 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Research: A Pre-Computing Solution for Online Advertising Serving
Jun 26, 2022
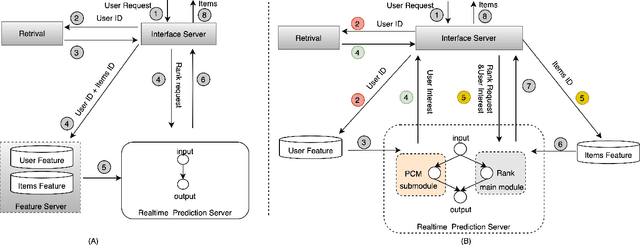

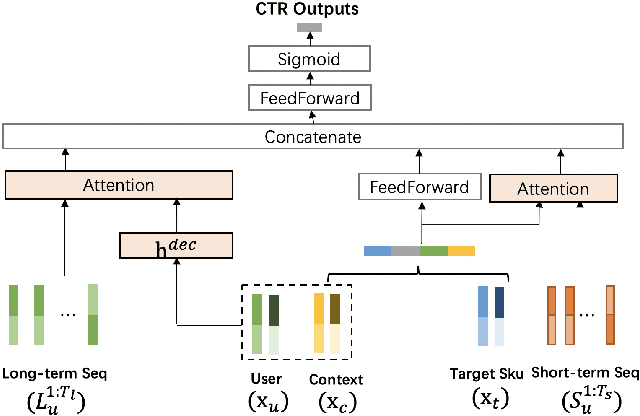
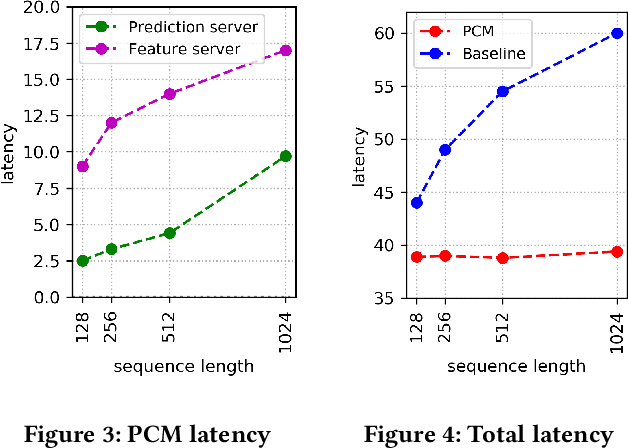
Click-Through Rate (CTR) prediction plays a key role in online advertising systems and online advertising. Constrained by strict requirements on online inference efficiency, it is often difficult to deploy useful but computationally intensive modules such as long-term behaviors modeling. Most recent works attempt to mitigate the online calculation issue of long historical behaviors by adopting two-stage methods to balance online efficiency and effectiveness. However, the information gaps caused by two-stage modeling may result in a diminished performance gain. In this work, we propose a novel framework called PCM to address this challenge in the view of system deployment. By deploying a pre-computing sub-module parallel to the retrieval stage, our PCM effectively reduces overall inference time which enables complex modeling in the ranking stage. Comprehensive offline and online experiments are conducted on the long-term user behaviors module to validate the effectiveness of our solution for the complex models. Moreover, our framework has been deployed into a large-scale real-world E-commerce system serving the main interface of hundreds of millions of active users, by deploying long sequential user behavior model in PCM. We achieved a 3\% CTR gain, with almost no increase in the ranking latency, compared to the base framework demonstrated from the online A/B test. To our knowledge, we are the first to propose an end-to-end solution for online training and deployment on complex CTR models from the system framework side.
On the Influence of Enforcing Model Identifiability on Learning dynamics of Gaussian Mixture Models
Jun 17, 2022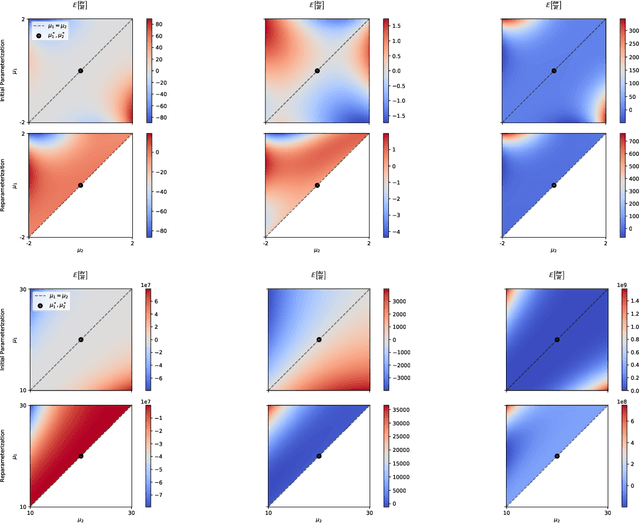
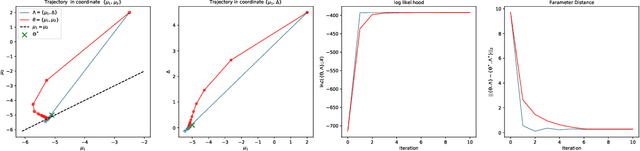
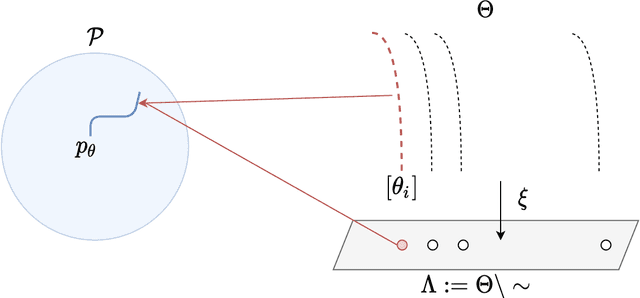
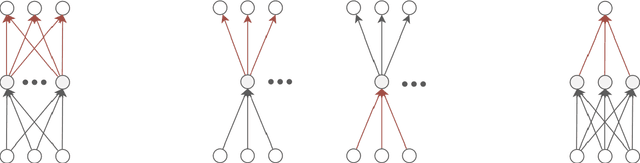
A common way to learn and analyze statistical models is to consider operations in the model parameter space. But what happens if we optimize in the parameter space and there is no one-to-one mapping between the parameter space and the underlying statistical model space? Such cases frequently occur for hierarchical models which include statistical mixtures or stochastic neural networks, and these models are said to be singular. Singular models reveal several important and well-studied problems in machine learning like the decrease in convergence speed of learning trajectories due to attractor behaviors. In this work, we propose a relative reparameterization technique of the parameter space, which yields a general method for extracting regular submodels from singular models. Our method enforces model identifiability during training and we study the learning dynamics for gradient descent and expectation maximization for Gaussian Mixture Models (GMMs) under relative parameterization, showing faster experimental convergence and a improved manifold shape of the dynamics around the singularity. Extending the analysis beyond GMMs, we furthermore analyze the Fisher information matrix under relative reparameterization and its influence on the generalization error, and show how the method can be applied to more complex models like deep neural networks.
Unsupervised Tokenization Learning
May 23, 2022
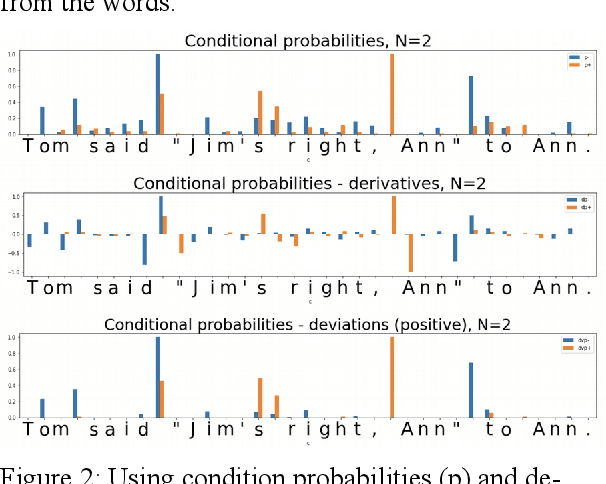
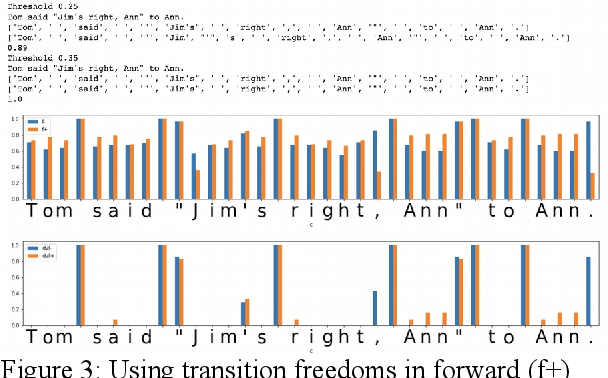
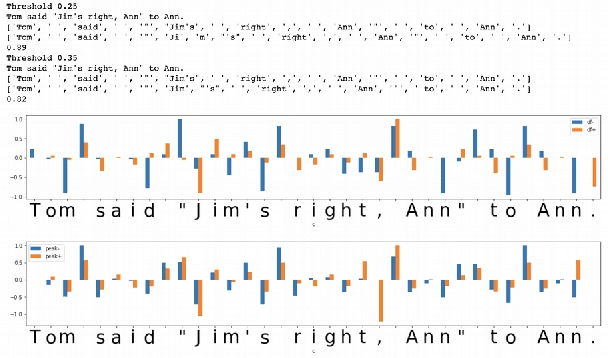
In the presented study, we discover that so called "transition freedom" metric appears superior for unsupervised tokenization purposes, compared to statistical metrics such as mutual information and conditional probability, providing F-measure scores in range from 0.71 to 1.0 across explored corpora. We find that different languages require different derivatives of that metric (such as variance and "peak values") for successful tokenization. Larger training corpora does not necessarily effect in better tokenization quality, while compacting the models eliminating statistically weak evidence tends to improve performance. Proposed unsupervised tokenization technique provides quality better or comparable to lexicon-based one, depending on the language.
Role of Attentive History Selection in Conversational Information Seeking
Feb 07, 2021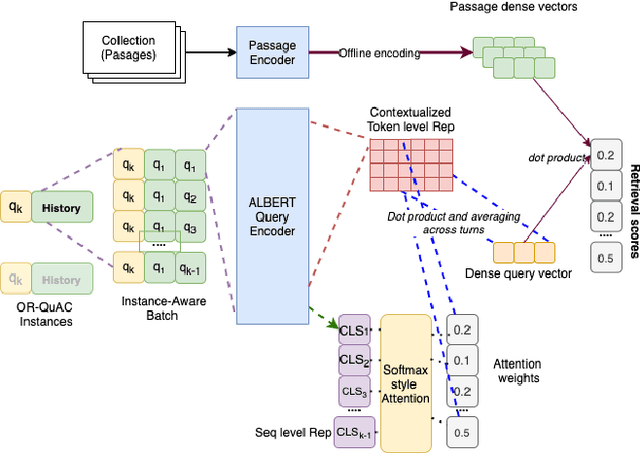
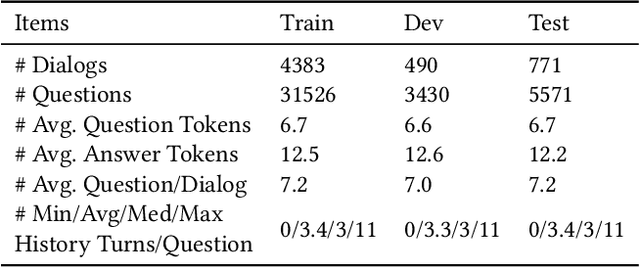
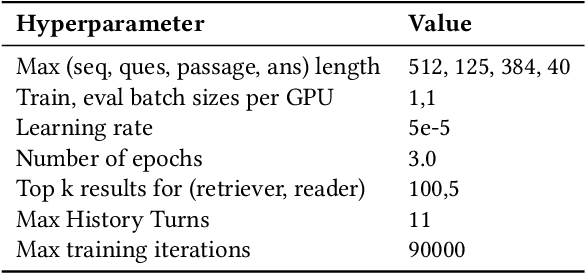
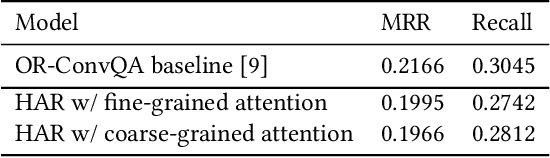
The rise of intelligent assistant systems like Siri and Alexa have led to the emergence of Conversational Search, a research track of Information Retrieval (IR) that involves interactive and iterative information-seeking user-system dialog. Recently released OR-QuAC and TCAsT19 datasets narrow their research focus on the retrieval aspect of conversational search i.e. fetching the relevant documents (passages) from a large collection using the conversational search history. Currently proposed models for these datasets incorporate history in retrieval by appending the last N turns to the current question before encoding. We propose to use another history selection approach that dynamically selects and weighs history turns using the attention mechanism for question embedding. The novelty of our approach lies in experimenting with soft attention-based history selection approach in an open-retrieval setting.
NAFS: A Simple yet Tough-to-beat Baseline for Graph Representation Learning
Jun 17, 2022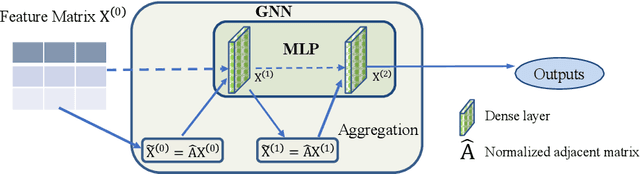
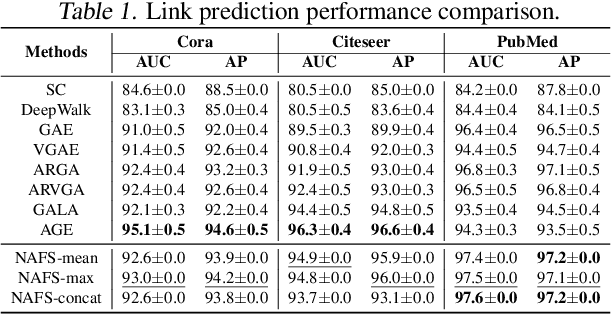
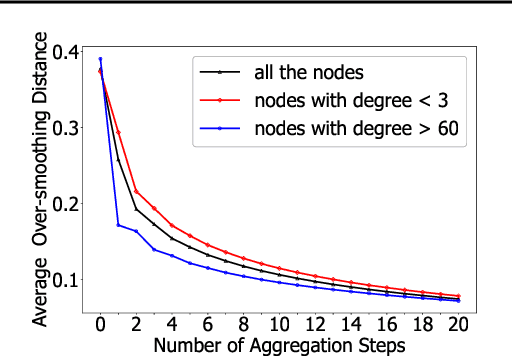
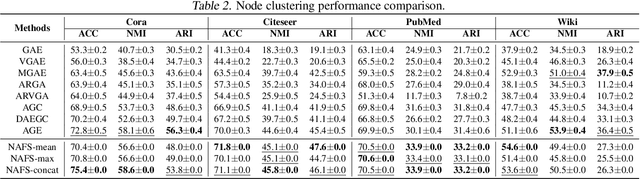
Recently, graph neural networks (GNNs) have shown prominent performance in graph representation learning by leveraging knowledge from both graph structure and node features. However, most of them have two major limitations. First, GNNs can learn higher-order structural information by stacking more layers but can not deal with large depth due to the over-smoothing issue. Second, it is not easy to apply these methods on large graphs due to the expensive computation cost and high memory usage. In this paper, we present node-adaptive feature smoothing (NAFS), a simple non-parametric method that constructs node representations without parameter learning. NAFS first extracts the features of each node with its neighbors of different hops by feature smoothing, and then adaptively combines the smoothed features. Besides, the constructed node representation can further be enhanced by the ensemble of smoothed features extracted via different smoothing strategies. We conduct experiments on four benchmark datasets on two different application scenarios: node clustering and link prediction. Remarkably, NAFS with feature ensemble outperforms the state-of-the-art GNNs on these tasks and mitigates the aforementioned two limitations of most learning-based GNN counterparts.
* 17 pages, 8 figures
IIRC: A Dataset of Incomplete Information Reading Comprehension Questions
Nov 13, 2020
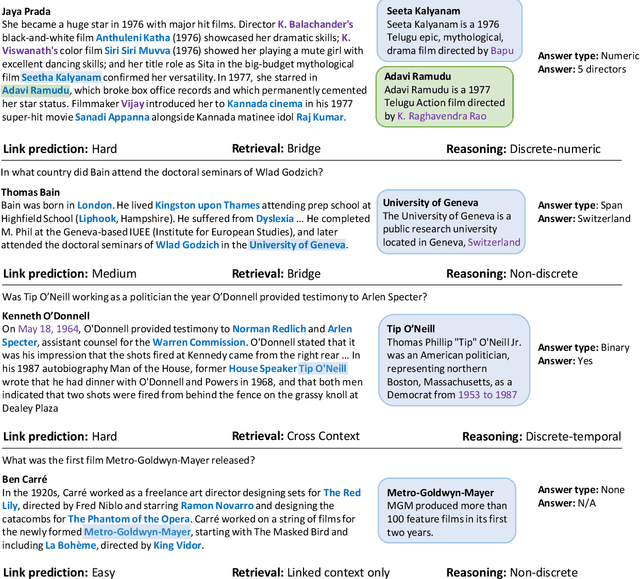

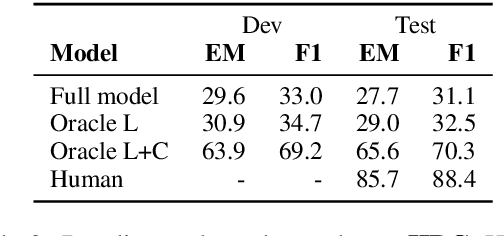
Humans often have to read multiple documents to address their information needs. However, most existing reading comprehension (RC) tasks only focus on questions for which the contexts provide all the information required to answer them, thus not evaluating a system's performance at identifying a potential lack of sufficient information and locating sources for that information. To fill this gap, we present a dataset, IIRC, with more than 13K questions over paragraphs from English Wikipedia that provide only partial information to answer them, with the missing information occurring in one or more linked documents. The questions were written by crowd workers who did not have access to any of the linked documents, leading to questions that have little lexical overlap with the contexts where the answers appear. This process also gave many questions without answers, and those that require discrete reasoning, increasing the difficulty of the task. We follow recent modeling work on various reading comprehension datasets to construct a baseline model for this dataset, finding that it achieves 31.1% F1 on this task, while estimated human performance is 88.4%. The dataset, code for the baseline system, and a leaderboard can be found at https://allennlp.org/iirc.
Predicting Loose-Fitting Garment Deformations Using Bone-Driven Motion Networks
May 06, 2022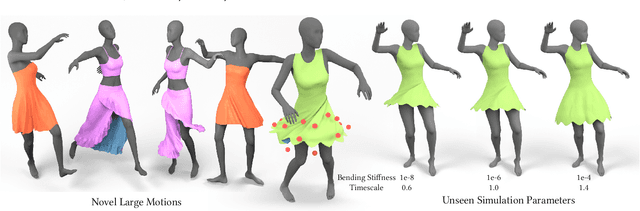
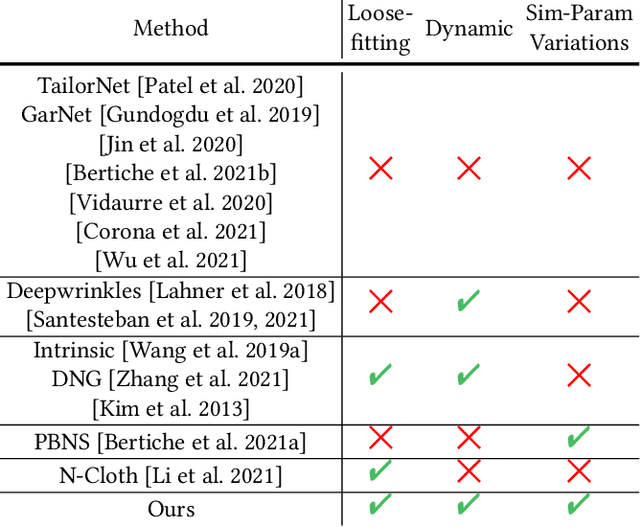
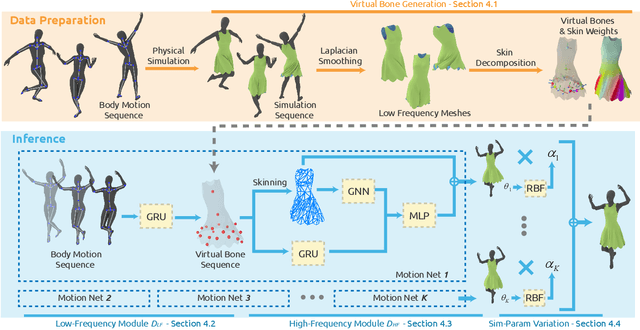
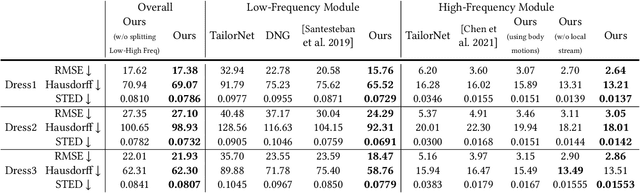
We present a learning algorithm that uses bone-driven motion networks to predict the deformation of loose-fitting garment meshes at interactive rates. Given a garment, we generate a simulation database and extract virtual bones from simulated mesh sequences using skin decomposition. At runtime, we separately compute low- and high-frequency deformations in a sequential manner. The low-frequency deformations are predicted by transferring body motions to virtual bones' motions, and the high-frequency deformations are estimated leveraging the global information of virtual bones' motions and local information extracted from low-frequency meshes. In addition, our method can estimate garment deformations caused by variations of the simulation parameters (e.g., fabric's bending stiffness) using an RBF kernel ensembling trained networks for different sets of simulation parameters. Through extensive comparisons, we show that our method outperforms state-of-the-art methods in terms of prediction accuracy of mesh deformations by about 20% in RMSE and 10% in Hausdorff distance and STED. The code and data are available at https://github.com/non-void/VirtualBones.
Transition-based Abstract Meaning Representation Parsing with Contextual Embeddings
Jun 13, 2022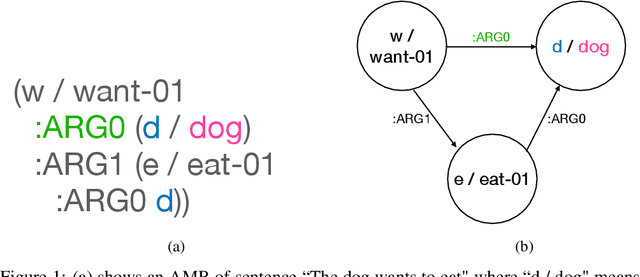
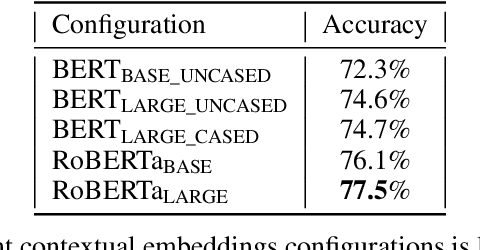


The ability to understand and generate languages sets human cognition apart from other known life forms'. We study a way of combing two of the most successful routes to meaning of language--statistical language models and symbolic semantics formalisms--in the task of semantic parsing. Building on a transition-based, Abstract Meaning Representation (AMR) parser, AmrEager, we explore the utility of incorporating pretrained context-aware word embeddings--such as BERT and RoBERTa--in the problem of AMR parsing, contributing a new parser we dub as AmrBerger. Experiments find these rich lexical features alone are not particularly helpful in improving the parser's overall performance as measured by the SMATCH score when compared to the non-contextual counterpart, while additional concept information empowers the system to outperform the baselines. Through lesion study, we found the use of contextual embeddings helps to make the system more robust against the removal of explicit syntactical features. These findings expose the strength and weakness of the contextual embeddings and the language models in the current form, and motivate deeper understanding thereof.
Semantic localization in BIM using a 3D LiDAR sensor
May 02, 2022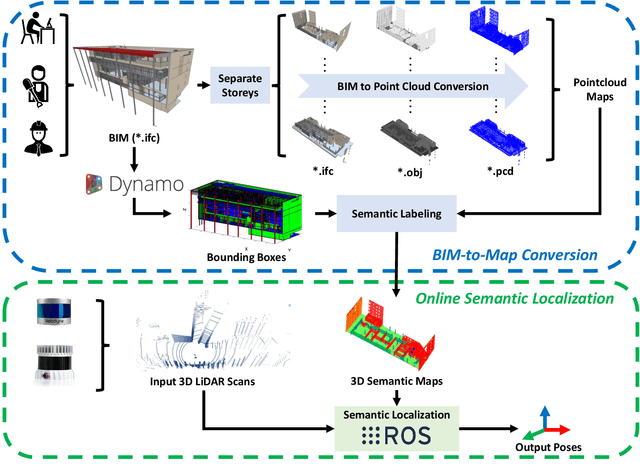

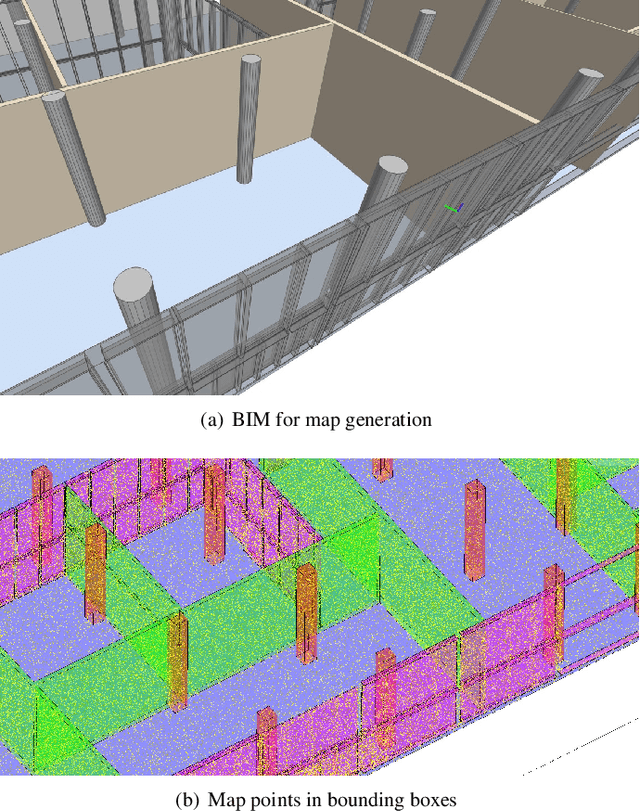
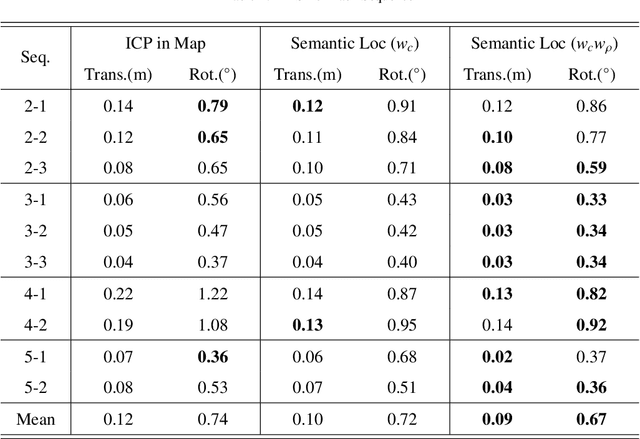
Conventional sensor-based localization relies on high-precision maps. These maps are generally built using specialized mapping techniques, which involve high labor and computational costs. While in the architectural, engineering and construction industry, building information models (BIMs) are available and can provide informative descriptions of environments. This paper explores an effective way to localize a mobile 3D LiDAR sensor in BIM considering both geometric and semantic properties. Specifically, we first convert original BIM to semantic maps using categories and locations of BIM elements. After that, a coarse-to-fine semantic localization is performed to align laser points to the map via iterative closest point registration. The experimental results show that the semantic localization can track the pose with only scan matching and present centimeter-level errors over 340 meters traveling, thus demonstrating the feasibility of the proposed mapping-free localization framework. The results also show that using semantic information can help reduce localization errors in BIM.
LightFR: Lightweight Federated Recommendation with Privacy-preserving Matrix Factorization
Jun 23, 2022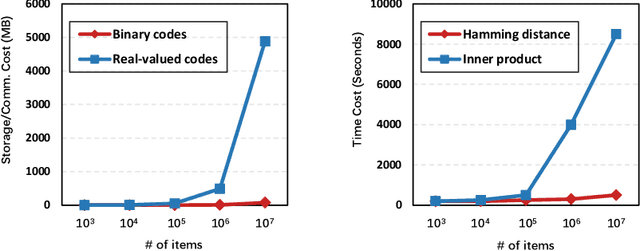


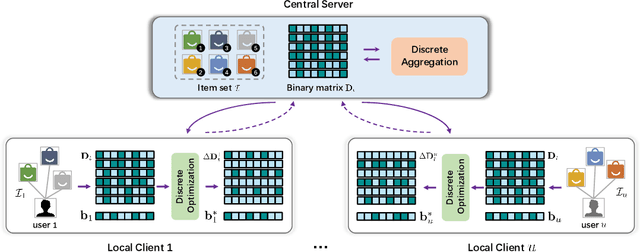
Federated recommender system (FRS), which enables many local devices to train a shared model jointly without transmitting local raw data, has become a prevalent recommendation paradigm with privacy-preserving advantages. However, previous work on FRS performs similarity search via inner product in continuous embedding space, which causes an efficiency bottleneck when the scale of items is extremely large. We argue that such a scheme in federated settings ignores the limited capacities in resource-constrained user devices (i.e., storage space, computational overhead, and communication bandwidth), and makes it harder to be deployed in large-scale recommender systems. Besides, it has been shown that the transmission of local gradients in real-valued form between server and clients may leak users' private information. To this end, we propose a lightweight federated recommendation framework with privacy-preserving matrix factorization, LightFR, that is able to generate high-quality binary codes by exploiting learning to hash techniques under federated settings, and thus enjoys both fast online inference and economic memory consumption. Moreover, we devise an efficient federated discrete optimization algorithm to collaboratively train model parameters between the server and clients, which can effectively prevent real-valued gradient attacks from malicious parties. Through extensive experiments on four real-world datasets, we show that our LightFR model outperforms several state-of-the-art FRS methods in terms of recommendation accuracy, inference efficiency and data privacy.