 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross Reconstruction Transformer for Self-Supervised Time Series Representation Learning
May 20, 2022
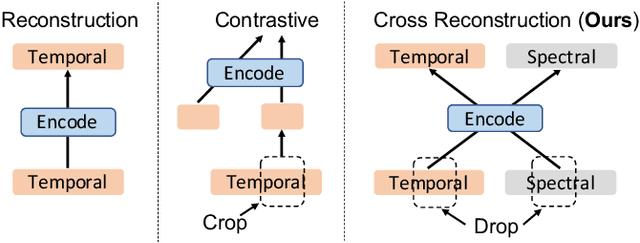
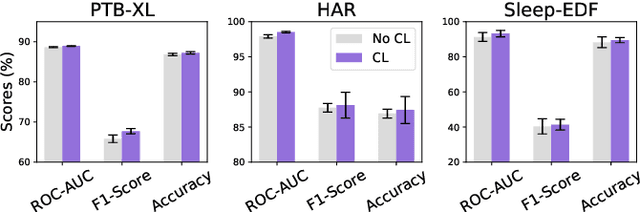
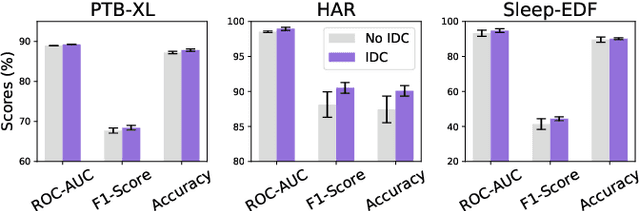
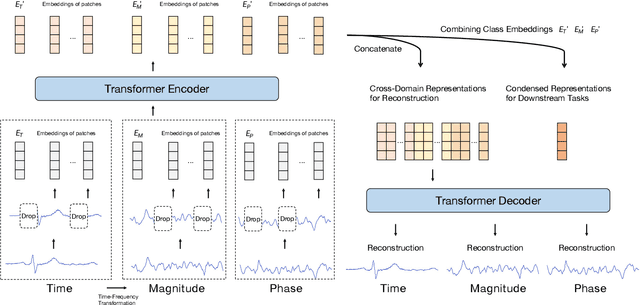
Unsupervised/self-supervised representation learning in time series is critical since labeled samples are usually scarce in real-world scenarios. Existing approaches mainly leverage the contrastive learning framework, which automatically learns to understand the similar and dissimilar data pairs. Nevertheless, they are restricted to the prior knowledge of constructing pairs, cumbersome sampling policy, and unstable performances when encountering sampling bias. Also, few works have focused on effectively modeling across temporal-spectral relations to extend the capacity of representations. In this paper, we aim at learning representations for time series from a new perspective and propose Cross Reconstruction Transformer (CRT) to solve the aforementioned problems in a unified way. CRT achieves time series representation learning through a cross-domain dropping-reconstruction task. Specifically, we transform time series into the frequency domain and randomly drop certain parts in both time and frequency domains. Dropping can maximally preserve the global context compared to cropping and masking. Then a transformer architecture is utilized to adequately capture the cross-domain correlations between temporal and spectral information through reconstructing data in both domains, which is called Dropped Temporal-Spectral Modeling. To discriminate the representations in global latent space, we propose Instance Discrimination Constraint to reduce the mutual information between different time series and sharpen the decision boundaries. Additionally, we propose a specified curriculum learning strategy to optimize the CRT, which progressively increases the dropping ratio in the training process.
Benchmarking Constraint Inference in Inverse Reinforcement Learning
Jun 20, 2022
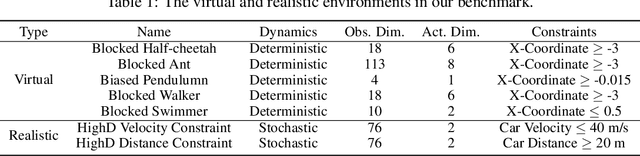
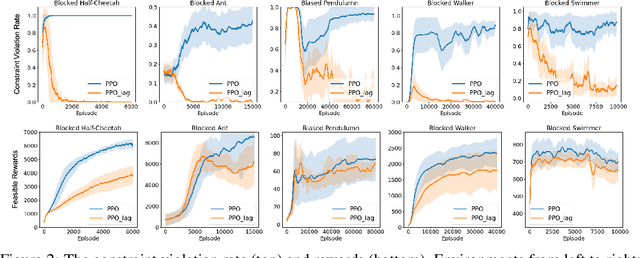

When deploying Reinforcement Learning (RL) agents into a physical system, we must ensure that these agents are well aware of the underlying constraints. In many real-world problems, however, the constraints followed by expert agents (e.g., humans) are often hard to specify mathematically and unknown to the RL agents. To tackle these issues, Constraint Inverse Reinforcement Learning (CIRL) considers the formalism of Constrained Markov Decision Processes (CMDPs) and estimates constraints from expert demonstrations by learning a constraint function. As an emerging research topic, CIRL does not have common benchmarks, and previous works tested their algorithms with hand-crafted environments (e.g., grid worlds). In this paper, we construct a CIRL benchmark in the context of two major application domains: robot control and autonomous driving. We design relevant constraints for each environment and empirically study the ability of different algorithms to recover those constraints based on expert trajectories that respect those constraints. To handle stochastic dynamics, we propose a variational approach that infers constraint distributions, and we demonstrate its performance by comparing it with other CIRL baselines on our benchmark. The benchmark, including the information for reproducing the performance of CIRL algorithms, is publicly available at https://github.com/Guiliang/CIRL-benchmarks-public
Efficient Multiscale Object-based Superpixel Framework
Apr 07, 2022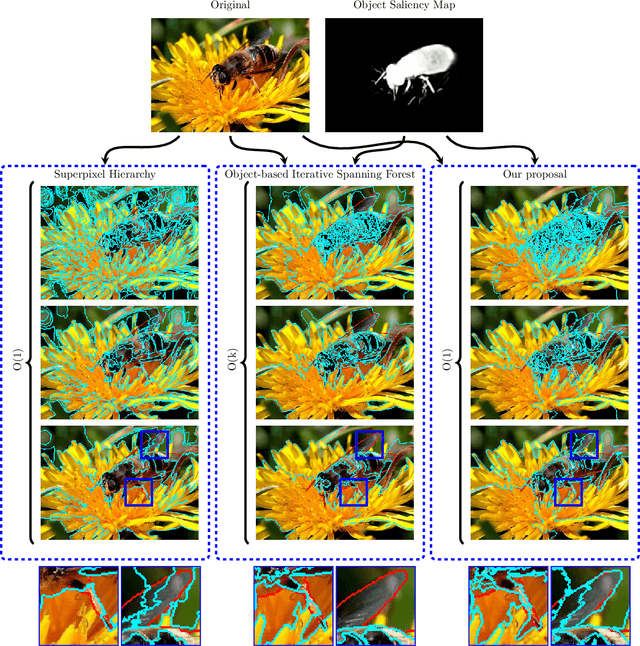
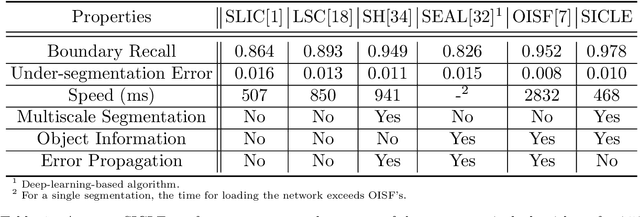
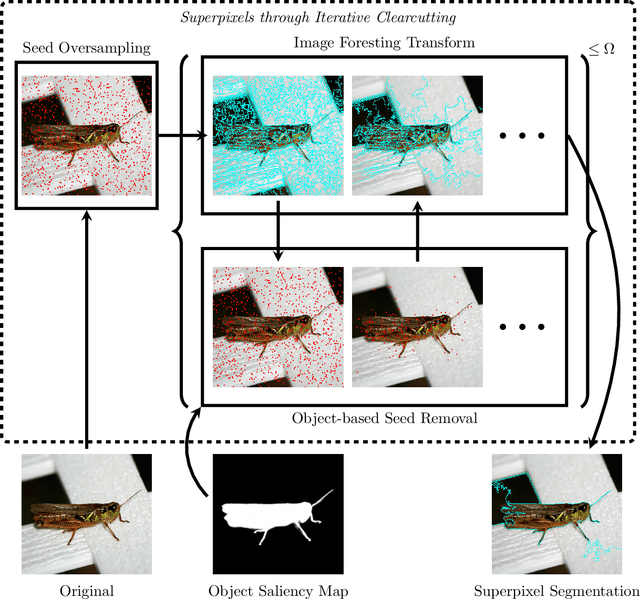

Superpixel segmentation can be used as an intermediary step in many applications, often to improve object delineation and reduce computer workload. However, classical methods do not incorporate information about the desired object. Deep-learning-based approaches consider object information, but their delineation performance depends on data annotation. Additionally, the computational time of object-based methods is usually much higher than desired. In this work, we propose a novel superpixel framework, named Superpixels through Iterative CLEarcutting (SICLE), which exploits object information being able to generate a multiscale segmentation on-the-fly. SICLE starts off from seed oversampling and repeats optimal connectivity-based superpixel delineation and object-based seed removal until a desired number of superpixels is reached. It generalizes recent superpixel methods, surpassing them and other state-of-the-art approaches in efficiency and effectiveness according to multiple delineation metrics.
Multi-Agent Neural Rewriter for Vehicle Routing with Limited Disclosure of Costs
Jun 13, 2022

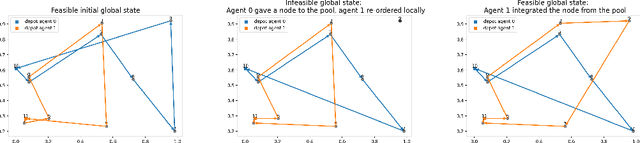

We interpret solving the multi-vehicle routing problem as a team Markov game with partially observable costs. For a given set of customers to serve, the playing agents (vehicles) have the common goal to determine the team-optimal agent routes with minimal total cost. Each agent thereby observes only its own cost. Our multi-agent reinforcement learning approach, the so-called multi-agent Neural Rewriter, builds on the single-agent Neural Rewriter to solve the problem by iteratively rewriting solutions. Parallel agent action execution and partial observability require new rewriting rules for the game. We propose the introduction of a so-called pool in the system which serves as a collection point for unvisited nodes. It enables agents to act simultaneously and exchange nodes in a conflict-free manner. We realize limited disclosure of agent-specific costs by only sharing them during learning. During inference, each agents acts decentrally, solely based on its own cost. First empirical results on small problem sizes demonstrate that we reach a performance close to the employed OR-Tools benchmark which operates in the perfect cost information setting.
Application of Knowledge Graphs to Provide Side Information for Improved Recommendation Accuracy
Jan 07, 2021
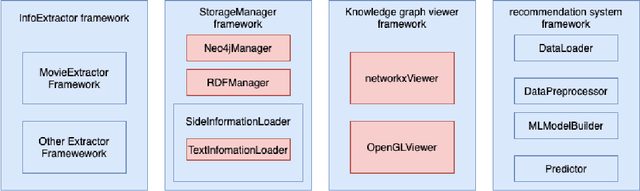

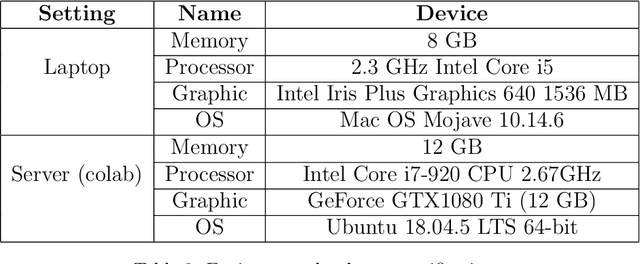
Personalized recommendations are popular in these days of Internet driven activities, specifically shopping. Recommendation methods can be grouped into three major categories, content based filtering, collaborative filtering and machine learning enhanced. Information about products and preferences of different users are primarily used to infer preferences for a specific user. Inadequate information can obviously cause these methods to fail or perform poorly. The more information we provide to these methods, the more likely it is that the methods perform better. Knowledge graphs represent the current trend in recording information in the form of relations between entities, and can provide additional (side) information about products and users. Such information can be used to improve nearest neighbour search, clustering users and products, or train the neural network, when one is used. In this work, we present a new generic recommendation systems framework, that integrates knowledge graphs into the recommendation pipeline. We describe its software design and implementation, and then show through experiments, how such a framework can be specialized for a domain, say movie recommendations, and the improvements in recommendation results possible due to side information obtained from knowledge graphs representation of such information. Our framework supports different knowledge graph representation formats, and facilitates format conversion, merging and information extraction needed for training recommendation methods.
DALL-E for Detection: Language-driven Context Image Synthesis for Object Detection
Jun 20, 2022
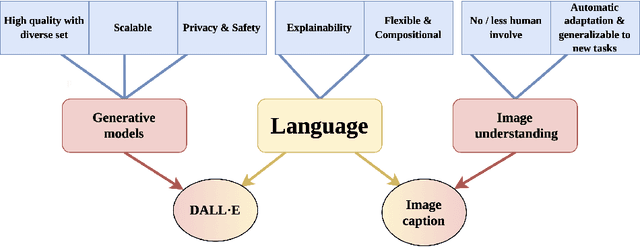
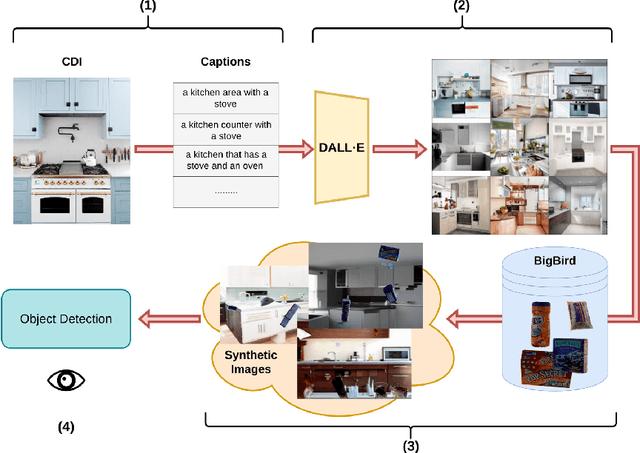
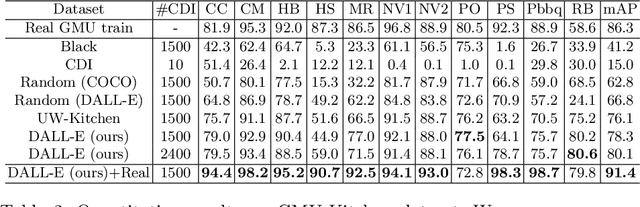
Object cut-and-paste has become a promising approach to efficiently generate large sets of labeled training data. It involves compositing foreground object masks onto background images. The background images, when congruent with the objects, provide helpful context information for training object recognition models. While the approach can easily generate large labeled data, finding congruent context images for downstream tasks has remained an elusive problem. In this work, we propose a new paradigm for automatic context image generation at scale. At the core of our approach lies utilizing an interplay between language description of context and language-driven image generation. Language description of a context is provided by applying an image captioning method on a small set of images representing the context. These language descriptions are then used to generate diverse sets of context images using the language-based DALL-E image generation framework. These are then composited with objects to provide an augmented training set for a classifier. We demonstrate the advantages of our approach over the prior context image generation approaches on four object detection datasets. Furthermore, we also highlight the compositional nature of our data generation approach on out-of-distribution and zero-shot data generation scenarios.
Domain-Adaptive Text Classification with Structured Knowledge from Unlabeled Data
Jun 20, 2022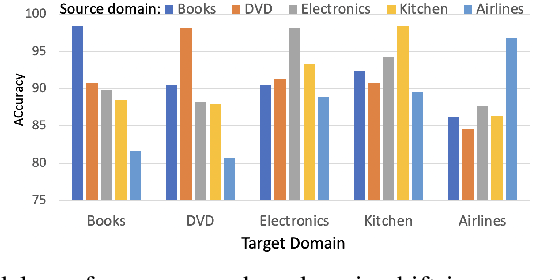
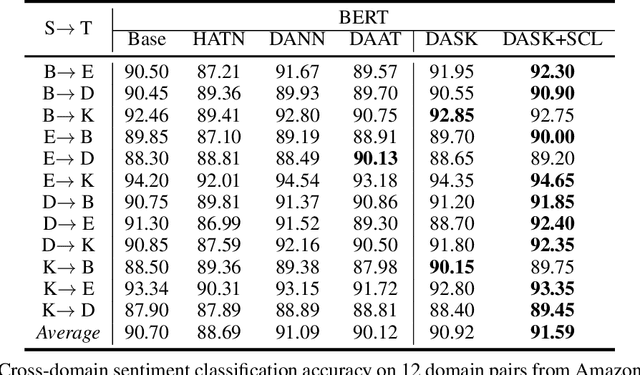
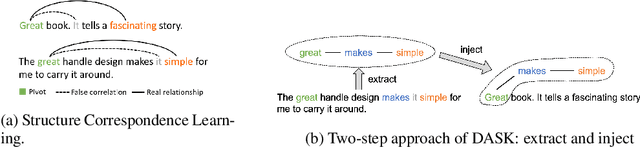
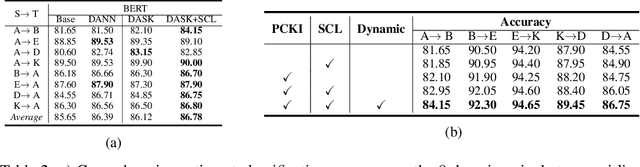
Domain adaptive text classification is a challenging problem for the large-scale pretrained language models because they often require expensive additional labeled data to adapt to new domains. Existing works usually fails to leverage the implicit relationships among words across domains. In this paper, we propose a novel method, called Domain Adaptation with Structured Knowledge (DASK), to enhance domain adaptation by exploiting word-level semantic relationships. DASK first builds a knowledge graph to capture the relationship between pivot terms (domain-independent words) and non-pivot terms in the target domain. Then during training, DASK injects pivot-related knowledge graph information into source domain texts. For the downstream task, these knowledge-injected texts are fed into a BERT variant capable of processing knowledge-injected textual data. Thanks to the knowledge injection, our model learns domain-invariant features for non-pivots according to their relationships with pivots. DASK ensures the pivots to have domain-invariant behaviors by dynamically inferring via the polarity scores of candidate pivots during training with pseudo-labels. We validate DASK on a wide range of cross-domain sentiment classification tasks and observe up to 2.9% absolute performance improvement over baselines for 20 different domain pairs. Code will be made available at https://github.com/hikaru-nara/DASK.
ELUDE: Generating interpretable explanations via a decomposition into labelled and unlabelled features
Jun 16, 2022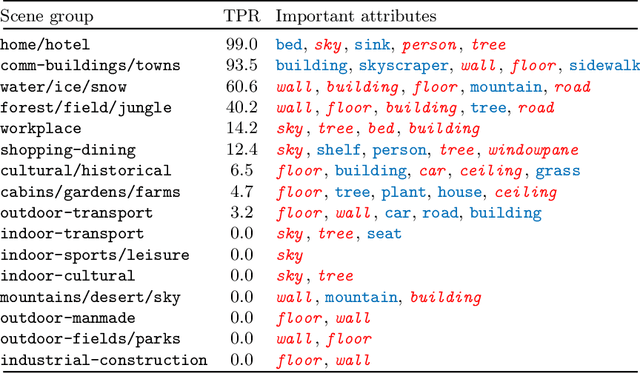
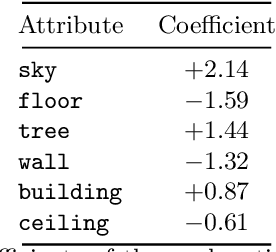
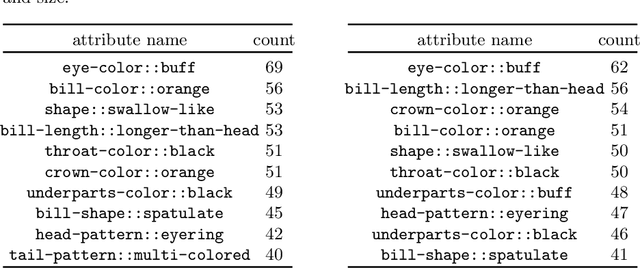

Deep learning models have achieved remarkable success in different areas of machine learning over the past decade; however, the size and complexity of these models make them difficult to understand. In an effort to make them more interpretable, several recent works focus on explaining parts of a deep neural network through human-interpretable, semantic attributes. However, it may be impossible to completely explain complex models using only semantic attributes. In this work, we propose to augment these attributes with a small set of uninterpretable features. Specifically, we develop a novel explanation framework ELUDE (Explanation via Labelled and Unlabelled DEcomposition) that decomposes a model's prediction into two parts: one that is explainable through a linear combination of the semantic attributes, and another that is dependent on the set of uninterpretable features. By identifying the latter, we are able to analyze the "unexplained" portion of the model, obtaining insights into the information used by the model. We show that the set of unlabelled features can generalize to multiple models trained with the same feature space and compare our work to two popular attribute-oriented methods, Interpretable Basis Decomposition and Concept Bottleneck, and discuss the additional insights ELUDE provides.
Wireless Picosecond Time Synchronization for Distributed Antenna Arrays
Jun 16, 2022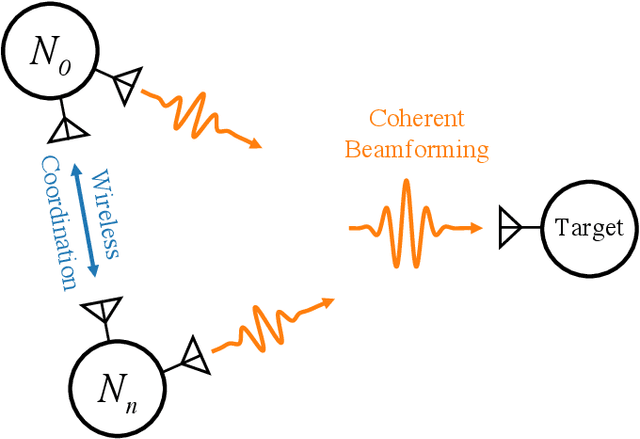
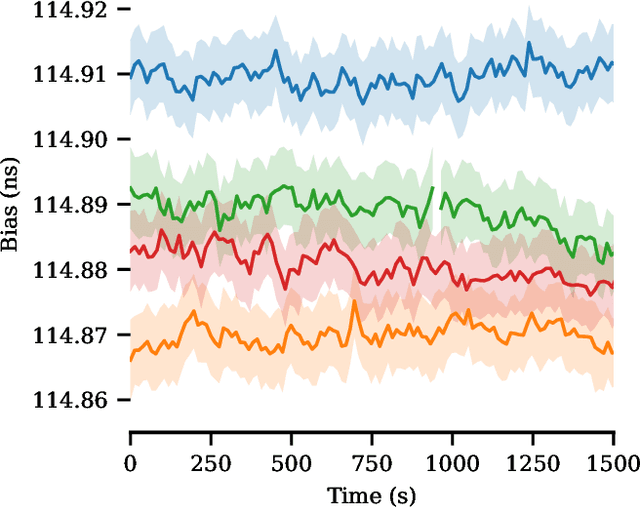
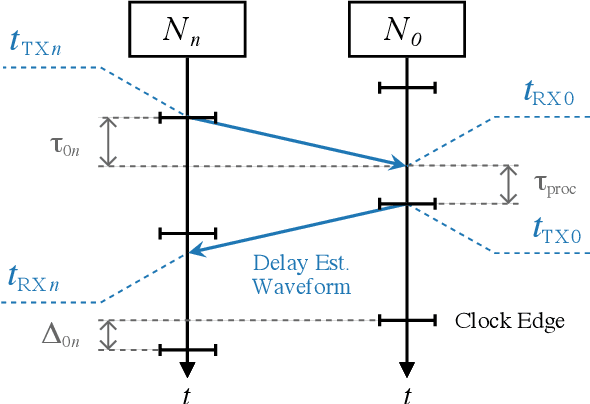
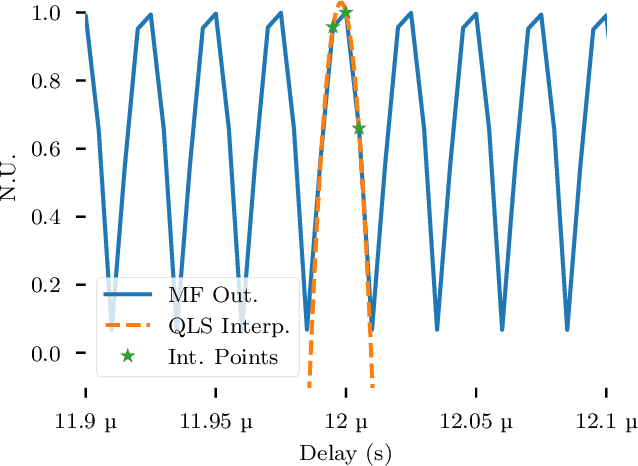
Distributed antenna arrays have been proposed for many applications ranging from space-based observatories to automated vehicles. Achieving good performance in distributed antenna systems requires stringent synchronization at the wavelength and information level to ensure that the transmitted signals arrive coherently at the target, or that scattered and received signals can be appropriately processed via distributed algorithms. In this paper we address the challenge of high precision time synchronization to align the operations of elements in a distributed antenna array and to overcome time-varying bias between platforms due to oscillator drift. We use a spectrally sparse two-tone waveform, which obtains approximately optimal time estimation accuracy, in a two-way time transfer process. We also describe a technique for determining the true time delay using the ambiguous two-tone matched filter output, and we compare the time synchronization precision of the two-tone waveform with the more common linear frequency modulation (LFM) waveform. We experimentally demonstrate wireless time synchronization using a single pulse 40$\,$MHz two-tone waveform over a 90$\,$cm 5.8$\,$GHz wireless link in a laboratory setting, obtaining a timing precision of 2.26$\,$ps.
BertNet: Harvesting Knowledge Graphs from Pretrained Language Models
Jun 28, 2022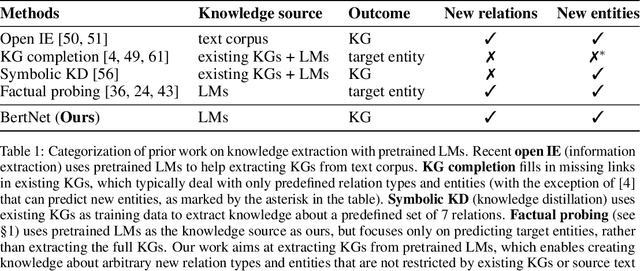
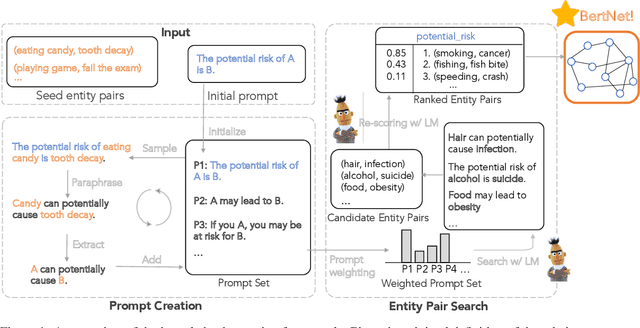
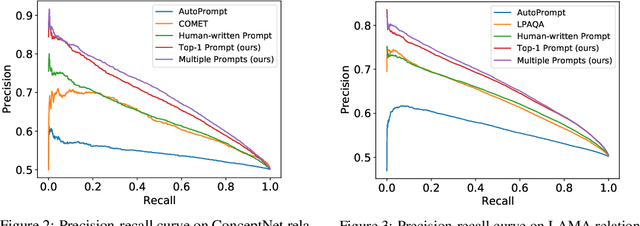

Symbolic knowledge graphs (KGs) have been constructed either by expensive human crowdsourcing or with domain-specific complex information extraction pipelines. The emerging large pretrained language models (LMs), such as Bert, have shown to implicitly encode massive knowledge which can be queried with properly designed prompts. However, compared to the explicit KGs, the implict knowledge in the black-box LMs is often difficult to access or edit and lacks explainability. In this work, we aim at harvesting symbolic KGs from the LMs, a new framework for automatic KG construction empowered by the neural LMs' flexibility and scalability. Compared to prior works that often rely on large human annotated data or existing massive KGs, our approach requires only the minimal definition of relations as inputs, and hence is suitable for extracting knowledge of rich new relations not available before.The approach automatically generates diverse prompts, and performs efficient knowledge search within a given LM for consistent and extensive outputs. The harvested knowledge with our approach is substantially more accurate than with previous methods, as shown in both automatic and human evaluation. As a result, we derive from diverse LMs a family of new KGs (e.g., BertNet and RoBERTaNet) that contain a richer set of commonsense relations, including complex ones (e.g., "A is capable of but not good at B"), than the human-annotated KGs (e.g., ConceptNet). Besides, the resulting KGs also serve as a vehicle to interpret the respective source LMs, leading to new insights into the varying knowledge capability of different LMs.