 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Empirical Analysis on the Vulnerabilities of End-to-End Speech Segregation Models
Jun 20, 2022
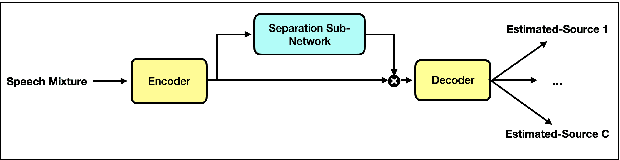
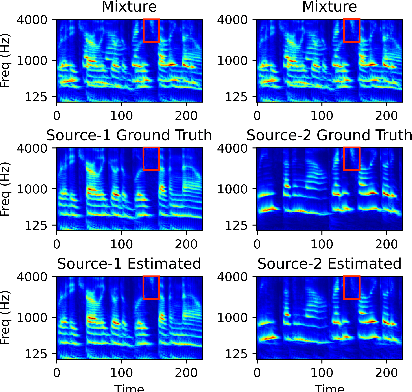
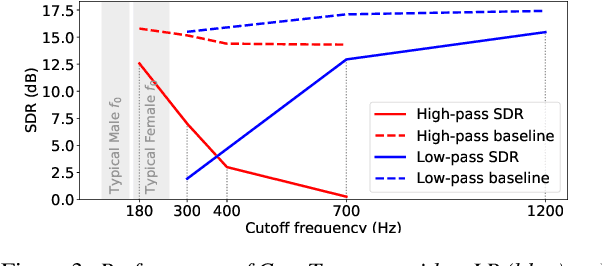
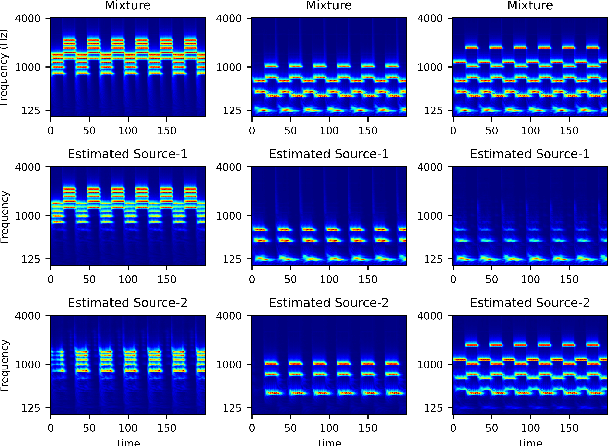
End-to-end learning models have demonstrated a remarkable capability in performing speech segregation. Despite their wide-scope of real-world applications, little is known about the mechanisms they employ to group and consequently segregate individual speakers. Knowing that harmonicity is a critical cue for these networks to group sources, in this work, we perform a thorough investigation on ConvTasnet and DPT-Net to analyze how they perform a harmonic analysis of the input mixture. We perform ablation studies where we apply low-pass, high-pass, and band-stop filters of varying pass-bands to empirically analyze the harmonics most critical for segregation. We also investigate how these networks decide which output channel to assign to an estimated source by introducing discontinuities in synthetic mixtures. We find that end-to-end networks are highly unstable, and perform poorly when confronted with deformations which are imperceptible to humans. Replacing the encoder in these networks with a spectrogram leads to lower overall performance, but much higher stability. This work helps us to understand what information these network rely on for speech segregation, and exposes two sources of generalization-errors. It also pinpoints the encoder as the part of the network responsible for these errors, allowing for a redesign with expert knowledge or transfer learning.
Entropy Maximization with Depth: A Variational Principle for Random Neural Networks
May 25, 2022
To understand the essential role of depth in neural networks, we investigate a variational principle for depth: Does increasing depth perform an implicit optimization for the representations in neural networks? We prove that random neural networks equipped with batch normalization maximize the differential entropy of representations with depth up to constant factors, assuming that the representations are contractive. Thus, representations inherently obey the \textit{principle of maximum entropy} at initialization, in the absence of information about the learning task. Our variational formulation for neural representations characterizes the interplay between representation entropy and architectural components, including depth, width, and non-linear activations, thereby potentially inspiring the design of neural architectures.
Predicting the Need for Blood Transfusion in Intensive Care Units with Reinforcement Learning
Jun 26, 2022
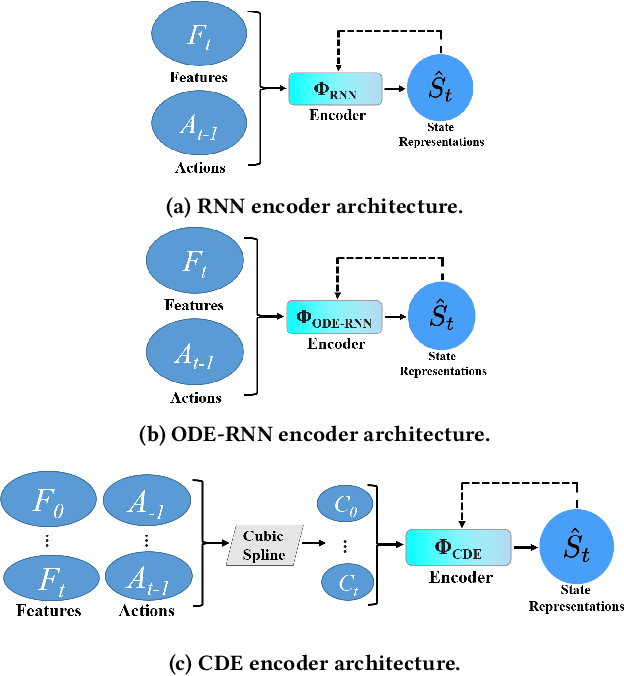
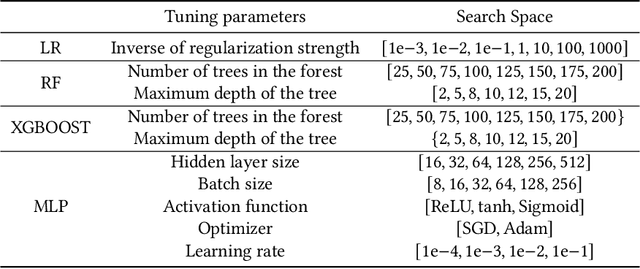
As critically ill patients frequently develop anemia or coagulopathy, transfusion of blood products is a frequent intervention in the Intensive Care Units (ICU). However, inappropriate transfusion decisions made by physicians are often associated with increased risk of complications and higher hospital costs. In this work, we aim to develop a decision support tool that uses available patient information for transfusion decision-making on three common blood products (red blood cells, platelets, and fresh frozen plasma). To this end, we adopt an off-policy batch reinforcement learning (RL) algorithm, namely, discretized Batch Constrained Q-learning, to determine the best action (transfusion or not) given observed patient trajectories. Simultaneously, we consider different state representation approaches and reward design mechanisms to evaluate their impacts on policy learning. Experiments are conducted on two real-world critical care datasets: the MIMIC-III and the UCSF. Results demonstrate that policy recommendations on transfusion achieved comparable matching against true hospital policies via accuracy and weighted importance sampling evaluations on the MIMIC-III dataset. Furthermore, a combination of transfer learning (TL) and RL on the data-scarce UCSF dataset can provide up to $17.02% improvement in terms of accuracy, and up to 18.94% and 21.63% improvement in jump-start and asymptotic performance in terms of weighted importance sampling averaged over three transfusion tasks. Finally, simulations on transfusion decisions suggest that the transferred RL policy could reduce patients' estimated 28-day mortality rate by 2.74% and decreased acuity rate by 1.18% on the UCSF dataset.
A Privacy-Preserving Approach to Extraction of Personal Information through Automatic Annotation and Federated Learning
May 19, 2021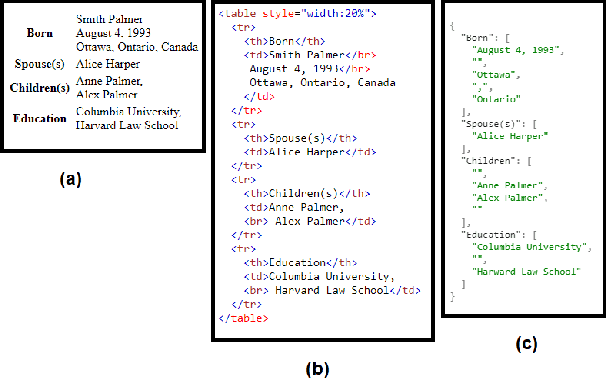



We curated WikiPII, an automatically labeled dataset composed of Wikipedia biography pages, annotated for personal information extraction. Although automatic annotation can lead to a high degree of label noise, it is an inexpensive process and can generate large volumes of annotated documents. We trained a BERT-based NER model with WikiPII and showed that with an adequately large training dataset, the model can significantly decrease the cost of manual information extraction, despite the high level of label noise. In a similar approach, organizations can leverage text mining techniques to create customized annotated datasets from their historical data without sharing the raw data for human annotation. Also, we explore collaborative training of NER models through federated learning when the annotation is noisy. Our results suggest that depending on the level of trust to the ML operator and the volume of the available data, distributed training can be an effective way of training a personal information identifier in a privacy-preserved manner. Research material is available at https://github.com/ratmcu/wikipiifed.
Debiasing Learning for Membership Inference Attacks Against Recommender Systems
Jun 28, 2022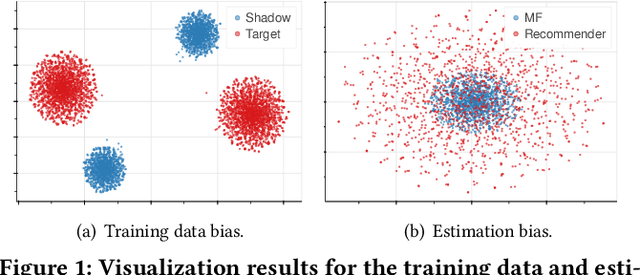
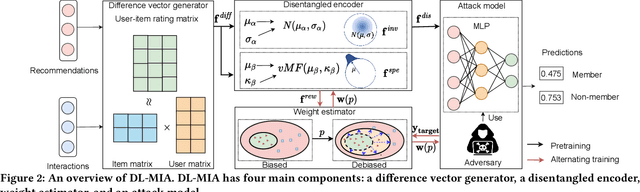
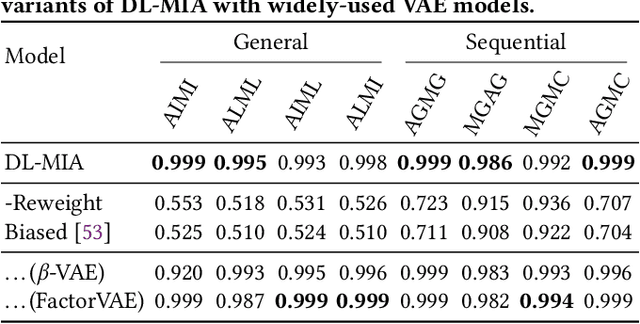
Learned recommender systems may inadvertently leak information about their training data, leading to privacy violations. We investigate privacy threats faced by recommender systems through the lens of membership inference. In such attacks, an adversary aims to infer whether a user's data is used to train the target recommender. To achieve this, previous work has used a shadow recommender to derive training data for the attack model, and then predicts the membership by calculating difference vectors between users' historical interactions and recommended items. State-of-the-art methods face two challenging problems: (1) training data for the attack model is biased due to the gap between shadow and target recommenders, and (2) hidden states in recommenders are not observational, resulting in inaccurate estimations of difference vectors. To address the above limitations, we propose a Debiasing Learning for Membership Inference Attacks against recommender systems (DL-MIA) framework that has four main components: (1) a difference vector generator, (2) a disentangled encoder, (3) a weight estimator, and (4) an attack model. To mitigate the gap between recommenders, a variational auto-encoder (VAE) based disentangled encoder is devised to identify recommender invariant and specific features. To reduce the estimation bias, we design a weight estimator, assigning a truth-level score for each difference vector to indicate estimation accuracy. We evaluate DL-MIA against both general recommenders and sequential recommenders on three real-world datasets. Experimental results show that DL-MIA effectively alleviates training and estimation biases simultaneously, and achieves state-of-the-art attack performance.
Subspace-Based Detection and Localization in Distributed MIMO Radars
May 18, 2022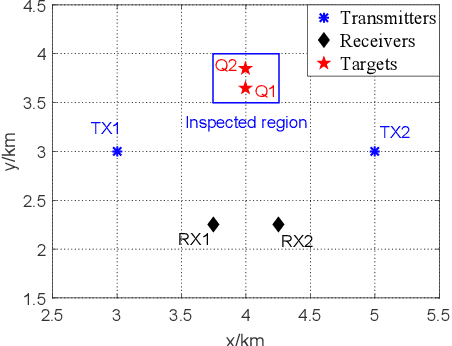
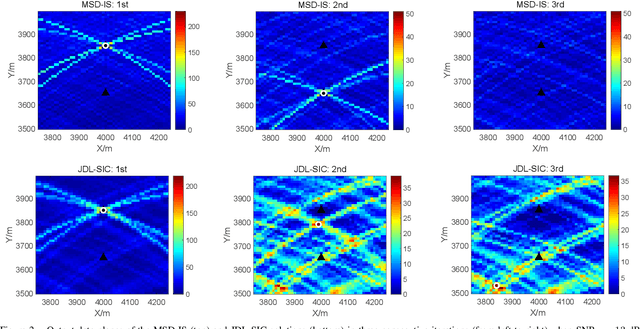
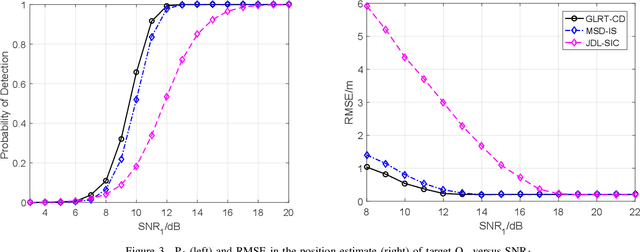
In this paper, we consider a distributed multiple-input multiple-output (MIMO) radar which radiates waveforms with non-ideal cross- and auto-correlation functions and derive a novel subspace-based procedure to detect and localize multiple prospective targets. The proposed solution solves a sequence of composite binary hypothesis testing problems by resorting to the generalized information criterion (GIC); in particular, at each step, it aims to detect and localize one additional target, upon removing the interference caused by the previously-detected targets. An illustrative example is provided.
'John ate 5 apples' != 'John ate some apples': Self-Supervised Paraphrase Quality Detection for Algebraic Word Problems
Jun 16, 2022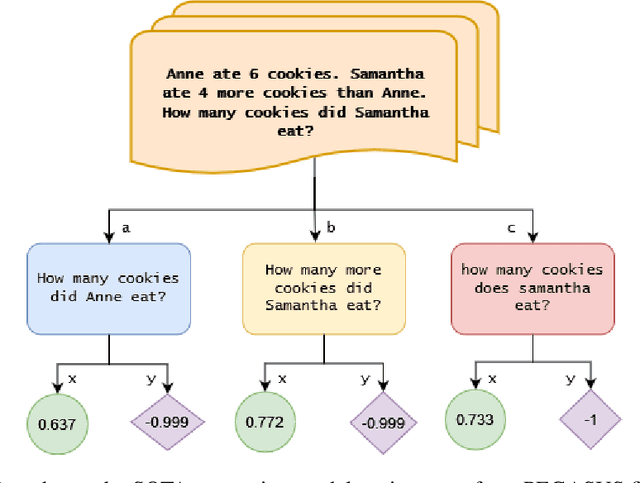
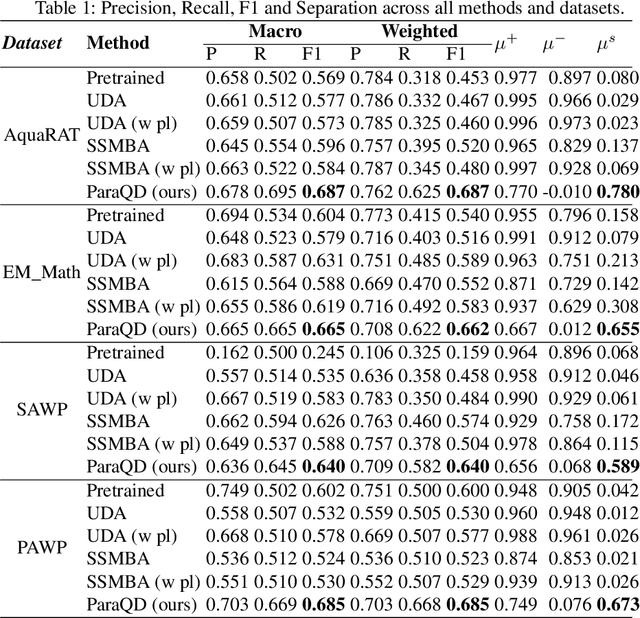

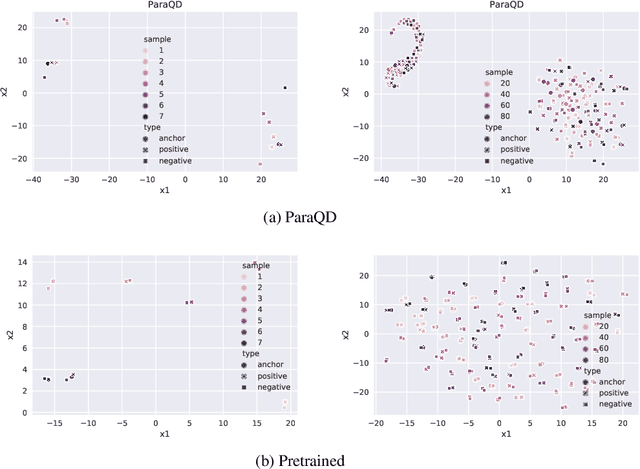
This paper introduces the novel task of scoring paraphrases for Algebraic Word Problems (AWP) and presents a self-supervised method for doing so. In the current online pedagogical setting, paraphrasing these problems is helpful for academicians to generate multiple syntactically diverse questions for assessments. It also helps induce variation to ensure that the student has understood the problem instead of just memorizing it or using unfair means to solve it. The current state-of-the-art paraphrase generation models often cannot effectively paraphrase word problems, losing a critical piece of information (such as numbers or units) which renders the question unsolvable. There is a need for paraphrase scoring methods in the context of AWP to enable the training of good paraphrasers. Thus, we propose ParaQD, a self-supervised paraphrase quality detection method using novel data augmentations that can learn latent representations to separate a high-quality paraphrase of an algebraic question from a poor one by a wide margin. Through extensive experimentation, we demonstrate that our method outperforms existing state-of-the-art self-supervised methods by up to 32% while also demonstrating impressive zero-shot performance.
A Deep Bayesian Bandits Approach for Anticancer Therapy: Exploration via Functional Prior
May 05, 2022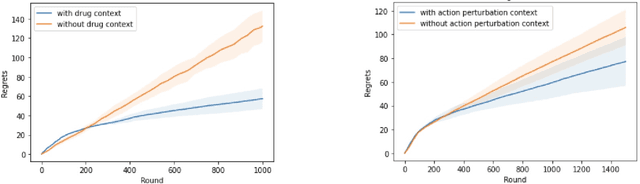
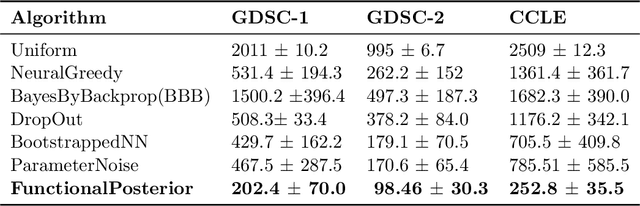
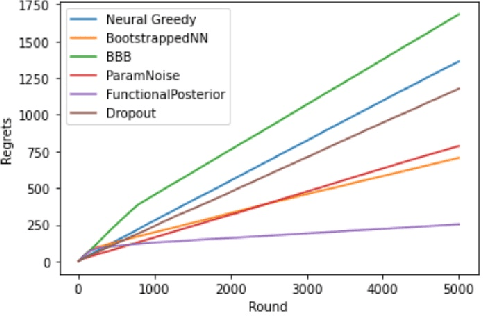
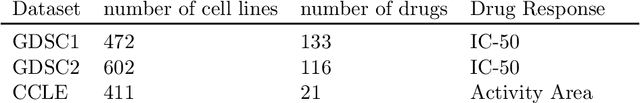
Learning personalized cancer treatment with machine learning holds great promise to improve cancer patients' chance of survival. Despite recent advances in machine learning and precision oncology, this approach remains challenging as collecting data in preclinical/clinical studies for modeling multiple treatment efficacies is often an expensive, time-consuming process. Moreover, the randomization in treatment allocation proves to be suboptimal since some participants/samples are not receiving the most appropriate treatments during the trial. To address this challenge, we formulate drug screening study as a "contextual bandit" problem, in which an algorithm selects anticancer therapeutics based on contextual information about cancer cell lines while adapting its treatment strategy to maximize treatment response in an "online" fashion. We propose using a novel deep Bayesian bandits framework that uses functional prior to approximate posterior for drug response prediction based on multi-modal information consisting of genomic features and drug structure. We empirically evaluate our method on three large-scale in vitro pharmacogenomic datasets and show that our approach outperforms several benchmarks in identifying optimal treatment for a given cell line.
Neo-GNNs: Neighborhood Overlap-aware Graph Neural Networks for Link Prediction
Jun 09, 2022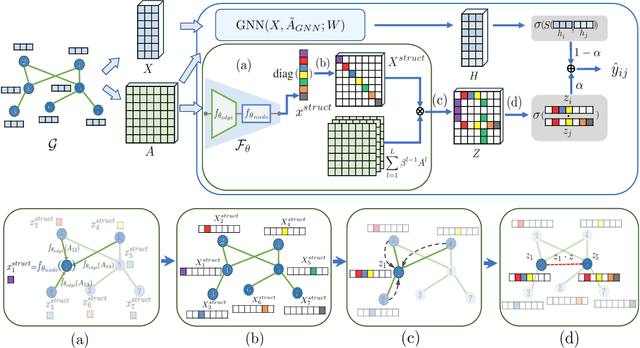
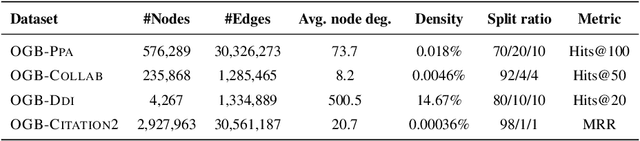
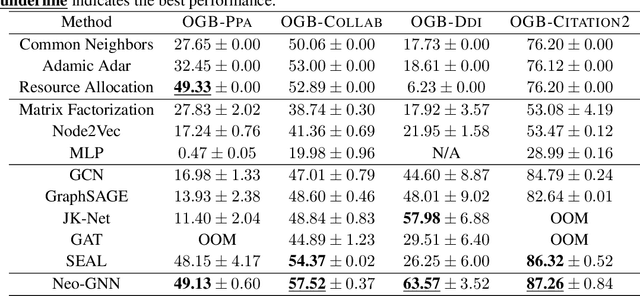
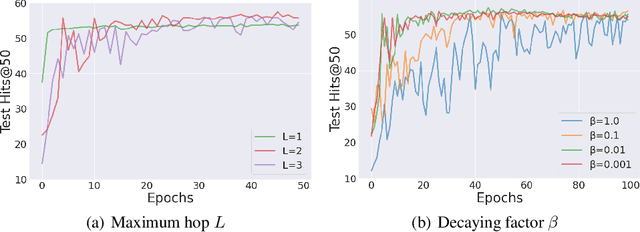
Graph Neural Networks (GNNs) have been widely applied to various fields for learning over graph-structured data. They have shown significant improvements over traditional heuristic methods in various tasks such as node classification and graph classification. However, since GNNs heavily rely on smoothed node features rather than graph structure, they often show poor performance than simple heuristic methods in link prediction where the structural information, e.g., overlapped neighborhoods, degrees, and shortest paths, is crucial. To address this limitation, we propose Neighborhood Overlap-aware Graph Neural Networks (Neo-GNNs) that learn useful structural features from an adjacency matrix and estimate overlapped neighborhoods for link prediction. Our Neo-GNNs generalize neighborhood overlap-based heuristic methods and handle overlapped multi-hop neighborhoods. Our extensive experiments on Open Graph Benchmark datasets (OGB) demonstrate that Neo-GNNs consistently achieve state-of-the-art performance in link prediction. Our code is publicly available at https://github.com/seongjunyun/Neo_GNNs.
Detecting tiny objects in aerial images: A normalized Wasserstein distance and a new benchmark
Jun 28, 2022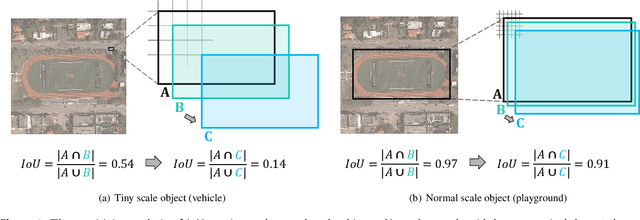
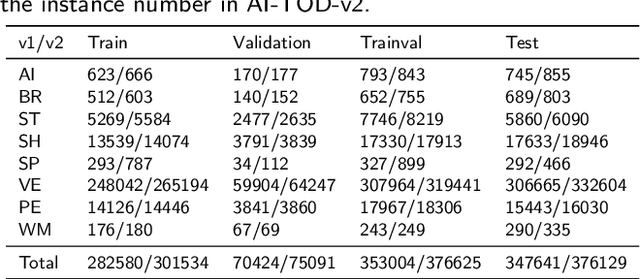
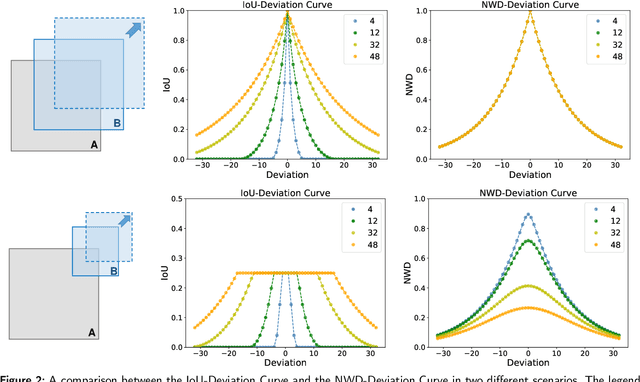
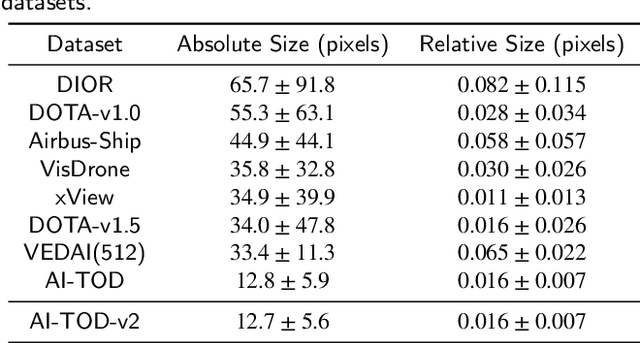
Tiny object detection (TOD) in aerial images is challenging since a tiny object only contains a few pixels. State-of-the-art object detectors do not provide satisfactory results on tiny objects due to the lack of supervision from discriminative features. Our key observation is that the Intersection over Union (IoU) metric and its extensions are very sensitive to the location deviation of the tiny objects, which drastically deteriorates the quality of label assignment when used in anchor-based detectors. To tackle this problem, we propose a new evaluation metric dubbed Normalized Wasserstein Distance (NWD) and a new RanKing-based Assigning (RKA) strategy for tiny object detection. The proposed NWD-RKA strategy can be easily embedded into all kinds of anchor-based detectors to replace the standard IoU threshold-based one, significantly improving label assignment and providing sufficient supervision information for network training. Tested on four datasets, NWD-RKA can consistently improve tiny object detection performance by a large margin. Besides, observing prominent noisy labels in the Tiny Object Detection in Aerial Images (AI-TOD) dataset, we are motivated to meticulously relabel it and release AI-TOD-v2 and its corresponding benchmark. In AI-TOD-v2, the missing annotation and location error problems are considerably mitigated, facilitating more reliable training and validation processes. Embedding NWD-RKA into DetectoRS, the detection performance achieves 4.3 AP points improvement over state-of-the-art competitors on AI-TOD-v2. Datasets, codes, and more visualizations are available at: https://chasel-tsui.github.io/AI-TOD-v2/
* Accepted by ISPRS Journal of Photogrammetry and Remote Sensing