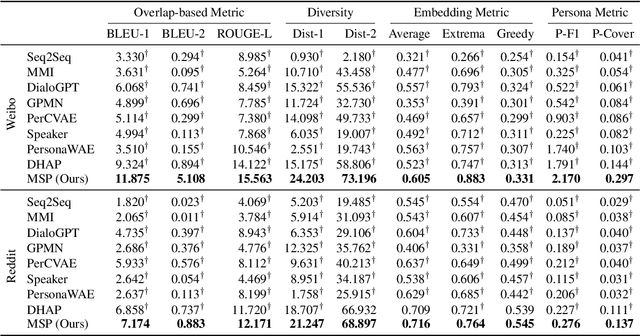
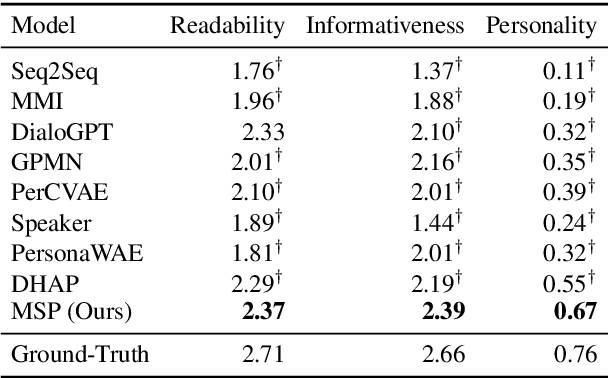
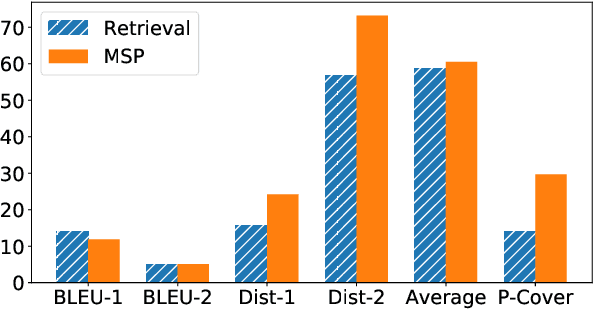
Personalized dialogue systems explore the problem of generating responses that are consistent with the user's personality, which has raised much attention in recent years. Existing personalized dialogue systems have tried to extract user profiles from dialogue history to guide personalized response generation. Since the dialogue history is usually long and noisy, most existing methods truncate the dialogue history to model the user's personality. Such methods can generate some personalized responses, but a large part of dialogue history is wasted, leading to sub-optimal performance of personalized response generation. In this work, we propose to refine the user dialogue history on a large scale, based on which we can handle more dialogue history and obtain more abundant and accurate persona information. Specifically, we design an MSP model which consists of three personal information refiners and a personalized response generator. With these multi-level refiners, we can sparsely extract the most valuable information (tokens) from the dialogue history and leverage other similar users' data to enhance personalization. Experimental results on two real-world datasets demonstrate the superiority of our model in generating more informative and personalized responses.
Online Segmentation of LiDAR Sequences: Dataset and Algorithm
Jun 16, 2022
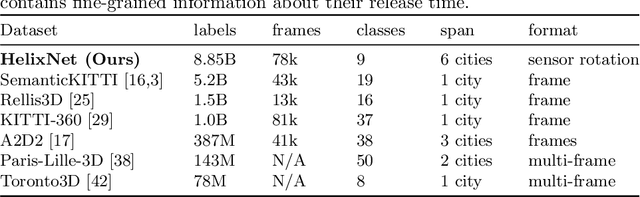
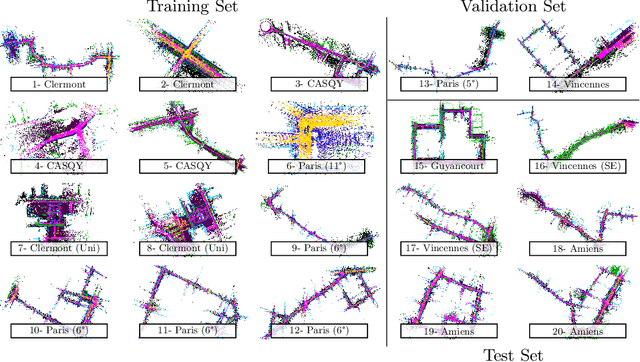
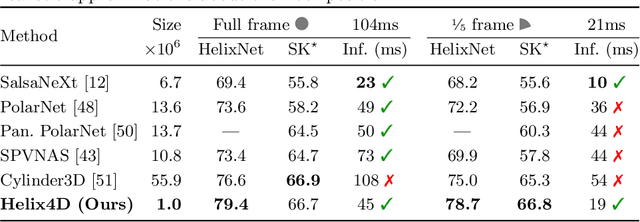
Roof-mounted spinning LiDAR sensors are widely used by autonomous vehicles, driving the need for real-time processing of 3D point sequences. However, most LiDAR semantic segmentation datasets and algorithms split these acquisitions into $360^\circ$ frames, leading to acquisition latency that is incompatible with realistic real-time applications and evaluations. We address this issue with two key contributions. First, we introduce HelixNet, a $10$ billion point dataset with fine-grained labels, timestamps, and sensor rotation information that allows an accurate assessment of real-time readiness of segmentation algorithms. Second, we propose Helix4D, a compact and efficient spatio-temporal transformer architecture specifically designed for rotating LiDAR point sequences. Helix4D operates on acquisition slices that correspond to a fraction of a full rotation of the sensor, significantly reducing the total latency. We present an extensive benchmark of the performance and real-time readiness of several state-of-the-art models on HelixNet and SemanticKITTI. Helix4D reaches accuracy on par with the best segmentation algorithms with a reduction of more than $5\times$ in terms of latency and $50\times$ in model size. Code and data are available at: https://romainloiseau.fr/helixnet
Functional Nonlinear Learning
Jun 22, 2022

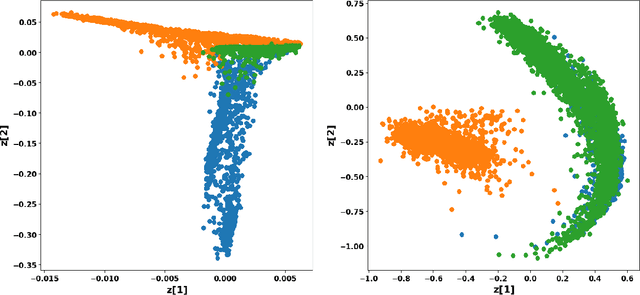
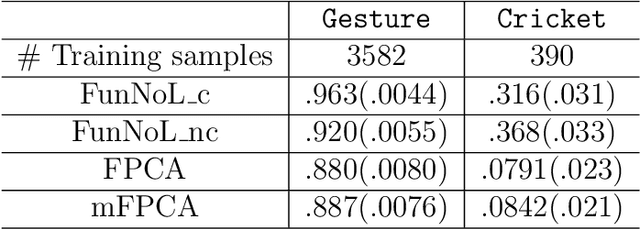
Using representations of functional data can be more convenient and beneficial in subsequent statistical models than direct observations. These representations, in a lower-dimensional space, extract and compress information from individual curves. The existing representation learning approaches in functional data analysis usually use linear mapping in parallel to those from multivariate analysis, e.g., functional principal component analysis (FPCA). However, functions, as infinite-dimensional objects, sometimes have nonlinear structures that cannot be uncovered by linear mapping. Linear methods will be more overwhelmed given multivariate functional data. For that matter, this paper proposes a functional nonlinear learning (FunNoL) method to sufficiently represent multivariate functional data in a lower-dimensional feature space. Furthermore, we merge a classification model for enriching the ability of representations in predicting curve labels. Hence, representations from FunNoL can be used for both curve reconstruction and classification. Additionally, we have endowed the proposed model with the ability to address the missing observation problem as well as to further denoise observations. The resulting representations are robust to observations that are locally disturbed by uncontrollable random noises. We apply the proposed FunNoL method to several real data sets and show that FunNoL can achieve better classifications than FPCA, especially in the multivariate functional data setting. Simulation studies have shown that FunNoL provides satisfactory curve classification and reconstruction regardless of data sparsity.
Application of Knowledge Graphs to Provide Side Information for Improved Recommendation Accuracy
Jan 07, 2021
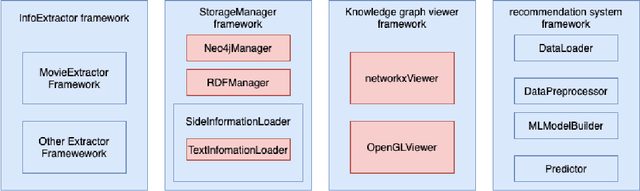

Personalized recommendations are popular in these days of Internet driven activities, specifically shopping. Recommendation methods can be grouped into three major categories, content based filtering, collaborative filtering and machine learning enhanced. Information about products and preferences of different users are primarily used to infer preferences for a specific user. Inadequate information can obviously cause these methods to fail or perform poorly. The more information we provide to these methods, the more likely it is that the methods perform better. Knowledge graphs represent the current trend in recording information in the form of relations between entities, and can provide additional (side) information about products and users. Such information can be used to improve nearest neighbour search, clustering users and products, or train the neural network, when one is used. In this work, we present a new generic recommendation systems framework, that integrates knowledge graphs into the recommendation pipeline. We describe its software design and implementation, and then show through experiments, how such a framework can be specialized for a domain, say movie recommendations, and the improvements in recommendation results possible due to side information obtained from knowledge graphs representation of such information. Our framework supports different knowledge graph representation formats, and facilitates format conversion, merging and information extraction needed for training recommendation methods.
Predicting Human Performance in Vertical Hierarchical Menu Selection in Immersive AR Using Hand-gesture and Head-gaze
Jun 19, 2022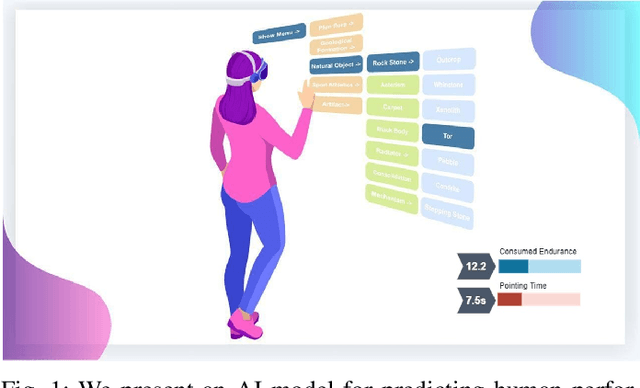
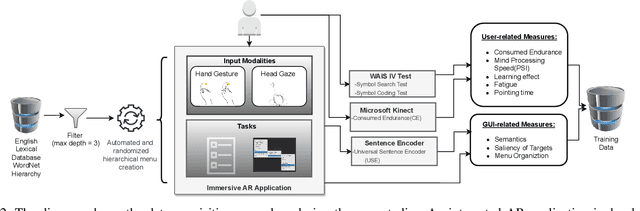

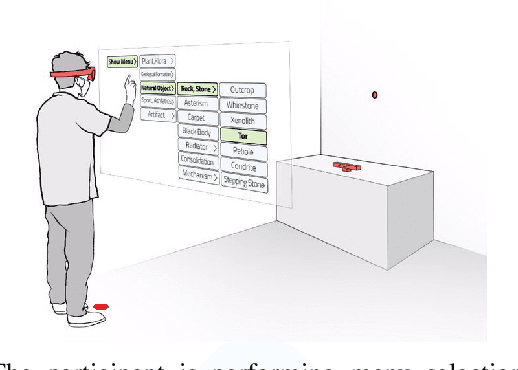
There are currently limited guidelines on designing user interfaces (UI) for immersive augmented reality (AR) applications. Designers must reflect on their experience designing UI for desktop and mobile applications and conjecture how a UI will influence AR users' performance. In this work, we introduce a predictive model for determining users' performance for a target UI without the subsequent involvement of participants in user studies. The model is trained on participants' responses to objective performance measures such as consumed endurance (CE) and pointing time (PT) using hierarchical drop-down menus. Large variability in the depth and context of the menus is ensured by randomly and dynamically creating the hierarchical drop-down menus and associated user tasks from words contained in the lexical database WordNet. Subjective performance bias is reduced by incorporating the users' non-verbal standard performance WAIS-IV during the model training. The semantic information of the menu is encoded using the Universal Sentence Encoder. We present the results of a user study that demonstrates that the proposed predictive model achieves high accuracy in predicting the CE on hierarchical menus of users with various cognitive abilities. To the best of our knowledge, this is the first work on predicting CE in designing UI for immersive AR applications.
Learning in Distributed Contextual Linear Bandits Without Sharing the Context
Jun 08, 2022Contextual linear bandits is a rich and theoretically important model that has many practical applications. Recently, this setup gained a lot of interest in applications over wireless where communication constraints can be a performance bottleneck, especially when the contexts come from a large $d$-dimensional space. In this paper, we consider a distributed memoryless contextual linear bandit learning problem, where the agents who observe the contexts and take actions are geographically separated from the learner who performs the learning while not seeing the contexts. We assume that contexts are generated from a distribution and propose a method that uses $\approx 5d$ bits per context for the case of unknown context distribution and $0$ bits per context if the context distribution is known, while achieving nearly the same regret bound as if the contexts were directly observable. The former bound improves upon existing bounds by a $\log(T)$ factor, where $T$ is the length of the horizon, while the latter achieves information theoretical tightness.
Spiking Graph Convolutional Networks
May 05, 2022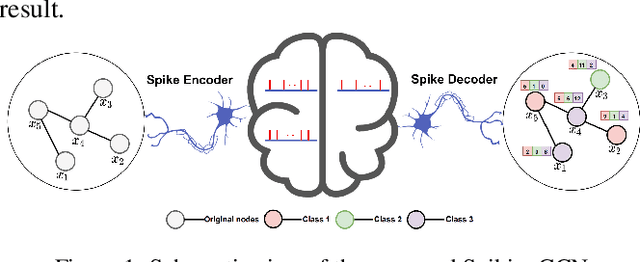
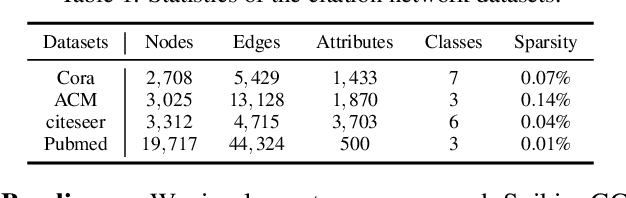
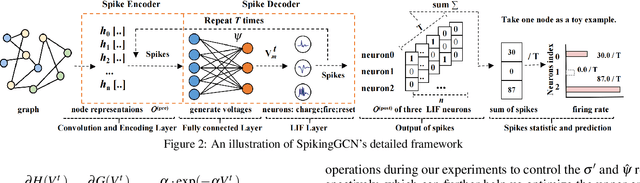
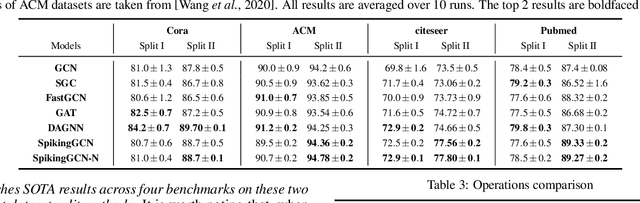
Graph Convolutional Networks (GCNs) achieve an impressive performance due to the remarkable representation ability in learning the graph information. However, GCNs, when implemented on a deep network, require expensive computation power, making them difficult to be deployed on battery-powered devices. In contrast, Spiking Neural Networks (SNNs), which perform a bio-fidelity inference process, offer an energy-efficient neural architecture. In this work, we propose SpikingGCN, an end-to-end framework that aims to integrate the embedding of GCNs with the biofidelity characteristics of SNNs. The original graph data are encoded into spike trains based on the incorporation of graph convolution. We further model biological information processing by utilizing a fully connected layer combined with neuron nodes. In a wide range of scenarios (e.g. citation networks, image graph classification, and recommender systems), our experimental results show that the proposed method could gain competitive performance against state-of-the-art approaches. Furthermore, we show that SpikingGCN on a neuromorphic chip can bring a clear advantage of energy efficiency into graph data analysis, which demonstrates its great potential to construct environment-friendly machine learning models.
Spatial Acoustic Projection for 3D Imaging Sonar Reconstruction
Jun 06, 2022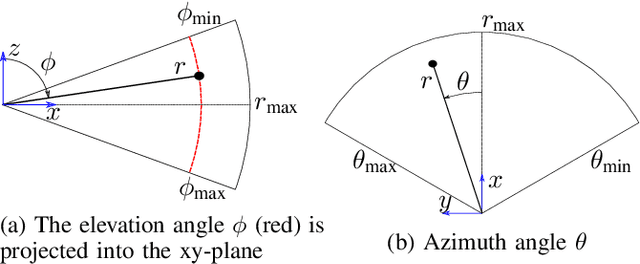


In this work we present a novel method for reconstructing 3D surfaces using a multi-beam imaging sonar. We integrate the intensities measured by the sonar from different viewpoints for fixed cell positions in a 3D grid. For each cell we integrate a feature vector that holds the mean intensity for a discretized range of viewpoints. Based on the feature vectors and independent sparse range measurements that act as ground truth information, we train convolutional neural networks that allow us to predict the signed distance and direction to the nearest surface for each cell. The predicted signed distances can be projected into a truncated signed distance field (TSDF) along the predicted directions. Utilizing the marching cubes algorithm, a polygon mesh can be rendered from the TSDF. Our method allows a dense 3D reconstruction from a limited set of viewpoints and was evaluated on three real-world datasets.
* Preprint
Threat Assessment in Machine Learning based Systems
Jun 30, 2022
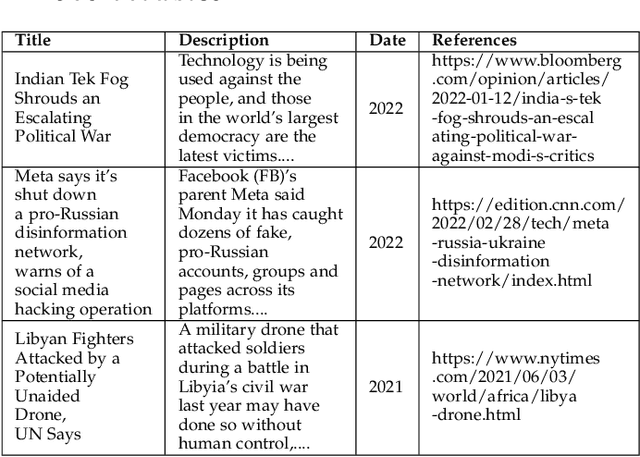
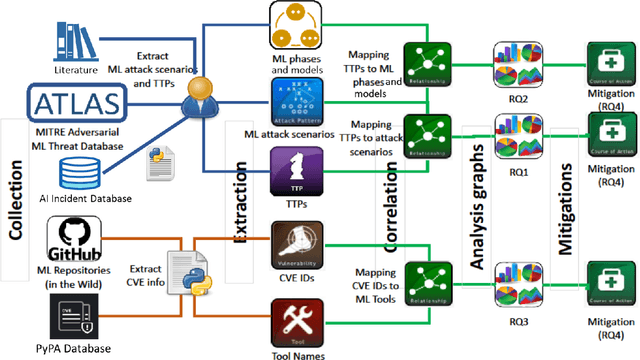
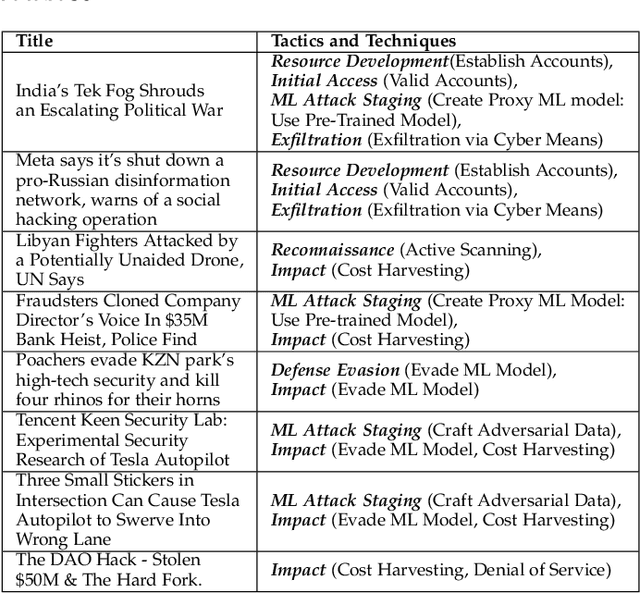
Machine learning is a field of artificial intelligence (AI) that is becoming essential for several critical systems, making it a good target for threat actors. Threat actors exploit different Tactics, Techniques, and Procedures (TTPs) against the confidentiality, integrity, and availability of Machine Learning (ML) systems. During the ML cycle, they exploit adversarial TTPs to poison data and fool ML-based systems. In recent years, multiple security practices have been proposed for traditional systems but they are not enough to cope with the nature of ML-based systems. In this paper, we conduct an empirical study of threats reported against ML-based systems with the aim to understand and characterize the nature of ML threats and identify common mitigation strategies. The study is based on 89 real-world ML attack scenarios from the MITRE's ATLAS database, the AI Incident Database, and the literature; 854 ML repositories from the GitHub search and the Python Packaging Advisory database, selected based on their reputation. Attacks from the AI Incident Database and the literature are used to identify vulnerabilities and new types of threats that were not documented in ATLAS. Results show that convolutional neural networks were one of the most targeted models among the attack scenarios. ML repositories with the largest vulnerability prominence include TensorFlow, OpenCV, and Notebook. In this paper, we also report the most frequent vulnerabilities in the studied ML repositories, the most targeted ML phases and models, the most used TTPs in ML phases and attack scenarios. This information is particularly important for red/blue teams to better conduct attacks/defenses, for practitioners to prevent threats during ML development, and for researchers to develop efficient defense mechanisms.